一種利用長短期記憶模型遞歸神經網絡的語音識別方法與流程
本發明涉及語音識別領域,尤其是涉及了一種利用長短期記憶模型遞歸神經網絡的語音識別方法。
背景技術:
語音識別常用于各種智能設備智能家居等領域中,迄今為止語音識別的誤差較大,效果不理想。遞歸神經網絡(RNNs)模型可以用來對兩個序列之間的關系進行建模。但是,傳統的RNNs,標注序列和輸入的序列是一一對應的。不適合語音識別中的序列建模:識別出的字符序列或者音素序列長度遠小于輸入的特征幀序列。所以不能直接用RNN來建模。
本發明采用遞歸神經網絡(RNNs),通過端到端的訓練方法,采用連接時間分類(CTC)訓練RNNs,這些結合長短期記憶模型LSTM單元,效果很好。結合多層表達在深度網絡中證明有效,使用靈活。根據TIMIT語音識別基準,深長短期記憶RNNs實現16.8%的測試集誤差。傳統的語音識別系統,是由語音模型、詞典、語言模型構成的,而其中的語音模型和語言模型是分別訓練的,這就造成每一部分的訓練目標都與整個系統的訓練目標不一致。而本專利從語音特征(輸入端)到文字串(輸出端)就只有一個神經網絡模型(這就叫“端到端”模型),可以直接用WER的某種代理作為目標函數來訓練這個神經網絡,避免花費無用功去優化個別的目標函數。
技術實現要素:
針對網絡性能在語音識別的問題和傳統語音識別系統每一部分的訓練目標都與整個系統的訓練目標不一致等問題,本發明的目的在于提供一種利用長短期記憶模型遞歸神經網絡的語音識別方法,可以通過訓練獲取模型參數,之后用于語音和文本數據的識別。
為解決上述問題,本發明提供一種利用長短期記憶模型遞歸神經網絡的語音識別方法,其主要內容包括:
(一)訓練
(二)識別
其中,所述的一種利用長短期記憶模型遞歸神經網絡的語音識別方法,通過端到端的訓練方法,和長短期記憶模型(LSTM)結合,實現了16.8%的測試集誤差,使用靈活,效果好。
其中,所述的遞歸神經網絡(RNNs),給定輸入序列x=(x1,…,xT),計算隱藏的向量序列h=(h1,…,hT),通過以下方程t=1~T輸出向量序列y=(y1,…,yT),
yt=Whyht+by
W表示重量矩陣,代表輸入-隱藏重量矩陣,b代表偏差向量,bh是指隱藏偏差向量,是指隱藏層功能,通常是一個sigmoid函數的對應元素的應用。
其中,所述的含LSTM單元,使用的是雙向LSTM,得到雙向LSTM的步驟如下:
(1)長短期記憶模型(LSTM)架構,使用內置的存儲單元來存儲信息,更好地發現和利用深度范圍的內容,是由以下的復合函數實現:
it=σ(Wxixt+Whiht-1+Wcict-1+bi)
ft=σ(Wxfxt+Whfht-1+Wcfct-1+bf)
ct=ftct-1+ittanh(Wxcxt+Whcht-1+bc)
ot=σ(Wxoxt+Whoht-1+Wcoct+bo)
ht=ottanh(ct)
σ是邏輯sigmoid函數,I,f,o和c分別為輸入門,forget門,輸出門和激活載體,所有這些都和隱藏的向量h相同的大小;
(2)深度卷積RNNs的一個缺點是他們只能夠利用以前的背景,在語音識別中,所有的話語都在一次被轉錄,雙向RNNs(BRNNs)在兩個方向上有兩個獨立的隱藏層處理數據,然后提供給相同的輸出層;BRNN計算前置隱藏序列向后隱藏序列輸出序列y通過重復后置層,t=1~T,前置層t=1~T然后更新輸出層:
結合BRNNS和LSTM給出了雙向LSTM,在兩個輸入方向上獲得遠距離內容,深度RNNs可以通過堆疊彼此的頂部的多個遞歸神經網絡隱層來獲得,隨著一個層的輸出序列,形成下一個的輸入序列;
(3)假設相同的隱藏層函數用于堆疊中的所有n層,隱藏的向量序列hn通過n=1~N和t=1~T的迭代計算獲得:
定義h0=x,網絡輸出yt
雙向深RNNs通過更換每一個隱藏序列hn前向序列和后向序列實現,保證每一個隱藏層收到前向層和后向層的輸入;如果LSTM應用于隱藏層,我們得到雙向LSTM,是這里用到的主要的結構,雙向LSTM效果明顯好于單向LSTM。
其中,所述的訓練,包括語音數據和文本數據,聲學模型和語言模型,RNN傳感器,解碼,模型參數。
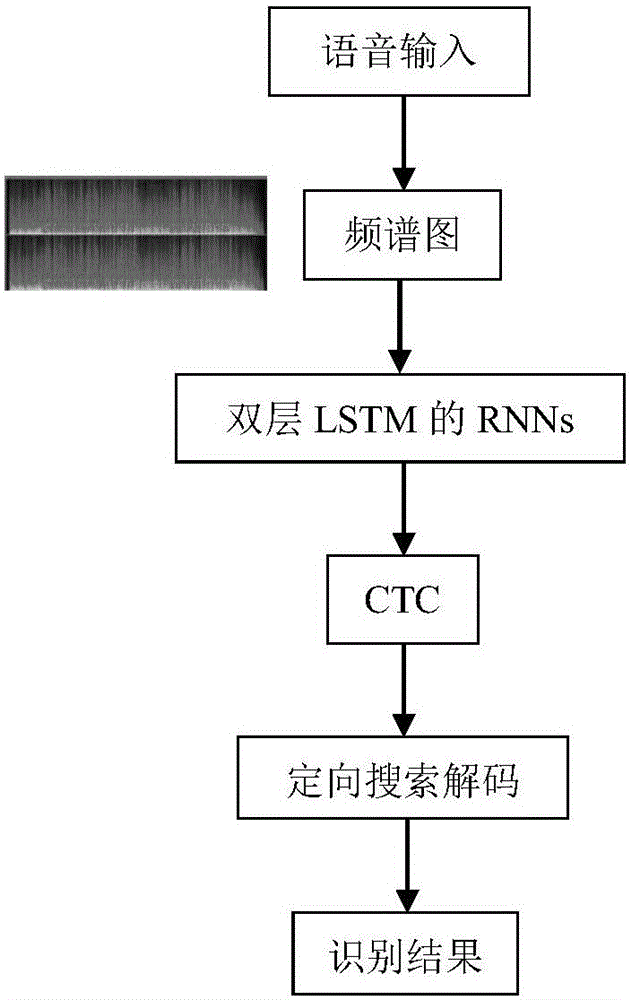
其中,所述的識別,包括語音輸入,頻譜圖,雙層LSTM的RNNs,CTC,定向搜索解碼,識別結果。
進一步的,所述的語音數據和文本數據,是對語音數據和文本數據進行訓練。
進一步的,所述的聲學模型和語言模型,是將語音數據和文本數據利用聲學模型和語言模型處理。
進一步的,所述的RNN傳感器,它預測每個音素和之前音素的對應,從而產生一個共同訓練的聲學和語言模型,RNN傳感器對每一個輸入間隔t和輸出時間間隔u的每個組合確定了一個單獨的分布Pr(k|t,u),對于一個長度U和目標序列z,全套的TU共同決定了x和z之間的所有可能的排列,可以通過向前-向后的算法來決定logPr(z|x);RNN傳感器可以從隨機初始權重訓練。
進一步的,所述的解碼,是RNN傳感器通過定向搜索解碼,產生一個轉錄的n-best列表,定向搜索作為傳感器,隨著輸出標簽概率Pr(k|t,u)的改進,不依賴于以前的輸出,因此Pr(k|t,u)=Pr(k|t),我們發現定向搜索比CTC前綴搜索更快更有效,注意轉錄的n-best列表起初通過長度歸一化log概率分類logPr(y)/|y|。
進一步的,所述的模型參數,是使用RNN傳感器進行解碼形成的,利用訓練好的參數對識別模型進行初始化。
進一步的,所述的頻譜圖,是通過將語音輸入通過傅立葉變換轉化得到的。
進一步的,所述的雙層LSTM的RNNs,是在轉化為頻譜圖后將利用含LSTM單元的RNNs網絡進行定向搜索解碼。
進一步的,所述的接時間分類(CTC),定義了一個只基于聲學輸入序列x的音素序列的分布,它是一個聲學模型,在輸入序列過程中在每一時間步使用軟件函數層來定義的輸出分布Pr(k|t),分布覆蓋了K音節加上額外的空白符號代表非輸出,因此軟件函數層尺寸為K+1;這個結果定義了輸入和輸出序列之間的連線分布,CTC使用前置-后置算法來總結所有的排列可能,確定給出的輸入序列中目標序列的正常化概率Pr(z|x),采用饋入隱藏激活代替將兩種網絡組成一個獨立的前饋輸出網絡,輸出用softmax函數使其正常化,產生Pr(k|t,u),用和代表CTC網絡的最高的向前和向后的隱藏序列,p代表預測網絡的隱藏序列,在每一步t,u,輸出網絡通過饋入和到一個線性層生成向量lt,然后饋入lt和pu到隱層函數生成ht,u,最后饋入ht,u,到一個尺寸為K+1的softmax層來確定Pr(k|t,u)
ht,u=tanh(Wlhlt,u+Wpbpu+bh)
yt,u=Whyht,u+by
yt,u[k]是指長度為K+1的非正常化輸出向量的第kth元素,為了簡化,我們限制所有的非輸出層為相同的尺寸然而,它們是可以獨立變化的;
用CTC訓練的RNNs通常是雙向的,為了確保每個Pr(k|t)依據全部的輸入序列,不止是輸入到t,這里,我們關注深度雙向網絡,Pr(k|t)的定義如下:
這里yt[k]是K+1非正常輸出向量yt的kth元素,N是指雙向級別的數量。
進一步的,所述的定向搜索解碼是使用傅立葉變換對數據集進行解碼濾波器,音素識別實驗TIMIT語料庫進行,隱藏層的數量為1~5。
進一步的,所述的識別結果,深度網絡的優勢非常明顯,CTC的錯誤率從23.9%降到了18.4%,隱藏層的數量從1增加到了5。
進一步的,所述的訓練,是利用隨機梯度下降訓練所有的網絡,學習率為10-4,動量0.9,隨機初始權值[-0.1,0.1],從開發集中的最高log-概率點開始,再用高斯權重噪聲訓練(σ=0.075),直到開發集中音素錯誤率最低。
進一步的,所述的識別,是使用TIMIT語料庫進行,定向搜索解碼的定向寬度為100。
附圖說明
圖1是本發明訓練過程的流程圖。
圖2是本發明識別過程的流程圖。
圖3是長短期記憶模型(LSTM)記憶單元。
圖4是雙向RNNs(BRNNs)在兩個方向上的兩個獨立的隱藏層處理數據。
具體實施方式
需要說明的是,在不沖突的情況下,本申請中的實施例及實施例中的特征可以相互結合,下面結合附圖和具體實施例對本發明作進一步詳細說明。
圖1是本發明訓練過程的流程圖,包括語音數據和文本數據,聲學模型和語言模型,RNN傳感器,解碼,模型參數。
語音數據和文本數據,是對語音數據和文本數據進行訓練。
聲學模型和語言模型,是將語音數據和文本數據利用聲學模型和語言模型處理。
RNN傳感器預測每個音素和之前音素的對應,從而產生一個共同訓練的聲學和語言模型,RNN傳感器對每一個輸入間隔t和輸出時間間隔u的每個組合確定了一個單獨的分布Pr(k|t,u),對于一個長度U和目標序列z,全套的TU共同決定了x和z之間的所有可能的排列,可以通過向前-向后的算法來決定logPr(z|x);RNN傳感器可以從隨機初始權重訓練。
RNN傳感器通過定向搜索解碼,產生一個轉錄的n-best列表,定向搜索作為傳感器,隨著輸出標簽概率Pr(k|t,u)的改進,不依賴于以前的輸出,因此Pr(k|t,u)=Pr(k|t),我們發現定向搜索比CTC前綴搜索更快更有效,注意轉錄的n-best列表起初通過長度歸一化log概率分類logPr(y)/|y|。
模型參數,是使用RNN傳感器進行解碼形成的,利用訓練好的參數對識別模型進行初始化。
訓練過程利用隨機梯度下降訓練所有的網絡,學習率為10-4,動量0.9,隨機初始權值[-0.1,0.1],從開發集中的最高log-概率點開始,再用高斯權重噪聲訓練(σ=0.075),直到開發集中音素錯誤率最低。
圖2是本發明識別過程的流程圖,包括語音輸入,頻譜圖,雙層LSTM的RNNs,CTC,定向搜索解碼,識別結果。
頻譜圖,是將語音輸入通過傅立葉變換轉化為頻譜圖。
雙層LSTM的RNNs,是轉化為頻譜圖后將利用含LSTM單元的RNNs網絡進行定向搜索解碼。
連接時間分類(CTC)定義了一個只基于聲學輸入序列x的音素序列的分布,它是一個聲學模型,在輸入序列過程中在每一時間步使用軟件函數層來定義的輸出分布Pr(k|t),分布覆蓋了K音節加上額外的空白符號代表非輸出,因此軟件函數層尺寸為K+1;這個結果定義了輸入和輸出序列之間的連線分布,CTC使用前置-后置算法來總結所有的排列可能,確定給出的輸入序列中目標序列的正常化概率Pr(z|x),采用饋入隱藏激活代替將兩種網絡組成一個獨立的前饋輸出網絡,輸出用softmax函數使其正常化,產生Pr(k|t,u),用和代表CTC網絡的最高的向前和向后的隱藏序列,p代表預測網絡的隱藏序列,在每一步t,u,輸出網絡通過饋入和到一個線性層生成向量lt,然后饋入lt和pu到隱層函數生成ht,u,最后饋入ht,u,到一個尺寸為K+1的softmax層來確定Pr(k|t,u)
ht,u=tanh(Wlhlt,u+Wpbpu+bh)
yt,u=Whyht,u+by
yt,u[k]是指長度為K+1的非正常化輸出向量的第kth元素,為了簡化,我們限制所有的非輸出層為相同的尺寸然而,它們是可以獨立變化的;
用CTC訓練的RNNs通常是雙向的,為了確保每個Pr(k|t)依據全部的輸入序列,不止是輸入到t,這里,我們關注深度雙向網絡,Pr(k|t)的定義如下:
這里yt[k]是K+1非正常輸出向量yt的kth元素,N是指雙向級別的數量。
定向搜索解碼,是使用傅立葉變換對數據集進行解碼濾波器,音素識別實驗TIMIT語料庫進行,隱藏層的數量為1~5。
識別結果,深度網絡的優勢非常明顯,CTC的錯誤率從23.9%降到了18.4%,隱藏層的數量從1增加到了5。
識別過程使用TIMIT語料庫進行,定向搜索解碼的定向寬度為100。
圖3是長短期記憶模型(LSTM)記憶單元。圖4是雙向RNNs(BRNNs)在兩個方向上的兩個獨立的隱藏層處理數據。
給定輸入序列x=(x1,…,xT),計算隱藏的向量序列h=(h1,…,hT),通過以下方程t=1~T輸出向量序列y=(y1,…,yT),
yt=Whyht+by
W表示重量矩陣,代表輸入-隱藏重量矩陣,b代表偏差向量,bh是指隱藏偏差向量,是指隱藏層功能,通常是一個sigmoid函數的對應元素的應用。
得到雙向LSTM的步驟如下:
(1)長短期記憶模型(LSTM)架構,使用內置的存儲單元來存儲信息,更好地發現和利用深度范圍的內容,如圖3所示,是由以下的復合函數實現:
it=σ(Wxixt+Whiht-1+Wcict-1+bi)
ft=σ(Wxfxt+Whfht-1+Wcfct-1+bf)
ct=ftct-1+ittanh(Wxcxt+Whcht-1+bc)
ot=σ(Wxoxt+Whoht-1+Wcoct+bo)
ht=ottanh(ct)
σ是邏輯sigmoid函數,I,f,o和c分別為輸入門,forget門,輸出門和激活載體,所有這些都和隱藏的向量h相同的大小;
(2)深度卷積RNNs的一個缺點是他們只能夠利用以前的背景,在語音識別中,所有的話語都在一次被轉錄,雙向RNNs(BRNNs)在兩個方向上有兩個獨立的隱藏層處理數據,然后提供給相同的輸出層;如圖4所示,BRNN計算前置隱藏序列向后隱藏序列輸出序列y通過重復后置層,t=1~T,前置層t=1~T然后更新輸出層:
結合BRNNS和LSTM給出了雙向LSTM,在兩個輸入方向上獲得遠距離內容,深度RNNs可以通過堆疊彼此的頂部的多個遞歸神經網絡隱層來獲得,隨著一個層的輸出序列,形成下一個的輸入序列;
(3)假設相同的隱藏層函數用于堆疊中的所有n層,隱藏的向量序列hn通過n=1~N和t=1~T的迭代計算獲得:
定義h0=x,網絡輸出yt
雙向深RNNs通過更換每一個隱藏序列hn前向序列和后向序列實現,保證每一個隱藏層收到前向層和后向層的輸入;如果LSTM應用于隱藏層,我們得到雙向LSTM,是這里用到的主要的結構,雙向LSTM效果明顯好于單向LSTM。
對于本領域技術人員,本發明不限制于上述實施例的細節,在不背離本發明的精神和范圍的情況下,能夠以其他具體形式實現本發明。此外,本領域的技術人員可以對本發明進行各種改動和變型而不脫離本發明的精神和范圍,這些改進和變型也應視為本發明的保護范圍。因此,所附權利要求意欲解釋為包括優選實施例以及落入本發明范圍的所有變更和修改。
- 還沒有人留言評論。精彩留言會獲得點贊!