一種基于情感和語義的智能對話方法及系統與流程
本發明涉及智能對話技術領域,具體涉及一種基于情感和語義智能對話方法及系統。
背景技術:
情感是人對客觀事物是否滿足自己的需要而產生的態度體驗,是智能對話過程中傳遞的重要信息。智能對話過程中,情感識別是交互系統的重要部分。情感狀態影響著信息表達的方式和信息傳遞的效果。
現有的對話系統是根據用戶的輸入話語,利用語料庫、模板來搜索一個或多個回復,或者利用算法自動產生一個或多個回復,不能根據用戶輸入話語來判斷用戶的情感,不能理解用戶要表達的意圖。情感,作為人類對話中非常重要的一個維度,在對話系統中不應該被忽略,如果忽略了情感,那么對話系統將會變的很生硬,用戶體驗較差,所以在對話系統中體現情感是非常有必要的。單獨根據情感就對所述用戶進行回復,顯然是不合理的,容易出現答非所問的現象,所以需要結合用戶的語義做針對性回復。因此,本發明提供了一種基于情感和語義的智能對話方法及系統。
技術實現要素:
針對現有技術中的上述缺陷,本發明提供了一種基于情感和語義的智能對話方法及系統,可以根據用戶輸入話語的情感和語義來做出相應的回復,以提高用戶體驗。
第一方面,本發明提供的一種基于情感和語義的智能對話方法,包括:
獲取用戶與智能對話系統的多輪對話信息;
根據所述多輪對話信息確定所述用戶當前的情感和語義;
根據所述用戶當前的情感和語義做出符合所述用戶當前的情感和語義的回復。
可選的,所述多輪對話信息,包括:多輪對話文本信息、多輪對話語音信息、多輪對話圖像信息中的一種或多種的組合;
所述根據所述多輪對話信息確定所述用戶當前的情感和語義,包括:
采用以下至少一種方式分析所述多輪對話信息,獲得所述用戶當前的情感特征和語義特征:
通過文字分析技術分析所述多輪對話文本信息,獲得所述用戶當前的情感特征和語義特征;
通過聲學語音識別技術分析所述多輪對話語音信息,獲得所述用戶當前的情感特征和語義特征;
根據圖像識別技術分析所述多輪對話圖像信息,獲得所述用戶當前的情感特征和語義特征;
根據所述用戶當前的情感特征和語義特征確定相應的所述用戶當前的情感和語義。
可選的,所述基于情感和語義的智能對話方法,還包括:
根據所述多輪對話信息對所述智能對話系統在所述多輪對話中的系統角色進行定位;
所述根據所述用戶當前的情感和語義做出符合所述用戶當前的情感和語義的回復,包括:
根據所述用戶當前的情感和語義以及所述系統角色做出符合所述用戶當前的情感和語義以及所述系統角色的回復。
可選的,所述基于情感和語義的智能對話方法,還包括:
根據所述多輪對話信息分析所述用戶在所述多輪對話信息中的情感變化;
所述根據所述用戶當前的情感和語義做出符合所述用戶當前的情感和語義的回復,包括:
根據所述用戶當前的情感和語義以及所述情感變化做出符合所述用戶當前的情感和語義以及所述情感變化的回復。
可選的,所述根據所述用戶當前的情感和語義做出符合所述用戶當前的情感和語義的回復,包括:
根據所述用戶當前的情感和語義從回復數據庫中選擇至少一個符合所述用戶當前的情感和語義的回復信息;和/或,
根據所述用戶當前的情感和語義,利用回復生成模型自動生成符合所述用戶當前的情感和語義的回復信息;
利用所述回復信息做出符合所述用戶當前的情感和語義的回復。
第二方面,本發明提供的一種基于情感和語義的智能對話系統,包括:
對話信息獲取模塊,用于獲取用戶與智能對話系統的多輪對話信息;
情感和語義確定模塊,用于根據所述多輪對話信息確定所述用戶當前的情感和語義;
回復模塊,用于根據所述用戶當前的情感和語義做出符合所述用戶當前的情感和語義的回復。
可選的,所述多輪對話信息,包括:多輪對話文本信息、多輪對話語音信息、多輪對話圖像信息中的一種或多種的組合;
所述情感和語義確定模塊,包括:
特征獲取單元,用于采用以下至少一種方式分析所述多輪對話信息,獲得所述用戶當前的情感特征和語義特征:
通過文字分析技術分析所述多輪對話文本信息,獲得所述用戶當前的情感特征和語義特征;
通過聲學語音識別技術分析所述多輪對話語音信息,獲得所述用戶當前的情感特征和語義特征;
根據圖像識別技術分析所述多輪對話圖像信息,獲得所述用戶當前的情感特征和語義特征;
確定單元,用于根據所述用戶當前的情感特征和語義特征確定相應的所述用戶當前的情感和語義。
可選的,所述基于情感和語義的智能對話系統,還包括:
系統角色定位模塊,用于根據所述多輪對話信息對所述智能對話系統在所述多輪對話中的系統角色進行定位;
所述回復模塊,具體用于根據所述用戶當前的情感和語義以及所述系統角色做出符合所述用戶當前的情感和語義以及所述系統角色的回復。
可選的,所述基于情感和語義的智能對話系統,還包括:
情感變化分析模塊,用于根據所述多輪對話信息分析所述用戶在所述多輪對話信息中的情感變化;
所述回復模塊,具體用于根據所述用戶當前的情感和語義以及所述情感變化做出符合所述用戶當前的情感和語義以及所述情感變化的回復。
可選的,所述回復模塊,包括:
回復信息選擇單元,用于根據所述用戶當前的情感和語義從回復數據庫中選擇至少一個符合所述用戶當前的情感和語義的回復信息;和/或,
自動生成回復信息單元,用于根據所述用戶當前的情感和語義,利用回復生成模型自動生成符合所述用戶當前的情感和語義的回復信息;
執行回復單元,用于利用所述回復信息做出符合所述用戶當前的情感和語義的回復。
由以上技術方案可知,本發明提供一種基于情感和語義的智能對話方法,首先,獲取用戶與智能對話系統的多輪對話信息;然后,根據所述多輪對話信息確定所述用戶當前的情感和語義;最后,根據所述用戶當前的情感和語義做出符合所述用戶當前的情感和語義的回復。相較于現有技術,本發明提供的所述基于情感和語義的智能對話方法,可以根據用戶與智能對話系統的多輪對話信息確定所述用戶當前的情感和語義,并且可以根據所述用戶當前的情感和語義做出符合所述用戶當前的情感和語義的回復,可以針對不同的情感和語義做出不同的回復,能夠提升回復和用戶情感的搭配程度,并且能夠提升回復和用戶語義的搭配程度,可以避免答非所問的現象,同時,可以提高用戶體驗。
本發明提供的一種基于情感和語義的智能對話系統,與上述基于情感和語義的智能對話方法出于相同的發明構思,具有相同的有益效果。
附圖說明
為了更清楚地說明本發明具體實施方式或現有技術中的技術方案,下面將對具體實施方式或現有技術描述中所需要使用的附圖作簡單地介紹。在所有附圖中,類似的元件或部分一般由類似的附圖標記標識。附圖中,各元件或部分并不一定按照實際的比例繪制。
圖1示出了本發明第一實施例提供一種基于情感和語義的智能對話方法的流程圖;
圖2示出了本發明第二實施例提供一種基于情感和語義的智能對話系統的示意圖。
具體實施方式
下面將結合附圖對本發明技術方案的實施例進行詳細的描述。以下實施例僅用于更加清楚地說明本發明的技術方案,因此只是作為示例,而不能以此來限制本發明的保護范圍。
需要注意的是,除非另有說明,本申請使用的技術術語或者科學術語應當為本發明所屬領域技術人員所理解的通常意義。
本發明提供了一種基于情感和語義的智能對話方法及系統。下面結合附圖對本發明的實施例進行說明。
圖1示出了本發明第一實施例所提供的一種基于情感和語義的智能對話方法的流程圖。如圖1所示,本發明第一實施例提供的一種基于情感和語義的智能對話方法包括以下步驟:
步驟S101:獲取用戶與智能對話系統的多輪對話信息。
在本步驟中,所述多輪對話信息,包括:多輪對話文本信息、多輪對話語音信息、多輪對話圖像信息中的至少一種,也可以是多種的組合,都在本發明的保護范圍之內。所述多輪對話信息是指當前對話回合中的多次對話信息。在與智能對話系統進行對話時,可以直接輸入文本信息,也可以輸入語音信息,所述智能對話系統裝有話筒,可以用來采集用戶的語音信息,所述智能對話系統還會裝有攝像頭,可以用來采集用戶的人臉、身體姿態等圖像信息。
步驟S102:根據所述多輪對話信息確定所述用戶當前的情感和語義。
在本步驟中,所述語義包括對話信息的表面意思和想表達的意圖。所述根據所述多輪對話信息確定所述用戶當前的情感和語義,首先,需要根據所述多輪對話信息獲得所述用戶當前的情感特征和語義特征;然后,根據所述用戶當前的情感特征和語義特征確定相應的所述用戶當前的情感和語義。
所述根據所述多輪對話信息獲得所述用戶當前的情感特征和語義特征包括多種方式,不同形式的對話信息具有不同的處理方式。第一種方式,通過文字分析技術分析所述多輪對話文本信息,獲得所述用戶當前的情感特征和語義特征。例如,用戶輸入了“我今天踢了足球,非常高興”的文本信息,可以通過文字分析技術分析出所述用戶現在的情感特征是“高興”,所述語義特征是“足球”、“高興”。
第二種方式,通過聲學語音識別技術分析所述多輪對話語音信息,獲得所述用戶當前的情感特征和語義特征。通過聲學語音識別技術可以識別出所述多輪對話語音信息中用戶說話的語氣、音量的變化、音調的高低、語速的快慢等,還能識別出所述多輪對話語音信息中的文字信息,并能夠根據所述語氣、音量的變化、音調的高低、語速的快慢和文字信息分析出所述多輪對話語音信息的情感特征和語義特征。
第三種方式,通過圖像識別技術識別出所述多輪對話圖像信息,獲得所述用戶當前的情感特征和語義特征。這里所說的圖像信息包括圖片信息、視頻信息,可以通過攝像頭采集用戶的面部表情、身體姿態等圖像信息,然后采用圖像識別技術識別所述圖像信息,分析出用戶的當前的情感特征和語義特征。所述情感特征包括:皺眉、摔東西、嘴角上翹等。所述語義特征包括:啞語的手勢、舞姿、米飯等。例如,通過所述攝像頭獲得的圖片是一個人在吃飯的時候嘴角上翹,大口吃飯。那么,所述圖片的情感特征是嘴角上翹,語義特征是吃飯、嘴角上翹。所述通過圖像識別技術識別出所述多輪對話信息,是所述智能對話系統的圖像功能。其中,通過所述攝像頭采集圖像信息,可以是用戶主動啟用所述智能對話系統的圖像功能,也可以是所述智能對話系統主動推送圖像功能,經用戶同意后,再啟動所述圖像功能。例如,在發現用戶情感有劇烈波動和變化時,所述智能對話系統可以主動推送圖像功能。可以通過對話框詢問所述用戶是否愿意嘗試所述智能對話系統的圖像功能,可以通過對話框告訴所述用戶所述圖像功能可以檢測所述用戶當前的情感狀態。
其中,在向用戶推送圖像功能時,所述圖像功能,還包括:變臉功能、智能化妝等,通過這些有趣的功能,可以吸引用戶嘗試所述圖像功能,進而獲取用戶在與所述智能對話系統對話時的表情,可以更好地識別用戶的情感和語義。
需要說明的是,以上幾種方式可以選擇一種使用,也可以組合使用,例如,可以同時采用文字分析技術和圖像識別技術識別出用戶當前的情感特征和語義特征。
其中,所述根據所述用戶當前的情感特征和語義特征確定所述用戶當前的情感和語義。所述情感和語義的確定是在所述智能對話系統中預先定義好的情感模型和語義模型中確定的。所述情感模型和語義模型是根據人工規則和機器學習的方法所建立的模型。所述人工規則即是專家通過觀察分析人類的行為模式和人如何處理情感變化,對應地制定的一些規則,是人為規定的一些規則。所述機器學習是一門多領域交叉學科,涉及概率論、統計學、逼近論、凸分析、神經網絡、算法復雜度理論等多門學科,專門研究計算機怎樣模擬或實現人類的學習行為,以獲取新的知識或技能,重新組織已有的知識結構使之不斷改善自身的性能。
在本發明中,所述情感模型和語義模型是利用人工規則和機器學習的方法預先訓練的模型。所述情感模型是一個所述情感特征和相應的所述情感相對應的一個情感數據庫,所述情感模型中有高興、憤怒、傷心、喜歡、厭惡、煩惱等不同分類的情感和相對應的所述情感的情感特征,所述情感特征,包括:摔東西、皺眉、語氣詞等。例如,“摔東西”的情感特征對應“憤怒”的情感。所述語義模型是一個所述語義特征和相應的所述語義相對應的一個數據庫。所述語義包括:用戶的意圖、對話信息的意思等。所述語義模型根據所述語義特征判斷所述用戶的意圖和所述對話信息的意思。這樣,就可以根據所述用戶當前的情感特征和語義特征確定所述用戶當前的情感和語義。通過多維度分析所述對話信息,可以更好的識別用戶的情感和語義。
需要說明的是,在確定所述用戶當前的情感和語義過程中,可以采用一種形式的多輪對話信息分析所述用戶的情感,也可以采用不同形式的多輪對話信息共同分析所述用戶的情感。例如,可以采用多輪對話文本信息中的情感特征和語義特征以及多輪對話語音信息中的情感特征和語義特征共同分析所述用戶的情感特征和語義特征,然后根據所述用戶的情感特征和語義特征分析所述用戶當前的情感和語義。通過多維度分析所述多輪對話信息,可以更加準確確定所述用戶當前的情感和語義,進而提高所述智能對話系統識別用戶情感和語義的準確性。
步驟S103:根據所述用戶當前的情感和語義做出符合所述用戶當前的情感和語義的回復。
在本步驟中,用符合所述用戶當前的情感和語義的回復進行回復,可以提升回復和用戶情感的搭配程度,提升用戶體驗。例如,在用戶很高興的時候,可以加強用戶高興;在用戶沮喪的時候,通過安慰,讓用戶情緒得到釋放。在進行回復時,如果用戶具有負面情感,需要保證對話系統不會出錯,如果對話系統出錯,可能會導致用戶情感惡化,從而對系統產生不滿。
在本步驟之前,所述基于情感和語義的智能對話方法,還包括:根據所述多輪對話信息對所述智能對話系統在所述多輪對話中的系統角色進行定位。然后,根據所述用戶當前的情感和語義以及所述系統角色做出符合所述用戶當前的情感和語義以及所述系統角色的回復。不同的系統角色的情感和語義不同,不同系統角色會給出不同回復,這樣,可以更有針對性的與用戶交流,提升用戶體驗。
所述系統角色是系統提前預設的,并且所述系統角色會隨著用戶的使用進行演變。所述系統角色包括:可愛少女、知心大姐、好朋友、智能投資顧問等。當用戶與所述智能對話系統進行多輪對話后,所述智能對話系統會根據所述多輪對話信息分析所述用戶是什么類型的人,然后根據所述用戶的類型對所述系統進行系統角色定位,所述智能對話系統會以定位的所述系統角色與所述用戶進行對話。所述智能對話系統會根據所述多輪對話信息體現出的用戶的情感、語義、說話方式、文字表達等來對所述系統角色進行定位。在與所述用戶進行對話過程中,所述系統角色可能會發生變化,所述系統會根據所述用戶在當前的一段對話中的情感、語義、說話方式、文字表達等來對所述系統角色進行定位。在一次對話中,所述系統可能始終會是一種系統角色,也可能會是不同系統角色交替與所述用戶對話,都在本發明的保護范圍內。
例如,用戶在使用所述系統過程中,發現用戶是一個隨意的人,會說錯話、開玩笑等,那么系統角色會定位為隨意型,所述系統在與用戶的對話過程中也會慢慢變得講話隨便、說錯話、開玩笑等。如果用戶在使用所述系統過程中,發現用戶是一個較死板的人,那么系統角色會定位為嚴謹型,所述系統在與用戶對話的過程中則應變得成熟穩重,注意用詞。
例如,用戶與所述智能對話系統對話時,剛開始說話的風格是可愛型的,比較高興,則系統的系統角色會定位為可愛型,過了一會,所述用戶突然生氣,則系統的系統角色會定位為知心大姐型。系統角色是可愛少女型時,且用戶當前的情感是高興,所述系統說話的風格就比較可愛,會帶有比較的可愛的語氣詞、疊詞等;當系統角色是知心大姐型時,所述系統說話就會帶有安慰的詞語,以安慰用戶。
在對系統角色定位后,所述系統會根據所述用戶當前的情感和語義以及所述系統角色做出符合所述用戶當前的情感和語義以及所述系統角色的回復。相同情感和語義,不同系統角色的回復是不一樣的,不同情感和語義,相同系統角色的回復也是不一樣的,比如,同樣是用戶“做錯事難過”,“知心大姐”型和“好朋友”型的系統角色給出的回復是不一樣的。
在本步驟之前,還包括:根據所述多輪對話信息分析所述用戶在所述多輪對話信息中的情感變化。在進行回復時,還包括:根據所述用戶當前的情感和語義以及所述情感變化做出符合所述用戶當前的情感和語義以及所述情感變化的回復。通過分析用戶在多輪對話信息中的情感變化,可以更加了解用戶,可以根據用戶的喜好來進行回復,投其所好,提升用戶體驗。
所述根據所述多輪對話信息分析所述用戶在所述多輪對話信息中的情感變化,是根據所述多輪對話信息中的情感特征來分析所述用戶在所述多輪對話信息中的情感變化,從所述多輪對話信息中識別出情感特征,分析情感,然后,分析所述用戶的情感變化。分析所述用戶的情感變化可以從對話內容、對話語氣、對話形式等方面來分析。所述情感變化有多種,比如,從高興到更高興、從煩惱到開心、從喜歡到厭惡等。這樣可以更加了解用戶的喜好,更好地與用戶對話,提升用戶體驗。
例如,在一段對話中,用戶剛開始比較傷心,在與所述系統聊了一會后,變的比較開心,那么,所述用戶可能喜歡這段對話的內容,在以后的聊天中就可以多聊這方面的內容,投其所好,提升用戶體驗,使用戶喜歡所述智能對話系統。
在本步驟中,首先,根據所述用戶當前的情感和語義從回復數據庫中選擇至少一個符合所述用戶當前的情感和語義的回復信息;和/或,根據所述用戶當前的情感和語義,利用回復生成模型自動生成符合所述用戶當前的情感和語義的回復信息;然后,利用所述回復信息做出符合所述用戶當前的情感和語義的回復。
所述根據所述用戶當前的情感和語義從回復數據庫中選擇至少一個符合所述用戶當前的情感和語義的回復信息的方法,其中,所述符合所述用戶當前的情感和語義的回復信息可以是多個備選回復信息。所述利用所述回復信息做出符合所述用戶當前的情感和語義的回復,可以是從所述多個備選回復信息中隨機選擇一個回復信息回復給用戶,也可以是將所述多個備選回復信息都回復給用戶。這種方法的優點是答案質量有保障,符合人類說話的語法、方式、語氣等,但是,由于回復數據庫是有限的,不可能把所有的回復信息都放在回復數據庫中,這樣,有時可能就會出現找不到合適的回復信息。
另一種方法是根據所述用戶當前的情感和語義,利用回復生成模型自動生成符合所述用戶當前的情感和語義的回復信息,然后,利用所述回復信息做出符合所述用戶當前的情感和語義的回復。所述回復生成模型是通過機器學習和/或人工規則的方法建立的模型,所述機器學習的方法是利用大規模的一般語句作為訓練語料,針對詞語、語法、句法等來進行訓練的方法。這種方法的優點是不受規模的限制,可以生成任意的回復信息,但是,利用這種方法對回復生成模型的質量要求很高,否則會產生不符合語法、語氣的低質量的回復信息。兩種方法可以結合使用,也可以獨立使用,都在本發明的保護范圍之內。
其中,所述符合所述用戶當前的情感和語義的回復信息可以是結合所述系統角色和/或所述用戶的情感變化選擇或生成的,相同的情感和語義,不同的系統角色,回復信息是不同的。通過這種方法,可以有針對性地與用戶聊天,使所述智能對話系統應用于不同的人群,同時,可以提升用戶體驗。
例如,同樣是面對用戶生氣,如果系統角色是“低三下四”型,那么所述智能對話系統發現用戶生氣,則跟用戶進行道歉;如果系統角色是“任性”型,則所述智能對話系統直接跟用戶開始對罵;如果系統角色是“冷漠”型,那么所述智能對話系統不理會用戶生氣,直接無視。
在本步驟中,如何根據所述用戶當前的情感和語義做出符合所述用戶當前的情感和語義的回復是在策略生成模型中完成的。所述策略生成模型是根據人工規則和機器學習的方法訓練的。所述策略生成模型有以下三種訓練方式,第一種,在訓練所述策略生成模型時,可以根據情感和語義進行訓練,訓練如何根據所述情感和語義進行回復。所述策略生成模型可以得到所述情感和語義的權重,然后,根據所述權重選擇出和/或自動生成符合所述用戶當前的情感和語義的回復。
第二種,在訓練所述策略生成模型時,還可以根據所述系統角色進行訓練。所述策略生成模型可以根據所述系統角色得到所述情感和語義的權重,然后,根據所述系統角色和權重選擇出和/或自動生成符合所述用戶當前的情感和語義的回復。
第三種,在訓練所述策略生成模型時,還可以根據所述情感變化進行訓練。所述策略生成模型可以根據所述情感變化得到所述情感和語義的權重,然后,根據所述情感變化和權重選擇出和/或自動生成符合所述用戶當前的情感和語義的回復。
所述策略生成模型可以根據以上三種方式中的任何一種或多種的組合來進行訓練,都在本發明的保護范圍內。
在本步驟中,可以根據所述用戶當前的情感和語義,或者,根據所述系統角色和/或所述情感變化以及所述用戶當前的情感和語義,直接做出合適的回復;可以根據所述用戶當前的情感和語義的權重,做出合適回復,這都在本發明的保護范圍內。
其中,在根據所述用戶當前的情感和語義的權重做出符合所述用戶當前的情感和語義的回復時,有時也可以只考慮所述用戶當前的語義和情感中的一種來做出相應的符合所述語義或情感的回復信息。當用戶情感強烈,但是沒有所述用戶當前的語義和情感都符合的回復信息,就可以將只符合所述用戶當前的情感的回復信息做為回復。當用戶情感比較弱或者用戶的情感呈中性的時候,所述用戶當前的語義的權重就很大,可以忽略情感,單純根據所述用戶當前的語義進行回復,只將符合所述用戶當前的語義的回復信息做為回復。對于其它的一般情況,則是根據所述用戶當前的情感和語義的權重來得出回復信息,并利用所述回復信息進行回復。
至此,通過步驟S101至步驟S103,完成了本發明第一實施例所提供的一種基于情感和語義的智能對話方法的流程。相較于現有技術,本發明提供的所述基于情感和語義的智能對話方法,可以根據用戶與智能對話系統的多輪對話信息確定所述用戶當前的情感和語義,并且可以根據所述用戶當前的情感和語義做出符合所述用戶當前的情感和語義的回復,可以針對不同的情感和語義做出不同的回復,能夠提升回復和用戶情感的搭配程度,能夠提升回復和用戶語義的搭配程度,可以避免答非所問的現象,同時,可以提高用戶體驗。
在上述的第一實施例中,提供了一種基于情感和語義的智能對話方法,與之相對應的,本申請還提供一種基于情感和語義的智能對話系統。請參考圖2,其為本發明第二實施例提供的一種基于情感和語義的智能對話系統的示意圖。由于系統實施例基本相似于方法實施例,所以描述得比較簡單,相關之處參見方法實施例的部分說明即可。下述描述的系統實施例僅僅是示意性的。
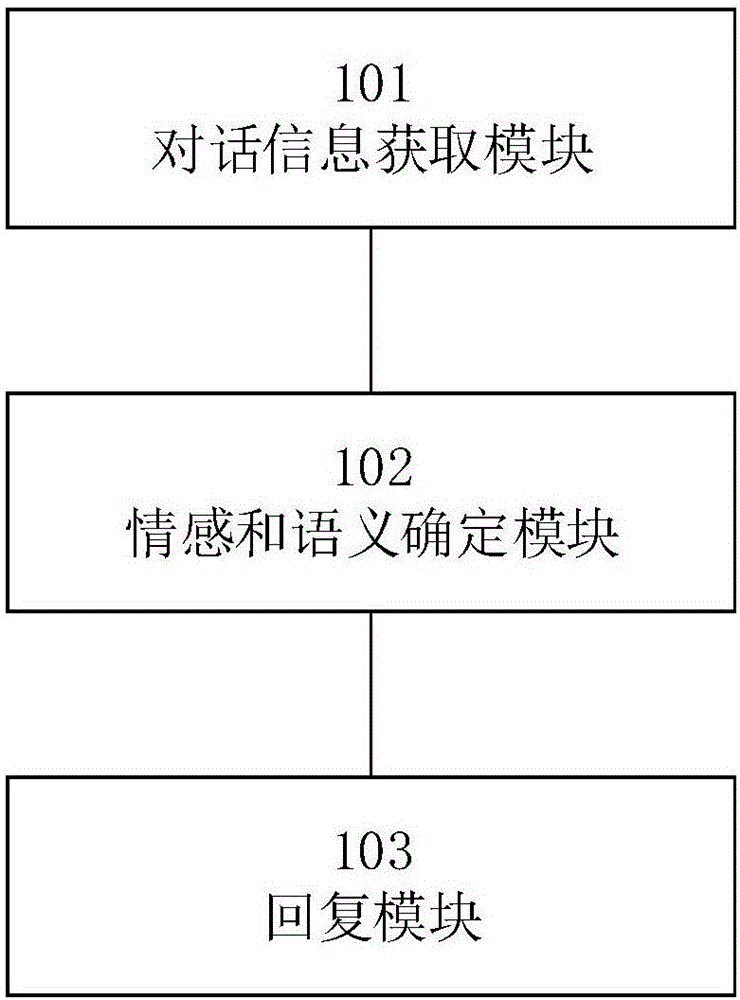
本發明第二實施例提供的一種基于情感和語義的智能對話系統,包括:
對話信息獲取模塊101,用于獲取用戶與智能對話系統的多輪對話信息;
情感和語義確定模塊102,用于根據所述多輪對話信息確定所述用戶當前的情感和語義;
回復模塊103,用于根據所述用戶當前的情感和語義做出符合所述用戶當前的情感和語義的回復。
在本發明提供的一個實施例中,所述多輪對話信息,包括:多輪對話文本信息、多輪對話語音信息、多輪對話圖像信息中的一種或多種的組合;
所述情感和語義確定模塊102,包括:
特征獲取單元,用于采用以下至少一種方式分析所述多輪對話信息,獲得所述用戶當前的情感特征和語義特征:
通過文字分析技術分析所述多輪對話文本信息,獲得所述用戶當前的情感特征和語義特征;
通過聲學語音識別技術分析所述多輪對話語音信息,獲得所述用戶當前的情感特征和語義特征;
根據圖像識別技術分析所述多輪對話圖像信息,獲得所述用戶當前的情感特征和語義特征;
確定單元,用于根據所述用戶當前的情感特征和語義特征確定相應的所述用戶當前的情感和語義。
在本發明提供的一個實施例中,所述基于情感和語義的智能對話系統,還包括:
系統角色定位模塊,用于根據所述多輪對話信息對所述智能對話系統在所述多輪對話中的系統角色進行定位;
所述回復模塊103,具體用于根據所述用戶當前的情感和語義以及所述系統角色做出符合所述用戶當前的情感和語義以及所述系統角色的回復。
在本發明提供的一個實施例中,所述基于情感和語義的智能對話系統,還包括:
情感變化分析模塊,用于根據所述多輪對話信息分析所述用戶在所述多輪對話信息中的情感變化;
所述回復模塊103,具體用于根據所述用戶當前的情感和語義以及所述情感變化做出符合所述用戶當前的情感和語義以及所述情感變化的回復。
在本發明提供的一個實施例中,所述回復模塊103,包括:
回復信息選擇單元,用于根據所述用戶當前的情感和語義從回復數據庫中選擇至少一個符合所述用戶當前的情感和語義的回復信息;和/或,
自動生成回復信息單元,用于根據所述用戶當前的情感和語義,利用回復生成模型自動生成符合所述用戶當前的情感和語義的回復信息;
執行回復單元,用于利用所述回復信息做出符合所述用戶當前的情感和語義的回復。
以上,為本發明第二實施例提供的一種基于情感和語義的智能對話系統的實施例說明。
本發明提供的一種基于情感和語義的智能對話系統與上述基于情感和語義的智能對話方法出于相同的發明構思,具有相同的有益效果,此處不再贅述。
在本說明書的描述中,參考術語“一個實施例”、“一些實施例”、“示例”、或“一些示例”等的描述意指結合該實施例或示例描述的具體特征、結構、材料或者特點包含于本發明的至少一個實施例或示例中。在本說明書中,對上述術語的示意性表述不是必須針對的是相同的實施例或示例。而且,描述的具體特征、結構、材料或者特點可以在任一個或多個實施例或示例中以合適的方式結合。此外,在不相互矛盾的情況下,本領域的技術人員可以將本說明書中描述的不同實施例或示例以及不同實施例或示例的特征進行結合和組合。需要說明的是,本發明附圖中的流程圖和框圖顯示了根據本發明的多個實施例的系統、方法和計算機程序產品的可能實現的體系架構、功能和操作。在這點上,流程圖或框圖中的每個方框可以代表一個模塊、程序段或代碼的一部分,所述模塊、程序段或代碼的一部分包含一個或多個用于實現規定的邏輯功能的可執行指令。也應當注意,在有些作為替換的實現中,方框中所標注的功能也可以以不同于附圖中所標注的順序發生。例如,兩個連續的方框實際上可以基本并行地執行,它們有時也可以按相反的順序執行,這依所涉及的功能而定。也要注意的是,框圖和/或流程圖中的每個方框、以及框圖和/或流程圖中的方框的組合,可以用執行規定的功能或動作的專用的基于硬件的系統來實現,或者可以用專用硬件與計算機指令的組合來實現。
所屬領域的技術人員可以清楚地了解到,為描述的方便和簡潔,上述描述的系統、裝置和單元的具體工作過程,可以參考前述方法實施例中的對應過程,在此不再贅述。
在本申請所提供的幾個實施例中,應該理解到,所揭露的系統、裝置和方法,可以通過其它的方式實現。以上所描述的裝置實施例僅僅是示意性的,例如,所述單元的劃分,僅僅為一種邏輯功能劃分,實際實現時可以有另外的劃分方式,又例如,多個單元或組件可以結合或者可以集成到另一個系統,或一些特征可以忽略,或不執行。
所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位于一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部單元來實現本實施例方案的目的。
另外,在本發明各個實施例中的各功能單元可以集成在一個處理單元中,也可以是各個單元單獨物理存在,也可以兩個或兩個以上單元集成在一個單元中。
所述功能如果以軟件功能單元的形式實現并作為獨立的產品銷售或使用時,可以存儲在一個計算機可讀取存儲介質中。基于這樣的理解,本發明的技術方案本質上或者說對現有技術做出貢獻的部分或者該技術方案的部分可以以軟件產品的形式體現出來,該計算機軟件產品存儲在一個存儲介質中,包括若干指令用以使得一臺計算機機器(可以是個人計算機,服務器,或者網絡機器等)執行本發明各個實施例所述方法的全部或部分步驟。而前述的存儲介質包括:U盤、移動硬盤、只讀存儲器(ROM,Read-Only Memory)、隨機存取存儲器(RAM,Random Access Memory)、磁碟或者光盤等各種可以存儲程序代碼的介質。
最后應說明的是:以上各實施例僅用以說明本發明的技術方案,而非對其限制;盡管參照前述各實施例對本發明進行了詳細的說明,本領域的普通技術人員應當理解:其依然可以對前述各實施例所記載的技術方案進行修改,或者對其中部分或者全部技術特征進行等同替換;而這些修改或者替換,并不使相應技術方案的本質脫離本發明各實施例技術方案的范圍,其均應涵蓋在本發明的權利要求和說明書的范圍當中。
- 還沒有人留言評論。精彩留言會獲得點贊!