一種基于深度卷積生成對抗網絡的語音生成方法與流程
本發明屬于語音生成技術領域,尤其涉及一種基于深度卷積生成對抗網絡的語音生成方法。
背景技術:
人機交互技術的研究是計算機技術研究領域的重要組成部分。使智能設備具有“說話”的功能,這在真正的“面對面人機交流”中扮演著很重要的角色。借助于語音生成系統,智能設備已經可以清晰、自然地說話,普通用戶很容易聽懂并接受。語音模仿作為人機語音交流的重要環節,一方面,需要在前期建立大量的語音庫,另一方面,需要對大量語音信號的特征提取及訓練最終生成接近原始學習內容的自然語音信號。
生成式對抗網絡,是一種近年來大熱的深度學習模型,其主要就是可以用tensorflow作為學習框架,訓練一個生成器g,從隨機噪聲或者潛在變量中生成逼真的的樣本,同時訓練一個鑒別器d來鑒別真實數據和生成數據,兩者同時訓練,利用g和d構成動態“博弈過程”,直到達到一個納什均衡,生成器生成的數據與真實樣本無差別,鑒別器也無法正確的區分生成數據和真實數據。通過基于生成式對抗網絡形成的語音信號,從而可以克服目前智能設備在人機對話時只能根據固定的語音庫來發聲及模式單調缺乏變化,不夠自然等缺點。
技術實現要素:
本發明提出了一種基于深度卷積生成對抗網絡的語音生成方法,目的在于克服目前智能設備在人機對話時只能根據固定的語音庫來發聲及模式單調缺乏變化的不足。
本發明實現的具體步驟如下:
步驟1,采集語音信號樣本:隨機采集m個(m一般取1000)具有相同內容的語音信號,作為語音訓練樣本和真實語音樣本;
步驟2,語音信號的預處理:對步驟1中采集到的m個語音信號進行預處理;
步驟3,將語音數據樣本輸入深度卷積生成對抗網絡:將步驟2中預處理后的m個語音訓練樣本數據和m個真實語音樣本數據輸入到深度卷積生成對抗網絡;
步驟4,對輸入的語音數據進行訓練:采用深度卷積生成對抗網絡對輸入的m個語音訓練樣本數據和m個真實語音樣本數據進行訓練;
步驟5,生成接近真實語音內容的語音信號:利用深度卷積對抗生成網絡對自回歸生成模型得到的波形進行訓練,最終生成全新的且接近真實語音樣本的語音信號。
步驟1中所述隨機采集m個具有相同內容的語音信號,其存儲格式為wav格式。
步驟2包括如下步驟:
步驟2-1,對采集的語音信號樣本做除雜的處理;
步驟2-2,對采集的語音信號樣本進行濾波處理。
步驟2-1包括:利用audacity軟件對采集的語音信號樣本進行剪輯,過濾掉原始采集的波形中超出軟件編輯范圍的語音部分以及非語音信號的部分。
步驟2-2包括如下步驟:
步驟2-2-1,計算n時刻的誤差信號ε(n):
其中,d(n)表示n時刻主信道輸入的帶噪語音信號,即為自適應濾波器的期望信號,主信道表示語音輸入的通道,w(n)表示n時刻對應的權重系數矢量,x(n)表示在n時刻的語音矢量,h表示共軛轉置;
步驟2-2-2,計算在n時刻的相關系數γ(n):
步驟2-2-3,計算n時刻的語音差異矢量u(n):
u(n)=x(n)-γ(n)x(n-1);
步驟2-2-4,通過如下公式計算迭代后每個時刻對應的權重系數矢量:
其中,μ表示自適應常數,δ>0,δ表示實數;
步驟2-2-5,計算最小方差
其中,n0表示主信道輸入的語音信號,v表示主信道輸入的噪聲,y表示自適應濾波器的輸出,ε表示誤差信號,w表示某特定時刻自適應濾波器的權重矢量,使得方差
步驟2-2-6,將步驟2-2-4中得到的每個時刻的對應的權重系數矢量分別帶入步驟2-2-5的公式中,計算最小方差
步驟4包括如下步驟:
步驟4-1,深度卷積生成對抗網絡包括兩個網絡,一個是生成網絡g,用于接收一個隨機的噪聲;一個是判別網絡d,用于判別生成的數據是不是真實的;
步驟4-2,計算生成網絡的損失函數:
(1-b)log(1-d(g(z))),
其中,z表示生成網絡g接收的一個隨機的噪聲,b表示在真實語音樣本數據輸入參數c下得到的輸出參數,g(z)表示生成網絡g的輸出,log表示以10為底對的對數操作,d(g(z))表示判別網絡d判斷生成網絡g生成的語音數據為真實的概率;
步驟4-3,計算判別網絡的損失函數:
-((1-b)log(1-d(g(z)))+blogd(c)),
其中,c表示真實語音樣本數據作為輸入參數,d(c)表示判別網絡d的輸出,即輸入真實語音樣本數據參數c為真實的概率;
步驟4-4,計算優化函數minmaxv(d,g):
其中,pz(z)表示隨機噪聲的概率密度,x表示真實語音樣本數據,pdata(x)表示參數數據的概率密度;
步驟4-5,當判別網絡d無法判定生成網絡g所生成的語音數據是否真實時,d(g(z))=0.5,得到訓練好的語音信號數據,否則,執行步驟4-6;
步驟4-6,利用隨機梯度下降法計算判別網絡d的梯度函數和生成網絡g的梯度函數:
其中,θd表示在判別網絡d方向上的梯度變化量,θg表示在生成網絡g方向上的梯度變化量,i∈[1,m],m表示生成網絡g接收隨機噪聲的個數,∈表示屬于符號,將訓練好的判別網絡d和生成網絡g帶入步驟4-4中。
步驟5包括如下步驟:
步驟5-1,計算自回歸生成模型:
其中,h表示步驟4中得到訓練好的語音樣本數據作為輸入的參數,p(s|h)表示最有可行的波形輸出向量,s(t)表示在時間點t的輸出,t∈[1,t],t表示總時間,∈表示屬于符號;
步驟5-2,采用步驟4中深度卷積生成對抗網絡,對步驟5-1中生成波形進行學習,再經過自回歸生成模型不斷的反饋及輸出,使得每一步當前輸出的結果,只與之前的輸出結果相關,當滿足步驟4-5中d(g(z))=0.5時,最終生成全新的且接近真實語音樣本的語音信號。
有益效果:與現有技術相比本發明具有以下優點:
第一,本發明主要優勢在于智能設備不需要借助一個死板的語音庫來實現人機交流,而是可以通過機器訓練,讓智能設備可以自主生成全新的語音,從而使智能設備可以清晰、自然地說話,普通用戶也很容易聽懂并接受。
第二,本發明是基于深度卷積生成對抗網絡的語音生成技術,利用判別網絡和生成網絡所構成的動態“博弈過程”,最終得到語音訓練數據,再利用自回歸生成模型,將生成的語音波形轉化為音頻信號,從而生成接近真實語音內容的自然語音信號。本發明可用于根據樣本訓練后生成的語音完成人與智能設備之間的自然語音交流。
附圖說明
下面結合附圖和具體實施方式對本發明做更進一步的具體說明,本發明的上述或其他方面的優點將會變得更加清楚。
圖1是本發明流程圖。
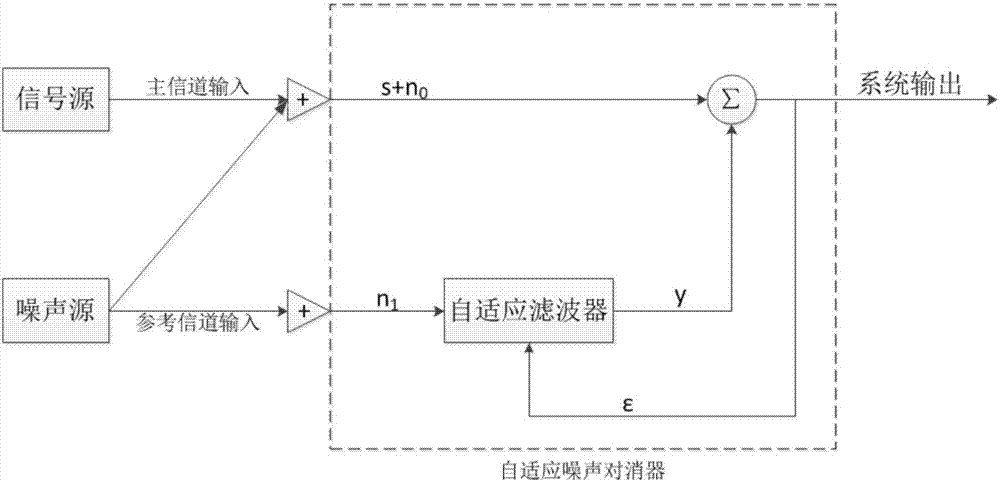
圖2是自適應噪聲濾波流程圖。
圖3是實施例生成(“你好”)語音波形圖
具體實施方式
下面結合附圖及實施例對本發明做進一步說明。
參照圖1,對本發明做進一步的詳細描述:
步驟1,語音信號樣本采集:
隨機采集m個具有相同內容的語音信號分別作為語音訓練樣本和真實語音樣本;
步驟2,語音信號的預處理:
(2a)將采集的語音信號做除雜的處理,保留完整的語音信號;
利用audacity軟件對語音信號進行剪輯,過濾掉原始采集的波形中超出軟件編輯范圍的語音部分以及非語音信號的部分;
(2b)對完整的語音信號進行濾波處理,組成語音訓練樣本庫和真實語音樣本庫,參照圖2,具體步驟如下:
第1步,計算n時刻的誤差信號ε(n):
其中,d(n)表示n時刻主信道輸入的帶噪語音信號,即為自適應濾波器的期望信號,主信道表示語音輸入的通道,
第2步,計算在n時刻的相關系數γ(n):
第3步,計算n時刻的語音差異矢量u(n):
u(n)=x(n)-γ(n)x(n-1);
第4步,計算迭代后每個時刻的w(n):
其中,μ表示自適應常數,δ>0,δ表示實數,w(n)表示權重系數矢量;
第5步,計算最小方差
其中,n0表示主信道輸入的語音信號,v表示主信道輸入的噪聲,y表示自適應濾波器的輸出,ε表示誤差信號,w表示某時刻自適應濾波器的權重矢量,使得方差e{ε2}最小;
第6步,將第4步中得到的每個時刻的w(n)分別帶入第5步中,計算最小方差
步驟3,將語音數據樣本輸入深度卷積生成對抗網絡;
將步驟2中預處理所得的m個語音訓練樣本數據和m個真實語音樣本數據輸入到深度卷積生成對抗網絡;
步驟4,對輸入的語音數據進行訓練;
采用深度卷積生成對抗網絡對輸入的m個語音訓練樣本數據和m個真實語音樣本數據進行訓練,具體步驟如下:
第1步,深度卷積生成對抗網絡包括兩個網絡,一個是生成網絡g,用于接收一個隨機的噪聲;一個是判別網絡d,用于判別生成的數據是不是真實的;
第2步,計算生成網絡的損失函數:
(1-b)log(1-d(g(z)))
其中,z表示生成網絡g接收的一個隨機的噪聲,b表示第3步中在真實語音樣本數據輸入參數c下得到的輸出參數,g(z)表示生成網絡g的輸出,log表示以10為底對的對數操作,d(g(z))表示判別網絡d判斷生成網絡g生成的語音數據為真實的概率;
第3步,計算判別網絡的損失函數:
-((1-b)log(1-d(g(z)))+blogd(c))
其中,c表示真實語音樣本數據作為輸入參數,d(c)表示判別網絡d的輸出,即輸入真實語音樣本數據參數c為真實的概率;
第4步,計算優化函數minmaxv(d,g):
其中,pz(z)表示隨機噪聲的概率密度,x表示真實語音樣本數據,pdata(x)表示參數數據的概率密度;
第5步,當判別網絡d無法判定生成網絡g所生成的語音數據是否真實時,d(g(z))=0.5,得到訓練好的語音數據,否則,執行第6步;
第6步,利用隨機梯度下降法計算d和g網絡的梯度函數:
其中,θd表示在判別網絡d方向上的梯度變化量,θg表示在生成網絡g方向上的梯度變化量,i∈[1,m],m表示生成網絡g接收隨機噪聲的個數,∈表示屬于符號,將訓練好的d和g帶入第4步中;
步驟5,生成接近真實語音內容的語音信號;
利用深度卷積對抗生成網絡對自回歸生成模型得到的波形進行訓練,最終生成全新的且接近真實語音樣本的語音信號,具體步驟如下:
第1步,計算自回歸生成模型:
其中,h表示步驟4第5步中得到訓練好的語音數據作為輸入的參數,p(x|h)表示最有可行的波形輸出向量,s(t)表示在時間點t的輸出,t∈[1,t],t表示總時間,∈表示屬于符號;
第2步,采用步驟4中深度卷積生成對抗網絡,對第一步中生成的波形進行學習,再經過自回歸生成模型不斷的反饋及輸出,使得每一步當前輸出的結果,只與之前的輸出結果相關,當滿足步驟4第5步中d(g(z))=0.5時,最終生成全新的且接近真實語音樣本的語音信號。
實施例
一種基于深度卷積生成對抗網絡的語音生成方法,其主要方法的流程圖如圖1所示,具體包括以下步驟:
(1)采集語音信號樣本:隨機采集1000個具有相同內容(“你好”)語音信號分別作為語音訓練樣本和真實語音樣本;
(2)語音信號的預處理:對步驟1中采集到的1000個(“你好”)語音信號進行預處理。首先,利用audacity軟件對1000個(“你好”)語音信號進行剪輯,過濾掉原始采集的波形中超出軟件編輯范圍的語音部分以及非語音信號的部分;其次,進行語音濾波處理:通過濾波算法計算n個時刻的誤差信號、相關系數、語音差異矢量,由迭代方法計算出每個時刻的權重系數矢量,通過自適應濾波器調整其下一時刻權重矢量求出最小方差,從而進行濾波處理,便可得到濾波后的語音信號;
(3)將語音數據樣本輸入深度卷積生成對抗網絡:將(2)中預處理都所得的1000個(“你好”)語音訓練樣本數據和真實語音樣本數據輸入到深度卷積生成對抗網絡;
(4)對輸入的語音數據進行訓練:采用深度卷積生成對抗網絡對輸入的1000個(“你好”)語音訓練樣本數據和真實語音樣本數據進行訓練,在該網絡下,分別計算生成網絡g和判別網絡d損失函數,再利用隨機梯度下降算法來訓練d和g,最終求得最優函數,得到訓練好的(“你好”)語音數據;
(5)生成接近真實語音內容的語音信號:將訓練好的(“你好”)語音數據帶入自回歸生成模型得到波形,再利用深度卷積對抗生成網絡對自回歸生成模型得到的波形進行訓練,得到訓練后的語音波形圖,如圖3所示,最終可生成全新的且接近真實(“你好”)語音樣本的語音信號。
本發明提供了一種基于深度卷積生成對抗網絡的語音生成方法,具體實現該技術方案的方法和途徑很多,以上所述僅是本發明的優選實施方式,應當指出,對于本技術領域的普通技術人員來說,在不脫離本發明原理的前提下,還可以做出若干改進和潤飾,這些改進和潤飾也應視為本發明的保護范圍。本實施例中未明確的各組成部分均可用現有技術加以實現。
- 還沒有人留言評論。精彩留言會獲得點贊!