一種基于改進型LeNet的魯棒蒙面人臉檢測方法與流程
本發明涉及蒙面人臉檢測,尤其是涉及一種基于改進型LeNet的魯棒蒙面人臉檢測方法。
背景技術:
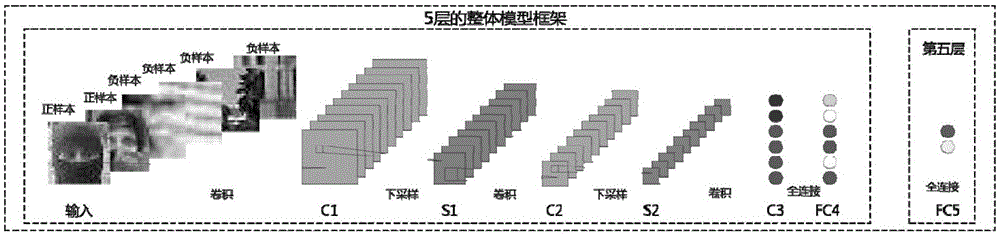
:隨著社會的發展,科學技術的提高,以及多媒體技術的普及,越來越多的人們在網絡上上傳各種各樣的網絡視頻,其中也包括不少犯罪分子企圖利用多媒體渠道,開始傳播暴力恐怖視頻,這種行為已經在一定程度上影響社會的穩定發展。若能在海量的視頻幀中快速且準確地定位出恐怖分子,將極大地減少人力資源和維護社會穩定。作為一種大尺度視頻庫的管理的基本需要,準確地檢索出擁有恐怖分子的暴恐視頻幀對整個社會穩定起到重大的作用。在給定的視頻幀中如何準確定義存在恐怖分子,這是一個困難的問題,因為恐怖分子表現形式多種多樣。通常情況下,恐怖分子都是蒙面的,所以在本發明中,將恐怖分子認為是具有蒙面特征的人。蒙面人人臉檢測作為一種人臉檢測的特殊任務,它跟傳統的人臉檢測技術不同的是面臨著更多的挑戰。一方面,蒙面人人臉檢測包含著傳統人臉檢測技術無法處理的姿勢變化,光照等影響條件。另一方面,蒙面人的臉部是嚴重遮擋的,大大丟失了原本人臉的正常結構,使得傳統算法對于蒙面人人臉檢測失效。目前,大量的人臉檢測技術依賴于手動設置的特征,比如:廣泛使用的Fisherface[1],基于Haar-like特征的級聯分類器[2],基于Gabor-like高維特征的AdaBoost檢測器[3]。由于這種手動設置的特征需要大量的訓練樣本以及蒙面人失去了完整的人臉結構使得手動設計的特征無法準確表征蒙面人人臉結構的,最終使得這些方法無法準確檢測到蒙面人人臉。近來,基于模板的(exemplar-based)人臉檢測方法[4]表現出了較好的效果,主要因為龐大的模板數據庫覆蓋了所有可能的人臉視覺變化(visualvariations),其中包括遮擋,光照,人臉姿勢等變化,但該方法需要大量的模板數據集,且在高度散亂的背景情況下,很容易產生虛警(falsealarm)結果。為了減少需要模板的個數,文獻[5]提出了一種有效的基于提升的模板人臉檢測方法。該方法能夠進一步提高人臉檢測率,加速檢測過程,以及通過判別式訓練和有效性的結合模板作為弱分類器的方式,大大地節約內存開銷。近年來,由于深度學習的興起,使得帶有強大的GPU計算能力的卷積神經網絡(convolutionalneuralnetworks,CNN)在人臉領域也取得了很大的突破,如LFW[6][7][8]。特別地,卷積網絡能夠通過訓練樣本自動學習有效的特征表示。在2012年大尺度識別競賽中(LargeScaleVisualRecognitionChallenge)中,文獻[9]利用深度卷積神經網絡取得了突破性的進展。此外,為了進一步處理只有少量的訓練樣本的情況,文獻[10]引入了預訓練初始化深度網絡的權重,加快網絡的收斂以及得到一個較優的局部解。文獻[11]提出了LeNet模型,在手寫體字符識別中,顯示了很好的性能。隨著這些深度學習技術的發展,基于深度學習的人臉檢測方法成為了可能。參考文獻:[1]H.J.P.BelhumeurPN,K.D.J.Eigenfacesvs.fisherfaces:Recognitionusingclassspecificlinearprojection.IEEETransactionsonPatternAnalysisandMachineIntelligence,1997,19(7):711-720.[2]P.Viola,M.Jones,Rapidobjectdetectionusingaboostedcascadeofsimplefeatures.inProceedingsofCVPR,2001.[3]C.Liu,H.Wechsler,Gaborfeaturebasedclassificationusingtheenhancedfisherlineardiscriminantmodelforfacerecognition.IEEETransactionsonImageProcessing,2002,11(4):467-476.[4]X.Shen,Z.Lin,J.Brandt,etal.Detectingandaligningfacesbyimageretrieval.inProceedingsofCVPR,2013:3460-3467.[5]H.Li,Z.Lin,J.Brandt,etal.Efficientboostedexemplar-basedfacedetection.InProceedingsofCVPR,2014:1843-1850.[6]X.W.YiSun,X.Tang.Deeplearningfacerepresentationfrompredicting10,000classes.inProceedingsofCVPR,2014:1891-1898.[7]Y.Sun,X.Wang,X.Tang.Deeplylearnedfacerepresentationsaresparse,selective,androbust.arXivpreprintarXiv:1412.1265.[8]Y.Sun,X.Wang,X.Tang.Hybriddeeplearningforfaceverification.inProceedingsofICCV,2013:1489-1496.[9]A.Krizhevsky,I.Sutskever,G.E.Hinton.Imagenetclassificationwithdeepconvolutionalneuralnetworks.inProceedingsofNIPS,2012:1097-1105.[10]G.E.Hinton,R.R.Salakhutdinov.Reducingthedimensionalityofdatawithneuralnetworks.Science,2006,313:504-507.[11]Y.LeCun,L.Bottou,Y.Bengio,etal.Gradient-basedlearningappliedtodocumentrecognition.ProceedingsoftheIEEE,1998,86(11):2278-2324.技術實現要素:本發明的目的在于針對訓練樣本少,以及蒙面人完整結構特征無法獲取的特點,提供MLeNet通過引入預訓練及微調(pre-trainingandfine-tuning)等手段,且結合滑動窗口方法,能夠快速且準確地定位蒙面人人臉位置的一種基于改進型LeNet的魯棒蒙面人臉檢測方法。本發明包括以下步驟:1)通過水平翻轉原始訓練圖片,擴充訓練數據;2)通過修改傳統的LeNet模型的結構,提出新的MLeNet模型,使之適應于蒙面人類的檢測問題,具體方法可為:調整卷積核大小和特征圖個數,另外,改變原來的輸出層的節點數10為2,使之適合于人類檢測的2分類問題;3)借用原始的LeNet模型中的參數預訓練MLeNet結構,并微調MLeNet模型,得到適合于蒙面人臉的檢測器;4)結合滑動窗口及非最大化抑制技術準確定位出蒙面人人臉的位置。本發明具有以下突出優點:本發明在原始LeNet模型的基礎上,通過修改卷積層的卷積核(convolutionalfilter)大小、特征圖(featuremap)的個數以及全連接層的節點個數,提出了一種新的MLeNet模型。同時通過擴充訓練樣本以及結合預訓練和微調等手段進一步提高了MLeNet的性能。最后,通過結合滑動窗口及非最大化抑制(non-maximumsuppression)準確定位出蒙面人人臉的位置。在本發明中,對于設備的要求較低,只需要一塊8GU盤用于存儲訓練MLeNet模型的數據集,此外還需要一塊高性能CPU用于計算MLeNet模型中的各種卷積計算。本發明的技術效果如下:通過修改的LeNet模型,提出新的MLeNet模型,利用預訓練、微調、以及數據擴充等技術,并引入一些后處理技術,本發明提出的模型能夠準確的檢測出蒙面人人臉,且在背景散亂,環境變化等干擾條件下,該模型依然有較強的魯棒性。MLeNet模型能夠有效的解決因小樣本問題而引起的模型過擬合問題,以及能夠在自然環境下,準確的定位蒙面人人臉位置,在視頻監控,公共安全等領域存在大量的應用前景。本發明建立了MLeNet模型,該模型修改了原始LeNet模型,使得該模型更適合蒙面人人臉檢測。在訓練樣本較少的情況下,訓練該模型容易導致過擬合現象的發生,因此通過擴充訓練數據集,并結合預訓練、微調等技術,克服了過擬合問題以及提高的MLeNet模型的分類準確率。后處理方法的使用,如非極大值抑制,使得檢測蒙面人人臉更加準確。附圖說明圖1為具體蒙面人臉檢測總流程圖。圖2為修改的卷積神經網絡MLeNet模型:MLeNet輸出層只有兩個節點,在所有的卷積層中擁有較小的卷積核大小,同時每層擁有較大的特征圖個數。圖3為LeNet損失函數值(包括訓練和驗證階段的函數損失值)。圖4為LeNet分類錯誤率(包括正負樣本的分類錯誤率)。圖5為無預訓練與微調的MLeNet損失函數值(包括訓練和驗證階段的函數損失值)。圖6為無預訓練與微調的MLeNet分類錯誤率(包括正負樣本的分類錯誤率)。圖7為有預訓練和微調的MLeNet損失函數值(包括訓練和驗證階段的函數損失值)。圖8為有預訓練和微調的MLeNet分類錯誤率(包括正負樣本的分類錯誤率)。圖9為蒙面的恐怖分子人臉檢測的部分結果(為了保護隱私性,蒙面人的人臉區域由馬賽克處理過)。具體實施方式本發明的目的在于針對訓練樣本少,以及改進傳統的手動調整人臉特征問題,提供MLeNet模型,并通過簡單的擴展樣本、預訓練及微調等手段,訓練得到準確魯棒的人臉模型,同時結合滑動窗口、非最大化抑制方法,得到快速、魯棒及準確的人臉檢測器。具體的算法流程如圖1所示。具體的每個模塊如下:1、擴充數據集本發明所用的訓練及測試數據集為公安部提供的部門暴恐視頻中的一些關鍵幀組合而成。總共包含1140張圖片,其中240張正樣本(即,包含蒙面人臉),900張負樣本(即,不含蒙面人臉),實驗通過隨機選取150張正樣本和750張負樣本作為訓練集(trainingset),50張正樣本和50張負樣本作為驗證集(validationset),留下140張圖片作為測試集(testset)。考慮到人臉的特殊的對稱信息,本發明利用了水平翻轉(horizontalreflection)技術將原本的數據集擴充了兩倍。2、MLeNet模型該MLeNet模型是改進原有的LeNet模型。LeNet模型總共有5層,分別3個卷積層(convolutionallayer)和2個全連接層(fullyconnectedlayer),卷積層含有卷積和下采樣的運算。首先考慮到是否存在蒙面人人臉的問題,這是一個二分類問題,通過修改最后一層全連接層的節點個數,從原來的10變成2,并將原始的LeNet中的卷積核大小減少到3×3,但增加每層特征圖的個數。特別地,改變第一個全連接層(FC4)的節點個數由原來的84增加到500。MLeNet與LeNet模型的每層信息都詳細列在了表1中,另外,最終的MLeNet模型如圖2所示。MLeNet與LeNet模型參見表1:每個模型包含3個卷積層和2個全連接層,詳細的各個模型的各層參數列在最后兩行,其中卷積核大小“num×size×size”,卷積核移動間隔“st.”,空間填充“pad”,及最大池因子。表1令N個訓練樣本為其中標簽yi是標簽變量(本發明中取值為0或1)。最后的損失函數為Softmax損失函數(即,預測值與標簽的誤差),定義為:其中,為模型輸出的概率值,l{yi=j}為示性函數,可定義為若模型輸出值與真實標簽值越相近,則誤差輸出越小。w,b分別為各層的權值和偏差。預測標簽可由一系列w,b前向傳播得到。另外,網絡的各個參數可結合背向傳播(back-propagating)各層誤差,和隨機梯度下降法(stochasticgradientdescent)更新所有的參數。具體地,本發明利用梯度下降法來訓練MLeNet模型(即,更新每層的變量w,b),將批量(batch)大小設置為20,動量(momentum)設為0.9,權重衰減(weightdecay)設為0.0005,學習率(learningrate)設為0.001,訓練回合數(epoch)為100。權重w和偏置b更新規則如下:其中,i是迭代索引值,u,v為動量變量,表示為第i個批量圖像Di所對應的目標函數對權重w的偏導,表示為第i個批量圖像Di所對應的目標函數對權重b的偏導。該更新的規則說明每層變量(權重w和偏差b)更新方式是使得目標損失函數沿著局部最小值方向移動,最終獲得局部最優解。本發明初始化的權重及偏置值直接來自于已訓練好的LeNet模型參數,利用隨機梯度下降法微調MLeNet。在6GB內存,1.90GHzAMDA8-4500MAPU普通PC機上,就可以訓練MLeNet模型100回合,不需要采用GPU,訓練時間只需要花費10min。3、提高檢測準確率技巧:預訓練、微調本發明通過預訓練和微調手段學習MLeNet模型。首先,利用MNIST數據集預先訓練LeNet模型,然后通過學習到的LeNet參數初始化MLeNet參數。最后,使用隨機梯度下降法微調MLeNet的參數。4、檢測蒙面人人臉利用上面介紹的訓練MLeNet方法,就可以得到一個準確率較高的蒙面人人臉檢測器能夠判斷出給定的窗口中是否存在蒙面人人臉。但是,沒有考慮到多尺度以及檢測窗口重疊問題,所以本發明利用圖像金字塔匹配方案并結合非極大值抑制來后處理此類問題。簡而言之,為了進行金字塔匹配,需要在多尺度圖像不同位置采集目標圖像,每個取樣的圖像放入已訓練好的MLeNet蒙面人人臉檢測器中,MLeNet檢測器就能給每個窗口產生一個是否存在人臉的得分值。然后,利用非極大值抑制融合一些高得分的子窗口,最終,完成檢測。基于一種新的MLeNet模型的蒙面人人臉檢測技術。MLeNet通過引入預訓練及微調(pre-trainingandfine-tuning)等手段,且結合滑動窗口方法,能夠快速且準確地定位蒙面人人臉位置。具體實驗結果如下:隨著社會的發展,科學技術的提高,以及多媒體技術的普及,越來越多的人們在網絡上上傳各種各樣的網絡視頻,其中也包括不少犯罪分子企圖利用多媒體渠道,開始傳播暴力恐怖視頻,這種行為已經在一定程度上影響社會的穩定發展。若能在海量的視頻幀中快速且準確地定位出恐怖分子,將極大地減少人力資源和維護社會穩定。在給定的視頻幀中如何準確定義存在恐怖分子,這是一個困難的問題,因為恐怖分子表現形式多種多樣。通常情況下,恐怖分子都是蒙面的,所以在本發明中,將恐怖分子認為是具有蒙面特征的人。因此,能否準確地定位出蒙面人人臉位置,是判斷出視頻幀中是否存在恐怖分子的關鍵。在給定少量的訓練樣本及蒙面人無法獲取完整人臉結構情況下,傳統的人臉檢測技術無法準確地定位蒙面人人臉位置。人臉檢測是計算機視覺方向一個重要的應用,傳統的人臉檢測算法能夠較為準確地檢測到正面的,無遮擋的人臉,但對于遮擋的,特別是低分辨率,蒙面的情況,得不到良好的檢測效果。在本發明中提出了一種新的模型用于蒙面人人臉檢測,能夠獲得很好的性能,本發明可用于視頻監控、人機交互、暴恐視頻檢索、公共安全等領域。圖3和4給出LeNet模型在給定的蒙面人臉數據集上的性能。圖5和6為沒有預訓練與微調的MLeNet的性能,圖7和8為有預訓練和微調的MLeNet的訓練結果。從實驗的曲線圖可知,加入預訓練及微調等手段訓練出來的MLeNet模型大大提高了蒙面人臉分類結果。在自行創建的蒙面人數據集中檢測蒙面人人臉的實驗結果見表2。從表2中可知,通過加入預訓練及微調等手段的MLeNet模型(即,Ours)相比于傳統的AdaBoost算法、LeNet模型,以及沒有加入預訓練及微調的MLeNet模型,本發明的方法更適合于蒙面人臉檢測問題。表2OursAdaBoost[2]LeNet[11]MLeNetRecall0.9250.750.820.85Precision0.710.60.640.68F1-score0.8030.6670.7190.756“Ours”表示加入預訓練與微調的MLeNet;“MLeNet”表示無預訓練與微調的MLeNet模型。公式說明如下:(定義的公式變量與符號可參考具體公式表達說明)公式(1)定義了模型的損失函數,目的用于衡量模型輸出的結果與原始標簽值的誤差。公式(2)為示性函數的定義,目的用于判斷兩個值是否相等,若相等,則值設為1,反之,則為0。公式(3)定義了隨機梯度下降法的更新規則,其目的為更新每層變量(權重w和偏差b)使得目標損失函數沿著局部最小值方向移動,獲得最終的局部最優解。當前第1頁1 2 3
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1