基于熵的數據價值衡量與定價方法與流程
本發明涉及信息服務技術領域,具體地,涉及基于熵的數據價值衡量與定價方法。
背景技術:
近年來,信息商品的交易和無線網絡的使用正在經歷一個巨大的增長。人們對于高質量,可信賴的信息商品的需求與日俱增。信息商品的交易量逐年遞增,此類交易服務多數由各大數據提供平臺(諸如Microsoft Azure Data Marketplace,Inforchimp等)所提供。這些數據提供平臺不僅出售數據和信息商品,同時還搭配出售與數據相關的分析和存儲服務。但是,至今在這些平臺上,仍然沒有一個統一的、明確的信息商品定價策略,這阻礙了信息商品交易的進一步發展。如今,主流的或者被廣泛研究的定價策略有三種:
訂閱制(Subscription)策略:
訂閱制是一種傳統的信息商品定價策略。在那些使用該策略的數據交易平臺,如Microsoft Azure Data Marketplace,數據購買者并不會真正擁有數據,而是每月繳納一定的費用,從而獲得訪問該數據平臺上相應數據的權利。比如在Azure平臺,數據商品分為兩大類:無限制訂閱型和有限制訂閱型。無限制訂閱型數據商品是指用戶在每月繳納一定費用后,可以無限制次數地訪問該數據商品。而有限制訂閱型數據商品是指用戶在每月繳納一定費用后,只能有限次數地訪問該數據商品。繳費是月結制,即每月用完訪問次數或者使用時間已到,就只能到下個月重新繳費再獲得數據訪問權。雖然,對于數據交易平臺來說,這種定價策略易于實現,但是如果沒有設計好商品價格水平的話,會容易出現套利現象,從而導致平臺利益受損。
基于查詢(Query)的定價策略:
基于查詢的定價策略是收到SQL關系數據庫的啟發。其交易流程是數據購買者對于自己想要的數據商品,向數據交易平臺發起一個查詢(Query)。數據交易平臺根據該查詢將指定數據集的視窗(View)作為結果返回給購買者。其交易費用是由交易平臺根據查詢復雜度而制定。然而,比較難的是找到一個精確度量查詢復雜度的函數,從而比較難制定出交易費用。
捆綁以及區別定價(Bundling and Discrimination)策略:
捆綁定價策略是來自于資本數據交易市場。在資本數據交易市場,數據提供者常常將多種信息商品捆綁在一起,并對不同層次的消費者收取不同的費用。因此,這種定價策略就會產生價格歧視效應。這種定價策略只有在捆綁銷售中單個商品之間是呈負相關關系時才會有效,不同的購買者才會愿意以不同的價格購買該捆綁商品。但是如今大多數信息商品都是非文本的數值數據(離散型的或者連續型的),人們不容易直觀地發現這些數據間的相關程度。另外,如今也沒有一個量化的方法來度量數據商品中的信息量。因此,數據生產商們也很難對自己的數據商品進行一個合理定價,因此更無法有效地捆綁出售自己的產品。
技術實現要素:
針對現有技術中的缺陷,本發明的目的是提供一種基于熵的數據價值衡量與定價方法。
根據本發明提供的基于熵的數據價值衡量與定價方法,包括如下步驟:
步驟1:定義數據商品新型的價格函數;
步驟2:將數據集抽象成為數據矩陣;
步驟3:從數據集的行和屬性兩個角度來度量數據集的信息量,獲得數據集的定價策略。
優選地,所述步驟1包括:令數據的價格P是數據信息熵H的函數,記為:
P=f(H) (1)
將一個擁有n個可能的值,記為{x1,x2,…,xn}和概率分布函數為p(X)的離散變量X的熵定義為H(X):
式中:p(xi)表示取xi值時的概率;當存在兩個離散變量X,Y,且分別對應有n和m個可能的輸出值,記為{x1,x2,…,xn},{y1,y2,…,ym},則定義X,Y的聯合概率分布函數p(X,Y),采用聯合熵來度量X,Y所共同擁有的信息量,定義為H(X,Y):
式中:p(xi,yj)表示輸出值xi,yj同時出現的聯合概率;n和m為正整數。
優選地,所述步驟2包括:
步驟2.1:將擁有n行記錄m列屬性的數據集抽象成為一個n×m的數據矩陣X,記為:
令ri=(xi1xi2…xim),ri表示第i條記錄,對應于矩陣X的第i行;其中i=1,2,…,n;矩陣X的第j列屬性記為:其中j=1,2,…,m。
優選地,所述步驟3包括:
步驟3.1:基于屬性的數據集信息度量;
對于單個屬性cj,共有k個可能的值記為利用信息熵來度量屬性cj所含有的信息量:
其中,
式中:H(cj)表示第j個屬性的信息熵,表示第j個屬性中第i個值出現的概率,表示第j個屬性的第i個值,xij表示數據集中第i行第j列的值,表示xij是否等于
當數據集中有多個屬性需要度量時,采用聯合熵,具體地,定義一個屬性集合所述屬性集合Sk的基于屬性的信息量定義為多個屬性的聯合熵:
式中:Hc(Sk)表示k個屬性組成的集合的信息熵,表示在這個屬性集合中第k個屬性,表示這k個屬性組成的信息熵的聯合熵;聯合公式
2、公式5、公式6求解公式7所定義的多屬性的聯合熵;
步驟3.2:基于行的數據集信息度量;將擁有n行記錄m個屬性的數據集X基于行的信息量定義為:
式中:ri表示第i個數據集中的一條記錄;Hr(X)表示數據子集X的信息熵,p(ri)表示第i條記錄出現的概率,
假設在數據交易平臺中,給定一個數據集D,數據購買者可能購買整個數據集D,也可能只購買數據集D的子集S,其中子集S可以就是數據集D本身;則基針對數據子集S給出如下定價策略如下:
式中,compensate(D)表示數據平臺為獲得數據集D所需要向數據擁有者支付的費用,h(D)表示數據集D在整個數據平臺中的熱度,Price(S)表示欲購買數據子集S的價格,Hr(S)表示S的信息熵,Hr(D)表示數據集D的信息熵,h(D)表示數據集D在數據平臺中的熱度;其中:
式中,click(D)表示該平臺下數據集D點擊瀏覽的次數,click(Di)表示該平臺下數據集Di點擊瀏覽的次數;Di表示數據平臺中第i個數據集;公式10中分子表示該數據集被點擊的次數,分母表示該平臺下所有數據集被點擊瀏覽的次數,從而來表示數據集D在整個數據交易平臺中的熱門程度。
與現有技術相比,本發明具有如下的有益效果:
本發明提供的基于熵的數據價值衡量與定價方法適用性強,數據交易平臺只需要收集數據集的瀏覽點擊次數和為獲得該數據集支付的成本費用等信息,便可根據本發明中給出的定價方法進行定價;通過大量的實驗發現,本發明的度量方法與分類正確率有較高的正相關性,因此本發明的定價策略相較于傳統方法更加可靠,且具有較高的針對性。
附圖說明
通過閱讀參照以下附圖對非限制性實施例所作的詳細描述,本發明的其它特征、目的和優點將會變得更明顯:
圖1為某一數據集的記錄示意圖;
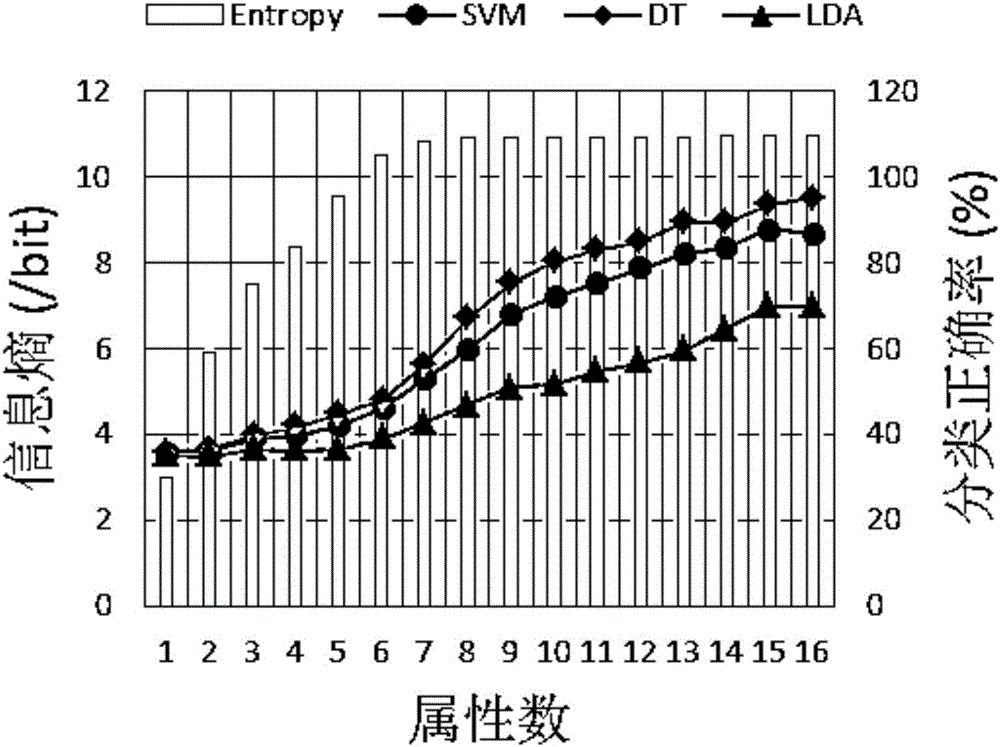
圖2為Letter數據集上的分類正確率與基于屬性的信息熵的關系示意圖;
圖3為在Mushroom數據集上的分類正確率與基于屬性的信息熵的關系示意圖;
圖4為在Ecoli數據集上的分類正確率與基于屬性的信息熵的關系示意圖;
圖5為在Vehicle數據集上的分類正確率與基于屬性的信息熵的關系示意圖;
圖6為在Letter數據集上的分類正確率與基于行的信息熵的關系示意圖;
圖7為在Mushroom數據集上的分類正確率與基于行的信息熵的關系示意圖;
圖8為在Ecoli數據集上的分類正確率與基于行的信息熵的關系示意圖;
圖9為在Vehicle數據集上的分類正確率與基于行的信息熵的關系示意圖。
具體實施方式
下面結合具體實施例對本發明進行詳細說明。以下實施例將有助于本領域的技術人員進一步理解本發明,但不以任何形式限制本發明。應當指出的是,對本領域的普通技術人員來說,在不脫離本發明構思的前提下,還可以做出若干變化和改進。這些都屬于本發明的保護范圍。
針對現今數據交易平臺沒有一個精確度量數據商品信息量的方法的問題,本發明提出了一種基于熵的數據價值衡量與定價方法。然后基于該度量方法,為數據交易平臺提出一種數據定價機制,即數據的價格P是數據信息熵H的函數,記為:
P=f(H)(1)
信息論由香濃提出,最初是用來測量信息內容的不確定性的。其中最基本的概念熵(Entropy),將一個擁有n個可能的值,記為{x1,x2,…,xn}和概率分布函數為p(X)的離散變量X的熵定義為H(X):
式中:p(xi)表示取xi值時的概率;而如果是兩個離散變量X,Y,它們分別有n和m個可能的輸出值,記為{x1,x2,…,xn},{y1,y2,…,ym},以及相應的聯合概率分布函數p(X,Y)。那么可以采用聯合熵(Joint Entropy)來度量它們所共同擁有的信息量,其定義為H(X,Y):
式中:p(xi,yj)表示xi,yj同時出現的聯合概率;上述聯合熵可以擴展應用到多個離散變量的信息度量。除此以外,上述兩種熵也都可以從離散變量的信息度量擴展到連續變量的信息度量,即只需要把求和符號換成積分符號。
一個數據集會有多列屬性,每個屬性又會出現多個不同的值。而一條記錄又是由不同屬性的值所組成,如圖1所示,通常會把一個擁有n行記錄m列屬性的數據集抽象成為一個n×m的數據矩陣X:
而第i條記錄對應于矩陣X的某一行ri=(xi1xi2…xim),其中i=1,2,…,n。而第j列屬性則對應于矩陣X的某一列其中j=1,2,…,m。基于上述兩種信息熵,從數據集的行和屬性兩個角度來度量其的信息量。
1)基于屬性的數據集信息度量
對于單個屬性cj,共有k個可能的值記為那么可以直接利用信息熵來度量其所含有的信息量:
其中,
式中:H(cj)表示cj的信息熵,表示值出現的概率,表示第j個屬性的第i個值,xij表示數據集中第i行第j列的值,表示xij是否等于而對于數據集中多個屬性的信息量度量就更加復雜一些,這就需要使用到聯合熵。定義一個屬性集合那么該屬性集合Sk的基于屬性的信息量定義為多個屬性的聯合熵:
式中:Hc(Sk)表示屬性集合Sk的信息熵,表示屬性集合Sk第k個屬性;聯合式子(2)(5)(6)便可求出式子(7)所定義的多屬性的聯合熵。值得注意的是,在一個共有m個屬性的數據集中,屬性個數為k的屬性子集共有個。
在捆綁和區別定價策略中,若將整個數據集看做一個待銷售的捆綁商品,那么各個屬性便是欲捆綁銷售的單個商品,式子(4)已經給出如何度量單個屬性信息量的方法。式子(7)給出了如何度量多個屬性組成的屬性集合的信息量的方法。但是在真實應用場景中,是不可能去計算所有屬性子集的信息量。比如一個擁有m個屬性的數據集,其共有2m個屬性子集,計算出所有屬性子集的信息熵的代價是巨大的。因此,推薦的方式是對于每個屬性個數k,從其個屬性子集中選取信息熵最大的屬性子集作為該屬性個數的屬性子集代表。那么,最后就一共就會給出m個屬性子集及其信息熵。
2)基于行的數據集信息度量
基于行的數據集信息度量可以看成是基于屬性的數據集信息度量的一個特例,即當屬性個數k=m時。一個擁有n行記錄m個屬性的數據集X,其基于行的信息量定義為:
式中:ri表示第i個數據集中的一條記錄;Hr(X)表示數據集X的信息熵,p(ri)表示第i條記錄出現的概率,盡管基于行的信息度量是基于列的信息度量的一種特烈,但是前者能從更加宏觀的角度來度量一個數據集的信息分布。
假設在數據交易平臺中,給定一個數據集D,數據購買者可能購買整個數據集D,也可能只購買數據集D的子集S(子集S可以就是數據集D本身),基于上述兩種數據度量方式,針對數據子集S給出如下定價策略:
式中,compensate(D)表示數據平臺為獲得數據集D所需要向數據擁有者支付的費用,h(D)表示數據集D在整個數據平臺中的熱度,Price(S)表示欲購買數據子集S的價格,Hr(S)表示S的信息熵,Hr(D)表示數據集D的信息熵,h(D)表示數據集D在數據平臺中的熱度;其中:
式中,click(D)表示該平臺下數據集D點擊瀏覽的次數,click(Di)表示該平臺下數據集Di點擊瀏覽的次數;Di表示數據平臺中第i個數據集;(10)式中分子表示該數據集被點擊的次數,分母表示該平臺下所有數據集被點擊瀏覽的次數,從而來表示該數據集在整個數據交易平臺中的熱門程度。因為子集S可以就是數據集D本身,那么上述定價公式(9)也是可以用來為數據集D來定價的。
下面結合具體實施例對本發明中的技術方案做更加詳細的說明。
本實施例分別選取了2個離散型有類標數據集和2個連續型有類標數據集作為測試集,數據集詳細信息見表1。分別對提出的兩個信息度量方法進行了實驗。
表1 實驗中所用到數據集的詳細信息
其中,基于屬性的信息度量方法的實驗流程如下:
1)對于一個給定的數據集,其有m個屬性,采用樸素遍歷的方法生成m個具有最大聯合熵的數據子集,并記錄其相應的聯合熵;
2)對于生成的m個屬性子集,分別用SVM、DT和LDA三個分類器采取10折交叉驗證法進行分類測試,并記錄相應數據子集的相應分類器的分類正確率;
3)比較相應數據子集的聯合熵和其相應的三個分類器的分類正確率,并繪圖。詳細實驗結果如圖2、圖3、圖4、圖5所示。
而基于行的信息度量方法的實驗流程如下:
1)對于一個給定的數據集,其共有n行記錄。按照原數據集記錄條數的10%,20%,30%,40%,50%,60%,70%,80%,90%從原始數據集中隨機挑選記錄生成9個不同大小的數據子集;
2)對于生成的9個數據子集,分別用SVM、DT和LDA三個分類器采取10折交叉驗證法進行分類測試,并記錄相應數據子集的相應分類器的分類正確率;
3)比較相應數據子集的基于行的信息熵和其相應的三個分類器的分類正確率,并繪圖;詳細實驗結果如圖6、圖7、圖8、圖9所示。
接下來,基于上述測出的信息熵,并假設我們作為數據交易平臺已經獲得上述四個數據集的所有相關信息(瀏覽點擊次數,獲得相應數據及的成本費用等),給出具體的計算實例,計算結果見表2:
表2 數據集定價計算結果
在機器學習的監督學習里,根據大量實驗經驗,如果對分類器輸入的有效訓練信息越多,那么分類器的分類正確率就會越高。即分類正確率往往與有效信息量是成正比的。因此,通過研究分類器正確率與我們的信息度量方法的相關性,來證明本發明提出的信息度量方法是有效的和合理的。首先根據提出的度量方法計算出一些數據集及其相應子集的信息熵,然后用三個主流的分類器:支持向量機(Support Vector Machine,SVM)、決策樹(Decision Tree,DT)和線性判別法(Linear Discriminative Analysis,LDA)來測試這些數據集和其子集,記錄分類器的分類正確率。通過大量的實驗發現,本發明的度量方法與分類正確率有較高的正相關性,這也就說明了本發明的度量方法是合理有效的。
數據交易平臺只需要收集數據集的瀏覽點擊次數和為獲得該數據集支付的成本費用等信息,便可根據本發明中給出的定價方法進行定價。
以上對本發明的具體實施例進行了描述。需要理解的是,本發明并不局限于上述特定實施方式,本領域技術人員可以在權利要求的范圍內做出各種變化或修改,這并不影響本發明的實質內容。在不沖突的情況下,本申請的實施例和實施例中的特征可以任意相互組合。
- 還沒有人留言評論。精彩留言會獲得點贊!