一種數據質量的評估方法及評估系統與流程
本發明涉及一種數據質量的評估方法及評估系統,屬于數據分析領域。
背景技術:
語音識別技術需要大量的說話人語音數據,該語音數據用來模擬真實應用場景中的用戶語音輸入,計算機運用深度學習等算法從該語音數據中進行處理生成語音識別模型,從而運用于真實場景的用戶語音識別中。語音數據是計算機學習的基礎,語音數據的質量對語音識別技術的準確性有決定性的作用,尤其是深度學習算法對語音數據有極大的依賴性,計算機迫切需要高質量的語音數據。
現有技術對語音數據的質量評估主要有兩種方法,第一種方法主要用于傳統的語音通信網絡傳輸中,通過語音信號層的分析來判斷語音的清晰度,然而這種方法不適用于語音識別技術的語音數據評價。第二種方法主要用于教育領域,說話人按照預先設定的文本進行朗讀,通過分析說話人聲音和文本的差異性來判斷說話人的朗讀準確性。語音識別需要的語音數據有不同的質量要求,清晰度及文本差異性并不是決定性因素,然而目前并沒有一種專門評估語音數據的質量評估方法。
技術實現要素:
針對上述問題,本發明的目的是提供一種專門評估語音數據的數據質量的評估方法及評估系統。
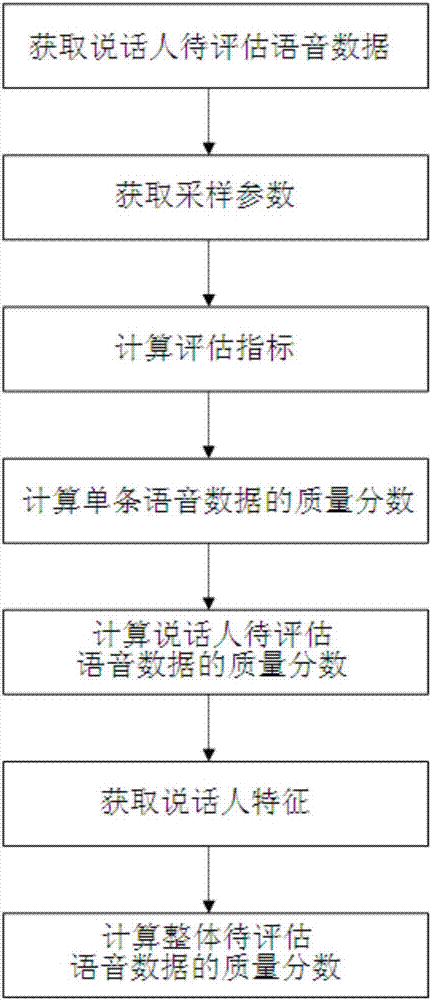
為實現上述目的,本發明采取以下技術方案:一種數據質量的評估方法,其特征在于,包括以下步驟:
1)獲取說話人的待評估語音數據;
2)獲取待評估語音數據的采樣參數;
3)計算待評估語音數據的評估指標;
4)根據采樣參數和評估指標計算說話人待評估語音數據中所有單條語音數據的質量分數;
5)根據所有單條語音數據的質量分數計算該說話人待評估語音數據的質量分數;
6)重復步驟1)~5)計算所有說話人待評估語音數據的質量分數;
7)獲取說話人的特征;
8)根據說話人的特征和預先設定的質量目標計算匹配度,并根據匹配度和所有說話人待評估語音數據的質量分數計算整體待評估語音數據的質量分數。
進一步地,采樣參數包括采樣格式、采樣率、采樣頻率和聲道數。
進一步地,計算評估指標具體為:評估指標包括截幅比例、低音量比例、前后靜音長度和信噪比,其中:
截幅比例:
截幅比例=超過預先設定截幅閾值的采樣點數目/采樣點總數(1)
低音量比例:
低音量比例=小于預先設定低音閾值的采樣點數目/采樣點總數(2)
前后靜音長度:設定從待評估語音數據的開頭位置向后平移,檢測出連續超過預先設定靜音閾值的采樣點作為前靜音結束位置,則:
前靜音長度=前靜音結束位置(3)
設定從待評估語音數據的結束位置向前平移,檢測出連續超過預先設定靜音閾值的采樣點作為后靜音開始位置,則:
后靜音長度=語音數據長度-后靜音開始位置(4)
信噪比:
snr=10lg(ps/pn)(5)
其中,snr為信噪比,ps為信號有效功率,pn為噪音有效功率。
進一步地,計算單條語音數據的質量分數具體為:說話人待評估語音數據中單條待評估語音數據的質量分數為分別基于采樣參數和評估指標進行計算后再進行綜合計算,單條語音數據的質量分數在0~1之間,基于采樣參數的單條語音數據質量分數為各個采樣參數權重的乘積:
qp(d)=w(采樣格式)*w(采樣率)*w(采樣頻率)*w(聲道數)(6)
其中,qp(d)為基于采樣參數的單條語音數據質量分數,w(采樣格式)為采樣格式的權重,w(采樣率)為采樣率的權重,w(采樣頻率)為采樣頻率的權重,w(聲道數)為聲道數的權重,每一采樣參數的權重在0~1之間;基于評估指標的單條語音數據質量分數為各個評估指標權重的乘積:
qe(d)=w(截幅比例)*w(低音量比例)*w(前靜音長度)*w(后靜音長度)*w(信噪比)(7)
其中,qe(d)為基于評估指標的單條語音數據質量分數,w(截幅比例)為截幅比例的權重,w(低音量比例)為低音量比例的權重,w(前靜音長度)為前靜音長度的權重,w(后靜音長度)為后靜音長度的權重,w(信噪比)為信噪比的權重,每一評估指標的權重在0~1之間;綜上,單條語音數據的質量分數q(d)為:
q(d)=qp(d)*qe(d)(8)
進一步地,計算該說話人待評估語音數據的質量分數具體為:說話人待評估語音數據的質量分數為綜合說話人待評估語音數據的所有單條語音數據的質量分數并求平均值,即:
其中,q(s)為說話人待評估語音數據的質量分數,q(di)為說話人第i條單條語音數據的質量分數,n為說話人所有單條語音數據的數量。
進一步地,說話人的特征包括說話人年齡、說話人性別、說話人籍貫、錄音設備、錄音方式和錄音環境。
進一步地,計算整體待評估語音數據的質量分數具體為:
a)預先設定質量目標:質量目標通常對待評估語音數據的錄音設備、錄音方式、錄音環境以及不同說話人的年齡比例、性別比例和籍貫比例進行要求;
b)計算匹配度:對所有說話人按特征分別創建目標向量和實際向量,分別計算所有說話人的各特征目標向量和實際向量的相似度:
上述公式(10)進一步表示為:
其中,cosθ為相似度,ak為目標向量a的第k個目標向量,bk為實際向量b的第k個實際向量,n為目標向量a或實際向量b的個數;根據公式(11)計算所有說話人的各特征相似度,并根據計算的各特征相似度計算整體待評估語音數據與預先設定質量目標的匹配度:
m=年齡相似度*性別相似度*籍貫相似度*錄音設備相似度*錄音方式相似度*錄音環境相似度(12)
其中,m為整體待評估語音數據與預先設定質量目標的匹配度;
c)計算整體待評估語音數據的質量分數:整體待評估語音數據的質量分數為所有說話人的待評估語音數據質量分數的平均值乘以整體待評估語音數據與預先設定質量目標的匹配度,即:
其中,q(all)為整體待評估語音數據的質量分數,q(si)為第i個說話人待評估語音數據的質量分數,m為說話人的數量。
一種數據質量的評估系統,其特征在于,該評估系統包括:一用于獲取說話人待評估語音數據的待評估語音數據獲取單元;一用于獲取待評估語音數據采樣參數的待評估語音數據采樣參數獲取單元;一用于計算待評估語音數據評估指標的待評估語音數據評估指標計算單元;一用于根據采樣參數和評估指標計算說話人待評估語音數據中所有單條語音數據的質量分數的單條語音數據質量分數計算單元;一用于根據所有單條語音數據的質量分數計算該說話人待評估語音數據的質量分數的待評估語音數據質量分數計算單元;一用于獲取說話人特征的特征獲取單元;以及,一用于根據說話人特征和預先設定的質量目標計算匹配度,并根據匹配度和所有說話人待評估語音數據的質量分數計算整體待評估語音數據的質量分數的整體待評估語音數據質量分數計算單元。
本發明由于采取以上技術方案,其具有以下優點:1、本發明根據采樣參數和評估指標計算說話人待評估語音數據的質量分數,并通過說話人特征、預先設定的質量目標計算所有說話人的整體待評估語音數據的質量分數,相對于以往只能通過人工抽查以及使用語音數據后對語音識別設備準確率提升的效果來評估語音數據質量好壞的方法,本發明可以幫助語音識別設備研發企業或機構在事前進行更準確、更高效的語音數據質量評估,還可以幫助語音數據提供商發現語音數據的問題并及時采取優化措施。2、本發明通過獲取采樣參數、評估指標和說話人特征等各種影響語音識別性能的因素,進而能夠保障語音數據質量評估的準確性,可以廣泛應用于語音識別技術領域中。
附圖說明
圖1是本發明的流程示意圖。
具體實施方式
以下結合附圖來對本發明進行詳細的描繪。然而應當理解,附圖的提供僅為了更好地理解本發明,它們不應該理解成對本發明的限制。
如圖1所示,本發明提供的數據質量的評估方法具體包括以下內容:
1、獲取說話人的待評估語音數據
待評估語音數據可以為有意識錄制的待評估語音數據,例如:說話人在室內通過手機等設備每人按照事先準備好的句子進行朗讀后保存的語音數據,也可以為無意識錄制的待評估語音數據,例如:企業客服和說話人通話完成后自動保存的語音數據。
2、獲取待評估語音數據的采樣參數
采樣參數通常由錄音設備及存儲設置決定,可以通過讀取文件屬性或文件頭獲取,采樣參數包括采樣格式(pcm、wav和mp3等)、采樣率(8位或16位)、采樣頻率(8khz、16khz、44khz和48khz等)和聲道數(單聲道和立體聲)。
3、計算待評估語音數據的評估指標
在說話人錄制語音時,由于說話人的原因影響語音數據質量的情況有多種,例如說話人的音量過高或過低、噪音過大、說話人沒有錄音完整、說話錄音不自然等,本發明的數據質量的評估方法針對主要影響語音數據質量的評估指標進行計算,評估指標包括:
截幅比例:待評估語音數據是由一系列連續的采樣點構成,每一采樣點均代表音量的高低,以16khz、16位的wav待評估語音數據為例,該待評估語音數據的峰值為32768,截幅是指說話人音量超過峰值從而造成削波,通過統計待評估語音數據中超過預先設定截幅閾值(如截幅閾值設定為30000)的采樣點數目計算截幅比例:
截幅比例=超過預先設定截幅閾值的采樣點數目/采樣點總數(1)
低音量比例:通過待評估語音數據中小于預先設定低音閾值的采樣點數目計算低音量比例:
低音量比例=小于預先設定低音閾值的采樣點數目/采樣點總數(2)
前后靜音長度:說話人因為操作錄音設備的原因容易出現在設備還未開啟錄制時就搶先說話以及未說完停止錄制的情況,因此需要對前后靜音長度進行計算。設定從待評估語音數據的開頭位置向后平移,檢測出連續超過預先設定靜音閾值的采樣點作為前靜音結束位置,則:
前靜音長度=前靜音結束位置(3)
從待評估語音數據的結束位置向前平移,檢測出連續超過預先設定靜音閾值的采樣點作為后靜音開始位置,則:
后靜音長度=語音數據長度-后靜音開始位置(4)
信噪比:通過現有技術中音頻信噪比的計算方法對信噪比snr進行計算:
snr=10lg(ps/pn)(5)
其中,ps為信號有效功率,pn為噪音有效功率。
此外,其他的評估指標可以通過人工進行判斷,包括說話人語速是否正常、說話人說話是否自然、說話人的說話內容與原始文本的差異性。
4、計算單條語音數據的質量分數
說話人待評估語音數據中單條待評估語音數據d的質量分數為分別基于采樣參數和評估指標進行計算后再進行綜合計算,單條語音數據d的質量分數在0~1之間。
基于采樣參數的單條語音數據質量分數qp(d)為各個采樣參數權重的乘積:
qp(d)=w(采樣格式)*w(采樣率)*w(采樣頻率)*w(聲道數)(6)
其中,w(采樣格式)為采樣格式的權重,w(采樣率)為采樣率的權重,w(采樣頻率)為采樣頻率的權重,w(聲道數)為聲道數的權重,每一采樣參數的權重在0~1之間,均可以根據經驗值得出,經驗值可以根據實際情況進行設置,但需符合以下規則:
采樣格式:mp3的權重<pcm的權重=wav的權重;
采樣率:8位的權重<16位的權重;
采樣頻率:8khz的權重<16khz的權重<44khz的權重<48khz的權重;
聲道數:單聲道的權重<立體聲的權重。
基于評估指標的單條語音數據質量分數qe(d)為各個評估指標權重的乘積:
qe(d)=w(截幅比例)*w(低音量比例)*w(前靜音長度)*w(后靜音長度)*w(信噪比)(7)
其中,w(截幅比例)為截幅比例的權重,w(低音量比例)為低音量比例的權重,w(前靜音長度)為前靜音長度的權重,w(后靜音長度)為后靜音長度的權重,w(信噪比)為信噪比的權重,每一評估指標的權重在0~1之間,均可以根據經驗值得出,經驗值可以根據實際情況進行設置,但需符合以下規則:
截幅比例:截幅比例越大,權重越小;
低音量比例:低音量比例越大,權重越小;
前靜音長度:前靜音長度大于閾值(通常為0.2~0.5s之間)時,權重最大,否則前靜音長度越小,權重越小;
后靜音長度:后靜音長度大于閾值(通常為0.2~0.5s之間)時,權重最大,否則后靜音長度越小,權重越小;
信噪比:信噪比越小,權重越小。
綜上,單條語音數據d的質量分數q(d)為:
q(d)=qp(d)*qe(d)(8)
5、計算說話人待評估語音數據的質量分數
說話人待評估語音數據的質量分數q(s)為綜合說話人待評估語音數據的所有單條語音數據d的質量分數并求平均值,即:
其中,q(di)為說話人第i條單條語音數據的質量分數,n為說話人所有單條語音數據的數量。
6、重復步驟1~5,計算所有說話人待評估語音數據的質量分數。
7、獲取說話人的特征
說話人的特征可以包括說話人年齡、說話人性別、說話人籍貫、錄音設備(手機、麥克風等)、錄音方式(朗讀、自然、電話呼入、電話呼出等)以及錄音環境(室內、室外、車載等)。
8、計算整體待評估語音數據的質量分數
1)預先設定質量目標
質量目標通常對待評估語音數據的錄音設備、錄音方式、錄音環境以及不同說話人的年齡比例、性別比例和籍貫比例進行要求,具體質量目標可以根據實際情況進行設定,例如某質量目標為1000名說話人,男女各半,年齡在6~60歲均勻分布,籍貫在全國各省均勻分布,錄音設備為手機,錄音方式為朗讀,錄音環境為室內。
2)計算匹配度
對所有說話人按特征為年齡、性別、籍貫、錄音設備、錄音方式和錄音環境分別創建一目標向量和一實際向量,例如性別的目標要求為500男500女,實際語音數據為600男400女,則性別的目標向量為<500,500>,實際向量為<600,400>。
分別計算所有說話人的各特征目標向量和實際向量的相似度,相似度可以通過現有向量相似度計算方法例如夾角余弦法進行計算,即對于目標向量a=<a1,a2,…an>和實際向量b=<b1,b2,…bn>,可以采用夾角余弦的概念衡量兩個向量間的相似度cosθ:
上述公式(10)可以進一步表示為:
其中,ak為目標向量a的第k個目標向量,bk為實際向量b的第k個實際向量,n為目標向量a或實際向量b的個數。
根據公式(11)計算所有說話人的各特征相似度,并根據計算的各特征相似度計算整體待評估語音數據與預先設定質量目標的匹配度m:
m=年齡相似度*性別相似度*籍貫相似度*錄音設備相似度*錄音方式相似度*錄音環境相似度(12)
3)計算整體待評估語音數據的質量分數
整體待評估語音數據的質量分數q(all)為所有說話人的待評估語音數據質量分數的平均值乘以整體待評估語音數據與預先設定質量目標的匹配度m,即:
其中,q(si)為第i個說話人待評估語音數據的質量分數,m為說話人的數量。
根據計算的整體待評估語音數據的質量分可以幫助語音識別設備研發企業或機構在使用語音數據前對語音數據進行更準確、更高效的質量評估,還可以幫助語音數據提供商發現語音數據的問題并及時采取優化措施。
基于上述數據質量的評估方法,本發明還提出一種數據質量的評估系統,該評估系統包括待評估語音數據獲取單元、待評估語音數據采樣參數獲取單元、待評估語音數據評估指標計算單元、單條語音數據質量分數計算單元、待評估語音數據質量分數計算單元、特征獲取單元以及整體待評估語音數據質量分數計算單元;其中,
待評估語音數據獲取單元用于獲取說話人的有意識待評估語音數據或無意識待評估語音數據。待評估語音數據采樣參數獲取單元用于獲取說話人待評估語音數據的采樣格式、采樣率、采樣頻率和聲道數等采樣參數,并將獲取的采樣參數發送到單條語音數據質量分數計算單元。待評估語音數據評估指標計算單元用于計算包括截幅比例、低音量比例、前后靜音長度和信噪比等的待評估語音數據評估指標,并將計算的評估指標發送到單條語音數據質量分數計算單元。單條語音數據質量分數計算單元用于根據接收的采樣參數和評估指標計算說話人待評估語音數據中所有單條語音數據的質量分數并發送到待評估語音數據質量分數計算單元。待評估語音數據質量分數計算單元用于根據接收的所有單條語音數據的質量分數計算該說話人待評估語音數據的質量分數并發送到整體待評估語音數據質量分數計算單元。特征獲取單元用于獲取說話人年齡、說話人性別、說話人籍貫、錄音設備、錄音方式以及錄音環境等特征并發送到整體待評估語音數據質量分數計算單元。整體待評估語音數據質量分數計算單元用于根據接收的說話人特征和預先設定的質量目標計算匹配度,并根據匹配度和所有說話人待評估語音數據的質量分數計算整體待評估語音數據的質量分數。
上述各實施例僅用于說明本發明,其中各部件的結構、連接方式和制作工藝等都是可以有所變化的,凡是在本發明技術方案的基礎上進行的等同變換和改進,均不應排除在本發明的保護范圍之外。
- 還沒有人留言評論。精彩留言會獲得點贊!