標點添加方法和裝置、用于標點添加的裝置與流程
本發明涉及信息處理技術領域,特別是涉及一種標點添加方法和裝置、以及一種用于標點添加的裝置。
背景技術:
在通信領域以及互聯網領域等信息處理技術領域,在某些應用場景中需要為一些缺少標點的文件添加標點。例如,為了方便閱讀,為語音識別結果對應的文本添加標點等。
現有方案,可以依據語音信號的靜音間隔,為語音識別結果對應的文本添加標點。具體地,可以首先設置靜音長短的閾值,如果語音信號中講話用戶說話時的靜音間隔的長度超過該閾值,則在對應的位置上添加標點;反之,如果語音信號中講話用戶說話時的靜音間隔的長度未超過該閾值,則不添加標點。
然而,發明人在實現本發明實施例的過程中發現,不同講話用戶往往具有不同的語速,這樣,現有方案中依據語音信號的靜音間隔,為語音識別結果對應的文本添加標點,將影響標點添加的準確度。例如,若講話用戶的語速過快,則語句之間沒有間隔、或者間隔很短以至于小于閾值,那么將不為文本添加任何標點;又如,若講話用戶的語速過慢,接近一字一頓的情況,那么文本將對應有很多的標點;上述兩種情況均會造成標點添加錯誤,也即標點添加的準確度較低。
技術實現要素:
鑒于上述問題,提出了本發明實施例以便提供一種克服上述問題或者至少部分地解決上述問題的標點添加方法、標點添加裝置、用于標點添加的裝置,本發明實施例可以提高標點添加的準確度。
為了解決上述問題,本發明公開了一種標點添加方法,包括:
獲取待處理文本;
通過神經網絡轉換模型為所述待處理文本添加標點,以得到所述待處理文本對應的標點添加結果;其中,所述神經網絡轉換模型為依據平行語料訓練得到,所述平行語料包括:源端語料和目標端語料,所述目標端語料為所述源端語料中各詞匯對應的標點。
可選地,所述通過神經網絡轉換模型為所述待處理文本添加標點,包括:
對所述待處理文本進行編碼,以得到所述待處理文本對應的源端隱層狀態;
依據神經網絡轉換模型的模型參數,對所述待處理文本對應的源端隱層狀態進行解碼,以得到所述待處理文本中各詞匯屬于候選標點的概率;
依據待處理文本中各詞匯屬于候選標點的概率,得到所述待處理文本對應的標點添加結果。
可選地,所述通過神經網絡轉換模型為所述待處理文本添加標點,還包括:
確定所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率;
則所述依據神經網絡轉換模型的模型參數,對所述待處理文本對應的源端隱層狀態進行解碼,包括:
依據所述對齊概率和所述待處理文本對應的源端隱層狀態,得到源端對應的上下文向量;
依據所述上下文向量,確定目標端隱層狀態;
依據所述隱層狀態和神經網絡轉換模型的模型參數,確定所述待處理文本中各詞匯屬于候選標點的概率。
可選地,所述確定所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率,包括:
依據神經網絡轉換模型的模型參數和目標端隱層狀態,得到所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率;或者
通過比較所述源端隱層狀態和目標端隱層狀態,得到所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率;或者
確定目標端位置對應的對齊源端位置,確定各目標端位置與其對應的對齊源端位置之間的對齊概率。
可選地,所述源端隱層狀態包括:前向的源端隱層狀態;或者,所述源端隱層狀態包括:前向的源端隱層狀態和后向的源端隱層狀態。
可選地,依據平行語料訓練得到神經網絡轉換模型,包括:
依據神經網絡結構,建立源端的詞匯到目標端的標點的神經網絡轉換模型;
利用神經網絡學習算法,對平行語料進行訓練,以得到所述神經網絡轉換模型的模型參數。
可選地,所述神經網絡結構包括以下至少一種:循環神經網絡rnn、長短期記憶lstm、以及門控循環單元gru。
另一方面,本發明公開了一種標點添加裝置,包括:
文本獲取模塊,用于獲取待處理文本;
標點添加模塊,用于通過神經網絡轉換模型為所述待處理文本添加標點,以得到所述待處理文本對應的標點添加結果;其中,所述神經網絡轉換模型為依據平行語料訓練得到,所述平行語料包括:源端語料和目標端語料,所述目標端語料為所述源端語料中各詞匯對應的標點。
可選地,所述標點添加模塊包括:
編碼子模塊,用于對所述待處理文本進行編碼,以得到所述待處理文本對應的源端隱層狀態;
解碼子模塊,用于依據神經網絡轉換模型的模型參數,對所述待處理文本對應的源端隱層狀態進行解碼,以得到所述待處理文本中各詞匯屬于候選標點的概率;
結果確定子模塊,用于依據待處理文本中各詞匯屬于候選標點的概率,得到所述待處理文本對應的標點添加結果。
可選地,所述標點添加模塊還包括:
對齊概率確定子模塊,用于確定所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率;
則所述解碼子模塊包括:
上下文向量確定單元,用于依據所述對齊概率和所述待處理文本對應的源端隱層狀態,得到源端對應的上下文向量;
目標端隱層狀態確定單元,用于依據所述上下文向量,確定目標端隱層狀態;
概率確定單元,用于依據所述隱層狀態和神經網絡轉換模型的模型參數,確定所述待處理文本中各詞匯屬于候選標點的概率。
可選地,所述對齊概率確定子模塊包括:
第一對齊概率確定單元,用于依據神經網絡轉換模型的模型參數和目標端隱層狀態,得到所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率;或者
第二對齊概率確定單元,用于通過比較所述源端隱層狀態和目標端隱層狀態,得到所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率;或者
第三對齊概率確定單元,用于確定目標端位置對應的對齊源端位置,確定各目標端位置與其對應的對齊源端位置之間的對齊概率。
可選地,所述源端隱層狀態包括:前向的源端隱層狀態,或者,所述源端隱層狀態包括:前向的源端隱層狀態和后向的源端隱層狀態。
可選地,所述裝置還包括:用于依據平行語料訓練得到神經網絡轉換模型的訓練模塊;
所述訓練模塊包括:
模型建立子模塊,用于依據神經網絡結構,建立源端的詞匯到目標端的標點的神經網絡轉換模型;
模型參數訓練子模塊,用于利用神經網絡學習算法,對平行語料進行訓練,以得到所述神經網絡轉換模型的模型參數。
可選地,所述神經網絡結構包括以下至少一種:循環神經網絡rnn、長短期記憶lstm、以及門控循環單元gru。
再一方面,本發明公開了一種用于標點添加的裝置,包括有存儲器,以及一個或者一個以上的程序,其中一個或者一個以上程序存儲于存儲器中,且經配置以由一個或者一個以上處理器執行所述一個或者一個以上程序包含用于進行以下操作的指令:
獲取待處理文本;
通過神經網絡轉換模型為所述待處理文本添加標點,以得到所述待處理文本對應的標點添加結果;其中,所述神經網絡轉換模型為依據平行語料訓練得到,所述平行語料包括:源端語料和目標端語料,所述目標端語料為所述源端語料中各詞匯對應的標點。
又一方面,本發明公開了一種機器可讀介質,其上存儲有指令,當由一個或多個處理器執行時,使得裝置執行前述的標點添加方法。
本發明實施例包括以下優點:
本發明實施例將標點添加的問題轉換為詞匯標點轉換的問題,該詞匯標點轉換具體為將源端語料中各詞匯轉換為目標端對應的標點,并通過基于平行語料訓練得到的神經網絡轉換模型處理該詞匯標點轉換問題,由于神經網絡可以通過詞向量來表示一個詞匯,并通過詞向量之間的距離來表征詞匯之間的語義距離,這樣本發明實施例可將一個詞匯對應的眾多上下文參與到網絡轉換模型的訓練,使得該神經網絡轉換模型具備準確的標點添加能力;因此,通過神經網絡轉換模型為所述待處理文本添加標點,可以提高標點添加的準確度。
附圖說明
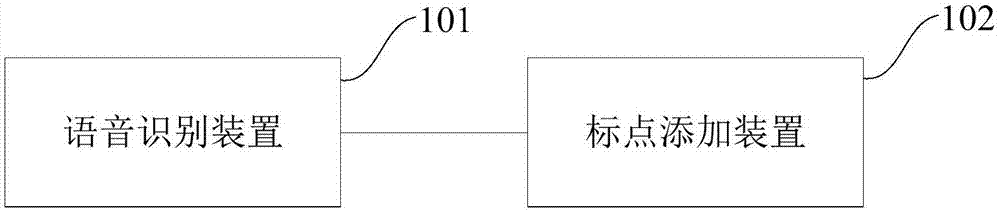
圖1是本發明的一種語音識別系統的示例性結構示意圖;
圖2是本發明的一種標點添加方法實施例的步驟流程圖;
圖3是本發明的一種標點添加裝置實施例的結構框圖;
圖4是根據一示例性實施例示出的一種用于標點添加的裝置作為終端時的框圖;及
圖5是根據一示例性實施例示出的一種用于標點添加的裝置作為服務器時的框圖。
具體實施方式
為使本發明的上述目的、特征和優點能夠更加明顯易懂,下面結合附圖和具體實施方式對本發明作進一步詳細的說明。
本發明實施例提供了一種標點添加方案,該方案可以獲取待處理文本,并通過神經網絡轉換模型為所述待處理文本添加標點,以得到所述待處理文本對應的標點添加結果;其中,所述神經網絡轉換模型為依據平行語料訓練得到,所述平行語料可以包括:源端語料和目標端語料,所述目標端語料為所述源端語料中各詞匯對應的標點。
本發明實施例將標點添加的問題轉換為詞匯標點轉換的問題,該詞匯標點轉換具體為將源端語料中各詞匯轉換為目標端對應的標點,并通過基于平行語料訓練得到的神經網絡轉換模型處理該詞匯標點轉換問題,由于神經網絡可以通過詞向量來表示一個詞匯,并通過詞向量之間的距離來表征詞匯之間的語義距離,這樣本發明實施例可將一個詞匯對應的眾多上下文參與到神經網絡轉換模型的訓練,使得該神經網絡轉換模型具備準確的標點添加能力;因此,通過神經網絡轉換模型為所述待處理文本添加標點,可以提高標點添加的準確度。
本發明實施例可以應用于在語音識別、語音翻譯等需要添加標點的任意應用場景,可以理解,本發明實施例對于具體的應用場景不加以限制。
本發明實施例提供的標點添加方法可應用于終端或者服務器等裝置的應用環境中。可選地,上述終端可以包括但不限于:智能手機、平板電腦、膝上型便攜計算機、車載電腦、臺式計算機、智能電視機、可穿戴設備等等。上述服務器可以為云服務器或者普通服務器,用于向客戶端提供標點添加服務。
本發明實施例提供的標點添加方法可適用于中文、日文、韓文等語言的處理處理,用于提高標點添加的準確度。可以理解,任意的需要進行添加標點的語言均在本發明實施例的標點添加方法方法的適用范圍內。
參照圖1,示出了本發明的一種語音識別系統的示例性結構示意圖,其具體可以包括:語音識別裝置101和標點添加裝置102。其中,語音識別裝置101和標點添加裝置102可以作為單獨的裝置(包括服務器或者終端),可以共同設置于同一個裝置中;可以理解,本發明實施例對于語音識別裝置101和標點添加裝置102的具體設置方式不加以限制。
其中,語音識別裝置101可用于將講話用戶的語音信號轉換為文本信息,具體地,語音識別裝置101可以輸出語音識別結果。在實際應用中,講話用戶可以為語音翻譯的場景中講話并發出語音信號的用戶,則可以通過麥克風或其他語音采集器件接收講話用戶的語音信號,并向語音識別裝置101發送所接收的語音信號;或者,該語音識別裝置101可以具有接收講話用戶的語音信號的功能。
可選地,語音識別裝置101可以采用語音識別技術將講話用戶的語音信號轉換為文本信息。如果將用戶講話用戶的語音信號記作s,對s進行一系列處理后得到與之相對應的語音特征序列o,記作o={o1,o2,…,ok,…,ot},其中oi是第k個語音特征,t為語音特征總個數。語音信號s對應的句子可看作是由許多詞組成的一個詞串,記作w={w1,w2,…,wn}。語音識別的過程就是根據已知的語音特征序列o,求出最可能的詞串w,其中,k、t和n為正整數。
具體來說,語音識別是一個模型匹配的過程,在這個過程中,可以首先根據人的語音特點建立語音模型,通過對輸入的語音信號的分析,抽取所需的特征,來建立語音識別所需的模板;對用戶所輸入語音進行識別的過程即是將用戶所輸入語音的特征與所述模板比較的過程,最后確定與所述用戶所輸入語音匹配的最佳模板,從而獲得語音識別的結果。具體的語音識別算法,可采用基于統計的隱含馬爾可夫模型的訓練和識別算法,也可采用基于神經網絡的訓練和識別算法、基于動態時間歸整匹配的識別算法等等其他算法,本發明實施例對于具體的語音識別過程不加以限制。
標點添加裝置102可以與語音識別裝置101連接,其可以接收語音識別裝置101發送的語音識別結果,為接收到的語音識別結果添加標點。具體地,其可以將接收到的語音識別結果作為待處理文本,通過神經網絡轉換模型為所述待處理文本添加標點,以得到所述待處理文本對應的標點添加結果,并輸出所述待處理文本對應的標點添加結果。
可選地,在語音識別的應用場景下,標點添加裝置102可以向用戶或者用戶對應的客戶端輸出該標點添加結果;在語音翻譯的應用場景下,標點添加裝置102可以向機器翻譯裝置輸出該標點添加結果。可以理解,本領域技術人員可以根據實際的應用場景,確定所述待處理文本對應的標點添加結果對應的輸出方式,本發明實施例對于所述待處理文本對應的標點添加結果對應的具體輸出方式不加以限制。
方法實施例
參照圖2,示出了本發明的一種標點添加方法實施例的步驟流程圖,具體可以包括如下步驟:
步驟201、獲取待處理文本;
步驟202、通過神經網絡轉換模型為所述待處理文本添加標點,以得到所述待處理文本對應的標點添加結果;其中,所述神經網絡轉換模型可以為依據平行語料訓練得到,所述平行語料可以包括:源端語料和目標端語料,所述目標端語料可以為所述源端語料中各詞匯對應的標點。
本發明實施例中,待處理文本可用于表示需要進行添加標點的文本,該待處理文本可以來源于用戶通過裝置輸入的文本或者語音,也可以來自其他裝置。需要說明的是,上述待處理文本中可以包括:一種語言、或者一種以上的語言,例如,上述待處理文本中可以包括中文,也可以包括中文與例如英文的其他語言的混合,本發明實施例對具體的待處理文本不加以限制。
在實際應用中,本發明實施例可以通過客戶端app(應用,application)執行本發明實施例的標點添加方法流程,客戶端應用可以運行在終端上,例如,該客戶端應用可以為終端上運行的任意app,則該客戶端應用可以從終端的其他應用獲取待處理文本。或者,本發明實施例可以通過客戶端應用的功能裝置執行本發明實施例的標點添加方法流程,則該功能裝置可以從其他功能裝置獲取待處理文本。或者,本發明實施例可以通過服務器執行本發明實施例的標點添加方法。
在本發明的一種可選實施例中,步驟201可以依據講話用戶的語音信號獲取待處理文本,此種情況下,步驟201可以將講話用戶的語音信號轉換為文本信息,并從該文本信息中獲取待處理文本。或者,步驟201可以直接從語音識別裝置接收用戶的語音信號對應的文本信息,并從從該文本信息中獲取待處理文本。
在實際應用中,步驟201可以根據實際應用需求,從語音信號對應的文本或者用戶輸入的文本中獲取待處理文本。可選地,可以依據語音信號s的間隔時間,從語音信號s對應的文本中獲取待處理文本;例如,在語音信號s的間隔時間大于時間閾值時,可以依據該時間點確定對應的第一分界點,將該第一分界點之前的語音信號s對應的文本作為待處理文本,并對該第一分界點之后的語音信號s對應的文本進行處理,以繼續從中獲取待處理文本。或者,可選地,可以依據語音信號對應的文本或者用戶輸入的文本所包含的字數,從語音信號對應的文本或者用戶輸入的文本中獲取待處理文本;例如,在語音信號對應的文本或者用戶輸入的文本包含的字數大于字數閾值時,可以依據該字數閾值確定對應的第二分界點,可以將該第二分界點之前的語音信號s對應的文本作為待處理文本,并對該第二分界點之后的語音信號s對應的文本進行處理,以繼續從中獲取待處理文本。可以理解,本發明實施例對于從語音信號對應的文本或者用戶輸入的文本中獲取待處理文本的具體過程不加以限制。
本發明實施例的神經網絡轉換模型可以為依據平行語料訓練得到。由于神經網絡可以通過詞向量來表示一個詞匯,并通過詞向量之間的距離來表征詞匯之間的語義距離,這樣本發明實施例可將一個詞匯對應的眾多上下文參與到網絡轉換模型的訓練,使得該神經網絡轉換模型具備準確的標點添加能力。
在實際應用中,所述平行語料可以包括:源端語料和目標端語料,所述目標端語料可以為所述源端語料中各詞匯對應的標點,通常,各詞匯對應的標點可以為該詞匯后面添加的標點。在實際應用中,源端語料可以包括:若干個源端句子,目標端語料可以為上述源端句子中各詞匯對應的標點。在實際應用中,目標端語料包括的標點可以為實際的標點符號,和/或,目標端語料包括的標點可以為實際的標點符號對應的標識,和/或,目標端語料包括的標點可以為標點添加結果對應的標識,可以理解,本發明實施例對于目標端語料包括的標點的具體表征方式不加以限制。可選地,對于“在對應詞匯后不加標點”對應的標點添加結果,可以將“_”作為其對應的標識;例如,對于源端句子“今天天氣怎么樣我們出去玩吧”,其中各詞匯“今天天氣怎么樣我們出去玩吧”對應的目標端標點可以為“__?___!”,其中,“_”表示在對應詞匯后不加標點。
在本發明的一種可選實施例中,依據平行語料訓練得到神經網絡轉換模型的過程可以包括以下至少一種:依據神經網絡結構,建立源端的詞匯到目標端的標點的神經網絡轉換模型;并利用神經網絡學習算法,對平行語料進行訓練,以得到所述神經網絡轉換模型的模型參數。
在本發明的一種可選實施例中,所述神經網絡結構可以包括:rnn(循環神經網絡,recurrentneuralnetworks)、lstm(長短期記憶,longshort-termmemory)、或者gru(門控循環單元,gatedrecurrentunit)等。可以理解,本領域技術人員可以根據實際應用需求,采用所需的神經網絡結構,可以理解,本發明實施例對于具體的神經網絡結構不加以限制。
可選地,上述神經網絡轉換模型可以包括:源端的詞匯到目標端的標點的映射函數,該映射函數可以表示成條件概率的形式,如p(y︱x)或者p(yj︱y<j,x),其中,x表示源端信息(例如待處理文本的信息),y表示目標端信息(例如待處理文本中各詞匯對應的標點);通常添加標點的準確率越高,則該條件概率越大。
在實際應用中,神經網絡結構可以包括有多個神經元層,具體地,該神經元層可以包括:輸入層、隱層及輸出層,其中,輸入層負責接收源端信息,并將其分發到隱層,隱層負責所需的計算、并向輸出層輸出計算結果,輸出層負責輸出目標端信息也即計算結果。在本發明的一種可選實施例中,神經網絡轉換模型的模型參數可以包括:輸入層與隱層之間的第一連接權重w、輸出層與隱層之間的第二連接權重u、以及輸出層和隱層的偏置參數中的至少一種,可以理解,本發明實施例對于具體的網絡轉換模型及其對應的模型參數不加以限制。
對平行語料進行訓練,神經網絡轉換模型的最大化目標是給定源端信息x輸出正確標點信息y的概率。在實際應用中,可以利用神經網絡學習算法,對平行語料進行訓練,并利用例如隨機梯度下降方法的優化方法對模型參數進行優化,例如,上述優化可以根據輸出層的誤差對模型參數求梯度,并依據優化方法對模型參數進行更新,這樣可以實現神經網絡轉換模型的最大化目標。可選地,神經網絡學習算法可以包括:bp(誤差反向傳播,errorbackpropagation)算法、遺傳等,可以理解,本發明實施例對于具體的神經網絡學習算法、以及利用神經網絡學習算法,對平行語料進行訓練的具體過程不加以限制。
在實際應用中,可以將所述待處理文本輸入訓練得到的神經網絡轉換模型,由該神經網絡轉換模型對該待處理文本進行處理,并輸出所述待處理文本對應的標點添加結果。在本發明的一種可選實施例中,上述通過神經網絡轉換模型為所述待處理文本添加標點涉及的神經網絡轉換模型對該待處理文本進行處理的過程可以包括:
步驟s1、對所述待處理文本進行編碼,以得到所述待處理文本對應的源端隱層狀態;
步驟s2、依據神經網絡轉換模型的模型參數,對所述待處理文本對應的源端隱層狀態進行解碼,以得到所述待處理文本中各詞匯屬于候選標點的概率;
步驟s3、依據待處理文本中各詞匯屬于候選標點的概率,得到所述待處理文本對應的標點添加結果。
在實際應用中,步驟s1可以首先將待處理文本中各詞匯轉化為對應的詞表向量,該詞表向量的維度可以與詞匯表的大小相同,但由于詞匯表的大小導致詞表向量的維度較大,為了避免維數災難、且更好地表達詞匯與詞匯之間的語義關系,可以將該詞表向量映射到一個低維的語義空間,每個詞匯將由一個固定維度的稠密向量表示,該稠密向量被稱作詞向量,該詞向量之間的距離可以在一定程度上衡量詞匯之間的相似性。進一步,可以利用神經網絡結構壓縮待處理文本對應的詞序列,以得到整個待處理文本的壓縮表示,也即待處理文本對應的源端隱層狀態。可選地,可以采用神經網絡結構隱層的激活函數(如sigmoid(s型函數)、tanh(雙曲正切函數)等),壓縮待處理文本對應的詞序列,以得到待處理文本對應的源端隱層狀態,本發明實施例對于待處理文本對應的源端隱層狀態的具體壓縮方式不加以限制。
在本發明的一種可選實施例中,所述源端隱層狀態可以包括:前向的源端隱層狀態。這樣,待處理文本中各詞匯的隱層狀態只壓縮了其前面的詞匯。或者,所述源端隱層狀態可以包括:前向的源端隱層狀態和后向的源端隱層狀態,這樣,待處理文本中各詞匯的隱層狀態不僅壓縮了其前面的詞匯,還可以壓縮器后面的詞匯,這樣可以將一個詞匯對應的眾多上下文參與到網絡轉換模型的訓練,使得該神經網絡轉換模型具備準確的標點添加能力。
在本發明的一種實施例中,步驟s2可以依據待處理文本對應的源端隱層狀態得到源端對應的上下文向量,依據所述上下文向量,確定目標端隱層狀態,并依據所述隱層狀態和神經網絡轉換模型的模型參數,確定所述待處理文本中各詞匯屬于候選標點的概率。
需要說明的是,本領域技術人員可以根據實際應用需求,確定需要在相鄰詞匯之間添加的候選標點,可選地,上述候選標點可以包括:逗號、問號、句號、感嘆號、空格等,其中,空格“_”可以起到詞分割的作用或者不起任何作用,例如,對于英文而言,空格可用于分割不同的詞,對于中文而言,空格可以為不起任何作用的標點符號,可以理解,本發明實施例對于具體的候選標點不加以限制。
在本發明的一種可選實施例中,源端對應的上下文向量可以為固定向量,具體地,源端對應的上下文向量可以為源端所有源端隱層狀態的組合。在源端對應的上下文向量可以為固定向量的情況下,源端每個詞匯對于每個目標端位置的貢獻是相同的,但這存在一定的不合理性,例如,與目標端位置一致的源端位置對于目標端位置的貢獻明顯更大。上述合理性在源端句子比較短的時候問題不大,但是如果源端句子比較長,缺點將比較明顯,因此將降低標點添加的準確度、且容易增加運算量。
針對上述源端對應的上下文向量可以為固定向量帶來的準確度下降的問題,在本發明的一種可選實施例中,可以采用可變的上下文向量,相對應地,上述通過神經網絡轉換模型為所述待處理文本添加標點還可以包括:步驟s3、確定所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率;
則所述步驟s2、依據神經網絡轉換模型的模型參數,對所述待處理文本對應的源端隱層狀態進行解碼的過程可以包括:依據所述對齊概率和所述待處理文本對應的源端隱層狀態,得到源端對應的上下文向量;依據所述上下文向量,確定目標端隱層狀態;依據所述隱層狀態和神經網絡轉換模型的模型參數,確定所述待處理文本中各詞匯屬于候選標點的概率。
上述對齊概率可用于表征第i個源端位置與第j個目標端位置之間的匹配程度,i和j分別為源端位置和目標端位置的編號,i和j可以均為正整數。依據所述對齊概率和所述待處理文本對應的源端隱層狀態,得到源端對應的上下文向量,這樣可以使源端對應的上下文向量更多地關注于源端的部分詞匯,因此可以在一定程度上降低運算量,且可以提高標點添加的準確度。
本發明實施例可以提供所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率的如下確定方式:
確定方式1、依據神經網絡轉換模型的模型參數和目標端隱層狀態,得到所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率;或者
確定方式2、通過比較所述源端隱層狀態和目標端隱層狀態,得到所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率;或者
確定方式3、確定目標端位置對應的對齊源端位置,確定各目標端位置與其對應的對齊源端位置之間的對齊概率。
其中,確定方式1可以依據神經網絡轉換模型的模型參數和目標端隱層狀態,得到對齊概率,具體地,可以對第一連接權重和目標端隱層狀態的乘積輸入softmax函數,由softmax函數輸出對齊概率。其中,softmax函數為歸一化函數,其可以把一堆實數的值映射到[0,1]區間,并且使它們的和為1。
確定方式2可以通過對齊函數對所述源端隱層狀態和目標端隱層狀態進行比較。對齊函數的例子可以為打分函數的指數與基于隱層狀態對打分函數的指數的求和結果之間的比值,打分函數可以為與源端隱層狀態和目標端隱層狀態相關的函數,可以理解,本發明實施例對于具體的對齊函數不加以限制。
確定方式3可以針對第j個目標端位置生成對應的對齊源端位置pj,并在源端取窗口[pj-d,pj+d],d為正整數,則上下文向量可以通過計算窗口內的源端隱層狀態的加權平均得到,如果窗口超出源端句子的邊界,則以句子的邊界為準。其中,pj可以為預設值,也可以為在線估計得到的值,本發明實施例對于對齊源端位置pj的具體確定過程不加以值。
以上通過確定方式1至確定方式3對于對齊概率的確定過程進行了詳細介紹,可以理解,本領域技術人員可以根據實際應用需求,采用確定方式1至確定方式3中的任一,或者,還可以采用其他確定方式,本發明實施例對于對齊概率的具體確定過程不加以限制。
步驟s3可以依據步驟s2得到的待處理文本中各詞匯屬于候選標點的概率,得到所述待處理文本對應的標點添加結果,具體地,可以將針對一個詞匯將概率最大的候選標點作為其對應的目標標點。進一步,可以依據待處理文本中各詞匯對應的目標標點,得到待處理文本對應的標點添加結果,該標點添加結果可以為經過標點添加處理的待處理文本。例如,待處理文本“你好我是小明很高興認識你”對應的標點添加結果可以為“你好,我是小明,很高興認識你”。當然,該標點添加結果可以為待處理文本中各詞匯對應的目標標點,可以理解,本發明實施例對于該標點添加結果的具體表征方式不加以限制。
綜上,本發明實施例的標點添加方法,將標點添加的問題轉換為詞匯標點轉換的問題,該詞匯標點轉換具體為將源端語料中各詞匯轉換為目標端對應的標點,并通過基于平行語料訓練得到的神經網絡轉換模型處理該詞匯標點轉換問題,由于神經網絡可以通過詞向量來表示一個詞匯,并通過詞向量之間的距離來表征詞匯之間的語義距離,這樣本發明實施例可將一個詞匯對應的眾多上下文參與到網絡轉換模型的訓練,使得該神經網絡轉換模型具備準確的標點添加能力;因此,通過神經網絡轉換模型為所述待處理文本添加標點,可以提高標點添加的準確度。
需要說明的是,對于方法實施例,為了簡單描述,故將其都表述為一系列的運動動作組合,但是本領域技術人員應該知悉,本發明實施例并不受所描述的運動動作順序的限制,因為依據本發明實施例,某些步驟可以采用其他順序或者同時進行。其次,本領域技術人員也應該知悉,說明書中所描述的實施例均屬于優選實施例,所涉及的運動動作并不一定是本發明實施例所必須的。
裝置實施例
參照圖3,示出了本發明的一種標點添加裝置實施例的結構框圖,具體可以可以包括:
文本獲取模塊301,用于獲取待處理文本;
標點添加模塊302,用于通過神經網絡轉換模型為所述待處理文本添加標點,以得到所述待處理文本對應的標點添加結果;其中,所述神經網絡轉換模型為依據平行語料訓練得到,所述平行語料可以包括:源端語料和目標端語料,所述目標端語料為所述源端語料中各詞匯對應的標點。
可選地,所述標點添加模塊302可以包括:
編碼子模塊,用于對所述待處理文本進行編碼,以得到所述待處理文本對應的源端隱層狀態;
解碼子模塊,用于依據神經網絡轉換模型的模型參數,對所述待處理文本對應的源端隱層狀態進行解碼,以得到所述待處理文本中各詞匯屬于候選標點的概率;
結果確定子模塊,用于依據待處理文本中各詞匯屬于候選標點的概率,得到所述待處理文本對應的標點添加結果。
可選地,所述標點添加模塊302還可以包括:
對齊概率確定子模塊,用于確定所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率;
則所述解碼子模塊可以包括:
上下文向量確定單元,用于依據所述對齊概率和所述待處理文本對應的源端隱層狀態,得到源端對應的上下文向量;
目標端隱層狀態確定單元,用于依據所述上下文向量,確定目標端隱層狀態;
概率確定單元,用于依據所述隱層狀態和神經網絡轉換模型的模型參數,確定所述待處理文本中各詞匯屬于候選標點的概率。
可選地,所述對齊概率確定子模塊可以包括:
第一對齊概率確定單元,用于依據神經網絡轉換模型的模型參數和目標端隱層狀態,得到所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率;或者
第二對齊概率確定單元,用于通過比較所述源端隱層狀態和目標端隱層狀態,得到所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率;或者
第三對齊概率確定單元,用于確定目標端位置對應的對齊源端位置,確定各目標端位置與其對應的對齊源端位置之間的對齊概率。
可選地,所述源端隱層狀態可以包括:前向的源端隱層狀態,或者,所述源端隱層狀態可以包括:前向的源端隱層狀態和后向的源端隱層狀態。
可選地,所述裝置還可以包括:用于依據平行語料訓練得到神經網絡轉換模型的訓練模塊;
所述訓練模塊可以包括:
模型建立子模塊,用于依據神經網絡結構,建立源端的詞匯到目標端的標點的神經網絡轉換模型;
模型參數訓練子模塊,用于利用神經網絡學習算法,對平行語料進行訓練,以得到所述神經網絡轉換模型的模型參數。
可選地,所述神經網絡結構可以包括以下至少一種:循環神經網絡rnn、長短期記憶lstm、以及門控循環單元gru。
對于裝置實施例而言,由于其與方法實施例基本相似,所以描述的比較簡單,相關之處參見方法實施例的部分說明即可。
本說明書中的各個實施例均采用遞進的方式描述,每個實施例重點說明的都是與其他實施例的不同之處,各個實施例之間相同相似的部分互相參見即可。
關于上述實施例中的裝置,其中各個模塊執行操作的具體方式已經在有關該方法的實施例中進行了詳細描述,此處將不做詳細闡述說明。
本發明實施例還提供了一種標點添加裝置,包括有存儲器,以及一個或者一個以上的程序,其中一個或者一個以上程序存儲于存儲器中,且經配置以由一個或者一個以上處理器執行所述一個或者一個以上程序包含用于進行以下操作的指令:獲取待處理文本;通過神經網絡轉換模型為所述待處理文本添加標點,以得到所述待處理文本對應的標點添加結果;其中,所述神經網絡轉換模型為依據平行語料訓練得到,所述平行語料包括:源端語料和目標端語料,所述目標端語料為所述源端語料中各詞匯對應的標點。
可選地,所述通過神經網絡轉換模型為所述待處理文本添加標點,包括:
對所述待處理文本進行編碼,以得到所述待處理文本對應的源端隱層狀態;
依據神經網絡轉換模型的模型參數,對所述待處理文本對應的源端隱層狀態進行解碼,以得到所述待處理文本中各詞匯屬于候選標點的概率;
依據待處理文本中各詞匯屬于候選標點的概率,得到所述待處理文本對應的標點添加結果。
可選地,所述通過神經網絡轉換模型為所述待處理文本添加標點,還包括:
確定所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率;
則所述依據神經網絡轉換模型的模型參數,對所述待處理文本對應的源端隱層狀態進行解碼,包括:
依據所述對齊概率和所述待處理文本對應的源端隱層狀態,得到源端對應的上下文向量;
依據所述上下文向量,確定目標端隱層狀態;
依據所述隱層狀態和神經網絡轉換模型的模型參數,確定所述待處理文本中各詞匯屬于候選標點的概率。
可選地,所述確定所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率,包括:
依據神經網絡轉換模型的模型參數和目標端隱層狀態,得到所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率;或者
通過比較所述源端隱層狀態和目標端隱層狀態,得到所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率;或者
確定目標端位置對應的對齊源端位置,確定各目標端位置與其對應的對齊源端位置之間的對齊概率。
可選地,所述源端隱層狀態包括:前向的源端隱層狀態;或者,所述源端隱層狀態包括:前向的源端隱層狀態和后向的源端隱層狀態。
可選地,依據平行語料訓練得到神經網絡轉換模型,包括:
依據神經網絡結構,建立源端的詞匯到目標端的標點的神經網絡轉換模型;
利用神經網絡學習算法,對平行語料進行訓練,以得到所述神經網絡轉換模型的模型參數。
可選地,所述神經網絡結構包括以下至少一種:循環神經網絡rnn、長短期記憶lstm、以及門控循環單元gru。
圖4是根據一示例性實施例示出的一種用于標點添加的裝置作為終端時的框圖。例如,終端900可以是移動電話,計算機,數字廣播終端,消息收發設備,游戲控制臺,平板設備,醫療設備,健身設備,個人數字助理等。
參照圖4,終端900可以包括以下一個或多個組件:處理組件902,存儲器904,電源組件906,多媒體組件908,音頻組件910,輸入/輸出(i/o)的接口912,傳感器組件914,以及通信組件916。
處理組件902通常控制終端900的整體操作,諸如與顯示,電話呼叫,數據通信,相機操作和記錄操作相關聯的操作。處理元件902可以包括一個或多個處理器920來執行指令,以完成上述的方法的全部或部分步驟。此外,處理組件902可以包括一個或多個模塊,便于處理組件902和其他組件之間的交互。例如,處理組件902可以包括多媒體模塊,以方便多媒體組件908和處理組件902之間的交互。
存儲器904被配置為存儲各種類型的數據以支持在終端900的操作。這些數據的示例包括用于在終端900上操作的任何應用程序或方法的指令,聯系人數據,電話簿數據,消息,圖片,視頻等。存儲器904可以由任何類型的易失性或非易失性存儲設備或者它們的組合實現,如靜態隨機存取存儲器(sram),電可擦除可編程只讀存儲器(eeprom),可擦除可編程只讀存儲器(eprom),可編程只讀存儲器(prom),只讀存儲器(rom),磁存儲器,快閃存儲器,磁盤或光盤。
電源組件906為終端900的各種組件提供電力。電源組件906可以包括電源管理系統,一個或多個電源,及其他與為終端900生成、管理和分配電力相關聯的組件。
多媒體組件908包括在所述終端900和用戶之間的提供一個輸出接口的屏幕。在一些實施例中,屏幕可以包括液晶顯示器(lcd)和觸摸面板(tp)。如果屏幕包括觸摸面板,屏幕可以被實現為觸摸屏,以接收來自用戶的輸入信號。觸摸面板包括一個或多個觸摸傳感器以感測觸摸、滑動和觸摸面板上的手勢。所述觸摸傳感器可以不僅感測觸摸或滑動運動動作的邊界,而且還檢測與所述觸摸或滑動操作相關的持續時間和壓力。在一些實施例中,多媒體組件908包括一個前置攝像頭和/或后置攝像頭。當終端900處于操作模式,如拍攝模式或視頻模式時,前置攝像頭和/或后置攝像頭可以接收外部的多媒體數據。每個前置攝像頭和后置攝像頭可以是一個固定的光學透鏡系統或具有焦距和光學變焦能力。
音頻組件910被配置為輸出和/或輸入音頻信號。例如,音頻組件910包括一個麥克風(mic),當終端900處于操作模式,如呼叫模式、記錄模式和語音識別模式時,麥克風被配置為接收外部音頻信號。所接收的音頻信號可以被進一步存儲在存儲器904或經由通信組件916發送。在一些實施例中,音頻組件910還包括一個揚聲器,用于輸出音頻信號。
i/o接口912為處理組件902和外圍接口模塊之間提供接口,上述外圍接口模塊可以是鍵盤,點擊輪,按鈕等。這些按鈕可包括但不限于:主頁按鈕、音量按鈕、啟動按鈕和鎖定按鈕。
傳感器組件914包括一個或多個傳感器,用于為終端900提供各個方面的狀態評估。例如,傳感器組件914可以檢測到終端900的打開/關閉狀態,組件的相對定位,例如所述組件為終端900的顯示器和小鍵盤,傳感器組件914還可以檢測終端900或終端900一個組件的位置改變,用戶與終端900接觸的存在或不存在,終端900方位或加速/減速和終端900的溫度變化。傳感器組件914可以包括接近傳感器,被配置用來在沒有任何的物理接觸時檢測附近物體的存在。傳感器組件914還可以包括光傳感器,如cmos或ccd圖像傳感器,用于在成像應用中使用。在一些實施例中,該傳感器組件914還可以包括加速度傳感器,陀螺儀傳感器,磁傳感器,壓力傳感器或溫度傳感器。
通信組件916被配置為便于終端900和其他設備之間有線或無線方式的通信。終端900可以接入基于通信標準的無線網絡,如wifi,2g或3g,或它們的組合。在一個示例性實施例中,通信部件916經由廣播信道接收來自外部廣播管理系統的廣播信號或廣播相關信息。在一個示例性實施例中,所述通信部件916還包括近場通信(nfc)模塊,以促進短程通信。例如,在nfc模塊可基于射頻識別(rfid)技術,紅外數據協會(irda)技術,超寬帶(uwb)技術,藍牙(bt)技術和其他技術來實現。
在示例性實施例中,終端900可以被一個或多個應用專用集成電路(asic)、數字信號處理器(dsp)、數字信號處理設備(dspd)、可編程邏輯器件(pld)、現場可編程門陣列(fpga)、控制器、微控制器、微處理器或其他電子元件實現,用于執行上述方法。
在示例性實施例中,還提供了一種包括指令的非臨時性計算機可讀存儲介質,例如包括指令的存儲器904,上述指令可由終端900的處理器920執行以完成上述方法。例如,所述非臨時性計算機可讀存儲介質可以是rom、隨機存取存儲器(ram)、cd-rom、磁帶、軟盤和光數據存儲設備等。
圖5是根據一示例性實施例示出的一種用于標點添加的裝置作為服務器時的框圖。該服務器1900可因配置或性能不同而產生比較大的差異,可以包括一個或一個以上中央處理器(centralprocessingunits,cpu)1922(例如,一個或一個以上處理器)和存儲器1932,一個或一個以上存儲應用程序1942或數據1944的存儲介質1930(例如一個或一個以上海量存儲設備)。其中,存儲器1932和存儲介質1930可以是短暫存儲或持久存儲。存儲在存儲介質1930的程序可以包括一個或一個以上模塊(圖示沒標出),每個模塊可以包括對服務器中的一系列指令操作。更進一步地,中央處理器1922可以設置為與存儲介質1930通信,在服務器1900上執行存儲介質1930中的一系列指令操作。
服務器1900還可以包括一個或一個以上電源1926,一個或一個以上有線或無線網絡接口1950,一個或一個以上輸入輸出接口1958,一個或一個以上鍵盤1956,和/或,一個或一個以上操作系統1941,例如windowsservertm,macosxtm,unixtm,linuxtm,freebsdtm等等。
在示例性實施例中,還提供了一種包括指令的非臨時性計算機可讀存儲介質,例如包括指令的存儲器1932,上述指令可由服務器1900的處理器執行以完成上述方法。例如,所述非臨時性計算機可讀存儲介質可以是rom、隨機存取存儲器(ram)、cd-rom、磁帶、軟盤和光數據存儲設備等。
一種非臨時性計算機可讀存儲介質,當所述存儲介質中的指令由裝置(終端或者服務器)的處理器執行時,使得裝置能夠執行一種標點添加方法,所述方法包括:獲取待處理文本;通過神經網絡轉換模型為所述待處理文本添加標點,以得到所述待處理文本對應的標點添加結果;其中,所述神經網絡轉換模型為依據平行語料訓練得到,所述平行語料包括:源端語料和目標端語料,所述目標端語料為所述源端語料中各詞匯對應的標點。
可選地,所述通過神經網絡轉換模型為所述待處理文本添加標點,包括:
對所述待處理文本進行編碼,以得到所述待處理文本對應的源端隱層狀態;
依據神經網絡轉換模型的模型參數,對所述待處理文本對應的源端隱層狀態進行解碼,以得到所述待處理文本中各詞匯屬于候選標點的概率;
依據待處理文本中各詞匯屬于候選標點的概率,得到所述待處理文本對應的標點添加結果。
可選地,所述通過神經網絡轉換模型為所述待處理文本添加標點,還包括:
確定所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率;
則所述依據神經網絡轉換模型的模型參數,對所述待處理文本對應的源端隱層狀態進行解碼,包括:
依據所述對齊概率和所述待處理文本對應的源端隱層狀態,得到源端對應的上下文向量;
依據所述上下文向量,確定目標端隱層狀態;
依據所述隱層狀態和神經網絡轉換模型的模型參數,確定所述待處理文本中各詞匯屬于候選標點的概率。
可選地,所述確定所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率,包括:
依據神經網絡轉換模型的模型參數和目標端隱層狀態,得到所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率;或者
通過比較所述源端隱層狀態和目標端隱層狀態,得到所述待處理文本對應的源端位置與標點添加結果對應的目標端位置之間的對齊概率;或者
確定目標端位置對應的對齊源端位置,確定各目標端位置與其對應的對齊源端位置之間的對齊概率。
可選地,所述源端隱層狀態包括:前向的源端隱層狀態;或者,所述源端隱層狀態包括:前向的源端隱層狀態和后向的源端隱層狀態。
可選地,依據平行語料訓練得到神經網絡轉換模型,包括:
依據神經網絡結構,建立源端的詞匯到目標端的標點的神經網絡轉換模型;
利用神經網絡學習算法,對平行語料進行訓練,以得到所述神經網絡轉換模型的模型參數。
可選地,所述神經網絡結構包括以下至少一種:循環神經網絡rnn、長短期記憶lstm、以及門控循環單元gru。
本領域技術人員在考慮說明書及實踐這里公開的發明后,將容易想到本發明的其它實施方案。本發明旨在涵蓋本發明的任何變型、用途或者適應性變化,這些變型、用途或者適應性變化遵循本發明的一般性原理并包括本公開未公開的本技術領域中的公知常識或慣用技術手段。說明書和實施例僅被視為示例性的,本發明的真正范圍和精神由下面的權利要求指出。
應當理解的是,本發明并不局限于上面已經描述并在附圖中示出的精確結構,并且可以在不脫離其范圍進行各種修改和改變。本發明的范圍僅由所附的權利要求來限制
以上所述僅為本發明的較佳實施例,并不用以限制本發明,凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護范圍之內。
以上對本發明所提供的一種標點添加方法、一種標點添加裝置、以及一種用于標點添加的裝置,進行了詳細介紹,本文中應用了具體個例對本發明的原理及實施方式進行了闡述,以上實施例的說明只是用于幫助理解本發明的方法及其核心思想;同時,對于本領域的一般技術人員,依據本發明的思想,在具體實施方式及應用范圍上均會有改變之處,綜上所述,本說明書內容不應理解為對本發明的限制。
- 還沒有人留言評論。精彩留言會獲得點贊!