一種基于聲音刺激的視覺圖像感知系統和方法與流程
本發明屬于信號處理領域,特別涉及一種基于聲音刺激的視覺圖像感知系統和方法。
背景技術:
市場上能夠輔助全盲病人生活的醫療產品少之又少。目前已通過美國fda認證的視障輔助設備主要分為兩類:第一類是需要手術植入的人工視覺系統,它先通過攝像頭采集植入者前方的圖像信息,然后編碼生成電脈沖信號,最后再用植入到病人視網膜上的電極陣列刺激視神經,從而幫助病人恢復一定的光感。這類設備的主要問題在于,具有一定的手術風險,而且部分病人不適合進行手術植入(視神經損傷等),再加上昂貴的價格(一套要10萬美元以上),使得大部分病人沒有條件使用人工視覺類的設備。另一類設備是將二維的圖像信息,通過其他感知通道傳遞給盲人,盲人再在腦中將的到的信息進行“翻譯”,從而獲知一定的圖像信息。比如用電極陣列刺激皮膚或舌頭,通過觸覺接收二維圖像信息,再將其轉換成“視覺感知”。此類設備特點是沒有風險,價格相對便宜,但是使用不夠方便且不夠美觀,需要將電極貼在頭皮上或者含在嘴里。
技術實現要素:
有鑒于此,本發明的目的在于提供一種既不需要手術植入,成本低,使用方便,又能夠給盲人傳遞圖像信息的系統,將會解決很多盲人基本生活上的困難,造福社會。
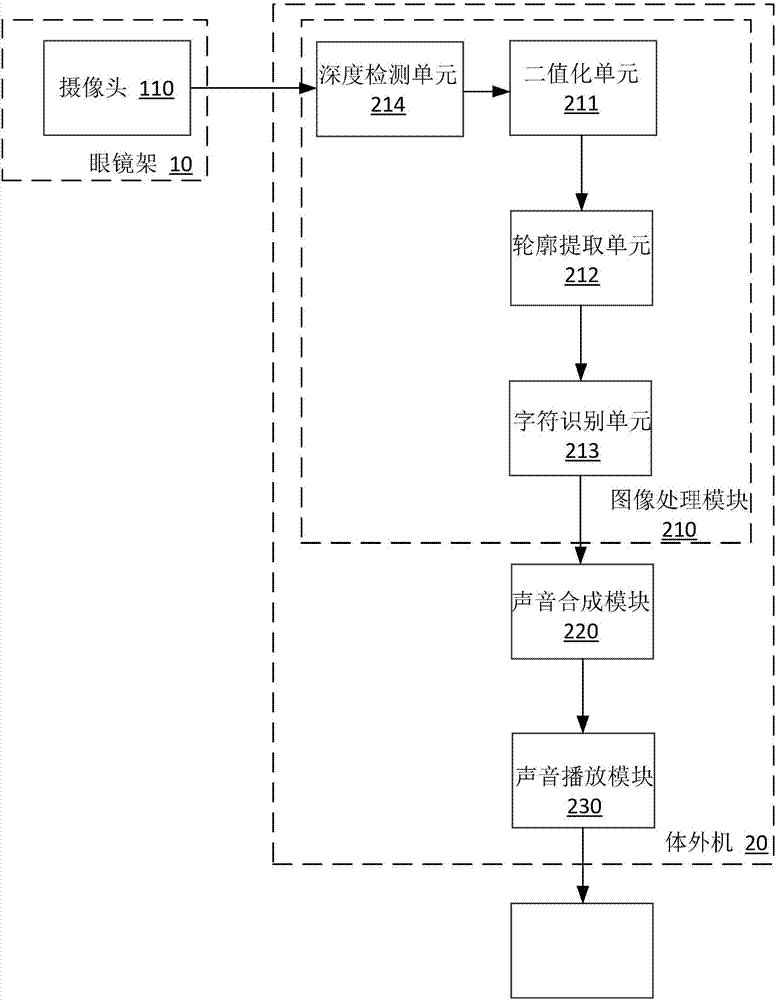
為達到上述目的,本發明提供了一種基于聲音刺激的視覺圖像感知系統,包括眼鏡架、體外機和耳機,其中眼鏡架上設置攝像頭;體外機包括圖像處理模塊、聲音合成模塊和聲音播放模塊,
所述攝像頭與體外機的圖像處理模塊連接,攝像頭獲取二維或三維圖像,圖像處理模塊將二維或三維圖像進行深度檢測、二值化、輪廓提取和字符識別后,輸出給聲音合成模塊進行聲音處理后,將聲音信號傳輸給聲音播放模塊通過氣導或骨導耳機播放。
優選地,所述圖像處理模塊至少包括依次連接的深度檢測單元、二值化單元、輪廓提取單元和字符識別單元。
優選地,所述攝像頭包括一個或兩個af鏡頭。
優選地,所述聲音合成模塊包括頭相關傳遞函數濾波單元。
優選地,所述聲音合成模塊對于圖像對應的聲音合成處理根據下式:
a(i)=s*h(i)*g(i)
a=a(1)→a(2)→a(3)→a(4)→...→a(n)
其中,s為基準聲音的頻域信號;h(i)為平面上第i個點所對應的頭相關傳遞函數;g(i)為第i個聲音的增益大小,通過物體的遠近來判斷;a(i)為聲音空間中第i個聲音;a為將平面上所有對應的聲音連續播放后,形成的可傳遞當前二維或三維圖像的聲音信號。
基于上述目的,本發明還提供了一種采用上述系統的基于聲音刺激的視覺圖像感知方法,包括以下步驟:
攝像頭采集獲取二維或三維圖像,進行圖像處理,獲得簡化二維或三維圖像;
根據簡化二維或三維圖像,進行聲音合成處理;
將處理后的聲音傳輸給耳機進行播放。
優選地,所述圖像處理包括以下步驟:
預處理,將二維或三維圖像進行深度檢測,然后灰度化后進行二值化和去噪;
輪廓提取,依次進行圖像剪切、圖像細化和圖像壓縮;
字符識別,輸出采集的二維或三維圖像中的字符或邊緣輪廓。
優選地,所述聲音合成根據頭相關傳遞函數進行。
優選地,所述聲音合成處理包括以下步驟:
第一步:假設平面的維度是n行n列,那么就從最左上角的節點開始遍歷,記為第1圈,坐標位置表示為(1,n),如果有信號則進行第二步,沒有信號則進入步驟第四步;
第二步:當遍歷到有信號的節點時,將此節點設為當前節點,首先播放該節點的聲音信號,然后選擇所處方位與當前遍歷方向一致的節點遍歷,若有信號則重復步驟第二步,直至遍歷完成;若無信號則進入步驟第三步;
第三步:由于處在當前遍歷方向的節點無信號,那么就從此節點接著順時針圍繞當前節點旋轉遍歷;如果遇到有信號的節點,則進入第二步,若沒有,則進入第四步;
第四步:如果之前遍歷到第i圈,那么繼續遍歷第i+1圈,節點坐標依次為(i,n),(i,n-1),(i,n-2)...(i,n-i+1),(i-1,n-i+1),(i-2,n-i+1)...(1,n-i+1),如果這些節點中有信號則繼續第二步,無信號則繼續遍歷更外側的第i+2圈,直至遇到有信號的節點,或遍歷完平面所有節點。
優選地,所述聲音合成處理根據下式:
a(i)=s*h(i)*g(i)
a=a(1)→a(2)→a(3)→a(4)→...→a(n)
其中,s為基準聲音的頻域信號;h(i)為平面上第i個點所對應的頭相關傳遞函數;g(i)為第i個聲音的增益大小,通過物體的遠近來判斷;a(i)為聲音空間中第i個聲音;a為將平面上所有對應的聲音連續播放后,形成的可傳遞當前二維或三維圖像的聲音信號。
本發明的有益效果在于:本發明采用頭相關轉移函數,對于任何一個聲音,都可以處理成從特定方向傳來的感覺,并通過耳機播放給病人。這就意味著,對于任何一個簡單的二維圖像,都可以通過這種連續處理聲音的方式,在聽覺空間中生成一個同樣的圖像,并被感知到。也就是將聲音變成一支筆,勾勒出你所希望的圖形。而盲人由于長期依靠聽覺生活,所以在聽聲辨位方面普遍要強于常人,所以本發明可以起到更好的效果來幫助盲人通過聲音感知物體的輪廓,形狀,甚至距離遠近,方便他們進行簡單的物體識別,會對盲人的生活帶來極大的幫助。
附圖說明
為了使本發明的目的、技術方案和有益效果更加清楚,本發明提供如下附圖進行說明:
圖1為本發明實施例1的一種基于聲音刺激的視覺圖像感知系統結構示意圖;
圖2為本發明實施例2的一種基于聲音刺激的視覺圖像感知系統結構示意圖;
圖3為本發明實施例1的一種基于聲音刺激的視覺圖像感知方法的步驟流程圖;
圖4為本發明實施例2的一種基于聲音刺激的視覺圖像感知方法的步驟流程圖;
圖5為本發明實施例的一種基于聲音刺激的視覺圖像感知系統經圖像處理模塊后的視覺圖像。
具體實施方式
下面將結合附圖,對本發明的優選實施例進行詳細的描述。
實施例1
參見圖1,所示為本發明實施例1的一種基于聲音刺激的視覺圖像感知系統,包括眼鏡架10、體外機20和耳機30,其中眼鏡架10上設置攝像頭;體外機20包括圖像處理模塊210、聲音合成模塊220和聲音播放模塊230,
所述攝像頭與體外機20的圖像處理模塊210連接,攝像頭獲取二維或三維圖像,圖像處理模塊210將二維或三維圖像進行深度檢測、二值化、輪廓提取和字符識別后,輸出給聲音合成模塊220進行聲音處理后,將聲音信號傳輸給聲音播放模塊230通過耳機30播放。
實施例2
在實施例1的基礎上,參見圖2,所示為本發明實施例2的一種基于聲音刺激的視覺圖像感知系統,圖像處理模塊210至少包括依次連接的深度檢測單元214、二值化單元211、輪廓提取單元212和字符識別單元213。
具體實施例中,采集二維圖像時需要一個攝像頭,采集三維圖像時需要兩個攝像頭,攝像頭包括af鏡頭。
聲音合成模塊220包括頭相關傳遞函數濾波單元,因為頭和耳廓等器官(作用類似于濾波器)的存在,導致不同方向傳來的聲音會受到頻率上不同的影響,因此,依據先前的經驗,人的大腦會自動根據聲音的頻率變化識別出聲音傳來的方向。在具體的聲音處理過程中,首先選定一個標準聲源,比如純音,復合音,白噪聲或人的語音等,然后針對二維平面上不同位置的點,對這個聲音進行相應的頭相關傳遞函數濾波,這樣便可在聽覺空間中,產生相應位置的聲音感受。然后再將所有這樣處理后的聲音,快速連續播放,使人產生聽覺上的輪廓感。
聲音合成模塊220對于圖像對應的聲音合成處理根據下式:
a(i)=s*h(i)*g(i)
a=a(1)→a(2)→a(3)→a(4)→...→a(n)
其中,s為基準聲音的頻域信號;h(i)為平面上第i個點所對應的頭相關傳遞函數;g(i)為第i個聲音的增益大小,通過物體的遠近來判斷;a(i)為聲音空間中第i個聲音;a為將平面上所有對應的聲音連續播放后,形成的可傳遞當前二維或三維圖像的聲音信號。
與上述系統對應的,本發明還提供了一種基于聲音刺激的視覺圖像感知方法,其實施例1流程圖參見圖3,包括以下步驟:
s10,攝像頭采集獲取二維或三維圖像,進行圖像處理,獲得簡化二維或三維圖像;
s20,根據簡化二維或三維圖像,進行聲音合成處理;
s30,將處理后的聲音傳輸給耳機進行播放。
方法實施例2,參見圖4,s10中的圖像處理和s20中的聲音合成處理,包括以下步驟:
s101,預處理,將二維或三維圖像進行深度檢測,再灰度化后進行二值化和去噪;
s102,輪廓提取,依次進行圖像剪切、圖像細化和圖像壓縮;
s103,字符識別,輸出采集的二維或三維圖像中的字符或邊緣輪廓。
s201,假設聲音空間的平面維度是n行n列,那么就從最左上角的節點開始遍歷,記為第1圈,坐標位置表示為(1,n),如果有信號則進行s202,沒有信號則進入步驟s204;
s202,當遍歷到有信號的節點時,將此節點設為當前節點,首先播放該節點的聲音信號并將該節點設為無信號以避免重復播放,然后選擇所處方位與當前遍歷方向一致的節點遍歷,若有信號則重復步驟s202,直至遍歷完成;若無信號則進入步驟s203;
其中,當前遍歷方向是指前兩個被連續遍歷到的有信號的相鄰節點的連接方向,比如從(1,n)遍歷到(2,n),且這兩個節點都有信號,那么當前遍歷方向就被設為正右,也就是說此時應優先遍歷當前節點正右方的相鄰節點,以此類推,遍歷方向默認為正右方;
s203,由于處在當前遍歷方向的節點無信號,那么就從此節點接著順時針圍繞當前節點旋轉遍歷;如果遇到有信號的節點,則進入s202,若沒有,則進入s204;
s204,如果之前遍歷到第i圈,那么繼續遍歷第i+1圈,節點坐標依次為(i,n),(i,n-1),(i,n-2)...(i,n-i+1),(i-1,n-i+1),(i-2,n-i+1)...(1,n-i+1),如果遍歷過程中遇到有信號的節點則繼續s202,無信號則繼續遍歷更外側的第i+2圈,直至遇到有信號的節點,或遍歷完平面所有節點。
具體實施例中,s20中聲音合成處理根據下式:
a(i)=s*h(i)*g(i)
a=a(1)→a(2)→a(3)→a(4)→...→a(n)
其中,s為基準聲音的頻域信號;h(i)為平面上第i個點所對應的頭相關傳遞函數;g(i)為第i個聲音的增益大小,通過物體的遠近來判斷;a(i)為聲音空間中第i個聲音;a為將平面上所有對應的聲音連續播放后,形成的可傳遞當前二維或三維圖像的聲音信號。
參見圖5為本發明實施例的一種基于聲音刺激的視覺圖像感知系統經圖像處理模塊后的視覺圖像。
攝像頭采集到了“8”的圖像,經過圖像處理后為圖5的輪廓圖像,具體實施例中可以從左下角依次播放聲音,快速掃過整個“8”字輪廓,這樣整個門的輪廓生成在人的腦海中。
最后說明的是,以上優選實施例僅用以說明本發明的技術方案而非限制,盡管通過上述優選實施例已經對本發明進行了詳細的描述,但本領域技術人員應當理解,可以在形式上和細節上對其作出各種各樣的改變,而不偏離本發明權利要求書所限定的范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!