模型參數優化的方法及裝置與流程
本發明屬于信息技術領域,尤其涉及一種模型參數優化的方法及裝置。
背景技術:
傳統的神經網絡方法會因為采用梯度下降法進行訓練學習而存在易陷入局部最小值的不足,同時,網絡構建過程因為需要對大量的參數進行調整,因此難以建立起最優的模型。為了克服神經網絡的上述缺點,南洋理工大學黃廣斌教授等人提出了一種新的神經網絡學習方法,即極限學習機。然而,由于極限學習機的輸入參數是隨機產生的,會導致模型的性能不穩定;對此,黃廣斌教授等人繼續提出了核極限學習機。核極限學習機不需要隨機設置輸入層和隱藏層的權值,能夠獲得更高的訓練速度,因此得到廣泛應用。
然而,現有的核極限學習機的性能極其容易受到懲罰系數C與核寬γ兩個參數的影響。其中,懲罰系數C用于控制訓練誤差和模型復雜度之間的平衡,核寬γ則定義了從輸入空間到高維特征空間的非線性映射關系。在構造模型時,需要預先確定所述懲罰系數C與核寬γ。現有技術主要利用網格搜索方法確定所述懲罰系數C與核寬γ,然而網格搜索方法容易陷入局部最優的問題,無法得到最優的懲罰系數C與核寬γ,進而影響了模型的分類、預測效果。
技術實現要素:
鑒于此,本發明實施例提供了一種模型參數優化的方法及裝置,以獲取最優的懲罰系數C與核寬γ,提高所構建模型的分類及預測效果。
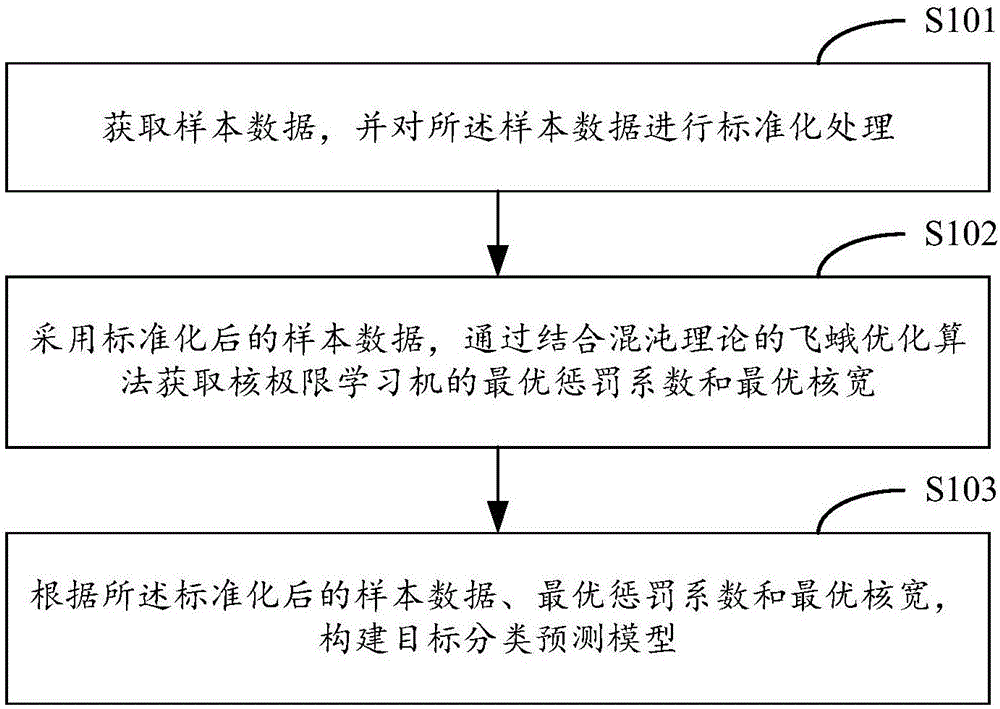
第一方面,提供了一種模型參數優化的方法,所述方法包括:
獲取樣本數據,并對所述樣本數據進行標準化處理;
采用標準化后的樣本數據,通過結合混沌理論的飛蛾優化算法獲取核極限學習機的最優懲罰系數C和最優核寬γ;
根據所述標準化后的樣本數據、最優懲罰系數C和最優核寬γ,構建目標分類預測模型;
其中,所述目標分類預測模型為:
在上式中,s表示待測數據,s1',…,sN'表示標準化后的樣本數據,N表示樣本數,ΩELM為預置的符合Mercer定理構造的核矩陣,O表示目標向量,O=[o1,…,oN],公式K(s,sn')=exp(-γ||s-sn'||2),n∈[1,N]。
進一步地,所述采用標準化后的樣本數據,通過結合混沌理論的飛蛾優化算法獲取核極限學習機的最優懲罰系數C和最優核寬γ包括:
A:初始化最大迭代次數T、飛蛾數量L以及搜索空間,其中所述搜索空間為由懲罰系數C的搜索范圍[Cmin,Cmax]和核寬γ的搜索范圍[γmin,γmax]組成的二維空間;
B:采用混沌映射函數,初始化L只飛蛾中每一只飛蛾在所述搜索空間中的飛蛾位置M'l,其中M'l=(m'l1,m'l2),l∈[1,L];
C:針對每一個飛蛾位置M'l計算其對應的飛蛾的適應度fl;
D:對所有L個飛蛾的適應度fl進行排序以及按照適應度fl的順序對所有的飛蛾位置M'l進行排序,參照排序后的所述適應度fl和飛蛾位置M'l對光源的位置進行更新;
E:根據更新后的光源的位置對所述搜索空間中的每一個飛蛾位置M'l進行更新;
F:采用混沌映射函數對每一個更新后的飛蛾位置M'l進行混沌化處理;
G:判斷當前迭代次數是否達到最大迭代次數T;若是時,從混沌化處理后的飛蛾位置M'l中輸出最優的飛蛾位置M'l_max=(m'l1_max,m'l2_max),以得到最優懲罰系數C和核寬γ;否則,返回步驟C,以計算混沌處理后的飛蛾位置M'l對應的飛蛾的適應度fl,進行下一次迭代運算。
進一步地,所述采用混沌映射函數,初始化L只飛蛾中每一只飛蛾在所述搜索空間中的飛蛾位置M'l包括:
隨機生成第一只飛蛾的位置M1=(m11,m12);
根據所述第一只飛蛾的位置M1=(m11,m12),按照預設的混沌映射函數獲取L-1只飛蛾的位置Ml,其中Ml=(ml1,ml2),l∈(1,L];
按照預設的映射函數將每一只飛蛾的位置Ml映射到所述搜索空間中,得到L個飛蛾位置M'l,其中M'l=(m'l1,m'l2),l∈[1,L];
所述映射函數為M'l=a1+(b1-a1)Ml,其中,所述a1表示搜索范圍[Cmin,Cmax]中的值,b1表示搜索范圍[γmin,γmax]中的值,且a1大于b1。
進一步地,所述針對每一個飛蛾位置M'l計算其對應的飛蛾的適應度fl包括:
遍歷每一個飛蛾位置M'l=(m'l1,m'l2),以所述m'l1作為第l只飛蛾在當前位置時的懲罰系數C,以所述m'l2作為第l只飛蛾在當前位置時的核寬γ,模擬對應的分類預測模型;
將所述標準化后的樣本數據劃分為K折,并將每一折樣本數據輸入至所述分類預測模型中,計算每一折樣本數據對應的學習準確度acck;
計算K折交叉驗證中所獲取的學習準確度acck的平均值,以所述平均值作為所述飛蛾的適應度fl。
進一步地,所述采用混沌映射函數對每一個更新后的飛蛾位置M'l進行混沌化處理包括:
遍歷每一個更新后的飛蛾位置M'l,采用預設的混沌映射函數對更新后的飛蛾位置M'l進行混沌序列化;
通過預設的映射函數將混沌序列化后的飛蛾位置M'l再次映射到所述搜索空間中。
第二方面,提供了一種模型參數優化的裝置,所述裝置包括:
獲取模塊,用于獲取樣本數據,并對所述樣本數據進行標準化處理;
優化模塊,用于采用標準化后的樣本數據,通過結合混沌理論的飛蛾優化算法獲取核極限學習機的最優懲罰系數C和最優核寬γ;
構建模塊,用于根據所述標準化后的樣本數據、最優懲罰系數C和最優核寬γ,構建目標分類預測模型;
其中,所述目標分類預測模型為:
在上式中,s表示待測數據,s1',…,sN'表示標準化后的樣本數據,N表示樣本數,ΩELM為預置的符合Mercer定理構造的核矩陣,O表示目標向量,O=[o1,…,oN],公式K(s,sn')=exp(-γ||s-sn'||2),n∈[1,N]。
進一步地,所述優化模塊包括:
參數初始化單元,用于初始化最大迭代次數T、飛蛾數量L以及搜索空間,其中所述搜索空間為由懲罰系數C的搜索范圍[Cmin,Cmax]和核寬γ的搜索范圍[γmin,γmax]組成的二維空間;
第一混沌處理單元,用于采用混沌映射函數,初始化L只飛蛾中每一只飛蛾在所述搜索空間中的飛蛾位置M'l,其中M'l=(m'l1,m'l2),l∈[1,L];
適應度計算單元,用于針對每一個飛蛾位置M'l計算其對應的飛蛾的適應度fl;
光源更新單元,用于對所有L個飛蛾的適應度fl進行排序以及按照適應度fl的順序對所有的飛蛾位置M'l進行排序,參照排序后的所述適應度fl和飛蛾位置M'l對光源的位置進行更新;
飛蛾位置更新單元,用于根據更新后的光源的位置對所述搜索空間中的每一個飛蛾位置M'l進行更新;
第二混沌處理單元,用于采用混沌映射函數對每一個更新后的飛蛾位置M'l進行混沌化處理;
判斷單元,用于判斷當前迭代次數是否達到最大迭代次數T;若是時,從混沌化處理后的飛蛾位置M'l中輸出最優的飛蛾位置M'l_max=(m'l1_max,m'l2_max),以得到最優懲罰系數C和核寬γ;否則,返回適應度計算單元對混沌處理后的飛蛾位置M'l計算其對應的飛蛾的適應度fl,進行下一次迭代運算。
進一步地,所述第一混沌處理單元包括:
混沌初始化子單元,用于隨機生成第一只飛蛾的位置M1=(m11,m12);根據所述第一只飛蛾的位置M1=(m11,m12),按照預設的混沌映射函數獲取L-1只飛蛾的位置Ml,其中Ml=(ml1,ml2),l∈(1,L];
第一映射子單元,用于按照預設的映射函數將每一只飛蛾的位置Ml映射到所述搜索空間中,得到L個飛蛾位置M'l,其中M'l=(m'l1,m'l2),l∈[1,L];
所述映射函數為M'l=a1+(b1-a1)Ml,其中,所述a1表示搜索范圍[Cmin,Cmax]中的值,b1表示搜索范圍[γmin,γmax]中的值,且a1大于b1。
進一步地,所述適應度計算單元包括:
模擬子單元,用于遍歷每一個飛蛾位置M'l=(m'l1,m'l2),以所述m'l1作為第l只飛蛾在當前位置時的懲罰系數C,以所述m'l2作為第l只飛蛾在當前位置時的核寬γ,模擬對應的分類預測模型;
學習準確度計算子單元,用于將所述標準化后的樣本數據劃分為K折,并將每一折樣本數據輸入至所述分類預測模型中,計算每一折樣本數據對應的學習準確度acck;
適應度計算子單元,用于計算K折交叉驗證中所獲取的學習準確度acck的平均值,以所述平均值作為所述飛蛾的適應度fl。
進一步地,所述第二混沌處理單元包括:
混沌序列化子單元,用于遍歷每一個更新后的飛蛾位置M'l,采用預設的混沌映射函數對更新后的飛蛾位置M'l進行混沌序列化;
第二映射子單元,用于通過預設的映射函數將混沌序列化后的飛蛾位置M'l再次映射到所述搜索空間中。
與現有技術相比,本發明實施例將混沌理論的飛蛾優化算法與核極限學習機進行融合;通過對所獲取樣本數據進行標準化處理;然后采用標準化后的樣本數據,通過結合混沌理論的飛蛾優化算法獲取核極限學習機的最優懲罰系數C和最優核寬γ;最后根據所述標準化后的樣本數據、最優懲罰系數C和最優核寬γ,構建目標分類預測模型;從而解決了現有技術利用網格搜索方法無法得到最優的懲罰系數C與核寬γ的問題,有利于提高所構建模型對指定問題進行分類及預測的效果。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對于本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他附圖。
圖1是本發明實施例提供的模型參數優化的方法的實現流程圖;
圖2是本發明實施例提供的模型參數優化的方法中步驟S102的具體實現流程;
圖3是本發明實施例提供的模型參數優化的裝置的組成結構圖。
具體實施方式
為了使本發明的目的、技術方案及優點更加清楚明白,以下結合附圖及實施例,對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅僅用以解釋本發明,并不用于限定本發明。
本發明實施例將混沌理論的飛蛾優化算法與核極限學習機進行融合;通過對所獲取樣本數據進行標準化處理;然后采用標準化后的樣本數據,通過結合混沌理論的飛蛾優化算法獲取核極限學習機的最優懲罰系數C和最優核寬γ;最后根據所述標準化后的樣本數據、最優懲罰系數C和最優核寬γ,構建目標分類預測模型;從而解決了現有技術利用網格搜索方法無法得到最優的懲罰系數C與核寬γ的問題,有利于提高所構建模型對指定問題進行分類及預測的效果。本發明實施例還提供了相應的裝置,以下分別進行詳細的說明。
圖1示出了本發明實施例提供的模型參數優化的方法的實現流程。
在本發明實施例中,所述模型參數優化的方法應用于計算機、服務器等設備。
參閱圖1,所述模型參數優化的方法包括:
在步驟S101中,獲取樣本數據,并對所述樣本數據進行標準化處理。
在這里,所述樣本數據為與所要構建的目標分類預測模型的應用領域對應的數據集。示例性地,若目標分類預測模型用于乳腺癌疾病智能診斷,則選用乳腺癌數據樣本;若目標分類預測模型用于甲狀腺結節智能診斷,則選用甲狀腺結節數據樣本;此處不做限定。所述樣本數據中包括多個特征屬性值。在獲取到樣本數據之后,對所述樣本數據的各個特征屬性值進行標準化。其中,標準化的公式可以為:
在上式中,si表示樣本數據中的一個特征的屬性值,si'表示屬性值si經標準化處理后的值,smax表示特征的屬性值si對應的樣本數據中的最大值,smin表示特征的屬性值si對應的樣本數據中的最小值。在本發明實施例中,標準化的作用是將所有特征的屬性值都轉換到指定大小范圍內,以避免較大特征值對較小特征值產生的影響,降低分類模型中的計算量。
在步驟S102中,采用標準化后的樣本數據,通過結合混沌理論的飛蛾優化算法獲取核極限學習機的最優懲罰系數C和最優核寬γ。
在這里,飛蛾優化算法相對于網格搜索方法具有更好的搜索能力,其通過模擬飛蛾圍繞著光源螺旋式飛行的行為方式來獲取問題的最優/次優解,然而在面對復雜問題時,飛蛾優化算法容易陷入局部極值不足的問題。而結合混沌理論之后的飛蛾優化算法,則具有了優秀的全局尋代能力,能夠獲得最優的懲罰系數C和最優核寬γ。
可選地,圖2示出了本發明實施例提供的模型參數優化的方法中步驟S102的具體實現流程。
參閱圖2,所述步驟S102包括:
在步驟S201中,初始化最大迭代次數T、飛蛾數量L以及搜索空間,其中所述搜索空間為由懲罰系數C的搜索范圍[Cmin,Cmax]和核寬γ的搜索范圍[γmin,γmax]組成的二維空間。
在步驟S202中,采用混沌映射函數,初始化L只飛蛾中每一只飛蛾在所述搜索空間中的飛蛾位置M'l,其中M'l=(m'l1,m'l2),l∈[1,L]。
本發明實施例將混沌理論引入到飛蛾位置的初始化過程中,首先隨機生成第一只飛蛾的位置M1=(m11,m12);然后根據所述第一只飛蛾的位置M1=(m11,m12),按照預設的混沌映射函數獲取L-1只飛蛾的位置Ml,其中Ml=(ml1,ml2),l∈(1,L]。在這里,所述預設的混沌映射函數包括但不限于Chebyshec map(4)、Logisitc map(5)。在得到每一只飛蛾的位置Ml之后,則按照預設的映射函數將每一只飛蛾的位置Ml映射到所述搜索空間中,得到L個飛蛾位置M'l,其中M'l=(m'l1,m'l2),l∈[1,L]。在這里,所述映射函數為M'l=a1+(b1-a1)Ml,所述a1表示搜索范圍[Cmin,Cmax]中的值,b1表示搜索范圍[γmin,γmax]中的值,且a1大于b1。a1和b1共同限定了懲罰系數C和核寬γ的搜索范圍。所述飛蛾位置M'l中的m'l1表示第l只飛蛾在當前位置時的懲罰系數C,所述m'l2表示第l只飛蛾在當前位置時的核寬γ。
現有技術在隨機生成飛蛾位置時是在一個假設的前提下進行的:即代碼中的隨機函數在理論上服從均勻分布。相比于通過現有技術隨機生成的飛蛾位置,本發明實施例通過采用混沌映射函數初始化所獲得的飛蛾位置,其在數值分布是真正意義上的均勻分布,且分布只是針對初始值敏感性,在初始化開始飛蛾算法的個體就具有了更優的適應度值,基于此能夠有效提高算法的收斂速度。
在步驟S203中,針對每一個飛蛾位置M'l計算其對應的飛蛾的適應度fl。
示例性地,以下以飛蛾位置M'l來說明適應度fl的計算過程,上述步驟S203具體包括:
a、針對飛蛾位置M'l=(m'l1,m'l2),以所述m'l1作為第l只飛蛾在當前位置時的懲罰系數C,以所述m'l2作為第l只飛蛾在當前位置時的核寬γ,模擬對應的分類預測模型;
b、將所述標準化后的樣本數據劃分為K折,并將每一折樣本數據輸入至所述分類預測模型中,計算每一折樣本數據對應的學習準確度acck;
c、計算K折交叉驗證中所獲取的學習準確度acck的平均值,以所述平均值作為所述飛蛾的適應度fl。
在這里,本發明實施例通過根據第l個飛蛾位置M'l=(m'l1,m'l2)模擬出所述飛蛾位置M'l對應的分類預測模型,在所述分類預測模型中,所述m'l1作為懲罰系數C,所述m'l2作為核寬γ。然后將標準化后的樣本數據劃分為K折,以每一折樣本數據作為訓練數據輸入至所述分類預測模型中,計算該折樣本數據對應的學習準確度acck,1≤k≤K。所述學習準確度acck反映了以所述飛蛾位置M'l中的所述m'l1作為懲罰系數C和以所述m'l2作為核寬γ所構建的分類預測模型對第k折樣本數據的學習精度。在獲取到K折樣本數據對應的K個學習準確度acck之后,則求取所述K個學習準確度acck的平均值ACC,即該平均值反映了根據所述飛蛾位置M'l=(m'l1,m'l2)構建的所述分類預測模型的分類精度,即第l只飛蛾的飛蛾的適應度fl。
遍歷L個飛蛾位置,對每一個飛蛾位置執行上述步驟a、b、c,得到L個飛蛾的適應度。
在步驟S204中,對所有L個飛蛾的適應度fl進行排序以及按照適應度fl的順序對所有的飛蛾位置M'l進行排序,參照排序后的所述適應度fl和飛蛾位置M'l對光源的位置進行更新。
在獲取到L個飛蛾的適應度fl之后,則按照由大到小對所述適應度fl進行降序排列,以及按照適應度fl的順序對所有的飛蛾位置M'l進行排序。然后參照排序后的所述適應度fl和飛蛾位置M'l對光源的位置進行更新,即兩代內獲得的飛蛾的適應度fl降序排序后取前n個值作為光源的適應度值,同時將前n個值對應的飛蛾位置作為光源的位置。
在步驟S205中,根據更新后的光源的位置對所述搜索空間中的每一個飛蛾位置M'l進行更新。
在這里,本發明實施例根據公式Dl,j=|Fj-Ml'|計算第l個飛蛾位置到第j個光源之間的距離,其中,Fj表示第j個光源,M'l表示第l個飛蛾位置,Dl,j表示第l個飛蛾位置到第j個光源之間的距離。然后通過公式S(Ml',Fj)=Dl,j·ebt·cos(2·πt)+Fj來更新飛蛾位置M'l,其中,b表示對數螺旋曲線的一個常系數,t表示飛蛾的下一個位置離對應光源的遠近,當t=-1時,表示飛蛾的下一個位置離光源是最近的,當t=1時,表示飛蛾的下一個位置離光源是最遠的。可選地,t的值可以通過公式t=(a-1)*rand+1得到,其中的變量a=-1+I*((-1)/T),I表示當前的迭代次數。
在步驟S206中,采用混沌映射函數對每一個更新后的飛蛾位置M'l進行混沌化處理。
在這里,所述對更新后的飛蛾位置M'l進行混沌化處理具體包括:
遍歷每一個更新后的飛蛾位置M'l,采用預設的混沌映射函數對更新后的飛蛾位置M'l進行混沌序列化;
通過預設的映射函數將混沌序列化后的飛蛾位置M'l再次映射到所述搜索空間中。
其中,所述預設的混沌映射函數包括但不限于Chebyshec map(4)、Logisitc map(5)。所述映射函數為M'l=a1+(b1-a1)Ml,所述a1表示搜索范圍[Cmin,Cmax]中的值,b1表示搜索范圍[γmin,γmax]中的值,且a1大于b1,a1和b1共同限定了懲罰系數C和核寬γ的搜索范圍。
在本發明實施例中,對更新后的飛蛾位置進行混沌化處理,其意義在于:在進行搜索的同時,保證在擇優過程中依然保持飛蛾位置的多樣性,以在全局和局部尋優中,保持一個最佳的平衡,也就是:既要在局部中搜索,也要在全局中搜索,且兩者的度要恰當,以盡可能地獲得最優的懲罰系數C與核寬γ。
在步驟S207中,判斷當前迭代次數是否達到最大迭代次數T。
若是時,執行步驟S208,否則,返回步驟S203,對混沌處理后的飛蛾位置M'l計算其對應的飛蛾的適應度fl,以進行下一次迭代運算。
在步驟S208中,從混沌化處理后的飛蛾位置M'l中輸出最優的飛蛾位置M'l_max=(m'l1_max,m'l2_max),以得到最優懲罰系數C和核寬γ。
本發明實施實施例通過將混沌理論引用到飛蛾優化算法中,使得飛蛾優化算法具有了優秀的全局尋代能力;然后基于結合混沌理論的飛蛾優化算法來優化核極限學習機的兩個關鍵參數,即懲罰系數C和核寬γ,從而得到最優的核極限學習機參數值。
在步驟S103中,根據所述標準化后的樣本數據、最優懲罰系數C和最優核寬γ,構建目標分類預測模型。
在本發明實施例中,所述目標分類預測模型為:
在上式中,s表示待測數據,s1'、…、sN'表示標準化后的樣本數據,N表示樣本數,ΩELM為預置的符合Mercer定理構造的核矩陣,O表示目標向量,O=[o1,…,oN],公式K(s,sn')=exp(-γ||s-sn'||2),n∈[1,N]。
借助所述目標分類預測模型,用戶可以對應用領域范圍內的指定問題進行更準確的分類和預測,能夠有效地輔助相關機構進行科學合理的智能決策。
綜上所述,本發明實施例將混沌理論的飛蛾優化算法與核極限學習機進行融合;通過對所獲取樣本數據進行標準化處理;然后采用標準化后的樣本數據,通過結合混沌理論的飛蛾優化算法獲取核極限學習機的最優懲罰系數C和最優核寬γ;最后根據所述標準化后的樣本數據、最優懲罰系數C和最優核寬γ,構建目標分類預測模型;從而解決了現有技術利用網格搜索方法無法得到最優的懲罰系數C與核寬γ的問題,有利于提高所構建模型對指定問題進行分類及預測的效果。
圖3示出了本發明實施例提供的模型參數優化的裝置的組成結構,為了便于說明,僅示出了與本發明實施例相關的部分。
在本發明實施例中,所述裝置用于實現上述圖1至圖2實施例中所述的模型參數優化的方法,可以是內置與計算機、服務器內的軟件單元、硬件單元或者軟硬件結合的單元。
參閱圖3,所述裝置包括:
獲取模塊31,用于獲取樣本數據,并對所述樣本數據進行標準化處理;
優化模塊32,用于采用標準化后的樣本數據,通過結合混沌理論的飛蛾優化算法獲取核極限學習機的最優懲罰系數C和最優核寬γ;
構建模塊33,用于根據所述標準化后的樣本數據、最優懲罰系數C和最優核寬γ,構建目標分類預測模型;
其中,所述目標分類預測模型為:
在上式中,s表示待測數據,s1'、…、sN'表示標準化后的樣本數據,N表示樣本數,ΩELM為預置的符合Mercer定理構造的核矩陣,O表示目標向量,O=[o1,…,oN],公式K(s,sn')=exp(-γ||s-sn'||2),n∈[1,N]。
在本發明實施例中,所述樣本數據為與所要構建的目標分類預測模型的應用領域對應的數據集。示例性地,若目標分類預測模型用于乳腺癌疾病智能診斷,則選用乳腺癌數據樣本;若目標分類預測模型用于甲狀腺結節智能診斷,則選用甲狀腺結節數據樣本;此處不做限定。所述樣本數據中包括多個特征屬性值。在獲取到樣本數據之后,對所述樣本數據的各個特征屬性值進行標準化。其中,標準化的公式可以為:
在上式中,si表示樣本數據中的一個特征的屬性值,si'表示屬性值si經標準化處理后的值,smax表示特征的屬性值si對應的樣本數據中的最大值,smin表示特征的屬性值si對應的樣本數據中的最小值。在本發明實施例中,標準化的作用是將所有特征的屬性值都轉換到指定大小范圍內,以避免較大特征值對較小特征值產生的影響,降低分類模型中的計算量。
可選地,所述優化模塊32包括:
參數初始化單元321,用于初始化最大迭代次數T、飛蛾數量L以及搜索空間,其中所述搜索空間為由懲罰系數C的搜索范圍[Cmin,Cmax]和核寬γ的搜索范圍[γmin,γmax]組成的二維空間。
第一混沌處理單元322,用于采用混沌映射函數,初始化L只飛蛾中每一只飛蛾在所述搜索空間中的飛蛾位置M'l,其中M'l=(m'l1,m'l2),l∈[1,L]。
適應度計算單元323,用于針對每一個飛蛾位置M'l計算其對應的飛蛾的適應度fl。
光源更新單元324,用于對所有L個飛蛾的適應度fl進行排序以及按照適應度fl的順序對所有的飛蛾位置M'l進行排序,參照排序后的所述適應度fl和飛蛾位置M'l對光源的位置進行更新。
飛蛾位置更新單元325,用于根據更新后的光源的位置對所述搜索空間中的每一個飛蛾位置M'l進行更新。
第二混沌處理單元326,用于采用混沌映射函數對每一個更新后的飛蛾位置M'l進行混沌化處理。
判斷單元327,用于判斷當前迭代次數是否達到最大迭代次數T;若是時,從混沌化處理后的飛蛾位置M'l中輸出最優的飛蛾位置M'l_max=(m'l1_max,m'l2_max),以得到最優懲罰系數C和核寬γ;否則,返回適應度計算單元323對混沌處理后的飛蛾位置M'l計算其對應的飛蛾的適應度fl,進行下一次迭代運算。
可選地,所述第一混沌處理單元322還包括:
混沌初始化子單元3221,用于隨機生成第一只飛蛾的位置M1=(m11,m12);根據所述第一只飛蛾的位置M1=(m11,m12),按照預設的混沌映射函數獲取L-1只飛蛾的位置Ml,其中Ml=(ml1,ml2),l∈(1,L];
第一映射子單元3222,用于按照預設的映射函數將每一只飛蛾的位置Ml映射到所述搜索空間中,得到L個飛蛾位置M'l,其中M'l=(m'l1,m'l2),l∈[1,L];
其中,所述預設的混沌映射函數包括但不限于Chebyshec map(4)、Logisitc map(5)。所述映射函數為M'l=a1+(b1-a1)Ml,所述a1表示搜索范圍[Cmin,Cmax]中的值,b1表示搜索范圍[γmin,γmax]中的值,且a1大于b1。a1和b1共同限定了懲罰系數C和核寬γ的搜索范圍。
可選地,所述適應度計算單元323還包括:
模擬子單元3231,用于遍歷每一個飛蛾位置M'l=(m'l1,m'l2),以所述m'l1作為第l只飛蛾在當前位置時的懲罰系數C,以所述m'l2作為第l只飛蛾在當前位置時的核寬γ,模擬對應的分類預測模型;
學習準確度計算子單元3232,用于將所述標準化后的樣本數據劃分為K折,并將每一折樣本數據輸入至所述分類預測模型中,計算每一折樣本數據對應的學習準確度acck;
適應度計算子單元3233,用于計算K折交叉驗證中所獲取的學習準確度acck的平均值,以所述平均值作為所述飛蛾的適應度fl。
在這里,所述學習準確度acck反映了以所述飛蛾位置M'l中的所述m'l1作為懲罰系數C和以所述m'l2作為核寬γ所構建的分類預測模型對第k折樣本數據的學習精度。在獲取到K折樣本數據對應的K個學習準確度acck之后,則求取所述K個學習準確度acck的平均值ACC,即該平均值反映了根據所述飛蛾位置M'l=(m'l1,m'l2)構建的所述分類預測模型的分類精度,即第l只飛蛾的飛蛾的適應度fl。
可選地,所述光源更新單元324可以按照由大到小對所述適應度fl進行降序排列,以及按照適應度fl的順序對所有的飛蛾位置M'l進行排序。然后參照排序后的所述適應度fl和飛蛾位置M'l對光源的位置和適應度進行更新,即兩代內獲得的飛蛾的適應度fl降序排序后取前n個值作為光源的適應度值,同時將對應的位置作為光源的位置。
可選地,所述飛蛾位置更新單元325可以根據公式Dl,j=|Fj-Ml'|計算第l個飛蛾位置到第j個光源之間的距離,其中,Fj表示第j個光源,M'l表示第l個飛蛾位置,Dl,j表示第l個飛蛾位置到第j個光源之間的距離。然后通過公式S(Ml',Fj)=Dl,j·ebt·cos(2·πt)+Fj來更新飛蛾位置M'l,其中,b表示對數螺旋曲線的一個常系數,t表示飛蛾的下一個位置離對應光源的遠近,當t=-1時,表示飛蛾的下一個位置離光源是最近的,當t=1時,表示飛蛾的下一個位置離光源是最遠的。在這里,t的值可以通過公式t=(a-1)*rand+1得到,其中的變量a=-1+I*((-1)/T),I表示當前的迭代次數。
可選地,所述第二混沌處理單元326還包括:
混沌序列化子單元3261,用于遍歷每一個更新后的飛蛾位置M'l,采用預設的混沌映射函數對更新后的飛蛾位置M'l進行混沌序列化;
第二映射子單元3262,用于通過預設的映射函數將混沌序列化后的飛蛾位置M'l再次映射到所述搜索空間中。
同樣地,所述預設的混沌映射函數包括但不限于Chebyshec map(4)、Logisitc map(5)。所述映射函數為M'l=a1+(b1-a1)Ml,所述a1表示搜索范圍[Cmin,Cmax]中的值,b1表示搜索范圍[γmin,γmax]中的值,且a1大于b1,a1和b1共同限定了懲罰系數C和核寬γ的搜索范圍。
需要說明的是,本發明實施例中的裝置可以用于實現上述方法實施例中的全部技術方案,其各個功能模塊的功能可以根據上述方法實施例中的方法具體實現,其具體實現過程可參照上述實例中的相關描述,此處不再贅述。
綜上所述,本發明實施例將混沌理論的飛蛾優化算法與核極限學習機進行融合;通過對所獲取樣本數據進行標準化處理;然后采用標準化后的樣本數據,通過結合混沌理論的飛蛾優化算法獲取核極限學習機的最優懲罰系數C和最優核寬γ;最后根據所述標準化后的樣本數據、最優懲罰系數C和最優核寬γ,構建目標分類預測模型;從而解決了現有技術利用網格搜索方法無法得到最優的懲罰系數C與核寬γ的問題,有利于提高所構建模型對指定問題進行分類及預測的效果。
本領域普通技術人員可以意識到,結合本文中所公開的實施例描述的各示例的單元及算法步驟,能夠以電子硬件、或者計算機軟件和電子硬件的結合來實現。這些功能究竟以硬件還是軟件方式來執行,取決于技術方案的特定應用和設計約束條件。專業技術人員可以對每個特定的應用來使用不同方法來實現所描述的功能,但是這種實現不應認為超出本發明的范圍。
所屬領域的技術人員可以清楚地了解到,為描述的方便和簡潔,上述描述的裝置和單元的具體工作過程,可以參考前述方法實施例中的對應過程,在此不再贅述。
在本申請所提供的幾個實施例中,應該理解到,所揭露的方法及裝置,可以通過其它的方式實現。例如,以上所描述的裝置實施例僅僅是示意性的,例如,所述模塊、單元的劃分,僅僅為一種邏輯功能劃分,實際實現時可以有另外的劃分方式,例如多個單元或組件可以結合或者可以集成到另一個系統,或一些特征可以忽略,或不執行。另一點,所顯示或討論的相互之間的耦合或直接耦合或通信連接可以是通過一些接口,裝置或單元的間接耦合或通信連接,可以是電性,機械或其它的形式。
所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位于一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部單元來實現本實施例方案的目的。
另外,在本發明各個實施例中的各功能單元、模塊可以集成在一個處理單元中,也可以是各個單元、模塊單獨物理存在,也可以兩個或兩個以上單元、模塊集成在一個單元中。
所述功能如果以軟件功能單元的形式實現并作為獨立的產品銷售或使用時,可以存儲在一個計算機可讀取存儲介質中。基于這樣的理解,本發明的技術方案本質上或者說對現有技術做出貢獻的部分或者該技術方案的部分可以以軟件產品的形式體現出來,該計算機軟件產品存儲在一個存儲介質中,包括若干指令用以使得一臺計算機設備(可以是個人計算機,服務器,或者網絡設備等)執行本發明各個實施例所述方法的全部或部分步驟。而前述的存儲介質包括:U盤、移動硬盤、只讀存儲器(ROM,Read-Only Memory)、隨機存取存儲器(RAM,Random Access Memory)、磁碟或者光盤等各種可以存儲程序代碼的介質。
以上所述,僅為本發明的具體實施方式,但本發明的保護范圍并不局限于此,任何熟悉本技術領域的技術人員在本發明揭露的技術范圍內,可輕易想到變化或替換,都應涵蓋在本發明的保護范圍之內。因此,本發明的保護范圍應所述以權利要求的保護范圍為準。
- 還沒有人留言評論。精彩留言會獲得點贊!