基于語義分析與多重Simhash的文本近似重復檢測方法與流程
本發明涉及一種文本重復檢測方法,尤其涉及一種基于語義分析與多重Simhash的文本近似重復檢測方法。
背景技術:
在數據挖掘和知識信息發現領域,隨著大規模數據噴涌而出而來的一大挑戰就是過多的重復信息。國外有關研究表明,有1.7%~7%的重復網頁充斥在互聯網環境中。這種問題在中國互聯網環境中更為突出,中國互聯網環境尚未成熟,版權保護機制與網民素養尚未完善,很多信息都被大量的剽竊和轉載,據有關統計,中國互聯網絡中有超過30%的重復頁面。而重復信息太多也是互聯網信息檢索中遇到的主要問題之一。
與網頁重復檢測相比,文本重復檢測更加困難,這是由于語法、句式以及詞語含義的多變性,而中文的復雜語言結構更是給重復檢測增加了困難。近似重復的相關研究,已經有十余年的歷史,其大多數是針對英文網頁重復設計的。根據其相似匹配位于的階段不同,可以簡單分為兩類,一類是單純兩兩根據文本信息直接進行相似匹配,另一種是將每個文檔的信息生成一個指定長度的編碼(一般是64位),只通過這個編碼來進行相似匹配,這種方式稱為指紋算法。
然而目前絕大多數算法均是針對幾乎完全相同的文章,而對于詞的替換、句式的變換、或者保證原文含義不變的情況下重寫等近似重復問題效果一般。因此在實際應用上具有一定的局限性。
技術實現要素:
本發明的目的在于針對現有技術的局限和不足,提供一種基于語義分析與多重Simhash的文本近似重復檢測方法。
本發明的目的是通過以下技術方案來實現的:一種基于語義分析與多重Simhash的文本近似重復檢測方法,利用詞語的詞性和統計特征選擇文本的關鍵詞,在關鍵詞周圍選取詞作為文本特征,對同義詞進行編碼,消除同義詞,利用文本特征和全文分別計算Simhash,利用多重Simhash檢測文檔重復;具體包括以下步驟:
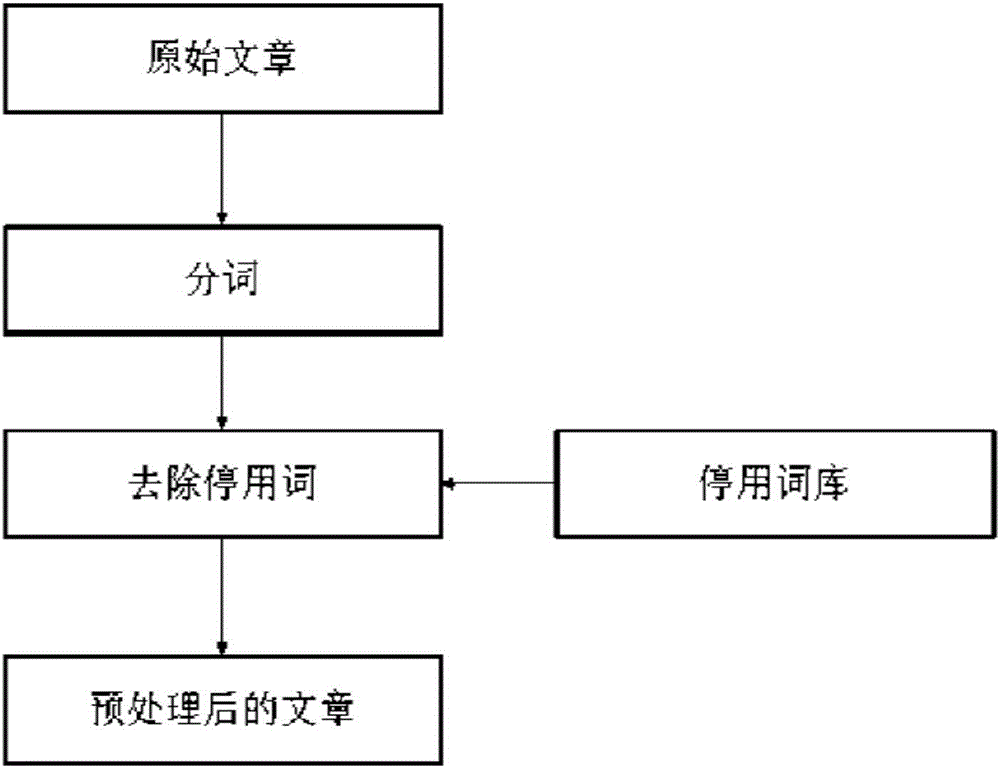
(1)對中文文章進行預處理:將原始文本進行分詞、去除停用詞處理,余下的詞稱為文章的實義詞;
(2)選取關鍵詞:以tfidf、詞性、詞長、詞首次出現的位置計算每個實義詞的權重,選取權重最高的N1個詞作為關鍵詞。N1的取值范圍為[5,15]。
詞的權重計算方式為:
其中wi表示文檔中第i個詞,tfidfi表示這個詞的tfidf,len(x)表示x(文檔或詞)的長度,posi表示詞首次出現的位置,proi表示詞性的權重指標,proi的取值范圍為[0,1]。λ1~λ4為不同指標的權重,且滿足λ1>λ2<λ4>λ3。
表示詞性的權重指標。為不同指標的權重的取值范圍為(3)選取關鍵詞每次出現位置前后各N2個詞作為文本特征,若關鍵詞出現位置前或后不足N2個詞,則取到文首或文尾為止。N2的取值范圍為[6,14]。
(4)預先統計好常用的同義詞,并對詞進行編碼,同一個含義的詞編碼相同,不同含義的詞編碼不同,但編碼長度相同。找到特征中所有有同義詞的詞,并將其替換為對應的編碼。
(5)根據文章的全部實義詞計算Simhash記為simhash_1,根據文本特征計算Simhash記為simhash_2。
(6)計算兩篇文章的simhash_1的海明距離,記為D1,計算兩篇文章的simhash_2的海明距離記為D2。若D1≤k1,或k1<D1≤k2且D2≤k1,則認為兩篇文章近似重復。其中k1的取值范圍為[1,3],k2的取值范圍為[5,7]。
進一步地,所述步驟2中,對于不同詞性的詞對應的proi滿足:
a.若wi為名詞,則proi>0.5
b.若wi為名詞,wj為形容詞,則proi>=1.5proj
c.若wi為名詞,wj為動詞,則proi>=2proj
d.若wi為形容詞,wj為動詞,則proi>proj
e.若wi為動詞,wj為其它詞性的詞,則proi>2proj。
本發明的有益效果是:本發明引入了語法、句法、語義等信息,首先根據多因素綜合考慮詞的重要性而獲得文章的關鍵詞,然后創新地提出以關鍵詞前后一定數目的詞為文章特征,并以此計算SimHash,在處理語義的問題上,我們通過同義詞替換的方法來消除同義詞,然而這種方法比較激進,因此一定程度上降低了準確率,因此我們采用二重SimHash的方法,即只有在一定范圍內才會使用這種激進的計算方式,結果表明改進的檢測方法要比傳統的SimHash、Shingling等方法效果更優。
附圖說明
圖1是原始文章預處理的示意圖;
圖2是選取文章關鍵詞的示意圖;
圖3是文章特征選取以及計算Simhash的示意圖;
圖4是判斷兩篇文章是否近似重復的示意圖;
圖5是本發明方法與傳統的SimHash、Shingling方法的比較結果示意圖。
具體實施方式
下面結合附圖詳細描述本發明,本發明的目的和效果將變得更加明顯。
本發明提供的一種基于語義分析與多重Simhash的文本近似重復檢測方法,包括以下步驟:
(1)對中文文章進行預處理:將原始文本進行分詞、去除停用詞處理,余下的詞稱為文章的實義詞;
(2)選取關鍵詞:以tfidf、詞性、詞長、詞首次出現的位置計算每個實義詞的權重,選取權重最高的N1個詞作為關鍵詞。N1的取值范圍為[5,15]。
詞的權重計算方式為:
其中wi表示文檔中第i個詞,tfidfi表示這個詞的tfidf,len(x)表示x(文檔或詞)的長度,posi表示詞首次出現的位置,proi表示詞性的權重指標。λ1~λ4為不同指標的權重。
proi的取值范圍為[0,1],對于不同詞性的詞對應的proi滿足:
a.若wi為名詞,則proi>0.5
b.若wi為名詞,wj為形容詞,則proi>=1.5proj
c.若wi為名詞,wj為動詞,則proi>=2proj
d.若wi為形容詞,wj為動詞,則proi>proj
e.若wi為動詞,wj為其它詞性的詞,則proi>2proj。
不同指標的權重滿足λ1>λ2>λ4>λ3。
(3)選取關鍵詞每次出現位置前后各N2個詞作為文本特征,若關鍵詞出現位置前或后不足N2個詞,則取到文首或文尾為止。N2的取值范圍為[6,14]。
(4)預先統計好常用的同義詞,并對詞進行編碼,同一個含義的詞編碼相同,不同含義的詞編碼不同,但編碼長度相同。找到特征中所有有同義詞的詞,并將其替換為對應的編碼。
(5)根據文章的全部實義詞計算Simhash記為simhash_1,根據文本特征計算Simhash記為simhash_2。
(6)計算兩篇文章的simhash_1的海明距離,記為D1,計算兩篇文章的simhash_2的海明距離記為D2。若D1≤k1,或k1<D1≤k2且D2≤k1,則認為兩篇文章近似重復。其中k1的取值范圍為[1,3],k2的取值范圍為[5,7]。
實施例
本實施例以2162篇IT新聞文章作為原始文本,具體實施方式如下:
(1)對中文文章進行預處理:如圖1所示,將原始文本進行分詞、去除停用詞處理,余下的詞為實義詞。
(2)選取關鍵詞:如圖2所示,以tfidf、詞性、詞長、詞首次出現的位置計算每個實義詞的權重,選取權重最高的10個詞作為關鍵詞。詞的權重通過如下公式計算:
參數選取如下:
若wi為名詞,則proi取0.6,若wi為形容詞,則proi取0.4,若wi為動詞,則proi取0.3,若wi為其他詞性的詞,則proi取0.1;
tfidf權重λ1取0.8;
詞性權重λ2取0.5;
詞長權重λ3取0.05;
首次出現位置權重λ4取0.1;
(3)如圖3所示,選取關鍵詞每次出現位置前后各10個詞作為文本特征。預先統計好常用的同義詞,并對詞進行編碼,同一個含義的詞編碼相同,不同含義的詞編碼不同,但長度相同。之后根據文章的全部實義詞計算Simhash記為simhash_1,根據文本特征計算Simhash記為simhash_2。
(4)判斷兩篇文章是否重復的方法如圖4所示,計算兩篇文章的simhash_1的海明距離,記為D1,計算兩篇文章的simhash_2的海明距離記為D2。若0≤D1≤2,或2<D1≤6且0≤D2≤2,則認為兩篇文章近似重復。
本實施例中按照上述參數設定實施,稱為Simhash_New,其重復檢測結果與Simhash、Shingling兩種方法的檢測結果對比如圖5所示,結果表明,本發明方法在準確率、召回率、f值三個指標上均顯著高于Simhash、Shingling方法。證明了本發明方法在中文文本近似重復檢測問題上具有更好的效果。
- 還沒有人留言評論。精彩留言會獲得點贊!