追蹤噪聲源和目標聲源的雙麥克風降噪系統和方法與流程
本發明屬于信號處理領域,特別涉及一種追蹤噪聲源和目標聲源的雙麥克風降噪系統和方法。
背景技術:
目前的人工耳蝸降噪技術一般是基于一個全向麥克風,即單麥克風降噪技術或兩個全向麥克風,也就是雙麥克風降噪技術。其中,單麥克風降噪技術的效果一般很難得到保證。比如傳統的譜減法或維納濾波,會產生語音信號的畸變以及“音樂噪音”,很難提升耳蝸植入者在噪聲環境下的言語識別率。而一些最新的基于單麥克風的降噪技術,往往需要很大的運算資源,這都是人工耳蝸或助聽器的DSP所無法承受的。
而傳統的雙麥克風技術,比如延時相加(DS,delay and sum)方法,是根據正前方的語音信號抵達兩個麥克風的時間差而進行處理的。可是,考慮到用戶體驗,人工耳蝸體外機的發展趨勢是越做越輕薄,因此兩個麥克風的物理距離往往不超過兩厘米,這也導致了語音信號抵達兩個麥克風的時間差非常短,甚至不到一個采樣點的差別。所以傳統的DS方法只能稍微提升語音信號的信噪比,效果微乎其微。
在此基礎上進行改進的差分麥克風陣列(DMA,differential microphone array)的方法,可以有效提升信號的信噪比,但是只能用來消除提前設定好的方向的噪聲(如側向90度或后向180度),而不能根據外部環境變化來實時地消除噪聲。這樣結果很有可能會導致噪聲不能被有效地消除,而使得耳蝸植入者不能在噪聲環境中感知語音信號。
技術實現要素:
有鑒于此,本發明的目的在于提供一種追蹤噪聲源和目標聲源的雙麥克風降噪系統和方法,據外部環境,實時追蹤噪聲源與目標聲源的方向,進行定向降噪。
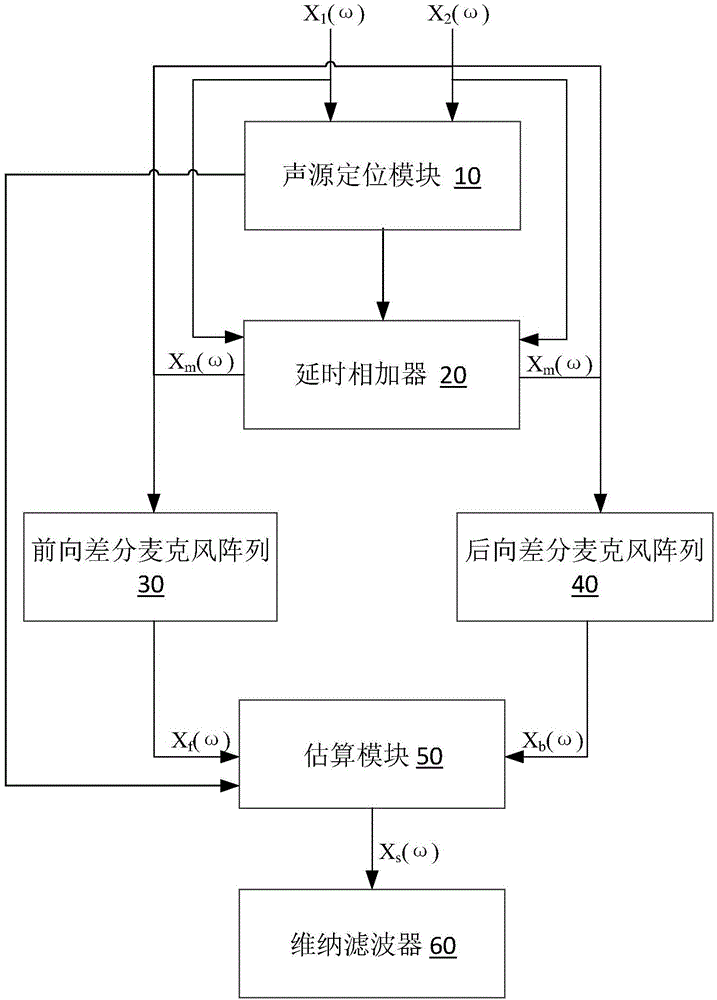
為達到上述目的,本發明提供了一種追蹤噪聲源和目標聲源的雙麥克風降噪系統,包括聲源定位模塊、延時相加器、前向差分麥克風陣列、后向差分麥克風陣列、估算模塊和維納濾波器,其中,
所述聲源定位模塊的輸入為前向和后向麥克風的兩路頻域信號,對目標聲源及噪聲源的方向進行計算后輸出;
所述延時相加器的輸入為聲源定位模塊輸出的目標聲源方向、前向和后向麥克風的兩路頻域信號,輸出為兩路頻域信號經方向識別和延時相加后,信噪比提升的混合信號;
所述前向差分麥克風陣列和后向差分麥克風陣列分別與所述延時相加器連接,二者的輸入均為延時相加器輸出的混合信號加后向麥克風的頻域信號,輸出分別為前向信號和后向信號;
所述估算模塊與前向差分麥克風陣列和后向差分麥克風陣列以及聲源定位模塊分別連接,根據三者的輸出估算出前向目標信號;
所述維納濾波器與所述估算模塊連接,將前向目標信號進行維納濾波,輸出目標語音信號。
優選地,所述聲源定位模塊輸出的目標聲源方向記為θt,噪聲源方向記為θn由如下公式獲得:
Xθ(ω)=X1(ω)+e-jωτcos(θ)X2(ω);
θt(ω)=θ,當Xθ(ω)=max(Xθ(ω)),且θ=-60°到60°;
θn(ω)=θ,當Xθ(ω)=max(Xθ(ω)),且θ=120°到240°;
其中,Xθ(ω)為不同延時疊加后的混合信號、θ為信號不同的入射角度、θt為目標聲源的方向、θn為噪聲源的方向、ω為角頻率、τ為后向麥克風的延時大小,0°定義為正前方。
優選地,所述延時相加器的輸出由如下公式獲得:
其中,X1(ω)為前向麥克風的頻域信號、X2(ω)為后向麥克風的頻域信號、θt為目標聲源即前向聲源的方向、ω為角頻率、τ為后向麥克風的延時大小,Xm(ω)為延時相加器輸出的混合信號。
優選地,所述前向差分麥克風陣列輸出的前向信號由如下公式獲得:
Xf(ω)=Xm(ω)-e-jωτX2(ω)
其中,X2(ω)為后向麥克風的頻域信號、ω為角頻率、τ為后向麥克風的延時大小、Xm(ω)為延時相加器輸出的混合信號、Xf(ω)為前向信號;
后向差分麥克風陣列輸出的后向信號由如下公式獲得:
Xb(ω)=Xm(ω)-ejωτX2(ω)
其中,X2(ω)為后向麥克風的頻域信號、ω為角頻率、τ為后向麥克風的延時大小、Xm(ω)為延時相加器輸出的混合信號、Xb(ω)為后向信號。
優選地,所述估算模塊輸出的前向目標信號由如下公式獲得:
XS(ω)=Xf(ω)-CXb(ω)
其中,Xf(ω)為前向信號、Xb(ω)為后向信號、C為介于0.1到1之間的常數,由噪聲源的方向所決定、Xs(ω)為前向目標信號。
優選地,所述維納濾波器輸出的目標語音信號由如下公式獲得:
其中,Xm(ω)為延時相加器輸出的混合信號、Xs(ω)為前向目標信號、X2(ω)為后向麥克風的頻域信號、S(ω)為目標語音信號。
基于上述目的,本發明還提供了一種追蹤噪聲源和目標聲源的雙麥克風降噪方法,包括以下步驟:
前向和后向麥克風的兩路頻域信號輸入聲源定位模塊,聲源定位模塊對目標聲源及噪聲源的方向進行計算后輸出;
目標聲源方向、前向和后向麥克風的兩路頻域信號輸入延時相加器,進行延時相加及信噪比提升處理,輸出混合信號;
混合信號和后向麥克風的頻域信號同時輸入前向差分麥克風陣列和后向差分麥克風陣列,而后分別輸出前向信號和后向信號;
前向信號、后向信號及噪聲源的方向一同輸入估算模塊,估算出前向目標信號;
維納濾波器與所述估算模塊連接,將前向目標信號進行維納濾波,輸出目標語音信號。
優選地,所述聲源定位模塊輸出的目標聲源方向記為θt,噪聲源方向記為θn,由如下公式獲得:
Xθ(ω)=X1(ω)+e-jωτcos(θ)X2(ω);
θt(ω)=θ,當Xθ(ω)=max(Xθ(ω)),且θ=-60°到60°;
θn(ω)=θ,當Xθ(ω)=max(Xθ(ω)),且θ=120°到240°;
其中,Xθ(ω)為不同延時疊加后的混合信號、θ為信號不同的入射角度、θt為目標聲源的方向、θn為噪聲源的方向、ω為角頻率、τ為后向麥克風的延時大小,0°定義為正前方。
優選地,所述延時相加器的輸出由如下公式獲得:
其中,X1(ω)為前向麥克風的頻域信號、X2(ω)為后向麥克風的頻域信號、θt為目標聲源即前向聲源的方向、ω為角頻率、τ為后向麥克風的延時大小,Xm(ω)為延時相加器輸出的混合信號。
優選地,所述前向差分麥克風陣列輸出的前向信號由如下公式獲得:
Xf(ω)=Xm(ω)-e-jωτX2(ω)
其中,X2(ω)為后向麥克風的頻域信號、ω為角頻率、τ為后向麥克風的延時大小、Xm(ω)為延時相加器輸出的混合信號、Xf(ω)為前向信號;
后向差分麥克風陣列輸出的后向信號由如下公式獲得:
Xb(ω)=Xm(ω)-ejωτX2(ω)
其中,X2(ω)為后向麥克風的頻域信號、ω為角頻率、τ為后向麥克風的延時大小、Xm(ω)為延時相加器輸出的混合信號、Xb(ω)為后向信號。
優選地,所述估算模塊輸出的前向目標信號由如下公式獲得:
XS(ω)=Xf(ω)-CXb(ω)
其中,Xf(ω)為前向信號、Xb(ω)為后向信號、C為介于0.1到1之間的常數,由噪聲源的方向所決定、Xs(ω)為前向目標信號。
優選地,所述維納濾波器輸出的目標語音信號由如下公式獲得:
其中,Xm(ω)為延時相加器輸出的混合信號、Xs(ω)為前向目標信號、X2(ω)為后向麥克風的頻域信號、S(ω)為目標語音信號。
本發明的有益效果在于:有效提升前向信號(目標語音信號)的信噪比,同時抑制側向或后向干擾(噪聲)信號的強度,使得耳蝸植入者可以在噪聲環境中感知和理解語音信號。并且,此技術可以根據周圍環境,實時追蹤噪聲源與目標聲源的方位,做到定向降噪。
附圖說明
為了使本發明的目的、技術方案和有益效果更加清楚,本發明提供如下附圖進行說明:
圖1為本發明實施例的一種追蹤噪聲源和目標聲源的雙麥克風降噪系統結構示意圖;
圖2為本發明實施例的一種追蹤噪聲源和目標聲源的雙麥克風降噪系統中前向與后向差分麥克風陣列的極坐標增益曲線;
圖3為本發明實施例的一種追蹤噪聲源和目標聲源的雙麥克風降噪系統中估算模塊輸出的極坐標增益曲線與聲源定位模塊判定的目標聲源方向;
圖4為采用本發明實施例的一種追蹤噪聲源和目標聲源的雙麥克風降噪系統的輸入噪聲信號輸入輸出波形圖;
圖5為采用本發明實施例的一種追蹤噪聲源和目標聲源的雙麥克風降噪系統的輸入語音信號輸入輸出波形圖;
圖6為本發明實施例的一種追蹤噪聲源和目標聲源的雙麥克風降噪方法的步驟流程圖。
具體實施方式
下面將結合附圖,對本發明的優選實施例進行詳細的描述。
參見圖1,所示為本發明實施例的一種追蹤噪聲源和目標聲源的雙麥克風降噪系統,包括聲源定位模塊10、延時相加器20、前向差分麥克風陣列30、后向差分麥克風陣列40、估算模塊50和維納濾波器60,其中,
所述聲源定位模塊10的輸入為前向和后向麥克風的兩路頻域信號,對目標聲源及噪聲源的方向進行計算后輸出;
所述延時相加器20的輸入為聲源定位模塊10輸出的目標聲源方向、前向和后向麥克風的兩路頻域信號,輸出為兩路頻域信號經方向識別和延時相加后,信噪比提升的混合信號;
所述前向差分麥克風陣列30和后向差分麥克風陣列40分別與所述延時相加器20連接,二者的輸入均為延時相加器20輸出的混合信號加后向麥克風的頻域信號,輸出分別為前向信號和后向信號;
所述估算模塊50與前向差分麥克風陣列30和后向差分麥克風陣列40以及聲源定位模塊10分別連接,根據三者的輸出估算出前向目標信號;
所述維納濾波器60與所述估算模塊50連接,將前向目標信號進行維納濾波,輸出目標語音信號。
進一步地,所述聲源定位模塊10輸出的目標聲源方向記為θt,噪聲源方向記為θn由如下公式獲得:
Xθ(ω)=X1(ω)+e-jωτcos(θ)X2(ω);
θt(ω)=θ,當Xθ(ω)=max(Xθ(ω)),且θ=-60°到60°;
θn(ω)=θ,當Xθ(ω)=max(Xθ(ω)),且θ=120°到240°;
其中,Xθ(ω)為不同延時疊加后的混合信號、θ為信號不同的入射角度、θt為目標聲源的方向、θn為噪聲源的方向、ω為角頻率、τ為后向麥克風的延時大小,0°定義為正前方。
進一步地,所述延時相加器20的輸出由如下公式獲得:
其中,X1(ω)為前向麥克風的頻域信號、X2(ω)為后向麥克風的頻域信號、θt為目標聲源即前向聲源的方向、ω為角頻率、τ為后向麥克風的延時大小,Xm(ω)為延時相加器20輸出的混合信號。
進一步地,所述前向差分麥克風陣列30輸出的前向信號由如下公式獲得:
Xf(ω)=Xm(ω)-e-jωτX2(ω)
其中,X2(ω)為后向麥克風的頻域信號、ω為角頻率、τ為后向麥克風的延時大小、Xm(ω)為延時相加器20輸出的混合信號、Xf(ω)為前向信號;
后向差分麥克風陣列40輸出的后向信號由如下公式獲得:
Xb(ω)=Xm(ω)-ejωτX2(ω)
其中,X2(ω)為后向麥克風的頻域信號、ω為角頻率、τ為后向麥克風的延時大小、Xm(ω)為延時相加器20輸出的混合信號、Xb(ω)為后向信號。
進一步地,所述估算模塊50輸出的前向目標信號由如下公式獲得:
XS(ω)=Xf(ω)-CXb(ω)
其中,Xf(ω)為前向信號、Xb(ω)為后向信號、C為介于0.1到1之間的常數,由噪聲源的方向所決定、Xs(ω)為前向目標信號。
進一步地,所述維納濾波器60輸出的目標語音信號由如下公式獲得:
其中,Xm(ω)為延時相加器20輸出的混合信號、Xs(ω)為前向目標信號、X2(ω)為后向麥克風的頻域信號、S(ω)為目標語音信號。
首先,進行目標聲源與噪聲源的定位。其中,Xθ為不同延時疊加后的混合信號,θ為信號不同的入射角度。聲源定位模塊10需要遍歷在不同入射角度下的混合信號的強度,然后在正前方120度(-60到60度)以及正后方120度(120到240度)的范圍內分別檢測出相應的信號能量的峰值,對應于目標聲源(θt)與噪聲源(θn)的方向。
圖2為本發明實施例的一種追蹤噪聲源和目標聲源的雙麥克風降噪系統中前向與后向差分麥克風陣列輸出的極坐標增益曲線:曲線1為前向信號Xf(ω)的極坐標增益曲線、曲線2為后向信號Xb(ω)的極坐標增益曲線;
圖3為本發明實施例的一種追蹤噪聲源和目標聲源的雙麥克風降噪系統中估算模塊輸出的極坐標增益曲線:使用前后向的兩路輸出信號Xf(ω)和Xb(ω),估算前向目標信號Xs(ω),當C=0.2時,噪聲源為135°,曲線3為Xs(ω)的極坐標增益曲線、曲線4為目標聲源的定位方向,30°;
為了說明本發明的有益效果,判定其是否對噪聲進行了有效地去除,通過下述兩種測試的波形來進行說明及驗證。
參見圖4,為采用本發明實施例的一種追蹤噪聲源和目標聲源的雙麥克風降噪系統的輸入噪聲信號輸入輸出波形圖:當噪聲信號為來自135°的語譜噪聲時,降噪前(曲線51),降噪后(曲線71)的信號與無噪信號(曲線61)對比圖,此處截取的為純噪聲片段,因此降噪處理降低了噪聲信號的幅度。
參見圖5為采用本發明實施例的一種追蹤噪聲源和目標聲源的雙麥克風降噪系統的輸入語音信號輸入輸出波形圖:當噪聲信號為來自180°的語譜噪聲時,降噪前(曲線52),降噪后(曲線72)的信號與原始語音信號(曲線62)對比圖,此處截取的為純語音片段,因此降噪處理后的信號幅度仍然很接近原始信號的幅度,語音信號并未受到降噪算法的影響。
與上述系統對應的,本發明還提供了一種追蹤噪聲源和目標聲源的雙麥克風降噪方法,其流程圖參見圖6,包括以下步驟:
S101,前向和后向麥克風的兩路頻域信號輸入聲源定位模塊,聲源定位模塊對目標聲源及噪聲源的方向進行判斷計算后輸出;
S102,目標聲源方向、前向和后向麥克風的兩路頻域信號輸入延時相加器,進行延時相加及信噪比提升處理,輸出混合信號;
S103,混合信號和后向麥克風的頻域信號同時輸入前向差分麥克風陣列和后向差分麥克風陣列,而后分別輸出前向信號和后向信號;
S104,前向信號、后向信號及噪聲源的方向一同輸入估算模塊,估算出前向目標信號;
S105,維納濾波器與所述估算模塊連接,將前向目標信號進行維納濾波,輸出目標語音信號。
進一步地,S101所述聲源定位模塊輸出的目標聲源方向記為θt,噪聲源方向記為θn,由如下公式獲得:
Xθ(ω)=X1(ω)+e-jωτcos(θ)X2(ω);
θt(ω)=θ,當Xθ(ω)=max(Xθ(ω)),且θ=-60°到60°;
θn(ω)=θ,當Xθ(ω)=max(Xθ(ω)),且θ=120°到240°;
其中,Xθ(ω)為不同延時疊加后的混合信號、θ為信號不同的入射角度、θt為目標聲源的方向、θn為噪聲源的方向、ω為角頻率、τ為后向麥克風的延時大小,0°定義為正前方。
進一步地,S102所述延時相加器的輸出由如下公式獲得:
其中,X1(ω)為前向麥克風的頻域信號、X2(ω)為后向麥克風的頻域信號、θt為目標聲源即前向聲源的方向、ω為角頻率、τ為后向麥克風的延時大小,Xm(ω)為延時相加器輸出的混合信號。
進一步地,S103所述前向差分麥克風陣列輸出的前向信號由如下公式獲得:
Xf(ω)=Xm(ω)-e-jωτX2(ω)
其中,X2(ω)為后向麥克風的頻域信號、ω為角頻率、τ為后向麥克風的延時大小、Xm(ω)為延時相加器輸出的混合信號、Xf(ω)為前向信號;
后向差分麥克風陣列輸出的后向信號由如下公式獲得:
Xb(ω)=Xm(ω)-ejωτX2(ω)
其中,X2(ω)為后向麥克風的頻域信號、ω為角頻率、τ為后向麥克風的延時大小、Xm(ω)為延時相加器輸出的混合信號、Xb(ω)為后向信號。
進一步地,S104所述估算模塊輸出的前向目標信號由如下公式獲得:
XS(ω)=Xf(ω)-CXb(ω)
其中,Xf(ω)為前向信號、Xb(ω)為后向信號、C為介于0.1到1之間的常數,由噪聲源的方向所決定、Xs(ω)為前向目標信號。
進一步地,S105所述維納濾波器輸出的目標語音信號由如下公式獲得:
其中,Xm(ω)為延時相加器輸出的混合信號、Xs(ω)為前向目標信號、X2(ω)為后向麥克風的頻域信號、S(ω)為目標語音信號。
具體實施例參照上述系統實施例,在此不贅述。
最后說明的是,以上優選實施例僅用以說明本發明的技術方案而非限制,盡管通過上述優選實施例已經對本發明進行了詳細的描述,但本領域技術人員應當理解,可以在形式上和細節上對其作出各種各樣的改變,而不偏離本發明權利要求書所限定的范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!