基于http服務切面與日志系統的異步數據同步方法和系統與流程
本發明涉及異步數據同步領域,特別涉及基于http服務切面與日志系統的異步數據同步方法和系統。
背景技術:
Bloor研究所2010的一項調查顯示,估計數據遷移市場將超過50億美元并且還正在日益增長。現在許多公司有不同的方法進行數據庫遷移,如抽取/轉換/裝載(簡稱ETL),復制和手動腳本。然而這些方法面臨著一些問題,當一方面數據量在增長,而另一方面允許的停機時間在減少時,這項工作將變得更復雜。數據遷移下統計數據大致如下:
·16%的數據遷移部分項目取得了成功
·37%的預算超支
·64%沒有按時完成
所以,遷移要經過精心策劃和執行,以盡量減少停機時間并保持數據的完整性和數據庫的性能,因為許多公司已經遍布全球,并且每天24小時都要操作數據庫。
有些情況下公司會做異構數據庫的遷移與切換:例如為了減少費用與技術靈活度,很多公司會選擇從商用數據庫遷移到開源數據庫。遷移是件很麻煩的事情,因為遷移不可能一蹴而就而是一個慢慢變遷的過程,所以就需要同時運營新老兩套系統。同時,遷移還需要考慮老的應用、其他服務的兼容。而兼容即包括:老系統接口的兼容、數據服務的兼容等。一般而言,接口的兼容容易實現,只需要對開發人員進行統一的約束、定期安排代碼審查即可。麻煩的是數據的協調、確保其他使用老系統數據的系統可以正常提供優質服務。因此,就需要打通數據環節。如何采用正確的方式來打通這個環節是現有技術中的難點。另外,由于新系統替換老系統需要時間去過度,所以數據同步就需要考慮是雙向同步、還是單向同步。一般而言,雙向同要比單向同步復雜很多。而數據同步需要考慮的問題有很多,比如:同步的延遲不能太大、同步的數據要完備、數據不可丟失、對原有系統要有較低的侵入、數據庫無關性等等。
異構數據庫遷移的方法包括:1)利用Power Builder的數據管道技術;2)利用ODBC技術和SQL語句;3)利用系統工具實現數據遷移。然而,這些方法大多操作較為復雜、靈活性差,不能夠實現對數據的良好組織管理;不能自動完成數據的遷移,用戶需要清楚地了解數據庫的儲存結構,且需要花費大量時間進行調試;并且一旦數據庫結構發生變化,代碼需要作大量改動,后期維護很困難。另外,系統工具又有一定的局限性,比較依賴具體的數據庫產品,通用性欠缺,需要利用這些工具編寫適當的遷移程序。
技術實現要素:
本發明要解決的技術問題是,如何采用應用日志的方式來實現數據同步。
解決上述技術問題,本發明提供了基于http服務切面與日志系統的異步數據同步方法,包括如下步驟:
攔截客戶端的接口請求,并記錄接口訪問日志,
將所述訪問日志作為請求事件源傳遞至消息隊列,解析所述消息隊列中的訪問日志,
解析后還原請求事件的入參和/或出參,將數據轉換后進行新老系統的數據映射后再寫入新數據庫。
更進一步,攔截客戶端的接口具體包括:采用切面技術來攔截接口請求。
更進一步,所述切面技術采用:jaxrs的請求過濾器、servlet的過濾器、spring mvc的攔截器中的一種或者多種,用以提取所述接口請求中的入參、出參、url以及method的數據。
更進一步,將所述訪問日志作為請求事件源傳遞至消息隊列的方法具體為:采用log4j2的kafka組件直接將日志寫入到kafka隊列。
更進一步,將所述訪問日志作為請求事件源傳遞至消息隊列的方法具體為:通過flume或者fluent的采集工具將數據提交到kafka隊列。
更進一步,解析所述消息隊列中的訪問日志的方法至少包括:一處理程序,用以將正確的消息保存到本地庫中,再去做同步,如果處理失敗則自動重試,所述自動重試的次數不大于3次,若大于3次則進行人工處理。
更進一步,方法還包括:在寫方法上加注釋,再編寫處理程序。
更進一步,將日志寫入老系統的數據庫,然后配置flume或者fluent來sink日志到kafka隊列。
更進一步,方法還包括:采用hibernate、mybatis或者任一db框架來進行新老數據庫中數據的提取和寫入。
基于上述,本申請還提供了基于http服務切面與日志系統的異步數據同步系統,包括:
一攔截單元,用以攔截客戶端的接口請求,并記錄接口訪問日志,
一隊列單元,用以將所述訪問日志作為請求事件源傳遞至消息隊列,解析所述消息隊列中的訪問日志,
一處理程序,用以解析后還原請求事件的入參和/或出參,將數據轉換后進行新老系統的數據映射后再寫入新數據庫。
本發明的有益效果:
由于本發明的方法包括攔截客戶端的接口請求,并記錄接口訪問日志,將所述訪問日志作為請求事件源傳遞至消息隊列,解析所述消息隊列中的訪問日志,解析后還原請求事件的入參和/或出參,將數據轉換后進行新老系統的數據映射后再寫入新數據庫。通過對接口記錄日志,將日志提交到任意一種數據源,由處理程序處理數據源的日志、做數據轉換、同步到新的庫中。從而可讓異步數據同步的延遲降低、復雜度可控。
此外,本發明提供的系統,并不針對特定的數據庫,同時可擴展能力較高。
附圖說明
圖1是本發明中的方法流程示意圖;
圖2是本發明中的系統的結構示意圖;
圖3圖1中的進一步處理步驟示意圖;
圖4是圖1中的請求接口數據的類型示意圖;
圖5是圖1中的方法具體實施方式示意圖;
圖6是圖1中的方法另一具體實施方式示意圖。
具體實施方式
現在將參考一些示例實施例描述本公開的原理。可以理解,這些實施例僅出于說明并且幫助本領域的技術人員理解和實施例本公開的目的而描述,而非建議對本公開的范圍的任何限制。在此描述的本公開的內容可以以下文描述的方式之外的各種方式實施。
如本文中所述,術語“包括”及其各種變體可以被理解為開放式術語,其意味著“包括但不限于”。術語“基于”可以被理解為“至少部分地基于”。術語“一個實施例”可以被理解為“至少一個實施例”。術語“另一實施例”可以被理解為“至少一個其它實施例”。
可以理解,本申請中的客戶端是指基于http協議的客戶端,如:瀏覽器、編程語言使用的http client等。HTTP協議(HyperText Transfer Protocol,超文本傳輸協議)是用于從www服務器傳輸超文本到本地瀏覽器的傳輸協議。可以使瀏覽器更加高效,使網絡傳輸減少。它不僅保證計算機正確快速地傳輸超文本文檔,還確定傳輸文檔中的哪一部分,以及哪部分內容首先顯示(如文本先于圖形)等。需要說明的是,本申請的基于的HTTP協議是客戶端瀏覽器或其他程序與Web服務器之間的應用層通信協議。在Internet上的Web服務器上存放的都是超文本信息,客戶機需要通過HTTP協議傳輸所要訪問的超文本信息。HTTP包含命令和傳輸信息,不僅可用于Web訪問,也可以用于其他因特網/內聯網應用系統之間的通信,從而實現各類應用資源超媒體訪問的集成。
HTTP協議能夠支持客戶/服務器模式,客戶向服務器請求服務時,只需傳送請求方法和路徑。請求方法包括但不限于:GET、HEAD、POST。每種方法規定了客戶與服務器聯系的類型不同。另外,HTTP協議允許傳輸任意類型的數據對象,正在傳輸的類型由Content-Type加以標記。
在本申請中的Flume是Cloudera提供的一個高可用的,高可靠的,分布式的海量日志采集、聚合和傳輸的系統,Flume支持在日志系統中定制各類數據發送方,用于收集數據;同時,Flume提供對數據進行簡單處理,并寫到各種數據接受方(可定制)的能力。Flume最早是Cloudera提供的日志收集系統,目前是Apache下的一個孵化項目,Flume支持在日志系統中定制各類數據發送方,用于收集數據。數據處理方面:Flume提供對數據進行簡單處理,并寫到各種數據接受方(可定制)的能力Flume提供了從console(控制臺)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系統,支持TCP和UDP等2種模式),exec(命令執行)等數據源上收集數據的能力。
圖1是本發明中的方法流程示意圖;步驟S100攔截客戶端的接口請求,并記錄接口訪問日志,所述攔截客戶端的接口具體包括:采用切面技術來攔截接口請求,所述切面技術采用:jaxrs的請求過濾器、servlet的過濾器、spring mvc的攔截器中的一種或者多種,用以提取所述接口請求中的入參、出參、url以及method的數據。如圖4是圖1中的請求接口數據的類型示意圖;請求接口數據包括但不限于:請求ID、時間ID、請求URL、請求數據類型、返回數據類型等。
步驟S101將所述訪問日志作為請求事件源傳遞至消息隊列,解析所述消息隊列中的訪問日志,在所述步驟S101中將所述訪問日志作為請求事件源傳遞至消息隊列的方法具體為:采用log4j2的Kafka組件直接將日志寫入到Kafka隊列。在一些實施例中,將所述訪問日志作為請求事件源傳遞至消息隊列的方法具體為:通過flume或者fluent的采集工具將數據提交到Kafka隊列。
Kafka是一種分布式的基于發布/訂閱的消息系統,以時間復雜度為O(1)的方式提供消息持久化能力,并保證即使對TB級以上數據也能保證常數時間的訪問性能。所以,在上述實施例中采用log4j2的Kafka組件直接將日志寫入到Kafka隊列,由于Kafka具備高吞吐率,同時支持離線數據處理和實時數據處理,所以可以將所述訪問日志作為請求事件源傳遞至消息隊列的優選方法。
步驟S102解析后還原請求事件的入參和/或出參,將數據轉換后進行新老系統的數據映射后再寫入新數據庫。
在上述步驟S101中,解析包括但不限于:日志以JSON的格式存儲,可以采用JSON庫將對應的請求消息轉換成封裝好的對象。JSON是一種輕量級的數據格式,易于程序員閱讀和編寫,同時也易于機器解析和生成。JSON可以將JavaScr ipt對象中表示的一組數據轉換為字符串,然后就可以在函數之間輕松地傳遞這個字符串,或者在異步應用程序中將字符串從Web客戶機傳遞給服務器端程序。
在一些實施例中,解析所述消息隊列中的訪問日志的方法至少包括:一處理程序,用以將正確的消息保存到本地庫中,再去做同步,如果處理失敗則自動重試,所述自動重試的次數不大于3次,若大于3次則進行人工處理。
在一些實施例中,方法還包括:在寫方法上加注釋,再編寫處理程序。在本申請中使用該注解的目的是用來找出需要做數據同步的服務,系統在做處理的時候會查看服務上有沒有該注解,如果有就輸出同步日志到隊列。如果沒有就不做處理。比如:會員模塊有注冊、更新、查詢等服務,這里只有注冊、更新需要做數據同步,而查詢是不需要的。這種情況下只需要對注冊、更新加上注解即可。
在本申請中,使用注解可以減少無效的日志寫入隊列,同時,也可以提升同步處理效率。
在一些實施例中,將日志寫入老系統的數據庫,然后配置flume或者fluent來sink日志到kafka隊列。
在一些實施例中,方法還包括:采用hibernate、mybatis或者任一db框架來進行新老數據庫中數據的提取和寫入。
上述實施例中,基于HTTP協議限制每次連接只處理一個請求,服務器處理完客戶的請求,并收到客戶的應答后,即斷開連接。采用這種方式可以節省傳輸時間。另外,HTTP協議是無狀態協議,即是指協議對于事務處理沒有記憶能力,在服務器不需要先前信息時的應答就較快。另外,JSON格式可以表示數組和復雜的對象,而不僅僅是鍵和值的簡單列表,對于異步數據同步而言具有更好地適應性。
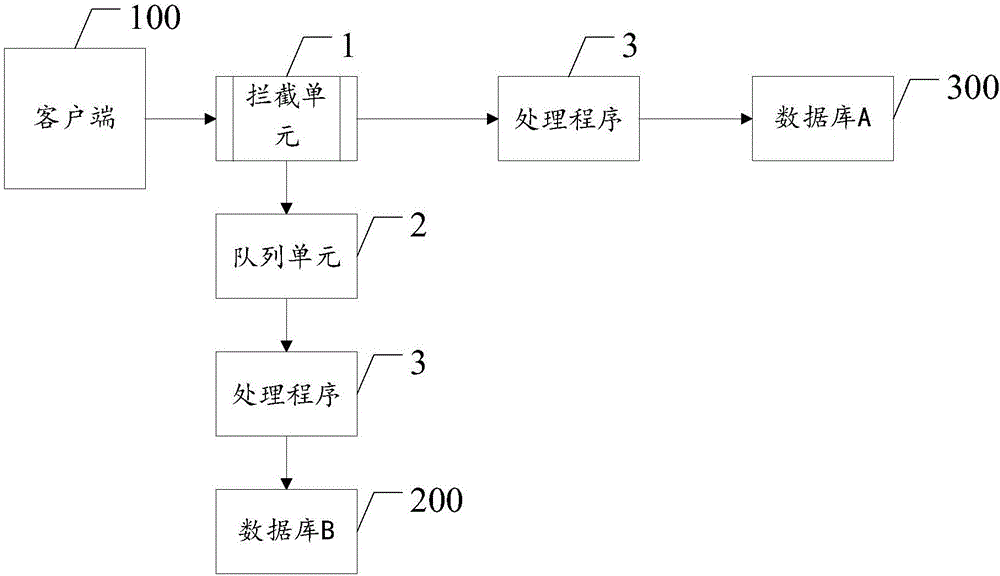
圖2是本發明中的系統的結構示意圖;系統包括:攔截單元1,用以攔截客戶端的接口請求,并記錄接口訪問日志,隊列單元2,用以將所述訪問日志作為請求事件源傳遞至消息隊列,解析所述消息隊列中的訪問日志,以及,處理程序3,用以解析后還原請求事件的入參和/或出參,將數據轉換后進行新老系統的數據映射后再寫入新數據庫。在所述攔截單元1采用切面技術來攔截接口請求。具體地,所述切面技術采用:jaxrs的請求過濾器、servlet的過濾器、spring mvc的攔截器中的一種或者多種,用以提取所述接口請求中的入參、出參、url以及method的數據。在所述隊列單元2中將所述訪問日志作為請求事件源傳遞至消息隊列的方法具體為:采用log4j2的kafka組件直接將日志寫入到kafka隊列。和/或,將所述訪問日志作為請求事件源傳遞至消息隊列的方法具體為:通過flume或者fluent的采集工具將數據提交到kafka隊列,也可以將日志寫入老系統的數據庫,然后配置flume或者fluent來sink日志到kafka隊列。作為本實施例中的優選,在所述處理程序3中,解析所述消息隊列中的訪問日志的方法至少包括:一處理程序,用以將正確的消息保存到本地庫中,再去做同步,如果處理失敗則自動重試,所述自動重試的次數不大于3次,若大于3次則進行人工處理。
本實施例中的系統,由于采用了隊列單元2,可以有效地降低延遲,同時具備高可擴展能力。由于處理程序3解析后還原請求事件的入參和/或出參,將數據轉換后進行新老系統的數據映射后再寫入新數據庫,使得整個系統復雜度可控、數據庫無關。另外,由于攔截單元1,攔截客戶端的接口請求,并記錄接口訪問日志降低了應用侵入性。
圖3圖1中的進一步處理步驟示意圖;解析所述消息隊列中的訪問日志的方法至少包括:一處理程序,用以將正確的消息保存到本地庫中,再去做同步,如果處理失敗則自動重試,所述自動重試的次數不大于3次,若大于3次則進行人工處理。
具體包括步驟為:
步驟S200從kafka提取數據同步的日志
步驟S201解析日志
步驟S202提取URL等數據放入exchange頭
步驟S203保存數據同步請求事件
步驟S204根據URL匹配到對應的處理程序
步驟S205調用對應的處理程序處理同步請求
若處理失敗且失敗次數小于3,則進入步驟S206數據放回隊列
若處理成功或者失敗的次數不小于3,則進入步驟S207處理完成更新完成數據
圖5是圖1中的方法具體實施方式示意圖;
step1客戶發起寫入請求到新的系統;
step 2系統接收請求后分析該請求是否需要做數據同步;
step 3如果需要做數據同步,則DataSyncFilter數據同步過濾器會將對應的請求和響應信息進行封裝,然后寫入隊列;
step 4處理程序會從隊列里提取消息;
step 5處理程序解析消息,將其轉換回封裝的對象;
step 6處理程序根據請求和響應去新的庫里提取數據;
step 7處理程序將新的數據映射成老的數據;
step 8處理程序保存老的數據到老系統的數據庫。
首先,攔截應用系統的接口日志。這里采用切面技術(切面如:jaxrs的請求過濾器、servlet的過濾器、spring mvc的攔截器等)來攔截系統的請求,通過過濾器來提取請求的入參、出參、url、method等數據。其次,本方案采用log4j2的kafka組件直接將日志寫入到kafka隊列的。當然,也可以通過flume、fluent這樣的采集工具將數據提交到kafka。接著,構建處理程序從kafka提取數據進行處理、做好數據轉換、保存數據到新的庫里。處理程序會將正確的消息保存到本地庫中,然后再去做同步,如果處理失敗會自動重試。重試是有次數限制的,系統默認的重試次數是3次,大于3次說明需要人工介入進行特殊處理了。大于3次的原因有很多,可能是數據映射做錯了,或者是數據庫磁盤滿了等。
最后,接入并使用數據同步呢,在需要做數據同步的寫方法上加@DataSyncLogged,然后編寫處理程序即可。這里的處理程序需要接入者完成新老表的數據映射,保存數據到新的庫。使用@DataSyncLogged該注解的目的是用來找出需要做數據同步的服務,系統在做處理的時候會查看服務上有沒有該注解,如果有就輸出同步日志到隊列。如果沒有就不做處理。
優選地,接入者如果覺得使用log4j2直接寫入日志到kafka對應用有比較大的影響,可以考慮將日志寫入本低文件系統。然后配置flume或者fluent來sink日志到kafka隊列也可以。
優選地,接入者如果不想使用kafka,那么可以更換掉。只是要注意下對應的處理程序的數據來源需要調整為新的數據源,如:hbase等。
優選地,接入者可以選擇自己喜歡的數據庫框架來做數據的提取和寫入,hibernate、mybatis或者其他的db框架任君選擇。
上述方法,可以適用于本申請中的系統,攔截單元1,用以攔截客戶端的接口請求,并記錄接口訪問日志,隊列單元2,用以將所述訪問日志作為請求事件源傳遞至消息隊列,解析所述消息隊列中的訪問日志,以及,處理程序3,用以解析后還原請求事件的入參和/或出參,將數據轉換后進行新老系統的數據映射后再寫入新數據庫。
圖6是圖1中的方法另一具體實施方式示意圖。
Step1客戶發起寫入請求到新的系統;
Step2系統接收請求后分析該請求是否需要做數據同步;
Step3如果需要做數據同步,那么DataSync Filter數據同步過濾器會將對應的請求和響應信息進行封裝,然后寫入日志文件;
Step4采集程序(如:flume、fluent)會采集日志并寫入隊列;
Step5處理程序會從隊列里提取消息;
Step6處理程序解析消息,將其轉換回封裝的對象;
Step7處理程序根據請求和響應去新的庫里提取數據;
Step8處理程序將新的數據映射成老的數據;
Step9處理程序保存老的數據到老系統的數據庫。
首先,攔截應用系統的接口日志。這里采用切面技術(切面如:jaxrs的請求過濾器、servlet的過濾器、spring mvc的攔截器等)來攔截系統的請求,通過過濾器來提取請求的入參、出參、url、method等數據。其次,本方案采用log4j2的kafka組件直接將日志寫入到kafka隊列的。當然,也可以通過flume、fluent這樣的采集工具將數據提交到kafka。接著,構建處理程序從kafka提取數據進行處理、做好數據轉換、保存數據到新的庫里。處理程序會將正確的消息保存到本地庫中,然后再去做同步,如果處理失敗會自動重試。重試是有次數限制的,系統默認的重試次數是3次,大于3次說明需要人工介入進行特殊處理了。大于3次的原因有很多,可能是數據映射做錯了,或者是數據庫磁盤滿了等。
最后,接入并使用數據同步呢,在需要做數據同步的寫方法上加@DataSyncLogged,然后編寫處理程序即可。這里的處理程序需要接入者完成新老表的數據映射,保存數據到新的庫。使用@DataSyncLogged該注解的目的是用來找出需要做數據同步的服務,系統在做處理的時候會查看服務上有沒有該注解,如果有就輸出同步日志到隊列。如果沒有就不做處理。
上述方法,可以適用于本申請中的系統,攔截單元1,用以攔截客戶端的接口請求,并記錄接口訪問日志,隊列單元2,用以將所述訪問日志作為請求事件源傳遞至消息隊列,解析所述消息隊列中的訪問日志,以及,處理程序3,用以解析后還原請求事件的入參和/或出參,將數據轉換后進行新老系統的數據映射后再寫入新數據庫。
雖然本公開以具體結構特征和/或方法動作來描述,但是可以理解在所附權利要求書中限定的本公開并不必然限于上述具體特征或動作。而是,上述具體特征和動作僅公開為實施權利要求的示例形式。
- 還沒有人留言評論。精彩留言會獲得點贊!