最近鄰分類裝置及方法與流程
本發明涉及信息技術領域,尤其涉及一種最近鄰分類裝置及方法。
背景技術:
隨著信息技術的不斷發展,模式識別的應用日益普遍。而最近鄰分類是模式識別領域中被普遍使用的分類策略。單純的最近鄰分類指的是,對于需要分類的物體,根據一些距離規則來選擇K個最近鄰的訓練樣本,而該物體的類別被確定為該K個最近鄰的訓練樣本中最普遍的類別,當K為1時,該物體的類別則被確定為該單一的最近鄰樣本的類別。
單純的最近鄰分類策略的魯棒性較差且對噪聲較為敏感,為了解決該問題,目前進行了很多改進。例如,可采用加權最近鄰分類法,其中,根據各個最近鄰樣本的貢獻分配權重,距離測試樣本較近的貢獻較大。例如,一種普遍使用的加權最近鄰分類法采用1/d作為各個最近鄰樣本的權重,d為各個最近鄰樣本距離測試樣本的距離。
應該注意,上面對技術背景的介紹只是為了方便對本發明的技術方案進行清楚、完整的說明,并方便本領域技術人員的理解而闡述的。不能僅僅因為這些方案在本發明的背景技術部分進行了闡述而認為上述技術方案為本領域技術人員所公知。
技術實現要素:
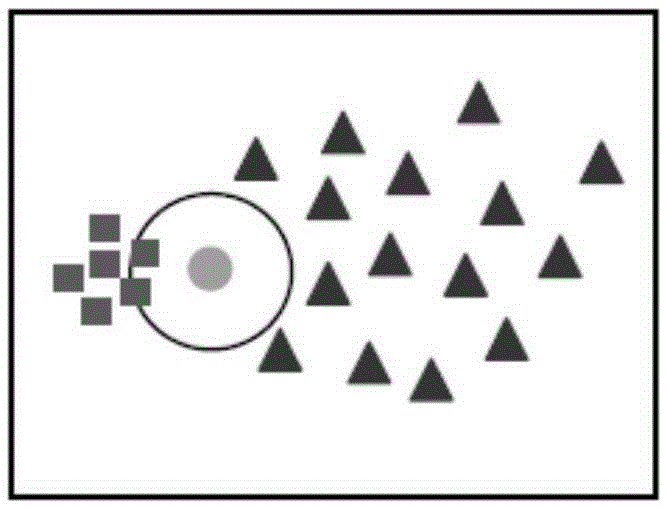
本發明的發明人發現,現有的加權最近鄰分類法的分類結果依賴于數據的局部結構,從而可能導致分類錯誤。圖1是一種示例的數據分布圖,如圖1所示,圓圈內的圓點表示測試樣本,當使用現有的加權最近鄰分類法時,由于采用1/d作為各個最近鄰的權重,該測試樣本被錯誤的劃分為正方形的類別。
另外,現有的最近鄰分類法依賴于最近鄰樣本的數量,即依賴于K值。圖2是另一種示例的數據分布圖,如圖2所示,圓點表示測試樣本,當K=3時,選取的最近鄰樣本為實線圓圈內的樣本,該測試樣本被劃分為三角形的類別,當K=5時,選 取的最近鄰樣本為虛線圓圈內的樣本,該測試樣本被劃分為正方形的類別,因此,K值的不同將導致分類結果的不同,使得分類結果不可靠。
本發明實施例提供一種最近鄰分類裝置及方法,由于在對測試樣本進行分類時,同時考慮了各個類別的權重和先驗概率這兩個因素,能夠有效提高分類結果的準確性,并具有較強的魯棒性。
根據本發明實施例的第一方面,提供一種最近鄰分類裝置,包括:獲取單元,所述獲取單元用于獲得測試樣本的K個最近鄰樣本,K為正整數;分組單元,所述分組單元用于根據所述K個最近鄰樣本的類別進行分組,其中,每個組對應于每個類別;第一計算單元,所述第一計算單元用于計算每個組的權重;第二計算單元,所述第二計算單元用于計算每個組的概率密度分布,并根據每個組的概率密度分布計算所述測試樣本對于每個組的先驗概率;第三計算單元,所述第三計算單元用于根據每個組的權重和所述測試樣本對于每個組的先驗概率,計算每個組對應的類別的得分;分類單元,所述分類單元用于將所有類別中得分最高的類別確定為所述測試樣本的類別。
根據本發明實施例的第二方面,提供一種最近鄰分類方法,包括:獲得測試樣本的K個最近鄰樣本,K為正整數;根據所述K個最近鄰樣本的類別進行分組,其中,每個組對應于每個類別;計算每個組的權重;計算每個組的概率密度分布,并根據每個組的概率密度分布計算所述測試樣本對于每個組的先驗概率;根據每個組的權重和所述測試樣本對于每個組的先驗概率,計算每個組對應的類別的得分;將所有類別中得分最高的類別確定為所述測試樣本的類別。
本發明的有益效果在于:由于在對測試樣本進行分類時,同時考慮了各個類別的權重和先驗概率這兩個因素,能夠有效提高分類結果的準確性,并具有較強的魯棒性。
參照后文的說明和附圖,詳細公開了本發明的特定實施方式,指明了本發明的原理可以被采用的方式。應該理解,本發明的實施方式在范圍上并不因而受到限制。在所附權利要求的精神和條款的范圍內,本發明的實施方式包括許多改變、修改和等同。
針對一種實施方式描述和/或示出的特征可以以相同或類似的方式在一個或更多個其它實施方式中使用,與其它實施方式中的特征相組合,或替代其它實施方式中的特征。
應該強調,術語“包括/包含”在本文使用時指特征、整件、步驟或組件的存在,但并不排除一個或更多個其它特征、整件、步驟或組件的存在或附加。
附圖說明
所包括的附圖用來提供對本發明實施例的進一步的理解,其構成了說明書的一部分,用于例示本發明的實施方式,并與文字描述一起來闡釋本發明的原理。顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動性的前提下,還可以根據這些附圖獲得其他的附圖。在附圖中:
圖1是一種示例的數據分布圖;
圖2是另一種示例的數據分布圖;
圖3是本發明實施例1的最近鄰分類裝置的組成示意圖;
圖4是本發明實施例1的第二計算單元304的組成示意圖;
圖5是本發明實施例2的電子設備的組成示意圖;
圖6是本發明實施例2的電子設備的系統構成的一示意框圖;
圖7是本發明實施例3的最近鄰分類方法流程圖;
圖8是本發明實施例4的最近鄰分類方法流程圖。
具體實施方式
參照附圖,通過下面的說明書,本發明的前述以及其它特征將變得明顯。在說明書和附圖中,具體公開了本發明的特定實施方式,其表明了其中可以采用本發明的原則的部分實施方式,應了解的是,本發明不限于所描述的實施方式,相反,本發明包括落入所附權利要求的范圍內的全部修改、變型以及等同物。
實施例1
圖3是本發明實施例1的最近鄰分類裝置的組成示意圖。如圖3所示,裝置300包括:
獲取單元301,用于獲得測試樣本的K個最近鄰樣本,K為正整數;
分組單元302,用于根據該K個最近鄰樣本的類別進行分組,其中,每個組對應于每個類別;
第一計算單元303,用于計算每個組的權重;
第二計算單元304,用于計算每個組的概率密度分布,并根據每個組的概率密度分布計算該測試樣本對于每個組的先驗概率;
第三計算單元305,用于根據每個組的權重和該測試樣本對于每個組的先驗概率,計算每個組對應的類別的得分;
分類單元306,用于將所有類別中得分最高的類別確定為該測試樣本的類別。
由上述實施例可知,由于在對測試樣本進行分類時,同時考慮了各個類別的權重和先驗概率這兩個因素,能夠有效提高分類結果的準確性,并具有較強的魯棒性。
在本實施例中,獲取單元301可采用現有方法獲得測試樣本的K個最近鄰樣本。例如,可以根據實際需要設定K的數值,從而獲得K個最近鄰樣本;也可以確定與測試樣本的距離,將該距離內的所有樣本作為測試樣本的最近鄰樣本。
在本實施例中,分組單元302根據該K個最近鄰樣本的類別進行分組,其中,每個組對應于每個類別。
例如,K個最近鄰樣本一共具有T個類別,表示為C={C1,C2,…,CT}。那么,可按照K個最近鄰樣本中各個樣本的類別將這些樣本分為T個組,同一類別的樣本被分在同一組,T個組分別表示為G1,G2,…,GT,各個組的樣本數量分別表示為M1,M2,…,MT。
在本實施例中,第一計算單元303可使用現有方法計算每個組的權重。例如,可使用以下的公式(1)計算每個組的權重:
Wi=Mi/K (1)
其中,Wi表示第i組的權重,Mi表示第i組的樣本數量,i=1,…,T,T表示K個最近鄰樣本的類別總數,也就是組的數量,T和i為正整數。
在本實施例中,第二計算單元304用于計算每個組的概率密度分布,并根據每個組的概率密度分布計算該測試樣本對于每個組的先驗概率,其中,可使用現有的方法計算概率密度分布和先驗概率。
以下對本實施例的第二計算單元304的結構以及計算概率密度分布和先驗概率的方法進行示例性的說明。
圖4是本發明實施例1的第二計算單元304的組成示意圖。如圖4所示,第二計算單元304包括:
第四計算單元401,用于使用高斯分布計算每個組的均值向量和協方差矩陣;
第五計算單元402,用于根據每個組的均值向量和協方差矩陣,計算該測試樣本對于每個組的先驗概率。
在本實施例中,第四計算單元401可使用高斯分布計算每個組的均值向量和協方差矩陣,例如,可使用以下的公式(2)和(3)計算每個組的均值向量和協方差矩陣:
其中,Meani表示第i組的均值向量,Mi表示第i組的樣本數量,xg_i表示屬于第i組的樣本,covi表示第i組的協方差矩陣,i=1,…,T,T表示組的數量,T和i為正整數。
第五計算單元402根據計算出的每個組的均值向量和協方差矩陣,計算該測試樣本對于每個組的先驗概率,例如,可使用以下的公式(4)計算該測試樣本對于每個組的先驗概率:
其中,Fi表示該測試樣本對于第i組的先驗概率,Meani表示第i組的均值向量,covi表示第i組的協方差矩陣,y表示該測試樣本的向量,d表示向量的維數,i=1,…,T,T表示組的數量,T和i為正整數。
在本實施例中,第三計算單元305用于根據每個組的權重和該測試樣本對于每個組的先驗概率,計算每個組對應的類別的得分。其中,可使用多種方法計算每個組對應的類別的得分,只要考慮了每個組的權重和該測試樣本對于每個組的先驗概率這兩個因素即可。
例如,將每個組的權重與所述測試樣本對于每個組的先驗概率的乘積、或者每個組的權重與所述測試樣本對于每個組的先驗概率之和、或者每個組的權重與所述測試樣本對于每個組的先驗概率的加權和,作為每個組對應的類別的得分。
例如,可根據以下的公式(5)計算每個組對應的類別的得分:
Zi=Wi*Fi (5)
其中,Zi表示第i組對應的類別的得分,Wi表示第i組的權重,Fi表示該測試樣本對于第i組的先驗概率,i=1,…,T,T表示組的數量,T和i為正整數。
例如,也可以根據以下的公式(6)計算每個組對應的類別的得分:
Zi=a*Wi+b*Fi (6)
其中,Zi表示第i組對應的類別的得分,Wi表示第i組的權重,Fi表示該測試樣本對于第i組的先驗概率,a表示權重的權重,b表示先驗概率的權重,a+b=1,i=1,…,T, T表示組的數量,T和i為正整數。
在本實施例中,在第三計算單元305計算出每個組對應的類別的得分后,分類單元306用于將所有類別中得分最高的類別確定為該測試樣本的類別。
在本實施例中,當分組單元302確定K個最近鄰樣本屬于同一個類別時,則第一計算單元303、第二計算單元304以及第三計算單元305不工作,分類單元306直接將該K個最近鄰樣本屬于的該類別確定為該測試樣本的類別。
在本實施例中,該裝置還可以包括:
設定單元307,用于設定K的取值,其中,當根據當前的K值計算出的所有類別的得分中的最高得分Z1與第二高得分Z2之比小于預定閾值t時,設定單元307將當前的K值加上預定的步長,該K值的初始值為預定范圍的最小值A;
此時,分類單元306用于當根據當前的K值計算出的所有類別的得分中的最高得分與第二高得分之比大于或等于該預定閾值t時,將所有類別中得分最高的類別確定為該測試樣本的類別。
在本實施例中,設定單元307為可選部件,在圖3中用虛線框表示。
這樣,根據最高得分與第二高得分之比自適應的設定K的取值,能夠使得分類結果更加可靠。
在本實施例中,該預定范圍的最小值A和最大值B以及該預定的步長Kstep可根據實際需要而設置。
例如,該預定范圍[A,B]的最小值A可以為樣本總量的十分之一,當樣本總量較小時,該預定范圍的最小值A可以為大于等于5的整數;該預定范圍的最大值B可以為樣本總量的五分之一;該預定的步長Kstep可以為2。
在本實施例中,該預定閾值t的數值可根據實際需要而設置,例如,該預定閾值t可以為1.1或1.2。
在本實施例中,分類單元306還用于在當前的K值大于或等于該預定范圍的最大值B、且當根據當前的K值計算出的所有類別的得分中的最高得分與第二高得分之比小于該預定閾值t的情況下,將該測試樣本的類別確定為:根據當前的K值以及之前的K值分別計算出的所有類別的得分中最高得分Z1與第二高得分Z2之比最大時具有該最高得分Z1的類別。也就是說,在上述情況下,根據當前的K值以及之前的各個K值分別計算出多個Z1/Z2,選取多個Z1/Z2中比值最大的Z1/Z2中具有最高得 分Z1的類別作為該測試樣本的類別。
例如,假設預定閾值t=1.1,預定范圍的最小值A=6,最大值B=10,當前的K值為K1=10,之前的K值包括K1和K2,K2=6,K3=8,其中,根據K1計算出的Z1/Z2=1.02,根據K2計算出的Z1/Z2=1.06,根據K3計算出的Z1/Z2=1.01,由于當前的K值已達到預定范圍的最大值B,并且根據K1、K2和K3計算出的Z1/Z2均小于預定閾值t,其中,根據K2計算出的Z1/Z2最大,那么將具有根據K2計算出的最高得分Z1的類別作為該測試樣本的類別。
這樣,即使在K值增加至達到或超過該預定范圍的最大值時仍然沒有滿足最高得分與第二高得分之比大于或等于該預定閾值的情況下,能夠在當前的K值以及之前的所有K值中選擇使得最高得分與第二高得分之比最大的K值,從而保證分類結果的可靠性。
由上述實施例可知,由于在對測試樣本進行分類時,同時考慮了各個類別的權重和先驗概率這兩個因素,能夠有效提高分類結果的準確性,并具有較強的魯棒性。
另外,根據最高得分與第二高得分之比自適應的設定K的取值,能夠使得分類結果更加可靠。
實施例2
本發明實施例還提供了一種電子設備,圖5是本發明實施例2的電子設備的組成示意圖。如圖5所示,電子設備500包括最近鄰分類裝置501,其中,最近鄰分類裝置501的結構和功能與實施例1中的記載相同,此處不再贅述。
圖6是本發明實施例2的電子設備的系統構成的一示意框圖。如圖6所示,電子設備600可以包括中央處理器601和存儲器602;存儲器602耦合到中央處理器601。該圖是示例性的;還可以使用其它類型的結構,來補充或代替該結構,以實現電信功能或其它功能。
如圖6所示,該電子設備600還可以包括:輸入單元603、顯示器604、電源605。
在一個實施方式中,實施例1所述的最近鄰分類裝置的功能可以被集成到中央處理器601中。其中,中央處理器601可以被配置為:獲得測試樣本的K個最近鄰樣本,K為正整數;根據所述K個最近鄰樣本的類別進行分組,其中,每個組對應于每個類別;計算每個組的權重;計算每個組的概率密度分布,并根據每個組的概率密度分布計算所述測試樣本對于每個組的先驗概率;根據每個組的權重和所述測試樣本 對于每個組的先驗概率,計算每個組對應的類別的得分;將所有類別中得分最高的類別確定為所述測試樣本的類別。
其中,所述計算每個組的概率密度分布,并根據每個組的概率密度分布計算所述測試樣本對于每個組的先驗概率,包括:使用高斯分布計算每個組的均值向量和協方差矩陣;根據每個組的均值向量和協方差矩陣,計算所述測試樣本對于每個組的先驗概率。
其中,中央處理器601還可以被配置為:設定K的取值,其中,當根據當前的K值計算出的所有類別的得分中的最高得分與第二高得分之比小于預定閾值時,所述設定單元將當前的K值加上預定的步長,所述K值的初始值為預定范圍的最小值;所述將所有類別中得分最高的類別確定為所述測試樣本的類別,包括:當根據當前的K值計算出的所有類別的得分中的最高得分與第二高得分之比大于或等于所述預定閾值時,將所有類別中得分最高的類別確定為所述測試樣本的類別。
其中,中央處理器601還可以被配置為:在當前的K值大于或等于所述預定范圍的最大值、且根據當前的K值計算出的所有類別的得分中的最高得分與第二高得分之比小于所述預定閾值的情況下,將所述測試樣本的類別確定為:根據當前的K值以及之前的K值分別計算出的所有類別的得分中最高得分與第二高得分之比最大時具有所述最高得分的類別。
其中,中央處理器601還可以被配置為:當所述K個最近鄰樣本屬于同一個類別時,將所述K個最近鄰樣本屬于的所述類別確定為所述測試樣本的類別。
其中,所述根據每個組的權重和所述測試樣本對于每個組的先驗概率,計算每個組對應的類別的得分,包括:將每個組的權重與所述測試樣本對于每個組的先驗概率的乘積、或者每個組的權重與所述測試樣本對于每個組的先驗概率之和、或者每個組的權重與所述測試樣本對于每個組的先驗概率的加權和,作為每個組對應的類別的得分。
在另一個實施方式中,實施例1所述的最近鄰分類裝置可以與中央處理器601分開配置,例如可以將最近鄰分類裝置配置為與中央處理器601連接的芯片,通過中央處理器601的控制來實現最近鄰分類裝置的功能。
在本實施例中電子設備600也并不是必須要包括圖6中所示的所有部件。
如圖6所示,中央處理器601有時也稱為控制器或操作控件,可以包括微處理器 或其它處理器裝置和/或邏輯裝置,中央處理器601接收輸入并控制電子設備600的各個部件的操作。
存儲器602,例如可以是緩存器、閃存、硬驅、可移動介質、易失性存儲器、非易失性存儲器或其它合適裝置中的一種或更多種。并且中央處理器601可執行該存儲器602存儲的該程序,以實現信息存儲或處理等。其它部件的功能與現有類似,此處不再贅述。電子設備600的各部件可以通過專用硬件、固件、軟件或其結合來實現,而不偏離本發明的范圍。
由上述實施例可知,由于在對測試樣本進行分類時,同時考慮了各個類別的權重和先驗概率這兩個因素,能夠有效提高分類結果的準確性,并具有較強的魯棒性。
另外,根據最高得分與第二高得分之比自適應的設定K的取值,能夠使得分類結果更加可靠。
實施例3
本發明實施例還提供一種最近鄰分類方法,其對應于實施例1的最近鄰分類裝置。圖7是本發明實施例3的最近鄰分類方法流程圖。如圖7所示,該方法包括:
步驟701:獲得測試樣本的K個最近鄰樣本,K為正整數;
步驟702:根據該K個最近鄰樣本的類別進行分組,其中,每個組對應于每個類別;
步驟703:計算每個組的權重;
步驟704:計算每個組的概率密度分布,并根據每個組的概率密度分布計算該測試樣本對于每個組的先驗概率;
步驟705:根據每個組的權重和該測試樣本對于每個組的先驗概率,計算每個組對應的類別的得分;
步驟706:將所有類別中得分最高的類別確定為該測試樣本的類別。
在本實施例中,獲得K個最近鄰樣本的方法、對K個最近鄰樣本進行分組的方法、計算每個組的權重、概率密度分布以及該測試樣本對于每個組的先驗概率的方法、計算每個組對應的類別的得分的方法與實施例1中的記載相同,此處不再贅述。
由上述實施例可知,由于在對測試樣本進行分類時,同時考慮了各個類別的權重和先驗概率這兩個因素,能夠有效提高分類結果的準確性,并具有較強的魯棒性。
另外,根據最高得分與第二高得分之比自適應的設定K的取值,能夠使得分類 結果更加可靠。
實施例4
本發明實施例還提供一種最近鄰分類方法,其對應于實施例1的最近鄰分類裝置。圖8是本發明實施例4的最近鄰分類方法流程圖。如圖8所示,該方法包括:
步驟801:將K值的初始值設為預定范圍[A,B]的最小值A,K為正整數;
步驟802:獲得測試樣本的K個最近鄰樣本;
步驟803:根據該K個最近鄰樣本的類別進行分組,其中,每個組對應于每個類別;
步驟804:計算每個組的權重;
步驟805:計算每個組的概率密度分布,并根據每個組的概率密度分布計算該測試樣本對于每個組的先驗概率;
步驟806:根據每個組的權重和該測試樣本對于每個組的先驗概率,計算每個組對應的類別的得分;
步驟807:判斷所有類別的得分中的最高得分Z1與第二高得分Z2之比是否大于或等于預定閾值t,當判斷結果為“否”時,進入步驟808,當判斷結果為“是”時,進入步驟811;
步驟808:判斷當前的K值是否小于該預定范圍[A,B]的最大值B,當判斷結果為“是”時,進入步驟809,當判斷結果為“否”時,進入步驟810;
步驟809:將當前的K值加上預定的步長Kstep;
步驟810:將該測試樣本的類別確定為:根據當前的K值以及之前的K值分別計算出的所有類別的得分中最高得分Z1與第二高得分Z2之比最大時具有該最高得分Z1的類別;
步驟811:將所有類別中得分最高的類別確定為該測試樣本的類別。
在本實施例中,獲得K個最近鄰樣本的方法、對K個最近鄰樣本進行分組的方法、計算每個組的權重、概率密度分布以及該測試樣本對于每個組的先驗概率的方法、計算每個組對應的類別的得分的方法與實施例1中的記載相同,此處不再贅述。
由上述實施例可知,由于在對測試樣本進行分類時,同時考慮了各個類別的權重和先驗概率這兩個因素,能夠有效提高分類結果的準確性,并具有較強的魯棒性。
另外,根據最高得分與第二高得分之比自適應的設定K的取值,能夠使得分類 結果更加可靠。
本發明實施例還提供一種計算機可讀程序,其中當在最近鄰分類裝置或電子設備中執行所述程序時,所述程序使得計算機在所述最近鄰分類裝置或電子設備中執行實施例3或實施例4所述的最近鄰分類方法。
本發明實施例還提供一種存儲有計算機可讀程序的存儲介質,其中所述計算機可讀程序使得計算機在最近鄰分類裝置或電子設備中執行實施例3或實施例4所述的最近鄰分類方法。
本發明以上的裝置和方法可以由硬件實現,也可以由硬件結合軟件實現。本發明涉及這樣的計算機可讀程序,當該程序被邏輯部件所執行時,能夠使該邏輯部件實現上文所述的裝置或構成部件,或使該邏輯部件實現上文所述的各種方法或步驟。本發明還涉及用于存儲以上程序的存儲介質,如硬盤、磁盤、光盤、DVD、flash存儲器等。
以上結合具體的實施方式對本發明進行了描述,但本領域技術人員應該清楚,這些描述都是示例性的,并不是對本發明保護范圍的限制。本領域技術人員可以根據本發明的精神和原理對本發明做出各種變型和修改,這些變型和修改也在本發明的范圍內。
關于包括以上實施例的實施方式,還公開下述的附記:
附記1、一種最近鄰分類裝置,包括:
獲取單元,所述獲取單元用于獲得測試樣本的K個最近鄰樣本,K為正整數;
分組單元,所述分組單元用于根據所述K個最近鄰樣本的類別進行分組,其中,每個組對應于每個類別;
第一計算單元,所述第一計算單元用于計算每個組的權重;
第二計算單元,所述第二計算單元用于計算每個組的概率密度分布,并根據每個組的概率密度分布計算所述測試樣本對于每個組的先驗概率;
第三計算單元,所述第三計算單元用于根據每個組的權重和所述測試樣本對于每個組的先驗概率,計算每個組對應的類別的得分;
分類單元,所述分類單元用于將所有類別中得分最高的類別確定為所述測試樣本的類別。
附記2、根據附記1所述的裝置,其中,所述第二計算單元包括:
第四計算單元,所述第四計算單元用于使用高斯分布計算每個組的均值向量和協方差矩陣;
第五計算單元,所述第五計算單元用于根據每個組的均值向量和協方差矩陣,計算所述測試樣本對于每個組的先驗概率。
附記3、根據附記1所述的裝置,其中,所述裝置還包括:
設定單元,所述設定單元用于設定K的取值,其中,當根據當前的K值計算出的所有類別的得分中的最高得分與第二高得分之比小于預定閾值時,所述設定單元將當前的K值加上預定的步長,所述K值的初始值為預定范圍的最小值;
所述分類單元用于當根據當前的K值計算出的所有類別的得分中的最高得分與第二高得分之比大于或等于所述預定閾值時,將所有類別中得分最高的類別確定為所述測試樣本的類別。
附記4、根據附記3所述的裝置,其中,
所述分類單元還用于在當前的K值大于或等于所述預定范圍的最大值、且當根據當前的K值計算出的所有類別的得分中的最高得分與第二高得分之比小于所述預定閾值的情況下,將所述測試樣本的類別確定為:根據當前的K值以及之前的K值分別計算出的所有類別的得分中最高得分與第二高得分之比最大時具有所述最高得分的類別。
附記5、根據附記1所述的裝置,其中,
所述分類單元還用于當所述分組單元確定所述K個最近鄰樣本屬于同一個類別時,將所述K個最近鄰樣本屬于的所述類別確定為所述測試樣本的類別。
附記6、根據附記1所述的裝置,其中,
所述第三計算單元用于將每個組的權重與所述測試樣本對于每個組的先驗概率的乘積、或者每個組的權重與所述測試樣本對于每個組的先驗概率之和、或者每個組的權重與所述測試樣本對于每個組的先驗概率的加權和,作為每個組對應的類別的得分。
附記7、一種最近鄰分類方法,包括:
獲得測試樣本的K個最近鄰樣本,K為正整數;
根據所述K個最近鄰樣本的類別進行分組,其中,每個組對應于每個類別;
計算每個組的權重;
計算每個組的概率密度分布,并根據每個組的概率密度分布計算所述測試樣本對于每個組的先驗概率;
根據每個組的權重和所述測試樣本對于每個組的先驗概率,計算每個組對應的類別的得分;
將所有類別中得分最高的類別確定為所述測試樣本的類別。
附記8、根據附記7所述的方法,其中,所述計算每個組的概率密度分布,并根據每個組的概率密度分布計算所述測試樣本對于每個組的先驗概率,包括:
使用高斯分布計算每個組的均值向量和協方差矩陣;
根據每個組的均值向量和協方差矩陣,計算所述測試樣本對于每個組的先驗概率。
附記9、根據附記7所述的方法,其中,所述方法還包括:
設定K的取值,其中,當根據當前的K值計算出的所有類別的得分中的最高得分與第二高得分之比小于預定閾值時,所述設定單元將當前的K值加上預定的步長,所述K值的初始值為預定范圍的最小值;
所述將所有類別中得分最高的類別確定為所述測試樣本的類別,包括:當根據當前的K值計算出的所有類別的得分中的最高得分與第二高得分之比大于或等于所述預定閾值時,將所有類別中得分最高的類別確定為所述測試樣本的類別。
附記10、根據附記9所述的方法,其中,所述方法還包括:
在當前的K值大于或等于所述預定范圍的最大值、且根據當前的K值計算出的所有類別的得分中的最高得分與第二高得分之比小于所述預定閾值的情況下,將所述測試樣本的類別確定為:根據當前的K值以及之前的K值分別計算出的所有類別的得分中最高得分與第二高得分之比最大時具有所述最高得分的類別。
附記11、根據附記7所述的方法,其中,所述方法還包括:
當所述K個最近鄰樣本屬于同一個類別時,將所述K個最近鄰樣本屬于的所述類別確定為所述測試樣本的類別。
附記12、根據附記7所述的方法,其中,
所述根據每個組的權重和所述測試樣本對于每個組的先驗概率,計算每個組對應的類別的得分,包括:將每個組的權重與所述測試樣本對于每個組的先驗概率的乘積、或者每個組的權重與所述測試樣本對于每個組的先驗概率之和、或者每個組的權重與所述測試樣本對于每個組的先驗概率的加權和,作為每個組對應的類別的得分。
- 還沒有人留言評論。精彩留言會獲得點贊!