基于螢火蟲算法和動態優先級的云工作流調度方法與流程
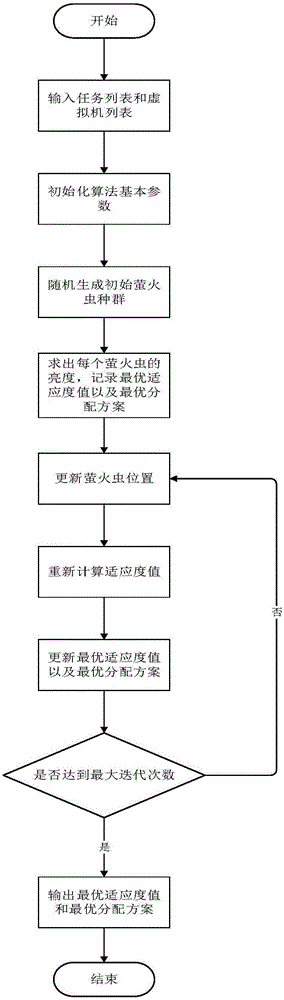
本發明屬于云工作流調度技術領域,在調度時綜合考慮了時間、費用和可靠性三個重要QoS因素。針對時間和可靠性雙重約束下費用最小化的云工作流調度問題,提出了基于螢火蟲算法和動態優先級的最優調度方案。
背景技術:
近年來,隨著云計算技術的迅猛發展,越來越多的組織將傳統的業務過程與應用遷移到云計算環境。云工作流調度指的是將相互之間具有依賴關系的工作流任務映射到虛擬機資源上執行的過程,它決定了工作流實例執行的成敗和執行效率的高低。一般說來,云工作流調度問題是一個NP-hard問題,對于用戶給定的工作流實例,調度過程存在著較大的改進和優化空間。
目前國內外學者在工作流優化調度方面做了許多有價值的研究工作。一是研究如何優化工作流完成時間。例如,針對單工作流應用,HEFT算法是一種針對異構資源的工作流調度經典算法。該算法根據任務的平均執行時間和通信時間計算出一個優先級,在任務分配時,選擇具有最大優先級的任務并將其調度到完成時間最小的計算節點上。二是研究如何在截止時間約束下優化工作流費用。例如,ByuByun等人針對云計算環境提出了PBTS算法,該算法將工作流截止期劃分為多個時間段,并利用BTS算法為每個時間段計算工作流需要的最少資源量,但該算法針對的是同構資源模型。
現有的工作流調度算法主要從時間和費用兩方面進行研究,但這些算法都沒有考慮可靠性,均假設任務執行過程和數據傳輸過程是沒有中斷、不會失敗的,但在實際系統中,資源和網絡的不可用都會對工作流的執行造成負面影響。
技術實現要素:
本發明針對現有技術的不足,提出了一種基于螢火蟲算法和動態優先級的多QoS云工作流調度方法。該方法在云工作流調度時綜合考慮了時間、費用和可靠性三個重要QoS因素。特別地,本發明結合云工作流調度問題的特點,重新定義了螢火蟲算法中的位置、距離以及位置更新方式,同時對于每一種調度方案,采取動態優先級算法確定任務順序,以減少工作流完成時間。
本發明方法的具體步驟是:
步驟(1).輸入任務列表和虛擬機列表;其中任務列表包含了目標工作流中的所有待執行任務;虛擬機列表包含了云服務提供商提供的用來執行工作流任務的虛擬機資源;
步驟(2).初始化螢火蟲算法的基本參數,設置螢火蟲的數目v、光吸收系數γ、最大迭代數itMax、步長因子α;
步驟(3).隨機生成初始螢火蟲種群的位置,每個螢火蟲的位置都代表了一種調度方案,即任務和虛擬機的映射關系;
假設螢火蟲的個數為c,工作流中任務的個數為N,可用來進行調度的虛擬機個數為M,則第i個螢火蟲的位置可用一個N維的向量xi=(xi,1,xi,2,...,xi,q,...,xi,N)表示,其中xi,q∈(1,2,...,M);一個螢火蟲的位置向量代表一種可行的調度方案,該位置向量中的每一個元素都代表工作流中的一個任務由哪個虛擬機調度執行;
步驟(4).對每個螢火蟲位置采用動態優先級調度算法來確定任務的執行順序;之后求出每種調度方案的完成時間makespan、費用cost和可靠性reliablity,最終求得每種調度方案的適應度函數值作為螢火蟲的亮度;設置最優適應度值bestFitness為初始螢火蟲中最優適應度值、最優調度方案bestDop為相應的螢火蟲位置;
對于某種調度方案S,其適應度函數f(S)定義如下:
其中,為了使費用單位化引入了min_cost變量,流程執行的費用必須小于這個值,MinRealiablity表示用戶要求的最低可靠性,Deadline表示截止時間;
步驟(5).對每一個螢火蟲i進行如下操作:若螢火蟲i的周圍有比其更亮的螢火蟲,則該螢火蟲向著比它亮的螢火蟲移動,按照如下公式更新螢火蟲移動之后的位置:
其中θ是0~1之間的隨機數,βi,j表示比螢火蟲i亮的螢火蟲j對i的吸引度,由如下公式求得:
其中γ為光吸收系數,β0為最大吸引度,即在光源處的吸引度;rij表示兩只螢火蟲的距離,由如下公式求得:
其中l(·)是指示函數,當參數為真時,函數值為1,否則為0;
若周圍沒有比它更亮的螢火蟲,此時該只螢火蟲為最優螢火蟲,如果對應的調度方案沒有滿足時間約束,則在最終完成時間最大的虛擬機上挑選出運行時間最短的任務,將它分配到最終完成時間最小的虛擬機上,優先滿足時間約束;如滿足了截止時間的情況下,則隨機移動;
步驟(6).更新螢火蟲位置后,重新計算適應度值,若適應度值大于bestFitness,則設置bestFitness為該適應度值,并更新最優調度方案bestDop;
步驟(7).重復步驟(5)、(6),直到迭代次數達到itMax;
步驟(8).輸出此時的最優適應度值bestFitness以及最優調度方案bestDop。
本發明所提出的基于螢火蟲算法和動態優先級的多QoS云工作流調度方法主要分為以下幾個模塊進行:工作流映射模塊、虛擬機實例生成模塊、工作流引擎模塊、工作流調度模塊。
工作流映射模塊用于導入XML格式的流程定義文件(DAG)以及其他元數據文件,比如文件的大小。流程定義文件包括任務的描述、任務之間的依賴關系、執行任務所需的輸入輸出文件等。
虛擬機實例生成模塊通過配置虛擬機的帶寬、每秒處理的指令數(MIPS)、失敗率、費用等參數生成處理工作流任務的虛擬機實例。
工作流引擎模塊根據工作流任務之間的依賴關系來管理各個任務,以確保一個任務只有在其所有父任務都成功完成后才能得到釋放。工作流引擎只會把空閑任務釋放到調度器中。
工作流調度模塊是整個調度過程中最核心的部分,該模塊依據本發明提出的算法將任務分配到相應的工作節點上。
本發明提出的方法綜合考慮了時間、費用和可靠性三個重要QoS因素。針對時間和可靠性雙重約束下費用最小化的云工作流調度問題,提出了基于螢火蟲算法和動態優先級的最優調度方案。特別地,本發明結合云工作流調度問題的特點對標準螢火蟲算法進行了改進,重新定義了螢火蟲算法中的位置、距離以及位置更新方式,提出了適用于云工作流調度問題的螢火蟲算法。同時對于每一種調度方案,采取動態優先級算法確定任務順序,以減少工作流完成時間。通過在WorkflowSim平臺上進行模擬調度仿真實驗,證明了該方法在收斂速度和最優值方面均優于傳統云工作流調度算法。
附圖說明
圖1算法流程圖;
具體實施方式
本發明提出的方法可以應用在如下場景:假設存在若干個相互之間具有依賴關系的工作流任務,以及用以執行這些工作流任務的若干虛擬機,如何將這些任務調度到相應的虛擬機上去執行使得工作流的執行效率達到最優。本發明提供的調度方法綜合考慮了時間、費用和可靠性三個重要QoS因素,在滿足時間和可靠性雙重約束的前提下,使工作流的執行費用盡可能達到最小。
下面將對本發明所提供的基于螢火蟲算法和動態優先級的最優調度方案做具體說明。
為敘述方便,定義相關符號如下:
ti:第i(i=1,2,...,N)個任務。
vmm:第m(m=1,2,...,M)個虛擬機。
表示虛擬機vmm的計算能力即每秒處理的指令數。
表示虛擬機vmm的失敗率。
表示虛擬機的單位時間的租賃費用。
表示任務tj的完成時間。
數據從ti傳輸給tj的時間。
表示虛擬機執行完ti之前的任務空閑下來的時間。
表示任務ti的所有前驅任務都已經執行完畢并且將數據都傳輸到ti上的時間。
表示虛擬機與之間的帶寬。
w(ti):任務ti的指令數。
虛擬機vmm上第一個被執行的任務。
虛擬機vmm上最后一個被執行的任務。
tf(vmm,vmn):表示虛擬機vmm與虛擬機vmn之間傳輸失敗率。
Deadline:表示用戶預先確定的工作流截止時間。
MinReliablity:表示用戶要求的最低可靠性。
βi,j:表示螢火蟲j對螢火蟲i的吸引度。
β0:為最大吸引度,即在光源處的吸引度。
γ:為光吸收系數,一般取值0~1,其值越大,表明被空氣介質吸收的熒光越多,被接收到的亮度越小吸引度越小。
rij:兩只螢火蟲之間的距離(即兩種調度方案距離),距離越遠,吸引度越小。
entityNum:表示每個任務的還有多少父任務未確定優先級。
idx:表示優先級(idx越小優先級越高)。
vmTaskList:表示每個虛擬機中的可執行任務列表。
步驟(1):輸入任務列表和虛擬機列表。其中任務列表包含了目標工作流中的所有待執行任務,虛擬機列表包含了云服務提供商提供的用來執行工作流任務的虛擬機資源。
步驟(2):初始化螢火蟲算法的基本參數,設置螢火蟲的數目v、光吸收系數γ、最大迭代數itMax、步長因子α。
步驟(3):隨機生成初始螢火蟲種群的位置,每個螢火蟲的位置都代表了一種調度方案,即任務和虛擬機的映射關系。
我們對傳統螢火蟲算法中的螢火蟲位置進行重新編碼,使得重新編碼后的位置都代表了一種調度方案,即任務和虛擬機之間的映射關系。假設螢火蟲的個數為c,工作流中任務的個數為N,可用來進行調度的虛擬機個數為M,則第i個螢火蟲的位置可用一個N維的向量xi=(xi,1,xi,2,...,xi,q,...,xi,N)表示,其中xi,q∈(1,2,...,M);一個螢火蟲的位置向量代表一種可行的調度方案,該位置向量中的每一個元素都代表工作流中的一個任務由哪個虛擬機調度執行。
步驟(4):對每個螢火蟲位置采用動態優先級調度算法來確定任務的執行順序。
動態優先級調度算法的具體執行過程如下:
1)將起始任務添加到對應的虛擬機可執行列表vmTaskList中,初始化entityNum為每個任務對應的父任務個數;
2)遍歷每個虛擬機的可執行列表中,計算可執行任務的完成時間;
3)在所有可執行任務中,找到完成時間最早的任務ttask_sel;
4)為ttask_sel分配優先級,刪除對應虛擬機中可執行任務列表中的該任務;
5)更新ttask_sel所有子任務在entityNum中的狀態,如果變為可執行任務,則添加到對應虛擬機的可執行列表中;
6)重復步驟2)-5)直到每個虛擬機都沒有可執行任務。
步驟(5):求出每種調度方案的完成時間makespan、費用cost和可靠性reliablity,最終求得每種調度方案的適應度函數值作為螢火蟲的亮度。
1.完成時間
假設任務ti被分配到虛擬機上執行。由于受到工作流結構的約束,任務ti必須在其前驅任務執行完畢后將數據傳輸到任務ti所在的虛擬機上才可以執行。如果此時虛擬機上還有其他未完成的任務,則任務ti必須等待虛擬機其他任務執行完成才能開始執行,因此任務ti的開始時間可用如下公式計算:
任務ti的完成時間可用如下公式計算:
其中,任務ti在虛擬機上的執行時間通過如下公式計算:
從第一個任務開始到執行到最后一個任務的時間段稱為整個工作流的完成時間,因而工作流的完成時間可用如下公式計算:
2.費用
對于單個虛擬機vmm的任務執行費用為:
整個工作流的費用等于所有虛擬機分費用之和,即:
3.可靠性
假設系統的調度方案可表示為S:T×R→{0,1},矩陣S代表了工作流中所有任務到所有虛擬機資源的一個有效映射,若其中的元素Si,m值為1,則表示任務ti被調度到虛擬機vmm上執行。由于虛擬機vmm在時間段t內的可靠性為則虛擬機vmm傳輸數據到虛擬機vmn在傳輸時間段t內的可靠性為在調度方案S中,虛擬機vmm上所有任務的執行時間為:
則虛擬機vmm的可靠性為:
同理可得數據在虛擬機vmm、vmn間的傳輸時間為:
則虛擬機vmm、vmn間傳輸可靠性為:
綜上所述,可得整個工作流的可靠性即流程成功執行的可能性為:
4.適應度函數
為了能體現費用為目標、時間和可靠性為約束這一特點,現采用如下公式描述本方法研究的調度問題:
min cost
s.t.maskspan≤Deadline
reliability≥MinReliability
基于這種約束,對于某一種調度方案,定義其適應度函數如下公式所示:
步驟(6):在所有的調度方案中選出適應度值最優的,設置最優適應度值bestFitness的初始值為該螢火蟲的適應度值、設置最優調度方案bestDop的初始值為該螢火蟲的位置。
步驟(7):對每一個螢火蟲i進行位置更新。在i的搜索范圍內,找到所有比它亮的螢火蟲放到集合中,其中ni表示集合中螢火蟲個數,niti,j表示螢火蟲編號。遍歷集合Niti,螢火蟲i被螢火蟲niti,j吸引而向niti,j移動,1≤j≤ni。首先按照如下公式求出螢火蟲niti,j對螢火蟲i的吸引度:
其中l(·)是指示函數,當參數為真時,函數值為1,否則為0(即l(true)=1,l(false)=0)。
若螢火蟲i的周圍有比其更亮的螢火蟲,則該螢火蟲向著比它亮的螢火蟲移動。假定比它亮的螢火蟲為j,移動的時候是根據吸引度的大小來進行位置更新。按照如下公式對螢火蟲的位置進行更新:
吸引度作為一個概率,用來決定xi是否從xj繼承某個解維度。在判定前,我們隨機得到0~1的取值θ,當吸引度大于θ時,則xi從xj處繼承某個解維度的值,否則保留原始的值。如果周圍沒有比它更亮的螢火蟲(Niti為空集),此時該只螢火蟲為最優螢火蟲,如果對應的調度方案沒有滿足時間約束,則在最終完成時間最大的虛擬機上挑選出運行時間最短的任務,將它分配到最終完成時間最小的虛擬機上,優先滿足時間約束。如滿足了截止時間的情況下,則隨機移動。
步驟(8):更新螢火蟲位置后,重新計算適應度值,若適應度值大于bestFitness,則設置bestFitness為該適應度值,并更新最優調度方案bestDop。
步驟(9):當前迭代次數it=it+1,如果it<itMax,則重復執行步驟(7)、步驟(8)。
步驟(10):當迭代次數達到itMax時,輸出此時的最優適應度值bestFitness以及最優調度方案bestDop。
整個算法的執行過程如圖1所示。
- 還沒有人留言評論。精彩留言會獲得點贊!