一種基于深度學(xué)習(xí)的智慧視聽設(shè)備多業(yè)務(wù)控制方法及系統(tǒng)與流程
本發(fā)明涉及智慧視聽設(shè)備多業(yè)務(wù)控制技術(shù)領(lǐng)域,尤其涉及一種基于深度學(xué)習(xí)的智慧視聽設(shè)備多業(yè)務(wù)控制方法及系統(tǒng)。
背景技術(shù):
隨著物聯(lián)網(wǎng)和人工智能技術(shù)的進(jìn)步,智慧視聽設(shè)備技術(shù)迅速發(fā)展。越來越多的智慧視聽設(shè)備被設(shè)計(jì)生產(chǎn)出來,實(shí)現(xiàn)了各種多媒體視聽業(yè)務(wù),以滿足人們生活中的不同需求。由不同廠商設(shè)計(jì)生產(chǎn)的設(shè)備有著不同的控制和人機(jī)交互方式。這些設(shè)備可能采用紅外、藍(lán)牙、Z-wave等各種控制方式,以語音、動(dòng)作、觸控等方式實(shí)現(xiàn)人機(jī)交互。智慧視聽設(shè)備控制和人機(jī)交互方式的不統(tǒng)一提高了用戶學(xué)習(xí)使用智慧視聽設(shè)備的門檻,且易造成用戶體驗(yàn)不佳的問題。融合多種業(yè)務(wù)場景、為這些智慧視聽設(shè)備提供一種統(tǒng)一、輕松自然的控制和人機(jī)交互方式是一個(gè)亟待解決的問題。
深度學(xué)習(xí)是人工智能的子領(lǐng)域。近年來,隨著圖形處理器(Graphics Processing Unit,GPU)、云計(jì)算等技術(shù)的進(jìn)步,深度學(xué)習(xí)理論研究取得了突破性進(jìn)展。與此同時(shí),深度學(xué)習(xí)技術(shù)的引入使得計(jì)算機(jī)視覺、語音識(shí)別等領(lǐng)域突飛猛進(jìn)。這也為智慧視聽設(shè)備控制技術(shù)帶來了新的思路。
現(xiàn)有一種基于音頻和視頻的智能家居自然交互系統(tǒng)[1],使用麥克風(fēng)和攝像頭采集聲音和圖像信息,使用信息融合模塊進(jìn)行信號(hào)處理,然后使用機(jī)器學(xué)習(xí)方法獲取有用指令,再使用控制信號(hào)發(fā)射模塊發(fā)出控制信號(hào)。
該系統(tǒng)使用語音、手勢、人臉、動(dòng)作多種等信息來進(jìn)行控制,不能為用戶提供一種簡單統(tǒng)一的交互方式,造成用戶掌握系統(tǒng)使用的學(xué)習(xí)成本高,用戶體驗(yàn)不佳等問題。其采用傳統(tǒng)機(jī)器學(xué)習(xí)方法來識(shí)別語音、圖像等多媒體信息,使得其識(shí)別率較低,系統(tǒng)健壯性較差。并且其語音、圖像識(shí)別程序運(yùn)行于本地,這增加了用戶的硬件和能源成本。
技術(shù)實(shí)現(xiàn)要素:
本發(fā)明的目的在于克服現(xiàn)有技術(shù)的不足,本發(fā)明提供了一種基于深度學(xué)習(xí)的智慧視聽設(shè)備多業(yè)務(wù)控制方法及系統(tǒng),可控制多種基于不同控制協(xié)議、實(shí)現(xiàn)多種不同業(yè)務(wù)的智慧視聽設(shè)備,為它們提供一種更統(tǒng)一、更自然的人機(jī)交互和控制的方式。
為了解決上述問題,本發(fā)明提出了一種基于深度學(xué)習(xí)的智慧視聽設(shè)備多業(yè)務(wù)控制方法,所述方法包括:
麥克風(fēng)陣列以特定頻率監(jiān)聽采集用戶發(fā)出的語音控制信號(hào);
語音預(yù)處理模塊對語音控制信號(hào)進(jìn)行提取,獲得梅爾倒譜系數(shù)(Mel-scale Frequency Cepstral Coefficients,MFCC)原始語音特征信息;檢測MFCC原始語音特征的對數(shù)能量是否大于閾值;若是,則由互聯(lián)網(wǎng)連接模塊發(fā)送MFCC原始語音特征信息到遠(yuǎn)程圖形處理器(Graphics Processing Unit,GPU)服務(wù)器;
遠(yuǎn)程GPU服務(wù)器接收到MFCC原始語音特征信息,根據(jù)MFCC原始語音特征信息獲得深度語音特征信息,并將深度特征信息對應(yīng)的控制信號(hào)標(biāo)識(shí)信息發(fā)送給互聯(lián)網(wǎng)連接模塊;
互聯(lián)網(wǎng)連接模塊將控制信號(hào)標(biāo)識(shí)信息傳遞給控制信號(hào)解析模塊,由控制信號(hào)解析模塊根據(jù)控制信號(hào)標(biāo)識(shí)信息生成控制信號(hào)編碼,選擇對應(yīng)的控制信號(hào)輸出模塊,將控制信號(hào)編碼傳遞給該控制信號(hào)輸出模塊;
控制信號(hào)輸出模塊根據(jù)控制信號(hào)編碼發(fā)送控制信號(hào)給智慧視聽設(shè)備。
優(yōu)選地,所述語音預(yù)處理模塊對語音控制信號(hào)進(jìn)行提取,獲得MFCC原始語音特征信息的步驟,包括:
對語音控制信號(hào)進(jìn)行端點(diǎn)檢測及分割處理;
對分割處理后的語音控制信號(hào)進(jìn)行降噪處理;
對降噪處理后的語音控制信號(hào)進(jìn)行MFCC原始語音特征提取,獲得MFCC原始語音特征信息。
優(yōu)選地,所述遠(yuǎn)程GPU服務(wù)器接收到MFCC原始語音特征信息,對MFCC原始語音特征信息進(jìn)行深度語音特征提取,獲得深度語音特征信息的步驟,包括:
遠(yuǎn)程GPU服務(wù)器接收到MFCC原始語音特征信息,啟動(dòng)深度學(xué)習(xí)語音識(shí)別程序,采用雙向長短時(shí)記憶循環(huán)神經(jīng)網(wǎng)絡(luò)(Bidirectional Long Short-Term Memory,biLSTM)算法對MFCC原始語音特征信息進(jìn)行深度語音特征提取,獲得深度語音特征信息。
優(yōu)選地,所述遠(yuǎn)程GPU服務(wù)器接收到MFCC原始語音特征信息,根據(jù)MFCC原始語音特征信息獲得深度語音特征信息,并將深度特征信息對應(yīng)的控制信號(hào)標(biāo)識(shí)信息發(fā)送給互聯(lián)網(wǎng)連接模塊的步驟,包括:
遠(yuǎn)程GPU服務(wù)器接收到MFCC原始語音特征信息,對MFCC原始語音特征信息進(jìn)行深度語音特征提取,獲得深度語音特征信息,并將深度特征信息對應(yīng)的控制信號(hào)標(biāo)識(shí)信息發(fā)送給互聯(lián)網(wǎng)連接模塊;
遠(yuǎn)程GPU服務(wù)器對深度語音特征信息進(jìn)行分類,得到該深度語音特征信息對應(yīng)的類別,并檢測該類別是否對應(yīng)一種控制信號(hào)標(biāo)識(shí);若是,返回控制信號(hào)標(biāo)識(shí)信息給互聯(lián)網(wǎng)連接模塊。
相應(yīng)地,本發(fā)明還提供一種基于深度學(xué)習(xí)的智慧視聽設(shè)備多業(yè)務(wù)控制系統(tǒng),所述系統(tǒng)包括:麥克風(fēng)陣列、語音預(yù)處理模塊、遠(yuǎn)程GPU服務(wù)器、互聯(lián)網(wǎng)連接模塊、控制信號(hào)解析模塊、控制信號(hào)輸出模塊;其中,
麥克風(fēng)陣列以特定頻率監(jiān)聽采集用戶發(fā)出的語音控制信號(hào);
語音預(yù)處理模塊對語音控制信號(hào)進(jìn)行提取,獲得MFCC原始語音特征信息;檢測MFCC原始語音特征的對數(shù)能量是否大于閾值;若是,則由互聯(lián)網(wǎng)連接模塊發(fā)送MFCC原始語音特征信息到遠(yuǎn)程GPU服務(wù)器;
遠(yuǎn)程GPU服務(wù)器接收到MFCC原始語音特征信息,根據(jù)MFCC原始語音特征信息獲得深度語音特征信息,并將深度特征信息對應(yīng)的控制信號(hào)標(biāo)識(shí)信息發(fā)送給互聯(lián)網(wǎng)連接模塊;
互聯(lián)網(wǎng)連接模塊將控制信號(hào)標(biāo)識(shí)信息傳遞給控制信號(hào)解析模塊,由控制信號(hào)解析模塊根據(jù)控制信號(hào)標(biāo)識(shí)信息生成控制信號(hào)編碼,選擇對應(yīng)的控制信號(hào)輸出模塊,將控制信號(hào)編碼傳遞給該控制信號(hào)輸出模塊;
控制信號(hào)輸出模塊根據(jù)控制信號(hào)編碼發(fā)送控制信號(hào)給智慧視聽設(shè)備。
優(yōu)選地,所述語音預(yù)處理模塊包括:
分割單元,用于對語音控制信號(hào)進(jìn)行端點(diǎn)檢測及分割處理;
降噪單元,用于對分割處理后的語音控制信號(hào)進(jìn)行降噪處理;
提取單元,用于對降噪處理后的語音控制信號(hào)進(jìn)行MFCC原始語音特征提取,獲得MFCC原始語音特征信息。
優(yōu)選地,所述遠(yuǎn)程GPU服務(wù)器接收到MFCC原始語音特征信息,啟動(dòng)深度學(xué)習(xí)語音識(shí)別程序,采用biLSTM算法對MFCC原始語音特征信息進(jìn)行深度語音特征提取,獲得深度語音特征信息。
優(yōu)選地,遠(yuǎn)程GPU服務(wù)器接收到MFCC原始語音特征信息,對MFCC原始語音特征信息進(jìn)行深度語音特征提取,獲得深度語音特征信息,并將深度特征信息對應(yīng)的控制信號(hào)標(biāo)識(shí)信息發(fā)送給互聯(lián)網(wǎng)連接模塊;
遠(yuǎn)程GPU服務(wù)器對深度語音特征信息進(jìn)行分類,得到該深度語音特征信息對應(yīng)的類別,并檢測該類別是否對應(yīng)一種控制信號(hào)標(biāo)識(shí);若是,返回控制信號(hào)標(biāo)識(shí)信息給互聯(lián)網(wǎng)連接模塊。
實(shí)施本發(fā)明實(shí)施例,可使用自然語音控制多種基于不同控制協(xié)議、實(shí)現(xiàn)多種不同業(yè)務(wù)的智慧視聽設(shè)備,為智慧視聽設(shè)備提供一種統(tǒng)一、自然、高效、低成本的人機(jī)交互方式;同時(shí)將復(fù)雜的深度學(xué)習(xí)任務(wù)部署在遠(yuǎn)程服務(wù)器上,降低了用戶的硬件和能源成本,為用戶提供高性能、低成本的智慧視聽設(shè)備語音控制指令識(shí)別服務(wù),提高智慧視聽設(shè)備語音控制指令的識(shí)別準(zhǔn)確率。
附圖說明
為了更清楚地說明本發(fā)明實(shí)施例或現(xiàn)有技術(shù)中的技術(shù)方案,下面將對實(shí)施例或現(xiàn)有技術(shù)描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發(fā)明的一些實(shí)施例,對于本領(lǐng)域普通技術(shù)人員來講,在不付出創(chuàng)造性勞動(dòng)的前提下,還可以根據(jù)這些附圖獲得其它的附圖。
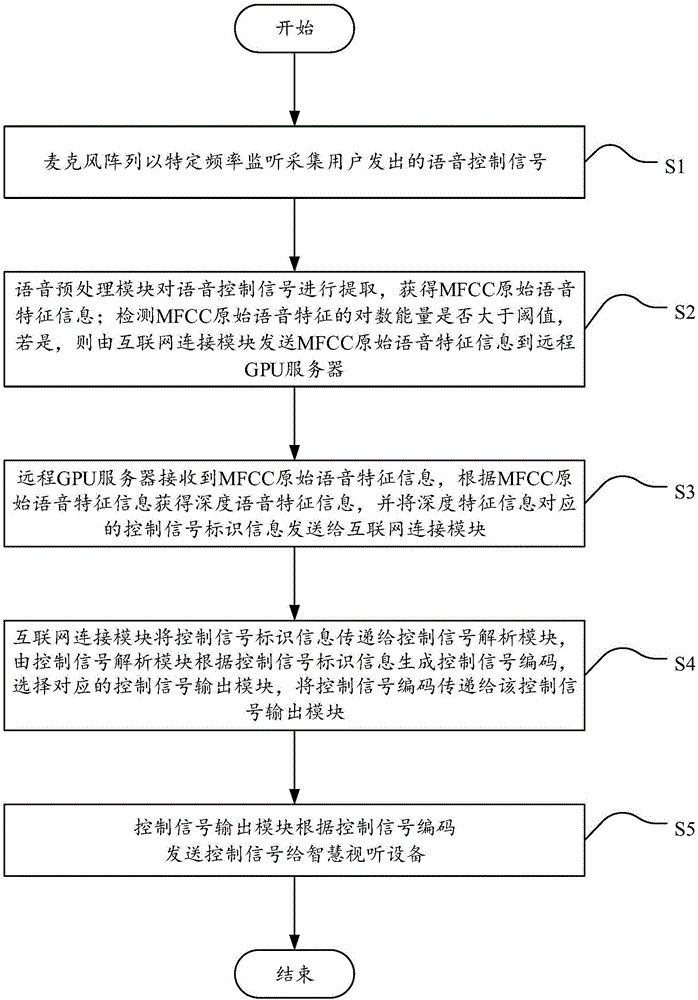
圖1是本發(fā)明實(shí)施例的基于深度學(xué)習(xí)的智慧視聽設(shè)備多業(yè)務(wù)控制方法的流程示意圖;
圖2是本發(fā)明實(shí)施例中深度學(xué)習(xí)語音識(shí)別模型的示意圖;
圖3是本發(fā)明實(shí)施例的基于深度學(xué)習(xí)的智慧視聽設(shè)備多業(yè)務(wù)控制及系統(tǒng)的結(jié)構(gòu)組成示意圖。
具體實(shí)施方式
下面將結(jié)合本發(fā)明實(shí)施例中的附圖,對本發(fā)明實(shí)施例中的技術(shù)方案進(jìn)行清楚、完整地描述,顯然,所描述的實(shí)施例僅僅是本發(fā)明一部分實(shí)施例,而不是全部的實(shí)施例。基于本發(fā)明中的實(shí)施例,本領(lǐng)域普通技術(shù)人員在沒有作出創(chuàng)造性勞動(dòng)前提下所獲得的所有其他實(shí)施例,都屬于本發(fā)明保護(hù)的范圍。
圖1是本發(fā)明實(shí)施例的基于深度學(xué)習(xí)的智慧視聽設(shè)備多業(yè)務(wù)控制方法的流程示意圖,如圖1所示,該方法包括:
S1,麥克風(fēng)陣列以特定頻率監(jiān)聽采集用戶發(fā)出的語音控制信號(hào);
S2,語音預(yù)處理模塊對語音控制信號(hào)進(jìn)行提取,獲得MFCC原始語音特征信息;檢測MFCC原始語音特征的對數(shù)能量是否大于閾值;若是,則由互聯(lián)網(wǎng)連接模塊發(fā)送MFCC原始語音特征信息到遠(yuǎn)程GPU服務(wù)器;若否,則返回S1;
S3,遠(yuǎn)程GPU服務(wù)器接收到MFCC原始語音特征信息,根據(jù)MFCC原始語音特征信息獲得深度語音特征信息,并將深度特征信息對應(yīng)的控制信號(hào)標(biāo)識(shí)信息發(fā)送給互聯(lián)網(wǎng)連接模塊;
S4,互聯(lián)網(wǎng)連接模塊將控制信號(hào)標(biāo)識(shí)信息傳遞給控制信號(hào)解析模塊,由控制信號(hào)解析模塊根據(jù)控制信號(hào)標(biāo)識(shí)信息生成控制信號(hào)編碼,選擇對應(yīng)的控制信號(hào)輸出模塊,將控制信號(hào)編碼傳遞給該控制信號(hào)輸出模塊;
S5,控制信號(hào)輸出模塊根據(jù)控制信號(hào)編碼發(fā)送控制信號(hào)給智慧視聽設(shè)備。
在語音預(yù)處理模塊對語音控制信號(hào)進(jìn)行提取,獲得MFCC原始語音特征信息的過程中,包括:
對語音控制信號(hào)進(jìn)行端點(diǎn)檢測及分割處理;
對分割處理后的語音控制信號(hào)進(jìn)行降噪處理;
對降噪處理后的語音控制信號(hào)進(jìn)行MFCC原始語音特征提取,獲得MFCC原始語音特征信息。
具體地,在S3中,遠(yuǎn)程GPU服務(wù)器接收到MFCC原始語音特征信息,啟動(dòng)深度學(xué)習(xí)語音識(shí)別程序,采用biLSTM算法對MFCC原始語音特征信息進(jìn)行深度語音特征提取,獲得深度語音特征信息。
進(jìn)一步地,遠(yuǎn)程GPU服務(wù)器接收到MFCC原始語音特征信息,對MFCC原始語音特征信息進(jìn)行深度語音特征提取,獲得深度語音特征信息,并將深度特征信息對應(yīng)的控制信號(hào)標(biāo)識(shí)信息發(fā)送給互聯(lián)網(wǎng)連接模塊;
遠(yuǎn)程GPU服務(wù)器對深度語音特征信息進(jìn)行分類,得到該深度語音特征信息對應(yīng)的類別,并檢測該類別是否對應(yīng)一種控制信號(hào)標(biāo)識(shí);若是,返回控制信號(hào)標(biāo)識(shí)信息給互聯(lián)網(wǎng)連接模塊;若否,則返回錯(cuò)誤標(biāo)識(shí)給互聯(lián)網(wǎng)連接模塊。
在本發(fā)明實(shí)施例中,如圖2所示,深度學(xué)習(xí)語音識(shí)別模型的主體結(jié)構(gòu)包括由一個(gè)正向長短時(shí)記憶循環(huán)神經(jīng)網(wǎng)絡(luò)和一個(gè)反向長短時(shí)記憶循環(huán)神經(jīng)網(wǎng)絡(luò)組成的biLSTM、一個(gè)Softmax分類器。該深度學(xué)習(xí)語音識(shí)別模型的輸入發(fā)送自本地互聯(lián)網(wǎng)連接單元MFCC語音特征,其輸出是T+1個(gè)類別標(biāo)識(shí)符。這些類別標(biāo)識(shí)符包括T個(gè)與本系統(tǒng)支持的控制信號(hào)一一對應(yīng)的類別,以及一個(gè)Default類別。如果模型輸出Default類別,說明該MFCC語音特征無法對應(yīng)一種對智慧視聽設(shè)備的控制信號(hào)。深度學(xué)習(xí)語音識(shí)別模型由其訓(xùn)練生成階段預(yù)先產(chǎn)生,而后被部署與遠(yuǎn)程GPU服務(wù)器上為用戶提供智慧視聽設(shè)備語音控制指令識(shí)別服務(wù)。
在具體實(shí)施中,深度學(xué)習(xí)語音識(shí)別模型的訓(xùn)練生成過程如下:
第一步:根據(jù)所需支持的智慧視聽設(shè)備種類和這些設(shè)備實(shí)現(xiàn)的業(yè)務(wù)功能,模擬真實(shí)的設(shè)備使用情境,使用麥克風(fēng)陣列收集大量語音片段;
第二步:人工標(biāo)注這些語音片段對應(yīng)的控制信號(hào)類別;
第三步:使用語音預(yù)處理模塊對所有語音片段提取MFCC語音特征,得到已標(biāo)記控制語音特征數(shù)據(jù)集;
第四步:數(shù)據(jù)集劃分,取上述已標(biāo)記控制語音特征數(shù)據(jù)集中一定量的數(shù)據(jù)組成訓(xùn)練數(shù)據(jù)集,即Training Set,一定量的數(shù)據(jù)作為驗(yàn)證數(shù)據(jù)集,即Validation Set;
第五步:隨機(jī)初始化深度學(xué)習(xí)語音識(shí)別模型中的所有參數(shù);
第六步:以訓(xùn)練數(shù)據(jù)集為輸入,執(zhí)行深度學(xué)習(xí)正向傳播過程;
第七步:采用時(shí)間反向傳播(Back Propagation Through Time,BPTT)方法執(zhí)行深度學(xué)習(xí)反向傳播過程,更新深度學(xué)習(xí)語音模型中的所有參數(shù);
第八步:若執(zhí)行周期到達(dá)驗(yàn)證周期,則使用驗(yàn)證數(shù)據(jù)集驗(yàn)證當(dāng)前的深度學(xué)習(xí)語音識(shí)別模型;
第九步:若達(dá)到訓(xùn)練的停止條件則停止訓(xùn)練,否則返回第六步。該停止條件可以是訓(xùn)練次數(shù)達(dá)到一定值,或驗(yàn)證誤差小于一定值。
相應(yīng)地,本發(fā)明實(shí)施例還提供一種基于深度學(xué)習(xí)的智慧視聽設(shè)備多業(yè)務(wù)控制系統(tǒng),如圖3所示,該系統(tǒng)包括:麥克風(fēng)陣列1、語音預(yù)處理模塊2、遠(yuǎn)程GPU服務(wù)器3、互聯(lián)網(wǎng)連接模塊4、控制信號(hào)解析模塊5、控制信號(hào)輸出模塊6;其中,
麥克風(fēng)陣列1以特定頻率監(jiān)聽采集用戶發(fā)出的語音控制信號(hào);
語音預(yù)處理模塊2對語音控制信號(hào)進(jìn)行提取,獲得MFCC原始語音特征信息;檢測MFCC原始語音特征的對數(shù)能量是否大于閾值;若是,則由互聯(lián)網(wǎng)連接模塊4發(fā)送MFCC原始語音特征信息到遠(yuǎn)程GPU服務(wù)器3;
遠(yuǎn)程GPU服務(wù)器3接收到MFCC原始語音特征信息,根據(jù)MFCC原始語音特征信息獲得深度語音特征信息,并將深度特征信息對應(yīng)的控制信號(hào)標(biāo)識(shí)信息發(fā)送給互聯(lián)網(wǎng)連接模塊4;
互聯(lián)網(wǎng)連接模塊4將控制信號(hào)標(biāo)識(shí)信息傳遞給控制信號(hào)解析模塊5,由控制信號(hào)解析模塊5根據(jù)控制信號(hào)標(biāo)識(shí)信息生成控制信號(hào)編碼,選擇對應(yīng)的控制信號(hào)輸出模塊6,將控制信號(hào)編碼傳遞給該控制信號(hào)輸出模塊6;
控制信號(hào)輸出模塊6根據(jù)控制信號(hào)編碼發(fā)送控制信號(hào)給智慧視聽設(shè)備。
在本發(fā)明實(shí)施例中,麥克風(fēng)陣列1實(shí)時(shí)采集用戶發(fā)出的語音信號(hào),并將語音信號(hào)發(fā)送給語音預(yù)處理模塊2。
語音預(yù)處理模塊2負(fù)責(zé)對語音信號(hào)進(jìn)行端點(diǎn)檢測、降噪處理、以及MFCC原始語音特征提取操作。
互聯(lián)網(wǎng)連接模塊4負(fù)責(zé)與遠(yuǎn)程GPU服務(wù)器3建立網(wǎng)絡(luò)連接、發(fā)送MFCC原始語音特征信息到遠(yuǎn)程GPU服務(wù)器3、接收來自遠(yuǎn)程GPU服務(wù)器3的反饋消息。
控制信號(hào)解析模塊5負(fù)責(zé)解析來自遠(yuǎn)程GPU服務(wù)器3的反饋消息,根據(jù)消息內(nèi)容啟用對應(yīng)的控制信號(hào)輸出模塊6,或進(jìn)行錯(cuò)誤處理。
控制信號(hào)輸出模塊6有多個(gè),每個(gè)控制信號(hào)輸出單元安裝了支持一種無線通信方式的硬件,負(fù)責(zé)控制基于該無線通信方式的所有智慧視聽設(shè)備。這些無線通信方式包括紅外、藍(lán)牙、Z-wave等。
遠(yuǎn)程GPU服務(wù)器3為用戶提供智慧視聽設(shè)備語音控制指令識(shí)別服務(wù)。
進(jìn)一步地,語音預(yù)處理模塊2包括:
分割單元,用于對語音控制信號(hào)進(jìn)行端點(diǎn)檢測及分割處理;
降噪單元,用于對分割處理后的語音控制信號(hào)進(jìn)行降噪處理;
提取單元,用于對降噪處理后的語音控制信號(hào)進(jìn)行MFCC原始語音特征提取,獲得MFCC原始語音特征信息。
遠(yuǎn)程GPU服務(wù)器3接收到MFCC原始語音特征信息,啟動(dòng)深度學(xué)習(xí)語音識(shí)別程序,采用biLSTM算法對MFCC原始語音特征信息進(jìn)行深度語音特征提取,獲得深度語音特征信息。
遠(yuǎn)程GPU服務(wù)器3接收到MFCC原始語音特征信息,對MFCC原始語音特征信息進(jìn)行深度語音特征提取,獲得深度語音特征信息,并將深度特征信息對應(yīng)的控制信號(hào)標(biāo)識(shí)信息發(fā)送給互聯(lián)網(wǎng)連接模塊4;
遠(yuǎn)程GPU服務(wù)器3對深度語音特征信息進(jìn)行分類,得到該深度語音特征信息對應(yīng)的類別,并檢測該類別是否對應(yīng)一種控制信號(hào)標(biāo)識(shí);若是,返回控制信號(hào)標(biāo)識(shí)信息給互聯(lián)網(wǎng)連接模塊4。
具體地,本發(fā)明實(shí)施例的系統(tǒng)相關(guān)功能模塊的工作原理可參見方法實(shí)施例的相關(guān)描述,這里不再贅述。
實(shí)施本發(fā)明實(shí)施例,可使用自然語音控制多種基于不同控制協(xié)議、實(shí)現(xiàn)多種不同業(yè)務(wù)的智慧視聽設(shè)備,為智慧視聽設(shè)備提供一種統(tǒng)一、自然、高效、低成本的人機(jī)交互方式;同時(shí)將復(fù)雜的深度學(xué)習(xí)任務(wù)部署在遠(yuǎn)程服務(wù)器上,降低了用戶的硬件和能源成本,為用戶提供高性能、低成本的智慧視聽設(shè)備語音控制指令識(shí)別服務(wù),提高智慧視聽設(shè)備語音控制指令的識(shí)別準(zhǔn)確率。
本領(lǐng)域普通技術(shù)人員可以理解上述實(shí)施例的各種方法中的全部或部分步驟是可以通過程序來指令相關(guān)的硬件來完成,該程序可以存儲(chǔ)于一計(jì)算機(jī)可讀存儲(chǔ)介質(zhì)中,存儲(chǔ)介質(zhì)可以包括:只讀存儲(chǔ)器(ROM,Read Only Memory)、隨機(jī)存取存儲(chǔ)器(RAM,Random Access Memory)、磁盤或光盤等。
另外,以上對本發(fā)明實(shí)施例所提供的基于深度學(xué)習(xí)的智慧視聽設(shè)備多業(yè)務(wù)控制方法及系統(tǒng)進(jìn)行了詳細(xì)介紹,本文中應(yīng)用了具體個(gè)例對本發(fā)明的原理及實(shí)施方式進(jìn)行了闡述,以上實(shí)施例的說明只是用于幫助理解本發(fā)明的方法及其核心思想;同時(shí),對于本領(lǐng)域的一般技術(shù)人員,依據(jù)本發(fā)明的思想,在具體實(shí)施方式及應(yīng)用范圍上均會(huì)有改變之處,綜上所述,本說明書內(nèi)容不應(yīng)理解為對本發(fā)明的限制。
- 還沒有人留言評(píng)論。精彩留言會(huì)獲得點(diǎn)贊!