尾音識別方法及語音遙控器與流程
本發明涉及語音遙控器的技術領域,尤其涉及一種尾音識別方法及語音遙控器。
背景技術:
目前,隨著數字化技術的發展,遙控器的功能也越來越多,有藍牙,紅外,語音等功能。而語音功能是智能設備非常重要的一種功能,其語音識別的準確率也是非常重要的。現有遙控器是通過藍牙或者2.4G技術傳輸聲音,但在遙控器的語音數據接收模塊外一層存在屏幕遮擋,且受到周圍復雜環境的影響,使得遙控器的語音識別能力比較差,容易丟失尾音。
技術實現要素:
本發明的主要目的在于提出一種尾音識別方法及語音遙控器,旨在解決遙控器的語音識別能力比較差,容易丟失尾音的技術問題。
為實現上述目的,本發明提供的一種尾音識別方法,所述尾音識別方法包括以下步驟:
根據用戶觸發的采集指令對用戶的語音進行采集;
當接收到用戶觸發的采集停止指令時,繼續對用戶的語音進行采集,并判斷通過采集獲得的總錄音數據是否為完整錄音數據;
若所述總錄音數據不為所述完整錄音數據,則繼續對用戶的語音進行采集,直至所述總錄音數據為完整錄音數據時,停止對用戶的語音進行采集。
可選地,所述根據用戶觸發的采集指令對用戶的語音進行采集的步驟包括:
根據所述語音采集指令將采集的語音數據緩存在預設數據緩存區中;
從所述預設數據緩存區中讀取預設字節數的語音數據;
將讀取獲得的語音數據寫入預設數據庫,所述預設數據庫中存儲的語音數據為當前讀取的語音數據加上之前讀取的語音數據。
可選地,所述判斷通過采集獲得的總錄音數據是否為完整錄音數據的步驟包括:
判斷所述預設數據庫中存儲的語音數據的字節數是否等于所述完整錄音數據的字節數;
所述繼續對用戶的語音進行采集,直至所述總錄音數據為完整錄音數據時,停止對用戶的語音進行采集的步驟包括:
若所述預設數據庫中存儲的語音數據的字節數小于所述完整錄音數據的字節數,則執行從所述預設數據緩存區中讀取預設字節數的語音數據的步驟;
若所述預設數據庫中存儲的語音數據的字節數等于所述完整錄音數據的字節數,則停止從所述預設數據緩存區中讀取語音數據。
可選地,所述判斷通過采集獲得的錄音數據是否為完整錄音數據的步驟之前,所述尾音識別方法還包括:
獲取用戶觸發語音采集指令的時間,記為開始時間;
當接收到用戶觸發的采集停止指令,記錄停止時間;
根據所述開始時間、所述停止時間和預設比特率計算獲得完整錄音數據的字節數。
可選地,所述尾音識別方法還包括:
根據從所述預設數據緩存區中讀取語音數據的次數計算延遲時間;
判斷所述延遲時間是否大于預設時間;
若所述延遲時間大于所述預設時間,則停止讀取所述預設數據緩存區中的語音數據。
此外,為實現上述目的,本發明還提供一種語音遙控器,所述語音遙控器包括:
采集模塊,用于根據用戶觸發的采集指令對用戶的語音進行采集;
所述采集模塊,還用于當接收到用戶觸發的采集停止指令時,繼續對用戶的語音進行采集,并判斷通過采集獲得的總錄音數據是否為完整錄音數據;
停止模塊,用于若所述總錄音數據不為所述完整錄音數據,繼續對用戶的語音進行采集,直至所述總錄音數據為完整錄音數據時,停止對用戶的語音進行采集。
可選地,所述采集模塊包括:
緩存單元,用于根據所述語音采集指令將采集的語音數據緩存在預設數據緩存區中;
讀取單元,用于從所述預設數據緩存區中讀取預設字節數的語音數據;
寫入單元,用于將讀取獲得的語音數據寫入預設數據庫,所述預設數據庫中存儲的語音數據為當前讀取的語音數據加上之前讀取的語音數據。
可選地,所述語音遙控器還包括:
判斷模塊,用于判斷所述預設數據庫中存儲的語音數據的字節數是否等于所述完整錄音數據的字節數;
所述讀取單元,還用于若所述預設數據庫中存儲的語音數據的字節數小于所述完整錄音數據的字節數,則從所述預設數據緩存區中讀取預設字節數的語音數據;
所述停止模塊,還用于若所述預設數據庫中存儲的語音數據的字節數等于所述完整錄音數據的字節數,則停止從所述預設數據緩存區中讀取語音數據。
可選地,所述語音遙控器還包括:
獲取模塊,用于獲取用戶觸發語音采集指令的時間,記為開始時間;
記錄模塊,用于當接收到用戶觸發的采集停止指令,記錄停止時間;
計算模塊,用于根據所述開始時間、所述停止時間和預設比特率計算獲得完整錄音數據的字節數。
可選地,所述計算模塊,還用于根據從所述預設數據緩存區中讀取語音數據的次數計算延遲時間;
所述判斷模塊,還用于判斷所述延遲時間是否大于預設時間;
所述停止模塊,還用于若所述延遲時間大于所述預設時間,則停止讀取所述預設數據緩存區中的語音數據。
本發明在接收到用戶觸發的采集指令后,對用戶的語音進行采集,當接收到用戶觸發的采集停止指令時,繼續對用戶的語音進行采集,直至采集獲得的錄音數據為完整錄音數據時,停止對用戶的語音進行采集,本方案在接收到用戶觸發的采集停止指令時,繼續對用戶的語音進行采集直至采集獲得的錄音數據為完整錄音數據,因此本發明能夠保證錄音數據的完整性,使得尾音不丟失,可以準確有效的識別用戶的語音。
附圖說明
圖1為本發明尾音識別方法第一實施例的流程示意圖;
圖2為本發明第二實施例中所述根據用戶觸發的采集指令對用戶的語音進行采集步驟的細化流程示意圖;
圖3為本發明尾音識別方法第三實施例的流程示意圖;
圖4為本發明尾音識別方法第四實施例流程示意圖;
圖5為本發明尾音識別方法第五實施例的流程示意圖;
圖6為本發明語音遙控器第一實施例的功能模塊示意圖;
圖7為本發明第二實施例中所述采集模塊的細化功能模塊示意圖;
圖8為本發明語音遙控器第三實施例的功能模塊示意圖;
圖9為本發明語音遙控器第四實施例的功能模塊示意圖。
本發明目的的實現、功能特點及優點將結合實施例,參照附圖做進一步說明。
具體實施方式
應當理解,此處所描述的具體實施例僅僅用以解釋本發明,并不用于限定本發明。
本發明提供一種尾音識別方法。
參照圖1,圖1為本發明尾音識別方法第一實施例的流程示意圖。
在本實施例中,該尾音識別方法包括:
步驟S10,根據用戶觸發的采集指令對用戶的語音進行采集;
用戶在所述語音遙控器上按下錄音按鍵,此時所述遙控器接收到錄音按鍵的狀態的為down,從而獲取觸發的語音采集指令,然后根據所述語音采集指令啟動所述語音遙控器的錄音功能,并消除歷史錄音數據,為保存新的錄音數據做準備,然后語音遙控器對用戶的語音數據進行采集,同時監聽采集獲得的語音數據,判斷采集獲得的語音數據是否異常。具體實施中,當用戶用手指按下所述錄音按鍵,即處于down狀態,在很短的時間內移開手指,使得所述錄音按鍵處于up狀態,所述語音遙控器不啟動錄音功能。在更多的實施中,用戶連續按下按上所述錄音按鍵,即所述錄音按鍵的狀態在down狀態和up狀態之間來回變化時,所述語音遙控器也不啟動錄音功能。
步驟S20,當接收到用戶觸發的采集停止指令時,繼續對用戶的語音進行采集,并判斷通過采集獲得的總錄音數據是否為完整錄音數據;
所述遙控器接收到用戶觸發的采集停止指令,即所述遙控器中的錄音按鍵處于up狀態時,此時由于遙控器外層有外殼阻擋和周圍網絡環境的影響等,用戶的語音數據會延遲傳輸,因此不會立即停止對用戶的語音進行采集,所述遙控器繼續對用戶的語音進行采集,獲得總錄音數據,然后判斷此時所述數據采集模塊采集獲得的總錄音數據是否為完整錄音數據。具體實施中,可根據預設算法獲得的完整錄音數據的字節數,然后判斷該總錄音數據的字節數是否與完整錄音數據的字節數相等,從而判斷該總錄音數據是否為完整錄音數據。所述預設算法是人為設置的,可以根據不同的實際情況進行不同的設置。所述完整錄音數據的字節數是通過預設算法得到的,即要保證錄音數據的完整性需要獲取的語音數據字節數的大小,只有當獲取的語音數據的字節數與完整錄音數據的字節數相等,則可以保證錄音數據的完整性。在更多的實施中,可預設數據緩存區,將采集獲得數據緩存在該數據緩存區中,然后讀取固定大小的語音數據,當讀取完該數據緩存區中的語音數據時,讀取獲得的語音數據即可判定為完整錄音數據。
步驟S30,若所述總錄音數據不為所述完整錄音數據,則繼續對用戶的語音進行采集,直至所述總錄音數據為完整錄音數據時,停止對用戶的語音進行采集。
通過判斷得到所述語音遙控器采集獲得的總錄音數據不為所述完整錄音數據,則繼續對用戶的語音進行采集,直至語音遙控器采集獲得的總錄音數據為完整錄音數據時,停止對用戶的語音進行采集,從而保證錄音數據的完整性。
在本實施例中,本發明在接收到用戶觸發的采集指令后,對用戶的語音進行采集,當接收到用戶觸發的采集停止指令時,繼續對用戶的語音進行采集,直至采集獲得的錄音數據為完整錄音數據時,停止對用戶的語音進行采集,本方案在接收到用戶觸發的采集停止指令時,繼續對用戶的語音進行采集直至采集獲得的錄音數據為完整錄音數據,因此本發明能夠保證錄音數據的完整性,使得尾音不丟失,可以準確有效的識別用戶的語音。
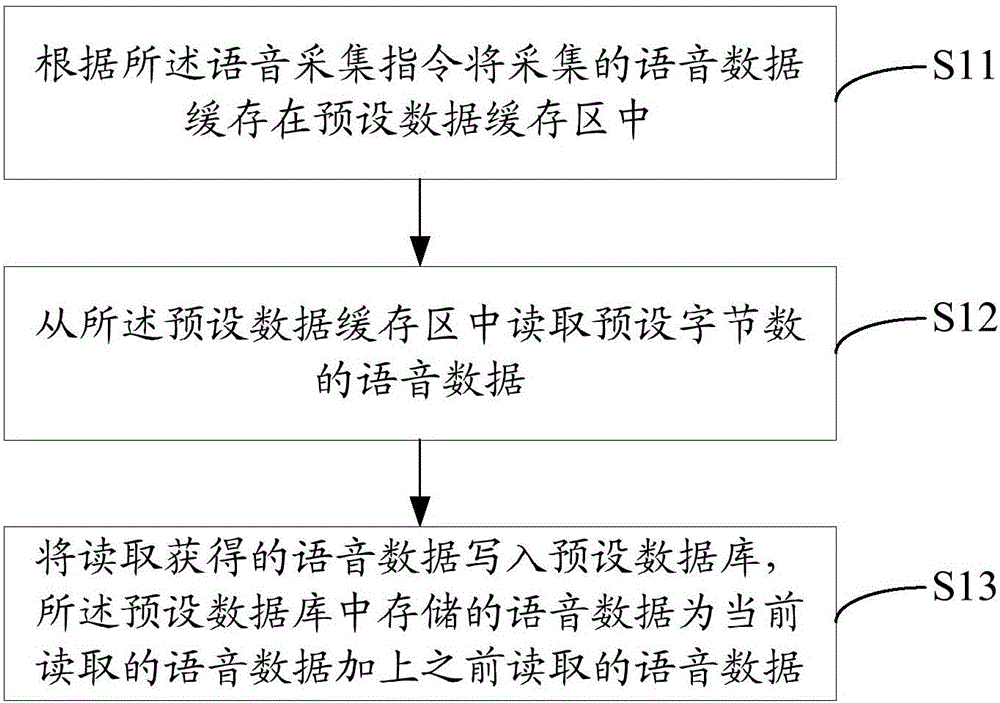
進一步地,參照圖2,基于上述第一實施例可得本發明發明尾音識別方法第二實施例中所述步驟S10的細化流程示意圖,在本實施例中,所述步驟S10包括:
步驟S11,根據所述語音采集指令將采集的語音數據緩存在預設數據緩存區中;
所述語音遙控器接收到用戶觸發的語音采集指令后,即所述語音遙控器中的錄音按鍵處于down狀態,根據所述語音采集指令傳輸到啟動所述語音遙控器的錄音功能。在本實施例中,所述語音遙控器中預設有語音數據緩存區,用于緩存采集獲得的語音數據,即根據所述語音采集指令先將用戶的語音數據緩存在預設數據緩存區中。
步驟S12,從所述預設數據緩存區中讀取預設字節數的語音數據;
所述語音遙控器將用戶的語音數據緩存在所述預設數據緩存區中后,所述語音遙控器從所述預設數據緩存區中讀取預設字節數的語音數據,即讀取固定大小的語音數據。所述預設字節數可以認為設置,具體實施中,可通過多次試驗獲得不同實際情況下的最優值,當然也可以設置一個普遍的值,提高所述語音遙控器的兼容性。所述語音遙控器在所述預設緩存區讀取語音數據的同時,所述預設緩存區可緩存用戶的語音數據,即緩存和讀取可同時進行。當然也可以在用戶的語音數據緩存完之后,再從預設數據緩存區中讀取語音數據。具體實施中,當所述數據緩存區中的語音數據的字節數小于預設字節數時,所述語音遙控器讀取該語音數據后,需記錄該語音數據的字節數,即記錄實際讀取獲得的語音數據的字節數。
步驟S13,將讀取獲得的語音數據寫入預設數據庫,所述預設數據庫中存儲的語音數據為當前讀取的語音數據加上之前讀取的語音數據。
所述語音遙控器讀取獲得語音數據后,將讀取獲得的語音數據寫入預設數據庫,所述預設數據庫用于存儲讀取獲得的語音數據,包括當前讀取的語音數據和之前讀取的語音數據,即所述預設數據庫中的語音數據為當前讀取的語音數據和之前讀取的語音數據之和。具體實施中,在事件完成之后,所述預設數據庫中的語音數據以及所述預設緩存區中的語音數據都會清空,便于下一次采集,當然也可以在下一次采集開始時,清空歷史語音數。
在本實施例中,本發明該語音遙控器中預設有語音數據緩存區,可將用戶的語音數據進行緩存,然后所述語音遙控器從所述數據緩存區中讀取固定大小的語音數據,并將其寫入預設數據庫中,使得所述預設數據庫中的語音數據為當前讀取的語音數據和之前讀取的語音數據之和,因此本發明能夠在緩存用戶的語音數據的同時,讀取獲得語音數據,減少采集時間。
進一步地,參照圖3,基于上述第一或第二實施例可得本發明尾音識別方法第三實施例的流程示意圖,在本實施例中,所述步驟S20包括:
步驟S21,判斷所述預設數據庫中存儲的語音數據的字節數是否等于所述完整錄音數據的字節數;
所述語音遙控器在接收到用戶觸發的采集停止指令后,即所述錄音按鍵的狀態處于up狀態,繼續對用戶的語音進行采集,所述語音遙控器從所述預設數據緩存區中讀取語音數據后,判斷所述預設數據庫中存儲的語音數據的字節數是否等于所述完整錄音數據的字節數。
所述步驟S30包括:
若所述預設數據庫中存儲的語音數據的字節數小于所述完整錄音數據的字節數,則執行步驟S12,即從所述預設數據緩存區中讀取預設字節數的語音數據;
步驟S31,若所述預設數據庫中存儲的語音數據的字節數等于所述完整錄音數據的字節數,則停止從所述預設數據緩存區中讀取語音數據。
所述語音遙控器通過判斷發現所述預設數據庫中存儲的語音數據的字節數小于所述完整錄音數據的字節數,則執行步驟S12:從所述預設數據緩存區中讀取預設字節數的語音數據,即繼續對用戶的語音進行采集,然后將讀取獲得的語音數據寫入預設數據庫,所述預設數據庫中存儲的語音數據為當前讀取的語音數據加上之前讀取的語音數據,在所述預設數據庫中存儲的語音數據的字節數等于所述完整錄音數據的字節數,則停止從所述預設數據緩存區中讀取語音數據。
在本實施例中,本發明在接收到用戶觸發的采集停止指令后,所述語音遙控器繼續從所述預設數據緩存區中讀取語音數據,然后判斷所述預設數據庫中存儲的語音數據的字節數是否等于所述完整錄音數據的字節數,若等于,則停止讀取,若小于,則繼續讀取,本方案通過在預設數據緩存區緩存語音數據和讀取語音數據,并在觸發停止指令時,繼續讀取語音數據,可快速采集用戶的語音數據,也能夠有效的保證錄音數據的完整性。
進一步地,參照圖4,基于上述第一、第二或第三實施例可得本發明尾音識別方法第四實施例流程示意圖,在本實施例中,所述步驟S20之前,所述尾音識別方法還包括:
步驟S40,獲取用戶觸發語音采集指令的時間,記為開始時間;
所述語音遙控器接收到用戶觸發的數據采集指令,即所述語音遙控器中的錄音按鍵處于down狀態,此時記錄用戶觸發語音采集指令的時間,該時間為數據采集的開始時間。
步驟S50,當接收到用戶觸發的采集停止指令,記錄停止時間;
所述語音遙控器接收到用戶觸發的采集停止指令,即所述語音遙控器中的錄音按鍵處于up狀態,此時記錄用戶觸發采集停止指令的時間,該時間為采集停止時間,但所述所述語音遙控器繼續從所述預設數據緩存區中讀取語音數據。
步驟S60,根據所述開始時間、所述停止時間和預設比特率計算獲得完整錄音數據的字節數。
所述所述語音遙控器獲得所述開始時間、所述停止時間和預設比特率后,可根據所述開始時間、所述停止時間和預設比特率計算完整錄音數據的字節數,即根據開始時間和停止時間計算獲得采集時間,然后采集時間與預設比特率相乘可以得到完整錄音數據的字節數,在該總錄音數據的字節數等于所述完整錄音數據的字節數時,判定所述總錄音數據為所述完整錄音數據。所述預設比特率可以通過多次試驗獲得最優值。在本實施例中,所述預設比特率為每毫秒1600字節。
在本實施例中,本發明根據采集語音數據的開始時間和停止時間可以得到采集時間,然后將所述采集時間與預設比特率相乘得到完整錄音數據的字節數,在該總錄音數據的字節數等于完整錄音數據的字節數時,判定所述總錄音數據為所述完整錄音數據,本發明通過計算完整錄音數據的字節數,可快速判定總錄音數據的完整性,增強語音識別的準確度。
進一步地,參照圖5,基于上述第一、第二、第三或第四實施例可得本發明尾音識別方法第五實施例的流程示意圖,在本實施例中,所述尾音識別方法還包括:
步驟S70,根據從所述預設數據緩存區中讀取語音數據的次數計算延遲時間;
步驟S80,判斷所述延遲時間是否大于預設時間;
步驟S90,若所述延遲時間大于所述預設時間,則停止讀取所述預設數據緩存區中的語音數據。
所述語音遙控器從所述預設數據緩存區中讀取語音數據的次數,根據所述次數計算延遲時間,然后判斷所述延遲時間是否大于預設時間,若所述延遲時間大于所述預設時間,則停止讀取所述預設數據緩存區中的語音數據,則所述所述語音遙控器判定當前的語音數據的狀態為異常,并停止讀取所述預設數據緩存區中的語音數據,
在本實施例中,本發明所述語音遙控器獲取從所述預設數據緩存區中讀取語音數據的次數,并根據該次數計算延遲時間,在該延遲時間大于所述預設時間時,停止讀取所述預設數據緩存區中的語音數據,本發明通過預設時間驗證延遲時間的有效性,能夠在異常情況下,立即停止采集語音,不會造成時間的浪費。
本發明進一步提供一種語音遙控器。
參照圖6,圖6為本發明語音遙控器第一實施例的功能模塊示意圖。
在本實施例中,該語音遙控器包括:
采集模塊10,用于根據用戶觸發的采集指令對用戶的語音進行采集;
用戶在所述語音遙控器上按下錄音按鍵,此時所述遙控器接收到錄音按鍵的狀態的為down,從而獲取觸發的語音采集指令,然后根據所述語音采集指令啟動所述語音遙控器的錄音功能,并消除歷史錄音數據,為保存新的錄音數據做準備,然后語音遙控器對用戶的語音數據進行采集,同時監聽采集獲得的語音數據,判斷采集獲得的語音數據是否異常。具體實施中,當用戶用手指按下所述錄音按鍵,即處于down狀態,在很短的時間內移開手指,使得所述錄音按鍵處于up狀態,所述語音遙控器不啟動錄音功能。在更多的實施中,用戶連續按下按上所述錄音按鍵,即所述錄音按鍵的狀態在down狀態和up狀態之間來回變化時,所述語音遙控器也不啟動錄音功能。
所述采集模塊10,還用于當接收到用戶觸發的采集停止指令時,繼續對用戶的語音進行采集,并判斷通過采集獲得的總錄音數據是否為完整錄音數據;
所述遙控器接收到用戶觸發的采集停止指令,即所述遙控器中的錄音按鍵處于up狀態時,此時由于遙控器外層有外殼阻擋和周圍網絡環境的影響等,用戶的語音數據會延遲傳輸,因此不會立即停止對用戶的語音進行采集,所述遙控器繼續對用戶的語音進行采集,獲得總錄音數據,然后判斷此時所述數據采集模塊采集獲得的總錄音數據是否為完整錄音數據。具體實施中,可根據預設算法獲得的完整錄音數據的字節數,然后判斷該總錄音數據的字節數是否與完整錄音數據的字節數相等,從而判斷該總錄音數據是否為完整錄音數據。所述預設算法是人為設置的,可以根據不同的實際情況進行不同的設置。所述完整錄音數據的字節數是通過預設算法得到的,即要保證錄音數據的完整性需要獲取的語音數據字節數的大小,只有當獲取的語音數據的字節數與完整錄音數據的字節數相等,則可以保證錄音數據的完整性。在更多的實施中,可預設數據緩存區,將采集獲得數據緩存在該數據緩存區中,然后讀取固定大小的語音數據,當讀取完該數據緩存區中的語音數據時,讀取獲得的語音數據即可判定為完整錄音數據。
停止模塊20,用于若所述總錄音數據不為所述完整錄音數據,則繼續對用戶的語音進行采集,直至所述總錄音數據為完整錄音數據時,停止對用戶的語音進行采集。
通過判斷獲得所述語音遙控器中的數據采集模塊采集獲得的總錄音數據不為所述完整錄音數據,則繼續對用戶的語音進行采集,直至數據采集模塊采集獲得的總錄音數據為完整錄音數據時,停止對用戶的語音進行采集,從而保證錄音數據的完整性。
在本實施例中,本發明在接收到用戶觸發的采集指令后,對用戶的語音進行采集,當接收到用戶觸發的采集停止指令時,繼續對用戶的語音進行采集,直至采集獲得的錄音數據為完整錄音數據時,停止對用戶的語音進行采集,本方案在接收到用戶觸發的采集停止指令時,繼續對用戶的語音進行采集直至采集獲得的錄音數據為完整錄音數據,因此本發明能夠保證錄音數據的完整性,使得尾音不丟失,可以準確有效的識別用戶的語音。
進一步地,參照圖7,基于上述第一實施例可得本發明發明語音遙控器第二實施例中所述采集模塊的細化功能模塊示意圖,基于上述實施例,在本實施例中,所述采集模塊10包括:
緩存單元11,用于根據所述語音采集指令將采集的語音數據緩存在預設數據緩存區中;
所述語音遙控器接收到用戶觸發的語音采集指令后,即所述語音遙控器中的錄音按鍵處于down狀態,根據所述語音采集指令傳輸到啟動所述語音遙控器的錄音功能。在本實施例中,所述語音遙控器中預設有語音數據緩存區,用于緩存采集獲得的語音數據,即根據所述語音采集指令先將用戶的語音數據緩存在預設數據緩存區中。
讀取單元12,用于從所述預設數據緩存區中讀取預設字節數的語音數據;
所述語音遙控器將用戶的語音數據緩存在所述預設數據緩存區中后,所述語音遙控器從所述預設數據緩存區中讀取預設字節數的語音數據,即讀取固定大小的語音數據。所述預設字節數可以認為設置,具體實施中,可通過多次試驗獲得不同實際情況下的最優值,當然也可以設置一個普遍的值,提高所述語音遙控器的兼容性。所述語音遙控器在所述預設緩存區讀取語音數據的同時,所述預設緩存區可緩存用戶的語音數據,即緩存和讀取可同時進行。當然也可以在用戶的語音數據緩存完之后,再從預設數據緩存區中讀取語音數據。具體實施中,當所述數據緩存區中的語音數據的字節數小于預設字節數時,所述語音遙控器讀取該語音數據后,需記錄該語音數據的字節數,即記錄實際讀取獲得的語音數據的字節數。
寫入單元13,用于將讀取獲得的語音數據寫入預設數據庫,所述預設數據庫中存儲的語音數據為當前讀取的語音數據加上之前讀取的語音數據。
所述語音遙控器讀取獲得語音數據后,將讀取獲得的語音數據寫入預設數據庫,所述預設數據庫用于存儲讀取獲得的語音數據,包括當前讀取的語音數據和之前讀取的語音數據,即所述預設數據庫中的語音數據為當前讀取的語音數據和之前讀取的語音數據之和。具體實施中,在事件完成之后,所述預設數據庫中的語音數據以及所述預設緩存區中的語音數據都會清空,便于下一次采集,當然也可以在下一次采集開始時,清空歷史語音數。
在本實施例中,本發明該語音遙控器中預設有語音數據緩存區,可將用戶的語音數據進行緩存,然后所述語音遙控器從所述數據緩存區中讀取固定大小的語音數據,并將其寫入預設數據庫中,使得所述預設數據庫中的語音數據為當前讀取的語音數據和之前讀取的語音數據之和,因此本發明能夠在緩存用戶的語音數據的同時,讀取獲得語音數據,減少采集時間。
進一步地,參照圖8,基于上述第一或第二實施例可得本發明語音遙控器第三實施例的功能模塊示意圖,在本實施例中,所述語音遙控器還包括:
判斷模塊30,用于判斷所述預設數據庫中存儲的語音數據的字節數是否等于所述完整錄音數據的字節數;
所述語音遙控器在接收到用戶觸發的采集停止指令后,即所述錄音按鍵的狀態處于up狀態,繼續對用戶的語音進行采集,所述語音遙控器從所述預設數據緩存區中讀取語音數據后,判斷所述預設數據庫中存儲的語音數據的字節數是否等于所述完整錄音數據的字節數。
所述讀取單元12,還用于若所述預設數據庫中存儲的語音數據的字節數小于所述完整錄音數據的字節數,則返回所述讀取單元,用于從所述預設數據緩存區中讀取預設字節數的語音數據;
所述停止模塊20,還用于若所述預設數據庫中存儲的語音數據的字節數等于所述完整錄音數據的字節數,則停止從所述預設數據緩存區中讀取語音數據。
所述語音遙控器通過判斷發現所述預設數據庫中存儲的語音數據的字節數小于所述完整錄音數據的字節數,則返回所述讀取單元12,用于從所述預設數據緩存區中讀取預設字節數的語音數據,即繼續對用戶的語音進行采集,然后將讀取獲得的語音數據寫入預設數據庫,所述預設數據庫中存儲的語音數據為當前讀取的語音數據加上之前讀取的語音數據,在所述預設數據庫中存儲的語音數據的字節數等于所述完整錄音數據的字節數,則停止從所述預設數據緩存區中讀取語音數據。
在本實施例中,本發明在接收到用戶觸發的采集停止指令后,所述語音遙控器繼續從所述預設數據緩存區中讀取語音數據,然后判斷所述預設數據庫中存儲的語音數據的字節數是否等于所述完整錄音數據的字節數,若等于,則停止讀取,若小于,則繼續讀取,本方案通過在預設數據緩存區緩存語音數據和讀取語音數據,并在觸發停止指令時,繼續讀取語音數據,可快速采集用戶的語音數據,也能夠有效的保證錄音數據的完整性。
進一步地,參照圖9,基于上述第一、第二或第三實施例可得本發明語音遙控器第四實施例的功能模塊示意圖,在本實施例中,所述語音遙控器還包括:
獲取模塊40,用于獲取用戶觸發語音采集指令的時間,記為開始時間;
所述語音遙控器接收到用戶觸發的數據采集指令,即所述語音遙控器中的錄音按鍵處于down狀態,此時記錄用戶觸發語音采集指令的時間,該時間為數據采集的開始時間。
記錄模塊50,用于當接收到用戶觸發的采集停止指令,記錄停止時間;
所述語音遙控器接收到用戶觸發的采集停止指令,即所述語音遙控器中的錄音按鍵處于up狀態,此時記錄用戶觸發采集停止指令的時間,該時間為采集停止時間,但所述語音遙控器繼續從所述預設數據緩存區中讀取語音數據。
計算模塊60,用于根據所述開始時間、所述停止時間和預設比特率計算獲得完整錄音數據的字節數。
所述所述語音遙控器獲得所述開始時間、所述停止時間和預設比特率后,可根據所述開始時間、所述停止時間和預設比特率計算完整錄音數據的字節數,即根據開始時間和停止時間計算獲得采集時間,然后采集時間與預設比特率相乘可以得到完整錄音數據的字節數。所述預設比特率可以通過多次試驗獲得最優值。在本實施例中,所述預設比特率為每毫秒1600字節。
在本實施例中,本發明根據采集語音數據的開始時間和停止時間可以得到采集時間,然后將所述采集時間與預設比特率相乘得到完整錄音數據的字節數,在該總錄音數據的字節數等于完整錄音數據的字節數時,判定所述總錄音數據為所述完整錄音數據,本發明通過計算完整錄音數據的字節數,可快速判定總錄音數據的完整性,增強語音識別的準確度。
進一步地,基于上述第一、第二、第三或第四實施例可得本發明語音遙控器第五實施例,在本實施例中,所述計算模塊60,用于根據所述語音遙控器中的數據采集模塊從所述預設數據緩存區中讀取語音數據的次數計算延遲時間;
所述判斷模塊30,用于判斷所述延遲時間是否大于預設時間;
所述停止模塊20,用于若所述延遲時間大于所述預設時間,則停止讀取所述預設數據緩存區中的語音數據。
所述語音遙控器從所述預設數據緩存區中讀取語音數據的次數,根據所述次數計算延遲時間,然后判斷所述延遲時間是否大于預設時間,若所述延遲時間大于所述預設時間,則停止讀取所述預設數據緩存區中的語音數據,則所述所述語音遙控器判定當前的語音數據的狀態為異常,并停止讀取所述預設數據緩存區中的語音數據,
在本實施例中,本發明所述語音遙控器獲取從所述預設數據緩存區中讀取語音數據的次數,并根據該次數計算延遲時間,在該延遲時間大于所述預設時間時,停止讀取所述預設數據緩存區中的語音數據,本發明通過預設時間驗證延遲時間的有效性,能夠在異常情況下,立即停止采集語音,不會造成時間的浪費。
以上僅為本發明的優選實施例,并非因此限制本發明的專利范圍,凡是利用本發明說明書及附圖內容所作的等效結構或等效流程變換,或直接或間接運用在其他相關的技術領域,均同理包括在本發明的專利保護范圍內。
- 還沒有人留言評論。精彩留言會獲得點贊!