用于誘導TH17細胞的組合物及方法與流程
本文描述的主題涉及誘導T輔助細胞17(Th17)細胞增殖的人來源細菌的組合物,其包含作為活性成分的人來源細菌,優選為(a)從排泄物樣品的氨芐青霉素抗性細菌級分分離和培養的一種或多種細菌,或(b)一種或多種(a)細菌的培養物上清。本發明還涉及誘導Th17細胞增殖的方法。包含上述(a)~(b)中任意的組合物稱為細菌組合物。此外,本主題涉及通過將細菌組合物單獨或與抗原組合口服施用于對其有需要的個體來治療或預防對Th17細胞的誘導有應答的至少一種疾病或病癥(例如傳染性疾病)的方法。
發明背景
數百種共生微生物生活在哺乳動物的胃腸道中,在那里它們與宿主免疫系統相互作用。使用無菌(GF)動物的研究已經顯示共生微生物影響粘膜疫苗免疫系統的形成(development),例如派伊爾氏淋巴集結(Peyer’s patches,PP)和分離的淋巴濾泡(ILF)的組織發生,抗微生物肽從上皮的分泌,以及粘膜組織中的獨特淋巴細胞的累積,包括產生免疫球蛋白A的漿細胞,上皮內淋巴細胞,產生IL-17的CD4陽性T細胞(Th17)、和產生IL-22的NK樣細胞((非專利文獻(NPL)1至7)。因此,腸道細菌的存在增強了粘膜的保護功能,使得宿主能夠對侵入身體的病原微生物產生強大的免疫應答。另一方面,粘膜免疫系統維持對膳食抗原和無害微生物的無反應性(NPL文獻3)。調節共生細菌和免疫系統(腸道生態失調)之間的對話中的異常可能導致對環境抗原和對共生和病原微生物的過度穩健或不足夠穩定的免疫應答,導致疾病(NPL 8至10)。需要更好的方法來使身體對入侵的致病微生物產生有效的免疫應答。
現有技術文獻
非專利文獻
[NPL 1]J.J.Cebra,"Am J Clin Nutr",May,1999,69,1046S
[NPL 2]A.J.Macpherson,N.L.Harris,"Nat Rev Immunol",June 2004,4,478
[NPL 3]J.L.Round,S.K.Mazmanian,"Nat Rev Immunol",May 2009,9,313
[NPL 4]D.Bouskra等,"Nature",November 27,2008,456,507
[NPL 5]K.Atarashi等,"Nature",October 9,2008,455,808
[NPL 6]I.I.Ivanov等,"Cell Host Microbe",October 16,2008,4,337
[NPL 7]S.L.Sanos等,"Nat Immunol",January 2009,10,83
[NPL 8]M.A.Curotto de Lafaille,J.J.Lafaille,"Immunity",May 2009,30,626
[NPL 9]M.J.Barnes,F.Powrie,"Immunity",September 18,2009,31,401
[NPL 10]W.S.Garrett等,"Cell",October 5,2007,131,33
[NPL 11]I.I.Ivanov,等,"Cell",October 30,2009,139,485
[NPL 12]V.Gaboriau-Routhiau等,"Immunity",October 16,2009,31,677
[NPL 13]N.H.Salzman等,"Nat Immunol",January 2010,11,76.
[NPL 14]J.Quin等,"Nature",March 4,2010,464,59
[NPL 15]T.Korn等,"Annu Rev Immunol",April 2009,27,485
[NPL 16]P.Miossec等,"N Engl N Med",August 27,2009,361,888
[NPL 17]I.I.Ivanov等,"Cell",September 22,2006,126,1121
[NPL 18]Lycke N,“Nature Reviews Immunology”,August 2012,12,605
發明概述
鑒于本領域中的上述問題,制得了本發明的組合物和方法。如本文所述,盡管在人微生物群中存在的一千多個菌種中的大多數細菌菌種不具有刺激Th17細胞的能力,但通過用各種抗生素處理改良來自人的排泄物樣品、應用方法來體外分離純菌株,以及開發培養方法來制備含有適合用作藥物和食品成分的菌株的細菌組合物,本發明人已經從人獲得了一些細菌菌種,其具有引起對Th17細胞的穩健誘導的能力。此外,發明人已顯示了用體外培養的菌株來接種動物也產生Th17細胞的穩健累積。
本文描述了獲得和培養分離自人的腸道共生細菌的方法,所述細菌誘導,優選為強力誘導Th17細胞的增殖、累積、或增殖和累積。描述了這樣的組合物(也稱為細菌組合物),其包含作為活性成分的(a)一種或多種(至少一種)本文提供的特定菌種(表1)或含有DNA的細菌,所述DNA包含與本文提供的序列具有至少97%的同源性(例如97%的同源性、98%的同源性、99%的同源性、或100%同源性)的核苷酸序列;(b)一種或多種(至少一種)此類細菌的培養物上清;或(c)(a)和(b)的組合,并且所述組合物誘導T輔助17細胞(Th17細胞)的增殖和/或累積。
更具體而言:
一個實施方案是誘導Th17細胞的增殖、累積、或增殖和累積二者的組合物(也稱為細菌組合物),所述組合物包含作為活性成分的(a)至少一種(一種或多種)選自下組的生物:共生梭菌(Clostridium symbiosum),哈氏梭菌(Clostridium hathewayi),Clostridium citroniae,鮑氏梭菌(Clostridium bolteae),瘤胃球菌屬菌種M-1(Ruminococcus sp.M-1),活潑瘤胃球菌(Ruminococcus gnavus),布勞特氏菌屬菌種犬口類143(Blautia sp.canine oral taxon 143),糞厭氧棒狀菌(Anaerostipes caccae),乳酸發酵梭菌(Clostridium lactatifermentans),Coprobacillus cateniformis,多枝梭菌(Clostridium ramosum),參見梭菌屬菌種MLG055(cf.Clostridium sp.MLG055),無害梭菌(Clostridium innocuum),鏈狀真桿菌(Eubacterium desmolans),圓環梭菌(Clostridium orbiscindens),瘤胃球菌屬菌種16442(Ruminococcus sp.16442),人腸道厭氧棒狀菌(Anaerotruncus colihominis),Bacteroides dorei,假長雙歧桿菌假長亞種(Bifidobacterium pseudolongum subsp.Pseudolongum),和短雙歧桿菌(Bifidobacterium breve);(b)至少一種(一種或多種)(a)細菌的培養物上清;或(c)至少一種(一種或多種)(a)細菌和至少一種(一種或多種)(a)細菌的培養物上清的組合。
一個實施方案是誘導Th17細胞增殖和/或累積的組合物,該組合物包含作為活性成分的(a)排泄物樣品的氨芐青霉素抗性細菌級分;(b)一種或多種(a)細菌的培養物上清;或(a)和(b)的組合物。
在一些實施方案中,活性成分是如下的一種或多種:共生梭菌,哈氏梭菌,Clostridium citroniae,鮑氏梭菌,瘤胃球菌屬菌種M-1,活潑瘤胃球菌,布勞特氏菌屬菌種犬口類143,糞厭氧棒狀菌,乳酸發酵梭菌,Coprobacillus cateniformis,多枝梭菌,參見梭菌屬菌種MLG055,無害梭菌,鏈狀真桿菌,圓環梭菌,瘤胃球菌屬菌種16442,人腸道厭氧棒狀菌,Bacteroides dorei,假長雙歧桿菌假長亞種,和短雙歧桿菌;以及本文所述/所列出的一種或多種細菌的培養物上清。在一些實施方案中,所述活性成分是文所述/所列出的一種或多種細菌的培養物上清。在一些實施方案中,所述一種或多種細菌或來源于細菌的一種或多種培養物上清是三種或更多種。在一些實施方案中,所述一種或多種細菌或來源于細菌的一種或多種培養物上清是五種或更多種。在一些實施方案中,所述一種或多種細菌或來源于細菌的一種或多種培養物上清是10種或更多種。在一些實施方案中,所述一種或多種細菌或來源于細菌的一種或多種培養物上清是15種或更多種。在一些實施方案中,所述一種或多種細菌或來源于細菌的一種或多種培養物上清是20種。
本文所述的細菌組合物包含如下的至少一項:一種本文所述的細菌;至少一種獲取自培養物的培養物上清或該上清中的級分,所述上清中存在(生長有或保持有)所述一種(或多種)細菌。其可以包含任何前述的組合。術語組合物/細菌組合物意指所有此類組合物。
誘導Th17細胞增殖和/或累積的組合物中的細菌可以是例如共生梭菌,哈氏梭菌,Clostridium citroniae,鮑氏梭菌,瘤胃球菌屬菌種M-1,活潑瘤胃球菌,布勞特氏菌屬菌種犬口類143,糞厭氧棒狀菌,乳酸發酵梭菌,Coprobacillus cateniformis,多枝梭菌,參見梭菌屬菌種MLG055,無害梭菌,鏈狀真桿菌,圓環梭菌,瘤胃球菌屬菌種16442,人腸道厭氧棒狀菌,Bacteroides dorei,假長雙歧桿菌假長亞種,和短雙歧桿菌,或任何含有這樣的DNA的細菌(如來源于人的細菌),所述DNA與本文提供的序列具有至少97%的同源性(例如97%,98%,99%或100%的同源性),所述序列例如但不限于指定為SEQ ID No.1-20的核苷酸序列,其列示于最后一個實施例之后的頁上以及序列表中。在具體的實施方案中,細菌含有包含核苷酸序列的DNA,所述核苷酸序列與指定為SEQ ID No.1-20的一個或多個DNA序列具有至少97%、至少98%或至少99%的同源性。或者,細菌含有包含核苷酸序列的DNA,所述核苷酸序列與如下一項或多項的DNA具有至少97%(例如97%,98%,99%,100%)的同源性:共生梭菌,哈氏梭菌,Clostridium citroniae,鮑氏梭菌,瘤胃球菌屬菌種M-1,活潑瘤胃球菌,布勞特氏菌屬菌種犬口類143,糞厭氧棒狀菌,乳酸發酵梭菌,Coprobacillus cateniformis,多枝梭菌,參見梭菌屬菌種MLG055,無害梭菌,鏈狀真桿菌,圓環梭菌,瘤胃球菌屬菌種16442,人腸道厭氧棒狀菌,Bacteroides dorei,假長雙歧桿菌假長亞種,和短雙歧桿菌。
在一個實施方案中,組合物誘導的Th17細胞是轉錄因子RORgt陽性的T細胞或產生IL-17的Th17細胞。在另一個實施方案中,組合物在粘膜表面促進保護性免疫應答。
一個實施方案是藥物組合物,其誘導Th17細胞的增殖、累積或增殖和/或累積二者,并促進免疫功能。所述藥物組合物包含本文所述的細菌組合物及藥學上可接受的組分,如載劑、溶劑或稀釋劑。在一個具體實施方案中,此種藥物組合物包含(a)(1)至少一種(一種或多種)表1中列出的或本文所述的細菌菌種,(2)至少一種(一種或多種)此類細菌的培養物上清,或(3)至少一種(一種或多種)表1中列出的或本文所述的細菌菌種與至少一種(一種或多種)此類細菌的至少一種(一種或多種)培養物上清的組合,及(b)藥學上可接受的組分,如載劑、溶劑或稀釋劑。在具體實施方案中,上述(a)是至少一種選自下組的生物或物質:共生梭菌,哈氏梭菌,Clostridium citroniae,鮑氏梭菌,瘤胃球菌屬菌種M-1,活潑瘤胃球菌,布勞特氏菌屬菌種犬口類143,糞厭氧棒狀菌,乳酸發酵梭菌,Coprobacillus cateniformis,多枝梭菌,參見梭菌屬菌種MLG055,無害梭菌,鏈狀真桿菌,圓環梭菌,瘤胃球菌屬菌種16442,人腸道厭氧棒狀菌,Bacteroides dorei,假長雙歧桿菌假長亞種,和短雙歧桿菌,及一種或多種所述細菌的培養物上清。在一些實施方案中,上述(a)(2)是所述細菌的至少一種(一種或多種)的培養物上清。在一些實施方案中,所述至少一種生物或物質是兩種或更多種或三種或更多種。在一些實施方案中,所述至少一種生物或物質是四種或更多種或五種或更多種。在一些實施方案中,所述至少一種生物或物質是10種或更多種。在一些實施方案中,所述至少一種生物或物質是15種或更多種。在一些實施方案中,所述至少一種生物或物質是20種。在進一步的實施方案中,上述(a)(1)是含有與本文提供的序列具有至少97%的同源性(例如97%,98%,99%,或100%的同源性)的DNA的細菌(如來源于人的細菌),所述序列例如但不限于本文指定為SEQ ID No.1-20的核苷酸序列,其列示于例如最后一個實施例之后的頁上及序列表中。在藥物組合物的具體實施例中,所述細菌含有與指定為SEQ ID No.1-20的一個或多個DNA序列具有至少97%,至少98%,至少99%或至少100%的同源性的DNA。
所述藥物組合物誘導T輔助細胞(Th17細胞)的增殖和/或累積并促進免疫功能。
還提供了在個體(例如對其有需要的個體,如需要誘導Th17細胞增殖和/或累積的個體)中誘導Th17細胞增殖、累積或增殖和累積二者的方法。該方法包括對個體施用本文所述的細菌組合物或包含本文所述的細菌組合物的藥物組合物。在該方法中,對個體(也稱為對其有需要的個體,其可以是健康個體或是需要預防、降低或治療病況或疾病的個體)施用至少一種選自下組的生物或物質:共生梭菌,哈氏梭菌,Clostridium citroniae,鮑氏梭菌,瘤胃球菌屬菌種M-1,活潑瘤胃球菌,布勞特氏菌屬菌種犬口類143,糞厭氧棒狀菌,乳酸發酵梭菌,Coprobacillus cateniformis,多枝梭菌,參見梭菌屬菌種MLG055,無害梭菌,鏈狀真桿菌,圓環梭菌,瘤胃球菌屬菌種16442,人腸道厭氧棒狀菌,Bacteroides dorei,假長雙歧桿菌假長亞種,和短雙歧桿菌;一種或多種所述細菌的培養物上清或所述培養物上清的一種或多種組分;或前述任意多項的組合。例如,可以將所述細菌組合物施用于需要治療、預防疾病或病況(如傳染性疾病)或降低其嚴重程度的個體。
任選地,細菌組合物的施用可以與一種或多種抗生素的療程進行組合,或在一種或多種抗生素的療程之后(preceeded by)進行。
任選地,細菌組合物的施用可以與至少一種益生元物質(prebiotic substance)的施用進行組合,所述益生元物質相對于其他人共生細菌菌種的生長而言優先地幫助所述細菌組合物中的菌種生長。在一個實施方案中,所述益生元物質是例如不易消化的寡糖。
在一個進一步的實施方案中,所述細菌組合物可用作佐劑來改進粘膜疫苗制劑的效力。例如,所述細菌組合物可用作疫苗的佐劑,所述疫苗用于預防或治療傳染性疾病或癌癥。在一些實施方案中,提供了用于預防或治療的方法,該方法包括將細菌組合物或藥物組合物作為疫苗佐劑施用。所述細菌組合物或藥物組合物可以作為佐劑伴隨現有的粘膜疫苗一起施用。
在一個進一步的實施方案中,所述細菌組合物包含作為活性成分的至少一種選自下組的生物:共生梭菌,哈氏梭菌,Clostridium citroniae,鮑氏梭菌,瘤胃球菌屬菌種M-1,活潑瘤胃球菌,布勞特氏菌屬菌種犬口類143,糞厭氧棒狀菌,乳酸發酵梭菌,Coprobacillus cateniformis,多枝梭菌,參見梭菌屬菌種MLG055,無害梭菌,鏈狀真桿菌,圓環梭菌,瘤胃球菌屬菌種16442,人腸道厭氧棒狀菌,Bacteroides dorei,假長雙歧桿菌假長亞種,和短雙歧桿菌,其中所述生物包含含有異源基因的表達載體,其也稱為表達異種蛋白質或肽(如抗原)的載體。
由本文所述組合物的施用引起的Th17細胞增殖或累積的誘導程度的評估可以通過多種方法來進行,如通過測量施用前后Th17細胞的數目或通過測量Th17活性,如施用后RORgt、IL-17A、IL-17F、IL-22、IL-23、IL-23R、CD161和CCR6中的至少一種的表達相對于利用細菌組合物對個體的施用形成集落(或施用建群,administering colonization)前測定的RORgt、IL-17A、IL-17F、IL-22、IL-23、IL-23R、CD161和CCR6中的至少一種的表達。此類評估的結果用作個體中Th17細胞的增殖或累積的誘導指數。
在一個實施方案中,施用本文所述的組合物引起對Th17細胞的誘導,所述Th17細胞是轉錄因子RORgt陽性的Th17細胞或產生IL-17的Th17細胞。
本文所述的組合物可以通過多種途徑來施用,并且在一個實施方案中是口服施用于對其有需要的個體,如對其有需要的患者。所述組合物可以以數種口服形式施用,如以干粉末、凍干制劑、或溶解于液體制劑中、于腸溶膠囊中、于囊劑中、或于食物基質如酸乳或飲料中施用。
還提供了監測受試者對使用本發明的細菌組合物治療的應答的方法,其包括:(a)在用本文所述的細菌組合物處理前從患者獲得(至少一個;一個或多個)樣品,如排泄物樣品或結腸活檢樣品;(b)在用本文所述的細菌組合物處理后從患者獲得(至少一個;一個或多個)對應的樣品;以及(c)確定和比較(a)中獲得的樣品中至少一個選自下組的細菌菌種的百分比或絕對計數:共生梭菌,哈氏梭菌,Clostridium citroniae,鮑氏梭菌,瘤胃球菌屬菌種M-1,活潑瘤胃球菌,布勞特氏菌屬菌種犬口類143,糞厭氧棒狀菌,乳酸發酵梭菌,Coprobacillus cateniformis,多枝梭菌,參見梭菌屬菌種MLG055,無害梭菌,鏈狀真桿菌,圓環梭菌,瘤胃球菌屬菌種16442,人腸道厭氧棒狀菌,Bacteroides dorei,假長雙歧桿菌假長亞種,和短雙歧桿菌,與(b)中獲得的樣品中相同的至少一個細菌菌種的百分比或絕對計數,其中(b)中(用細菌組合物處理后)獲得的樣品比(a)中(處理前)獲得的樣品的值更高,指示受試者已良好地應答于治療(例如是受試者中增強的免疫應答的陽性指示物)。在一些實施方案中,該方法還包括(d)基于(c)中的比較而進一步對患者施用細菌組合物或停止施用細菌組合物。
還提供了獲得誘導Th17的細菌組合物的方法,其包括(a)用抗生素氨芐青霉素或具有相似譜的抗生素(例如氨基青霉素家族成員如阿莫西林、青霉素、或芐基青霉素)來處理受試者;(b)從受試者獲得(至少一個)樣品,如排泄物樣品或腸活檢樣品(“排泄物樣品的氨芐青霉素抗性細菌級分”);(c)培養來自(b)的樣品并從所得的菌落分離純細菌菌株。在優選實施方案中,(a)中的受試者是先前的無菌動物(ex-germ-free animal),其利用獲取自人供者的排泄物樣品形成集落(colonized with)。在優選實施方案中,(c)的純細菌菌株的分離通過盲腸內容物樣品的系列稀釋來進行,所述盲腸內容物樣品在嚴格厭氧條件下平板(plating)培養。在另一個實施方案中,該方法包括(a)從受試者獲得(至少一個;一個或多個)樣品,如排泄物樣品或腸活檢;(b)用氨芐青霉素處理(a)樣品;(c)培養經氨芐青霉素處理的(b)的樣品并分離純細菌菌株。
還提供了抑制誘導Th17的細菌組合物以治療個體中的自身免疫性疾病和炎性疾病的方法,該方法包括對所述個體施用抗生素,如萬古霉素和/或甲硝唑。
發明效果
本文所述的組合物能優良地誘導T輔助17細胞(Th17細胞)的增殖或累積。可以通過施用主題組合物來促進個體中的免疫力,如通過以食物或飲料形式或作為飲食補充劑攝入細菌組合物或是通過施用包含所述細菌組合物的藥物組合物來進行。例如,主題組合物可以用于預防或治療傳染性疾病,以及與粘膜疫苗組合用于預防由微生物等引起的疾病。此外,如果食物或飲料(如健康食物)包含了主題組合物,健康個體可以容易且常規地攝入所述組合物。因此,可以誘導Th17細胞的增殖和/或累積并由此改進免疫功能。
本文所述的組合物提供強力的、持久的、對患者友好的、且良性的針對傳染性疾病的治療選擇。例如,通常用抗生素來管控傳染性疾病,這可能產生抗生素抗藥性和/或機會性感染;全身性疫苗由于其可注射特性而需要大量的純化,這產生了傳播血源性感染的風險并且對于大規模疫苗接種而言是不可行的;現有的粘膜疫苗不能達到充分的強免疫應答并且常常不如活減毒制劑穩定。
本文所述的用于與粘膜疫苗抗原組合的組合物還可以具有如下效果:增加針對抗原的免疫應答,或延長針對抗原的免疫應答的持續時間,或使達到保護所需的抗原施用的劑量和頻率降低(例如減少含抗原的組合物的加強注射的數目),或提高達到血清轉化的患者的比例,或在其他免疫策略無效的患者(例如年輕或老年群體)中引發最佳免疫應答。
附圖簡述
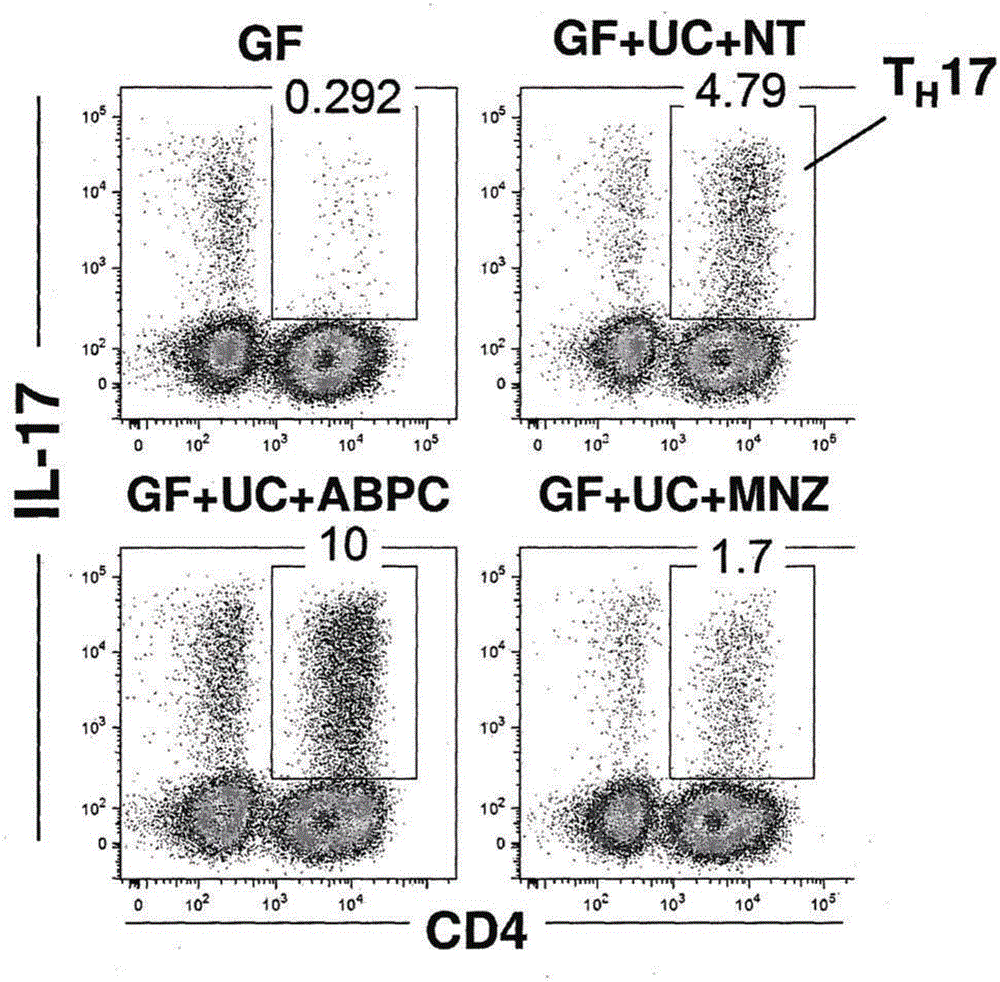
圖1A是FACS點繪圖(dot-plot diagram),其顯示了在CD4+淋巴細胞中的IL-17表達結果的分析,所述細胞分離自無菌(GF)小鼠(左上小圖),或利用來自潰瘍性結腸炎患者的排泄物形成集落的且未處理的GF小鼠(GF+UC+NT,右上小圖),或利用來自潰瘍性結腸炎患者的排泄物形成集落且用飲用水中的氨芐青霉素處理過的GF小鼠(GF+UC+ABPC,左下小圖),或利用來自潰瘍性結腸炎患者的排泄物形成集落且用飲用水中的甲硝唑處理過的GF小鼠(GF+UC+MNZ,右下小圖)的結腸固有層(colonic lamina propia)。
圖1B是圖表,其顯示了無菌小鼠(GF)、利用來自潰瘍性結腸炎患者的排泄物形成集落且未處理的GF小鼠(NT)、或利用來自潰瘍性結腸炎患者的排泄物形成集落且用飲用水中的氨芐青霉素處理過的GF小鼠(ABPC)或萬古霉素處理過的GF小鼠(VCM)或多粘菌素B處理過的GF小鼠(PL-B)或甲硝唑處理過的GF小鼠(MNZ)的CD4+淋巴細胞中IL-17+細胞比率的分析結果。
圖2顯示了盲腸樣品中具有相同最接近相關性(closest relative)的OTU的相對豐度,所述盲腸樣品來自利用來自潰瘍性結腸炎患者的排泄物形成集落的,且僅給予水(未處理:NT)或于飲用水中給予氨芐青霉素(+ABPC;1g/L)、或萬古霉素(+VCM;500mg/L)、或多粘菌素B(+PL-B;200mg/L)、或甲硝唑(+MNZ;1g/L)的IQI無菌小鼠;每組n=5。與Th17細胞數量負相關的OTU以藍色或灰色標示,而與Th17細胞數量正相關的OTU以紅色標記。
圖3A顯示了無菌小鼠和利用表1所示的20個菌株形成集落的無菌小鼠的結腸固定層中CD4+T細胞群體中IL-17+細胞和IFN-g+的百分比。
圖3B是圖表,其顯示了無菌小鼠對比利用表1所示的20個菌株形成集落的無菌小鼠的結腸固定層(CLP)或小腸固定層(SILP)中的CD4+淋巴細胞中IL-17+細胞的比率的分析結果。
表1針對分離自利用人患者排泄物形成集落且用氨芐青霉素處理的小鼠的盲腸內容物的20個細菌菌株的每一個顯示了來自RDP(Ribosomal DatabaseProject)數據庫的已知菌種中的最接近相關物,以及與所述最接近相關物的最大相似性。
實施方案描述
近期的研究顯示,個體共生細菌控制粘膜疫苗系統中的其特異性的免疫細胞的分化。例如,小鼠中的腸道共生細菌,分段絲狀菌,其誘導粘膜的Th17細胞應答并增強針對具有病原體的宿主胃腸道感染的抗性(NPL 11至13)。雖然已經鑒定出了鼠細菌共生體的具體菌種,例如分段絲狀菌(其能強力刺激Th17細胞)(NPL 11至13),但尚未明確人共生細菌的菌種是否對人免疫系統發揮相當的影響。此外,人腸道容納超過一千種細菌菌種,其中許多都尚未進行培養(NPL 14)。推測哪一種(如果有的話)可能對Th17細胞起作用是不可行的。
為了開發用于人用途的具有有益免疫功能的藥物、疫苗、飲食補充劑、或食物,需要鑒定出天然在人中形成集落且具有免疫調節特性的共生微生物。此外,由于尚未對人微生物組中的許多共生體加以培養,因此需要開發出培養它們的方法,從而使其能通過工業發酵工藝來生產并隨后整合于藥物或食品制劑中。
T輔助17(Th17)細胞是CD4+T輔助細胞的一個亞組,其在黏膜表面提供抗微生物免疫力,這對于防御微生物如細菌和真菌是至關重要的。Th17細胞依賴于TGF-β和IL-6用于進行分化,并且由種系特異性轉錄因子RORgt(NPL11、15、和16)所定義。表達RORgt的Th17細胞大量存在于胃腸道中(NPL 6、17)。記憶CD4+和CD8+T細胞也可以因粘膜疫苗接種而產生。具體而言,具有局域保護性功能的記憶Th17細胞可以通過粘膜疫苗接種來誘導(NPL 18)。
許多傳染性疾病局限于粘膜上,或者感染原需要在感染早期過程中穿過粘膜。因此,作為免疫的結果不僅需要得到全身免疫應答,還需要得到局部粘膜疫苗接種應答,其可能增強針對感染的保護。因此,通過粘膜途徑施用的疫苗能特別有效地保護抵抗粘膜病原體。然而,現有的粘膜疫苗在粘膜處促進穩健免疫應答的能力有限,這是由于其對抗原的暴露不足夠長、由于提供的抗原量不足以誘發穩健應答、或是由于抗原的免疫原性或穩定性不足所致。在一定程度上,由于這些原因,當前使用的大多數疫苗仍然是經腸道外途徑施用的。當宿主對免疫原性抗原的免疫應答過弱時,可能需要通過共同施用佐劑來將其增強。
因此,需要來源于人的具有強力誘導Th17細胞能力的共生細菌組合物,同樣需要制造此類組合物的方法。此類組合物可用于使宿主增加針對入侵身體的病原性微生物的穩健免疫應答,并從而用作抗感染劑或作為粘膜疫苗的佐劑。
術語“T輔助17細胞(Th17細胞)”意指促進免疫應答并在免疫防疫中起作用的T細胞。Th17細胞通常是轉錄因子RORgt陽性的、CD4陽性的T細胞。本發明的Th17細胞還包括轉錄因子RORgt陰性但產生IL-17的、CD4陽性的T細胞。
術語“誘導Th17細胞增殖或累積”意指誘導未成熟T細胞分化為Th17細胞的效果,該分化導致Th17細胞的增殖和/或累積。此外,“誘導Th17細胞增殖或累積”的含義包括體內效果、體外效果、以及離體效果。包括所有如下效果:通過施用或攝入前述細菌、或所述細菌的培養物上清或上清組分(一種或多種)來誘導Th17細胞的體內增殖或累積的效果;通過引發前述細菌或所述細菌的培養物上清或上清組分(一種或多種)作用于培養的Th17細胞,從而誘導培養的Th17細胞的增殖或累積的效果;以及通過引發前述細菌、所述細菌的培養物上清或上清組分(一種或多種)、或來源于所述細菌的生理學活性物質作用于這樣的Th17細胞,來誘導所述Th17細胞的增殖或累積的效果,所述Th17細胞收集自活體且意欲隨后將其引入活體,如引入獲取所述細胞的生物體或其他生物體。可以按照例如如下來評估誘導Th17細胞增殖或累積的效果。具體而言,將前述細菌、所述細菌的培養物上清或上清組分(一種或多種)、或來源于所述細菌的生理學活性物質口服施用于實驗動物,如無菌小鼠,然后分離胃腸道中的CD4陽性細胞,并通過流式細胞術來測量CD4陽性細胞中含有的Th17細胞比率。
通過本發明的組合物來誘導其增殖或累積的Th17細胞優選為轉錄因子RORgt陽性的Th17細胞或產生IL-17的Th17細胞。
在本發明中,“人來源的細菌”意指分離自從人個體獲得的排泄物樣品或胃腸道活檢的細菌菌種,或其祖先是分離自從人獲得的排泄物樣品或胃腸道活檢的細菌菌種(例如其是獲取自排泄物樣品或胃腸道活檢的細菌的后代)。例如,所述細菌菌種可以是之前分離自從人獲得的排泄物樣品或胃腸道活檢的,并且培養了足夠的時間以產生后代。然后將所述后代進一步培養或冷凍。
在本發明中,術語“免疫應答”表示在具有運轉的免疫系統的宿主中抗原(如蛋白抗原)產生的任何反應。免疫應答可以是體液的,其涉及免疫球蛋白或抗體的產生;或是細胞的,其涉及多種類型的B淋巴細胞和T淋巴細胞、樹突細胞、巨噬細胞、抗原呈遞細胞等等;或二者均有涉及。免疫應答還可以涉及多種效應分子如細胞因子的產生或加工。
<具有誘導Th17細胞的增殖或累積的效果的組合物>
本文描述了誘導Th17細胞的增殖、累積或Th17細胞的增殖和累積二者的組合物。所述組合物包含作為活性成分的如下的一種或多種:(至少一種,一種或多種)選自下組的微生物(細菌):共生梭菌(SEQ ID No 16)、哈氏梭菌(SEQ ID No 12)、Clostridium citroniae(SEQ ID No 20)、鮑氏梭菌(SEQ ID No 19)、瘤胃球菌屬菌種M-1(SEQ ID No 14)、活潑瘤胃球菌(SEQ ID No 9)、布勞特氏菌屬菌種犬口類143(SEQ ID No 4)、糞厭氧棒狀菌(SEQ ID No 18)、乳酸發酵梭菌(SEQ ID No 3)、Coprobacillus cateniformis(SEQ ID No 15)、多枝梭菌(SEQ ID No 1)、參見梭菌屬菌種MLG055(SEQ ID No 5)、無害梭菌(SEQ ID No 6)、鏈狀真桿菌(SEQ ID No 11)、圓環梭菌(SEQ ID No 7)、瘤胃球菌屬菌種16442(SEQ ID No 8)、人腸道厭氧棒狀菌(SEQ ID No 10)、Bacteroides dorei(SEQ ID No 17)、假長雙歧桿菌假長亞種(SEQ ID No 2)、和短雙歧桿菌(SEQ ID No 13);所述細菌的一種或多種的培養物上清;本文所述的(至少一種,一種或多種)細菌所生長的培養基的組分;以及(至少一種;一種或多種)含有DNA的細菌,所述DNA包含與任何本文所述細菌菌種(例如上文列出的那些)的DNA的核苷酸序列具有至少97%的同源性的核苷酸序列。本文所述細菌用實施例1至3中概述的方法從人排泄物樣品分離。
所述細菌組合物或藥物組合物可以僅包括任何本文列出的或描述的細菌菌種的一個菌株(僅一種菌株);所述細菌的兩種或更多種菌株可以一起使用。例如表1中列出的菌株的1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、或20個可以任何組合一起用于影響Th17細胞。
如果使用了細菌的多于一種菌株,使用的菌株數量和比率可以有大量的變化。要使用的數量和比率可以基于多種因素來確定(例如所需的效果,如Th17細胞的增殖或累積的誘導或抑制;要治療、預防或降低其嚴重程度的疾病或病況;受試者的年齡或性別;健康人中菌株的通常數量)。菌株可以存在于單一組合物中,在這種情況下其可以一同(在單一組合物中)被消耗或消化;或可存在于多于一個組合物中(例如可以在分開的組合物中),在這種情況下其可以單獨被消耗或者可以將組合物進行組合從而使得組合(組合物的組合)被消耗的或消化。可以施用任意數目或組合的證明為有效的菌株(例如任意數目為1-20,如1-20、1-15、1-10、1-5、1-3、1-2以及其間的任意數目)。在本發明的一些實施方案中,使用了本發明所述的20個菌株(例如表1中的20個菌株)的部分或全部的組合。例如,可以使用20種所述菌株的至少1種、2種或更多種、3種、3種或更多種、4種、4種或更多種、5種、5種或更多種、6種、6種或更多種,或任何其他數目,包括20種。它們可以互相組合使用或與未記載于引述的文獻中的菌株組合使用。
當前述細菌組合物培養于培養基中時,細菌中含有的物質、細菌產生的分泌產物和代謝物從細菌釋放出來。組合物中的活性成分“細菌的培養物上清”的含義包括此類物質、分泌產物和代謝物。只要培養物上清具有誘導Th17細胞增殖或累積的效果,則所述培養物上清不作具體限制。培養物上清的實例包括培養物上清的蛋白質級分、培養物上清的多糖級分、培養物上清的脂質級分、和培養物上清的低分子量代謝物級分。
細菌組合物中的細菌菌株可以以活體形式施用,或其可以以減毒、滅活、或殺滅形式(例如熱殺滅的)施用。
細菌組合物可以以藥物組合物、飲食補充劑、或食品或飲料(也可以是動物飼料)的形式施用,或可以用作動物模型實驗的試劑。所述藥物組合物、飲食補充劑、食品或飲料、以及試劑誘導Th17細胞的增殖或累積。本文呈示的實例揭示了所述細菌組合物在施用于動物時誘導Th17細胞。本發明的組合物可以合適地用作具有促進免疫應答的效果的組合物。
例如,本發明的細菌組合物可以用作預防或治療傳染性疾病(降低其部分或全部的不良作用)的藥物組合物,所述傳染性疾病如細菌感染、病毒感染、寄生蟲感染、和真菌感染。新鑒定的組合物的口服施用及其隨后的胃腸道形成集落在粘膜表面誘導Th17細胞。這些Th17細胞在粘膜表面介導針對若干感染原(包括細菌、病毒、真菌和寄生蟲)的保護性免疫應答。
可使用所述組合物來治療(降低不良作用或預防)的目標感染性疾病更具體的實例包括細菌感染,其包括但不限于:銅綠假單胞菌(P.aeruginosa)、大腸桿菌(E.coli)、破傷風梭菌(C.tetani)、淋病奈瑟氏球菌(N.gonorrhoeae)、肉毒梭菌(C.botulinum)、克雷伯氏菌屬菌種(Klebsiella sp.)、沙雷氏菌屬菌種(Serratia sp.)、假單胞菌屬菌種(Pseudomanas sp.)、洋蔥假單胞菌(P.cepacia)、不動桿菌屬菌種(Acinetobacter sp.)、S.epidermis、糞腸球菌(E.faecalis)、S.pneumonias、金黃色葡萄球菌(S.aureus)、變形鏈球菌(S.mutans)、嗜血菌屬菌種(Haemophilus sp.)、奈瑟氏球菌屬菌種(Neisseria Sp.)、腦膜炎奈瑟氏球菌(N.meningitides)、擬桿菌屬菌種(Bacteroides sp.)、檸檬酸桿菌屬菌種(Citrobacter sp.)、布蘭漢氏球菌屬菌種(Branhamella sp.)、沙門氏菌屬菌種(Salmonelia sp.)、志賀氏菌屬菌種(Shigella sp.)、化膿性鏈球菌(S.pyogenes)、變形菌屬菌種(Proteus sp.)、梭菌屬菌種(Clostridium sp.)、丹毒絲菌屬菌種(Erysipelothrix sp.)、利斯特氏菌屬菌種(Listeria sp.)、多殺巴斯德氏菌(Pasteurella multocida)、鏈桿菌屬菌種(Streptobacillus sp.)、螺菌屬菌種(Spirillum sp.)、梭螺菌屬菌種(Fusospirocheta sp.)、蒼白密螺旋體(Treponema pallidum)、疏螺旋體屬菌種(Borrelia sp.)、放線菌屬(Actinomycetes)、支原體屬菌種(Mycoplasma sp.)、衣原體屬菌種(Chlamydia sp.)、立克次氏體屬菌種(Rickettsia sp.)、螺旋體屬菌種(Spirochaeta)、布氏疏螺旋體(Borellia burgdorferi)、軍團菌屬菌種(Legionella sp.)、分枝桿菌屬菌種(Mycobacteria sp)、尿枝原體屬菌種(Ureaplasma sp)、鏈霉菌屬菌種(Streptomyces sp.)、奇可莫拉菌屬菌種(Trichomoras sp.)、奇異變形桿菌(P.mirabilis)、霍亂弧菌(vibrio cholera)、產腸毒素大腸桿菌(enterotoxigenic Escherichia coli)、艱難梭菌(Clostridium difficile)、傷寒沙門氏菌(Salmonella typhi)、白喉棒桿菌(C.diphtheria)、麻風分枝桿菌(Mycobacterium leprae)、Mycobacterium lepromatosi;病毒感染包括但不限于小核糖核酸病毒科(picornaviridae)、杯狀病毒科(caliciviridae)、披膜病毒科(togaviridae)、黃病毒科(flaviviridae)、冠狀病毒科(coronaviridae)、彈狀病毒科(rhabdoviridae)、纖絲病毒科(filoviridae)、副粘病毒科(paramyxoviridae)、正粘病毒科(orthomyxoviridae)、本揚病毒科(bunyaviridae)、沙粒病毒科(arenaviridae)、呼腸孤病毒科(reoviridae)、逆轉錄病毒科(retroviridae)、肝脫氧核糖核酸病毒科(hepadnaviridae)、細小病毒科(parvoviridae)、乳多空病毒科(papovaviridae)、腺病毒科(adenoviridae)、皰疹病毒科(herpesviridae)、痘病毒科(poxviridae)、輪狀病毒(rotavirus)、副流感病毒(parainfluenza virus)、甲型和乙型流感病毒(influenza virus A and B)、梅毒(syphilis)、HIV、狂犬病病毒(rabies virus)、EB病毒(Epstein-Barr virus)、及單純皰疹病毒(herpes simplex virus);寄生蟲感染包括但不限于惡性瘧原蟲(Plasmodium falciparum)、間日瘧原蟲(P.vivax)、卵形瘧原蟲(P.ovale)、三日瘧原蟲(P.malaria)、鼠弓形蟲(Toxoplasma gondii)、墨西哥利什曼原蟲(Leishmania mexicana)、熱帶利什曼原蟲(L.tropica)、碩大利什曼原蟲(L.major)、埃塞俄比亞利什曼原蟲(L.aethiopica)、杜氏利什曼蟲(L.donovani)、克氏錐蟲(Trypanosoma cruzi)、布氏錐蟲(T.brucei)、曼氏血吸蟲(Schistosoma mansoni)、埃及血吸蟲(S.haematobium)、日本血吸蟲(S.japonium)、旋毛蟲(Trichinella spiralis)、班氏絲蟲(Wuchereria bancrofti)、馬來絲蟲(Brugia malayli)、溶組織內阿米巴(Entamoeba histolytica)、蟯蟲(Enterobius vermiculoarus)、豬肉絳蟲(Taenia solium)、牛帶絳蟲(T.saginata)、陰道毛滴蟲(Trichomonas vaginatis)、人毛滴蟲(T.hominis)、口腔毛滴蟲(T.tenax)、藍氏賈第鞭毛蟲(Giardia lamblia)、微小隱孢子蟲(Cryptosporidium parvum)、卡氏肺孢子蟲(Pneumocytis carinii)、牛巴貝蟲(Babesia bovis)、分歧巴貝蟲(B.divergens)、田鼠巴貝蟲(B.microti)、Isospore belli、L hominis、脆雙核阿米巴(Dientamoeba fragiles)、旋盤尾絲蟲(Onchocerca volvulus)、人蛔蟲(Ascaris lumbricoides)、美洲鉤蟲(Necator americanis)、十二指腸鉤口線蟲(Ancylostoma duodenale)、糞類圓線蟲(Strongyloides stercoralis)、菲律賓毛細線蟲(Capillaria philippinensis)、廣州管圓線蟲(Angiostrongylus cantonensis)、微小膜殼絳蟲(Hymenolepis nana)、闊節裂頭絳蟲(Diphyllobothrium latum)、細粒棘球絳蟲(Echinococcus granulosus)、多房棘球絳蟲(E.multilocularis)、衛氏并殖吸蟲(Paragonimus westermani)、P.caliensis、中華枝睪吸蟲(Chlonorchis sinensis)、貓后睪吸蟲(Opisthorchis felineas)、G.Viverini、肝片吸蟲(Fasciola hepatica)、疥螨(Sarcoptes scabiei)、人虱(Pediculus humanus)、陰虱(Phthirius pubis)、及人膚蠅(Dermatobia hominis);且真菌感染包括但不限于新型隱球菌(Cryptococcus neoformans)、皮炎芽生菌(Blastomyces dermatitidis)、皮炎阿耶洛霉(Aiellomyces dermatitidis)、莢膜組織孢漿菌(Histoplasfria capsulatum)、粗球袍子菌(Coccidioides immitis)、念珠菌屬菌種(Candida species),包括白色念珠菌(C.albicans)、熱帶假絲酵母(C.tropicalis)、近平滑假絲酵母(C.parapsilosis)、季也蒙假絲酵母(C.guilliermondii)和克魯斯假絲酵母(C.krusei)、曲霉屬菌株(Aspergillus species),包括煙曲霉(A.fumigatus)、黃曲霉(A.flavus)和黑曲霉(A.niger),根霉屬菌種(Rhizopus species),根毛霉屬菌種(Rhizomucor species)、小克銀漢霉屬菌種(Cunninghammella species)、節壺霉屬菌種(Apophysomyces species),包括A.saksenaea、A.mucor和A.absidia、申克孢子絲菌(Sporothrix schenckii)、巴西副球孢子菌(Paracoccidioides brasiliensis)、假阿利什霉菌(Pseudallescheria boydii)、光滑球擬酵母(Torulopsis glabrata),以及皮癬菌屬菌種(Dermatophyres species)。
細菌組合物可以作為佐劑與抗原材料組合施用。所述抗原材料可以包含病原體的蛋白外殼、蛋白核心、或功能性蛋白和肽的一個或多個部分,或完整病原體(活的、殺滅的、滅活的、或減毒的),或可包含一個或多個癌表位或癌抗原。抗原材料可在細菌組合物之前或之后施用,或是共同施用。細菌組合物還可以與現有的粘膜疫苗一起施用,所述粘膜疫苗如流感疫苗(例如來自MedImmune的FluMist或來自的印度血清研究所(Serum Institute of India)的NASOVAC)、輪狀病毒疫苗(例如來自Merck的RotaTeq或來自GlaxoSmithKline的Rotarix)、傷寒疫苗(例如來自Crucell的Vivotif,Ty21A)、霍亂疫苗(例如來自Crucell的Orochol,來自Shantha Biotechnics的Shanchol)、旅行者腹瀉疫苗(例如來自Crucell的Dukoral),以及與如下的抗原一起施用:活減毒甲型流感病毒H1株,活減毒甲型流感病毒H3株,乙型流感病毒,活減毒H1N1流感病毒(豬流感),活減毒輪狀病毒,單價和多價脊髓灰質炎病毒,減毒活傷寒沙門氏菌,缺乏霍亂毒素亞基A的活重組霍亂弧菌,具有或不具有霍亂毒素亞基B的完全殺滅的霍亂弧菌O1經典和El Tor生物型,癌抗原,癌表位,及其組合。
使用本領域技術人員熟知的遺傳工程方法,可以將細菌組合物工程化以表達來自所選病原體或癌抗原的特異性抗原,并用作例如用于延長暴露于所述抗原并誘導比口服單獨施用可溶性抗原更強的粘膜免疫應答的藥物組合物。在一個實施方案中,來自表1的生物體可以通過摻入表達異種抗原的表達載體來工程化。所述異種抗原可以包括但不限于流感HA,NA,M2,HIVgp120,結核分枝桿菌(mycobacterium tuberculosis)Ag85B和ESAT6,肺炎鏈球菌(Streptococcus pneumonia)PspA,PsaA和CbpA,呼吸道合胞體病毒(RSV)F和G蛋白,人乳頭狀瘤病毒蛋白,和癌抗原。此外,還可以將Th-17誘導菌株工程化以使其在宿主中具有有限的復制能力,同時在免疫位點遞送足夠高的抗原負載,從而避免該菌株的長期集落形成。
可以抑制本文所述的細菌組合物及其他Th17誘導菌株以用于預防或治療(降低其部分或全部的不良作用)自身免疫性疾病和炎癥疾病。Th17細胞還可能具有在宿主中促進慢性自身免疫和炎癥反應的有害作用。因此,通過施用損害其生長和/或功能的分子、或直接殺死Th17誘導菌株來抑制Th17誘導菌株的方法可用于治療由Th17應答介導的自身免疫性疾病和炎癥疾病。包括但不限于萬古霉素和甲硝唑的抗生素可用于抑制Th17誘導菌株。可通過抑制Th17誘導菌株來治療的目標疾病包括:炎性腸病(IBD),潰瘍性結腸炎,克羅恩氏病(Crohn's disease),口炎性腹瀉,自身免疫性關節炎,類風濕性關節炎,I型糖尿病,多發性硬化,骨關節炎,系統性紅斑狼瘡,胰島素依賴性糖尿病,哮喘,牛皮癬,特應性皮炎,移植物抗宿主病,與器官移植相關的急性或慢性免疫疾病,結節病(sarcoidosis),動脈粥樣硬化,特應性變態反應(atopic allergy),食物過敏如花生過敏,樹堅果過敏,雞蛋過敏,牛奶過敏,大豆過敏,小麥過敏,海產過敏,貝類過敏或芝麻過敏,過敏性鼻炎(花粉變態反應),過敏反應,寵物過敏,乳膠過敏,藥物過敏,過敏性鼻結膜炎(rhinoconjuctivitis),嗜酸性粒細胞性食管炎(eosinophilic esophagitis)和腹瀉,及其他。
藥物制劑可以由本領域技術人員已知的藥物配制方法描述的細菌組合物來配制。例如,組合物可以以膠囊,片劑,藥丸,小囊,液體,粉末,顆粒,細顆粒,薄膜包衣制劑,丸劑,錠劑,舌下制劑,咀嚼劑,頰含制劑,糊劑,糖漿劑,懸浮劑,酏劑和乳劑來口服使用,或者其可以以栓劑或灌腸劑使用。
用于粘膜疫苗接種的藥物制劑可以配制成口服形式,例如水性或油性溶劑中的溶液,懸浮液或乳液,或干燥為粉末。此外,根據目的,可以向粘膜疫苗制劑添加緩沖劑,等張劑,舒緩劑,防腐劑或抗氧化劑。
為了配制這些制備物,細菌組合物可以與藥理學上可接受的或對于攝取而言可接受的載劑適當地組合使用,例如在食品或飲料中,包括如下一種或多種:無菌水,生理鹽水,植物油,溶劑,堿性材料,乳化劑,懸浮劑,表面活性劑,穩定劑,調味劑,芳香劑,賦形劑,載劑,防腐劑,粘合劑,稀釋劑,張力調節劑,舒緩劑,填充劑,崩解劑,緩沖劑,包衣劑,潤滑劑,著色劑,甜味劑,增稠劑,矯味劑,增溶劑,以及其他添加劑。
藥物制備物或制劑,特別是用于口服施用的藥物制備物可以包含能夠有效地將本發明的細菌組合物遞送至結腸的額外組分,以便更有效地誘導結腸中Th17的增殖或累積。可以使用能夠將細菌組合物遞送至結腸的多種藥物制備物。其實例包括pH敏感組合物,更具體地是緩沖的小囊制劑或腸溶聚合物,當所述腸溶聚合物通過胃后在pH變為堿性時釋放其內容物。當pH敏感性組合物用于配制藥物制備物時,pH敏感性組合物優選為其分解pH閾值為約6.8至約7.5的聚合物。該數值范圍是在胃的末端部pH向堿性側移動的范圍,因此是適于用于向結腸遞送的范圍。
用于將細菌組合物遞送至結腸的藥物制備物的另一個實施方案是通過延遲內容物(例如細菌組合物)的釋放約3至5小時(其對應于小腸運輸時間)來確保遞送至結腸。在用于延遲釋放的藥物制備物的一個實施方案中,使用水凝膠作為殼。水凝膠在與胃腸液接觸時水合并膨脹,導致內容物有效地釋放(主要在結腸中釋放)。延遲釋放劑量單位包括含藥組合物,其具有包衣涂覆或選擇性包衣涂覆待施用的藥物或活性成分的材料。這種選擇性包衣材料的實例包括體內可降解聚合物,可逐漸水解的聚合物,逐漸水溶性聚合物和/或酶可降解的聚合物。用于有效地延遲釋放的多種包衣材料是可用的,并且其包括例如基于纖維素的聚合物如羥丙基纖維素,丙烯酸聚合物和共聚物例如甲基丙烯酸聚合物和共聚物,以及乙烯基聚合物和共聚物例如聚乙烯吡咯烷酮。
能夠遞送至結腸的組合物的實例還包括特異性粘附至結腸粘膜的生物粘附組合物(例如美國專利6.368.586的說明書中描述的聚合物)和其中摻入蛋白酶抑制劑的組合物,用于保護尤其是胃腸道中的生物藥物制備物免受蛋白酶的活性所分解。
細菌組合物可以用作食品或飲料,例如保健食品或飲料,旅行者,嬰兒,孕婦,運動員,老年人或其他特定群體的食品或飲料,功能性食品,用于特定保健用途的食品或飲料,膳食補充劑,用于患者的食品或飲料,或動物飼料。
將細菌組合物添加至無抗生素的動物飼料,使得能夠將攝取動物飼料的動物的體重增加至等于或高于通過攝入含抗生素的動物飼料所達到的水平,還使得可以將胃腸道中的病原細菌減少至與消耗典型的含抗生素的動物飼料的動物中的那些相等的水平。細菌組合物可以用作不需要添加抗生素的動物飼料的組分。可以用包含細菌組合物的動物飼料飼喂各種不同類型的動物和不同年齡的動物,并且可以定期飼喂或飼喂一段具體的時間(例如在出生時、在斷奶期間、或當動物被遷移或運輸時)。
細菌組合物的細菌活性成分可以使用發酵技術來制備。在一個實施方案中,細菌活性成分使用厭氧發酵罐來制備,其可以支持細菌菌株的快速生長。厭氧發酵罐可以是例如攪拌釜反應器或一次性波生物反應器(disposable wave bioreactor)。培養基例如BL瓊脂,或這些培養基的沒有動物組分的類似形式,可用于支持細菌菌種的生長。細菌產物可以通過諸如離心和過濾的技術從發酵液中純化和濃縮,并且可以任選地干燥和凍干。
要施用或攝取的細菌組合物的量可以根據經驗確定,考慮到諸如要接受其的個體的年齡,體重,性別,癥狀,健康狀況等因素,以及要施用或攝取的細菌組合物(藥物產品,食品或飲料)的種類。例如,每次施用或攝取的量通常為0.01mg/kg體重至100mg/kg體重,并且在具體實施方案中為1mg/kg體重至10mg/kg體重。本文還描述了用于促進受試者的免疫(賦予(或增強)免疫應答)的方法,所述方法的特征在于如上所述對受試者施用或使其攝取所述細菌組合物。
細菌組合物可以施用于個體一次,或者其可以施用多于一次。如果組合物被施用多于一次,其可以定期施用(例如,每天一次,每兩天一次,每周一次,每兩周一次,每月一次,每6個月一次或每年一次)或根據需要施用或不定期施用。可根據經驗確定適當的施用頻率(其可取決于宿主遺傳特征,年齡,性別,受試者的健康或疾病狀態,以及其他因素)。例如,可以給患者施用一劑的組合物,并可以在不同的時間測量從患者獲得的排泄物樣品中組合物的細菌菌株的水平(例如1天后,2天后,1周后,2周后,1個月后)。當細菌水平降至例如其最大給藥后值的一半時,可以施用第二劑,等等。
包含細菌組合物或其手冊的產品(藥物產品,食品或飲料,或試劑)可以伴有解釋該產品可用于促進免疫的文件或說明(包括陳述該產品具有促進免疫的效果的說明和陳述該產物具有促進Th17細胞的增殖或功能的效果的說明)。在此,“對具有注釋的產品或其手冊的提供”是指將文件或說明提供于產品的主體,容器,包裝等,或者提供注釋于手冊,包裝插頁,小冊傳單或其他印刷品,其公開了關于產品的信息。
<誘導Th17細胞的增殖或累積的方法>
如上文所述,以及如實施例1-3所示,對個體施用細菌組合物使得可以誘導個體中Th17細胞的增殖或累積。這提供了誘導個體中Th17細胞增殖或累積的方法,該方法包括:對個體施用選自下組的至少一項,下組包括:(a)共生梭菌,哈氏梭菌,Clostridium citroniae,鮑氏梭菌,瘤胃球菌屬菌種M-1,活潑瘤胃球菌,布勞特氏菌屬菌種犬口類143,糞厭氧棒狀菌,乳酸發酵梭菌,Coprobacillus cateniformis,多枝梭菌,參見梭菌屬菌種MLG055,無害梭菌,鏈狀真桿菌,圓環梭菌,瘤胃球菌屬菌種16442,人腸道厭氧棒狀菌,Bacteroides dorei,假長雙歧桿菌假長亞種,和短雙歧桿菌;(b)至少一種(一種或多種)本文所述/所列的細菌的培養物上清;或(a)和(b)的組合。細菌組合物以足以產生誘導所需Th17細胞的增殖、累積或增殖和累積二者的量施用(提供于)個體。其可以施用于需要治療傳染性疾病或降低其嚴重程度的個體。其還可以作為粘膜疫苗制劑的佐劑施用于需要預防傳染性疾病的個體。
需注意,“個體”或“受試者”(例如人)可以是健康狀態或患病狀態。該方法可以進一步包括任選的在細菌組合物之前或與其組合施用至少一種(一種或多種)抗生素的步驟。
此外,可使用益生元組合物來相對于其他人共生細菌物種生長促進細菌組合物中的菌種的生長。在一個實施方案中,所述益生元物質(一種或多種)是不可消化的寡糖。在個體中誘導Th17的增殖和/或累積的方法可以包括對所述個體施用至少一種益生元或至少一種抗生素與細菌組合物的組合。本文還涵蓋包含細菌組合物和益生元組合物或抗生素組合物的組合物。
對于治療組合物與選自細菌組合物,“粘膜疫苗制劑”,“粘膜疫苗抗原”,“抗生素”,和“益生元組合物”中的至少一種物質的組合使用沒有特別限制。例如,“一種物質”和治療組合物在任何適當的時間同時或序貫地/分別地口服或腸胃外施用于個體。
可以通過使用如下至少一項的增加或增強作為指數來確定細菌組合物的施用是否誘導Th17細胞的增殖和/或累積:Th17細胞的數量,胃腸道T細胞群體中Th17細胞的比率,Th17細胞的功能,或Th17細胞的標志物的表達。具體方法是測量患者樣品(如活檢或血液樣品)中表達RORgt的Th17細胞的測量計數或百分比,IL-17表達的促進(增強),或利用施用的細菌組合物個體的集落形成,作為Th17細胞增殖或累積的誘導指數。檢測這種表達的方法包括用于檢測轉錄水平的基因表達的northern印跡,RT-PCR和斑點印跡;用于檢測翻譯水平的基因表達的ELISA,放射免疫測定,免疫印跡,免疫沉淀和流式細胞術。可用于測量這種指數的樣品包括獲取自個體的組織和液體(例如血液),獲取于活檢中的組織和液體,以及排泄物樣品。
<用于監測受試者對細菌組合物的應答的方法>
還提供了監測受試者(例如人)對使用本文所述的細菌組合物的治療的應答的方法,其包括(a)獲得(一個或多個,至少一個)樣品,如來自用本文所述細菌組合物處理前的患者的排泄物樣品或結腸活檢;(b)獲得(一個或多個,至少一個)來自用本文所述細菌組合物處理后的患者的對應樣品;和(c)將(a)中獲得的樣品中的至少一個選自共生梭菌,哈氏梭菌,Clostridium citroniae,鮑氏梭菌,瘤胃球菌屬菌種M-1,活潑瘤胃球菌,布勞特氏菌屬菌種犬口類143,糞厭氧棒狀菌,乳酸發酵梭菌,Coprobacillus cateniformis,多枝梭菌,參見梭菌屬菌種MLG055,無害梭菌,鏈狀真桿菌,圓環梭菌,瘤胃球菌屬菌種16442,人腸道厭氧棒狀菌,Bacteroides dorei,假長雙歧桿菌假長亞種,和短雙歧桿菌的細菌的百分比或絕對計數與(b)中獲得的樣品中的相同的至少一個細菌菌種的百分比或絕對計數進行比較,其中(b)中(用細菌組合物處理后)獲得的樣品比(a)中(處理前)獲得的樣品的值更高,指示受試者已良好地應答于治療(例如是受試者中增強的免疫應答的陽性指示物)。在一些實施方案中,該方法還包括(d)基于(c)中的比較而進一步對患者施用細菌組合物或停止施用細菌組合物。在本文所述的監測方法中,多種已知方法可用于確定細菌菌種的百分比或絕對計數。例如可以使用16S rRNA測序。
<獲得誘導Th17的細菌組合物的方法>
對排泄物樣品應用的一些修飾可以導致獲得誘導Th17的細菌組合物。令人驚訝的是,向動物施用氨芐青霉素豐富了Th17誘導菌株在樣品中的表征。通過在嚴格厭氧條件下在實施例2中描述的某些培養基中鋪板來從氨芐青霉素處理的動物中培養系列稀釋的樣品,導致獲得有效的誘導Th17的細菌組合物。因此,提供了獲得誘導Th17的細菌組合物的方法,其包括(a)用抗生素氨芐青霉素或具有類似譜的抗生素例如氨基青霉素家族成員例如阿莫西林,青霉素或芐基青霉素來處理受試者;(b)獲得(一個或多個,至少一個)來自受試者的樣品,例如排泄物樣品或腸活檢;(c)培養來自(b)的樣品并從所得菌落分離純細菌菌株。在優選實施方案中,(a)中的受試者是先前的無菌動物,其首先用獲取自人供體的排泄物樣品來形成集落,然后用氨芐青霉素處理,之后從動物獲得盲腸樣品并如實施例2所述培養。在一個實施方案中,(c)純細菌菌株的分離是通過盲腸內容物樣品的系列稀釋并在嚴格厭氧條件下鋪板培養而進行的。在另一個實施方案中,該方法包括(a)獲得(至少一個)來自受試者的樣品,如排泄物樣品或腸活檢;(b)用氨芐青霉素處理(a)的樣品;(c)培養(b)的經氨芐青霉素處理的樣品并分離純細菌菌株。
<使用誘導Th17的細菌組合物來重新建立接受抗生素處理個體的微生物群的方法>
細菌組合物可以施用于還接受抗生素處理的個體。發明人已經證明,諸如萬古霉素或甲硝唑的抗生素可以有效地消除或大大減少來自哺乳動物胃腸道的Th17誘導細菌菌種,并隨后降低Th17細胞的水平(實施例1)。不希望受理論束縛,Th17誘導細菌促進免疫應答的關鍵作用強烈地表明它們的存在或高水平可以在自身免疫性疾病中發揮關鍵作用。因此,經歷諸如萬古霉素或甲硝唑的抗生素療程的個體處于喪失Th17誘導細菌的高風險中并因此經歷免疫缺陷,其可以通過使用細菌組合物預防性地“再重新建立(repopulated)”。細菌組合物可以在抗生素治療之前,與之同時或之后施用,但優選為與抗生素治療同時施用或在抗生素治療后施用。
下文為描述具體方面的實施例。它們不意在以任何方式進行限制。
實施例
實施例1
將來自處于臨床活性狀態的潰瘍性結腸炎(UC)日本患者的人排泄物(2g)用8ml含有20%甘油的磷酸鹽緩沖鹽水(PBS)重懸,于液氮中速凍,并儲存于-80℃直至使用。將凍存的儲液解凍,并將其口服接種至IQI無菌(GF)小鼠(250μl/小鼠)。對小鼠在其飲用水中給予氨芐青霉素(ABPC;1g/L)、萬古霉素(VCM;500mg/L)、多粘菌素B(PL-B;200mg/L)、甲硝唑(MNZ;1g/L)、或僅水(未處理的:NT),從用UC患者排泄物接種后1天開始直至分析日。將每組的ex-GF小鼠(每組n=5)分離地養在乙烯基隔離室中4周。
收集結腸并縱向打開,用PBS洗滌以除去所有腔內容物,并于37℃在含有5mM EDTA的Hanks平衡鹽溶液(HBSS)中振蕩20分鐘。在用鑷子除去上皮細胞、肌肉層和脂肪組織后,將固有層切成小片并與含有4%胎牛血清(FBS)、0.5mg/mL膠原酶D、0.5mg/mL分散酶和40mg/mL DNA酶I(均為RocheDiagnostics)的RPMI1640在37℃于振蕩水浴中溫育1小時。用含有5mM EDTA的HBSS洗滌消化的組織,將其重懸于5mL的40%Percoll(GE Healthcare)中并覆蓋在15-ml Falcon管中的2.5ml的80%Percoll上。通過在25℃以800g離心20分鐘進行Percoll梯度分離。從Percoll梯度的界面收集固有層淋巴細胞并懸浮于含有10%FBS的RPMI1640中。為了進行Th1和Th17細胞的分析,在GolgiStop(BD Biosciences)存在下,用50ng/mL佛波醇12-豆蔻酸酯13-乙酸酯(PMA,Sigma)和750ng/mL離子霉素(Sigma)刺激分離的淋巴細胞4小時。溫育4小時后,在PBS中洗滌細胞,用LIVE/DEAD可固定死細胞染色試劑盒(Invitrogen)進行標記,并且用PECy7標記的抗CD4Ab(RM4-5,BD Biosciences)和BV605標記的抗CD3Ab(17A2,BioLegend)將表面CD4和CD3染色。洗滌細胞,固定并用Foxp3染色緩沖液套組(eBioscience)透明化,并用APC標記的抗IL-17Ab(eBio17B7,eBioscience)和BV421標記的抗IFN-g Ab(XMG1.2,BioLegend)染色。用LSR Fortessa(BD Biosciences)分析Ab染色的細胞,并用FlowJo軟件(Treestar)分析數據。
在口服接種UC患者排泄物的小鼠中,觀察到Th17細胞的顯著誘導。令人驚奇的是,與僅給予水的小鼠(未處理的:NT)相比,在飲用水中給予氨芐青霉素(ABPC)的小鼠中Th17誘導增強。相比之下,通過用萬古霉素(VCM)或甲硝唑(MNZ)處理,Th17誘導顯著受損。另一方面,用多粘菌素B(PL-B)處理不影響Th17細胞數量(圖1)。
因此,人的排泄物中存在Th17誘導細菌,并且細菌菌種對氨芐青霉素和多粘菌素B有抗性,但對萬古霉素和甲硝唑敏感。
實施例2
將來自實施例1中所述的每個exGF小鼠的盲腸內容物懸浮于10mL的含有10mM Tris-HCl和1mM EDTA的Tris-EDTA(pH 8)中,并在37℃與溶菌酶(SIGMA,15mg/mL)溫和混合1小時。加入純化的無色肽酶(Wako)(終濃度為2000單位/mL),并在37℃再溫育30分鐘。然后向細胞懸浮液中加入十二烷基硫酸鈉(終濃度1%)并充分混合。隨后向懸浮液加入蛋白酶K(Merck)(終濃度1mg/mL)并將混合物在55℃溫育1小時。經苯酚/氯仿提取、乙醇,和最后的聚乙二醇沉淀,分離和純化高分子量的DNA。用Ex Taq(TAKARA)和針對16SrRNA基因的V1-V2區的(i)修飾的引物8F[5’-CCATCTCATCCCTGCGTGTCTCCGACTCAG(454轉接子序列,SEQ ID NO.:21)+Barcode(10個堿基)+AGRGTTTGATYMTGGCTCAG(SEQ ID NO.:22)-3’]和(ii)修飾的引物338R[5’-CCTATCCCCTGTGTGCCTTGGCAGTCTCAG(454轉接子序列,SEQ ID NO.:23)+TGCTGCCTCCCGTAGGAGT(SEQ ID NO.:24)-3’]進行了PCR。隨后將產生自每個樣品的擴增子(~330bp)用AMPure XP(BECKMAN COULTER)進行純化。用Quant-iT Picogreen dsDNA測定試劑盒(Invitrogen)和TBS-380微型熒光計(Turner Biosystems)對DNA的量進行定量。然后,用擴增的DNA作為模板用于IonPGM測序儀。基于序列相似性(≥96%同一性)將所得的序列(每個樣品產生了3000個讀段)分類成OTU。用BLAST將來自每個OTU的代表性序列與核酸數據庫(Ribosomal Database Project)或GenomeDB(NCBI+HMP+Hattori Lab數據庫)中的序列進行比較,以確定最接近的株。
與Th17細胞數目負相關的OTU以藍色或灰色示于圖2中,而與Th17細胞數目正相關的OTU以紅色標記。
來自利用UF患者的排泄物形成集落且給予了氨芐青霉素的小鼠的盲腸內容物的系列稀釋物通過在嚴格厭氧條件(80%N2 10%H2 10%CO2)下鋪板培養于用5%去纖維蛋白的馬血(Nippon Bio-Supp.Center)補充的BL瓊脂(Eiken Chemical)、用5%去纖維蛋白的馬血補充的GAM瓊脂(Nissui)、用5%去纖維蛋白的馬血補充的胰蛋白(Tryptic)大豆瓊脂(Becton Dickinson)、用5%去纖維蛋白的馬血補充的加強梭菌瓊脂(Oxoid)、Schaedler瓊脂(BectonDickinson)或腦心浸液瓊脂(Becton Dickinson)上。在37℃培養2天后,挑取每個單菌落(總共250個菌落),并在-80℃貯存于含有10%甘油的Schaedler培養液(Becton Dickinson)中。為了鑒定分離的菌株,通過菌落PCR用g KOD FX(TOYOBO)和16S rRNA基因特異性引物對:8F(5’-AGAGTTTGATCMTGGCTCAG-3’)(SEQ ID NO.:25)和1492R(5’-GGYTACCTTGTTACGACTT-3’)(SEQ ID NO.:26)來擴增16S rRNA基因。擴增程序包括:一個循環,98℃2分鐘,然后35個循環,98℃10秒,57℃30秒和68℃90秒。使用AMPure XP從反應混合物純化每個擴增的DNA。使用BigDye Terminator V3.1循環測序試劑盒(Applied Biosystems)和Applied Biosystems 3730xl DNA分析儀(Applied Biosystems)進行序列分析。將所得序列與RDP數據庫中的序列進行比較以確定最接近的親緣關系。對這些挑取的菌落的16S rRNA基因序列的BLAST檢索揭示,我們成功地分離了20個菌株(表1)。
實施例3
為了研究分離的20個菌株(表1)是否具有誘導Th17細胞的能力,將全部20個菌株培養和混合以制成混合物,并將所述混合物口服接種至GF小鼠中。用Schaedler或PYG培養液在厭氧室(Coy Laboratory Products)內在嚴格厭氧條件下(80%N2,10%H2,10%CO2)于37℃分別地培養分離的20個菌株,然后以等量的培養基體積混合以制備細菌混合物。將等份試樣的細菌混合物口服接種至小鼠中(0.5ml/小鼠)。4周后,收集結腸和小腸并分析Th17和Th1細胞。指示的小鼠的結腸固有層和小腸固有層中的CD4+T細胞群體內IL-17+細胞和IFN-g+的百分比示于圖3中。在(接種)利用20個菌株形成集落(建群)的小鼠中,觀察到了對Th17細胞的強誘導。
SEQ ID No.:2H6、1B11、1D10、2E3、1C12、2G4、2H11、1E11、2D9、2F7、1D1、1F8、1C2、1D4、1E3、1A9、2G11、2E1、1F7、1D2,分別是SEQ ID No.1-20。
工業應用性
如上文所見,本文所述的組合物與方法使得可以通過利用某些來源于人的細菌或來源于所述細菌的上清液等等來提供優良的且充分表征的用于誘導Th17增殖或累積的組合物。由于細菌組合物具有促進免疫應答的效果,所述細菌組合物可作為粘膜疫苗的組分用于例如治療感染,以及預防感染。此外,健康個體能容易地且常規地攝取所述細菌組合物,如在食品或飲料(例如保健食品)中攝取,以提高其免疫功能。
本申請是基于美國臨時專利申請61/978,182(申請日2014年4月10日),其內容以其全文并入本文。
表1
表2
>2H6(SEQ ID NO.:1)
GGGGCGGCTGCTATAATGCAGTCGACGCGAGCACTTGTGCTCGAGTGGCGAACGGGTGAGTAATACATAAGTAACCTGCCCTAGACAGGGGGATAACTATTGGAAACGATAGCTAAGACCGCATATGTACGGACACTGCATGGTGACCGTATTAAAAGTGCCTCAAAGCACTGGTAGAGGATGGACTTATGGCGCATTAGCTGGTTGGCGGGGTAACGGCCCACCAAGGCGACGATGCGTAGCCGACCTGAGAGGGTGACCGGCCACACTGGGACTGAGACACGGCCCAGACTCCTACGGGAGGCAGCAGTAGGGAATTTTCGGCAATGGGGGAAACCCTGACCGAGCAACGCCGCGTGAAGGAAGAAGGTTTTCGGATTGTAAACTTCTGTTATAAAGGAAGAACGGCGGCTACAGGAAATGGTAGCCGAGTGACGGTACTTTATTAGAAAGCCACGGCTAACTACGTGCCAGCAGCCGCGGTAATACGTAGGTGGCAAGCGTTATCCGGAATTATTGGGCGTAAAGAGGGAGCAGGCGGCAGCAAGGGTCTGTGGTGAAAGCCTGAAGCTTAACTTCAGTAAGCCATAGAAACCAGGCAGCTAGAGTGCAGGAGAGGATCGTGGAATTCCATGTGTAGCGGTGAAATGCGTAGATATATGGAGGAACACCAGTGGCGAAGGCGACGATCTGGCCTGCAACTGACGCTCAGTCCCGAAAGCGTGGGGAGCAAATAGGATTAGATACCCTAGTAGTCCACGCCGTAAACGATGAGTACTAAGTGTTGGATGTCAAAGTTCAGTGCTGCAGTTAACGCAATAAGTACTCCGCCTGAGTAGTACGTTCGCAAGAATGAAACTCAAAGGAATTGACGGGGGCCCGCACAAGCGGTGGAGCATGTGGTTTAATTCGAAGCAACGCGAAGAACCTTACCAGGTCTTGACATACTCATAAAGGCTCCAGAGATGGAGAGATAGCTATATGAGATACAGGTGGTGCATGGTTGTCGTCAGCTCGTGTCGTGAGATGTTGGGTTAAGTCCCGCAACGAGCGCAACCCTTATCGTTAGTTACCATCATTAAGTTGGGGACTCTAGCGAGACTGCCAGTGACAAGCTGGAGGAAGGCGGGGATGACGTCAAATCATCATGCCCCTTATGACCTGGGCTACACACGTGCTACAATGGATGGTGCAGAGGGAAGCGAAGCCGCGAGGTGAAGCAAAACCCATAAAACCATTCTCAGTTCGGATTGTAGTCTGCAACTCGACTACATGAAGTTGGAATCGCTAGTAATCGCGAATCAGCATGTCGCGGTGAATACGTTCTCGGGCCTTGTACACACCGCCCGTCACACCACGAGAGTTGATAACACCCGAAGCCGGTGGCCTAACCGCAAGGAAGGAGCTTCTAAGGTGGAT
表3
>1B11(SEQ ID NO.:2)
CTGCGGCGTCTACCATGCAGTCGAACGGGATCCCTGGCAGCTTGCTGCCGGGGTGAGAGTGGCGAACGGGTGAGTAATGCGTGACCGACCTGCCCCATGCACCGGAATAGCTCCTGGAAACGGGTGGTAATGCCGGATGTTCCACATGAGCGCATGCGAGTGTGGGAAAGGCTTTTTGCGGCATGGGATGGGGTCGCGTCCTATCAGCTTGTTGGTGGGGTAACGGCCTACCAAGGCGTTGACGGGTAGCCGGCCTGAGAGGGCGACCGGCCACATTGGGACTGAGATACGGCCCAGACTCCTACGGGAGGCAGCAGTGGGGAATATTGCACAATGGGCGCAAGCCTGATGCAGCGACGCCGCGTGCGGGATGGAGGCCTTCGGGTTGTAAACCGCTTTTGTTCAAGGGCAAGGCACGGTCTTTGGCCGTGTTGAGTGGATTGTTCGAATAAGCACCGGCTAACTACGTGCCAGCAGCCGCGGTAATACGTAGGGTGCAAGCGTTATCCGGATTTATTGGGCGTAAAGGGCTCGTAGGCGGTTCGTCGCGTCCGGTGTGAAAGTCCATCGCTTAACGGTGGATCCGCGCCGGGTACGGGCGGGCTTGAGTGCGGTAGGGGAGACTGGAATTCCCGGTGTAACGGTGGAATGTGTAGATATCGGGAAGAACACCAATGGCGAAGGCAGGTCTCTGGGCCGTTACTGACGCTGAGGAGCGAAAGCGTGGGGAGCGAACAGGATTAGATACCCTGGTAGTCCACGCCGTAAACGGTGGATGCTGGATGTGGGGCCCTTTTTCCGGGTCCTGTGTCGGAGCTAACGCGTTAAGCATCCCGCCTGGGGAGTACGGCCGCAAGGCTAAAACTCAAAGAAATTGACGGGGGCCCGCACAAGCGGCGGAGCATGCGGATTAATTCGATGCAACGCGAAGAACCTTACCTGGGCTTGACATGTGCCGGACGCCCGCGGAGACGCGGGTTCCCTTCGGGGCCGGTTCACAGGTGGTGCATGGTCGTCGTCAGCTCGTGTCGTGAGATGTTGGGTTAAGTCCCGCAACGAGCGCAACCCTCGCCGCGTGTTGCCAGCGGGTCATGCCGGGAACTCACGTGGGACCGCCGGGGTTAACTCGGAGGAAGGTGGGGATGACGTCAGATCATCATGCCCCTTACGTCCAGGGCTTCACGCATGCTACAATGGCCGGTACAACGGGGTGCGACACGGTGACGTGGGGCGGATCCCTGAAAACCGGTCTCAGTTCGGATCGCAGTCTGCAACTCGACTGCGTGAAGGTGGAGTCGCTAGTAATCGCGGATCAGCAACGCCGCGGTGAATGCGTTCCCGGGCCTTGTACACACCGCCCGTCAAGTCATGAAAGTGGGCAGCACCCGAAGACGGTGGCCTAACCCTTGTGGGGGGAGCCGTCTAAGGTAGTG
表4
>1D10(SEQ ID NO.:3)
CTGCCGGCTCTACCATGCAGTCGAACGAAGATAGTTAGAATGAGAGCTTCGGCAGGATTTTTTTCTATCTTAGTGGCGGACGGGTGAGTAACGTGTGGGCAACCTGCCCTGTACTGGGGAATAATCATTGGAAACGATGACTAATACCGCATGTGGTCCTCGGAAGGCATCTTCTGAGGAAGAAAGGATTTATTCGGTACAGGATGGGCCCGCATCTGATTAGCTAGTTGGTGAGATAACAGCCCACCAAGGCGACGATCAGTAGCCGACCTGAGAGGGTGATCGGCCACATTGGGACTGAGACACGGCCCAAACTCCTACGGGAGGCAGCAGTGGGGAATATTGCACAATGGGCGAAAGCCTGATGCAGCAACGCCGCGTGAAGGATGAAGGGTTTCGGCTCGTAAACTTCTATCAATAGGGAAGAAACAAATGACGGTACCTAAATAAGAAGCCCCGGCTAACTACGTGCCAGCAGCCGCGGTAATACGTAGGGGGCAAGCGTTATCCGGAATTACTGGGTGTAAAGGGAGCGTAGGCGGCATGGTAAGCCAGATGTGAAAGCCTTGGGCTTAACCCGAGGATTGCATTTGGAACTATCAAGCTAGAGTACAGGAGAGGAAAGCGGAATTCCTAGTGTAGCGGTGAAATGCGTAGATATTAGGAAGAACACCAGTGGCGAAGGCGGCTTTCTGGACTGAAACTGACGCTGAGGCTCGAAAGCGTGGGGAGCAAACAGGATTAGATACCCTGGTAGTCCACGCCGTAAACGATGAGTGCTAGGTGTCGGGGAGGAATCCTCGGTGCCGCAGCTAACGCAATAAGCACTCCACCTGGGGAGTACGACCGCAAGGTTGAAACTCAAAGGAATTGACGGGGGCCCGCACAAGCGGTGGAGCATGTGGTTTAATTCGAAGCAACGCGAAGAACCTTACCAAGGCTTGACATCCCGATGACCGTCCTAGAGATAGGACTTCTCTTCGGAGCATCGGTGACAGGTGGTGCATGGTTGTCGTCAGCTCGTGTCGTGAGATGTTGGGTTAAGTCCCGCAACGAGCGCAACCCTTATCTTCAGTAGCCATCATTCAGTTGGGCACTCTGGAGAGACTGCCGTGGATAACACGGAGGAAGGTGGGGATGACGTCAAATCATCATGCCCCTTATGTCTTGGGCTACACACGTGCTACAATGGCTGGTAACAAAGTGACGCGAGACGGCGACGTTAAGCAAATCACAAAAACCCAGTCCCAGTTCGGATTGTAGTCTGCAACTCGACTACATGAAGCTGGAATCGCTAGTAATCGCGAATCAGCATGTCGCGGTGAATACGTTCCCGGGCCTTGTACACACCGCCCGTCACACCATGGGAGTTGGAAGCACCCGAAGTCGGTGACCTAACCGTAAGGAAGAGCCGCCGAAGTAGGGGAT
表5
>2E3(SEQ ID NO.:4)
CGGCGCTCTACCATGCAGTCGACGAAGCGATTTGAATGAAGTTTTCGGATGGATTTTAAATTGACTGAGTGGCGGACGGGTGAGTAACGCGTGGGTAACCTGCCCCATACAGGGGGATAACAGTTAGAAATGACTGCTAATACCGCATAAGACCACAGCGCCGCATGGTGCAGGGGTAAAAACTCCGGTGGTATGGGATGGACCCGCGTCTGATTAGCTTGTTGGCGGGGTAACGGCCCACCAAGGCGACGATCAGTAGCCGACCTGAGAGGGTGACCGGCCACATTGGGACTGAGACACGGCCCAAACTCCTACGGGAGGCAGCAGTGGGGAATATTGCACAATGGGGGAAACCCTGATGCAGCGACGCCGCGTGAGTGATGAAGTATTTCGGTATGTAAAGCTCTATCAGCAGGGAAGAAAATGACGGTACCTGACTAAGAAGCCCCGGCTAACTACGTGCCAGCAGCCGCGGTAATACGTAGGGGGCAAGCGTTATCCGGATTTACTGGGTGTAAAGGGAGCGTAGACGGCTGTGCAAGTCTGGAGTGAAAGCCCGGGGCTCAACCCCGGGACTGCTTTGGAAACTGTACGGCTGGAGTGCTGGAGAGGCAAGCGGAATTCCTAGTGTAGCGGTGAAATGCGTAGATATTAGGAGGAACACCAGTGGCGAAGGCGGCTTGCTGGACAGTAACTGACGTTGAGGCTCGAAAGCGTGGGGAGCAAACAGGATTAGATACCCTGGTAGTCCACGCCGTAAACGATGAATGCTAGGTGTCGGGGAGCAAAGCTCTTCGGTGCCGCCGCAAACGCAATAAGCATTCCACCTGGGGAGTACGTTCGCAAGAATGAAACTCAAAGGAATTGACGGGGACCCGCACAAGCGGTGGAGCATGTGGTTTAATTCGAAGCAACGCGAAGAACCTTACCAAGTCTTGACATCCCCCTGACCGGCAAGTAATGTCGCCTTTCCTTCGGGACAGGGGAGACAGGTGGTGCATGGTTGTCGTCAGCTCGTGTCGTGAGATGTTGGGTTAAGTCCCGCAACGAGCGCAACCCTTATCCTCAGTAGCCAGCAGGTGAAGCTGGGCACTCTGTGGAGACTGCCAGGGATAACCTGGAGGAAGGTGGGGACGACGTCAAATCATCATGCCCCTTATGACTTGGGCTACACACGTGCTACAATGGCGTAAACAAAGGGAAGCGAGAGGGTGACCTGGAGCAAATCCCAAAAATAACGTCTCAGTTCGGATTGTAGTCTGCAACTCGACTACATGAAGCTGGAATCGCTAGTAATCGCGAATCAGCATGTCGCGGTGAATACGTTCCCGGGTCTTGTACACACCGCCCGTCACACCATGGGAGTCAGCAACGCCCGAAGCCGGTGACCTAACCGCAAGGAAGGAGCCGTCGAAGTCGTCG
表6
>1C12(SEQ ID NO.:5)
CGGCGCTGCTATACTGCAGTCGAACGAAGCGAAGGTAGCTTGCTATCGGAGCTTAGTGGCGAACGGGTGAGTAACACGTAGATAACCTGCCTGTATGACCGGGATAACAGTTGGAAACGACTGCTAATACCGGATAGGCAGAGAGGAGGCATCTCTTCTCTGTTAAAGTTGGGATACAACGCAAACAGATGGATCTGCGGTGCATTAGCTAGTTGGTGAGGTAACGGCCCACCAAGGCGATGATGCATAGCCGGCCTGAGAGGGCGAACGGCCACATTGGGACTGAGACACGGCCCAAACTCCTACGGGAGGCAGCAGTAGGGAATTTTCGGCAATGGGGGAAACCCTGACCGAGCAATGCCGCGTGAGTGAAGACGGCCTTCGGGTTGTAAAGCTCTGTTGTAAGGGAAGAACGGCATAGAGAGGGAATGCTCTATGAGTGACGGTACCTTACCAGAAAGCCACGGCTAACTACGTGCCAGCAGCCGCGGTAATACGTAGGTGGCAAGCGTTATCCGGAATTATTGGGCGTAAAGGGTG
CGTAGGCGGCTGGATAAGTCTGAGGTAAAAGCCCGTGGCTCAACCACGGTAAGCCTTGGAAACTGTCTGGCTGGAGTGCAGGAGAGGACAATGGAATTCCATGTGTAGCGGTAAAATGCGTAGATATATGGAGGAACACCAGTGGCGAAGGCGGTTGTCTGGCCTGTAACTGACGCTGAAGCACGAAAGCGTGGGGAGCAAATAGGATTAGATACCCTAGTAGTCCACGCCGTAAACGATGAGAACTAAGTGTTGGGGAAACTCAGTGCTGCAGTTAACGCAATAAGTTCTCCGCCTGGGGAGTATGCACGCAAGTGTGAAACTCAAAGGAATTGACGGGGGCCCGCACAAGCGGTGGAGTATGTGGTTTAATTCGACGCAACGCGAAGAACCTTACCAGGCCTTGACATGGTATCAAAGGCCCTAGAGATAGGGAGATAGGTATGATACACACAGGTGGTGCATGGTTGTCGTCAGCTCGTGTCGTGAGATGTTGGGTTAAGTCCCGCAACGAGCGCAACCCTTGTTTCTAGTTACCAACAGTAAGATGGGGACTCTAGAGAGACTGCCGGTGACAAACCGGAGGAAGGTGGGGATGACGTCAAATCATCATGCCCCTTATGGCCTGGGCTACACACGTACTACAATGGCGTCTACAAAGAGCAGCGAGCAGGTGACTGTAAGCGAATCTCATAAAGGACGTCTCAGTTCGGATTGAAGTCTGCAACTCGACTTCATGAAGTCGGAATCGCTAGTAATCGCGGATCAGCATGCCGCGGTGAATACGTTCTCGGGCCTTGTACACACCGCCCGTCAAACCATGGGAGTTGATAATACCCGAAGCCGGTGGCCTAACCGAAAGGAGGGAGCCGTCGAAGTAGATTG
表7
>2G4(SEQ ID NO.:6)
CGGCGCTGCTATAATGCAGTCGAACGAAGTTTCGAGGAAGCTTGCTTCCAAAGAGACTTAGTGGCGAACGGGTGAGTAACACGTAGGTAACCTGCCCATGTGTCCGGGATAACTGCTGGAAACGGTAGCTAAAACCGGATAGGTATACAGAGCGCATGCTCAGTATATTAAAGCGCCCATCAAGGCGTGAACATGGATGGACCTGCGGCGCATTAGCTAGTTGGTGAGGTAACGGCCCACCAAGGCGATGATGCGTAGCCGGCCTGAGAGGGTAAACGGCCACATTGGGACTGAGACACGGCCCAAACTCCTACGGGAGGCAGCAGTAGGGAATTTTCGTCAATGGGGGAAACCCTGAACGAGCAATGCCGCGTGAGTGAAGAAGGTCTTCGGATCGTAAAGCTCTGTTGTAAGTGAAGAACGGCTCATAGAGGAAATGCTATGGGAGTGACGGTAGCTTACCAGAAAGCCACGGCTAACTACGTGCCAGCAGCCGCGGTAATACGTAGGTGGCAAGCGTTATCCGGAATCATTGGGCGTAAAGGGTGCGTAGGTGGCGTACTAAGTCTGTAGTAAAAGGCAATGGCTCAACCATTGTAAGCTATGGAAACTGGTATGCTGGAGTGCAGAAGAGGGCGATGGAATTCCATGTGTAGCGGTAAAATGCGTAGATATATGGAGGAACACCAGTGGCGAAGGCGGTCGCCTGGTCTGTAACTGACACTGAGGCACGAAAGCGTGGGGAGCAAATAGGATTAGATACCCTAGTAGTCCACGCCGTAAACGATGAGAACTAAGTGTTGGAGGAATTCAGTGCTGCAGTTAACGCAATAAGTTCTCCGCCTGGGGAGTATGCACGCAAGTGTGAAACTCAAAGGAATTGACGGGGGCCCGCACAAGCGGTGGAGTATGTGGTTTAATTCGAAGCAACGCGAAGAACCTTACCAGGCCTTGACATGGATGCAAATGCCCTAGAGATAGAGAGATAATTATGGATCACACAGGTGGTGCATGGTTGTCGTCAGCTCGTGTCGTGAGATGTTGGGTTAAGTCCCGCAACGAGCGCAACCCTTGTCGCATGTTACCAGCATCAAGTTGGGGACTCATGCGAGACTGCCGGTGACAAACCGGAGGAAGGTGGGGATGACGTCAAATCATCATGCCCCTTATGGCCTGGGCTACACACGTACTACAATGGCGACCACAAAGAGCAGCGACACAGTGATGTGAAGCGAATCTCATAAAGGTCGTCTCAGTTCGGATTGAAGTCTGCAACTCGACTTCATGAAGTCGGAATCGCTAGTAATCGCAGATCAGCATGCTGCGGTGAATACGTTCTCGGGCCTTGTACACACCGCCCGTCAAACCATGGGAGTCAGTAATACCCGAAGCCGGTGGCATAACCGTAAGGAGGAGCCGTCGAAGTGACTG
表8
>2H11(SEQ ID NO.:7)
AGGGCGGCTCTTAAATGCAGTCGAACGGGGTGCTCATGACGGAGGATTCGTCCAACGGATTGAGTTACCTAGTGGCGGACGGGTGAGTAACGCGTGAGGAACCTGCCTTGGAGAGGGGAATAACACTCCGAAAGGAGTGCTAATACCGCATGATGCAGTTGGGTCGCATGGCTCTGACTGCCAAAGATTTATCGCTCTGAGATGGCCTCGCGTCTGATTAGCTAGTAGGCGGGGTAACGGCCCACCTAGGCGACGATCAGTAGCCGGACTGAGAGGTTGACCGGCCACATTGGGACTGAGACACGGCCCAGACTCCTACGGGAGGCAGCAGTGGGGAATATTGGGCAATGGGCGCAAGCCTGACCCAGCAACGCCGCGTGAAGGAAGAAGGCTTTCGGGTTGTAAACTTCTTTTGTCGGGGACGAAACAAATGACGGTACCCGACGAATAAGCCACGGCTAACTACGTGCCAGCAGCCGCGGTAATACGTAGGTGGCAAGCGTTATCCGGATTTACTGGGTGTAAAGGGCGTGTAGGCGGGATTGCAAGTCAGATGTGAAAACTGGGGGCTCAACCTCCAGCCTGCATTTGAAACTGTAGTTCTTGAGTGCTGGAGAGGCAATCGGAATTCCGTGTGTAGCGGTGAAATGCGTAGATATACGGAGGAACACCAGTGGCGAAGGCGGATTGCTGGACAGTAACTGACGCTGAGGCGCGAAAGCGTGGGGAGCAAACAGGATTAGATACCCTGGTAGTCCACGCCGTAAACGATGGATACTAGGTGTGGGGGGTCTGACCCCCTCCGTGCCGCAGTTAACACAATAAGTATCCCACCTGGGGAGTACGATCGCAAGGTTGAAACTCAAAGGAATTGACGGGGGCCCGCACAAGCGGTGGAGTATGTGGTTTAATTCGAAGCAACGCGAAGAACCTTACCAGGGCTTGACATCCCACTAACGAGGCAGAGATGCGTTAGGTGCCCTTCGGGGAAAGTGGAGACAGGTGGTGCATGGTTGTCGTCAGCTCGTGTCGTGAGATGTTGGGTTAAGTCCCGCAACGAGCGCAACCCTTATTGTTAGTTGCTACGCAAGAGCACTCTAGCGAGACTGCCGTTGACAAAACGGAGGAAGGTGGGGACGACGTCAAATCATCATGCCCCTTATGTCCTGGGCCACACACGTACTACAATGGTGGTTAACAGAGGGAGGCAATACCGCGAGGTGGAGCAAATCCCTAAAAGCCATCCCAGTTCGGATTGCAGGCTGAAACCCGCCTGTATGAAGTTGGAATCGCTAGTAATCGCGGATCAGCATGCCGCGGTGAATACGTTCCCGGGCCTTGTACACACCGCCCGTCACACCATGAGAGTCGGGAACACCCGAAGTCCGTAGCCTAACCGCAAGGAGGGCGCGGCCGAAAGTTGTTCAT
表9
>1E11(SEQ ID NO.:8)
CGGGGGCTGCTACCATGCAGTCGAACGGAGTTAAGAGAGCTTGCTCTTTTAACTTAGTGGCGGACGGGTGAGTAACGCGTGAGTAACCTGCCTTTCAGAGGGGAATAACATTCTGAAAAGAATGCTAATACCGCATGAGATCGTAGTATCGCATGGTACAGCGACCAAAGGAGCAATCCGCTGAAAGATGGACTCGCGTCCGATTAGCTAGTTGGTGAGATAAAGGCCCACCAAGGCGACGATCGGTAGCCGGACTGAGAGGTTGAACGGCCACATTGGGACTGAGACACGGCCCAGACTCCTACGGGAGGCAGCAGTGGGGGATATTGCACAATGGGGGAAACCCTGATGCAGCAACGCCGCGTGAAGGAAGAAGGTCTTCGGATTGTAAACTTCTGTCCTCAGGGAAGATAATGACGGTACCTGAGGAGGAAGCTCCGGCTAACTACGTGCCAGCAGCCGCGGTAATACGTAGGGAGCAAGCGTTGTCCGGATTTACTGGGTGTAAAGGGTGCGTAGGCGGATCTGCAAGTCAGTAGTGAAATCCCAGGGCTTAACCCTGGAACTGCTATTGAAACTGTGGGTCTTGAGTGAGGTAGAGGCAGGCGGAATTCCCGGTGTAGCGGTGAAATGCGTAGAGATCGGGAGGAACACCAGTGGCGAAGGCGGCCTGCTGGGCCTTAACTGACGCTGAGGCACGAAAGCATGGGTAGCAAACAGGATTAGATACCCTGGTAGTCCATGCCGTAAACGATGATTACTAGGTGTGGGTGGTCTGACCCCATCCGTGCCGGAGTTAACACAATAAGTAATCCACCTGGGGAGTACGGCCGCAAGGTTGAAACTCAAAGGAATTGACGGGGGCCCGCACAAGCAGTGGAGTATGTGGTTTAATTCGAAGCAACGCGAAGAACCTTACCAGGTCTTGACATCCTGCTAACGAGGTAGAGATACGTTAGGTGCCCTTCGGGGAAAGCAGAGACAGGTGGTGCATGGTTGTCGTCAGCTCGTGTCGTGAGATGTTGGGTTAAGTCCCGCAACGAGCGCAACCCCTGCTATTAGTTGCTACGCAAGAGCACTCTAATAGGACTGCCGTTGACAAAACGGAGGAAGGTGGGGACGACGTCAAATCATCATGCCCCTTATGACCTGGGCTACACACGTACTACAATGGCCGTCAACAGAGAGAAGCAAAGCCGCGAGGTGGAGCAAAACTCTAAAAACGGTCCCAGTTCGGATCGTAGGCTGCAACCCGCCTACGTGAAGTTGGAATTGCTAGTAATCGCGGATCATCATGCCGCGGTGAATACGTTCCCGGGCCTTGTACACACCGCCCGTCACACCATGGGAGCCGGTAATACCCGAAGTCAGTAGTCTAACCGCAAGGGGACGCGCCGAAAGGTGGAGTG
表10
>2D9(SEQ ID NO.:9)
CTGGCGGGTGCTACCATGCAGTCGAGCGAAGCACTTTTGCGGATTTCTTCGGATTGAAGCAATTGTGACTGAGCGGCGGACGGGTGAGTAACGCGTGGGTAACCTGCCTCATACAGGGGGATAACAGTTGGAAACGGCTGCTAATACCGCATAAGCGCACAGTACCGCATGGTACCGTGTGAAAAACTCCGGTGGTATGAGATGGACCCGCGTCTGATTAGCTAGTTGGTGGGGTAACGGCCTACCAAGGCGACGATCAGTAGCCGACCTGAGAGGGTGACCGGCCACATTGGGACTGAGACACGGCCCAAACTCCTACGGGAGGCAGCAGTGGGGAATATTGCACAATGGGGGAAACCCTGATGCAGCGACGCCGCGTGAGCGATGAAGTATTTCGGTATGTAAAGCTCTATCAGCAGGGAAGAAAATGACGGTACCTGACTAAGAAGCCCCGGCTAACTACGTGCCAGCAGCCGCGGTAATACGTAGGGGGCAAGCGTTATCCGGATTTACTGGGTGTAAAGGGAGCGTAGACGGCATGGCAAGCCAGATGTGAAAGCCCGGGGCTCAACCCCGGGACTGCATTTGGAACTGTCAGGCTAGAGTGTCGGAGAGGAAAGCGGAATTCCTAGTGTAGCGGTGAAATGCGTAGATATTAGGAGGAACACCAGTGGCGAAGGCGGCTTTCTGGACGATGACTGACGTTGAGGCTCGAAAGCGTGGGGAGCAAACAGGATTAGATACCCTGGTAGTCCACGCCGTAAACGATGAATACTAGGTGTCGGGTGGCAAAGCCATTCGGTGCCGCAGCAAACGCAATAAGTATTCCACCTGGGGAGTACGTTCGCAAGAATGAAACTCAAAGGAATTGACGGGGACCCGCACAAGCGGTGGAGCATGTGGTTTAATTGGAAGCAACGCGAAGAACCTTACCTGGTCTTGACATCCCTCTGACCGCTCTTTAATCGGAGTTTTCTTTCGGGACAGAGGAGACAGGTGGTGCATGGTTGTCGTCAGCTCGTGTCGTGAGATGTTGGGTTAAGTCCCGCAACGAGCGCAACCCCTATCTTTAGTAGCCAGCATTTAGGGTGGGCACTCTAGAGAGACTGCCAGGGATAACCTGGAGGAAGGTGGGGATGACGTCAAATCATCATGCCCCTTATGACCAGGGCTACACACGTGCTACAATGGCGTAAACAAAGGGAAGCGAGCCCGCGAGGGGGAGCAAATCCCAAAAATAACGTCTCAGTTCGGATTGTAGTCTGCAACTCGACTACATGAAGCTGGAATCGCTAGTAATCGCGAATCAGAATGTCGCGGTGAATACGTTCCCGGGTCTTGTACACACCGCCCGTCACACCATGGGAGTCAGTAACGCCCGAAGTCAGTGACCCAACCGTAAGGAGGAGCTGCCGAAGTGTACTAT
表11
>2F7(SEQ ID NO.:10)
GAGTGGGCCGCTACCATGCAGTCGACGAGCCGAGGGGAGCTTGCTCCCCAGAGCTAGTGGCGGACGGGTGAGTAACACGTGAGCAACCTGCCTTTCAGAGGGGGATAACGTTTGGAAACGAACGCTAATACCGCATAACATACCGGGACCGCATGATTCTGGTATCAAAGGAGCAATCCGCTGAAAGATGGGCTCGCGTCCGATTAGCTAGTTGGCGGGGTAACGGCCCACCAAGGCGACGATCGGTAGCCGGACTGAGAGGTTGATCGGCCACATTGGGACTGAGACACGGCCCAGACTCCTACGGGAGGCAGCAGTGGGGGATATTGCACAATGGAGGAAACTCTGATGCAGCGACGCCGCGTGAGGGAAGACGGTCTTCGGATTGTAAACCTCTGTCTTTGGGGACGATAATGACGGTACCCAAGGAGGAAGCTCCGGCTAACTACGTGCCAGCAGCCGCGGTAATACGTAGGGAGCGAGCGTTGTCCGGAATTACTGGGTGTAAAGGGAGCGTAGGCGGGGTCTCAAGTCGAATGTTAAATCTACCGGCTCAACTGGTAGCTGCGTTCGAAACTGGGGCTCTTGAGTGAAGTAGAGGCAGGCGGAATTCCTAGTGTAGCGGTGAAATGCGTAGATATTAGGAGGAACACCAGTGGCGAAGGCGGCCTGCTGGGCTTTTACTGACGCTGAGGCTCGAAAGCGTGGGGAGCAAACAGGATTAGATACCCTGGTAGTCCACGCCGTAAACGATGATTACTAGGTGTGGGGGGACTGACCCCTTCCGTGCCGGAGTTAACACAATAAGTAATCCACCTGGGGAGTACGACCGCAAGGTTGAAACTCAAAGGAATTGACGGGGGCCCGCACAAGCAGTGGATTATGTGGTTTAATTCGAAGCAACGCGAAGAACCTTACCAGGTCTTGACATCGAGTGACGGCTCTAGAGATAGAGCTTTCCTTCGGGACACAAAGACAGGTGGTGCATGGTTGTCGTCAGCTCGTGTCGTGAGATGTTGGGTTAAGTCCCGCAACGAGCGCAACCCTTATTATTAGTTGCTACATTCAGTTGAGCACTCTAATGAGACTGCCGTTGACAAAACGGAGGAAGGTGGGGATGACGTCAAATCATCATGCCCCTTATGACCTGGGCTACACACGTAATACAATGGCGATCAACAGAGGGAAGCAAGACCGCGAGGTGGAGCAAACCCCTAAAAGTCGTCTCAGTTCGGATTGCAGGCTGCAACTCGCCTGCATGAAGTCGGAATTGCTAGTAATCGCGGATCAGCATGCCGCGGTGAATACGTTCCCGGGCCTTGTACACACCGCCCGTCACACCATGGGAGTCGGTAACACCCGAAGTCAGTAGCCTAACCGCAAAGAGGGCGCTGCCGAAGATGGATT
表12
>1D1(SEQ ID NO.:11)
ATGGCGGCTGCTACCTGCAGTCGAACGGGGTTATTTTGGAAATCTCTTCGGAGATGGAATTCTTAACCTAGTGGCGGACGGGTGAGTAACGCGTGAGCAATCTGCCTTTAGGAGGGGGATAACAGTCGGAAACGGCTGCTAATACCGCATAATACGTTTGGGAGGCATCTCTTGAACGTCAAAGATTTTATCGCCTTTAGATGAGCTCGCGTCTGATTAGCTGGTTGGCGGGGTAACGGCCCACCAAGGCGACGATCAGTAGCCGGACTGAGAGGTTGAACGGCCACATTGGGACTGAGACACGGCCCAGACTCCTACGGGAGGCAGCAGTGGGGAATATTGCGCAATGGGGGAAACCCTGACGCAGCAACGCCGCGTGATTGAAGAAGGCCTTCGGGTTGTAAAGATCTTTAATCAGGGACGAAAAATGACGGTACCTGAAGAATAAGCTCCGGCTAACTACGTGCCAGCAGCCGCGGTAATACGTAGGGAGCAAGCGTTATCCGGATTTACTGGGTGTAAAGGGCGCGCAGGCGGGCCGGCAAGTTGGGAGTGAAATCCCGGGGCTTAACCCCGGAACTGCTTTCAAAACTGCTGGTCTTGAGTGATGGAGAGGCAGGCGGAATTCCGTGTGTAGCGGTGAAATGCGTAGATATACGGAGGAACACCAGTGGCGAAGGCGGCCTGCTGGACATTAACTGACGCTGAGGCGCGAAAGCGTGGGGAGCAAACAGGATTAGATACCCTGGTAGTCCACGCCGTAAACGATGGATACTAGGTGTGGGAGGTATTGACCCCTTCCGTGCCGCAGTTAACACAATAAGTATCCCACCTGGGGAGTACGGCCGCAAGGTTGAAACTCAAAGGAATTGACGGGGGCCCGCACAAGCAGTGGAGTATGTGGTTTAATTCGAAGCAACGCGAAGAACCTTACCAGGTCTTGACATCCCGATGACCGGCGTAGAGATACGCCCTCTCTTCGGAGCATCGGTGACAGGTGGTGCATGGTTGTCGTCAGCTCGTGTCGTGAGATGTTGGGTTAAGTCCCGCAACGAGCGCAACCCTTACGGTTAGTTGATACGCAAGATCACTCTAGCCGGACTGCCGTTGACAAAACGGAGGAAGGTGGGGACGACGTCA
AATCATCATGCCCCTTATGACCTGGGCTACACACGTACTACAATGGCAGTCATACAGAGGGAAGCAATACCGCGAGGTGGAGCAAATCCCTAAAAGCTGTCCCAGTTCAGATTGCAGGCTGCAACCCGCCTGCATGAAGTCGGAATTGCTAGTAATCGCGGATCAGCATGCCGCGGTGAATACGTTCCCGGGCCTTGTACACACCGCCCGTCACACCATGAGAGCCGTCAATACCCGAAGTCCGTAGCCTAACCGCAAGGGGGCGCGCCGAAGTTACGT
表13
>1F8(SEQ ID NO.:12)
ATCGGGTGCTACCTGCAAGTCGAGCGAAGCGGTTTCGATGAAGTTTTCGGATGGAATTGAAATTGACTTAGCGGCGGACGGGTGAGTAACGCGTGGGTAACCTGCCTTACACTGGGGGATAACAGTTAGAAATGACTGCTAATACCGCATAAGCGCACAGGGCCGCATGGTCTGGTGCGAAAAACTCCGGTGGTGTAAGATGGACCCGCGTCTGATTAGGTAGTTGGTGGGGTAACGGCCCACCAAGCCGACGATCAGTAGCCGACCTGAGAGGGTGACCGGCCACATTGGGACTGAGACACGGCCCAAACTCCTACGGGAGGCAGCAGTGGGGAATATTGGACAATGGGCGAAAGCCTGATCCAGCGACGCCGCGTGAGTGAAGAAGTATTTCGGTATGTAAAGCTCTATCAGCAGGGAAGAAAATGACGGTACCTGACTAAGAAGCCCCGGCTAACTACGTGCCAGCAGCCGCGGTAATACGTAGGGGGCAAGCGTTATCCGGATTTACTGGGTGTAAAGGGAGCGTAGACGGTTAAGCAAGTCTGAAGTGAAAGCCCGGGGCTCAACCCCGGTACTGCTTTGGAAACTGTTTGACTTGAGTGCAGGAGAGGTAAGTGGAATTCCTAGTGTAGCGGTGAAATGCGTAGATATTAGGAGGAACACCAGTGGCGAAGGCGGCTTACTGGACTGTAACTGACGTTGAGGCTCGAAAGCGTGGGGAGCAAACAGGATTAGATACCCTGGTAGTCCACGCCGTAAACGATGAATACTAGGTGTCGGGGGACAACGTCCTTCGGTGCCGCCGCTAACGCAATAAGTATTCCACCTGGGGAGTACGTTCGCAAGAATGAAACTCAAAGGAATTGACGGGGACCCGCACAAGCGGTGGAGCATGTGGTTTAATTCGAAGCAACGCGAAGAACCTTACCAAGTCTTGACATCCCATTGAAAATCCTTTAACCGTGGTCCCTCTTCGGAGCAATGGAGACAGGTGGTGCATGGTTGTCGTCAGCTCGTGTCGTGAGATGTTGGGTTAAGTCCCGCAACGAGCGCAACCCTTATCCTTAGTAGCCAGCACATGATGGTGGGCACTCTGGGGAGACTGCCAGGGATAACCTGGAGGAAGGTGGGGATGACGTCAAATCATCATGCCCCTTATGATTTGGGCTACACACGTGCTACAATGGCGTAAACAAAGGGAAGCAAAGGAGCGATCTGGAGCAAACCCCAAAAATAACGTCTCAGTTCGGATTGCAGGCTGCAACTCGCCTGCATGAAGCTGGAATCGCTAGTAATCGCGAATCAGAATGTCGCGGTGAATACGTTCCCGGGTCTTGTACACACCGCCCGTCACACCATGGGAGTTGGTAACGCCCGAAGTCAGTGACCCAACCGTAAGGAGGAGCGCCGAAGGCGAGGT
表14
>1C2(SEQ ID NO.:13)
CGGGGCTGCTTAAATGCAGTCGAACGGGATCCATCAAGCTTGCTTGGTGGTGAGAGTGGCGAACGGGTGAGTAATGCGTGACCGACCTGCCCCATGCACCGGAATAGCTCCTGGAAACGGGTGGTAATGCCGGATGCTCCATCACACTGCATGGTGTGTTGGGAAAGCCTTTGCGGCATGGGATGGGGTCGCGTCCTATCAGCTTGATGGCGGGGTAACGGCCCACCATGGCTTCGACGGGTAGCCGGCCTGAGAGGGCGACCGGCCACATTGGGACTGAGATACGGCCCAGACTCCTACGGGAGGCAGCAGTGGGGAATATTGCACAATGGGCGCAAGCCTGATGCAGCGACGCCGCGTGAGGGATGGAGGCCTTCGGGTTGTAAACCTCTTTTGTTAGGGAGCAAGGCATTTTGTGTTGAGTGTACCTTTCGAATAAGCACCGGCTAACTACGTGCCAGCAGCCGCGGTAATACGTAGGGTGCAAGCGTTATCCGGAATTATTGGGCGTAAAGGGCTCGTAGGCGGTTCGTCGCGTCCGGTGTGAAAGTCCATCGCTTAACGGTGGATCCGCGCCGGGTACGGGCGGGCTTGAGTGCGGTAGGGGAGACTGGAATTCCCGGTGTAACGGTGGAATGTGTAGATATCGGGAAGAACACCAATGGCGAAGGCAGGTCTCTGGGCCGTTACTGACGCTGAGGAGCGAAAGCGTGGGGAGCGAACAGGATTAGATACCCTGGTAGTCCACGCCGTAAACGGTGGATGCTGGATGTGGGGCCCGTTCCACGGGTTCCGTGTCGGAGCTAACGCGTTAAGCATCCCGCCTGGGGAGTACGGCCGCAAGGCTAAAACTCAAAGAAATTGACGGGGGCCCGCACAAGCGGCGGAGCATGCGGATTAATTCGATGCAACGCGAAGAACCTTACCTGGGCTTGACATGTTCCCGACGATCCCAGAGATGGGGTTTCCCTTCGGGGCGGGTTCACAGGTGGTGCATGGTCGTCGTCAGCTCGTGTCGTGAGATGTTGGGTTAAGTCCCGCAACGAGCGCAACCCTCGCCCCGTGTTGCCAGCGGATTGTGCCGGGAACTCACGGGGGACCGCCGGGGTTAACTCGGAGGAAGGTGGGGATGACGTCAGATCATCATGCCCCTTACGTCCAGGGCTTCACGCATGCTACAATGGCCGGTACAACGGGATGCGACAGCGCGAGCTGGAGCGGATCCCTGAAAACCGGTCTCAGTTCGGATCGCAGTCTGCAACTCGACTGCGTGAAGGCGGAGTCGCTAGTAATCGCGAATCAGCAACGTCGCGGTGAATGCGTTCCCGGGCCTTGTACACACCGCCCGTCAAGTCATGAAAGTGGGCAGCACCCGAAGCCGGTGGCCTAACCCCTTGCGGGAGGGAGCCGTCTAAGGTAGGTT
表15
>1D4(SEQ ID NO.:14)
CGGGCGCTGCTTACCTGCAGTCGAGCGAAGCACTTGAGCGGATTTCTTCGGATTGAAGTTTTTTTGACTGAGCGGCGGACGGGTGAGTAACGCGTGGGTAACCTGCCTCATACAGGGGGATAACAGTTAGAAATGGCTGCTAATACCGCATAAGCGCACAGGACCGCATGGTCTGGTGTGAAAAACTCCGGTGGTATGAGATGGACCCGCGTCTGATTAGCTAGTTGGAGGGGTAACGGCCCACCAAGGCGACGATCAGTAGCCGGCCTGAGAGGGTGAACGGCCACATTGGGACTGAGACACGGCCCAGACTCCTACGGGAGGCAGCAGTGGGGAATATTGCACAATGGGGGAAACCCTGATGCAGCGACGCCGCGTGAAGGAAGAAGTATCTCGGTATGTAAACTTCTATCAGCAGGGAAGAAAATGACGGTACCTGACTAAGAAGCCCCGGCTAACTACGTGCCAGCAGCCGCGGTAATACGTAGGGGGCAAGCGTTATCCGGATTTACTGGGTGTAAAGGGAGCGTAGACGGAAGAGCAAGTCTGATGTGAAAGGCTGGGGCTTAACCCCAGGACTGCATTGGAAACTGTTTTTCTAGAGTGCCGGAGAGGTAAGCGGAATTCCTAGTGTAGCGGTGAAATGCGTAGATATTAGGAGGAACACCAGTGGCGAAGGCGGCTTACTGGACGGTAACTGACGTTGAGGCTCGAAAGCGTGGGGAGCAAACAGGATTAGATACCCTGGTAGTCCACGCCGTAAACGATGAATACTAGGTGTCGGGTGGCAAAGCCATTCGGTGCCGCAGCAAACGCAATAAGTATTCCACCTGGGGAGTACGTTCGCAAGAATGAAACTCAAAGGAATTGACGGGGACCCGCACAAGCGGTGGAGCATGTGGTTTAATTCGAAGCAACGCGAAGAACCTTACCAAGTCTTGACATCCCTCTGACCGGCCCGTAACGGGGCCTTCCCTTCGGGGCAGAGGAGACAGGTGGTGCATGGTTGTCGTCAGCTCGTGTCGTGAGATGTTGGGTTAAGTCCCGCAACGAGCGCAACCCCTATCCTTAGTAGCCAGCAGGTGAAGCTGGGCACTCTAGGGAGACTGCCGGGGATAACCCGGAGGAAGGCGGGGACGACGTCAAATCATCATGCCCCTTATGATTTGGGCTACACACGTGCTACAATGGCGTAAACAAAGGGAAGCGAGACAGCGATGTTGAGCAAATCCCAAAAATAACGTCCCAGTTCGGACTGCAGTCTGCAACTCGACTGCACGAAGCTGGAATCGCTAGTAATCGCGAATCAGAATGTCGCGGTGAATACGTTCCCGGGTCTTGTACACACCGCCCGTCACACCATGGGAGTCAGTAACGCCCGAAGTCAGTGACCCAACCTTATAGGAGGAGCGCCGAAGTCGACCT
表16
>1E3(SEQ ID NO.:15)
CGCGGGTGCTATACTGCAGTCGAACGCACTGATTTTATCAGTGAGTGGCGAACGGGTGAGTAATACATAAGTAACCTGCCCTCATGAGGGGGATAACTATTAGAAATGATAGCTAAGACCGCATAGGTGAAGGGGTCGCATGACCGCTTCATTAAATATCCGTATGGATAGCAGGAGGATGGACTTATGGCGCATTAGCTGGTTGGTGAGGTAACGGCTCACCAAGGCGACGATGCGTAGCCGACCTGAGAGGGTGGACGGCCACACTGGGACTGAGACACGGCCCAGACTCCTACGGGAGGCAGCAGTAGGGAATTTTCGGCAATGGGGGAAACCCTGACCGAGCAACGCCGCGTGAGGGAAGAAGTATTTCGGTATGTAAACCTCTGTTATAAAGGAAGAACGGTATGAATAGGAAATGATTCATAAGTGACGGTACTTTATGAGAAAGCCACGGCTAACTACGTGCCAGCAGCCGCGGTAATACGTAGGTGGCGAGCGTTATCCGGAATCATTGGGCGTAAAGAGGGAGCAGGCGGCAATAGAGGTCTGCGGTGAAAGCCTGAAGCTAAACTTCAGTAAGCCGTGGAAACCAAATAGCTAGAGTGCAGTAGAGGATCGTGGAATTCCATGTGTAGCGGTGAAATGCGTAGATATATGGAGGAACACCAGTGGCGAAGGCGACGATCTGGGCTGCAACTGACGCTCAGTCCCGAAAGCGTGGGGAGCAAATAGGATTAGATACCCTAGTAGTCCACGCCGTAAACGATGAGTACTAAGTGTTGGGGGTCAAACCTCAGTGCTGCAGTTAACGCAATAAGTACTCCGCCTGAGTAGTACGTTCGCAAGAATGAAACTCAAAGGAATTGACGGGGGCCCGCACAAGCGGTGGAGCATGTGGTTTAATTCGAAGCAACGCGAAGAACCTTACCAGGTCTTGACATACCTCTAAAGGCTCTAGAGATAGAGAGATAGCTATAGGGGATACAGGTGGTGCATGGTTGTCGTCAGCTCGTGTCGTGAGATGTTGGGTTAAGTCCCGCAACGAGCGCAACCCTTGTCGCTAGTTACCATCATTAAGTTGGGGACTCTAGCGAGACTGCCTCTGCAAGGAGGAGGAAGGCGGGGATGACGTCAAATCATCATGCCCCTTATGACCTGGGCTACACACGTGCTACAATGGACGGATCAAAGGGAAGCGAAGCCGCGAGGTGGAGCGAAACCCAAAAACCCGTTCTCAGTTCGGACTGCAGTCTGCAACTCGACTGCACGAAGTTGGAATCGCTAGTAATCGCGAATCAGAATGTCGCGGTGAATACGTTCTCGGGCCTTGTACACACCGCCCGTCACACCATGAGAGTTGGTAACACCCGAAGCCGGTGGCTTAACCGCAAGGAGAGAGCTTCTAAGGTGAAT
表17
>1A9(SEQ ID NO.:16)
AGGCGCGTGCTACCATGCAGTCGAACGAAGCAATTTAACGGAAGTTTTCGGATGGAAGTTGAATTGACTGAGTGGCGGACGGGTGAGTAACGCGTGGGTAACCTGCCTTGTACTGGGGGACAACAGTTAGAAATGACTGCTAATACCGCATAAGCGCACAGTATCGCATGATACAGTGTGAAAAACTCCGGTGGTACAAGATGGACCCGCGTCTGATTAGCTAGTTGGTAAGGTAACGGCTTACCAAGGCGACGATCAGTAGCCGACCTGAGAGGGTGACCGGCCACATTGGGACTGAGACACGGCCCAAACTCCTACGGGAGGCAGCAGTGGGGAATATTGCACAATGGGCGAAAGCCTGATGCAGCGACGCCGCGTGAGTGAAGAAGTATTTCGGTATGTAAAGCTCTATCAGCAGGGAAGAAAATGACGGTACCTGACTAAGAAGCCCCGGCTAACTACGTGCCAGCAGCCGCGGTAATACGTAGGGGGCAAGCGTTATCCGGATTTACTGGGTGTAAAGGGAGCGTAGACGGTAAAGCAAGTCTGAAGTGAAAGCCCGCGGCTCAACTGCGGGACTGCTTTGGAAACTGTTTAACTGGAGTGTCGGAGAGGTAAGTGGAATTCCTAGTGTAGCGGTGAAATGCGTAGATATTAGGAGGAACACCAGTGGCGAAGGCGACTTACTGGACGATAACTGACGTTGAGGCTCGAAAGCGTGGGGAGCAAACAGGATTAGATACCCTGGTAGTCCACGCCGTAAACGATGAATACTAGGTGTTGGGGAGCAAAGCTCTTCGGTGCCGTCGCAAACGCAGTAAGTATTCCACCTGGGGAGTACGTTCGCAAGAATGAAACTCAAAGGAATTGACGGGGACCCGCACAAGCGGTGGAGCATGTGGTTTAATTCGAAGCAACGCGAAGAACCTTACCAGGTCTTGACATCGATCCGACGGGGGAGTAACGTCCCCTTCCCTTCGGGGCGGAGAAGACAGGTGGTGCATGGTTGTCGTCAGCTCGTGTCGTGAGATGTTGGGTTAAGTCCCGCAACGAGCGCAACCCTTATTCTAAGTAGCCAGCGGTTCGGCCGGGAACTCTTGGGAGACTGCCAGGGATAACCTGGAGGAAGGTGGGGATGACGTCAAATCATCATGCCCCTTATGATCTGGGCTACACACGTGCTACAATGGCGTAAACAAAGAGAAGCAAGACCGCGAGGTGGAGCAAATCTCAAAAATAACGTCTCAGTTCGGACTGCAGGCTGCAACTCGCCTGCACGAAGCTGGAATCGCTAGTAATCGCGAATCAGAATGTCGCGGTGAATACGTTCCCGGGTCTTGTACACACCGCCCGTCACACCATGGGAGTCAGTAACGCCCGAAGTCAGTGACCCAACCGCAAGGAGGAGCGCCGAAGGCGACCGT
表18
>2G11(SEQ ID NO.:17)
CGGTCTCGGCTTACCATGCAGTCGAGGGGCAGCATGGTCTTAGCTTGCTAAGGCTGATGGCGACCGGCGCACGGGTGAGTAACACGTATCCAACCTGCCGTCTACTCTTGGCCAGCCTTCTGAAAGGAAGATTAATCCAGGATGGCATCATGAGTTCACATGTCCGCATGATTAAAGGTATTTTCCGGTAGACGATGGGGATGCGTTCCATTAGATAGTAGGCGGGGTAACGGCCCACCTAGTCAACGATGGATAGGGGTTCTGAGAGGAAGGTCCCCCACATTGGAACTGAGACACGGTCCAAACTCCTACGGGAGGCAGCAGTGAGGAATATTGGTCAATGGGCGATGGCCTGAACCAGCCAAGTAGCGTGAAGGATGACTGCCCTATGGGTTGTAAACTTCTTTTATAAAGGAATAAAGTCGGGTATGCATACCCGTTTGCATGTACTTTATGAATAAGGATCGGCTAACTCCGTGCCAGCAGCCGCGGTAATACGGAGGATCCGAGCGTTATCCGGATTTATTGGGTTTAAAGGGAGCGTAGATGGATGTTTAAGTCAGTTGTGAAAGTTTGCGGCTCAACCGTAAAATTGCAGTTGATACTGGATGTCTTGAGTGCAGTTGAGGCAGGCGGAATTCGTGGTGTAGCGGTGAAATGCTTAGATATCACGAAGAACTCCGATTGCGAAGGCAGCCTGCTAAGCTGCAACTGACATTGAGGCTCGAAAGTGTGGGTATCAAACAGGATTAGATACCCTGGTAGTCCACACGGTAAACGATGAATACTCGCTGTTTGCGATATACGGCAAGCGGCCAAGCGAAAGCGTTAAGTATTCCACCTGGGGAGTACGCCGGCAACGGTGAAACTCAAAGGAATTGACGGGGGCCCGCACAAGCGGAGGAACATGTGGTTTAATTCGATGATACGCGAGGAACCTTACCCGGGCTTAAATTGCACTCGAATGATCCGGAAACGGTTCAGCTAGCAATAGCGAGTGTGAAGGTGCTGCATGGTTGTCGTCAGCTCGTGCCGTGAGGTGTCGGCTTAAGTGCCATAACGAGCGCAACCCTTGTTGTCAGTTACTAACAGGTGATGCTGAGGACTCTGACAAGACTGCCATCGTAAGATGTGAGGAAGGTGGGGATGACGTCAAATCAGCACGGCCCTTACGTCCGGGGCTACACACGTGTTACAATGGGGGGTACAGAGGGCCGCTACCACGCGAGTGGATGCCAATCCCTAAAACCCCTCTCAGTTCGGACTGGAGTCTGCAACCCGACTCCACGAAGCTGGATTCGCTAGTAATCGCGCATCAGCCACGGCGCGGTGAATACGTTCCCGGGCCTTGTACACACCGCCCGTCAAGCCATGGGAGCCGGGGGTACCTGAAGTGCGTAACCGCGAGGATCGCCCTAGGTAATGA
表19
>2E1(SEQ ID NO.:18)
CGGCGGCTGCTTACCATGCAGTCGAACGAAGCATTTAGGATTGAAGTTTTCGGATGGATTTCCTATATGACTGAGTGGCGGACGGGTGAGTAACGCGTGGGGAACCTGCCCTATACAGGGGGATAACAGCTGGAAACGGCTGCTAATACCGCATAAGCGCACAGAATCGCATGATTCAGTGTGAAAAGCCCTGGCAGTATAGGATGGTCCCGCGTCTGATTAGCTGGTTGGTGAGGTAACGGCTCACCAAGGCGACGATCAGTAGCCGGCTTGAGAGAGTGAACGGCCACATTGGGACTGAGACACGGCCCAAACTCCTACGGGAGGCAGCAGTGGGGAATATTGCACAATGGGGGAAACCCTGATGCAGCGACGCCGCGTGAGTGAAGAAGTATTTCGGTATGTAAAGCTCTATCAGCAGGGAAGAAAACAGACGGTACCTGACTAAGAAGCCCCGGCTAACTACGTGCCAGCAGCCGCGGTAATACGTAGGGGGCAAGCGTTATCCGGAATTACTGGGTGTAAAGGGTGCGTAGGTGGCATGGTAAGTCAGAAGTGAAAGCCCGGGGCTTAACCCCGGGACTGCTTTTGAAACTGTCATGCTGGAGTGCAGGAGAGGTAAGCGGAATTCCTAGTGTAGCGGTGAAATGCGTAGATATTAGGAGGAACACCAGTGGCGAAGGCGGCTTACTGGACTGTCACTGACACTGATGCACGAAAGCGTGGGGAGCAAACAGGATTAGATACCCTGGTAGTCCACGCCGTAAACGATGAATACTAGGTGTCGGGGCCGTAGAGGCTTCGGTGCCGCAGCAAACGCAGTAAGTATTCCACCTGGGGAGTACGTTCGCAAGAATGAAACTCAAAGGAATTGACGGGGACCCGCACAAGCGGTGGAGCATGTGGTTTAATTCGAAGCAACGCGAAGAACCTTACCTGGTCTTGACATCCCAATGACCGAACCTTAACCGGTTTTTTCTTTCGAGACATTGGAGACAGGTGGTGCATGGTTGTCGTCAGCTCGTGTCGTGAGATGTTGGGTTAAGTCCCGCAACGAGCGCAACCCCTATCTTTAGTAGCCAGCATTTAAGGTGGGCACTCTAGAGAGACTGCCAGGGATAACCTGGAGGAAGGTGGGGACGACGTCAAATCATCATGCCCCTTATGGCCAGGGCTACACACGTGCTACAATGGCGTAAACAAAGGGAAGCGAAGTCGTGAGGCGAAGCAAATCCCAGAAATAACGTCTCAGTTCGGATTGTAGTCTGCAACTCGACTACATGAAGCTGGAATCGCTAGTAATCGTGAATCAGAATGTCACGGTGAATACGTTCCCGGGTCTTGTACACACCGCCCGTCACACCATGGGAGTCAGTAACGCCCGAAGTCAGTGACCCAACCGCAAGGAGGGAGCTGCCGAAGTACGAG
表20
>1F7(SEQ ID NO.:19)
TTTGTGGCGAAGCCTGATGCAGCGACGCCGCGTGAGTGAAGAAGTATTTCGGTATGTAAAGCTCTATCAGCAGGGAAGAAAATGACGGTACCTGACTAAGAAGCCCCGGCTAACTACGTGCCAGCAGCCGCGGTAATACGTAGGGGGCAAGCGTTATCCGGATTTACTGGGTGTAAAGGGAGCGTAGACGGCGAAGCAAGTCTGAAGTGAAAACCCAGGGCTCAACCCTGGGACTGCTTTGGAAACTGTTTTGCTAGAGTGTCGGAGAGGTAAGTGGAATTCCTAGTGTAGCGGTGAAATGCGTAGATATTAGGAGGAACACCAGTGGCGAAGGCGGCTTACTGGACGATAACTGACGTTGAGGCTCGAAAGCGTGGGGAGCAAACAGGATTAGATACCCTGGTAGTCCACGCCGTAAACGATGAATGCTAGGTGTTGGGGGGCAAAGCCCTTCGGTGCCGTCGCAAACGCAGTAAGCATTCCACCTGGGGAGTACGTTCGCAAGAATGAAACTCAAAGGAATTGACGGGGACCCGCACAAGCGGTGGAGCATGTGGTTTAATTCGAAGCAACGCGAAGAACCTTACCAAGTCTTGACATCCTCTTGACCGGCGTGTAACGGCGCCTTCCCTTCGGGGCAAGAGAGACAGGTGGTGCATGGTTGTCGTCAGCTCGTGTCGTGAGATGTTGGGTTAAGTCCCGCAACGAGCGCAACCCTTATCCTTAGTAGCCAGCAGGTAAAGCTGGGCACTCTAGGGAGACTGCCAGGGATAACCTGGAGGAAGGTGGGGATGACGTCAAATCATCATGCCCCTTATGATTTGGGCTACACACGTGCTACAATGGCGTAAACAAAGGGAAGCAAGACAGTGATGTGGAGCAAATCCCAAAAATAACGTCCCAGTTCGGACTGTAGTCTGCAACCCGACTACACGAAGCTGGAATCGCTAGTAATCGCGAATCAGAATGTCGCGGTGAATACGTTCCCGGGTCTTGTACACACCGCCCGTCACACCATGGGAGTCAGCAACGCCCGAAGTCAGTGACCCAACTCGCAAGAGAGGGAGCGCCGAAGTCGTCAT
表21
>1D2(SEQ ID NO.:20)
CTGGCGCGGCTACCATGCAGTCGAGCGAAGCATTACAGCGGAAGTTTTCGGATGGAAGCTTTAATGACTGAGCGGCGGACGGGTGAGTAACGCGTGGATAACCTGCCTCATACAGGGGGATAACAGTTAGAAATGACTGCTAATACCGCATAAGCGCACAGTATCGCATGATACGGTGTGAAAAACTCCGGTGGTATGAGATGGATCCGCGTCTGATTAGTTAGTTGGCGGGGTAAAGGCCCACCAAGACGACGATCAGTAGCCGGCCTGAGAGGGTGAACGGCCACATTGGGACTGAGACACGGCCCAAACTCCTACGGGAGGCAGCAGTGGGGAATATTGCACAATGGGGGAAACCCTGATGCAGCGACGCCGCGTGAGTGAAGAAGTATTTCGGTATGTAAAGCTCTATCAGCAGGGAAGAAAATGACGGTACCTGACTAAGAAGCCCCGGCTAACTACGTGCCAGCAGCCGCGGTAATACGTAGGGGGCAAGCGTTATCCGGATTTACTGGGTGTAAAGGGAGCGTAGACGGCAATGCAAGTCTGGAGTGAAAACCCAGGGCTCAACCCTGGGAGTGCTTTGGAAACTGTATAGCTAGAGTGCTGGAGAGGTAAGTGGAATTCCTAGTGTAGCGGTGAAATGCGTAGATATTAGGAGGAACACCAGTGGCGAAGGCGGCTTACTGGACAGTAACTGACGTTGAGGCTCGAAAGCGTGGGGAGCAAACAGGATTAGATACCCTGGTAGTCCACGCCGTAAACGATGAATGCTAGGTGTTGGGGGGCAAAGCCCTTCGGTGCCGTCGCAAACGCAATAAGCATTCCACCTGGGGAGTACGTTCGCAAGAATGAAACTCAAAGGAATTGACGGGGACCCGCACAAGCGGTGGAGCATGTGGTTTAATTCGAAGCAACGCGAAGAACCTTACCAAGTCTTGACATCCTCCTGACCGGTCCGTAACGGGGCCTTTCCTTCGGGACAAGAGAGACAGGTGGTGCATGGTTGTCGTCAGCTCGTGTCGTGAGATGTTGGGTTAAGTCCCGCAACGAGCGCAACCCTTATCCTTAGTAGCCAGCAGGTAGAGCTGGGCACTCTAGGGAGACTGCCAGGGATAACCTGGAGGAAGGTGGGGATGACGTCAAATCATCATGCCCCTTATGATTTGGGCTACACACGTGCTACAATGGCGTAAACAAAGGGAGGCGACCCTGCGAAGGCAAGCAAATCCCAAAAATAACGTCCCAGTTCGGACTGTAGTCTGCAACCCGACTACACGAAGCTGGAATCGCTAGTAATCGCGAATCAGAATGTCGCGGTGAATACGTTCCCGGGTCTTGTACACACCGCCCGTCACACCATGGGAGTCAGCAACGCCCGAAGTCAGTGACCCAACTGCAGGAGAGGGAGCGCCGAAGTCGGGCT
序列表
<110> 國立研究開發法人理化學研究所(RIKEN)
國立大學法人東京大學(THE UNIVERSITY OF TOKYO)
學校法人麻布獸醫學園(SCHOOL CORPORATION, AZABU VETERINARY MEDICINE EDUCATIONAL
INSTITUTION)
<120> 用于誘導TH17細胞的組合物及方法
<130> 092332
<150> US 61/978,182
<151> 2014-04-10
<160> 26
<170> PatentIn版本3.5
<210> 1
<211> 1419
<212> DNA
<213> 多枝梭菌(Clostridium ramosum)
<400> 1
ggggcggctg ctataatgca gtcgacgcga gcacttgtgc tcgagtggcg aacgggtgag 60
taatacataa gtaacctgcc ctagacaggg ggataactat tggaaacgat agctaagacc 120
gcatatgtac ggacactgca tggtgaccgt attaaaagtg cctcaaagca ctggtagagg 180
atggacttat ggcgcattag ctggttggcg gggtaacggc ccaccaaggc gacgatgcgt 240
agccgacctg agagggtgac cggccacact gggactgaga cacggcccag actcctacgg 300
gaggcagcag tagggaattt tcggcaatgg gggaaaccct gaccgagcaa cgccgcgtga 360
aggaagaagg ttttcggatt gtaaacttct gttataaagg aagaacggcg gctacaggaa 420
atggtagccg agtgacggta ctttattaga aagccacggc taactacgtg ccagcagccg 480
cggtaatacg taggtggcaa gcgttatccg gaattattgg gcgtaaagag ggagcaggcg 540
gcagcaaggg tctgtggtga aagcctgaag cttaacttca gtaagccata gaaaccaggc 600
agctagagtg caggagagga tcgtggaatt ccatgtgtag cggtgaaatg cgtagatata 660
tggaggaaca ccagtggcga aggcgacgat ctggcctgca actgacgctc agtcccgaaa 720
gcgtggggag caaataggat tagataccct agtagtccac gccgtaaacg atgagtacta 780
agtgttggat gtcaaagttc agtgctgcag ttaacgcaat aagtactccg cctgagtagt 840
acgttcgcaa gaatgaaact caaaggaatt gacgggggcc cgcacaagcg gtggagcatg 900
tggtttaatt cgaagcaacg cgaagaacct taccaggtct tgacatactc ataaaggctc 960
cagagatgga gagatagcta tatgagatac aggtggtgca tggttgtcgt cagctcgtgt 1020
cgtgagatgt tgggttaagt cccgcaacga gcgcaaccct tatcgttagt taccatcatt 1080
aagttgggga ctctagcgag actgccagtg acaagctgga ggaaggcggg gatgacgtca 1140
aatcatcatg ccccttatga cctgggctac acacgtgcta caatggatgg tgcagaggga 1200
agcgaagccg cgaggtgaag caaaacccat aaaaccattc tcagttcgga ttgtagtctg 1260
caactcgact acatgaagtt ggaatcgcta gtaatcgcga atcagcatgt cgcggtgaat 1320
acgttctcgg gccttgtaca caccgcccgt cacaccacga gagttgataa cacccgaagc 1380
cggtggccta accgcaagga aggagcttct aaggtggat 1419
<210> 2
<211> 1433
<212> DNA
<213> 假長雙歧桿菌假長亞種(Bifidobacterium pseudolongum subsp. Pseudolongum)
<400> 2
ctgcggcgtc taccatgcag tcgaacggga tccctggcag cttgctgccg gggtgagagt 60
ggcgaacggg tgagtaatgc gtgaccgacc tgccccatgc accggaatag ctcctggaaa 120
cgggtggtaa tgccggatgt tccacatgag cgcatgcgag tgtgggaaag gctttttgcg 180
gcatgggatg gggtcgcgtc ctatcagctt gttggtgggg taacggccta ccaaggcgtt 240
gacgggtagc cggcctgaga gggcgaccgg ccacattggg actgagatac ggcccagact 300
cctacgggag gcagcagtgg ggaatattgc acaatgggcg caagcctgat gcagcgacgc 360
cgcgtgcggg atggaggcct tcgggttgta aaccgctttt gttcaagggc aaggcacggt 420
ctttggccgt gttgagtgga ttgttcgaat aagcaccggc taactacgtg ccagcagccg 480
cggtaatacg tagggtgcaa gcgttatccg gatttattgg gcgtaaaggg ctcgtaggcg 540
gttcgtcgcg tccggtgtga aagtccatcg cttaacggtg gatccgcgcc gggtacgggc 600
gggcttgagt gcggtagggg agactggaat tcccggtgta acggtggaat gtgtagatat 660
cgggaagaac accaatggcg aaggcaggtc tctgggccgt tactgacgct gaggagcgaa 720
agcgtgggga gcgaacagga ttagataccc tggtagtcca cgccgtaaac ggtggatgct 780
ggatgtgggg ccctttttcc gggtcctgtg tcggagctaa cgcgttaagc atcccgcctg 840
gggagtacgg ccgcaaggct aaaactcaaa gaaattgacg ggggcccgca caagcggcgg 900
agcatgcgga ttaattcgat gcaacgcgaa gaaccttacc tgggcttgac atgtgccgga 960
cgcccgcgga gacgcgggtt cccttcgggg ccggttcaca ggtggtgcat ggtcgtcgtc 1020
agctcgtgtc gtgagatgtt gggttaagtc ccgcaacgag cgcaaccctc gccgcgtgtt 1080
gccagcgggt catgccggga actcacgtgg gaccgccggg gttaactcgg aggaaggtgg 1140
ggatgacgtc agatcatcat gccccttacg tccagggctt cacgcatgct acaatggccg 1200
gtacaacggg gtgcgacacg gtgacgtggg gcggatccct gaaaaccggt ctcagttcgg 1260
atcgcagtct gcaactcgac tgcgtgaagg tggagtcgct agtaatcgcg gatcagcaac 1320
gccgcggtga atgcgttccc gggccttgta cacaccgccc gtcaagtcat gaaagtgggc 1380
agcacccgaa gacggtggcc taacccttgt ggggggagcc gtctaaggta gtg 1433
<210> 3
<211> 1428
<212> DNA
<213> 乳酸發酵梭菌(Clostridium lactatifermentans)
<400> 3
ctgccggctc taccatgcag tcgaacgaag atagttagaa tgagagcttc ggcaggattt 60
ttttctatct tagtggcgga cgggtgagta acgtgtgggc aacctgccct gtactgggga 120
ataatcattg gaaacgatga ctaataccgc atgtggtcct cggaaggcat cttctgagga 180
agaaaggatt tattcggtac aggatgggcc cgcatctgat tagctagttg gtgagataac 240
agcccaccaa ggcgacgatc agtagccgac ctgagagggt gatcggccac attgggactg 300
agacacggcc caaactccta cgggaggcag cagtggggaa tattgcacaa tgggcgaaag 360
cctgatgcag caacgccgcg tgaaggatga agggtttcgg ctcgtaaact tctatcaata 420
gggaagaaac aaatgacggt acctaaataa gaagccccgg ctaactacgt gccagcagcc 480
gcggtaatac gtagggggca agcgttatcc ggaattactg ggtgtaaagg gagcgtaggc 540
ggcatggtaa gccagatgtg aaagccttgg gcttaacccg aggattgcat ttggaactat 600
caagctagag tacaggagag gaaagcggaa ttcctagtgt agcggtgaaa tgcgtagata 660
ttaggaagaa caccagtggc gaaggcggct ttctggactg aaactgacgc tgaggctcga 720
aagcgtgggg agcaaacagg attagatacc ctggtagtcc acgccgtaaa cgatgagtgc 780
taggtgtcgg ggaggaatcc tcggtgccgc agctaacgca ataagcactc cacctgggga 840
gtacgaccgc aaggttgaaa ctcaaaggaa ttgacggggg cccgcacaag cggtggagca 900
tgtggtttaa ttcgaagcaa cgcgaagaac cttaccaagg cttgacatcc cgatgaccgt 960
cctagagata ggacttctct tcggagcatc ggtgacaggt ggtgcatggt tgtcgtcagc 1020
tcgtgtcgtg agatgttggg ttaagtcccg caacgagcgc aacccttatc ttcagtagcc 1080
atcattcagt tgggcactct ggagagactg ccgtggataa cacggaggaa ggtggggatg 1140
acgtcaaatc atcatgcccc ttatgtcttg ggctacacac gtgctacaat ggctggtaac 1200
aaagtgacgc gagacggcga cgttaagcaa atcacaaaaa cccagtccca gttcggattg 1260
tagtctgcaa ctcgactaca tgaagctgga atcgctagta atcgcgaatc agcatgtcgc 1320
ggtgaatacg ttcccgggcc ttgtacacac cgcccgtcac accatgggag ttggaagcac 1380
ccgaagtcgg tgacctaacc gtaaggaaga gccgccgaag taggggat 1428
<210> 4
<211> 1422
<212> DNA
<213> 布勞特氏菌屬菌種犬口類143 (Blautia sp. canine oral taxon 143)
<400> 4
cggcgctcta ccatgcagtc gacgaagcga tttgaatgaa gttttcggat ggattttaaa 60
ttgactgagt ggcggacggg tgagtaacgc gtgggtaacc tgccccatac agggggataa 120
cagttagaaa tgactgctaa taccgcataa gaccacagcg ccgcatggtg caggggtaaa 180
aactccggtg gtatgggatg gacccgcgtc tgattagctt gttggcgggg taacggccca 240
ccaaggcgac gatcagtagc cgacctgaga gggtgaccgg ccacattggg actgagacac 300
ggcccaaact cctacgggag gcagcagtgg ggaatattgc acaatggggg aaaccctgat 360
gcagcgacgc cgcgtgagtg atgaagtatt tcggtatgta aagctctatc agcagggaag 420
aaaatgacgg tacctgacta agaagccccg gctaactacg tgccagcagc cgcggtaata 480
cgtagggggc aagcgttatc cggatttact gggtgtaaag ggagcgtaga cggctgtgca 540
agtctggagt gaaagcccgg ggctcaaccc cgggactgct ttggaaactg tacggctgga 600
gtgctggaga ggcaagcgga attcctagtg tagcggtgaa atgcgtagat attaggagga 660
acaccagtgg cgaaggcggc ttgctggaca gtaactgacg ttgaggctcg aaagcgtggg 720
gagcaaacag gattagatac cctggtagtc cacgccgtaa acgatgaatg ctaggtgtcg 780
gggagcaaag ctcttcggtg ccgccgcaaa cgcaataagc attccacctg gggagtacgt 840
tcgcaagaat gaaactcaaa ggaattgacg gggacccgca caagcggtgg agcatgtggt 900
ttaattcgaa gcaacgcgaa gaaccttacc aagtcttgac atccccctga ccggcaagta 960
atgtcgcctt tccttcggga caggggagac aggtggtgca tggttgtcgt cagctcgtgt 1020
cgtgagatgt tgggttaagt cccgcaacga gcgcaaccct tatcctcagt agccagcagg 1080
tgaagctggg cactctgtgg agactgccag ggataacctg gaggaaggtg gggacgacgt 1140
caaatcatca tgccccttat gacttgggct acacacgtgc tacaatggcg taaacaaagg 1200
gaagcgagag ggtgacctgg agcaaatccc aaaaataacg tctcagttcg gattgtagtc 1260
tgcaactcga ctacatgaag ctggaatcgc tagtaatcgc gaatcagcat gtcgcggtga 1320
atacgttccc gggtcttgta cacaccgccc gtcacaccat gggagtcagc aacgcccgaa 1380
gccggtgacc taaccgcaag gaaggagccg tcgaagtcgt cg 1422
<210> 5
<211> 1425
<212> DNA
<213> 參見梭菌屬菌種MLG055 (cf. Clostridium sp. MLG055)
<400> 5
cggcgctgct atactgcagt cgaacgaagc gaaggtagct tgctatcgga gcttagtggc 60
gaacgggtga gtaacacgta gataacctgc ctgtatgacc gggataacag ttggaaacga 120
ctgctaatac cggataggca gagaggaggc atctcttctc tgttaaagtt gggatacaac 180
gcaaacagat ggatctgcgg tgcattagct agttggtgag gtaacggccc accaaggcga 240
tgatgcatag ccggcctgag agggcgaacg gccacattgg gactgagaca cggcccaaac 300
tcctacggga ggcagcagta gggaattttc ggcaatgggg gaaaccctga ccgagcaatg 360
ccgcgtgagt gaagacggcc ttcgggttgt aaagctctgt tgtaagggaa gaacggcata 420
gagagggaat gctctatgag tgacggtacc ttaccagaaa gccacggcta actacgtgcc 480
agcagccgcg gtaatacgta ggtggcaagc gttatccgga attattgggc gtaaagggtg 540
cgtaggcggc tggataagtc tgaggtaaaa gcccgtggct caaccacggt aagccttgga 600
aactgtctgg ctggagtgca ggagaggaca atggaattcc atgtgtagcg gtaaaatgcg 660
tagatatatg gaggaacacc agtggcgaag gcggttgtct ggcctgtaac tgacgctgaa 720
gcacgaaagc gtggggagca aataggatta gataccctag tagtccacgc cgtaaacgat 780
gagaactaag tgttggggaa actcagtgct gcagttaacg caataagttc tccgcctggg 840
gagtatgcac gcaagtgtga aactcaaagg aattgacggg ggcccgcaca agcggtggag 900
tatgtggttt aattcgacgc aacgcgaaga accttaccag gccttgacat ggtatcaaag 960
gccctagaga tagggagata ggtatgatac acacaggtgg tgcatggttg tcgtcagctc 1020
gtgtcgtgag atgttgggtt aagtcccgca acgagcgcaa cccttgtttc tagttaccaa 1080
cagtaagatg gggactctag agagactgcc ggtgacaaac cggaggaagg tggggatgac 1140
gtcaaatcat catgcccctt atggcctggg ctacacacgt actacaatgg cgtctacaaa 1200
gagcagcgag caggtgactg taagcgaatc tcataaagga cgtctcagtt cggattgaag 1260
tctgcaactc gacttcatga agtcggaatc gctagtaatc gcggatcagc atgccgcggt 1320
gaatacgttc tcgggccttg tacacaccgc ccgtcaaacc atgggagttg ataatacccg 1380
aagccggtgg cctaaccgaa aggagggagc cgtcgaagta gattg 1425
<210> 6
<211> 1431
<212> DNA
<213> 無害梭菌(Clostridium innocuum)
<400> 6
cggcgctgct ataatgcagt cgaacgaagt ttcgaggaag cttgcttcca aagagactta 60
gtggcgaacg ggtgagtaac acgtaggtaa cctgcccatg tgtccgggat aactgctgga 120
aacggtagct aaaaccggat aggtatacag agcgcatgct cagtatatta aagcgcccat 180
caaggcgtga acatggatgg acctgcggcg cattagctag ttggtgaggt aacggcccac 240
caaggcgatg atgcgtagcc ggcctgagag ggtaaacggc cacattggga ctgagacacg 300
gcccaaactc ctacgggagg cagcagtagg gaattttcgt caatggggga aaccctgaac 360
gagcaatgcc gcgtgagtga agaaggtctt cggatcgtaa agctctgttg taagtgaaga 420
acggctcata gaggaaatgc tatgggagtg acggtagctt accagaaagc cacggctaac 480
tacgtgccag cagccgcggt aatacgtagg tggcaagcgt tatccggaat cattgggcgt 540
aaagggtgcg taggtggcgt actaagtctg tagtaaaagg caatggctca accattgtaa 600
gctatggaaa ctggtatgct ggagtgcaga agagggcgat ggaattccat gtgtagcggt 660
aaaatgcgta gatatatgga ggaacaccag tggcgaaggc ggtcgcctgg tctgtaactg 720
acactgaggc acgaaagcgt ggggagcaaa taggattaga taccctagta gtccacgccg 780
taaacgatga gaactaagtg ttggaggaat tcagtgctgc agttaacgca ataagttctc 840
cgcctgggga gtatgcacgc aagtgtgaaa ctcaaaggaa ttgacggggg cccgcacaag 900
cggtggagta tgtggtttaa ttcgaagcaa cgcgaagaac cttaccaggc cttgacatgg 960
atgcaaatgc cctagagata gagagataat tatggatcac acaggtggtg catggttgtc 1020
gtcagctcgt gtcgtgagat gttgggttaa gtcccgcaac gagcgcaacc cttgtcgcat 1080
gttaccagca tcaagttggg gactcatgcg agactgccgg tgacaaaccg gaggaaggtg 1140
gggatgacgt caaatcatca tgccccttat ggcctgggct acacacgtac tacaatggcg 1200
accacaaaga gcagcgacac agtgatgtga agcgaatctc ataaaggtcg tctcagttcg 1260
gattgaagtc tgcaactcga cttcatgaag tcggaatcgc tagtaatcgc agatcagcat 1320
gctgcggtga atacgttctc gggccttgta cacaccgccc gtcaaaccat gggagtcagt 1380
aatacccgaa gccggtggca taaccgtaag gaggagccgt cgaagtgact g 1431
<210> 7
<211> 1428
<212> DNA
<213> 圓環梭菌(Clostridium orbiscindens)
<400> 7
agggcggctc ttaaatgcag tcgaacgggg tgctcatgac ggaggattcg tccaacggat 60
tgagttacct agtggcggac gggtgagtaa cgcgtgagga acctgccttg gagaggggaa 120
taacactccg aaaggagtgc taataccgca tgatgcagtt gggtcgcatg gctctgactg 180
ccaaagattt atcgctctga gatggcctcg cgtctgatta gctagtaggc ggggtaacgg 240
cccacctagg cgacgatcag tagccggact gagaggttga ccggccacat tgggactgag 300
acacggccca gactcctacg ggaggcagca gtggggaata ttgggcaatg ggcgcaagcc 360
tgacccagca acgccgcgtg aaggaagaag gctttcgggt tgtaaacttc ttttgtcggg 420
gacgaaacaa atgacggtac ccgacgaata agccacggct aactacgtgc cagcagccgc 480
ggtaatacgt aggtggcaag cgttatccgg atttactggg tgtaaagggc gtgtaggcgg 540
gattgcaagt cagatgtgaa aactgggggc tcaacctcca gcctgcattt gaaactgtag 600
ttcttgagtg ctggagaggc aatcggaatt ccgtgtgtag cggtgaaatg cgtagatata 660
cggaggaaca ccagtggcga aggcggattg ctggacagta actgacgctg aggcgcgaaa 720
gcgtggggag caaacaggat tagataccct ggtagtccac gccgtaaacg atggatacta 780
ggtgtggggg gtctgacccc ctccgtgccg cagttaacac aataagtatc ccacctgggg 840
agtacgatcg caaggttgaa actcaaagga attgacgggg gcccgcacaa gcggtggagt 900
atgtggttta attcgaagca acgcgaagaa ccttaccagg gcttgacatc ccactaacga 960
ggcagagatg cgttaggtgc ccttcgggga aagtggagac aggtggtgca tggttgtcgt 1020
cagctcgtgt cgtgagatgt tgggttaagt cccgcaacga gcgcaaccct tattgttagt 1080
tgctacgcaa gagcactcta gcgagactgc cgttgacaaa acggaggaag gtggggacga 1140
cgtcaaatca tcatgcccct tatgtcctgg gccacacacg tactacaatg gtggttaaca 1200
gagggaggca ataccgcgag gtggagcaaa tccctaaaag ccatcccagt tcggattgca 1260
ggctgaaacc cgcctgtatg aagttggaat cgctagtaat cgcggatcag catgccgcgg 1320
tgaatacgtt cccgggcctt gtacacaccg cccgtcacac catgagagtc gggaacaccc 1380
gaagtccgta gcctaaccgc aaggagggcg cggccgaaag ttgttcat 1428
<210> 8
<211> 1409
<212> DNA
<213> 瘤胃球菌屬菌種16442 (Ruminococcus sp. 16442)
<400> 8
cgggggctgc taccatgcag tcgaacggag ttaagagagc ttgctctttt aacttagtgg 60
cggacgggtg agtaacgcgt gagtaacctg cctttcagag gggaataaca ttctgaaaag 120
aatgctaata ccgcatgaga tcgtagtatc gcatggtaca gcgaccaaag gagcaatccg 180
ctgaaagatg gactcgcgtc cgattagcta gttggtgaga taaaggccca ccaaggcgac 240
gatcggtagc cggactgaga ggttgaacgg ccacattggg actgagacac ggcccagact 300
cctacgggag gcagcagtgg gggatattgc acaatggggg aaaccctgat gcagcaacgc 360
cgcgtgaagg aagaaggtct tcggattgta aacttctgtc ctcagggaag ataatgacgg 420
tacctgagga ggaagctccg gctaactacg tgccagcagc cgcggtaata cgtagggagc 480
aagcgttgtc cggatttact gggtgtaaag ggtgcgtagg cggatctgca agtcagtagt 540
gaaatcccag ggcttaaccc tggaactgct attgaaactg tgggtcttga gtgaggtaga 600
ggcaggcgga attcccggtg tagcggtgaa atgcgtagag atcgggagga acaccagtgg 660
cgaaggcggc ctgctgggcc ttaactgacg ctgaggcacg aaagcatggg tagcaaacag 720
gattagatac cctggtagtc catgccgtaa acgatgatta ctaggtgtgg gtggtctgac 780
cccatccgtg ccggagttaa cacaataagt aatccacctg gggagtacgg ccgcaaggtt 840
gaaactcaaa ggaattgacg ggggcccgca caagcagtgg agtatgtggt ttaattcgaa 900
gcaacgcgaa gaaccttacc aggtcttgac atcctgctaa cgaggtagag atacgttagg 960
tgcccttcgg ggaaagcaga gacaggtggt gcatggttgt cgtcagctcg tgtcgtgaga 1020
tgttgggtta agtcccgcaa cgagcgcaac ccctgctatt agttgctacg caagagcact 1080
ctaataggac tgccgttgac aaaacggagg aaggtgggga cgacgtcaaa tcatcatgcc 1140
ccttatgacc tgggctacac acgtactaca atggccgtca acagagagaa gcaaagccgc 1200
gaggtggagc aaaactctaa aaacggtccc agttcggatc gtaggctgca acccgcctac 1260
gtgaagttgg aattgctagt aatcgcggat catcatgccg cggtgaatac gttcccgggc 1320
cttgtacaca ccgcccgtca caccatggga gccggtaata cccgaagtca gtagtctaac 1380
cgcaagggga cgcgccgaaa ggtggagtg 1409
<210> 9
<211> 1426
<212> DNA
<213> 活潑瘤胃球菌(Ruminococcus gnavus)
<400> 9
ctggcgggtg ctaccatgca gtcgagcgaa gcacttttgc ggatttcttc ggattgaagc 60
aattgtgact gagcggcgga cgggtgagta acgcgtgggt aacctgcctc atacaggggg 120
ataacagttg gaaacggctg ctaataccgc ataagcgcac agtaccgcat ggtaccgtgt 180
gaaaaactcc ggtggtatga gatggacccg cgtctgatta gctagttggt ggggtaacgg 240
cctaccaagg cgacgatcag tagccgacct gagagggtga ccggccacat tgggactgag 300
acacggccca aactcctacg ggaggcagca gtggggaata ttgcacaatg ggggaaaccc 360
tgatgcagcg acgccgcgtg agcgatgaag tatttcggta tgtaaagctc tatcagcagg 420
gaagaaaatg acggtacctg actaagaagc cccggctaac tacgtgccag cagccgcggt 480
aatacgtagg gggcaagcgt tatccggatt tactgggtgt aaagggagcg tagacggcat 540
ggcaagccag atgtgaaagc ccggggctca accccgggac tgcatttgga actgtcaggc 600
tagagtgtcg gagaggaaag cggaattcct agtgtagcgg tgaaatgcgt agatattagg 660
aggaacacca gtggcgaagg cggctttctg gacgatgact gacgttgagg ctcgaaagcg 720
tggggagcaa acaggattag ataccctggt agtccacgcc gtaaacgatg aatactaggt 780
gtcgggtggc aaagccattc ggtgccgcag caaacgcaat aagtattcca cctggggagt 840
acgttcgcaa gaatgaaact caaaggaatt gacggggacc cgcacaagcg gtggagcatg 900
tggtttaatt ggaagcaacg cgaagaacct tacctggtct tgacatccct ctgaccgctc 960
tttaatcgga gttttctttc gggacagagg agacaggtgg tgcatggttg tcgtcagctc 1020
gtgtcgtgag atgttgggtt aagtcccgca acgagcgcaa cccctatctt tagtagccag 1080
catttagggt gggcactcta gagagactgc cagggataac ctggaggaag gtggggatga 1140
cgtcaaatca tcatgcccct tatgaccagg gctacacacg tgctacaatg gcgtaaacaa 1200
agggaagcga gcccgcgagg gggagcaaat cccaaaaata acgtctcagt tcggattgta 1260
gtctgcaact cgactacatg aagctggaat cgctagtaat cgcgaatcag aatgtcgcgg 1320
tgaatacgtt cccgggtctt gtacacaccg cccgtcacac catgggagtc agtaacgccc 1380
gaagtcagtg acccaaccgt aaggaggagc tgccgaagtg tactat 1426
<210> 10
<211> 1407
<212> DNA
<213> 人腸道厭氧棒狀菌(Anaerotruncus colihominis)
<400> 10
gagtgggccg ctaccatgca gtcgacgagc cgaggggagc ttgctcccca gagctagtgg 60
cggacgggtg agtaacacgt gagcaacctg cctttcagag ggggataacg tttggaaacg 120
aacgctaata ccgcataaca taccgggacc gcatgattct ggtatcaaag gagcaatccg 180
ctgaaagatg ggctcgcgtc cgattagcta gttggcgggg taacggccca ccaaggcgac 240
gatcggtagc cggactgaga ggttgatcgg ccacattggg actgagacac ggcccagact 300
cctacgggag gcagcagtgg gggatattgc acaatggagg aaactctgat gcagcgacgc 360
cgcgtgaggg aagacggtct tcggattgta aacctctgtc tttggggacg ataatgacgg 420
tacccaagga ggaagctccg gctaactacg tgccagcagc cgcggtaata cgtagggagc 480
gagcgttgtc cggaattact gggtgtaaag ggagcgtagg cggggtctca agtcgaatgt 540
taaatctacc ggctcaactg gtagctgcgt tcgaaactgg ggctcttgag tgaagtagag 600
gcaggcggaa ttcctagtgt agcggtgaaa tgcgtagata ttaggaggaa caccagtggc 660
gaaggcggcc tgctgggctt ttactgacgc tgaggctcga aagcgtgggg agcaaacagg 720
attagatacc ctggtagtcc acgccgtaaa cgatgattac taggtgtggg gggactgacc 780
ccttccgtgc cggagttaac acaataagta atccacctgg ggagtacgac cgcaaggttg 840
aaactcaaag gaattgacgg gggcccgcac aagcagtgga ttatgtggtt taattcgaag 900
caacgcgaag aaccttacca ggtcttgaca tcgagtgacg gctctagaga tagagctttc 960
cttcgggaca caaagacagg tggtgcatgg ttgtcgtcag ctcgtgtcgt gagatgttgg 1020
gttaagtccc gcaacgagcg caacccttat tattagttgc tacattcagt tgagcactct 1080
aatgagactg ccgttgacaa aacggaggaa ggtggggatg acgtcaaatc atcatgcccc 1140
ttatgacctg ggctacacac gtaatacaat ggcgatcaac agagggaagc aagaccgcga 1200
ggtggagcaa acccctaaaa gtcgtctcag ttcggattgc aggctgcaac tcgcctgcat 1260
gaagtcggaa ttgctagtaa tcgcggatca gcatgccgcg gtgaatacgt tcccgggcct 1320
tgtacacacc gcccgtcaca ccatgggagt cggtaacacc cgaagtcagt agcctaaccg 1380
caaagagggc gctgccgaag atggatt 1407
<210> 11
<211> 1419
<212> DNA
<213> 鏈狀真桿菌(Eubacterium desmolans)
<400> 11
atggcggctg ctacctgcag tcgaacgggg ttattttgga aatctcttcg gagatggaat 60
tcttaaccta gtggcggacg ggtgagtaac gcgtgagcaa tctgccttta ggagggggat 120
aacagtcgga aacggctgct aataccgcat aatacgtttg ggaggcatct cttgaacgtc 180
aaagatttta tcgcctttag atgagctcgc gtctgattag ctggttggcg gggtaacggc 240
ccaccaaggc gacgatcagt agccggactg agaggttgaa cggccacatt gggactgaga 300
cacggcccag actcctacgg gaggcagcag tggggaatat tgcgcaatgg gggaaaccct 360
gacgcagcaa cgccgcgtga ttgaagaagg ccttcgggtt gtaaagatct ttaatcaggg 420
acgaaaaatg acggtacctg aagaataagc tccggctaac tacgtgccag cagccgcggt 480
aatacgtagg gagcaagcgt tatccggatt tactgggtgt aaagggcgcg caggcgggcc 540
ggcaagttgg gagtgaaatc ccggggctta accccggaac tgctttcaaa actgctggtc 600
ttgagtgatg gagaggcagg cggaattccg tgtgtagcgg tgaaatgcgt agatatacgg 660
aggaacacca gtggcgaagg cggcctgctg gacattaact gacgctgagg cgcgaaagcg 720
tggggagcaa acaggattag ataccctggt agtccacgcc gtaaacgatg gatactaggt 780
gtgggaggta ttgacccctt ccgtgccgca gttaacacaa taagtatccc acctggggag 840
tacggccgca aggttgaaac tcaaaggaat tgacgggggc ccgcacaagc agtggagtat 900
gtggtttaat tcgaagcaac gcgaagaacc ttaccaggtc ttgacatccc gatgaccggc 960
gtagagatac gccctctctt cggagcatcg gtgacaggtg gtgcatggtt gtcgtcagct 1020
cgtgtcgtga gatgttgggt taagtcccgc aacgagcgca acccttacgg ttagttgata 1080
cgcaagatca ctctagccgg actgccgttg acaaaacgga ggaaggtggg gacgacgtca 1140
aatcatcatg ccccttatga cctgggctac acacgtacta caatggcagt catacagagg 1200
gaagcaatac cgcgaggtgg agcaaatccc taaaagctgt cccagttcag attgcaggct 1260
gcaacccgcc tgcatgaagt cggaattgct agtaatcgcg gatcagcatg ccgcggtgaa 1320
tacgttcccg ggccttgtac acaccgcccg tcacaccatg agagccgtca atacccgaag 1380
tccgtagcct aaccgcaagg gggcgcgccg aagttacgt 1419
<210> 12
<211> 1423
<212> DNA
<213> 哈氏梭菌(Clostridium hathewayi)
<400> 12
atcgggtgct acctgcaagt cgagcgaagc ggtttcgatg aagttttcgg atggaattga 60
aattgactta gcggcggacg ggtgagtaac gcgtgggtaa cctgccttac actgggggat 120
aacagttaga aatgactgct aataccgcat aagcgcacag ggccgcatgg tctggtgcga 180
aaaactccgg tggtgtaaga tggacccgcg tctgattagg tagttggtgg ggtaacggcc 240
caccaagccg acgatcagta gccgacctga gagggtgacc ggccacattg ggactgagac 300
acggcccaaa ctcctacggg aggcagcagt ggggaatatt ggacaatggg cgaaagcctg 360
atccagcgac gccgcgtgag tgaagaagta tttcggtatg taaagctcta tcagcaggga 420
agaaaatgac ggtacctgac taagaagccc cggctaacta cgtgccagca gccgcggtaa 480
tacgtagggg gcaagcgtta tccggattta ctgggtgtaa agggagcgta gacggttaag 540
caagtctgaa gtgaaagccc ggggctcaac cccggtactg ctttggaaac tgtttgactt 600
gagtgcagga gaggtaagtg gaattcctag tgtagcggtg aaatgcgtag atattaggag 660
gaacaccagt ggcgaaggcg gcttactgga ctgtaactga cgttgaggct cgaaagcgtg 720
gggagcaaac aggattagat accctggtag tccacgccgt aaacgatgaa tactaggtgt 780
cgggggacaa cgtccttcgg tgccgccgct aacgcaataa gtattccacc tggggagtac 840
gttcgcaaga atgaaactca aaggaattga cggggacccg cacaagcggt ggagcatgtg 900
gtttaattcg aagcaacgcg aagaacctta ccaagtcttg acatcccatt gaaaatcctt 960
taaccgtggt ccctcttcgg agcaatggag acaggtggtg catggttgtc gtcagctcgt 1020
gtcgtgagat gttgggttaa gtcccgcaac gagcgcaacc cttatcctta gtagccagca 1080
catgatggtg ggcactctgg ggagactgcc agggataacc tggaggaagg tggggatgac 1140
gtcaaatcat catgcccctt atgatttggg ctacacacgt gctacaatgg cgtaaacaaa 1200
gggaagcaaa ggagcgatct ggagcaaacc ccaaaaataa cgtctcagtt cggattgcag 1260
gctgcaactc gcctgcatga agctggaatc gctagtaatc gcgaatcaga atgtcgcggt 1320
gaatacgttc ccgggtcttg tacacaccgc ccgtcacacc atgggagttg gtaacgcccg 1380
aagtcagtga cccaaccgta aggaggagcg ccgaaggcga ggt 1423
<210> 13
<211> 1423
<212> DNA
<213> 短雙歧桿菌(Bifidobacterium breve)
<400> 13
cggggctgct taaatgcagt cgaacgggat ccatcaagct tgcttggtgg tgagagtggc 60
gaacgggtga gtaatgcgtg accgacctgc cccatgcacc ggaatagctc ctggaaacgg 120
gtggtaatgc cggatgctcc atcacactgc atggtgtgtt gggaaagcct ttgcggcatg 180
ggatggggtc gcgtcctatc agcttgatgg cggggtaacg gcccaccatg gcttcgacgg 240
gtagccggcc tgagagggcg accggccaca ttgggactga gatacggccc agactcctac 300
gggaggcagc agtggggaat attgcacaat gggcgcaagc ctgatgcagc gacgccgcgt 360
gagggatgga ggccttcggg ttgtaaacct cttttgttag ggagcaaggc attttgtgtt 420
gagtgtacct ttcgaataag caccggctaa ctacgtgcca gcagccgcgg taatacgtag 480
ggtgcaagcg ttatccggaa ttattgggcg taaagggctc gtaggcggtt cgtcgcgtcc 540
ggtgtgaaag tccatcgctt aacggtggat ccgcgccggg tacgggcggg cttgagtgcg 600
gtaggggaga ctggaattcc cggtgtaacg gtggaatgtg tagatatcgg gaagaacacc 660
aatggcgaag gcaggtctct gggccgttac tgacgctgag gagcgaaagc gtggggagcg 720
aacaggatta gataccctgg tagtccacgc cgtaaacggt ggatgctgga tgtggggccc 780
gttccacggg ttccgtgtcg gagctaacgc gttaagcatc ccgcctgggg agtacggccg 840
caaggctaaa actcaaagaa attgacgggg gcccgcacaa gcggcggagc atgcggatta 900
attcgatgca acgcgaagaa ccttacctgg gcttgacatg ttcccgacga tcccagagat 960
ggggtttccc ttcggggcgg gttcacaggt ggtgcatggt cgtcgtcagc tcgtgtcgtg 1020
agatgttggg ttaagtcccg caacgagcgc aaccctcgcc ccgtgttgcc agcggattgt 1080
gccgggaact cacgggggac cgccggggtt aactcggagg aaggtgggga tgacgtcaga 1140
tcatcatgcc ccttacgtcc agggcttcac gcatgctaca atggccggta caacgggatg 1200
cgacagcgcg agctggagcg gatccctgaa aaccggtctc agttcggatc gcagtctgca 1260
actcgactgc gtgaaggcgg agtcgctagt aatcgcgaat cagcaacgtc gcggtgaatg 1320
cgttcccggg ccttgtacac accgcccgtc aagtcatgaa agtgggcagc acccgaagcc 1380
ggtggcctaa ccccttgcgg gagggagccg tctaaggtag gtt 1423
<210> 14
<211> 1425
<212> DNA
<213> 瘤胃球菌屬菌種M-1(Ruminococcus sp. M-1)
<400> 14
cgggcgctgc ttacctgcag tcgagcgaag cacttgagcg gatttcttcg gattgaagtt 60
tttttgactg agcggcggac gggtgagtaa cgcgtgggta acctgcctca tacaggggga 120
taacagttag aaatggctgc taataccgca taagcgcaca ggaccgcatg gtctggtgtg 180
aaaaactccg gtggtatgag atggacccgc gtctgattag ctagttggag gggtaacggc 240
ccaccaaggc gacgatcagt agccggcctg agagggtgaa cggccacatt gggactgaga 300
cacggcccag actcctacgg gaggcagcag tggggaatat tgcacaatgg gggaaaccct 360
gatgcagcga cgccgcgtga aggaagaagt atctcggtat gtaaacttct atcagcaggg 420
aagaaaatga cggtacctga ctaagaagcc ccggctaact acgtgccagc agccgcggta 480
atacgtaggg ggcaagcgtt atccggattt actgggtgta aagggagcgt agacggaaga 540
gcaagtctga tgtgaaaggc tggggcttaa ccccaggact gcattggaaa ctgtttttct 600
agagtgccgg agaggtaagc ggaattccta gtgtagcggt gaaatgcgta gatattagga 660
ggaacaccag tggcgaaggc ggcttactgg acggtaactg acgttgaggc tcgaaagcgt 720
ggggagcaaa caggattaga taccctggta gtccacgccg taaacgatga atactaggtg 780
tcgggtggca aagccattcg gtgccgcagc aaacgcaata agtattccac ctggggagta 840
cgttcgcaag aatgaaactc aaaggaattg acggggaccc gcacaagcgg tggagcatgt 900
ggtttaattc gaagcaacgc gaagaacctt accaagtctt gacatccctc tgaccggccc 960
gtaacggggc cttcccttcg gggcagagga gacaggtggt gcatggttgt cgtcagctcg 1020
tgtcgtgaga tgttgggtta agtcccgcaa cgagcgcaac ccctatcctt agtagccagc 1080
aggtgaagct gggcactcta gggagactgc cggggataac ccggaggaag gcggggacga 1140
cgtcaaatca tcatgcccct tatgatttgg gctacacacg tgctacaatg gcgtaaacaa 1200
agggaagcga gacagcgatg ttgagcaaat cccaaaaata acgtcccagt tcggactgca 1260
gtctgcaact cgactgcacg aagctggaat cgctagtaat cgcgaatcag aatgtcgcgg 1320
tgaatacgtt cccgggtctt gtacacaccg cccgtcacac catgggagtc agtaacgccc 1380
gaagtcagtg acccaacctt ataggaggag cgccgaagtc gacct 1425
<210> 15
<211> 1416
<212> DNA
<213> Coprobacillus cateniformis
<400> 15
cgcgggtgct atactgcagt cgaacgcact gattttatca gtgagtggcg aacgggtgag 60
taatacataa gtaacctgcc ctcatgaggg ggataactat tagaaatgat agctaagacc 120
gcataggtga aggggtcgca tgaccgcttc attaaatatc cgtatggata gcaggaggat 180
ggacttatgg cgcattagct ggttggtgag gtaacggctc accaaggcga cgatgcgtag 240
ccgacctgag agggtggacg gccacactgg gactgagaca cggcccagac tcctacggga 300
ggcagcagta gggaattttc ggcaatgggg gaaaccctga ccgagcaacg ccgcgtgagg 360
gaagaagtat ttcggtatgt aaacctctgt tataaaggaa gaacggtatg aataggaaat 420
gattcataag tgacggtact ttatgagaaa gccacggcta actacgtgcc agcagccgcg 480
gtaatacgta ggtggcgagc gttatccgga atcattgggc gtaaagaggg agcaggcggc 540
aatagaggtc tgcggtgaaa gcctgaagct aaacttcagt aagccgtgga aaccaaatag 600
ctagagtgca gtagaggatc gtggaattcc atgtgtagcg gtgaaatgcg tagatatatg 660
gaggaacacc agtggcgaag gcgacgatct gggctgcaac tgacgctcag tcccgaaagc 720
gtggggagca aataggatta gataccctag tagtccacgc cgtaaacgat gagtactaag 780
tgttgggggt caaacctcag tgctgcagtt aacgcaataa gtactccgcc tgagtagtac 840
gttcgcaaga atgaaactca aaggaattga cgggggcccg cacaagcggt ggagcatgtg 900
gtttaattcg aagcaacgcg aagaacctta ccaggtcttg acatacctct aaaggctcta 960
gagatagaga gatagctata ggggatacag gtggtgcatg gttgtcgtca gctcgtgtcg 1020
tgagatgttg ggttaagtcc cgcaacgagc gcaacccttg tcgctagtta ccatcattaa 1080
gttggggact ctagcgagac tgcctctgca aggaggagga aggcggggat gacgtcaaat 1140
catcatgccc cttatgacct gggctacaca cgtgctacaa tggacggatc aaagggaagc 1200
gaagccgcga ggtggagcga aacccaaaaa cccgttctca gttcggactg cagtctgcaa 1260
ctcgactgca cgaagttgga atcgctagta atcgcgaatc agaatgtcgc ggtgaatacg 1320
ttctcgggcc ttgtacacac cgcccgtcac accatgagag ttggtaacac ccgaagccgg 1380
tggcttaacc gcaaggagag agcttctaag gtgaat 1416
<210> 16
<211> 1424
<212> DNA
<213> 共生梭菌(Clostridium symbiosum)
<400> 16
aggcgcgtgc taccatgcag tcgaacgaag caatttaacg gaagttttcg gatggaagtt 60
gaattgactg agtggcggac gggtgagtaa cgcgtgggta acctgccttg tactggggga 120
caacagttag aaatgactgc taataccgca taagcgcaca gtatcgcatg atacagtgtg 180
aaaaactccg gtggtacaag atggacccgc gtctgattag ctagttggta aggtaacggc 240
ttaccaaggc gacgatcagt agccgacctg agagggtgac cggccacatt gggactgaga 300
cacggcccaa actcctacgg gaggcagcag tggggaatat tgcacaatgg gcgaaagcct 360
gatgcagcga cgccgcgtga gtgaagaagt atttcggtat gtaaagctct atcagcaggg 420
aagaaaatga cggtacctga ctaagaagcc ccggctaact acgtgccagc agccgcggta 480
atacgtaggg ggcaagcgtt atccggattt actgggtgta aagggagcgt agacggtaaa 540
gcaagtctga agtgaaagcc cgcggctcaa ctgcgggact gctttggaaa ctgtttaact 600
ggagtgtcgg agaggtaagt ggaattccta gtgtagcggt gaaatgcgta gatattagga 660
ggaacaccag tggcgaaggc gacttactgg acgataactg acgttgaggc tcgaaagcgt 720
ggggagcaaa caggattaga taccctggta gtccacgccg taaacgatga atactaggtg 780
ttggggagca aagctcttcg gtgccgtcgc aaacgcagta agtattccac ctggggagta 840
cgttcgcaag aatgaaactc aaaggaattg acggggaccc gcacaagcgg tggagcatgt 900
ggtttaattc gaagcaacgc gaagaacctt accaggtctt gacatcgatc cgacggggga 960
gtaacgtccc cttcccttcg gggcggagaa gacaggtggt gcatggttgt cgtcagctcg 1020
tgtcgtgaga tgttgggtta agtcccgcaa cgagcgcaac ccttattcta agtagccagc 1080
ggttcggccg ggaactcttg ggagactgcc agggataacc tggaggaagg tggggatgac 1140
gtcaaatcat catgcccctt atgatctggg ctacacacgt gctacaatgg cgtaaacaaa 1200
gagaagcaag accgcgaggt ggagcaaatc tcaaaaataa cgtctcagtt cggactgcag 1260
gctgcaactc gcctgcacga agctggaatc gctagtaatc gcgaatcaga atgtcgcggt 1320
gaatacgttc ccgggtcttg tacacaccgc ccgtcacacc atgggagtca gtaacgcccg 1380
aagtcagtga cccaaccgca aggaggagcg ccgaaggcga ccgt 1424
<210> 17
<211> 1426
<212> DNA
<213> Bacteroides dorei
<400> 17
cggtctcggc ttaccatgca gtcgaggggc agcatggtct tagcttgcta aggctgatgg 60
cgaccggcgc acgggtgagt aacacgtatc caacctgccg tctactcttg gccagccttc 120
tgaaaggaag attaatccag gatggcatca tgagttcaca tgtccgcatg attaaaggta 180
ttttccggta gacgatgggg atgcgttcca ttagatagta ggcggggtaa cggcccacct 240
agtcaacgat ggataggggt tctgagagga aggtccccca cattggaact gagacacggt 300
ccaaactcct acgggaggca gcagtgagga atattggtca atgggcgatg gcctgaacca 360
gccaagtagc gtgaaggatg actgccctat gggttgtaaa cttcttttat aaaggaataa 420
agtcgggtat gcatacccgt ttgcatgtac tttatgaata aggatcggct aactccgtgc 480
cagcagccgc ggtaatacgg aggatccgag cgttatccgg atttattggg tttaaaggga 540
gcgtagatgg atgtttaagt cagttgtgaa agtttgcggc tcaaccgtaa aattgcagtt 600
gatactggat gtcttgagtg cagttgaggc aggcggaatt cgtggtgtag cggtgaaatg 660
cttagatatc acgaagaact ccgattgcga aggcagcctg ctaagctgca actgacattg 720
aggctcgaaa gtgtgggtat caaacaggat tagataccct ggtagtccac acggtaaacg 780
atgaatactc gctgtttgcg atatacggca agcggccaag cgaaagcgtt aagtattcca 840
cctggggagt acgccggcaa cggtgaaact caaaggaatt gacgggggcc cgcacaagcg 900
gaggaacatg tggtttaatt cgatgatacg cgaggaacct tacccgggct taaattgcac 960
tcgaatgatc cggaaacggt tcagctagca atagcgagtg tgaaggtgct gcatggttgt 1020
cgtcagctcg tgccgtgagg tgtcggctta agtgccataa cgagcgcaac ccttgttgtc 1080
agttactaac aggtgatgct gaggactctg acaagactgc catcgtaaga tgtgaggaag 1140
gtggggatga cgtcaaatca gcacggccct tacgtccggg gctacacacg tgttacaatg 1200
gggggtacag agggccgcta ccacgcgagt ggatgccaat ccctaaaacc cctctcagtt 1260
cggactggag tctgcaaccc gactccacga agctggattc gctagtaatc gcgcatcagc 1320
cacggcgcgg tgaatacgtt cccgggcctt gtacacaccg cccgtcaagc catgggagcc 1380
gggggtacct gaagtgcgta accgcgagga tcgccctagg taatga 1426
<210> 18
<211> 1428
<212> DNA
<213> 糞厭氧棒狀菌(Anaerostipes caccae)
<400> 18
cggcggctgc ttaccatgca gtcgaacgaa gcatttagga ttgaagtttt cggatggatt 60
tcctatatga ctgagtggcg gacgggtgag taacgcgtgg ggaacctgcc ctatacaggg 120
ggataacagc tggaaacggc tgctaatacc gcataagcgc acagaatcgc atgattcagt 180
gtgaaaagcc ctggcagtat aggatggtcc cgcgtctgat tagctggttg gtgaggtaac 240
ggctcaccaa ggcgacgatc agtagccggc ttgagagagt gaacggccac attgggactg 300
agacacggcc caaactccta cgggaggcag cagtggggaa tattgcacaa tgggggaaac 360
cctgatgcag cgacgccgcg tgagtgaaga agtatttcgg tatgtaaagc tctatcagca 420
gggaagaaaa cagacggtac ctgactaaga agccccggct aactacgtgc cagcagccgc 480
ggtaatacgt agggggcaag cgttatccgg aattactggg tgtaaagggt gcgtaggtgg 540
catggtaagt cagaagtgaa agcccggggc ttaaccccgg gactgctttt gaaactgtca 600
tgctggagtg caggagaggt aagcggaatt cctagtgtag cggtgaaatg cgtagatatt 660
aggaggaaca ccagtggcga aggcggctta ctggactgtc actgacactg atgcacgaaa 720
gcgtggggag caaacaggat tagataccct ggtagtccac gccgtaaacg atgaatacta 780
ggtgtcgggg ccgtagaggc ttcggtgccg cagcaaacgc agtaagtatt ccacctgggg 840
agtacgttcg caagaatgaa actcaaagga attgacgggg acccgcacaa gcggtggagc 900
atgtggttta attcgaagca acgcgaagaa ccttacctgg tcttgacatc ccaatgaccg 960
aaccttaacc ggttttttct ttcgagacat tggagacagg tggtgcatgg ttgtcgtcag 1020
ctcgtgtcgt gagatgttgg gttaagtccc gcaacgagcg caacccctat ctttagtagc 1080
cagcatttaa ggtgggcact ctagagagac tgccagggat aacctggagg aaggtgggga 1140
cgacgtcaaa tcatcatgcc ccttatggcc agggctacac acgtgctaca atggcgtaaa 1200
caaagggaag cgaagtcgtg aggcgaagca aatcccagaa ataacgtctc agttcggatt 1260
gtagtctgca actcgactac atgaagctgg aatcgctagt aatcgtgaat cagaatgtca 1320
cggtgaatac gttcccgggt cttgtacaca ccgcccgtca caccatggga gtcagtaacg 1380
cccgaagtca gtgacccaac cgcaaggagg gagctgccga agtacgag 1428
<210> 19
<211> 1082
<212> DNA
<213> 鮑氏梭菌(Clostridium bolteae)
<400> 19
tttgtggcga agcctgatgc agcgacgccg cgtgagtgaa gaagtatttc ggtatgtaaa 60
gctctatcag cagggaagaa aatgacggta cctgactaag aagccccggc taactacgtg 120
ccagcagccg cggtaatacg tagggggcaa gcgttatccg gatttactgg gtgtaaaggg 180
agcgtagacg gcgaagcaag tctgaagtga aaacccaggg ctcaaccctg ggactgcttt 240
ggaaactgtt ttgctagagt gtcggagagg taagtggaat tcctagtgta gcggtgaaat 300
gcgtagatat taggaggaac accagtggcg aaggcggctt actggacgat aactgacgtt 360
gaggctcgaa agcgtgggga gcaaacagga ttagataccc tggtagtcca cgccgtaaac 420
gatgaatgct aggtgttggg gggcaaagcc cttcggtgcc gtcgcaaacg cagtaagcat 480
tccacctggg gagtacgttc gcaagaatga aactcaaagg aattgacggg gacccgcaca 540
agcggtggag catgtggttt aattcgaagc aacgcgaaga accttaccaa gtcttgacat 600
cctcttgacc ggcgtgtaac ggcgccttcc cttcggggca agagagacag gtggtgcatg 660
gttgtcgtca gctcgtgtcg tgagatgttg ggttaagtcc cgcaacgagc gcaaccctta 720
tccttagtag ccagcaggta aagctgggca ctctagggag actgccaggg ataacctgga 780
ggaaggtggg gatgacgtca aatcatcatg ccccttatga tttgggctac acacgtgcta 840
caatggcgta aacaaaggga agcaagacag tgatgtggag caaatcccaa aaataacgtc 900
ccagttcgga ctgtagtctg caacccgact acacgaagct ggaatcgcta gtaatcgcga 960
atcagaatgt cgcggtgaat acgttcccgg gtcttgtaca caccgcccgt cacaccatgg 1020
gagtcagcaa cgcccgaagt cagtgaccca actcgcaaga gagggagcgc cgaagtcgtc 1080
at 1082
<210> 20
<211> 1426
<212> DNA
<213> Clostridium citroniae
<400> 20
ctggcgcggc taccatgcag tcgagcgaag cattacagcg gaagttttcg gatggaagct 60
ttaatgactg agcggcggac gggtgagtaa cgcgtggata acctgcctca tacaggggga 120
taacagttag aaatgactgc taataccgca taagcgcaca gtatcgcatg atacggtgtg 180
aaaaactccg gtggtatgag atggatccgc gtctgattag ttagttggcg gggtaaaggc 240
ccaccaagac gacgatcagt agccggcctg agagggtgaa cggccacatt gggactgaga 300
cacggcccaa actcctacgg gaggcagcag tggggaatat tgcacaatgg gggaaaccct 360
gatgcagcga cgccgcgtga gtgaagaagt atttcggtat gtaaagctct atcagcaggg 420
aagaaaatga cggtacctga ctaagaagcc ccggctaact acgtgccagc agccgcggta 480
atacgtaggg ggcaagcgtt atccggattt actgggtgta aagggagcgt agacggcaat 540
gcaagtctgg agtgaaaacc cagggctcaa ccctgggagt gctttggaaa ctgtatagct 600
agagtgctgg agaggtaagt ggaattccta gtgtagcggt gaaatgcgta gatattagga 660
ggaacaccag tggcgaaggc ggcttactgg acagtaactg acgttgaggc tcgaaagcgt 720
ggggagcaaa caggattaga taccctggta gtccacgccg taaacgatga atgctaggtg 780
ttggggggca aagcccttcg gtgccgtcgc aaacgcaata agcattccac ctggggagta 840
cgttcgcaag aatgaaactc aaaggaattg acggggaccc gcacaagcgg tggagcatgt 900
ggtttaattc gaagcaacgc gaagaacctt accaagtctt gacatcctcc tgaccggtcc 960
gtaacggggc ctttccttcg ggacaagaga gacaggtggt gcatggttgt cgtcagctcg 1020
tgtcgtgaga tgttgggtta agtcccgcaa cgagcgcaac ccttatcctt agtagccagc 1080
aggtagagct gggcactcta gggagactgc cagggataac ctggaggaag gtggggatga 1140
cgtcaaatca tcatgcccct tatgatttgg gctacacacg tgctacaatg gcgtaaacaa 1200
agggaggcga ccctgcgaag gcaagcaaat cccaaaaata acgtcccagt tcggactgta 1260
gtctgcaacc cgactacacg aagctggaat cgctagtaat cgcgaatcag aatgtcgcgg 1320
tgaatacgtt cccgggtctt gtacacaccg cccgtcacac catgggagtc agcaacgccc 1380
gaagtcagtg acccaactgc aggagaggga gcgccgaagt cgggct 1426
<210> 21
<211> 30
<212> DNA
<213> 人工序列
<220>
<223> 454銜接頭序列
<400> 21
ccatctcatc cctgcgtgtc tccgactcag 30
<210> 22
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 修飾的引物8F的部分序列
<400> 22
agrgtttgat ymtggctcag 20
<210> 23
<211> 30
<212> DNA
<213> 人工序列
<220>
<223> 454銜接頭序列
<400> 23
cctatcccct gtgtgccttg gcagtctcag 30
<210> 24
<211> 19
<212> DNA
<213> 人工序列
<220>
<223> 修飾的引物338R的部分序列
<400> 24
tgctgcctcc cgtaggagt 19
<210> 25
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 引物8F
<400> 25
agagtttgat cmtggctcag 20
<210> 26
<211> 19
<212> DNA
<213> 人工序列
<220>
<223> 引物1492R
<400> 26
ggytaccttg ttacgactt 19
- 還沒有人留言評論。精彩留言會獲得點贊!