基于人體PPG信號分段的身份識別方法與流程
本發明屬于信息處理技術領域,具體涉及一種身份識別方法,可作為金融、政府機構等領域中維護個人信息安全的一種手段。
背景技術:
當今社會,安全問題越來越突出,人們不得不記憶復雜的密碼或者攜帶額外的電子密碼器,這使得傳統的身份識別方法越來越失去它的實用性和可靠性,這一現狀使人們對生物識別的需求越來越大。今天,大多數的系統比如金融交易、計算機網絡和對安全領域的訪問系統仍是通過身份證或口令進行識別授權的。這樣的系統并不足夠安全,因為身份證或口令信息很容易被竊取或者遺忘。生物識別系統可以提供更多的可靠性和隱秘性,因為它是根據個人的生理信號和行為特征進行身份認證的,這種生理信號或行為特征是個人獨有的,并可以用來區分開不同個體。人體或行為屬性獨特的特性,如指紋、人臉、聲音、腦電圖和心電圖等被用來進行身份識別。基于這些特征的應用提供了一種有發展前景和不可取代的識別方法。然而,指紋可以用乳膠提取特征,人臉識別可以用偽造的照片進行欺騙,聲音可以被模仿,基于腦電信號或者心電信號的方法因需要各種各樣的電極采集信號而不能廣泛使用。
光電容積脈搏波ppg信號是一種非入侵式的光電方法,通過靠近皮膚測試身體的某一部位,獲取關于血管中血液流動體積變化的信息。ppg信號作為人體固有的一種生理特征,具有難以被復制和模仿的特點,具有較高的安全性,且采集簡單。目前基于ppg信號的時域身份識別方法,識別率不足夠高,難以滿足實際應用需求。
目前已提出的基于ppg信號的身份識別方法有:
a.
nimohammednadzr,msulaimi,lfumadi,kasidek等人2016年在“indianjournalofscienceandtechnology”期刊上發表的文章“photoplethysmogrambasedbiometricrecognitionfortwins”中,研究了一種利用ppg信號對雙胞胎的身份進行識別的方法,該方法首先利用低通濾波器對原始ppg信號進行去噪,然后對ppg信號波形進行分割,提取單周期波形,再利用徑向基函數網絡和樸素貝葉斯分類器分別對單周期波形進行識別分類,最終身份正確識別率達到97%以上,該方法驗證了ppg信號的單周期波形特征對個體身份識別的有效性,但身份識別率仍有待進一步提升。
技術實現要素:
本發明的目的在于針對上述已有技術的不足,提出一種基于人體ppg信號分段的身份識別方法,以提高身份識別的正確率。
本發明的技術方案是通過對人體ppg信號單周期波形進行分段處理,再利用鑒別式非負矩陣分解dnmf方法獲取各子波段的特征向量,最后將各子波段的特征向量加權融合,生成融合的特征向量,進行身份識別,其實現步驟如下:
(1)獲取訓練數據庫和測試數據。采集m個人在規定時間段內的光電容積脈搏波ppg信號,組成訓練數據庫s;再采集其中一人在另一時間段內的ppg信號,作為被鑒定者的測試數據xg;
(2)對訓練數據庫s依次進行去噪,歸一化處理,波峰檢測,波形分割,插值,去除差異性大的波形和進行波形平均,得到單周期平均波形數據庫w;
(3)將單周期平均波形數據庫w中每一個單周期波形進行分段處理,得到訓練數據的上子波形集v1、中子波形集v2和下子波形集v3,并計算各子波形集中同一個人兩兩子波形之間的相似度,得到訓練數據上子波形集的權重因子d1、中子波形集的權重因子d2和下子波形集的權重因子d3;
(4)利用鑒別式非負矩陣分解dnmf方法分別對訓練數據的上子波形集v1、中子波形集v2和下子波形集v3進行分解,得到訓練數據上子波形集的基空間z1、中子波形集的基空間z2、下子波形集的基空間z3、訓練數據上子波形特征集h1、中子波形特征集h2和下子波形特征集h3;
(5)利用訓練數據上子波形集的權重因子d1,中子波形集的權重因子d2和下子波形集的權重因子d3分別對訓練數據上子波形特征集h1,中子波形特征集h2下子波形特征集h3中相應的子特征進行加權融合,得到訓練模板庫h;
(6)對被xg鑒定者的測試數據依次進行步驟(2)-(3)操作,得到測試數據xg的上子波形集α1,中子波形集α2,下子波形集α3和測試數據上子波形集的權重因子a1,測試數據中子波形集的權重因子a2和測試數據下子波形集的權重因子a3;
(7)將測試數據xg的上子波形集α1,中子波形集α2,下子波形集α3分別在訓練數據上子波形集的基空間z1,中子波形集的基空間z2,下子波形集的基空間z3上進行投影,獲得測試數據上子波形特征集f1,中子波形特征集f2和下子波形特征集f3;
(8)利用測試數據xg的各子波形集的權重因子a1,a2和a3,將測試數據xg的上子波形特征集f1,中子波形特征集f2和下子波形特征集f3進行加權融合,得到測試特征集f;
(9)利用訓練模板庫h和被鑒定者的測試特征集f,對被鑒定者的身份進行識別。
本發明與現有技術相比具有以下優點:
第一,本發明充分挖掘并利用ppg信號單周期波形的特征,通過將被鑒定者ppg信號的單周期波形進行分段處理,利用余弦相似公式計算各段子波形的權重因子,并利用權重因子對各段子波形進行加權融合,利用獲得的融合特征向量進行身份識別,提高了被鑒定者身份正確識別率。
第二,本發明利用鑒別式非負矩陣分解方法提取ppg信號單周期波形的主要特征,使得相同個體的單周期波形特征之間的差異性變小,不同個體單周期波形特征之間的差異性增大,從而提高了被鑒定者身份的正確識別率。
附圖說明
圖1為本發明的實現總流程圖;
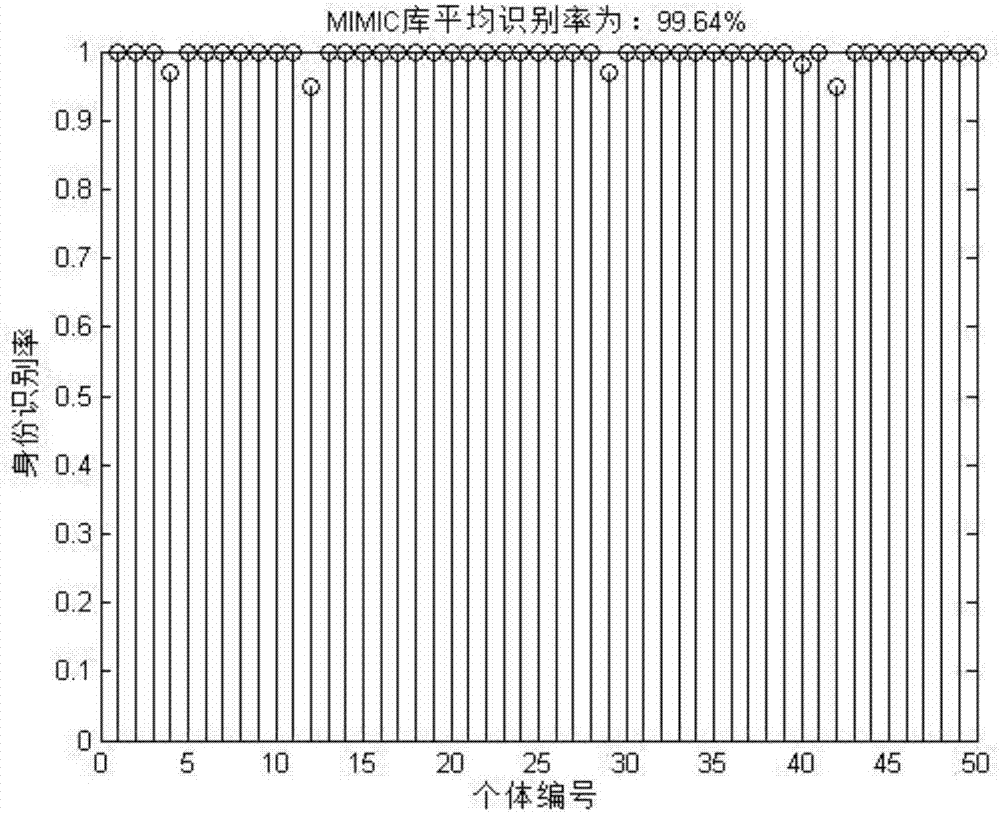
圖2為mimic數據庫的身份識別率結果圖;
圖3為mimic2數據庫的身份識別率結果圖;
圖4為capnobase數據庫的身份識別率結果圖。
具體實施方式
下面結合附圖對本發明的實施及效果作進一步詳細描述。
參照圖1,本發明的實現如下:
步驟1.采集ppg信號,得到訓練數據庫和測試數據。
采集m個人在規定時間段內的ppg信號,設采集的每個人的ppg信號采樣點數為n,將采集的每個人的ppg信號作為一個行向量,構造一個m×n大小的矩陣,作為訓練數據庫s;再采集其中一人在另一時間段內的ppg信號,作為被鑒定者的測試數據,用符號xg表示,則測試數據xg是一個包含多個采樣點的向量。
本發明以mimic數據庫中的ppg信號作為實驗數據,模擬從人體采集到的ppg信號,從mimic數據庫中隨機選取其中50個個體的ppg數據文件,讀取每個人的ppg數據文件的前200秒的ppg信號,組成訓練數據庫s;再從該50個個體中隨機讀取其中一個人的ppg數據文件后200秒的ppg信號,作為被鑒定者的測試數據xg;mimic數據庫中的ppg信號的采樣頻率f為125hz,所以訓練數據庫s是一個50×25000大小的矩陣,測試數據xg是一個1×25000維的向量。
步驟2.對訓練數據庫s進行預處理,獲取單周期波形數據庫。
(2a)對訓練數據庫s每行ppg信號進行去噪處理,由去噪后的所有行ppg信號組成去噪后的訓練數據庫s1,其中,訓練數據庫s1中每行的ppg信號s1i由n個采樣點組成,表示為:s1i={s1(i,j)|j∈[1,n]},i∈[1,m],s1(i,j)表示去噪后的訓練數據庫s1第i行第j列的采樣點,n表示每人ppg信號的采樣點數;
常用的去噪方法有低通濾波器、小波去噪、傅里葉分析等,本實例采用2014年胡廣書編著的清華大學出版社出版的“現代信號處理教程第2版”的第12.4節“小波去噪”;
(2b)對去噪后訓練數據庫s1的每行ppg信號的每個采樣點進行歸一化處理,使歸一化后的所有采樣點的取值都在區間[0,1]之內,得到歸一化后的訓練數據庫s2,其中,歸一化后的訓練數據庫s2中第i行第j列的采樣點s2(i,j)計算公式為:
(2c)對歸一化后的訓練數據庫s2的每行ppg信號進行收縮期波峰檢測,獲取所有收縮期波峰的位置,去除第一個位置和最后一個位置,由剩余的所有位置組成每行ppg信號收縮期波峰位置的集合
ppg信號是周期性信號,ppg信號的一個周期包括兩個波峰,即收縮期波峰和舒張期波峰,收縮期波峰的幅度值高于舒張期波峰的幅度值。常用的波峰檢測方法有極大值檢測法、差分閾值法、自適應閾值法等,本實例使用王黎,韓清鵬編著的2011年科學出版社出版的“人體生理信號的非線性分析方法”一書的第4.4.1節“p波波峰點的提取方法”;
(2d)波形分割,獲取單周期波形;
以第i行ppg信號的位置集合loci中的所有元素為分割點,將相鄰兩個分割點之間的波形作為一個單周期波形,對歸一化后的訓練數據庫s2的第i行ppg信號s2i進行波形分割,使ppg信號s2i分割后變成
(2e)對所有類單周期集合中每一個單周期波形進行插值,使插值后的每個單周期波形的采樣點數均為n,得到插值后的單周期波形為
(2f)去除差異性較大的單周期波形;
計算第i類所有插值后的單周期波形的平均周期波形,作為參考波形;將每個單周期波形作為//隨機變量,計算第i類的每個單周期波形與參考波形的皮氏積矩相關系數;然后將相關系數與設定的閾值th進行比較,若相關系數小于設定的閾值th,則刪除相應的單周期波形,否則保留相應的單周期波形;由保留下來的所有單周期組合成第i類去除雜波的單周期波形集合
(2g)對第i類去除雜波的單周期波形集合
步驟3.對單周期平均波形數據庫w的單周期波形進行分段處理。取單周期波形數據庫w的第1行到第
步驟4.計算訓練數據的上子波形集v1、中子波形集v2和下子波形集v3各自的相似因子,并根據相似因子,得到各子波形集的權重因子。
(4a)將兩個向量夾角的余弦值作為兩個子波形之間的相似度,設vi,θ和vi,χ分別為上子波形集v1的第i類的第θ個子波形和第χ個子波形,則上子波形集v1的第i類所有子波形之間的相似度simi計算公式如下:
其中,θ,χ∈[1,ki],(·)t表示向量或矩陣的轉置,||·||l2表示向量的l2范數;
(4b)按照步驟(4a)的計算公式,計算訓練數據的上子波形集v1的每一類子波形的相似度,再利用下列公式,得到上子波形集v1的相似因子s1:
(4c)按照步驟(4a)-(4b),求出訓練數據的中子波形集v2的相似因子s2和下子波形集v3的相似因子s3;
(4d)利用訓練數據的上子波形集的相似因子s1,中子波形集的相似因子s2和下子波形集的相似因子s3,按照下列公式,求得各子波形集的權重因子d1,d2和d3:
其中,d1,d2和d3分別為訓練數據的上子波形集的權重因子,中子波形集權重因子和下子波形集權重因子,d1,d2和d3都是0到1之間的實數。
步驟5.獲取基空間和訓練模板庫。
利用鑒別式非負矩陣分解dnmf方法分別對訓練數據的上子波形集v1,中子波形集v2和下子波形集v3進行分解,得到上子波形集的基空間z1,中子波形集的基空間z2,下子波形集的基空間z3和各子波形的子特征集h1,h2,h3;并對各子波形的子特征集h1,h2,h3進行融合,得到訓練模板庫h。
此處的鑒別式非負矩陣分解方法是采用的2006年stefanoszafeiriou,anastasiostefas等人在“ieeetransactionsonneuralnetworks”期刊發表的“exploitingdiscriminantinformationinnonnegativematrixfactorizationwithapplicationtofrontalfaceverification”一文中描述的鑒別式非負矩陣分解方法dnmf。
(5a)利用鑒別式非負矩陣分解方法對訓練數據的上子波形集v1進行分解:
(5a1)隨機初始化基矩陣z(0)和系數矩陣h(0),使基矩陣z(0)中的任意元素滿足
(5a2)根據如下公式,對基矩陣z(t)中的元素
首先,按照如下公式更新,得到中間變量值
然后,對中間變量值
將
(5a3)根據步驟(5a2)得到的迭代t次后的基矩陣z(t),按如下迭代規則更新系數矩陣h(t)中的元素
其中,γ,δ分別為類內散度約束項和類間散度約束項的約束因子,μφ表示系數矩陣h(t-1)中所有列向量的均值向量μ中的第φ個元素;
(5a4)采用預定義的最大迭代次數iter作為停止迭代條件,當迭代次數t達到iter次后,停止迭代,輸出基矩陣z(iter)和系數矩陣h(iter);否則,返回步驟(5a2);
(5b)將基矩陣z(iter)作為上子波形集v1的基空間z1,將系數矩陣h(iter)的每列作為一個子特征向量,組成上子波形的子特征集
(5c)按照步驟(5a),分別對訓練數據的中子波形集v2和下子波形集v3進行分解,得到中子波形集的基空間z2和子特征集
(5d)利用訓練數據的上子波形集的權重因子d1,中子波形集的權重因子d2和下子波形集的權重因子d3對上子波形的子特征集h1中的子特征向量
步驟6.對被鑒定者的測試數據xg進行處理,得到測試數據xg的各子波形集及各子波形集的權重因子。
(6a)對測試數據xg進行步驟2-3操作,得到測試數據xg的上子波形集α1,中子波形集α2和下子波形集a3;其中,
(6b)對測試數據xg的上子波形集α1,中子波形集α2和下子波形集a3進行步驟4操作,得到測試數據上子波形集的權重因子a1,中子波形集的權重因子a2,下子波形集的權重因子a3,其中,a1,a2,a3∈(0,1)。
步驟7.按照下式,將測試數據xg的上子波形集α1,中子波形集α2和下子波形集a3分別在訓練數據的上子波形集基空間z1,中子波形集基空間z2和下子波形集基空間z3上進行投影,獲得測試數據上子波形的子特征集f1,中子波形的子特征集f2和下子波形的子特征集f3:
f1=inv((z1)t×z1)×(z1)t×a1,
f2=inv((z2)t×z2)×(z2)t×a2,
f3=inv((z3)t×z3)×(z3)t×a3,
其中,
步驟8.獲取測試特征集。按照步驟(5d),利用權重因子a1,a2和a3,對f1,f2和f3的對應列加權融合,得到測試特征集f={ξ1,ξ2,…,ξg,…,ξg},其中,ξg表示測試特征集f的第g個測試特征向量,
步驟9.利用支持向量機svm對被鑒定者的身份進行識別。
(9a)將訓練模板庫h中所有模板輸入到支持向量機中進行訓練,得出支持向量機模型;
(9b)將被鑒定者的測試特征集f中的所有測試特征向量依次輸入到訓練好的支持向量機模型中進行類別預測,得到預測類別信息;
(9c)根據所有測試特征向量的預測類別信息,分別統計各類中測試特征向量的個數,將測試特征向量個數最多的類預測為被鑒定者的身份。
本發明的效果可通過以下仿真做進一步說明。
1.仿真條件
本發明的仿真實驗使用三個公開的ppg信號數據庫mimic,mimic2和capnobase數據庫,模擬從人體采集到的ppg信號,仿真實驗在intelpentiume58003.2ghzcpu、內存2gb的計算機上進行。
2.仿真內容
首先,分別從mimic數據庫,mimic2數據庫和capnobase數據庫中隨機選取50個人,50個人和42個人的ppg信號,使用本發明分別對數據庫中的每個人進行身份預測,計算每個人的識別率:
身份識別率=類別預測正確的測試特征數目/被鑒定者的測試特征總數;
然后,取數據庫中所有人身份識別率的平均值作為數據庫的身份識別率,得到每個庫身份識別率的結果圖,如圖2、圖3和圖4。
從圖2、圖3和圖4可以看出,每個庫的正確身份識別率均達到99.62%以上,充分說明了本發明的有效性和高識別率。
- 還沒有人留言評論。精彩留言會獲得點贊!