一種基于數據挖掘的車輛停留行為模式預測與評估方法與流程
本發明涉及數據挖掘的方法、車輛的停留行為模式以及相關的預測與評估方法,特別是涉及一種基于數據挖掘的車輛停留行為模式預測與評估方法。
背景技術:
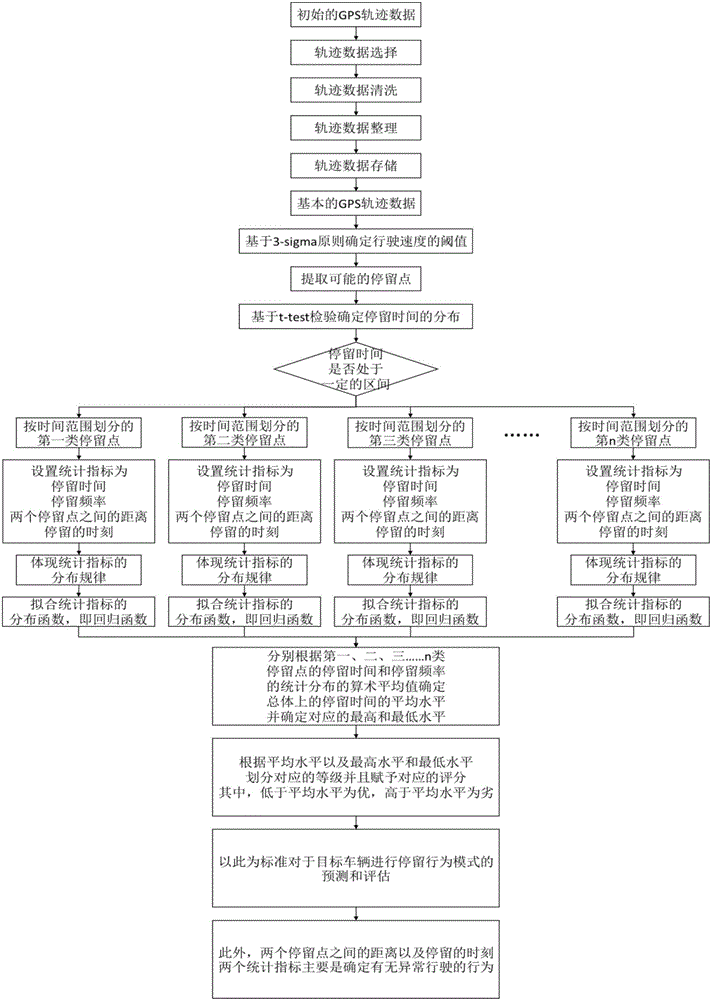
:數據挖掘的方法是一個從大量數據中提取出人們所感興趣的知識的復雜的方式,人們所感興趣的知識是有實際意義的并且以可以被理解的模式蘊含在數據之中。20年左右的發展,數據挖掘的相關研究已經越來越成熟,并且應用到其他領域。移動對象的數據挖掘主要是通過數據的處理與分析,數學,以及統計學等一系列數據挖掘的方法從移動對象的歷史活動數據——軌跡數據中挖掘,并進一步發現有意義的和有價值的信息。軌跡數據是移動對象的歷史活動數據,在一定水平上可以體現移動對象的性質、狀態、行為等等內部特征和外部特征,此外,還可以體現內部環境和外部環境的變化對于移動對象的活動的影響。行為模式是從大量的行為活動中提取出來的,是行為的基本的理論、模型和規律。具體到車輛的停留行為模式,指的是車輛,特別是貨運車輛,在一次行駛過程中,因為某一種因素的影響,所導致停留行為的時刻、間隔、頻率、距離等一系列的指標所體現出來的特征。相關的預測與評估方法,主要有常規的預測與評估,灰色系統理論以及模型等,一般情況下,是通過對于現有的數據的整理及進一步處理,統計及進一步分析,建立一個回歸函數進行預測,并且建立一個指標體系進行評估,在這一過程中,這個回歸函數的類型還要求根據所使用的數據進一步確定,這個指標體系可以是單值函數或者集值函數。另外,對于規律性不大的系統也可以用灰色系統方法。技術實現要素:本發明的目的是為了解決上述問題,提出一種基于數據挖掘的車輛停留行為模式預測與評估方法。本發明是一種基于數據挖掘的車輛停留行為模式預測與評估方法,如圖1所示,包括以下幾個步驟:步驟一,導入初始的GPS軌跡數據,進行數據預處理;步驟二,從SQL數據庫之中提取數據預處理之后的基本的GPS軌跡數據,并且進一步的進行停留點的提取;步驟三,對于每一種類型的停留點,分別對于以下四個統計指標;步驟四,對于每一種類型的停留點的四個統計指標的統計分布進一步的擬合,擬合過程主要是根據最小二乘法按照線性回歸的方式提取統計分布的回歸函數,可以利用一系列的常規函數擬合統計分布,并且比較擬合效果以確定回歸函數,這里所采用的的函數是相關研究中通常會采用的函數。步驟五,根據每一種類型的停留點的停留時間和停留頻率的統計分布平均值來確定總體上的停留時間的平均水平。本發明的優點在于:(1)本發明基于數據挖掘的車輛停留行為模式預測與評估方法,基本的主要流程是基于大量的GPS軌跡數據,采取數據挖掘技術相關的方法,對于以上軌跡數據進行選擇、清洗、整理、存儲等一系列的處理步驟,以保證接下來所使用的數據的真實性、實時性、準確性,進一步的利用相關的統計學理論來進行貨運車輛的停留點的提取和停留點的分類,以保證接下來的統計分析過程的具體性和合理性,在此基礎之上,對于行為模式理論相關的一系列統計指標進行統計分析,以提取分布規律和分布函數,與此同時,分析總體和個體的統計指標的分布之間的關系,為預測和評估提供數據和理論上的支持;(2)本發明基于數據挖掘的車輛停留行為模式預測與評估方法,其中預測與評估的主要方法選擇了回歸函數與指標體系二者相結合的方式,以保證總體的完整性,回歸函數的確定主要是通過對于實際數據的統計指標的統計分析,體現其合理性,指標體系的確定主要是通過對于大量的統計分析的結果的處理,以總體反映個體,如此,可以保證預測與評估方法體系的正確性,以實現所要達到的效果。附圖說明圖1為本發明基于數據挖掘的車輛停留行為模式預測與評估方法流程圖;具體實施方式下面將結合附圖和實施例對本發明作進一步的詳細說明。本發明是一種基于數據挖掘的車輛停留行為模式預測與評估方法,如圖1所示,包括以下幾個步驟:步驟一,導入初始的GPS軌跡數據,進行數據預處理;一般情況下,車輛的GPS軌跡數據包括以下字段,如時間、車輛ID、經度、緯度、速度、方向,根據數據所反映的車輛的類型、行駛路線、行駛時間、行駛區域的相關的信息,選擇所需要的GPS軌跡數據,并且主要關注時間、車輛ID、經度、緯度以及速度,這里所需要導入的數據是若干車輛行駛一段時間的GPS軌跡數據,主要包括時間、車輛ID、經度、緯度、速度幾個字段;初始的數據往往存在一定的問題,如字段的記錄是否正確、規范、或者存在缺失,因此還需要對數據進行清洗和整理,根據相應的字段的性質,選擇其中的記錄正常的數據,并且保證數據的完整性,具體的方法是將GPS軌跡數據記錄中,時間、車輛ID、經度、緯度、速度幾個字段的記錄存在不正確、不規范、或者存在缺失問題的條目篩選出來并且去除掉,將處理之后的數據根據車輛ID分類,并且對于每一個車輛ID分類下的數據按照時間的順序重新排列,如果其中有時間不連續的情況,還需要進一步對時間字段進行補全,并且對于相應的條目中的經度、緯度、速度字段,結合車輛行駛的實際情況的合理性,進行理論的估計和補全,以保證時間、經度、緯度、速度的前后連貫性,并且將數據存儲入SQL數據庫中。步驟二,從SQL數據庫之中提取數據預處理之后的基本的GPS軌跡數據,并且進一步的進行停留點的提取;為了進行停留點的提取,必須判斷數據記錄中的速度是否為零,因為軌跡數據可能存在一定的誤差,所以依據記錄判斷不合理,因此,可以進行以下處理,將總體的軌跡數據中的速度字段提取出來為一條數據,定義為x1,x2,x3,……xM,其中,xn為某一車輛在某一時刻的速度數值,并且,xn≥0,M為所有具有速度數值的有效記錄的個數,在此基礎之上,根據3-sigma原則,判斷總體的速度數據是否符合正態分布,若符合正態分布,則可以根據一個區間來判斷速度是否為零,和分別為區間的下限和上限,表示均值,δ表示方差,在這一區間范圍內的速度為零,不在這一區間范圍內的速度不為零,其中,定義為其中,δ定義為若不符合正態分布,則需要對數據進行正態化處理,公式如下所示,其中,x表示不符合正態分布的數據,y表示經過正態化處理后符合正態分布的數據,γ為冪指數,對于x1,x2,x3,……xM一系列數值,可以將使以下公式達到其最大值的式中的參數γ的理論值作為參數γ的實際值,其中,l(γ)表示目標函數值,yi表示y中數據的單個值,表示y中數據的平均值,以上處理方法可以參考非正態數據的正態變換處理方法;上述處理過程之后,選擇出來的速度為零的數據記錄,可能存在的情況是,一系列連續的速度為零的數據記錄實際上屬于一個停留點,對于某一輛ID為XXX的車輛,獲得其一部分連續的行駛軌跡數據記錄,時間記錄為t1、t2……、tn,經度和緯度記錄分別為lon1、lon2……、lonn和lat1、lat2……、latn,并且數值變化比較小(兩點之間實際距離誤差范圍為s米以內,s=1),速度記錄均為0,具體形式如下所示,時間車輛ID經度緯度速度t1XXXlon1lat10…………………………tnXXXlonnlatn0對于這樣一系列連續的速度為零的數據記錄,可以將其整理為一條數據記錄,將這一條數據記錄的時間取為上述數據中第一條數據條目的時間,記為t,經度和緯度分別取為上述數據中所有經度和緯度的平均值,記為lonave和latave,速度取為0,持續時間取為上述數據中第一條數據條目和最后一條數據條目的時間之差,記為tlast,車輛的ID還是為XXX,具體形式如下所示,時間車輛ID經度緯度速度持續時間tXXXlonave1atave0tlast時間記為t=t1,經度記為lonave=(lon1+lon2+lon3+……+lonn)/n,緯度記為latave=(lat1+lat2+lat3+……+latn)/n,速度記為0,持續時間記為tlast=(tn–t1),到此為止,完成了停留點的提取,提取出來的停留點的形式為一條一條的數據條目,每一條數據條目包括時間、車輛ID、經度、緯度、速度、持續時間幾個字段的內容,因為表示的是停留點,所以這里的速度字段的值均為0,則這一條條目的含義就是某一個ID的車輛,在某一時間(時間表示的),于某一位置(經度和緯度表示的),停留了多少時間(持續時間表示的),接下來,進一步的來進行停留點的分類,將提取出來的總體的停留點的數據,按照持續時間的長短,體現其統計分布結果,以持續時間的長短為橫坐標,單位為分鐘,區間為(0,480),間隔為10,并且以停留點的個數為縱坐標,單位為個數,表示出總體的停留點的數據的統計分布,按照統計分布中所反映的停留點的持續時間的分布情況,結合可能的行駛過程中導致停留行為的因素的種類,將停留點劃分為n種類型,持續時間的區間分別設為(0,t1),(t1,t2),(t2,t3),……(tn-1,∞)。此處,統計分布主要是為了直觀的表示,劃分為n種類型主要還是根據實際的經驗。步驟三,對于每一種類型的停留點,分別對于以下四個統計指標,表示出其統計分布規律,(1)停留時間,指的是某一次停留中停留行為的持續時間,(2)停留頻率,指的是某一段時間內停留行為的重復次數,(3)兩個停留點之間的距離,指的是某一車輛的兩次停留位置之間的距離,可以依據停留點的經度和緯度的信息來計算,兩個停留點的經緯度坐標分別為(lonend,latend),(lonstart,latstart),兩者之間其實還有一系列的點的坐標,例如(lon1,lat1),(lon2,lat2),……可以逐個計算兩點之間的距離,再一一加起來,也就是兩個停留點之間的距離,計算公式如下所示,C=(sin(MlatA)*sin(MlatB)*cos(MlonA-MlonB)+cos(MlatA)*cos(MlatB))(6)Distance=R*arccos(C)*π/180(7)其中,(lonA,latA)和(lonB,latB)為兩點的經緯度坐標,東經取經度的正值(longitude),西經取經度負值(-longitude),北緯取90-緯度值(90-latitude),南緯取90+緯度值(90+latitude),進行以上處理的兩點的經緯度坐標分別為(MlonA,MlatA),(MlonB,MlatB),R為地球的平均半徑,(4)停留時刻,指的是某一車輛的某一次停留行為發生的時間,對于根據某一車輛的停留點的數據和根據所有車輛的停留點的數據所獲得的上述某一類型停留點(指的是之前劃分的n種停留點的類型)的某一個統計指標(指的是之前提到的四個統計指標,也就是停留時間、停留頻率、兩個停留點之間的距離、停留時刻)的統計分布,還要確定是否為類似分布,這個可以根據t-test檢驗進行判斷,檢驗主要用于檢測兩個分布是否為類似分布,其功能可以通過MATLAB或者其他的數學軟件實現。步驟四,對于每一種類型的停留點的四個統計指標的統計分布進一步的擬合,擬合過程主要是根據最小二乘法按照線性回歸的方式提取統計分布的回歸函數,可以利用一系列的常規函數擬合統計分布,并且比較擬合效果以確定回歸函數,這里所采用的的函數是相關研究中通常會采用的函數。可以考慮采用的常規函數有,(1)指數分布函數f(x)=a·eb·x(8)(2)高斯分布函數(3)冪律分布函數f(x)=a·xb(10)(4)對數正態分布函數其中,f(x)為目標函數,也就是上述的四個統計指標所對應的橫坐標的量,x為變化的量,也就是數據的個數所對應的縱坐標的量,a,b,c分別為其參數,可以考慮采用R-Square公式來比較擬合效果,其中,R-Square為一個(0,1)的數值,通常用來描述數據對模型的擬合程度的好壞,yi,wi四個參數分別表示第i個數據點的實際值,擬合值,平均值,數據點的數據量占數據總量的權重,R-Square的值越趨于0表示效果越差,R-Square的值越趨于1表示效果越好。步驟五,根據每一種類型的停留點的停留時間和停留頻率的統計分布平均值來確定總體上的停留時間的平均水平,對于類型M的停留點,對其所包含的停留點的數據統計如下,表1類型M的停留點所包含的停留點的數據序號123……m個數num(1)num(2)num(3)……num(m)停留時間t1t2t3……tm平均停留時間為其中tMmean表示平均停留時間,num(i)表示停留時間為ti的停留點個數,ti表示停留時間,nfrequentMmean表示類型M的停留點的停留頻率的平均值,tMmean為類型M的停留點的停留時間的平均水平,并且可以根據數據t1,t2,t3,…tm中的最大值和最小值,來分別確定停留時間的最高水平和最低水平,分別設為tMmax,tMmin,此外,還可以將(tMmin,tMmean,tMmax)之間進一步的劃分對應的等級并且賦予對應的評分,如下,表2類型M的停留點對應的等級和評分的劃分tMmin~tM1tM1~tM2tM2~tM3tM3~tMmeantMmean~tM4tM4~tM5tM5~tM6tM6~tMmaxP1P2P3P4P5P6P7P8其中tM1、tM2、tM3、tM4、tM5、tM6表示時間常數,用于劃分tMmin,tMmean,tMmax之間的等級,P1、P2、P3、P4、P5、P6、P7、P8表示對應等級的評分,具體來說,等級指的是根據類型M的停留點的停留時間所進行的分類,如tMmin~tM1、tM1~tM2、tM2~tM3、tM3~tMmean、tMmean~tM4、tM4~tM5、tM5~tM6、tM6~tMmax分別對應8個等級,評分指的是人為規定的對應于各個等級的分數,以用于進一步的評價,如P1、P2、P3、P4、P5、P6、P7、P8指的就是對應于8個等級的評分;所劃分的等級和賦予的評分可以是均勻的,并且規則是時間增加,評分減少,考慮到之前劃分了n種類型的停留點,對于每一種類型的停留點均進行上述的處理,如下所示,表3任意類型的停留點對應的等級和評分的劃分其中,t11、t12、t13、t14、t15、t16和t21、t22、t23、t24、t25、t26和tn1、tn2、tn3、tn4、tn5、tn6表示時間常數,A1、A2、A3、A4、A5、A6、A7、A8和B1、B2、B3、B4、B5、B6、B7、B8和C1、C2、C3、C4、C5、C6、C7、C8表示對應等級的評分,這里與P1、P2、P3、P4、P5、P6、P7、P8沒有直接的關系,也可以人為的設為1、2、3、4、5、6、7、8,并不影響進一步的評分,具體的如上所述,等級指的是根據相應類型的停留點的停留時間所進行的分類,評分指的是人為規定的對應于各個等級的分數,以用于進一步的評價。對于某一車輛在某一個時間區間之內正常行駛過程中的停留時間t,可以應用上述體系進行預測和評估,對其進行預測的方法具體是,根據目標車輛預期的行駛路線過程中可能出現的停留點的類型和頻率,對照上述表3顯示的結果,可以計算出對應于不同等級情況下的車輛可能的用于停留的時間,作為停留行為模式的預測,對其進行評估的方法具體是,根據目標車輛實際的行駛路線過程中確實出現的停留點的類型、時間、頻率,計算出車輛在不同類型的停留點停留的時間,對照上述表3顯示的結果,可以給出相應的等級和評分,作為停留行為模式的評估,并且可以以此為依據,進一步調整其行駛的方案,另外,兩個停留點之間的距離以及停留的時刻這兩個統計指標主要可以用來確定是否有異常駕駛的行為,也就是根據大量的歷史數據發現這兩個統計指標的正常情況下的數值,并且與某一車輛在某一個時間區間之內行駛過程中的對應的統計指標的數值相比較,若一致,則沒有異常駕駛的行為,若不一致,則有異常駕駛的行為。當前第1頁1 2 3
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1