數據分層存儲方法及系統與流程
本發明涉及通信領域,且特別涉及一種數據分層存儲方法及系統。
背景技術:
隨著云計算和容器化技術的發展,容器技術已經廣泛的應用在各個領域,而容器技術的核心是鏡像,鏡像的存儲對于業務的正常運行起著非常關鍵的作用。現有的容器鏡像數據存儲技術在磁盤介質管理上采用的是“靜態”存儲技術,即在固定的磁盤陣列中劃分卷,再對數據進行存儲,從而使得很多用戶在部署實施分層技術后發現,整體IOPS(Input/Output Operations Per Second)性能依然與傳統架構相當,即磁盤吞吐能力并未獲得大幅提升。
同時,現有的容器鏡像數據存儲技術從存儲系統的底層考慮,對應用數據的存放成本進行了優化,使得需要高存取性能的數據能夠存放在讀寫性能高的磁盤介質,海量低訪問頻率的數據存放在低成本大容量的低轉速磁盤。但是對于數據的存儲性能類型的辨別,需要使用人為的方式,通過人為辨別之后,再將數據存儲到對應的磁盤介質中。現有容器鏡像數據存儲系統架構圖如圖1所示。圖1中的標記具體為:互聯網1000、管理員2000、交換機3000、磁盤陣列組4000。從圖1中可以看出,當讀寫數據時,可以人為的判斷數據是冷數據(訪問率低的數據)或熱數據(訪問率高的數據),進而把不同類型的數據存儲在性不同的磁盤中,方便用戶的下次讀取,這樣可以加快數據的讀取速度,保障一些業務功能能夠高效的運行。
在現有的方法中需要人為的對數據進行判斷,當出現大量的讀寫操作時人為決策較為困難,并對存儲設備造成壓力,不能及時響應。人為對冷數據和熱數據時考慮的因素較為單一,沒有考慮數據與數據是相互影響的關系,數據的區分存在不準確性,當需要讀取冷數據時,無法快速的響應需求從而導致上線業務不能正常運行,用戶感知較差。當發生以上問題時,只能通過管理員進行被動故障處理,對數據庫或者存儲設備進行修正。嚴重時,導致存儲系統宕機,需要重新啟動,這對于核心系統來說是不可接受的。此外,人為操作需要投入大量的人力成本,造成資源的浪費。
進一步的,現有的容器鏡像數據存儲技術應用數據卷(LUN)與磁盤陣列(RAID)組形成映射關系,RAID組中磁盤的性能會影響該數據卷的數據存取性能,使其成為瓶頸問題,且數據卷一旦創建,所有歸屬于該卷的數據RAID架構即被固定,不能改變。
技術實現要素:
本發明為了克服現有數據存儲技術不能智能地且準確地區分數據的冷熱的問題,提供一種能自動準確地檢測數據的冷熱度并根據數據的冷熱度進行自動分層存儲的數據分層存儲方法及系統。
為了實現上述目的,本發明提供一種數據分層存儲方法,該方法包括:
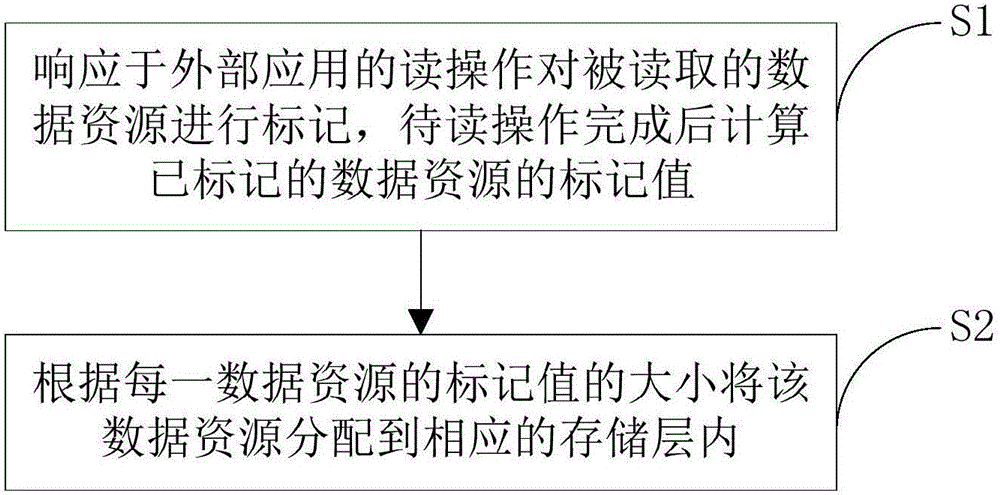
響應于外部應用的讀操作對被讀取的數據資源進行標記,待讀操作完成后計算已標記的數據資源的標記值;
根據每一數據資源的標記值的大小將該數據資源分配到相應的存儲層內。
于本發明一實施例中,在計算某一數據資源的標記值時基于在相鄰時間內與其共同被讀取的數據資源的標記值以及共同被讀取的數據集合進行計算。
于本發明一實施例中,采用以下公式計算數據資源的標記值:
其中,DR(i)表示第i個數據資源的標記值,N(j)表示在當前時間之前,第j個數據資源一共被讀取的次數,B(j)表示在讀取i的同時被讀取的數據集合。
于本發明一實施例中,在計算已標記的數據資源的標記值后將計算所得的每一數據資源的標記值存入數據表中。
于本發明一實施例中,所述存儲層包括性能驅動器和容量驅動器,存儲入性能驅動器的數據資源的標記值大于存儲入容量驅動器內的數據資源的標記值。
于本發明一實施例中,所述數據分層存儲方法還包括:
響應于外部應用的寫操作初始化寫入的數據資源的標記值;
將該標記值存儲入數據表后將數據資源分配至相應的存儲層內。
于本發明一實施例中,在響應于外部應用的讀操作對被讀取的數據資源進行標記,待讀操作完成后計算已標記的數據資源的標記值這一步驟之前,所述數據分層存儲方法還包括:
檢測外部應用的操作;
判斷檢測到的外部應用的操作類別。
相對應的,本發明還提供一種數據分層存儲系統,包括計算模塊和分配模塊。計算模塊響應于外部應用的讀操作對被讀取的數據資源進行標記,待讀操作完成后計算已標記的數據資源的標記值。分配模塊根據每一數據資源的標記值的大小將該數據資源分配到相應的存儲層內。
于本發明一實施例中,計算模塊在計算某一數據資源的標記值時基于在相鄰時間內與其共同被讀取的數據資源的標記值以及共同被讀取的數據集合進行計算。
于本發明一實施例中,數據分層存儲系統還包括檢測模塊和判斷模塊。檢測模塊檢測外部應用的操作。判斷模塊判斷檢測模塊所檢測到的外部應用的操作類別。
綜上所述,本發明提供的數據分層存儲方法及系統與現有技術相比,具有以下優點:
通過對被讀取的數據資源進行標記并對標記后的數據資源計算其標記值來實時動態的分析數據資源的冷熱度,實現數據資源冷熱度的自動判斷,并根據該數據資源的冷熱度將熱數據分配至高速的性能驅動器,而將海量的冷數據分配至低速的容量驅動器,從而提高數據訪問的命中率以及存儲系統的資源利用率,針對大量的讀寫問題能夠很好進行應對,保障業務系統的正常運行。進一步的,在計算已標記的數據資源的標記值時考慮了數據與數據間的關系問題,大大提高了數據的響應速度。
為讓本發明的上述和其它目的、特征和優點能更明顯易懂,下文特舉較佳實施例,并配合附圖,作詳細說明如下。
附圖說明
圖1所示為現有容器鏡像數據存儲系統架構圖。
圖2所示為本發明實施例一提供的數據分層存儲方法的流程圖。
圖3所示為本發明提供的數據分層存儲的構架圖。
圖4所示為本發明實施例一提供的數據分層存儲系統的框架圖。
圖5所示為本發明實施例二提供的數據分層存儲方法的流程圖。
圖6所示為本發明實施例二和實施例三提供的數據分層存儲系統的框架圖。
圖7所示為本發明實施例三提供的數據分層存儲方法的流程圖。
具體實施方式
實施例一
作為信息技術的一大優化策略,分層存儲技術已經成為主流存儲產品的基本配置。分層存儲可提高存儲需求的靈活性,優化數據管理,并降低總擁有成本。現有的容器鏡像存儲中,采用人為對數據資源的冷熱度進行判斷,根據判斷的結果將數據資源存儲在不同性質的存儲層內。數據資源冷熱度的人為判斷不僅存在判斷速度無法滿足讀寫需求并且還存在判斷不正確的問題。有鑒于此,本發明提供了一種能自動準確識別數據資源冷熱度的數據分層存儲方法及系統。
本實施例提供的數據分層存儲方法包括:響應于外部應用的讀操作對被讀取的數據資源進行標記,待讀操作完成后計算已標記的數據資源的標記值(步驟S1)。根據每一數據資源的標記值的大小將該數據資源分配到相應的存儲層內(步驟S2)。
該方法始于步驟S1,在該步驟內系統為每一數據資源關聯一標記參數,記為DataRank(簡稱DR)。當外部應用讀取該數據資源時,系統通過改變DR值(標記值)來對該數據資源進行標記,每讀取一次,DR值不斷地被疊加,該過程直到該讀操作完成。DR值表征了這個數據資源被讀取的頻率(即重要度),DR值越大表明當前這段時間內該數據資源越重要,其被讀取的次數越多,在這段時間內該數據資源為熱數據。相反的,在當前這段時間內某一數據資源的DR值很小,則表明在這段時間內該數據資源為不重要的數據資源,其被讀取的次數很少,在這段時間內該數據為冷數據。
然而,在實際應用中,由于應用和應用之間、數據和數據之間存在著依賴的關系,外部應用讀取單條數據往往不能解決問題。通常外部應用會先后或同時讀取多條數據資源來滿足應用的需求。因此,在對數據資源的冷熱度判斷時若僅僅只考慮其自身的DR值會存在判斷的偏差。在數據讀取中,一般會認為與重要數據一起被讀取的數據資源一般也較為重要,基于這一理論,在計算某一數據資源的DR值時基于在相鄰時間內與其共同被讀取的數據資源的DR值以及共同被讀取的數據集合B(j)進行計算。計算的具體公式為:
其中,DR(i)表示第i個數據資源的標記值,N(j)表示在當前時間之前,第j個數據資源一共被讀取的次數,B(j)表示在讀取i的同時被讀取的數據集合。
為了標準化計算結果,需要在公式一的基礎上增加一個常數C,得到以下公式:
當計算得到被讀取的數據資源的DR值后,執行步驟S2,根據該DR值將該數據資源分配到相應的存儲層中。于本實施例中,當計算完所有被標記的數據資源后再根據數據資源的DR值將該數據資源分配到相應的存儲層內。然而,本發明對此不作任何限定。于其它實施例中,可計算完一個數據資源的DR值后即可將該數據資源分配到相應的存儲層內,之后再進行下一個數據資源的DR值計算。
如圖3所示,本發明提供的數據分層存儲方法基于圖3所給出的存儲構架。于本實施例中,將整個數據存儲層分為三層:位于底層的容量最大的低頻層,位于低頻層上的容量較小的中頻層以及位于中頻層上的容量最小的高頻層;三者的讀取速度為:高頻層大于中頻層,中頻層大于低頻層。于本實施例中,設置一個DR閾值,根據被讀取的數據資源的DR值將DR值小于DR閾值的數據資源(COLD數據)分配到低頻區,而將DR值大于或等于DR閾值的數據資源(HOT數據)分配到高頻區。然而,本發明對此不作任何限定。于其它實施例中,可設置兩個DR閾值來將數據資源分配到低頻區、中頻區(WARM數據)和高頻區,也可以設置三個以上的DR閾值來將整個存儲層劃分為四個以上的存儲層。于本實施例中,存儲層包括性能驅動器和容量驅動器,性能驅動器對應存儲構架內的高頻層,容量驅動器對應存儲構架內的低頻層。
基于DR值的數據資源分配實現了數據資源在不同存儲層之間的快速移動,實時動態的分析使得被高頻讀取的數據資源能快速的從低頻區進入高頻區;而被低頻讀取的且位于高頻區內的數據資源能快速地進入低頻區,大大提高了數據的讀取速度。
為便于DR值的計算,于本實施例中,計算已標記的數據資源的DR值后將該DR值存入數據表中。然而,本發明對此不作任何限定。
與上述數據分層存儲方法相對應的,本實施例還提供一種數據分層存儲系統300,該系統300包括計算模塊1和分配模塊2。計算模塊1響應于外部應用100的讀操作對被讀取的數據資源進行標記,待讀操作完成后計算已標記的數據資源的標記值。分配模塊2根據每一數據資源的標記值的大小將該數據資源分配到相應的存儲層200內。
計算模塊1為每一數據資源關聯一標記參數,記為DataRank(簡稱DR)。當外部應用讀取該數據資源時,計算模塊1通過改變DR值(標記值)來對該數據進行標記,如每讀取一次,DR值不斷地被疊加直到該讀操作完成。DR值表征了這個數據資源被讀取的頻率(即重要度),DR值越大表明當前這段時間內該數據資源越重要,其被讀取的次數越多,在這段時間內該數據資源為熱數據。相反的,在當前這段時間內某一數據資源的DR值很小,則表明在這段時間內該數據資源為不重要的數據資源,其被讀取的次數很少,在這段時間內該數據為冷數據。
在DR值的計算過程中,考慮到應用和應用之間、數據和數據之間存在著依賴的關系,一般會認為與重要數據一起被讀取的數據資源一般也較為重要,基于這一理論,在計算某一數據資源的DR值時基于在相鄰時間內與其共同被讀取的數據資源的DR值以及共同被讀取的數據集合B(j)進行計算。計算的具體公式為:
其中,DR(i)表示第i個數據資源的標記值,N(j)表示在當前時間之前,第j個數據資源一共被讀取的次數,B(j)表示在讀取i的同時被讀取的數據集合。
為了標準化計算結果,需要在公式一的基礎上增加一個常數C,得到以下公式:
當計算模塊1計算出每一已標記的數據資源的DR值后,分配模塊2根據DR值將已標記的數據資源分配至不同的存儲層內。具體而言,圖3中給出了具體的存儲構架。該構架將整個數據存儲層劃分為三個區域,位于頂層的具有最快的數據讀取速度且容量最小的高頻區,在該區域內存儲的是HOT數據;位于中間的中頻區,在該區域內存儲的是WARM數據;以及位于底層的數據讀取速度最慢的且容量最大的低頻區,在該區域內存儲的是COLD數據。于本實施例中,設置一個DR閾值來將數據資源進行區分,DR值大于或等于DR閾值的數據資源分配到高頻區內,而將DR值小于DR閾值的數據分配到低頻區內。然而,本發明對此不作任何限定。于其它實施例中,可設置兩個DR閾值來將數據分配到低頻區、中頻區(WARM數據)和高頻區,也可以設置三個以上的DR閾值來將整個存儲層劃分為四個以上的存儲層。
本實施例提供的數據分層存儲方法及系統不僅實現了數據資源冷熱度的自動且準確的識別,且可根據數據資源的冷熱度將其進行分層存儲,將熱數據存儲在高頻區內直接提供客戶訪問,提高數據訪問的命中率,檢索速度以及傳輸速度。進一步的,在對表征數據冷熱度的DR值的計算過程中綜合考慮了數據與數據之間的影響,在讀取數據當前數據的同時,考慮鄰近時間內其它數據的影響,大大提高數據資源冷熱度判斷的準確性。此外,相對傳統的分布式存儲方案,在保持了系統IOPS的同時,降低了投入成本,并提高了系統的資源利用率,減少能耗。
實施例二
本實施例提供的數據分層存儲方法包括:
步驟S10、檢測外部應用的操作。
步驟S20、判斷外部應用的操作是否為讀操作;
步驟S30、若是,響應于外部應用的讀操作對被讀取的數據資源進行標記,待讀操作完成后計算已標記的數據資源的標記值。
步驟S40、根據每一數據資源的標記值的大小將該數據資源分配到相應的存儲層內。
本實施例與實施例一及其變化的區別在于,在對被讀取的數據資源進行標記之前判斷外部應用的操作是否為讀操作,具體的流程圖如圖5所示。
相對應的,本實施例還提供一種數據分層存儲系統300,該系統300包括檢測模塊30、判斷模塊40、計算模塊10和分配模塊20。檢測模塊30檢測外部應用100的操作。判斷模塊40判斷檢測模塊所檢測到的外部應用100的操作類別。于本實施例中,判斷模塊40只需判斷外部應用100的操作是否為讀操作。當為讀操作時計算模塊10響應于外部應用的讀操作對被讀取的數據資源進行標記,待讀操作完成后計算所有已標記的數據資源的標記值。分配模塊20根據每一數據資源的標記值的大小將該數據資源分配到相應的存儲層內。計算模塊10的具體計算以及分配模塊20的具體分配方式與實施例一相同。
為保證DR值的準確性以及有效性,于本實施例中,數據分層存儲系統還包括對DR值進行維護的維護模塊50。然而,本發明對此不作任何限定。
實施例三
本實施例與實施例一及其變化的區別在于,本實施例提供的數據分層存儲方法還包括:
響應于外部應用的寫操作初始化寫入的數據資源的標記值;
將該標記值存儲入數據表后將數據資源分配至相應的存儲層內。
具體的流程如7所示,包括:
步驟S100、檢測外部應用的操作。
步驟S200、判斷外部應用的操作為讀操作還是寫操作;
步驟S300、當外部應用的操作為讀操作時,響應于外部應用的讀操作對被讀取的數據資源進行標記,待讀操作完成后計算已標記的數據資源的標記值。
步驟S301、根據每一數據資源的標記值的大小將該數據資源分配到相應的存儲層內。
步驟S400、當外部應用的操作為寫操作時,響應于外部應用的寫操作初始化寫入的數據資源的標記值。
步驟S401、將該標記值存儲入數據表后將數據資源分配至相應的存儲層內。
于本實施例中,當外部應用寫入一數據資源時,系統自動為寫入的數據資源關聯一標記DR,并初始化DR值(即標記值),使其等于1,即步驟S400。在初始化完成后執行步驟S401,將該DR值存儲入數據表內并根據DR閾值將該數據資源分配至相應的存儲層內。然而,本發明對此不作任何限定。于其它實施例中,DR值的產生可在數據資源的第一次被讀取時進行初始化,如實施例一中應用的。
同樣的,當外部操作讀取某一數據資源時,該數據資源被標記且其所對應的DR值不斷被疊加,該過程直到該操作完成,即步驟S300。當該讀操作完成后計算每一數據資源的DR值。于本實施例中,考慮到數據和數據之間的依賴關系,一般認為與重要數據一起被讀取的數據也是比較重要的,因此在計算數據資源的DR值的同時會綜合考慮在鄰近時間內與其共同被讀取的其它數據資源的DR值以及共同被讀取的數據資源的集合。
具體采用如下公式計算
其中,DR(i)表示第i個數據資源的標記值,N(j)表示在當前時間之前,第j個數據資源一共被讀取的次數,B(j)表示在讀取i的同時被讀取的數據集合。
為了標準化計算結果,需要在公式一的基礎上增加一個常數C,得到以下公式:
當計算得到被讀取的數據資源的DR值后,執行步驟S301,根據該DR值將該數據資源分配到相應的存儲層中。于本實施例中,當計算完所有被標記的數據資源后再根據數據資源的DR值將該數據資源分配到相應的存儲層內。然而,本發明對此不作任何限定。于其它實施例中,可計算完一個數據資源的DR值后即可將該數據資源分配到相應的存儲層內,之后再進行下一個數據資源的DR值計算。
如圖3所示,本發明提供的數據分層存儲方法基于圖3所給出的存儲構架。于本實施例中,將整個數據存儲層分為三層:位于底層的容量最大的低頻層,位于低頻層上的容量較小的中頻層以及位于中頻層上的容量最小的高頻層;三者的讀取速度為:高頻層大于中頻層,中頻層大于低頻層。于本實施例中,設置一個DR閾值,根據被讀取的數據資源的DR值將DR值小于DR閾值的數據資源(COLD數據)分配到低頻區,而將DR值大于或等于DR閾值的數據資源(HOT數據)分配到高頻區。然而,本發明對此不作任何限定。于其它實施例中,可設置兩個DR閾值來將數據資源分配到低頻區、中頻區(WARM數據)和高頻區,也可以設置三個以上的DR閾值來將整個存儲層劃分為四個以上的存儲層。于本實施例中,存儲層包括性能驅動器和容量驅動器,性能驅動器對應存儲構架內的高頻層,容量驅動器對應存儲構架內的低頻層。
基于DR值的數據資源分配實現了數據資源在不同存儲層之間的快速移動,實時動態的分析使得被高頻讀取的數據資源能快速的從低頻區進入高頻區;而被低頻讀取的且位于高頻區內的數據資源能快速地進入低頻區,大大提高了數據的讀取速度。
為便于DR值的計算,于本實施例中,計算已標記的數據資源的DR值后將該DR值存入數據表中。然而,本發明對此不作任何限定。
本實施例與實施例二及其變化的區別在于,對外部應用的操作的判斷不一樣。在實施例二中僅僅需要判斷是否為讀操作即可,而在本實施例中則需要判斷具體是何種類型的操作,系統根據不同類型的外部應用操作做不同的響應。
相對應的,如圖6所示,本實施例提供的數據分層存儲系統300,該系統300包括檢測模塊30、判斷模塊40、計算模塊10和分配模塊20。該原理框圖與實施例二的相同,但判斷模塊40、計算模塊10以及分配模塊20的工作不同,具體如下:
檢測模塊30檢測外部應用的操作。判斷模塊40判斷檢測模塊所檢測到的外部應用的操作類別。于本實施例中,判斷模塊40需要具體的判斷外部應用100的操作為讀操作或寫操作。當判斷模塊40判斷外部應用為讀操作時計算模塊10響應于外部應用的讀操作對被讀取的數據資源進行標記,待讀操作完成后計算已標記的數據資源的標記值。分配模塊20根據每一數據資源的標記值的大小將該數據資源分配到相應的存儲層200內。當判斷模塊40判斷外部應用為寫操作時,計算模塊10為寫入的數據關聯一DR,并將該DR值進行初始化,使其為1。之后分配模塊20將該DR值存儲入數據表內并根據DR閾值將該數據資源分配至相應的存儲層內。然而,本發明對此不作任何限定。于其它實施例中,DR的關聯以及DR值的產生可在數據資源的第一次被讀取時進行初始化,如實施例一中應用的。本實施例中計算模塊10的具體計算以及分配模塊20的具體分配方式與實施例一相同。
為保證DR值的準確性以及有效性,于本實施例中,數據分層存儲系統還包括對DR值進行維護的維護模塊50。然而,本發明對此不作任何限定。
綜上所述,本發明提供的數據分層存儲方法及系統通過對被讀取的數據資源進行標記并對標記后的數據資源計算其標記值來實時動態的分析數據資源的冷熱度,實現數據資源冷熱度的自動判斷,并根據該數據資源的冷熱度將熱數據分配至高速的性能驅動器,而將海量的冷數據分配至低速的容量驅動器,從而提高數據訪問的命中率以及存儲系統的資源利用率,針對大量的讀寫問題能夠很好進行應對,保障業務系統的正常運行。進一步的,在計算已標記的數據資源的標記值時考慮了數據與數據間的關系問題,大大提高了數據的響應速度。
雖然本發明已由較佳實施例揭露如上,然而并非用以限定本發明,任何熟知此技藝者,在不脫離本發明的精神和范圍內,可作些許的更動與潤飾,因此本發明的保護范圍當視權利要求書所要求保護的范圍為準。
- 還沒有人留言評論。精彩留言會獲得點贊!