模擬信息特征提取的基于時間的頻率調諧的制作方法
不適用。
關于聯邦政府資助研究或開發的聲明
不適用。
技術領域
本發明屬于音頻輸入的主動感測(active sensing)領域。實施例針對感測音頻中的具體特征的檢測。
背景技術:
半導體制造和傳感器技術的最新進展已經使對傳感器和控制器的低功率網絡的使用的新能力能夠監測環境以及控制過程。預期這些網絡來進行廣泛應用(包括運輸、制造、生物醫學、環境管理、安全以及保密)的部署。這些低功率網絡中的許多低功率網絡涉及廣域網上的機器對機器(“M2M”)通信,現在這種網絡通常被稱為“物聯網”(“IoT”)。
被設想作為這些網絡中的傳感器的輸入的特定的環境屬性或事件也是廣范圍的,包括如溫度、濕度、地震活動、壓力、機械應變或振動等條件。在這些網絡化系統中還設想感測音頻屬性或事件。例如,在安全性背景中,可以部署傳感器來檢測特定聲音,如槍聲、玻璃打破聲、人聲、腳步聲、附近的汽車聲、動物咀嚼電力電纜聲、天氣狀況等。
音頻信號或輸入的感測還由這種用戶設備(如移動電話、個人電腦、平板電腦、汽車音響系統、家庭娛樂或照明系統等)實施。例如,在現代移動電話手機中,軟件“app”的語音激活通常是可用的。典型地,通過檢測感測到的音頻中的特定特征或“簽名”以及調用相應的應用或行動作為響應來運行常規的語音激活。能夠由這些用戶設備感測的其他類型的音頻輸入包括背景聲音(如用戶是否為辦公環境、餐廳、移動的汽車或其他運輸工具中),設備響應于這些音頻輸入而對其響應或操作進行修改。
在低功率網絡設備和電池供電移動設備中,對考慮到最大靈活性和電池壽命以及最小形狀系數來說,低功率操作是關鍵的。例如,已經觀察到的是,在等待預期的事件發生同時,一些類型的傳感器(如在IoT背景環境中部署的無線環境傳感器)能夠在環境或信道監測上使用其可用功率的一大部分。考慮通常在語音或聲音識別中需要的大量的功率,對聲學傳感器來說是尤其如此。這種類型的常規傳感器通常根據低功率或“睡眠”運行模式來運行,在該運行模式中,傳感器組件(例如,信號發送器電路系統)的后端被有效地斷電直到接收到指示預期事件發生的信號。而此方法能夠顯著地減少傳感器組件的功率消耗,許多小功率循環系統在空閑周期期間仍然消耗大量功率,以便構成總功率預算的主要部分,在這些小功率循環系統中,每個傳感器組件花費非常小量的時間執行數據傳輸。
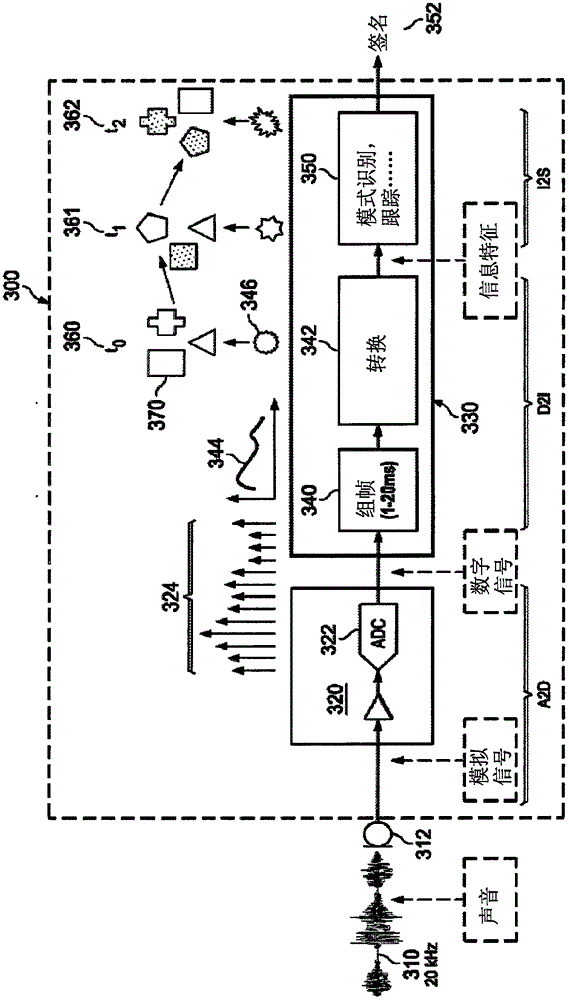
圖1示出了典型的常規聲音識別系統300,例如應用于人類語言的檢測。識別系統300的麥克風312接收來自周圍環境的聲音310,并且將其轉換為模擬信號。系統300的模擬前端(AFE)級320中的模數轉換器(ADC)322將此模擬輸入信號轉換為數字信號,具體地,以數字采樣324的序列的形式。作為本領域的基本原理,ADC 322的采樣率超過兩倍的感興趣的最大頻率的尼奎斯特率(Nyquist rate)。對典型的人類語言識別系統來說高達大約20kHz的聲音信號是感興趣的,并且對典型的人類語言識別系統來說采樣率將為至少40kHz。
在此常規系統300中,系統300的數字邏輯330將數字采樣324轉換為聲音信息(D2I)。數字邏輯330通常由通用微控制器單元(MCU)、專用數字信號處理器(DSP)、專用集成電路(ASIC)或其他類型的可編程邏輯實現,并且在此布置中將采樣劃分為幀340以及然后使用定義的轉換函數344將組幀(frame)的采樣轉換342為信息特征。然后,通過模式識別和跟蹤邏輯350將這些信息特征映射到聲音簽名(I2S)。
識別邏輯350通常由一種或更多種類型的已知模式識別技術(如神經網絡、分級樹、隱馬爾科夫模型、條件隨機域、支持向量機等)實現,并且以由時間點t0360,t1361,t2362等表示的周期的方式運行。例如,由轉換342產生的每個信息特征(例如,特征346)與預先識別的特征的數據庫370比較。在每個時間步驟,識別邏輯350企圖找到由轉換邏輯342產生的信息特征的序列和存儲在數據庫370中的聲音簽名的序列之間的匹配。被識別的每個候選簽名352被分配指示其與數據庫370中的特征之間的匹配程度的分數值。那些具有超過閾值的分數的簽名352被識別器300識別為與已知簽名匹配。
由于復雜的信號分段,因此在識別系統300中是信號轉換和最終模式識別操作在數字域執行,需要ADC 322的高性能和高精度實現以及其余的模擬前端(AFE)320來為接下來復雜的數字處理提供足夠的數字信號。例如,由典型的常規聲音識別系統進行的具有8kHz帶寬的聲音信號的語音識別將需要以16KSps(每秒采樣)或更高采樣率運行的具有16比特精度的ADC。此外,由于原始輸入信號310本質上由系統300記錄,因此信號能夠從存儲的數據、提高隱私和安全問題方面被重建。
另外,為了緩解電池供電應用中的高功率消耗問題,在一些工作周期,系統300可以在正常檢測和備用操作模式之間切換。例如,有時,整個系統可以被開啟并且運行在全功率模式用于檢測,然后是低功率備用模式中的間隔。然而,這種周期性工作操作增加了在備用模式期間丟失事件的可能性。
借助于進一步的背景,2015年3月5日公開的通常由此參考指定在此并結合于此的美國專利申請公開號US 2015/0066498,描述了配置成接收可能包括簽名聲音的模擬信號的低功率聲音識別傳感器。在此傳感器中,使用模擬部分的檢測部分評估接收到的模擬信號以確定何時超過模擬信號上的背景噪聲。當超過背景噪聲時,觸發模擬部分的特征提取部分以從模擬信號中提取稀疏的聲音參數信息。當期望的聲音可能以模擬信號的形式被接收時,聲音參數信息的初始截斷部分與隨著聲音識別傳感器本地存儲的截斷聲音參數數據庫比較以進行檢測。當期望的聲音可能以超過閾值的形式被接收時,產生觸發信號以觸發分類邏輯。
借助于進一步的背景,2015年3月5日公開的通常由此參考指定在此并結合于此的美國專利申請公開號US 2015/0066495,描述了配置成接收可能包括簽名聲音的模擬信號的低功率聲音識別傳感器。在此傳感器中,當在模擬信號中接收簽名聲音時,從模擬信號中提取稀疏的聲音參數信息,并且將該稀疏的聲音參數信息與隨著聲音識別傳感器本地存儲的聲音參數參考比較以進行檢測。稀疏的聲音參數信息的部分為微分零交叉(ZC)計數。通過測量在時間幀的每個序列期間模擬信號交叉閾值的次數以形成ZC計數的序列以及通過ZC計數的選擇對之間的區別來形成微分ZC計數的序列,可以確定微分ZC率。
技術實現要素:
所公開的實施例提供了以減少的功率消耗有效識別具體音頻事件的音頻識別系統和方法。
所公開的實施例提供了以改進的精度識別具體音頻事件的這種系統和方法。
所公開的實施例提供了實現提高的硬件效率(具體結合模擬電路系統和功能電路)的這種系統和方法。
所公開的實施例提供了能夠以更高的頻帶分辨率而不增加檢測信道復雜度執行這種音頻識別的這種系統和方法。
所公開的實施例提供了這種系統和在音頻識別系統中降低模擬濾波器失配的方法。
通過參照以下說明連同其附圖,所公開的實施例的其他目標和優點對本領域普通技術人員將是明顯的。
根據特定的實施例,通過將信號持續時間劃分成多個間隔(例如,劃分為多個幀),在接收的音頻信號上執行模擬音頻檢測。從在信號中的不同時間以不同頻率特性濾波的信號中識別模擬信號特征,因此在輸入信號中的具體時間點識別具體頻率的信號特征。根據識別的模擬信號特征構造輸出特征序列,并且針對檢測的事件,將輸出特征序列與預定義的特征序列比較。
附圖說明
圖1為框圖形式的常規音頻識別系統的電路圖。
圖2為框圖形式的根據公開的實施例的音頻識別系統的電路圖。
圖3為框圖形式的根據實施例的具有模擬特征提取能力的模擬前端的電路圖。
圖4為框圖形式的根據實施例的圖3的模擬前端的模擬特征提取功能電路的功能圖。
圖5示出了濾波的信號的曲線圖,該曲線圖將多信道濾波方法與實施例的操作進行比較。
圖6a和圖6b為框圖形式的根據替代實施例的時間相關的模擬濾波特征提取和排序(sequencing)功能電路的電路圖。
圖7為框圖形式的根據公開的實施例的利用A2I稀疏聲音特征進行聲音識別的系統的電路圖。
具體實施方式
將此說明中描述的一個或更多個實施例實現為(例如移動電話手機中的)語音識別功能,如設想在其上下文中這種實現是特別有利的。然而,還設想本發明的概念可以在其他應用中有益地應用和實現,例如,在如可以由遠程傳感器、安全以及其他環境傳感器等實施的聲音檢測中實現。因此,將理解的是,以下描述僅以示例的方式提供且不旨在限制如要求保護的本發明的真實范圍。
圖2功能性地示出模擬信息(analog-to-information)(A2I)聲音識別系統5的架構和操作,本發明的實施例可以在該系統中實現。在此布置中,如上述結合的美國專利申請公開號US 2015/0066495和US 2015/0066498中大體描述的,系統5作用于從模擬輸入信號中直接提取的稀疏信息,其中模擬輸入信號在該實例中由麥克風M接收。根據此布置,模擬前端(AFE)10還執行各種形式的模擬信號處理,如具有期望的頻率特性的模擬濾波器的應用、濾波信號的組幀(frame)等。
如結合這些實施例在下面將進一步描述的,AFE 10還執行模擬域處理來提取接收的輸入信號中的具體特征。將這些典型地“稀疏的”提取模擬特征分類(例如,通過比較存儲在簽名/冒名(imposter)數據庫17中的簽名特征),然后將其數字化并且轉發至數字微控制器單元(MCU)20(該數字微控制器單元可以由通用微處理器單元、專用數字信號處理器(DSP)、專用集成電路(ASIC)等實現)。MCU 20應用一種或更多種類型的已知模式識別技術(如神經網絡、分級樹、隱馬爾科夫模型、條件隨機域、支持向量機等)來對由此布置中的AFE 10提取的數字化特征執行數字域模式識別。一旦MCU 20從那些特征中檢測聲音簽名,相應的信息以常規的方式從聲音識別系統5轉發至系統5在其中實施的系統中合適的目標功能電路。根據此布置,聲音識別系統5僅數字化提取的特征(即,包括有用的和可識別的信息的那些特征)而不是全部輸入信號,并且基于那些特征而不是全部輸入信號的數字化版本執行數字模式識別。根據此布置,由于輸入聲音在模擬域中被處理和組幀,因此可能出現在聲音信號中的許多噪聲和干擾在數字化之前被移除,這繼而降低了AFE 10中需要的精度,具體地,降低了AFE 10中模擬數字轉換(ADC)功能的速度和性能需求。所產生的對AFE 10的性能需求的放寬使聲音識別系統5能夠在非常低的功率水平上運行,這在現代電池供電系統中是關鍵的。
如圖2所示,AFE 10(特別是其模擬特征提取功能電路)能夠與簽名/冒名數據庫17的在線實施通信以執行其特征識別功能。在此布置中,聲音識別系統5功能性地包括網絡鏈路15,系統5通過該網絡鏈路能夠與服務器16通信,在針對接收的輸入信號的識別過程中其反過來實時的訪問簽名/冒名數據庫17。替代性的,本地存儲器資源可以存儲系統5中的本地特征識別的必要數據,該本地存儲器資源在聲音識別系統5中或在系統5在其中實施的終端用戶系統(例如,移動電話手機)中的其他地方。在此示例中,如圖2所示,設想通過“基于云端的”在線訓練18可以開發應用在信號特征的識別中的數據,如在上述結合的美國專利申請公開號US 2015/0066495和US 2015/0066498中描述的,或在本領域已知的其他常規方式中描述的。
圖3示出了根據這些實施例的AFE 10的功能化布置。在此實現中,由麥克風M接收的模擬信號被放大器22放大,并且應用于在模擬前端10中的模擬信號處理電路系統24。信號處理電路系統24執行各種形式的模擬域信號處理和調節,如適合于下游功能;設想參考此說明書的本領域技術人員將能夠容易地實現如適合具體的實現而不進行過度實驗的模擬信號處理功能電路24。在此實施例中,模擬特征提取在逐幀(frame-by-frame)基礎上實施,模擬組幀功能電路26將處理過的模擬信號分成時域幀。每個幀的長度可以根據具體的應用而變化,例如,從大約1毫秒到大約20毫秒的典型的幀值范圍。然后,將處理過的模擬信號幀轉發至模擬特征提取功能電路28。
圖4示出了根據此實施例的模擬特征提取功能電路28的功能化布置。信號觸發器30被實現為評估組幀的模擬信號相對背景噪聲以確定之后的信號鏈中的功能是否將從備用狀態被喚醒的模擬電路系統,這允許AFE 10中的電路系統的許多電路多次斷電。在信號觸發器30檢測具體數量的信號能量的事件中(例如,比較信號的放大版本與模擬閾值),將組幀的模擬信號傳遞到時間相關的模擬濾波特征提取和排序功能電路35。
上述結合的美國專利申請公開號US 2015/0066495和US 2015/0066498描述了模擬特征提取的方法,其中多個模擬信道作用于模擬信號上以提取不同的模擬特征。如那些公開中描述的,使用選擇的帶通、低通、高通或其他類型的濾波器,一個或更多個信道可以從模擬輸入信號各自的濾波版本中提取這種屬性(如零交叉信息和總能量)。提取的特征可以基于微分(differential)零交叉(ZC)計數,例如相鄰聲音幀(即在時域中)之間的ZC率中的差,通過使用不同的閾值電壓代替僅一個參考閾值(即在振幅域中)來確定ZC率的差;通過使用不同的采樣時鐘頻率(即在頻域中)來確定ZC率的差,通過單獨或結合使用的這些或其他微分ZC措施來識別具體的特征。能夠分析從模擬信號中提取的總能量值和該信號的各種濾波版本來檢測具體頻帶內的能量值,該總能量值和各種濾波版本還能夠指示具體的特征。
根據上述結合的美國專利申請公開號US 2015/0066495和US 2015/0066498中的方法,在接收信號的持續時間內應用模擬特征提取信道。圖5示出了被這些不同的模擬信道應用的濾波的說明性示例。在此示例中,模擬信號i(t)為在一段時間內(如在第二事件的持續時間內或在一些數量的幀內)接收的輸入信號。例如,如果期望的聲音事件通常在一秒鐘內發生,并且由組幀功能電路26產生的幀的長度為20毫秒,那么模擬信號i(t)將具有大約五十幀的持續時間。在一個模擬特征提取信道中,低通濾波器LPF1使用具有0.5kHz的截止頻率fCO的低通濾波器濾波此接收的模擬信號i(t),以產生如所示的濾波的模擬信號i(t)LPE1。類似地,在另一個特征提取信道中,低通濾波器LPF2將具有2.5kHz的截止頻率fCO的濾波器應用于輸入信號i(t)以產生如所示的濾波的模擬信號i(t)LPF2。根據上述結合的美國專利申請公開號US 2015/0066495和US 2015/0066498中描述的實現,然后通過特征提取電路(如零交叉(ZC)計數器、微分ZC分析器、導出總能量的積分器等)分析這些信號i(t)LPF1和i(t)LPF2中的每個信號,該特征提取電路確定在相應的濾波信號i(t)LPF1和i(t)LPF2中的具體模擬信號特征的振幅。
結合本發明已經發現,在信號內的具體時間間隔的具體頻帶內的信號特征對簽名識別來說能夠比在該間隔期間的其他頻帶內的特征更重要,并且比在該信號內的其他時間的相同的具體頻帶內的特征更重要。根據這些實施例,提供時間相關的模擬濾波特征提取和排序功能電路35(圖4)以使得信號中的特征的提取能夠在音頻信號事件持續時間內的不同時間以不同頻率敏感度來執行。
設想在輸入信號持續時間內應用的濾波頻率特性的具體序列將通常在簽名/冒名數據庫17的發展中由在線訓練功能電路18確定。通常,此訓練將運行以識別待檢測的聲音事件的最獨特的特征(如上述結合的美國專利申請公開號US 2015/0066495和US 2015/0066498中描述的),附加必要的訓練來識別具體頻帶和幀間隔,那些特征在幀間隔處出現在該信號內。根據這些實施例,在該信號持續時間內(視情況而定),此訓練導致濾波頻帶序列以及待應用或檢測的相應信號特征的確定。
根據這些實施例的通過低通濾波器LPF(t)的時間相關的模擬濾波特征提取和排序功能電路35的操作的一個示例在圖5中示出,該功能電路將具有時間相關的截止頻率fCO(t)的濾波器應用到輸入信號i(t)以產生濾波的輸入信號i(t)LPF(t)。在此示例中,低通濾波器LPF(t)在輸入信號序列中的第一幀期間以及在靠近該輸入信號序列的中間的兩個獨立的幀期間應用具有2.5kHz的截止頻率fCO的低通濾波器LPF2,并且在輸入信號i(t)持續時間內的其他幀期間應用具有0.5kHz的截止頻率fCO的低通濾波器LPF1。如果待測的期望的聲音簽名在聲音事件早期(即在第一幀期間)以及還在靠近選擇低通濾波器LPF2時的聲音事件的中間的兩個獨立的幀內在高頻處具有高能量,以及在該事件中的其他時間在較低頻處具有特征,那么該模式是有用的。通過時間相關的模擬濾波特征提取和排序功能電路35,在那些間隔內將模擬特征提取應用到這些各自的濾波信號中,以在輸入信號i(t)持續時間內產生信號特征序列。以此方式,時間相關的模擬濾波特征提取和排序功能電路35實現信號間隔內的不同時間的不同頻率處的信號特征的識別,并且因此實現簽名檢測的精度改進。
參照圖6a,現在將進一步詳細描述根據一個實施例的時間相關的模擬濾波特征提取和排序功能電路35的構建與操作。在此實施例中,可調諧濾波器40接收模擬輸入信號i(t),并且根據在該信號持續時間內能夠隨時間變化的頻率特性來濾波該信號。例如,可以將可調諧濾波器40構造為模擬濾波器,在該模擬濾波器中響應于數字控制信號可以將選擇的部件(例如,電阻器、電容器)切換到或切換出濾波器電路。在這種實施例中,時基控制器42包括用于生成數字控制信號的合適的邏輯電路系統,該數字控制信號選擇可調諧濾波器40應用的濾波器特性。在圖4的此實施例中,針對表示為m個幀的序列的模擬輸入信號i(t)的示例,時基控制器42向可調諧濾波器40發出合適的控制信號以使得其將具體的濾波器特性應用到m個幀的序列的每個幀內的輸入信號i(t)。這些濾波器特性的示例包括具有不同的截止頻率的低通濾波器、帶通濾波器、高通濾波器、陷波濾波器等,如圖5的簡單示例中的LPF1和LPF2的情況。例如,時基控制器42能夠針對m個幀的每個,控制從可用濾波器特性的集合F={F1,F2,F3,...,FX}的可調諧濾波器40的可適用濾波器特性的選擇,以使得應用于給定幀n的選擇濾波器特性為該集合(例如,F(n)∈F)的成員。當然,成功的幀可以應用相同的濾波器特性,例如,如圖5所示通過更長的間隔,在該間隔內應用低通濾波器LPF1。
如以上所指出的,基于在線訓練功能電路18的結果或者以其他方式對應于待測的聲音簽名的簽名/冒名數據庫17中的預先知道的特征序列能夠預定義在m個幀的序列內由時基控制器42選擇的濾波器特性序列。
因此,根據此實施例,組幀濾波模擬信號F(n)的序列由可調諧濾波器40提供給特征提取功能電路45,根據可以在m個幀的序列的幀之間變化的濾波器特性濾波該組幀濾波模擬信號的每個信號。構造特征提取功能電路45以從每個幀中的濾波信號中提取一個或更多個特征。例如,如上述結合的美國專利申請公開號US 2015/0066495和US 2015/0066498中描述的,可以構造特征提取功能電路45來提取特征如ZC計數、ZC微分、總能量等。設想通過參考此說明連同上述結合的美國專利申請公開號US 2015/0066495和US 2015/0066498,本領域技術人員將能夠容易的實現零交叉電路系統、積分器電路系統等,以根據此實施例從可調諧濾波器40產生的信號F(n)中提取期望的特征而不進行過度實驗。因此,特征提取功能電路45產生所提取的特征的逐幀序列E(F(n))/ZC(F(n)),其中,在信號的持續時間內的各時間處從輸入信號的具體頻率中提取那些特征。
然后,如圖4所示,在模擬特征提取功能電路28中將提取的特征的此序列E(F(n))/ZC(F(n))提供給事件觸發器36。如以上討論的,類似于上述結合的美國專利申請公開號US 2015/0066495和US 2015/0066498中描述的,事件觸發器36被實現為將提取的特征的序列E(F(n))/ZC(F(n))與預定義的特征序列比較并基于該比較決定是否喚醒MCU 20中的數字分類器功能電路來運行完整的簽名檢測的邏輯。根據此實施例,事件觸發器36可以依賴于序列E(F(n))/ZC(F(n))中的一個或更多個模擬信號特征來發送開始點以與已知特征比較,例如那些由在線訓練18確定的已知特征或以其他方式存儲在簽名/冒名數據庫17中的已知特征。可以將由此具體系統5識別的具體特征(例如,用戶具體特征)存儲在事件觸發器36內部的存儲器或以其他方式由事件觸發器可訪問的存儲器中的一個或更多個聲音簽名的數據庫中,用于在此比較中使用,從而使得提取的特征的序列E(F(n))/ZC(F(n))可以與預定義的特征序列比較,例如在每個時間間隔內(例如,一個或更多個幀)具體頻率特征由可調諧模擬濾波器40應用。一旦事件觸發器36檢測到根據匹配準則可能匹配(例如由識別的特征序列E(F(n))/ZC(F(n))與預定義的已知特征的比較超過閾值的一些測量),事件觸發器36斷言啟動由數字處理電路系統執行的行動的信號,如,引起MCU 20喚醒以及引起其數字分類邏輯在模擬特征提取功能電路28提取的稀疏的聲音特征上執行嚴格的聲音識別過程的觸發信號。在此實施例中,特征序列E(F(n))/ZC(F(n))自身轉發至ADC 29以進行數字化以及轉發至MCU 20用于此嚴格的數字聲音識別任務;替代地,接收的模擬信號自身(即不根據可調諧模擬濾波器40的時間相關的濾波而被濾波)反而可以轉發至ADC 29以使得數字聲音識別在完整的信號上執行。
參照圖6b,現在將進一步詳細描述根據另一個實施例的時間相關的模擬濾波特征提取和排序功能電路35’的構建與操作。在此布置中,提取和排序功能電路35’而不是可調諧模擬濾波器包括一組模擬濾波器50a,50b,...,50k,每個濾波器在輸入信號i(t)的整個持續時間內接收和濾波所述輸入信號。然而,根據此實施例,模擬濾波器50a至50k彼此應用不同濾波器特性到輸入信號i(t);而圖6b通過低通濾波指示示出了模擬濾波器50a至50k的每個,由這些濾波器應用的濾波特性當然不限于低通濾波器。可以由模擬濾波器50a至50k的單獨的一個應用的濾波器特性的示例包括低通濾波器、帶通濾波器、高通濾波器、陷波濾波器等,它們具有不同的截止頻率,如圖5的簡單的低通濾波器示例中的LPF1和LPF2的情況。
然后,將由模擬濾波器50a至50k產生的濾波信號應用到相應的特征提取功能電路55a,55b,...,55k,這些特征提取功能電路經構造以從相應的濾波信號中提取一個或更多個特征。設想可以相似于特征提取功能電路45構造特征提取功能電路55a至55k,其中每個實例提取特征(如ZC計數器、ZC微分、總能量等),該特征提取功能電路45在上述結合的美國專利申請公開號US 2015/0066495和US 2015/0066498中描述。設想通過參考此說明連同上述結合的美國專利申請公開號US 2015/0066495和US 2015/0066498,本領域技術人員將能夠容易地以零交叉電路系統、積分器電路系統等形式實現特征提取功能電路55a至55k,適合于從來自相應的模擬濾波器50a至50k的濾波信號中提取期望的特征而不進行過度實驗。設想來自一個或更多個模擬濾波器50a至50k的濾波輸出可以被提供至多于一個相應的特征提取功能電路55a至55k。例如,如圖6b所示,將來自模擬濾波器50c的濾波信號應用于兩個特征提取功能電路55c1、55c2;這些功能電路55c1、55c2可以被布置以從濾波信號中提取不同的特征,例如,用功能電路55c1提取總能量以及功能電路55c2提取ZC計數或微分等。
根據此實施例,多個模擬濾波器50a至50k的每個模擬濾波器可以被使能以在輸入信號i(t)的整個持續時間內濾波輸入信號i(t),特征提取功能電路55a至55k的每個特征提取功能電路的輸出應用到多路復用器60的相應輸入。多路復用器60的輸出將特征序列E(F(n))/ZC(F(n))提供給以上描述的觸發器邏輯36和ADC 29(圖4)。在此實施例中,多路復用器60經構造以響應于來自時基控制器42的控制信號,從特征提取功能電路55a至55k中選擇一個或更多個提取特征。類似于以上關于圖6a的描述,時基控制器42包括用于產生控制信號的合適的邏輯電路系統,這些控制信號引起多路復用器60在輸入信號i(t)的持續時間內的期望的幀或時間間隔處選擇合適的提取特征。在模擬輸入信號i(t)被呈現為m個幀的序列的圖4的實施例中,時基控制器42向多路復用器60發出合適的控制信號,從而使得其在m個幀的序列中的每一個幀中的特征提取功能電路55a至55k選擇所提取的特征中的一個或更多個特征。以此方式,多路復用器60的輸出產生所提取的特征的逐幀序列E(F(n))/ZC(F(n)),其中,在信號的持續時間內的各時間處從輸入信號的具體頻率中提取那些特征。
如在圖6a的實施例中,然后由時間相關的模擬濾波特征提取和排序功能電路35’的多路復用器60將所提取的特征的序列E(F(n))/ZC(F(n))提供至模擬特征提取功能電路28(圖4)中的事件觸發器36。如以上所描述的,事件觸發器36將所提取的特征的序列E(F(n))/ZC(F(n))與預定義的特征序列比較,并且如以上相對于圖6a描述的,基于該比較以及適用的匹配準則決定是否喚醒在MCU 20中的數字分類器功能以進行完整的簽名檢測。如果是,則觸發器邏輯130斷言啟動對下游電路系統部分的行動的信號,例如,使MCU 20喚醒并且使其數字分類邏輯對模擬特征提取功能28所提取的稀疏聲音特征執行嚴密的聲音識別過程的信號。或者特征序列E(F(n))/ZC(F(n))自身轉發至ADC 29用于數字化并且轉發至MCU 20用于此嚴密的數字聲音識別任務,或者所接收的模擬信號(由時間相關的模擬濾波特征提取和排序功能電路35’從該模擬信號中提取特征)自身轉發至ADC 29用于數字化以及由MCU 20進行數字聲音識別。
圖7是根據這些實施例的利用A2I稀疏聲音特征的示例性移動蜂窩電話1000的框圖,比如用于命令識別。數字基帶(DBB)單元1002可以包括數字處理處理器系統(DSP),該數字處理處理器系統包括嵌入式存儲器和安全特征。激勵處理(SP)單元1004從手機麥克風1013a接收語音數據流并將語音數據流發送至手機單聲道揚聲器1013b。SP單元1004還從麥克風1014a接收語音數據流并將語音數據流發送至單聲道耳機1014b。通常,SP和DBB是單獨的IC。在多數實施例中,SP并不嵌入可編程處理器芯片,但是基于由在DBB上運行的軟件設置的音頻路徑、濾波、增益等的配置來執行處理。在可替代的實施例中,在執行DBB處理的相同的處理器上執行SP處理。在另一個實施例中,單獨的DSP或者其他類型的處理器執行SP處理。
在此實施方式中,SP單元1004包括采用以上所描述的聲音識別系統5的形式的A2I聲音提取模塊,其允許移動電話1000以超低功率消耗模式運行同時持續監測可以被配置成喚醒移動電話1000的口頭字命令或者其他聲音。可以提取并向數字基帶模塊1002提供魯棒的聲音特征用于分類和識別命令字的詞匯表,該命令字然后調用移動電話1000的各種運行特征的中使用。例如,可以執行至地址簿中的聯系人的語音撥號。如以上更加詳細地描述的,可以經由RF收發器1006將魯棒的聲音特征發送至基于云的訓練服務器。
RF收發器1006是數字無線電處理器并且包括用于經由天線1007從蜂窩基站接收編碼的數據幀流的接收器,以及用于經由天線1007將編碼的數據幀流發送至蜂窩基站的發送器。RF收發器1006被耦合至DBB 1002,該DBB提供對移動電話1000接收并發送的編碼的數據幀的處理。
DBB單元1002可以向連接至通用串行總線(USB)端口1026的各種設備發送或者接收數據。能夠將DBB 1002連接至用戶識別模塊(SIM)卡1010,并且該DBB能夠存儲并檢索用于經由蜂窩系統來做出呼叫的信息。還能夠將DBB 1002連接至存儲器1012,該存儲器增加板載內存并且用于各種處理需要。能夠將DBB 1002連接至藍牙基帶單元1030用于與發送和接收語音數據的麥克風1032a和耳機1032b的無線連接。還能夠將DBB 1002連接至顯示器1020,該DBB能夠向該顯示器發送信息以在呼叫過程中與移動UE 1000進行交互。可以將觸摸屏1021連接至DBB 1002用于觸覺反饋。顯示器1020還可以顯示從網絡、從本地攝像機1028或者從如USB 1026的其他源接收的圖片。DBB 1002還可以經由RF收發器1006或者攝像機1028將從如蜂窩網絡的各種源接收的視頻流發送至顯示器1020。DBB 1002還可以經由在復合輸出終端1024之上的編碼器1022將視頻流發送至外部視頻顯示單元。編碼器單元1022能夠根據PAL/SECAM/NTSC視頻標準提供編碼。在一些實施例中,音頻編解碼器1009從FM無線電調諧器1008接收音頻流并將音頻流發送至立體聲耳機1016和/或立體聲揚聲器1018。在其他實施例中,可能存在音頻流的其他源,比如光盤(CD)播放器、固態存儲器模塊等。
根據本實施例的模擬濾波特征提取和排序功能在音頻事件、命令等的識別中提供重要益處。由根據這些實施例的模擬特征提取產生的一個這種益處是減少下游數字聲音識別過程的復雜性。這些實施例能夠呈現所提取的特征的單個序列,而不是接收并處理由多個模擬信道處理的多個模擬特征序列,這允許數字分類器的復雜性顯著減小。這些實施例還改進了通過固定頻帶實施方式的聲音識別過程的潛在頻帶分辨率,在固定頻帶實施方式中,頻帶分辨率與信道數目成比例。在這些實施例中,能夠向輸入信號的某些時間間隔分配不同的頻帶,使單個信道在多個頻率上達到良好的分辨率。這些實施例的這種屬性還通過使訓練過程提取待檢測的音頻事件的在時間和頻率上都孤立的最獨特的特征來改進聲音識別過程的整體精確度和效率,這在改進識別的精確度的同時減少了識別簽名的計算工作。
以上所描述的一些實施例提供硬件效率和改進的硬件性能。更具體地,與多信道方法相比,在信號持續時間內的不同時間應用不同頻率特性的可調諧模擬濾波器的使用減少了模擬濾波器的數量以及在模擬前端中的特征提取功能電路的數量。此外,使用可調諧模擬濾波器的實施例消除了在多個并行運行的濾波器之間的濾波器不匹配的可能性;反而,許多相同的電路元件被用于在不同的時間應用多個濾波器特性。
設想參考本說明書的本領域的技術人員將認識到所描述的實施例的變型形式和替代形式,并且要理解的是,這種變型形式和替代形式旨在落入權利要求的范圍內。例如,當這些實施例在對輸入模擬信號進行組幀之后執行模擬濾波和特征提取的同時,設想可以在特征提取和識別之后可替代地執行組幀。此外,其他實施例可以包括其他類型的模擬信號處理電路,這些模擬信號處理電路可以被裁剪成提取可以用于檢測如馬達或引擎運行聲音、電弧聲音、汽車碰撞聲音、剎車聲音、動物咀嚼電力電纜的聲音、雨聲、風聲等特定類型的聲音的聲音信息。設想參照本說明書的本領域的技術人員能夠容易地實施并實現這種替代形式,而沒有過度實驗。
已經在本說明書中描述了一個或更多個實施例的同時,當然設想這些實施例的修改形式和替代形式,這種修改形式和替代形式能夠獲得本發明的一個或更多個優點和益處,這對參照本說明書以及其附圖的本領域的普通技術人員而言將是明顯的。設想這種修改形式和替代形式在如隨后在本文中所要求保護的本發明的范圍內。
- 還沒有人留言評論。精彩留言會獲得點贊!