錄音方法、裝置及終端與流程
本發明涉及音頻處理領域,尤其涉及一種錄音方法、裝置及終端。
背景技術:
錄音即是將音頻數據通過麥克、放大器轉換為電信號,用不同的材料和工藝記錄在媒質上的過程。當前,錄音后得到的錄音文件中,會記錄錄音過程中麥克接收到的所有發聲對象的音頻數據,例如:在會議過程中,會議錄音會記錄參加會議的所有發言者的語音信號,以及,與會人員的肢體動作等發出的噪音等。
發明人在實現本發明實施例的過程中發現,由于錄音文件中會記錄麥克接收到的多個發言者在不同時間段的語音信號,而且,每個發言者的語音靠人耳非常難以區分,因此,在想要有針對性的獲取錄音文件中指定發言者的發言內容時,可能需要反復播放錄音文件,導致浪費時間精力,效率低。
技術實現要素:
為克服相關技術中存在的問題,本發明提供一種錄音方法、裝置及終端。
根據本發明實施例的第一方面,提供一種錄音方法,包括:
接收至少兩個聲源發出的多個音頻數據;
根據所接收到的所述多個音頻數據確定所述至少兩個聲源中的每個聲源的聲源方向和/或位置;
根據所確定的所述至少兩個聲源中的每個聲源的聲源方向和/或位置,確定與所述至少兩個聲源一一對應的至少兩個目標扇區,并為所確定的至少兩個目標扇區中的每個目標扇區分配扇區標識;
生成包含所述音頻數據與所述扇區標識的對應關系的至少一個音頻文件。
可選地,所述至少兩個目標扇區彼此不重疊,每個目標扇區僅覆蓋相對應的聲源的聲源方向和/或位置。
可選地,所述方法還包括:
獲取具有相同扇區標識的音頻數據;
提取所述音頻數據中的聲紋特征;
根據所述聲紋特征,判斷所述目標扇區內的音頻數據是否來自同一聲源;
當所述目標扇區內的音頻數據不來自同一聲源時,為所述目標扇區內來自不同聲源的音頻數據分別設置不同的聲源標識。
可選地,所述生成包含所述音頻數據與所述扇區標識的對應關系的至少一個音頻文件,包括:
生成第一音頻文件,其中,所述第一音頻文件中的多個音頻數據按照采集時間的先后順序排序,并且所述多個音頻數據中的每個音頻數據均具有相應的扇區標識。
可選地,所述生成包含所述音頻數據與扇區標識的對應關系的至少一個音頻文件,還包括:
生成至少兩個第二音頻文件,其中,每個所述第二音頻文件用于保存具有相同扇區標識的音頻數據。
可選地,所述接收至少兩個聲源發出的多個音頻數據,包括:
獲取每個聲音采集設備采集的音頻數據的聲音信息;
根據所述聲音信息確定距離聲源位置最近的聲音采集設備為主聲音采集設備,確定除所述主聲音采集設備之外的聲音采集設備為輔聲音采集設備;
確定所述主聲音采集設備采集的主音頻數據,確定所述輔聲音采集設備采集的輔音頻數據;
將所述主音頻數據與所述輔音頻數據的反相位進行相位疊加,得到聲源數據,
確定所述聲源數據為所述聲音采集設備采集的聲源的音頻數據。
根據本發明實施例的第二方面,提供一種錄音裝置,應用于包含多個聲音采集設備的終端,包括:
接收模塊,用于接收至少兩個聲源發出的多個音頻數據;
第一確定模塊,用于根據所接收到的所述多個音頻數據確定所述至少兩個聲源中的每個聲源的聲源方向和/或位置;
第二確定模塊,用于根據所確定的所述至少兩個聲源中的每個聲源的聲源方向和/或位置,確定與所述至少兩個聲源一一對應的至少兩個目標扇區,并為所確定的至少兩個目標扇區中的每個目標扇區分配扇區標識;
生成模塊,用于生成包含所述音頻數據與所述扇區標識的對應關系的至少一個音頻文件。
可選地,第二確定模塊,還用于,所述至少兩個目標扇區彼此不重疊,每個目標扇區僅覆蓋相對應的聲源的聲源方向和/或位置。
可選地,所述裝置還包括:
獲取模塊,用于獲取具有相同扇區標識的音頻數據;
提取模塊,用于提取所述音頻數據中的聲紋特征;
判斷模塊,用于根據所述聲紋特征,判斷所述目標扇區內的音頻數據是否來自同一聲源;
設置模塊,用于當所述目標扇區內的音頻數據不來自同一聲源時,為所述目標扇區內來自不同聲源的音頻數據分別設置不同的聲源標識。
可選地,所述生成模塊用于:
生成第一音頻文件,其中,所述第一音頻文件中的多個音頻數據按照采集時間的先后順序排序,并且所述多個音頻數據中的每個音頻數據均具有相應的扇區標識。
可選地,所述生成模塊還用于:
生成至少兩個第二音頻文件,其中,每個所述第二音頻文件用于保存具有相同扇區標識的音頻數據。
可選地,所述多個聲音采集設備中的任意兩個所述聲音采集設備之間的距離大于預設距離,所述接收模塊,包括:
獲取子模塊,用于獲取每個聲音采集設備采集的音頻數據的聲音信息;
確定子模塊,用于根據所述聲音信息確定距離聲源位置最近的聲音采集設備為主聲音采集設備,確定除所述主聲音采集設備之外的聲音采集設備為輔聲音采集設備;
第一確定子模塊,用于確定所述主聲音采集設備采集的主音頻數據,確定所述輔聲音采集設備采集的輔音頻數據;
疊加子模塊,用于將所述主音頻數據的反相位與所述輔音頻數據的相位疊加,得到聲源數據;
第三確定子模塊,用于確定所述聲源數據為所述聲音采集設備采集的聲源的音頻數據。
根據本發明實施例的第三方面,提供一種終端,所述終端包括:
處理器;
用于存儲處理器可執行指令的存儲器;
其中,所述處理器被配置為:
接收至少兩個聲源發出的多個音頻數據;
根據所接收到的所述多個音頻數據確定所述至少兩個聲源中的每個聲源的聲源方向和/或位置;
根據所確定的所述至少兩個聲源中的每個聲源的聲源方向和/或位置,確定與所述至少兩個聲源一一對應的至少兩個目標扇區,并為所確定的至少兩個目標扇區中的每個目標扇區分配扇區標識;
生成包含所述音頻數據與所述扇區標識的對應關系的至少一個音頻文件。
根據本發明實施例的第四方面,還提供一種計算機存儲介質,其中,該計算機存儲介質可存儲有程序,該程序執行時可實現本發明第一方面提供一種錄音方法的各實現方式中的部分或全部步驟。
本發明的實施例提供的技術方案可以包括以下有益效果:
本發明首先通過接收至少兩個聲源發出的多個音頻數據,根據所接收到的所述多個音頻數據確定所述至少兩個聲源中的每個聲源的聲源方向和/或位置;進而確定與所述至少兩個聲源一一對應的至少兩個目標扇區,并為所確定的至少兩個目標扇區中的每個目標扇區分配扇區標識,最后生成包含所述音頻數據與所述扇區標識的對應關系的至少一個音頻文件。
在本發明實施例提供的該方法,能夠根據音頻數據所屬的聲音識別扇區,將聲音采集設備采集的多個音頻數據分別設置扇區標識,然后生成包含所述音頻數據與所述扇區標識的對應關系的至少一個音頻文件,這樣能夠便于根據某一扇區標識獲取該扇區標識對應的音頻數據,能夠簡化聲音內容獲取流程,節省時間,提高效率。
應當理解的是,以上的一般描述和后文的細節描述僅是示例性和解釋性的,并不能限制本發明。
附圖說明
此處的附圖被并入說明書中并構成本說明書的一部分,示出了符合本發明的實施例,并與說明書一起用于解釋本發明的原理。
圖1是根據一示例性實施例示出的一種錄音方法的流程圖;
圖2是根據一示例性實施例示出的一種錄音方法的另一種流程圖;
圖3是圖1中步驟S101的流程圖;
圖4是根據一示例性實施例示出的一種錄音裝置的一種結構圖;
圖5是根據一示例性實施例示出的一種錄音裝置的另一種結構圖;
圖6是根據一示例性實施例示出的一種終端的框圖。
具體實施方式
這里將詳細地對示例性實施例進行說明,其示例表示在附圖中。下面的描述涉及附圖時,除非另有表示,不同附圖中的相同數字表示相同或相似的要素。以下示例性實施例中所描述的實施方式并不代表與本發明相一致的所有實施方式。相反,它們僅是與如所附權利要求書中所詳述的、本發明的一些方面相一致的裝置和方法的例子。
由于錄音文件中會記錄麥克接收到的多個發言者在不同時間段的語音信號,而且,每個發言者的語音靠人耳非常難以識別,因此,在想要有針對性的獲取錄音文件中指定發言者的發言內容時,可能需要反復播放錄音文件,導致浪費時間精力,效率低,為此,如圖1所示,在本發明的一個實施例中,提供一種錄音方法,應用于包含多個聲音采集設備的終端,這個聲音采集設備的數量可以是3個、4個或者5個等等,所述多個聲音采集設備中的任意兩個所述聲音采集設備之間的距離可以大于預設距離,這里預設距離可以大于等于30毫米,例如:30毫米、35毫米或者40毫米等等,具體可以根據終端的實際尺寸確定,所述方法包括以下步驟。
在步驟S101中,接收至少兩個聲源發出的多個音頻數據。
在本發明實施例中,音頻數據可以指聲音采集設備在工作狀態采集的所有音頻數據,這里的音頻數據可以是多個聲源發出的聲音信號,例如:人說話的語音信號、肢體動作導致的物體碰撞的聲音信號和室內環境的噪聲等等,每個聲音采集設備可以采集其拾音有效范圍內的音頻數據。
在該步驟中,在聲音采集設備采集到音頻數據后,會將采集到的音頻數據發送給終端中的處理器,處理器接收多個聲音采集設備采集的音頻數據。
在步驟S102中,根據所接收到的所述多個音頻數據確定所述至少兩個聲源中的每個聲源的聲源方向和/或位置。
在該步驟中,以終端為中心,由于在聲音采集設備拾音有效范圍內,任意一點的發出的聲音到達每個聲音采集設備的時沿、響度和相位不同,所以可以根據接收到的多個音頻數據確定每個聲源的聲源方向和/或位置。
在步驟S103中,根據所確定的所述至少兩個聲源中的每個聲源的聲源方向和/或位置,確定與所述至少兩個聲源一一對應的至少兩個目標扇區,并為所確定的至少兩個目標扇區中的每個目標扇區分配扇區標識。
在本發明實施例中,聲音采集設備的有效拾音范圍可以抽象為一個2D平面,并且可以預先將2D平面平均劃分為若干個預設聲音識別扇區,例如,可以將2D平面平均劃分為4個預設聲音識別扇區、劃分為6個預設聲音識別扇區或者劃分為8個預設聲音識別扇區等等。
在該步驟中,可以根據聲源方向和/或位置確定每個音頻數據所屬的預設聲音識別扇區,將覆蓋有音頻數據的聲源方向和/或位置的預設聲音識別扇區確定為目標扇區,所述至少兩個目標扇區彼此不重疊,每個目標扇區僅覆蓋相對應的聲源的聲源方向和/或位置,可以為每個目標扇區分配扇區標識,例如A、B或C等等。
例如,當音頻采集設備同時采集到3個音頻數據1、音頻數據2和音頻數據3,則可以首先確定音頻數據1、音頻數據2和音頻數據3的聲源位置,以將有效拾音范圍劃分為以終端為中心的4個預設聲音識別扇區(對應的扇區標識分別為A、B、C和D)為例,假設音頻數據1的聲源位置位于A對應的預設聲音識別扇區,音頻數據2和音頻數據3位于C對應的預設聲音識別扇區,可以確定A對應的預設聲音識別扇區和C對應的預設聲音識別扇區為目標扇區,這樣音頻數據1對應的扇區標識為A,音頻數據2對應的扇區標識為C,音頻數據3對應的扇區標識為C等。
在步驟S104中,生成包含所述音頻數據與所述扇區標識的對應關系的至少一個音頻文件。
在該步驟中,可以生成一個音頻文件,該音頻文件中的多個音頻數據按照采集時間的先后順序排序,每個音頻數據分別用其對應的扇區標識標記;和/或,生成至少兩個音頻文件,每個所述第二音頻文件中包含具有相同扇區標識的至少一個音頻數據。
本發明首先通過接收至少兩個聲源發出的多個音頻數據,根據所接收到的所述多個音頻數據確定所述至少兩個聲源中的每個聲源的聲源方向和/或位置;進而確定與所述至少兩個聲源一一對應的至少兩個目標扇區,并為所確定的至少兩個目標扇區中的每個目標扇區分配扇區標識,最后生成包含所述音頻數據與所述扇區標識的對應關系的至少一個音頻文件。
在本發明實施例提供的該方法,能夠根據音頻數據所屬的聲音識別扇區,將聲音采集設備采集的多個音頻數據分別設置扇區標識,然后生成包含所述音頻數據與所述扇區標識的對應關系的至少一個音頻文件,這樣能夠便于根據某一扇區標識獲取該扇區標識對應的音頻數據,能夠簡化聲音內容獲取流程,節省時間,提高效率。
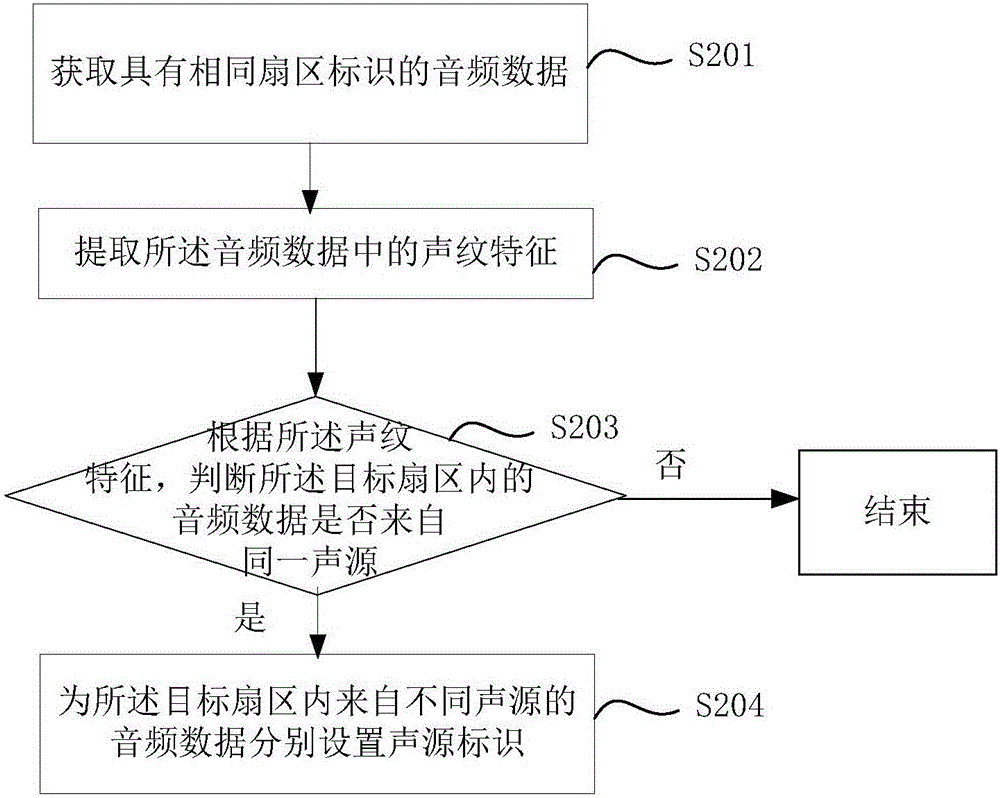
由于在實際應用中,同一預設聲音識別扇區中可能包含兩個聲源或者更多,或者多個發言人處于同一方位時,在同一聲音識別扇區中每個聲源的音頻數據靠人耳仍然難以區分,為此,如圖2所示,在本發明的又一實施例中,可采用聲紋的方式進一步區分,所述方法還包括以下步驟。
在步驟S201中,獲取具有相同扇區標識的音頻數據。
在該步驟中,可以針對每個目標扇區的扇區標識查找其對應的音頻數據,例如,可以根據扇區標識“A”查找到音頻數據1,根據扇區標識“C”查找到音頻數據2和音頻數據3。
在步驟S202中,提取所述音頻數據中的聲紋特征。
在該步驟中,可以采用聲紋識別技術等方式提取音頻數據中的聲紋特征。
在步驟S203中,根據所述聲紋特征,判斷所述目標扇區內的音頻數據是否來自同一聲源。
在該步驟中,由于不同聲源的聲紋是不同的,所以可以根據聲紋特征,確定目標扇區內的音頻數據是否不來自同一聲源,當目標扇區內的音頻數據的聲紋不同時,可以確定目標扇區內的音頻數據不來自同一聲源。
當所述目標扇區內的音頻數據不來自同一聲源時,在步驟S204中,為所述目標扇區內來自不同聲源的音頻數據分別設置不同的聲源標識。
在該步驟中,可以為目標扇區內的每個音頻數據分別設置一個聲源標識,例如,(1)、(2)或(3)等,假設該目標扇區的扇區標識為C,假設任一音頻數據為C對應的預設聲音識別區域中(1)號聲源發出的,則該音頻數據的聲源標識可以設置為C(1)等。
本發明通過首先獲取具有相同扇區標識的音頻數據,然后提取所述音頻數據中的聲紋特征,再根據所述聲紋特征,判斷所述目標扇區內的音頻數據是否來自同一聲源,當所述目標扇區內的音頻數據不來自同一聲源時,可以為所述目標扇區內每個聲源的音頻數據分別設置聲源標識。
本發明實施例提供的該方法,能夠在同一預設聲音識別扇區中包含兩個聲源或者更多,或者多個發言人處于同一方位時,可以通過聲紋識別的方式區分同一聲音識別扇區中多個聲源的音頻數據,并為每個來自不同聲源的音頻數據設置不同的聲源標識,這樣能夠便于根據某一扇區標識獲取該扇區標識對應的音頻數據,能夠簡化聲音內容獲取流程,節省時間,提高效率。
在本發明的又一實施例中,所述步驟S104包括:
生成第一音頻文件,其中,所述第一音頻文件中的多個音頻數據按照采集時間的先后順序排序,并且所述多個音頻數據中的每個音頻數據均具有相應的扇區標識。
在該步驟中,可以生成一個包含多個音頻數據的第一音頻文件,在第一音頻文件中,每個音頻數據均具有扇區標識的標簽,方便用戶后續查詢。
在本發明的又一實施例中,所述步驟S104還包括:
生成至少兩個第二音頻文件,其中,每個所述第二音頻文件用于保存具有相同扇區標識的音頻數據。
在該步驟中,可以針對每個扇區標識,分別生成一個音頻文件,例如,可以將具有相同的扇區標識“C”的音頻數據2和音頻數據3,生成一個音頻文件,將具有扇區標識“A”的音頻數據1生成一個音頻文件等。
在實際應用中,聲音采集設備采集到的音頻數據會包含很多環境聲音數據,例如,環境噪聲等,又由于任意一個聲源的發出的聲音到達每個聲音采集設備的時延、響度和/或相位是不同的,為了能夠獲取到不同聲源的高品質的音頻數據,如圖3所示,在本發明的又一實施例中,所述步驟S101,包括以下步驟。
在步驟S301中,獲取每個聲音采集設備采集的音頻數據的聲音信息。
在本發明實施例中,聲音信息可以指音頻數據的時延、響度和/或相位等。
在該步驟中,可以提取每個聲音采集設備接收的音頻數據的時延、響度和/或相位等聲音信息。
在步驟S302中,根據所述聲音信息確定距離聲源位置最近的聲音采集設備為主聲音采集設備,確定除所述主聲音采集設備之外的聲音采集設備為輔聲音采集設備。
在該步驟中,可以通過對比響度和時延確定距離聲源位置最近的聲音采集設備,并將該距離聲源位置最近的聲音采集設備確定為主聲音采集設備,將終端上的其他聲音采集設備確定為輔聲音采集設備。
在步驟S303中,確定所述主聲音采集設備采集的主音頻數據,確定所述輔聲音采集設備采集的輔音頻數據。
在本發明實施例中,所述主音頻數據中包含,和輔音頻數據中均包括聲源數據和環境聲音數據。可以將輔音頻數據的聲音能量判定為環境聲音(噪音or非主要音源聲音),主音頻數據的聲音能量判定為主要音源聲音+環境聲音。
在步驟S304中,將所述主音頻數據與所述輔音頻數據的反相位進行相位疊加,得到聲源數據。
在本發明實施例中,由于環境聲音集中在低頻,主音頻數據具有中高頻的特征能量,因此,可以以此作為區分生源數據和環境聲音的依據,又由于環境聲音對于所有聲音采集設備來說能量是基本相同的,因此可以通過將輔音頻數據的相位反向(假設輔音頻數據的相位為0度,那么反向后的相位為180度),與主音頻數據的聲音能量相加對消,這樣即可保證濾除其他噪聲聲源的聲音僅得到聲源發出的聲源數據。
在該步驟中后,可以通過濾波處理、穩態消噪及非穩態能量補償等修正方式,使聲源數據的能量得到充分補充,使噪聲及環境聲音得到足夠減弱,提升錄音的信噪比。
在步驟S305中,確定所述聲源數據為所述聲音采集設備采集的聲源的音頻數據。
在該步驟中,可以將得到的聲源數據確定為聲音采集設備采集的音頻數據。
如圖4所示,在本發明的又一實施例中,提供一種錄音裝置,應用于包含多個聲音采集設備的終端,包括:接收模塊41、第一確定模塊42、第二確定模塊43和生成模塊44。
接收模塊41,用于接收至少兩個聲源發出的多個音頻數據。
第一確定模塊42,用于根據所接收到的所述多個音頻數據確定所述至少兩個聲源中的每個聲源的聲源方向和/或位置。
第二確定模塊43,用于根據所確定的所述至少兩個聲源中的每個聲源的聲源方向和/或位置,確定與所述至少兩個聲源一一對應的至少兩個目標扇區,并為所確定的至少兩個目標扇區中的每個目標扇區分配扇區標識。
生成模塊44,用于生成包含所述音頻數據與所述扇區標識的對應關系的至少一個音頻文件。
在本發明的又一實施例中,第二確定模塊,還用于,所述至少兩個目標扇區彼此不重疊,每個目標扇區僅覆蓋相對應的聲源的聲源方向和/或位置。
如圖5所示,在本發明的又一實施例中,所述裝置還包括:獲取模塊51、提取模塊52、判斷模塊53和設置模塊54。
獲取模塊51,用于獲取具有相同扇區標識的音頻數據。
提取模塊52,用于提取所述音頻數據中的聲紋特征。
判斷模塊53,用于根據所述聲紋特征,判斷所述目標扇區內的音頻數據是否來自同一聲源.
設置模塊54,用于當所述目標扇區內的音頻數據不來自同一聲源時,為所述目標扇區內來自不同聲源的音頻數據分別設置不同的聲源標識。
在本發明的又一實施例中,所述生成模塊用于:
生成第一音頻文件,其中,所述第一音頻文件中的多個音頻數據按照采集時間的先后順序排序,并且所述多個音頻數據中的每個音頻數據均具有相應的扇區標識。
在本發明的又一實施例中,所述生成模塊還用于:
生成至少兩個第二音頻文件,其中,每個所述第二音頻文件用于保存具有相同扇區標識的音頻數據。
在本發明的又一實施例中,所述多個聲音采集設備中的任意兩個所述聲音采集設備之間的距離大于預設距離,所述接收模塊,包括:獲取子模塊、確定子模塊、第一確定子模塊、疊加子模塊和第三確定子模塊。
獲取子模塊,用于獲取每個聲音采集設備采集的音頻數據的聲音信息;
確定子模塊,用于根據所述聲音信息確定距離聲源位置最近的聲音采集設備為主聲音采集設備,確定除所述主聲音采集設備之外的聲音采集設備為輔聲音采集設備;
第一確定子模塊,用于確定所述主聲音采集設備采集的主音頻數據,確定所述輔聲音采集設備采集的輔音頻數據;
疊加子模塊,用于將所述主音頻數據的反相位與所述輔音頻數據的相位疊加,得到聲源數據;
第三確定子模塊,用于確定所述聲源數據為所述聲音采集設備采集的聲源的音頻數據。
圖6是根據一示例性實施例示出的一種應用程序安裝裝置的框圖。參照圖6,該裝置包括:
處理器21;
用于存儲處理器21可執行指令的存儲器22;
其中,所述處理器21被配置為:
接收至少兩個聲源發出的多個音頻數據;
根據所接收到的所述多個音頻數據確定所述至少兩個聲源中的每個聲源的聲源方向和/或位置;
根據所確定的所述至少兩個聲源中的每個聲源的聲源方向和/或位置,確定與所述至少兩個聲源一一對應的至少兩個目標扇區,并為所確定的至少兩個目標扇區中的每個目標扇區分配扇區標識;
生成包含所述音頻數據與所述扇區標識的對應關系的至少一個音頻文件。
本發明實施例還提供一種計算機存儲介質,其中,該計算機存儲介質可存儲有程序,該程序執行時可實現圖1-圖3所示實施例提供的錄音方法的各實現方式中的部分或全部步驟。
本領域技術人員在考慮說明書及實踐這里公開的發明后,將容易想到本發明的其它實施方案。本申請旨在涵蓋本發明的任何變型、用途或者適應性變化,這些變型、用途或者適應性變化遵循本發明的一般性原理并包括本發明未公開的本技術領域中的公知常識或慣用技術手段。說明書和實施例僅被視為示例性的,本發明的真正范圍和精神由所附的權利要求指出。
應當理解的是,本發明并不局限于上面已經描述并在附圖中示出的精確結構,并且可以在不脫離其范圍進行各種修改和改變。本發明的范圍僅由所附的權利要求來限制。
- 還沒有人留言評論。精彩留言會獲得點贊!