一種基于無線接入點情境分類與感知的在線視頻推薦方法與流程
本發明涉及推薦系統與多媒體網絡領域,更具體地,涉及一種基于無線接入點情境分類與感知的在線視頻推薦方法。
背景技術:
互聯網的出現和普及給用戶帶來了大量的信息,滿足了用戶在信息時代對信息的需求,但隨著網絡的迅速發展而帶來的網上信息量的大幅增長,使得用戶在面對大量信息時無法從中獲得對自己真正有用的那部分信息,對信息的使用效率反而降低了,這就是所謂的信息超載問題。
解決信息超載問題一個非常有潛力的辦法是推薦系統,它是根據用戶的信息需求、興趣等,將用戶感興趣的信息、產品等推薦給用戶的個性化信息推薦系統。和搜索引擎相比,推薦系統通過研究用戶的興趣偏好,進行個性化計算,由系統發現用戶的興趣點,從而引導用戶發現自己的信息需求。一個好的推薦系統不僅能為用戶提供個性化的服務,還能和用戶之間建立密切關系,讓用戶對推薦產生依賴。
個性化推薦的基本形式是提供一個排好序的物品列表。通過這個物品列表,推薦系統試圖根據用戶的偏好和其他約束條件來預測最合適的產品或服務。為了完成這樣的計算任務,推薦系統手機用于的喜好。這種喜好可以是顯式的,如為產品打分;或者是隱式的,如把觀看某個視頻的行為作為用戶喜愛這個視頻的信號。
實現個性化推薦的算法有很多,其中一種最流行和最廣泛的方法是協同過濾。這種方法是找到與用戶有相同品味的用戶,然后將相似用戶過去喜歡的物品推薦給用戶。
在線視頻的普及給用戶帶來了大量的資訊和娛樂信息,極大地改變了用戶獲取信息的方式。但隨著互聯網的發展,在線視頻的數量越來越多,每天都有海量的視頻被上傳和觀看。面對如此海量的視頻,如何有效地獲取視頻這一問題變得越來越突出。一方面,用戶希望更快更好地觀看自己喜好的視頻;另一方面,視頻提供商希望盡可能地滿足用戶的觀看需求,從而增加用戶粘性,提高觀看量。因此,設計一種能夠有效地為用戶提供個性化推薦的視頻推薦系統是十分重要的。
視頻推薦領域已經積累了許多技術,但是大多數方法只是關注把最相關的視頻推薦給用戶,卻忽略了相關情境信息,如時間、地點,或陪同觀看的人。而用戶所做的決策往往與當時的情境是相關的,用戶所處情景不同,所觀看的視頻也會有所不同。例如,在公司里用戶往往看一些較短視頻,而在家里可能偏好看一些較長的娛樂類視頻。因此,在視頻推薦系統里,情境信息整合到推薦方法中,毫無疑問會影響用戶偏好的預測準確度。
綜上所述,從在線視頻服務提供商的角度出發,為了給用戶提供個性化的視頻,增加用戶粘度,繼而增加視頻的瀏覽量,在線視頻服務商需要設計一種推薦系統來預測用戶的喜好。為了實現更精準的預測,還需要結合一些有效的情境信息來優化推薦系統。
技術實現要素:
本發明提供一種更為良好的個性化視頻推薦服務的基于無線接入點情境分類與感知的在線視頻推薦方法。
為了達到上述技術效果,本發明的技術方案如下:
一種基于無線接入點情境分類與感知的在線視頻推薦方法,包括以下步驟:
S1:根據用戶觀看記錄,訓練出協同過濾推薦模型和AP分類模型;
S2:根據訓練好的協同過濾推薦模型計算出給定用戶的視頻推薦列表;
S3:根據AP分類模型對用戶所在情境進行估計;
S4:針對每個情境,利用該情境中的視頻流行度排名,基于后過濾方法,對上述協同過濾模型計算得出的視頻推薦列表進行重排與過濾。
進一步地,所述步驟S1中訓練出協同過濾推薦模型的具體過程如下:
S111:根據用戶觀看記錄,以視頻的觀看比例作為用戶的隱式評分,生成user-video矩陣Muv,并轉化為置信度矩陣:
Cuv=1+αruv
其中,Cuv即為置信度矩陣,α是線性增長系數,ruv是隱式評分;
S112:找如下代價函數的有最優解:
其中,xu為用戶u的因子向量,yv為視頻v的因子向量,puv為用戶u對視頻v的偏好系數,λ為規則化系數用于防止過擬合;
S113:所有最優的xu向量組成的矩陣X,以及yv向量組成的矩陣Y即為最終的同過濾推薦模型。
進一步地,所述步驟S1中訓練出AP分類模型的具體過程如下:
S121:AP特征提取:
一個AP即一個接入點,可以接入多個用戶,為了根據觀看記錄來提取AP的特征,可以使每個AP都當作一個“復合用戶”,形成一個AP-video矩陣V,其中,復合用戶是指,將屬于該AP下的所有用戶的觀看記錄全部合并在一起,當作一個復合而成的虛擬用戶,而AP-video矩陣V與上述user-video矩陣M類似,矩陣中的每個元素Vij即表示APi對videoj的隱式反饋評分,然后,對矩陣M進行非負矩陣分解得到W和H矩陣,其中W矩陣的的每個行向量Wi即為APi的特征向量,由此完成了AP的特征提取;
S122:AP分類模型的訓練:
1)、提取SSID關鍵字,確定部分SSID所對應的AP的情境;
2)、以確定情境的AP作為種子,使用k-means聚類算法將特征相似的AP聚在一起,經過多次迭代訓練后得到AP分類模型。
進一步地,所述步驟S2的具體過程如下:
S211:在矩陣X中找到用戶u的因子向量xu;
S212:預測用戶u對所有視頻的打分:
S213:結合每個打分對應的視頻id,輸出一個二元組序列Recu,即為協同過濾推薦模型視頻推薦列表。
進一步地,所述步驟S3的具體過程如下:
S31:通過用戶觀看記錄中的SSID和MAC地址值,確定用戶所在的AP;
S32:利用上述AP分類模型,推測用戶所在AP的情境。用戶情境即為其所屬AP的情境。
進一步地,所述步驟S4的具體過程如下:
(1)、通過協同過濾推薦模型預測評分
對于用戶u,首先通過上述協同過濾推薦模型得到推薦列表Recu,推薦列表Recu是一個二元組數組,其形式為:
其中,vid為視頻v的標識符,為協同過濾推薦模型模型預測的,用戶u給視頻v評分,然后,通過伸縮變換函數fscale,變換到[0,1]之間:
其中,
(2)、計算視頻v在情境c下的流行度rpop(c,v):
對情境c下所有視頻以觀看量作為鍵值排序:
rpop(c,v)=1-rank(c,v),rank(c,v)∈[0,1]
其中,rank(v)為視頻v的相對排名,由于其值為0到1之間,則有rpop(c,v)∈[0,1];
(3)、加權平均計算新評分:
情境c下視頻的集合為Sc,若v∈Sc,則新評分為等于協同過濾推薦模型的預測評分與流行度的加權和;否則,新評分等于協同過濾推薦模型的預測評分,即:
其中,β1和β2為權重系數,用于調整情境信息對視頻推薦的影響程度;
(4)、根據新評分重新排序:
根據新評分對推薦列表Recu重新排序,得到重排的推薦列表:
最后取出二元組中的視頻號vid,即為最終的推薦列表:
與現有技術相比,本發明技術方案的有益效果是:
本發明方法以視頻的觀看比例作為用戶隱式評分,因此只需要用戶的觀看歷史數據而不需要用戶打分,解決了用戶打分率偏低以及打分不準確的問題。同時,本發明通過對SSID進行關鍵字提取,找出與用戶情境相關的關鍵字,從而確定部分AP的情境。然后再以確定情境的AP作為種子,通過矩陣分解提取AP的特征,并根據這些特征使用k-means聚類算法將情境相似的AP聚合在一起,解決了用戶所在AP的情境如何確定的問題。最后,針對每個情境,本發明利用該情境中的視頻流行度排名,基于后過濾方法,對上述協同過濾模型計算得出的視頻推薦列表進行重排與過濾,使得情境中觀看量更大的視頻的排名更高,從而實現根據情境自適應調整視頻推薦列表的方法,為用戶提供更為良好的個性化視頻推薦服務。
附圖說明
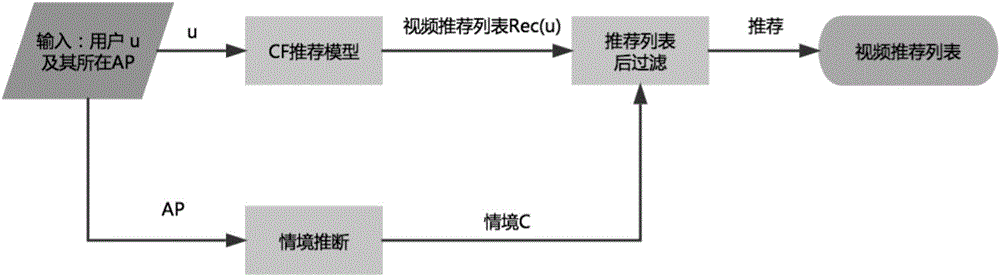
圖1為本發明方法流程圖;
圖2為本發明方法中AP特征提取基本流程;
圖3為本發明方法中AP分類模型訓練基本流程圖;
圖4為本發明方法中情境估計流程圖。
具體實施方式
附圖僅用于示例性說明,不能理解為對本專利的限制;
為了更好說明本實施例,附圖某些部件會有省略、放大或縮小,并不代表實際產品的尺寸;
對于本領域技術人員來說,附圖中某些公知結構及其說明可能省略是可以理解的。
下面結合附圖和實施例對本發明的技術方案做進一步的說明。
實施例1
如圖1所示,一種基于無線接入點情境分類與感知的在線視頻推薦方法,包括以下步驟:
S1:根據用戶觀看記錄,訓練出協同過濾推薦模型和AP分類模型;
S2:根據訓練好的協同過濾推薦模型計算出給定用戶的視頻推薦列表;
S3:根據AP分類模型對用戶所在情境進行估計;
S4:針對每個情境,利用該情境中的視頻流行度排名,基于后過濾方法,對上述協同過濾模型計算得出的視頻推薦列表進行重排與過濾。
步驟S1中訓練出協同過濾推薦模型的具體過程如下:
S111:根據用戶觀看記錄,以視頻的觀看比例作為用戶的隱式評分,生成user-video矩陣Muv,并轉化為置信度矩陣:
Cuv=1+αruv
其中,Cuv即為置信度矩陣,α是線性增長系數,ruv是隱式評分;
S112:找如下代價函數的有最優解:
其中,xu為用戶u的因子向量,yv為視頻v的因子向量,puv為用戶u對視頻v的偏好系數,λ為規則化系數用于防止過擬合;
S113:所有最優的xu向量組成的矩陣X,以及yv向量組成的矩陣Y即為最終的同過濾推薦模型。
步驟S1中訓練出AP分類模型的具體過程如下:
S121:AP特征提取(如圖2所示):
一個AP即一個接入點,可以接入多個用戶,為了根據觀看記錄來提取AP的特征,可以使每個AP都當作一個“復合用戶”,形成一個AP-video矩陣V,其中,復合用戶是指,將屬于該AP下的所有用戶的觀看記錄全部合并在一起,當作一個復合而成的虛擬用戶,而AP-video矩陣V與上述user-video矩陣M類似,矩陣中的每個元素Vij即表示APi對videoj的隱式反饋評分,然后,對矩陣M進行非負矩陣分解得到W和H矩陣,其中W矩陣的的每個行向量Wi即為APi的特征向量,由此完成了AP的特征提取;
S122:AP分類模型的訓練(如圖3所示):
1)、提取SSID關鍵字,確定部分SSID所對應的AP的情境;
2)、以確定情境的AP作為種子,使用k-means聚類算法將特征相似的AP聚在一起,經過多次迭代訓練后得到AP分類模型。
進一步地,所述步驟S2的具體過程如下:
S211:在矩陣X中找到用戶u的因子向量xu;
S212:預測用戶u對所有視頻的打分:
S213:結合每個打分對應的視頻id,輸出一個二元組序列Recu,即為協同過濾推薦模型視頻推薦列表。
如圖4所示,所述步驟S3的具體過程如下:
S31:通過用戶觀看記錄中的SSID和MAC地址值,確定用戶所在的AP;
S32:利用上述AP分類模型,推測用戶所在AP的情境。用戶情境即為其所屬AP的情境。
步驟S4的具體過程如下:
(1)、通過協同過濾推薦模型預測評分
對于用戶u,首先通過上述協同過濾推薦模型得到推薦列表Recu,推薦列表Recu是一個二元組數組,其形式為:
其中,vid為視頻v的標識符,為協同過濾推薦模型模型預測的,用戶u給視頻v評分,然后,通過伸縮變換函數fscale,變換到[0,1]之間:
其中,
(2)、計算視頻v在情境c下的流行度rpop(c,v):
對情境c下所有視頻以觀看量作為鍵值排序:
rpop(c,v)=1-rank(c,v),rank(c,v)∈[0,1]
其中,rank(v)為視頻v的相對排名,由于其值為0到1之間,則有rpop(c,v)∈[0,1];
(3)、加權平均計算新評分:
情境c下視頻的集合為Sc,若v∈Sc,則新評分為等于協同過濾推薦模型的預測評分與流行度的加權和;否則,新評分等于協同過濾推薦模型的預測評分,即:
其中,β1和β2為權重系數,用于調整情境信息對視頻推薦的影響程度;
(4)、根據新評分重新排序:
根據新評分對推薦列表Recu重新排序,得到重排的推薦列表:
最后取出二元組中的視頻號vid,即為最終的推薦列表:
相同或相似的標號對應相同或相似的部件;
附圖中描述位置關系的用于僅用于示例性說明,不能理解為對本專利的限制;
顯然,本發明的上述實施例僅僅是為清楚地說明本發明所作的舉例,而并非是對本發明的實施方式的限定。對于所屬領域的普通技術人員來說,在上述說明的基礎上還可以做出其它不同形式的變化或變動。這里無需也無法對所有的實施方式予以窮舉。凡在本發明的精神和原則之內所作的任何修改、等同替換和改進等,均應包含在本發明權利要求的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!