一種基于動(dòng)作識(shí)別的活體人臉識(shí)別方法及系統(tǒng)與流程
本發(fā)明涉及人臉識(shí)別技術(shù)領(lǐng)域,具體涉及一種基于動(dòng)作識(shí)別的活體人臉識(shí)別及系統(tǒng)。
背景技術(shù):
隨著計(jì)算機(jī)技術(shù)的發(fā)展,人臉識(shí)別的使用越來越廣泛,當(dāng)前,人臉識(shí)別系統(tǒng)越來越多地應(yīng)用于安防、金融領(lǐng)域需要身份驗(yàn)證的場景,如銀行開戶、門禁系統(tǒng)、遠(yuǎn)程交易操作驗(yàn)證等。在這些高安全級(jí)別的應(yīng)用領(lǐng)域,除了確保被驗(yàn)證者的人臉相似度符合數(shù)據(jù)庫中存儲(chǔ)的底庫,還需要對被驗(yàn)證者進(jìn)行活體檢測。現(xiàn)有的人臉識(shí)別系統(tǒng)在進(jìn)行識(shí)別時(shí),有時(shí)會(huì)出現(xiàn)用戶使用照片或預(yù)先拍攝的視頻騙過系統(tǒng)完成驗(yàn)證,此外還需要防范用戶使用3D人臉模型或者面具等方式進(jìn)行欺騙。
目前市場上的技術(shù)產(chǎn)品中還沒有公認(rèn)成熟的活體驗(yàn)證方案,已有的技術(shù)要么依賴特殊的硬件設(shè)備(諸如紅外相機(jī)、深度相機(jī)),要么只能防范簡單的靜態(tài)照片攻擊;另外在一些公開的技術(shù)中通過檢測人臉的動(dòng)態(tài)部位,如果有差異,則視為活體人臉,但此種方法較為被動(dòng),假設(shè)人沒有動(dòng)作,則檢測可能失敗;或者采用設(shè)定序列動(dòng)作,以用戶完成度進(jìn)行活體檢測,此種檢測需要被鑒別人臉部做大量的表情配合動(dòng)作,人機(jī)交互方式不友好,易使用戶產(chǎn)生厭倦感,而且算法復(fù)雜,降低人臉識(shí)別的速度。
技術(shù)實(shí)現(xiàn)要素:
發(fā)明目的:本發(fā)明目的在于針對現(xiàn)有技術(shù)的不足,提供一種基于動(dòng)作識(shí)別的活體人臉識(shí)別方法及系統(tǒng),在不更換硬件設(shè)備的情況下,通過識(shí)別人的動(dòng)作來解決活體人臉識(shí)別問題,且識(shí)別準(zhǔn)確度高。
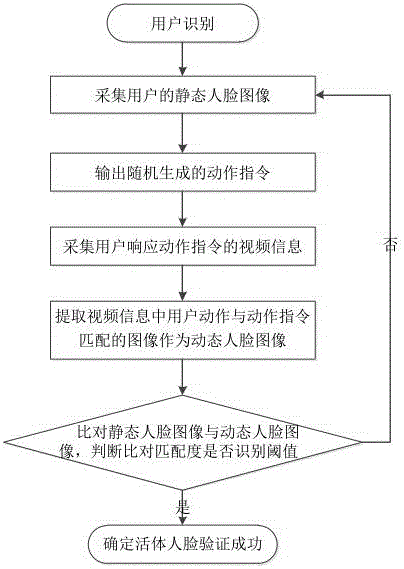
技術(shù)方案:本發(fā)明所述的基于動(dòng)作識(shí)別的活體人臉識(shí)別方法,包括如下步驟:
S11、采集用戶的靜態(tài)人臉圖像;
S12、輸出隨機(jī)生成的動(dòng)作指令;
S13、采集用戶響應(yīng)動(dòng)作指令的視頻信息;
S14、提取視頻信息中用戶動(dòng)作與動(dòng)作指令匹配的圖像作為動(dòng)態(tài)人臉圖像;
S15、比對靜態(tài)人臉圖像與動(dòng)態(tài)人臉圖像,當(dāng)比對匹配度大于識(shí)別閾值,確定活體人臉驗(yàn)證成功,否則驗(yàn)證失敗。
進(jìn)一步完善上述技術(shù)方案,所述步驟S11通過攝像頭即時(shí)拍攝采集用戶的靜態(tài)人臉圖像。
進(jìn)一步地,所述動(dòng)作指令包括朗讀一段文字、眨眼睛、張嘴、舉手中一種或多種動(dòng)作。
進(jìn)一步地,所述步驟S12中輸出隨機(jī)生成的多種動(dòng)作指令;步驟S13中采集用戶響應(yīng)多種動(dòng)作指令的視頻信息;所述步驟S14提取視頻信息中用戶動(dòng)作與每種動(dòng)作指令匹配的圖像,選擇識(shí)別度最高的圖像作為動(dòng)態(tài)人臉圖像。
進(jìn)一步地,所述步驟S13在采集視頻信息過程中進(jìn)行人臉動(dòng)作檢測,若沒有檢測到人臉動(dòng)作,則采集失敗,重新執(zhí)行步驟S12。
進(jìn)一步地,所述步驟S14在提取視頻信息過程中,若沒有提取到用戶動(dòng)作與動(dòng)作指令匹配的圖像,則提取失敗,重新執(zhí)行步驟S12。
本發(fā)明還提供了用于實(shí)現(xiàn)上述方法的基于動(dòng)作識(shí)別的活體人臉識(shí)別系統(tǒng),包括攝像頭、指令輸出模塊、提取模塊、活體認(rèn)證模塊;指令輸出模塊用于輸出動(dòng)作指令,攝像頭用于采集用戶的靜態(tài)人臉圖像和用戶相應(yīng)動(dòng)作指令的視頻信息,提取模塊用于提取視頻信息中的動(dòng)態(tài)人臉圖像,活體認(rèn)證模塊用于比對靜態(tài)人臉圖像和動(dòng)態(tài)人臉圖像,在確定為同一人時(shí)確定活體人臉認(rèn)證成功,否則驗(yàn)證失敗。
有益效果:與現(xiàn)有技術(shù)相比,本發(fā)明的優(yōu)點(diǎn)在于:本發(fā)明在不更換硬件設(shè)備的情況下,通過對比靜態(tài)人臉圖像和動(dòng)態(tài)人臉圖像進(jìn)行活體人臉驗(yàn)證,易于實(shí)現(xiàn),驗(yàn)證準(zhǔn)確率高,采用主動(dòng)式輸出動(dòng)作指令采集活體人臉動(dòng)態(tài)人臉圖像,提高檢測成功率,防止用戶通過預(yù)先拍攝的照片或視頻進(jìn)行欺騙;相對于現(xiàn)有技術(shù)中通過檢測用戶完成動(dòng)作指令序列的驗(yàn)證方法,更易于實(shí)現(xiàn),用戶操作難度更低,同時(shí)保證了驗(yàn)證的識(shí)別率和防欺騙能力。
附圖說明
圖1為本發(fā)明的系統(tǒng)流程圖。
具體實(shí)施方式
下面通過附圖對本發(fā)明技術(shù)方案進(jìn)行詳細(xì)說明,但是本發(fā)明的保護(hù)范圍不局限于所述實(shí)施例。
實(shí)施例1:如圖1所示的基于動(dòng)作識(shí)別的活體人臉識(shí)別方法,包括如下步驟:
S11、靜態(tài)人臉圖像采集:采用攝像頭即時(shí)拍攝采集用戶的靜態(tài)人臉圖像;
S12、輸出動(dòng)作指令“眨眼睛”;
S13、采集用戶響應(yīng)動(dòng)作指令“眨眼睛”的視頻信息,在采集視頻信息過程中進(jìn)行人臉動(dòng)作檢測,若沒有檢測到人臉動(dòng)作,則采集失敗,重新執(zhí)行步驟S12;
S14、提取視頻信息中用戶動(dòng)作與動(dòng)作指令“眨眼睛”匹配的圖像作為動(dòng)態(tài)人臉圖像,若沒有提取到用戶動(dòng)作與動(dòng)作指令“眨眼睛”匹配的圖像,則提取失敗,重新執(zhí)行步驟S12;
S15、比對靜態(tài)人臉圖像與動(dòng)態(tài)人臉圖像,當(dāng)比對匹配度大于識(shí)別閾值,確定活體人臉驗(yàn)證成功,否則驗(yàn)證失敗。
上述方法通過如下系統(tǒng)實(shí)現(xiàn):包括攝像頭、指令輸出模塊、提取模塊、活體認(rèn)證模塊;指令輸出模塊用于輸出動(dòng)作指令,攝像頭用于采集用戶的靜態(tài)人臉圖像和用戶相應(yīng)動(dòng)作指令的視頻信息,提取模塊用于提取視頻信息中的動(dòng)態(tài)人臉圖像,活體認(rèn)證模塊用于比對靜態(tài)人臉圖像和動(dòng)態(tài)人臉圖像,在確定為同一人時(shí)確定活體人臉認(rèn)證成功,否則驗(yàn)證失敗。
如上所述,盡管參照特定的優(yōu)選實(shí)施例已經(jīng)表示和表述了本發(fā)明,但其不得解釋為對本發(fā)明自身的限制。在不脫離所附權(quán)利要求定義的本發(fā)明的精神和范圍前提下,可對其在形式上和細(xì)節(jié)上作出各種變化。
- 還沒有人留言評(píng)論。精彩留言會(huì)獲得點(diǎn)贊!