異常交易數(shù)據(jù)的獲取方法和裝置與流程
本申請(qǐng)涉及互聯(lián)網(wǎng)技術(shù)領(lǐng)域,特別涉及一種異常交易數(shù)據(jù)的獲取方法和裝置。
背景技術(shù):
隨著互聯(lián)網(wǎng)的飛速發(fā)展,電子商務(wù)在整個(gè)商業(yè)領(lǐng)域的地位越來越重要。互聯(lián)網(wǎng)交易中虛假交易也越來越多,且升級(jí)為多個(gè)用戶團(tuán)伙作弊的特征等更加隱蔽的模式,這對(duì)整個(gè)電子商務(wù)平臺(tái)產(chǎn)生了嚴(yán)重的負(fù)面影響。現(xiàn)有的異常交易的識(shí)別技術(shù)已較難適應(yīng)如今變化多端的團(tuán)伙作弊模式。目前可通過以下方法發(fā)現(xiàn)異常交易方法:
1)收集大量異常交易數(shù)據(jù)作為識(shí)別正樣本;
2)結(jié)合業(yè)務(wù)知識(shí)設(shè)計(jì)相關(guān)識(shí)別特征;
3)通過人工數(shù)據(jù)分析或機(jī)器學(xué)習(xí)分類算法挖掘相關(guān)模式與規(guī)則;
4)根據(jù)挖掘的模式規(guī)則,從原始交易數(shù)據(jù)中發(fā)現(xiàn)異常交易。
但是,上述方法需要人工判別數(shù)據(jù),消耗的人力資源很多,尤其是在大數(shù)據(jù)背景下此問題尤為嚴(yán)重。其次,該方法需要結(jié)合大量的業(yè)務(wù)背景知識(shí),針對(duì)不同業(yè)務(wù)場(chǎng)景設(shè)計(jì)不同的算法,得到的模型缺少可解釋性。另外,對(duì)于團(tuán)伙作弊的異常交易,由于其隱蔽性較高,因此基于交易表面特征的方法已經(jīng)較難適應(yīng),召回率遠(yuǎn)不能滿足現(xiàn)有業(yè)務(wù)場(chǎng)景的需求。
技術(shù)實(shí)現(xiàn)要素:
本申請(qǐng)旨在至少在一定程度上解決上述技術(shù)問題。
為此,本申請(qǐng)的第一個(gè)目的在于提出一種異常交易數(shù)據(jù)的獲取方法,能夠有效識(shí)別團(tuán)伙作弊交易模式的異常交易,提高異常交易的召回率。
本申請(qǐng)的第二個(gè)目的在于提出一種異常交易數(shù)據(jù)的獲取裝置。
為達(dá)上述目的,根據(jù)本申請(qǐng)第一方面實(shí)施例提出了一種異常交易數(shù)據(jù)的獲取方法,包括以下步驟:獲取目標(biāo)產(chǎn)品的用戶交易數(shù)據(jù),其中,所述用戶交易數(shù)據(jù)包括用戶信息和交易編號(hào);根據(jù)所述用戶信息對(duì)用戶進(jìn)行群組劃分,為每一群組對(duì)應(yīng)生成群組標(biāo)簽;根據(jù)各群組標(biāo)簽對(duì)應(yīng)的用戶交易數(shù)據(jù)獲取所述目標(biāo)產(chǎn)品的用戶分布信息;根據(jù)所述用戶分布信息計(jì)算用戶分布的信息熵,判斷所述用戶分布信息是否符合預(yù)設(shè)分布;如果所述用戶分布信息不符合所述預(yù)設(shè)分布,則根據(jù)各群組標(biāo)簽對(duì)應(yīng)的交易數(shù)據(jù)的數(shù)量篩選出一個(gè)或多個(gè)群組;以所述篩選出的群組及其交易數(shù)據(jù)作為異常交易群組及其異常交易數(shù)據(jù)。
本申請(qǐng)實(shí)施例的異常交易數(shù)據(jù)的獲取方法,可根據(jù)交易數(shù)據(jù)中的用戶信息生成群組標(biāo)簽,并根據(jù)群組標(biāo)簽對(duì)用戶進(jìn)行群組劃分,并根據(jù)各群組對(duì)應(yīng)的用戶交易數(shù)據(jù)獲取目標(biāo)產(chǎn)品的用戶分布信息,并在用戶分布信息不符合預(yù)設(shè)分布時(shí),根據(jù)各群組標(biāo)簽對(duì)應(yīng)的交易數(shù)據(jù)的數(shù)量篩選出異常交易數(shù)據(jù)對(duì)應(yīng),能夠有效識(shí)別團(tuán)伙作弊交易模式的異常交易,提高異常交易的召回率。
本申請(qǐng)第二方面實(shí)施例提供了一種異常交易數(shù)據(jù)的獲取裝置,包括:第一獲取模塊,用于獲取目標(biāo)產(chǎn)品的用戶交易數(shù)據(jù),其中,所述用戶交易數(shù)據(jù)包括用戶信息和交易編號(hào);生成模塊,用于根據(jù)所述用戶信息對(duì)用戶進(jìn)行群組劃分,為每一群組對(duì)應(yīng)生成群組標(biāo)簽;第二獲取模塊,用于根據(jù)各群組標(biāo)簽對(duì)應(yīng)的用戶交易數(shù)據(jù)獲取所述目標(biāo)產(chǎn)品的用戶分布信息;判斷模塊,用于根據(jù)所述用戶分布信息計(jì)算用戶分布的信息熵,判斷所述用戶分布信息是否符合預(yù)設(shè)分布;篩選模塊,用于當(dāng)所述用戶分布信息不符合所述預(yù)設(shè)分布時(shí),根據(jù)各群組標(biāo)簽對(duì)應(yīng)的交易數(shù)據(jù)的數(shù)量篩選出一個(gè)或多個(gè)群組,并以所述篩選出的群組及其交易數(shù)據(jù)作為異常交易群組及其異常交易數(shù)據(jù)。
本申請(qǐng)實(shí)施例的異常交易數(shù)據(jù)的獲取裝置,可根據(jù)交易數(shù)據(jù)中的用戶信息生成群組標(biāo)簽,并根據(jù)群組標(biāo)簽對(duì)用戶進(jìn)行群組劃分,并根據(jù)各群組對(duì)應(yīng)的用戶交易數(shù)據(jù)獲取目標(biāo)產(chǎn)品的用戶分布信息,并在用戶分布信息不符合預(yù)設(shè)分布時(shí),根據(jù)各群組標(biāo)簽對(duì)應(yīng)的交易數(shù)據(jù)的數(shù)量篩選出異常交易數(shù)據(jù)對(duì)應(yīng),能夠有效識(shí)別團(tuán)伙作弊交易模式的異常交易,提高異常交易的召回率。
本申請(qǐng)的附加方面和優(yōu)點(diǎn)將在下面的描述中部分給出,部分將從下面的描述中變得明顯,或通過本申請(qǐng)的實(shí)踐了解到。
附圖說明
本申請(qǐng)的上述和/或附加的方面和優(yōu)點(diǎn)從結(jié)合下面附圖對(duì)實(shí)施例的描述中將變得明顯和容易理解,其中:
圖1為根據(jù)本申請(qǐng)一個(gè)實(shí)施例的異常交易數(shù)據(jù)的獲取方法的流程圖;
圖2為根據(jù)本申請(qǐng)圖1所示實(shí)施例中s104的流程圖;
圖3為根據(jù)本申請(qǐng)一個(gè)實(shí)施例的根據(jù)用戶分布信息計(jì)算用戶分布的信息熵的方法流程圖;
圖4為根據(jù)本申請(qǐng)一個(gè)實(shí)施例的擬合預(yù)估函數(shù)的流程圖;
圖5為根據(jù)本申請(qǐng)另一個(gè)實(shí)施例的異常交易數(shù)據(jù)的獲取方法的流程圖;
圖6為根據(jù)本申請(qǐng)一個(gè)實(shí)施例的異常交易數(shù)據(jù)的獲取架構(gòu)圖;
圖7為根據(jù)本申請(qǐng)一個(gè)實(shí)施例的異常交易數(shù)據(jù)的獲取裝置的結(jié)構(gòu)示意圖;
圖8為根據(jù)本申請(qǐng)另一個(gè)實(shí)施例的異常交易數(shù)據(jù)的獲取裝置的結(jié)構(gòu)示意圖。
具體實(shí)施方式
下面詳細(xì)描述本申請(qǐng)的實(shí)施例,所述實(shí)施例的示例在附圖中示出,其中自始至終相同或類似的標(biāo)號(hào)表示相同或類似的元件或具有相同或類似功能的元件。下面通過參考附圖描述的實(shí)施例是示例性的,僅用于解釋本申請(qǐng),而不能理解為對(duì)本申請(qǐng)的限制。
下面參考附圖描述根據(jù)本申請(qǐng)實(shí)施例的異常交易數(shù)據(jù)的獲取方法和裝置。
圖1為根據(jù)本申請(qǐng)一個(gè)實(shí)施例的異常交易數(shù)據(jù)的獲取方法的流程圖。
如圖1所示,根據(jù)本申請(qǐng)實(shí)施例的異常交易數(shù)據(jù)的獲取方法,包括以下步驟。
s101,獲取目標(biāo)產(chǎn)品的用戶交易數(shù)據(jù),其中,用戶交易數(shù)據(jù)包括用戶信息和交易編號(hào)。
其中,用戶交易數(shù)據(jù)可為用戶在互聯(lián)網(wǎng)購(gòu)物平臺(tái)上的交易。例如,可以是購(gòu)物交易等。用戶信息可包括買家的賬戶、姓名、收貨地址、聯(lián)系方式、社交關(guān)系、用戶的硬件信息、ip(internetprotocol,網(wǎng)絡(luò)之間互連的協(xié)議)地址等。交易編號(hào)可為交易訂單號(hào)等。舉例來說,用戶交易數(shù)據(jù)的數(shù)據(jù)格式可為:{交易id,產(chǎn)品id}。
s102,根據(jù)用戶信息對(duì)用戶進(jìn)行群組劃分,為每一群組對(duì)應(yīng)生成群組標(biāo)簽。
其中,一個(gè)群組標(biāo)簽唯一標(biāo)識(shí)一個(gè)用戶群組。在本申請(qǐng)的一個(gè)實(shí)施例中,可針對(duì)目標(biāo)產(chǎn)品收集大量用戶交易數(shù)據(jù),并根據(jù)用戶交易數(shù)據(jù)中的用戶信息生成群組標(biāo)簽。添加群組標(biāo)簽后用戶交易數(shù)據(jù)的數(shù)據(jù)格式可為:{交易id,產(chǎn)品id,群組標(biāo)簽(grouptag)}。
在本申請(qǐng)的一個(gè)實(shí)施例中,可根據(jù)用戶信息計(jì)算用戶組群關(guān)系特征,并將用戶組群關(guān)系特征作為群組標(biāo)簽。例如,可基于lpa(labelpropagationalgorithm,標(biāo)簽傳播算法)、fnca(fastnetworkclusteringalgorithm,快速社區(qū)挖掘算法)等社區(qū)發(fā)現(xiàn)算法從用戶信息中生成群組標(biāo)簽。舉例來說,通過社區(qū)發(fā)現(xiàn)算法挖掘出兩個(gè)交易數(shù)據(jù)a和b中的用戶為同一用戶或者為屬于同一社交圈m的用戶,則可為交易數(shù)據(jù)a和b生成群組標(biāo)簽“m”。
在本申請(qǐng)的另一個(gè)實(shí)施例中,如果用戶信息為用戶的硬件信息,則可根據(jù)用戶的硬件信息生成群組標(biāo)簽。舉例來說,如果兩個(gè)交易數(shù)據(jù)c和d中用戶的設(shè)備標(biāo)識(shí)都是“n”,則可為交易數(shù)據(jù)c和d生成群組標(biāo)簽“n”。
或者,可將用戶的ip地址等信息直接作為群組標(biāo)簽。
因此,可以看出,一個(gè)交易數(shù)據(jù)可具有一個(gè)或多個(gè)群組標(biāo)簽,一個(gè)群組標(biāo)簽中也可標(biāo)記一個(gè)或多個(gè)交易數(shù)據(jù)中的用戶群組信息。
需要說明的是,由于一個(gè)買家可以屬于多個(gè)用戶群組,因此同一買家可以以多個(gè)用戶群組的身份完成針對(duì)同一產(chǎn)品的交易,由于無法獲知買家是以哪一個(gè)群組(一個(gè)用戶群組對(duì)應(yīng)一個(gè)群組標(biāo)簽)的身份參加的交易活動(dòng),因此同一個(gè)交易id可以帶有多個(gè)群組標(biāo)簽,即交易數(shù)據(jù)中存在交易id相同,但是群組標(biāo)簽不同的數(shù)據(jù)。
s103,根據(jù)各群組標(biāo)簽對(duì)應(yīng)的用戶交易數(shù)據(jù)獲取目標(biāo)產(chǎn)品的用戶分布信息。
其中,用戶分布信息為用戶對(duì)應(yīng)的交易數(shù)據(jù)基于各個(gè)群組標(biāo)簽的分布情況。本申請(qǐng)的實(shí)施例中,可根據(jù)交易數(shù)據(jù)中各個(gè)群組標(biāo)簽中的數(shù)量以及交易編號(hào)與用戶信息的對(duì)應(yīng)關(guān)系確定用戶分布在各個(gè)群組中的數(shù)量,即用戶分布信息。
s104,根據(jù)用戶分布信息計(jì)算用戶分布的信息熵,判斷所述用戶分布信息是否符合預(yù)設(shè)分布。
在本申請(qǐng)的一個(gè)實(shí)施例中,可通過目標(biāo)產(chǎn)品對(duì)應(yīng)的用戶分布的信息熵來判斷用戶分布信息是否符合預(yù)設(shè)分布。用戶分布的信息熵越大,則表示目標(biāo)產(chǎn)品的用戶越近似隨機(jī)分布,用戶分布的信息熵越小,則表示目標(biāo)產(chǎn)品的用戶存在個(gè)別群組聚集的情況。
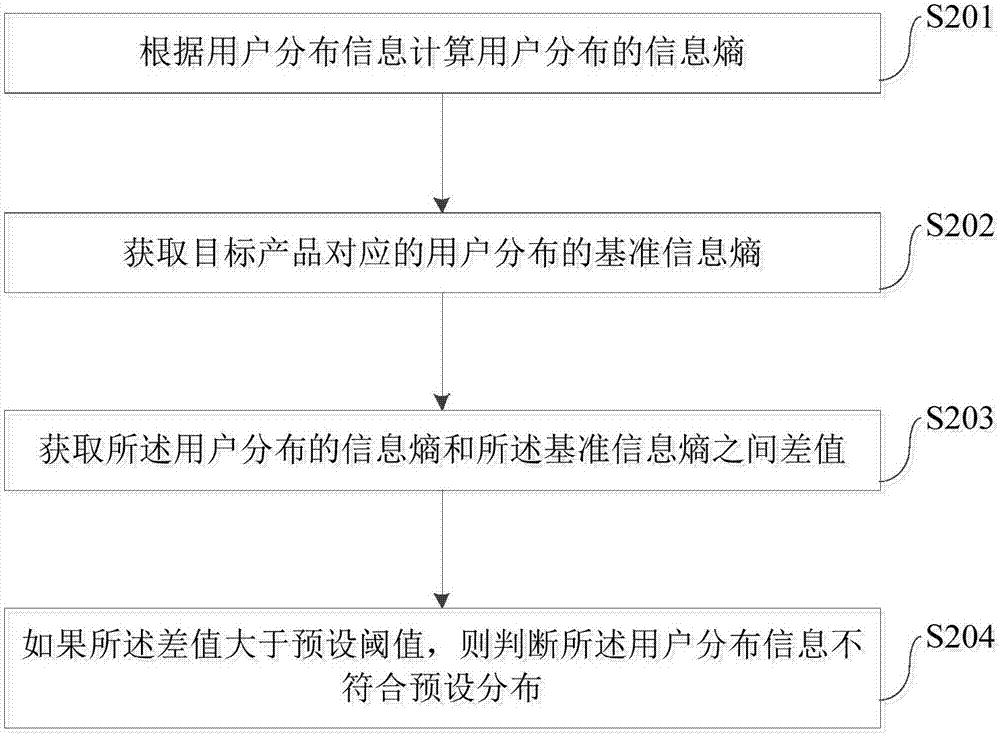
具體地,在本申請(qǐng)的一個(gè)實(shí)施例中,s104可具體包括步驟s201-s204。
s201,根據(jù)用戶分布信息計(jì)算用戶分布的信息熵。
考慮到現(xiàn)實(shí)數(shù)據(jù)中,同一個(gè)用戶在不同的時(shí)間窗口內(nèi)可以屬于不同的用戶群組,交易數(shù)據(jù)中存在交易粒度的重復(fù)數(shù)據(jù)。因此在本申請(qǐng)的一個(gè)實(shí)施例中,可采用基于最大化用戶群體的二次哈希方法,削弱多標(biāo)簽數(shù)據(jù)在計(jì)算用戶分布的信息熵的過程中引入的噪音,從而強(qiáng)化隱性團(tuán)體的用戶聚集度,使用戶分布接近真實(shí)分布,并且適合多標(biāo)簽這類復(fù)雜識(shí)別模式。圖3為根據(jù)本申請(qǐng)一個(gè)實(shí)施例的根據(jù)用戶分布信息計(jì)算用戶分布的信息熵的流程圖。
如圖3所示,根據(jù)用戶分布信息計(jì)算用戶分布的信息熵,包括以下步驟。
s301,以群組標(biāo)簽為主鍵、交易編號(hào)為值對(duì)用戶交易數(shù)據(jù)進(jìn)行整理,以生成第一交易列表。
其中,群組標(biāo)簽用grouptag表示,交易編號(hào)用biz表示。
具體地,以grouptag為主鍵對(duì)所有用戶交易數(shù)據(jù)進(jìn)行哈希map存儲(chǔ),生成第一交易列表,其中,第一交易列表中的主鍵為grouptag,值為與grouptag對(duì)應(yīng)的交易編號(hào)biz列表。舉例來說,第一交易列表的存儲(chǔ)格式可為:
其中,該哈希map的主鍵grouptagi表示目標(biāo)產(chǎn)品的第i組買家對(duì)應(yīng)的群組標(biāo)簽,bizi,j表示第i組買家購(gòu)買的第j筆交易的交易編號(hào),其中,i=1,...,m1,j=1,...,mi,m1表示第一交易列表中群組標(biāo)簽grouptag的總數(shù),mi表示第i組群組標(biāo)簽對(duì)應(yīng)的交易編號(hào)列表大小。
也就是說,第一交易列表中包括m1個(gè)群組標(biāo)簽,其中,第i個(gè)群組標(biāo)簽對(duì)應(yīng)有mi個(gè)交易編號(hào)。
s302,以交易編號(hào)為主鍵、群組標(biāo)簽為值對(duì)用戶交易數(shù)據(jù)進(jìn)行整理,以生成第二交易列表。
具體地,與步驟s301類似,以biz為主鍵對(duì)所有用戶交易數(shù)據(jù)進(jìn)行哈希map存儲(chǔ)生成第二交易列表。其中,第二交易列表的主鍵為biz,值為與biz對(duì)應(yīng)的群組標(biāo)簽grouptag列表。舉例來說,第二交易列表的存儲(chǔ)格式可為:
其中,該哈希map的主鍵bizp表示目標(biāo)產(chǎn)品的第p筆交易的交易編號(hào),bizp,q表示第p筆交易的第q個(gè)群組標(biāo)簽,q=1,...,np,np表第p筆交易具有的群組標(biāo)簽的總數(shù)。
s303,根據(jù)預(yù)設(shè)條件對(duì)第二交易列表中每個(gè)交易編號(hào)對(duì)應(yīng)的群組標(biāo)簽進(jìn)行壓縮,以使第二交易列表中每個(gè)交易編號(hào)具有唯一對(duì)應(yīng)的群組標(biāo)簽。
具體地,可對(duì)bizmap進(jìn)行壓縮,即取交易編號(hào)bizp對(duì)應(yīng)的最大組群(具有最大交易量的標(biāo)簽)作為交易編號(hào)bizp所屬的組群,具體可通過以下公式進(jìn)行篩選:
其中,
舉例來說,交易編號(hào)bizp屬于3個(gè)組群,即具有3個(gè)群組標(biāo)簽,分別為1、2、3,其中,根據(jù)第一交易列表知道群組標(biāo)簽1、2、3分別對(duì)應(yīng)5個(gè)、10個(gè)、6個(gè)交易編號(hào)。則可將群組標(biāo)簽2作為bizp唯一對(duì)應(yīng)的群組標(biāo)簽。
由于同一個(gè)用戶可以存在于多個(gè)群組,因此交易數(shù)據(jù)中存在具有多標(biāo)簽的交易數(shù)據(jù),即同一個(gè)biz可以屬于不同的grouptagi。為此,本申請(qǐng)的實(shí)施例中采用最大化群組的思想,即將該biz歸屬于目標(biāo)產(chǎn)品的最大群組的方法來弱化同一個(gè)買家屬于不同群組在計(jì)算產(chǎn)品特征熵過程中帶來的噪音。由此,能夠提高群組的聚集性,最大化異常群體。
s304,以群組標(biāo)簽為主鍵、交易編號(hào)為值對(duì)壓縮后的第二交易列表進(jìn)行整理,以生成第三交易列表。
也就是說,將壓縮后的第二交易列表bizmapmax中的數(shù)據(jù)以群組標(biāo)簽為主鍵、交易編號(hào)為值進(jìn)行哈希map存儲(chǔ),得到第三交易列表grouptagmapmax,其存儲(chǔ)格式可為:
其中,該哈希map的主鍵grouptagi表示目標(biāo)產(chǎn)品的第i組買家對(duì)應(yīng)的群組標(biāo)簽,bizi,j表示第i組買家購(gòu)買的第j筆交易的交易編號(hào),其中,i=1,...,m2,j=1,...,li,m2表示第三交易列表中群組標(biāo)簽grouptag的總數(shù),li表示第i組群組標(biāo)簽對(duì)應(yīng)的交易編號(hào)列表大小。
由于壓縮后的第二交易列表bizmapmax中,每個(gè)交易編號(hào)具有唯一對(duì)應(yīng)的群組標(biāo)簽,也就是說,在對(duì)第二交易列表進(jìn)行壓縮的過程中,刪除了一部分群組標(biāo)簽與交易編號(hào)的對(duì)應(yīng)關(guān)系。因此,當(dāng)以群組標(biāo)簽為主鍵、交易編號(hào)為值對(duì)壓縮后的第二交易列表bizmapmax進(jìn)行整理之后,得到的第三交易列表相對(duì)于第一交易列表來說,群組標(biāo)簽與交易編號(hào)的對(duì)應(yīng)關(guān)系也相應(yīng)減少,且部分群組標(biāo)簽對(duì)應(yīng)的交易編號(hào)的數(shù)量也相應(yīng)減少。也就是說,上述m2≤m1,且li與mi也不一定相等。
s305,獲取各群組標(biāo)簽在所述第三交易列表中的出現(xiàn)概率,并根據(jù)各出現(xiàn)概率計(jì)算所述用戶分布的信息熵。
具體地,可基于grouptagmapmax中的grouptag數(shù)據(jù)按照如下公式計(jì)算用戶分布的信息熵:
其中,entropy(grouptag)為所述用戶分布的信息熵,p(grouptagj)為j第組群組標(biāo)簽在第三交易列表中的出現(xiàn)頻率,j=1,...,m2,m2為第三交易列表中所包括的群組標(biāo)簽的總數(shù)。
舉例來說,如果grouptagmapmax中的數(shù)據(jù)為:
{a:1,2,3,4},{b:5,6},也就是說,grouptagmapmax包括a和b兩個(gè)群組標(biāo)簽,則群組標(biāo)簽a的出現(xiàn)頻率為p(a)=4/6,群組標(biāo)簽b標(biāo)簽的出現(xiàn)頻率為p(b)=2/6。
應(yīng)當(dāng)理解,上述示例是將交易數(shù)據(jù)為粒度進(jìn)行群組標(biāo)簽劃分,在本申請(qǐng)的其他實(shí)施例中,也可以用戶為粒度進(jìn)行劃分,即每個(gè)買家的多筆交易僅算一筆交易的方式進(jìn)行劃分,來計(jì)算產(chǎn)品特征熵,效果類似。
s202,獲取目標(biāo)產(chǎn)品對(duì)應(yīng)的用戶分布的基準(zhǔn)信息熵。
在現(xiàn)實(shí)的電子商務(wù)場(chǎng)景下,一般情況下商品的交易過程中買家應(yīng)該具有近似隨機(jī)的群組分布,然而在團(tuán)伙刷單等異常交易場(chǎng)景中買家的分布在個(gè)別特征中體現(xiàn)出聚集性。用戶分布的信息熵,作為一種衡量用戶分布信息混亂程度的指標(biāo),能夠恰如其分的刻畫這種場(chǎng)景。當(dāng)商品交易過程中買家用戶近似隨機(jī)分布時(shí),用戶分布的信息熵具有最大值,而當(dāng)存在個(gè)別的團(tuán)體聚集時(shí),上述用戶分布的信息熵的值將大幅度的減小。
因此,在本申請(qǐng)的實(shí)施例中,可將買家用戶隨機(jī)分布時(shí)的用戶分布的信息熵作為用戶分布的基準(zhǔn)信息熵,并通過實(shí)際交易過程中實(shí)際的用戶分布的信息熵與該基準(zhǔn)信息熵進(jìn)行比對(duì)來判斷是否存在個(gè)別的團(tuán)體聚集的情況。如果存在,則可判斷出現(xiàn)了異常交易。
那么,首先需要獲取目標(biāo)產(chǎn)品的用戶分布的基準(zhǔn)信息熵。在本申請(qǐng)的一個(gè)實(shí)施例中,獲取目標(biāo)產(chǎn)品對(duì)應(yīng)的用戶分布的基準(zhǔn)信息熵可具體包括:獲取目標(biāo)產(chǎn)品對(duì)應(yīng)的產(chǎn)品交易量,根據(jù)預(yù)先擬合的預(yù)估函數(shù)和產(chǎn)品交易量生成目標(biāo)產(chǎn)品對(duì)應(yīng)的用戶分布的基準(zhǔn)信息熵。其中,預(yù)估函數(shù)為表示產(chǎn)品交易量與用戶分布的基準(zhǔn)信息熵函數(shù)關(guān)系的曲線。因此,可將目標(biāo)產(chǎn)品的產(chǎn)品交易量帶入預(yù)估函數(shù),得到目標(biāo)產(chǎn)品對(duì)應(yīng)的用戶分布的基準(zhǔn)信息熵。
圖4為根據(jù)本申請(qǐng)一個(gè)實(shí)施例的擬合預(yù)估函數(shù)的流程圖。
如圖4所示,根據(jù)本申請(qǐng)一個(gè)實(shí)施例,可通過以下步驟擬合預(yù)估函數(shù)。
s401,獲取目標(biāo)產(chǎn)品的樣本交易數(shù)據(jù)。
具體地,可在用戶交易數(shù)據(jù)中大規(guī)模采樣得到各個(gè)產(chǎn)品的樣本交易數(shù)據(jù),其中,樣本交易數(shù)據(jù)中包括交易編號(hào)、用戶信息以及產(chǎn)品標(biāo)識(shí)。
s402,根據(jù)交易數(shù)據(jù)樣本分別獲取目標(biāo)產(chǎn)品在多個(gè)交易量下對(duì)應(yīng)的用戶分布的信息熵。
具體地,可根據(jù)產(chǎn)品標(biāo)識(shí)對(duì)樣本交易數(shù)據(jù)進(jìn)行劃分。從而,可得到不同產(chǎn)品對(duì)應(yīng)的樣本交易數(shù)據(jù)。對(duì)于每個(gè)產(chǎn)品,可提取出不同數(shù)量的交易數(shù)據(jù),即得到多個(gè)不同交易量的交易數(shù)據(jù),并計(jì)算與各個(gè)交易量相應(yīng)的用戶分布的信息熵。由此,可得到不同交易量下的用戶分布的信息熵。不同交易量下的用戶分布的信息熵的計(jì)算方法可參見圖1所示實(shí)施例。交易量值可用d表示,用戶分布的信息熵可用ef表示。
在樣本中正常交易占絕大多數(shù)的假設(shè)下,可通過統(tǒng)計(jì)方法計(jì)算出各產(chǎn)品在不同交易量下的用戶分布的信息熵,并分別作為不同交易量下的用戶分布的基準(zhǔn)信息熵。
舉例來說,通過統(tǒng)計(jì)學(xué)方法,假設(shè)選取了n個(gè)不同的交易量進(jìn)行統(tǒng)計(jì)分析,交易量d下的產(chǎn)品分布服從高斯分布n(μd,δd),取(d,max(0,μd-λδd))點(diǎn)為交易量d下的用戶分布的信息熵的邊界點(diǎn),并作為交易量d下的用戶分布的基準(zhǔn)信息熵,其中λ∈(0,3)為衡量偏離度的參數(shù)。經(jīng)過統(tǒng)計(jì)學(xué)計(jì)算后得到產(chǎn)品交易量與用戶分布的基準(zhǔn)信息熵的樣本:
di=1:n:{xi=d,yi=max(0,μd-λδd)},其中,n為選取的不同交易量的個(gè)數(shù)。
s403,構(gòu)建基準(zhǔn)信息熵?cái)M合函數(shù)。
其中,基準(zhǔn)信息熵?cái)M合函數(shù)可為
s404,根據(jù)多個(gè)交易量和多個(gè)交易量分別對(duì)應(yīng)的用戶分布的信息熵對(duì)基準(zhǔn)信息熵?cái)M合函數(shù)進(jìn)行參數(shù)估計(jì),以得到預(yù)估函數(shù)。
舉例來說,為提高模型的泛化能力,可采用如下所示參數(shù)估計(jì)的方法:
首先,根據(jù)基準(zhǔn)信息熵?cái)M合函數(shù)的參數(shù)向量構(gòu)建如下?lián)p失函數(shù):
然后,根據(jù)多個(gè)交易量和多個(gè)交易量分別對(duì)應(yīng)的用戶分布的信息熵對(duì)上述損失函數(shù)進(jìn)行優(yōu)化,得到基準(zhǔn)信息熵?cái)M合函數(shù)的參數(shù)向量,由此得到參數(shù)確定的基準(zhǔn)信息熵?cái)M合函數(shù),即預(yù)估函數(shù)。具體地,可基于損失函數(shù)采用各類成熟的優(yōu)化算法(例如,擬牛頓、梯度下降、隨機(jī)搜索算法等)進(jìn)行優(yōu)化求解,得到預(yù)估函數(shù)。
需要解釋的是,上述統(tǒng)計(jì)學(xué)方法僅為示例性的,不應(yīng)理解為對(duì)本申請(qǐng)的限制。計(jì)算用戶分布的基準(zhǔn)信息熵的方法可以用任何其他有效的統(tǒng)計(jì)學(xué)分析方法代替,并且上述各交易量下產(chǎn)品的分布可以采用如學(xué)生分布等其他各類適合具體業(yè)務(wù)的分布代替。上述參數(shù)估計(jì)方法也可用目前或未來可實(shí)現(xiàn)的任何有效的參數(shù)估計(jì)算法代替。
s203,獲取所述用戶分布的信息熵和所述基準(zhǔn)信息熵之間差值。
s204,如果所述差值大于預(yù)設(shè)閾值,則判斷所述用戶分布信息不符合預(yù)設(shè)分布。
s105,如果所述用戶分布信息不符合預(yù)設(shè)分布,則根據(jù)各群組標(biāo)簽對(duì)應(yīng)的交易數(shù)據(jù)的數(shù)量篩選出一個(gè)或多個(gè)群組。
s106,以所述篩選出的群組及其交易數(shù)據(jù)作為異常交易群組及其異常交易數(shù)據(jù)。
在當(dāng)前用戶交易數(shù)據(jù)中異常交易數(shù)據(jù)和正常交易數(shù)據(jù)混雜的情況下,影響用戶分布信息熵的往往是具有最大規(guī)模的群組,其在產(chǎn)品買家用戶分布中呈現(xiàn)峰值狀態(tài),即用戶在某一群組中具有高聚集度的特點(diǎn)。因此,在本申請(qǐng)的一個(gè)實(shí)施例中,可篩選出交易數(shù)據(jù)的數(shù)量最大的一個(gè)或多個(gè)群組,并以交易數(shù)據(jù)的數(shù)量最大的群組作為異常交易群組,以異常交易群組的交易數(shù)據(jù)作為異常交易數(shù)據(jù)。
其中,可根據(jù)上述第三交易列表
由此,可通過實(shí)際交易過程中的目標(biāo)產(chǎn)品的用戶分布的信息熵與相應(yīng)的基準(zhǔn)信息熵進(jìn)行比對(duì)來判斷是否存在異常交易數(shù)據(jù),并進(jìn)行提取,可解釋性強(qiáng),能夠有效識(shí)別團(tuán)伙作弊交易模式(如團(tuán)伙刷單等)的異常交易,提高異常交易的召回率。
本申請(qǐng)實(shí)施例的異常交易數(shù)據(jù)的獲取方法,可根據(jù)交易數(shù)據(jù)中的用戶信息生成群組標(biāo)簽,并根據(jù)群組標(biāo)簽對(duì)用戶進(jìn)行群組劃分,并根據(jù)各群組對(duì)應(yīng)的用戶交易數(shù)據(jù)獲取目標(biāo)產(chǎn)品的用戶分布信息,并在用戶分布信息不符合預(yù)設(shè)分布時(shí),根據(jù)各群組標(biāo)簽對(duì)應(yīng)的交易數(shù)據(jù)的數(shù)量篩選出異常交易數(shù)據(jù)對(duì)應(yīng),能夠有效識(shí)別團(tuán)伙作弊交易模式(如團(tuán)伙刷單等)的異常交易,提高異常交易的召回率。
圖5為根據(jù)本申請(qǐng)另一個(gè)實(shí)施例的異常交易數(shù)據(jù)的獲取方法的流程圖。
如圖5所示,根據(jù)本申請(qǐng)實(shí)施例的異常交易數(shù)據(jù)的獲取方法,包括步驟s501-s506。其中,s501-s506與圖1所示實(shí)施例中s101-s106相同。進(jìn)一步地,還可包括以下步驟。
s507,將異常交易數(shù)據(jù)從交易數(shù)據(jù)中刪除,并更新產(chǎn)品交易量。
s508,根據(jù)更新后的產(chǎn)品交易量更新相應(yīng)的基準(zhǔn)信息熵。
從而,可根據(jù)刪除異常交易數(shù)據(jù)后的交易量對(duì)應(yīng)的用戶分布的信息熵與更新后的交易量對(duì)應(yīng)的基準(zhǔn)信息熵進(jìn)行比對(duì),以判斷是否存在異常數(shù)據(jù)。如果存在,則繼續(xù)刪除,并再次判斷。
圖6為根據(jù)本申請(qǐng)一個(gè)實(shí)施例的異常交易數(shù)據(jù)的獲取架構(gòu)圖。如圖6所示,可將用戶交易數(shù)據(jù)輸入群組標(biāo)簽挖掘模塊,得到帶群組標(biāo)簽的交易數(shù)據(jù),并根據(jù)交易數(shù)據(jù)或者用戶等粒度進(jìn)行商品粒度匯總,得到商品交易數(shù)據(jù)。由商品特征熵計(jì)算模塊根據(jù)商品交易數(shù)據(jù)計(jì)算目標(biāo)產(chǎn)品的用戶分布的信息熵。另外,基準(zhǔn)熵預(yù)測(cè)模塊根據(jù)基準(zhǔn)熵?cái)M合模塊擬合出的預(yù)估函數(shù)預(yù)測(cè)目標(biāo)產(chǎn)品的基準(zhǔn)信息熵。通過異常特征熵判別模塊將目標(biāo)產(chǎn)品的用戶分布的信息熵與基準(zhǔn)信息熵進(jìn)行比對(duì)以判斷目標(biāo)產(chǎn)品的用戶分布的信息熵是否異常,如果異常,則通過異常交易剔除模塊刪除異常交易數(shù)據(jù),并輸出異常交易數(shù)據(jù),同時(shí)更新剩余交易量(也可稱為剩余銷量),以便于商品特征熵計(jì)算模塊繼續(xù)根據(jù)更新后的交易量重新計(jì)算更新交易量后的用戶分布的信息熵,并繼續(xù)判斷。
可以看出,可根據(jù)上述方法從用戶交易數(shù)據(jù)中獲取異常交易數(shù)據(jù),并刪除異常交易數(shù)據(jù)的過程可以是一個(gè)迭代過程,即刪除之后,再次判斷是否存在異常交易數(shù)據(jù),如果存在則繼續(xù)刪除,并再次判斷。直至用戶交易數(shù)據(jù)中不再有異常交易數(shù)據(jù),或者用戶交易數(shù)據(jù)中包括的交易量小于預(yù)設(shè)的交易量閾值。具體迭代過程,可如下:
1)令i=1,
2)基于特征熵計(jì)算模塊計(jì)算目標(biāo)產(chǎn)品當(dāng)前的用戶分布的信息熵ef,i,并將商品的交易量di作為輸入預(yù)估函數(shù)
3)若ed>ε且di>δ則基于grouptagmapmaxi剔除具有最大biz列表的grouptag數(shù)據(jù)(用grouptagk表示),即按如下方式更新:
其中,ε為控制目標(biāo)產(chǎn)品的用戶分布的信息熵與基準(zhǔn)信息熵差值的預(yù)設(shè)閾值,δ為控制交易量(間接反映團(tuán)伙規(guī)模)大小的參數(shù),lj為該grouptagk對(duì)應(yīng)的交易量。
4)更新剩余交易量di+1=di-lk,轉(zhuǎn)2);否則算法終止。其中,lk為刪除的異常交易數(shù)據(jù)對(duì)應(yīng)的交易量。
5)輸出3)、4)過程中刪除的grouptag對(duì)應(yīng)的全部交易作數(shù)據(jù)為異常交易數(shù)據(jù)。
本申請(qǐng)實(shí)施例的異常交易數(shù)據(jù)的獲取方法,通過不斷剔除目標(biāo)產(chǎn)品的用戶交易數(shù)據(jù)中最大規(guī)模的具有團(tuán)伙特征的交易數(shù)據(jù)(異常交易數(shù)據(jù))的貪心算法,不斷剔除與輸出異常交易數(shù)據(jù),商品異常交易數(shù)據(jù)與正常交易數(shù)據(jù)的區(qū)分更加準(zhǔn)確,能夠挖掘具有高聚集度的團(tuán)伙用戶以及其對(duì)應(yīng)的異常交易數(shù)據(jù)。
與上述實(shí)施例提供的異常交易數(shù)據(jù)的獲取方法相對(duì)應(yīng),本申請(qǐng)還提出一種異常交易數(shù)據(jù)的獲取裝置。
圖7為根據(jù)本申請(qǐng)一個(gè)實(shí)施例的異常交易數(shù)據(jù)的獲取裝置的結(jié)構(gòu)示意圖。
如圖7所示,根據(jù)本申請(qǐng)實(shí)施例的異常交易數(shù)據(jù)的獲取裝置,包括:第一獲取模塊10、生成模塊20、第二獲取模塊30、判斷模塊40和篩選模塊50。
具體地,第一獲取模塊10用于獲取目標(biāo)產(chǎn)品的用戶交易數(shù)據(jù),其中,用戶交易數(shù)據(jù)包括用戶信息和交易編號(hào)。
其中,用戶交易數(shù)據(jù)可為用戶在互聯(lián)網(wǎng)購(gòu)物平臺(tái)上的交易。例如,可以是購(gòu)物交易等。用戶信息可包括買家的賬戶、姓名、收貨地址、聯(lián)系方式、社交關(guān)系、用戶的硬件信息、ip(internetprotocol,網(wǎng)絡(luò)之間互連的協(xié)議)地址等。交易編號(hào)可為交易訂單號(hào)等。舉例來說,用戶交易數(shù)據(jù)的數(shù)據(jù)格式可為:{交易id,產(chǎn)品id}。
生成模塊20用于根據(jù)所述用戶信息對(duì)用戶進(jìn)行群組劃分,為每一群組對(duì)應(yīng)生成群組標(biāo)簽。
其中,一個(gè)群組標(biāo)簽唯一標(biāo)識(shí)一個(gè)用戶群組。在本申請(qǐng)的一個(gè)實(shí)施例中,可針對(duì)目標(biāo)產(chǎn)品收集大量用戶交易數(shù)據(jù),并根據(jù)用戶交易數(shù)據(jù)中的用戶信息生成群組標(biāo)簽。添加群組標(biāo)簽后用戶交易數(shù)據(jù)的數(shù)據(jù)格式可為:{交易id,產(chǎn)品id,群組標(biāo)簽(grouptag)}。
在本申請(qǐng)的一個(gè)實(shí)施例中,生成模塊20可用于:可根據(jù)用戶信息計(jì)算用戶組群關(guān)系特征,并將用戶組群關(guān)系特征作為群組標(biāo)簽。例如,可基于lpa(labelpropagationalgorithm,標(biāo)簽傳播算法)、fnca(fastnetworkclusteringalgorithm,快速社區(qū)挖掘算法)等社區(qū)發(fā)現(xiàn)算法從用戶信息中生成群組標(biāo)簽。舉例來說,通過社區(qū)發(fā)現(xiàn)算法挖掘出兩個(gè)交易數(shù)據(jù)a和b中的用戶為同一用戶或者為屬于同一社交圈m的用戶,則可為交易數(shù)據(jù)a和b生成群組標(biāo)簽“m”。
在本申請(qǐng)的另一個(gè)實(shí)施例中,如果用戶信息為用戶的硬件信息,生成模塊20可用于根據(jù)用戶的硬件信息生成群組標(biāo)簽。舉例來說,如果兩個(gè)交易數(shù)據(jù)c和d中用戶的設(shè)備標(biāo)識(shí)都是“n”,則可為交易數(shù)據(jù)c和d生成群組標(biāo)簽“n”。
或者,生成模塊20可將用戶的ip地址等信息直接作為用戶標(biāo)簽。
第二獲取模塊30用于根據(jù)各群組標(biāo)簽對(duì)應(yīng)的交易數(shù)據(jù)獲取目標(biāo)產(chǎn)品的用戶分布信息。
其中,用戶分布信息為用戶對(duì)應(yīng)的交易數(shù)據(jù)基于各個(gè)群組標(biāo)簽的分布情況。本申請(qǐng)的實(shí)施例中,第二獲取模塊30可根據(jù)交易數(shù)據(jù)中各個(gè)群組標(biāo)簽中的數(shù)量以及交易編號(hào)與用戶信息的對(duì)應(yīng)關(guān)系確定用戶分布在各個(gè)群組中的數(shù)量,即用戶分布信息。
判斷模塊40用于根據(jù)用戶分布信息計(jì)算用戶分布的信息熵,判斷所述用戶分布信息是否符合預(yù)設(shè)分布。
在本申請(qǐng)的一個(gè)實(shí)施例中,判斷模塊40可通過目標(biāo)產(chǎn)品對(duì)應(yīng)的用戶分布的信息熵來判斷用戶分布信息是否符合預(yù)設(shè)分布。用戶分布的信息熵越大,則表示目標(biāo)產(chǎn)品的用戶越近似隨機(jī)分布,用戶分布的信息熵越小,則表示目標(biāo)產(chǎn)品的用戶存在個(gè)別群組聚集的情況。
具體地,在本申請(qǐng)的一個(gè)實(shí)施例中,判斷模塊40可包括:計(jì)算單元41、第一獲取單元42、第二獲取單元43和判斷單元44。
其中,計(jì)算單元41用于根據(jù)所述用戶分布信息計(jì)算用戶分布的信息熵。
考慮到現(xiàn)實(shí)數(shù)據(jù)中,同一個(gè)用戶在不同的時(shí)間窗口內(nèi)可以屬于不同的用戶群組,交易數(shù)據(jù)中存在交易粒度的重復(fù)數(shù)據(jù)。因此在本申請(qǐng)的一個(gè)實(shí)施例中,可采用基于最大化用戶群體的二次哈希方法,削弱多標(biāo)簽數(shù)據(jù)在計(jì)算用戶分布的信息熵的過程中引入的噪音,從而強(qiáng)化隱性團(tuán)體的用戶聚集度,使用戶分布接近真實(shí)分布,并且適合多標(biāo)簽這類復(fù)雜識(shí)別模式。
計(jì)算單元41用于執(zhí)行圖3所示的步驟以根據(jù)用戶分布信息計(jì)算用戶分布的信息熵。
第一獲取單元42用于獲取所述目標(biāo)產(chǎn)品對(duì)應(yīng)的用戶分布的基準(zhǔn)信息熵。
在現(xiàn)實(shí)的電子商務(wù)場(chǎng)景下,一般情況下商品的交易過程中買家應(yīng)該具有近似隨機(jī)的群組分布,然而在團(tuán)伙刷單等異常交易場(chǎng)景中買家的分布在個(gè)別特征中體現(xiàn)出聚集性。用戶分布的信息熵,作為一種衡量用戶分布信息混亂程度的指標(biāo),能夠恰如其分的刻畫這種場(chǎng)景。當(dāng)商品交易過程中買家用戶近似隨機(jī)分布時(shí),用戶分布的信息熵具有最大值,而當(dāng)存在個(gè)別的團(tuán)體聚集時(shí),上述用戶分布的信息熵的值將大幅度的減小。
因此,在本申請(qǐng)的實(shí)施例中,可將買家用戶隨機(jī)分布時(shí)的用戶分布的信息熵作為用戶分布的基準(zhǔn)信息熵,并通過實(shí)際交易過程中實(shí)際的用戶分布的信息熵與該基準(zhǔn)信息熵進(jìn)行比對(duì)來判斷是否存在個(gè)別的團(tuán)體聚集的情況。如果存在,則可判斷出現(xiàn)了異常交易。
那么,首先需要獲取目標(biāo)產(chǎn)品的用戶分布的基準(zhǔn)信息熵。在本申請(qǐng)的一個(gè)實(shí)施例中,第一獲取單元42可用于:獲取目標(biāo)產(chǎn)品對(duì)應(yīng)的產(chǎn)品交易量,根據(jù)預(yù)先擬合的預(yù)估函數(shù)和產(chǎn)品交易量生成目標(biāo)產(chǎn)品對(duì)應(yīng)的用戶分布的基準(zhǔn)信息熵。其中,預(yù)估函數(shù)為表示產(chǎn)品交易量與用戶分布的基準(zhǔn)信息熵函數(shù)關(guān)系的曲線。因此,可將目標(biāo)產(chǎn)品的產(chǎn)品交易量帶入預(yù)估函數(shù),得到目標(biāo)產(chǎn)品對(duì)應(yīng)的用戶分布的基準(zhǔn)信息熵。
第二獲取單元43用于獲取所述信息熵和所述基準(zhǔn)信息熵之間差值。
判斷單元44用于如果所述差值大于預(yù)設(shè)閾值,則判斷所述用戶分布信息不符合預(yù)設(shè)分布。
篩選模塊50用于如果所述用戶分布信息不符合預(yù)設(shè)分布,則根據(jù)各群組標(biāo)簽對(duì)應(yīng)的交易數(shù)據(jù)的數(shù)量篩選出一個(gè)或多個(gè)群組,并以所述篩選出的群組及其交易數(shù)據(jù)作為異常交易群組及其異常交易數(shù)據(jù)。
在當(dāng)前用戶交易數(shù)據(jù)中異常交易數(shù)據(jù)和正常交易數(shù)據(jù)混雜的情況下,影響用戶分布信息熵的往往是具有最大規(guī)模的群組,其在產(chǎn)品買家用戶分布中呈現(xiàn)峰值狀態(tài),即用戶在某一群組中具有高聚集度的特點(diǎn)。因此,在本申請(qǐng)的一個(gè)實(shí)施例中,篩選模塊50可具體用于篩選出交易數(shù)據(jù)的數(shù)量最大的一個(gè)或多個(gè)群組,并以所述篩選出的群組及其交易數(shù)據(jù)作為異常交易群組及其異常交易數(shù)據(jù),。即以交易數(shù)據(jù)的數(shù)量最大的群組作為異常交易群組,以異常交易群組的交易數(shù)據(jù)作為異常交易數(shù)據(jù)。
其中,可根據(jù)上述第三交易列表
由此,可通過實(shí)際交易過程中的目標(biāo)產(chǎn)品的用戶分布的信息熵與相應(yīng)的基準(zhǔn)信息熵進(jìn)行比對(duì)來判斷是否存在異常交易數(shù)據(jù),并進(jìn)行提取,可解釋性強(qiáng),能夠有效識(shí)別團(tuán)伙作弊交易模式(如團(tuán)伙刷單等)的異常交易,提高異常交易的召回率。
本申請(qǐng)實(shí)施例的異常交易數(shù)據(jù)的獲取裝置,可根據(jù)交易數(shù)據(jù)中的用戶信息生成群組標(biāo)簽,并根據(jù)群組標(biāo)簽對(duì)用戶進(jìn)行群組劃分,并根據(jù)各群組對(duì)應(yīng)的用戶交易數(shù)據(jù)獲取目標(biāo)產(chǎn)品的用戶分布信息,并在用戶分布信息不符合預(yù)設(shè)分布時(shí),根據(jù)各群組標(biāo)簽對(duì)應(yīng)的交易數(shù)據(jù)的數(shù)量篩選出異常交易數(shù)據(jù)對(duì)應(yīng)。
圖8為根據(jù)本申請(qǐng)另一個(gè)實(shí)施例的異常交易數(shù)據(jù)的獲取裝置的結(jié)構(gòu)示意圖。
如圖8所示,根據(jù)本申請(qǐng)實(shí)施例的異常交易數(shù)據(jù)的獲取裝置,包括:第一獲取模塊10、生成模塊20、第二獲取模塊30、判斷模塊40和篩選模塊50和更新模塊60。
更新模塊60用于將異常交易數(shù)據(jù)從交易數(shù)據(jù)中刪除,并更新產(chǎn)品交易量,并根據(jù)更新后的產(chǎn)品交易量更新相應(yīng)的基準(zhǔn)信息熵。
從而,可根據(jù)刪除異常交易數(shù)據(jù)后的交易量對(duì)應(yīng)的用戶分布的信息熵與更新后的交易量對(duì)應(yīng)的基準(zhǔn)信息熵進(jìn)行比對(duì),以判斷是否存在異常數(shù)據(jù)。如果存在,則繼續(xù)刪除,并再次判斷。
本申請(qǐng)實(shí)施例的異常交易數(shù)據(jù)的獲取裝置,通過不斷剔除目標(biāo)產(chǎn)品的用戶交易數(shù)據(jù)中最大規(guī)模的具有團(tuán)伙特征的交易數(shù)據(jù)(異常交易數(shù)據(jù))的貪心算法,不斷剔除與輸出異常交易數(shù)據(jù),商品異常交易數(shù)據(jù)與正常交易數(shù)據(jù)的區(qū)分更加準(zhǔn)確,能夠挖掘具有高聚集度的團(tuán)伙用戶以及其對(duì)應(yīng)的異常交易數(shù)據(jù)。
流程圖中或在此以其他方式描述的任何過程或方法描述可以被理解為,表示包括一個(gè)或更多個(gè)用于實(shí)現(xiàn)特定邏輯功能或過程的步驟的可執(zhí)行指令的代碼的模塊、片段或部分,并且本申請(qǐng)的優(yōu)選實(shí)施方式的范圍包括另外的實(shí)現(xiàn),其中可以不按所示或討論的順序,包括根據(jù)所涉及的功能按基本同時(shí)的方式或按相反的順序,來執(zhí)行功能,這應(yīng)被本申請(qǐng)的實(shí)施例所屬技術(shù)領(lǐng)域的技術(shù)人員所理解。
在流程圖中表示或在此以其他方式描述的邏輯和/或步驟,例如,可以被認(rèn)為是用于實(shí)現(xiàn)邏輯功能的可執(zhí)行指令的定序列表,可以具體實(shí)現(xiàn)在任何計(jì)算機(jī)可讀介質(zhì)中,以供指令執(zhí)行系統(tǒng)、裝置或設(shè)備(如基于計(jì)算機(jī)的系統(tǒng)、包括處理器的系統(tǒng)或其他可以從指令執(zhí)行系統(tǒng)、裝置或設(shè)備取指令并執(zhí)行指令的系統(tǒng))使用,或結(jié)合這些指令執(zhí)行系統(tǒng)、裝置或設(shè)備而使用。就本說明書而言,"計(jì)算機(jī)可讀介質(zhì)"可以是任何可以包含、存儲(chǔ)、通信、傳播或傳輸程序以供指令執(zhí)行系統(tǒng)、裝置或設(shè)備或結(jié)合這些指令執(zhí)行系統(tǒng)、裝置或設(shè)備而使用的裝置。計(jì)算機(jī)可讀介質(zhì)的更具體的示例(非窮盡性列表)包括以下:具有一個(gè)或多個(gè)布線的電連接部(電子裝置),便攜式計(jì)算機(jī)盤盒(磁裝置),隨機(jī)存取存儲(chǔ)器(ram),只讀存儲(chǔ)器(rom),可擦除可編輯只讀存儲(chǔ)器(eprom或閃速存儲(chǔ)器),光纖裝置,以及便攜式光盤只讀存儲(chǔ)器(cdrom)。另外,計(jì)算機(jī)可讀介質(zhì)甚至可以是可在其上打印所述程序的紙或其他合適的介質(zhì),因?yàn)榭梢岳缤ㄟ^對(duì)紙或其他介質(zhì)進(jìn)行光學(xué)掃描,接著進(jìn)行編輯、解譯或必要時(shí)以其他合適方式進(jìn)行處理來以電子方式獲得所述程序,然后將其存儲(chǔ)在計(jì)算機(jī)存儲(chǔ)器中。
應(yīng)當(dāng)理解,本申請(qǐng)的各部分可以用硬件、軟件、固件或它們的組合來實(shí)現(xiàn)。在上述實(shí)施方式中,多個(gè)步驟或方法可以用存儲(chǔ)在存儲(chǔ)器中且由合適的指令執(zhí)行系統(tǒng)執(zhí)行的軟件或固件來實(shí)現(xiàn)。例如,如果用硬件來實(shí)現(xiàn),和在另一實(shí)施方式中一樣,可用本領(lǐng)域公知的下列技術(shù)中的任一項(xiàng)或他們的組合來實(shí)現(xiàn):具有用于對(duì)數(shù)據(jù)信號(hào)實(shí)現(xiàn)邏輯功能的邏輯門電路的離散邏輯電路,具有合適的組合邏輯門電路的專用集成電路,可編程門陣列(pga),現(xiàn)場(chǎng)可編程門陣列(fpga)等。
本技術(shù)領(lǐng)域的普通技術(shù)人員可以理解實(shí)現(xiàn)上述實(shí)施例方法攜帶的全部或部分步驟是可以通過程序來指令相關(guān)的硬件完成,所述的程序可以存儲(chǔ)于一種計(jì)算機(jī)可讀存儲(chǔ)介質(zhì)中,該程序在執(zhí)行時(shí),包括方法實(shí)施例的步驟之一或其組合。
此外,在本申請(qǐng)各個(gè)實(shí)施例中的各功能單元可以集成在一個(gè)處理模塊中,也可以是各個(gè)單元單獨(dú)物理存在,也可以兩個(gè)或兩個(gè)以上單元集成在一個(gè)模塊中。上述集成的模塊既可以采用硬件的形式實(shí)現(xiàn),也可以采用軟件功能模塊的形式實(shí)現(xiàn)。所述集成的模塊如果以軟件功能模塊的形式實(shí)現(xiàn)并作為獨(dú)立的產(chǎn)品銷售或使用時(shí),也可以存儲(chǔ)在一個(gè)計(jì)算機(jī)可讀取存儲(chǔ)介質(zhì)中。
上述提到的存儲(chǔ)介質(zhì)可以是只讀存儲(chǔ)器,磁盤或光盤等。
在本說明書的描述中,參考術(shù)語(yǔ)“一個(gè)實(shí)施例”、“一些實(shí)施例”、“示例”、“具體示例”、或“一些示例”等的描述意指結(jié)合該實(shí)施例或示例描述的具體特征、結(jié)構(gòu)、材料或者特點(diǎn)包含于本申請(qǐng)的至少一個(gè)實(shí)施例或示例中。在本說明書中,對(duì)上述術(shù)語(yǔ)的示意性表述不一定指的是相同的實(shí)施例或示例。而且,描述的具體特征、結(jié)構(gòu)、材料或者特點(diǎn)可以在任何的一個(gè)或多個(gè)實(shí)施例或示例中以合適的方式結(jié)合。
盡管已經(jīng)示出和描述了本申請(qǐng)的實(shí)施例,本領(lǐng)域的普通技術(shù)人員可以理解:在不脫離本申請(qǐng)的原理和宗旨的情況下可以對(duì)這些實(shí)施例進(jìn)行多種變化、修改、替換和變型,本申請(qǐng)的范圍由權(quán)利要求及其等同限定。
- 還沒有人留言評(píng)論。精彩留言會(huì)獲得點(diǎn)贊!