基于人工智能的網(wǎng)頁原創(chuàng)性識別方法、裝置及存儲介質(zhì)與流程
【技術領域】
本發(fā)明涉及互聯(lián)網(wǎng)技術,特別涉及基于人工智能的網(wǎng)頁原創(chuàng)性識別方法、裝置及存儲介質(zhì)。
背景技術:
人工智能(artificialintelligence),英文縮寫為ai。它是研究、開發(fā)用于模擬、延伸和擴展人的智能的理論、方法、技術及應用系統(tǒng)的一門新的技術科學。人工智能是計算機科學的一個分支,它企圖了解智能的實質(zhì),并生產(chǎn)出一種新的能以人類智能相似的方式做出反應的智能機器,該領域的研究包括機器人、語言識別、圖像識別、自然語言處理和專家系統(tǒng)等。
隨著近年來互聯(lián)網(wǎng)數(shù)據(jù)的爆炸性增長,搜索引擎公司開始檢索千億級別的網(wǎng)頁資源。在海量網(wǎng)頁資源的背后,存在相當一部分數(shù)量的站長或資源產(chǎn)生方,為了減少網(wǎng)頁制作的成本,或是利用其它的優(yōu)質(zhì)網(wǎng)頁為自己的網(wǎng)站吸取點擊增加流量等,轉(zhuǎn)載甚至抄襲其它的優(yōu)質(zhì)原創(chuàng)網(wǎng)頁。
這種現(xiàn)象雖然在一定程度上有利于網(wǎng)絡資源的快速傳播,但由于原創(chuàng)內(nèi)容的作者花費了一定的時間和精力創(chuàng)作內(nèi)容,上述的轉(zhuǎn)載或抄襲行為會削減甚至消除原創(chuàng)作者的創(chuàng)作價值;另外,對于搜索引擎而言,如果搜錄了大量重復的資源,會消耗掉更多的成本如儲存和檢索時間等。
因此,需要對網(wǎng)頁的原創(chuàng)性進行識別,一方面可以保護原創(chuàng)作者的權益,另一方面,搜索引擎可以利用節(jié)省出來的成本去搜錄更多的原創(chuàng)網(wǎng)頁,從而促進高價值內(nèi)容的成長以及內(nèi)容生態(tài)的建設。
現(xiàn)有技術中,主要采用以下方式來進行網(wǎng)頁的原創(chuàng)性識別:從整個網(wǎng)頁中,提取出一個最長句子,根據(jù)提取出的最長句子的簽名進行分組,同組內(nèi)根據(jù)title的皮爾遜距離(計算網(wǎng)頁內(nèi)容的相似度)和鏈接發(fā)現(xiàn)時間進行原創(chuàng)性網(wǎng)頁的識別,即判斷同組內(nèi)誰是真正的原創(chuàng)。
但是,這種方式在實際應用中會存在一定的問題,即識別結果的準確性較低,比如,網(wǎng)頁中的句子有細微的變化,或者最長句子的提取發(fā)生小的變化等,都會造成簽名的變化,進而影響后續(xù)的分組等處理。
技術實現(xiàn)要素:
有鑒于此,本發(fā)明提供了基于人工智能的網(wǎng)頁原創(chuàng)性識別方法、裝置及存儲介質(zhì),能夠提高識別結果的準確性。
具體技術方案如下:
一種基于人工智能的網(wǎng)頁原創(chuàng)性識別方法,包括:
分別對保存在數(shù)據(jù)庫中的各網(wǎng)頁進行句子提取;
根據(jù)提取出的句子生成句子級的原創(chuàng)查找詞典;
根據(jù)所述原創(chuàng)查找詞典,分別識別出從待識別的網(wǎng)頁中提取出的各句子是否為原創(chuàng)句子;
根據(jù)識別結果確定出所述待識別的網(wǎng)頁的原創(chuàng)性。
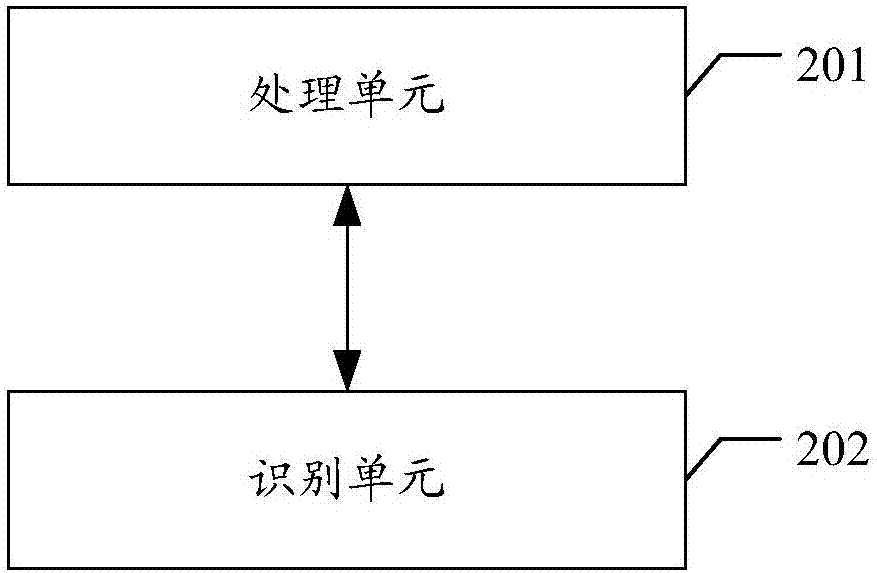
一種基于人工智能的網(wǎng)頁原創(chuàng)性識別裝置,包括:處理單元以及識別單元;
所述處理單元,用于分別對保存在數(shù)據(jù)庫中的各網(wǎng)頁進行句子提取,并根據(jù)提取出的句子生成句子級的原創(chuàng)查找詞典;
所述識別單元,用于根據(jù)所述原創(chuàng)查找詞典,分別識別出從待識別的網(wǎng)頁中提取出的各句子是否為原創(chuàng)句子,根據(jù)識別結果確定出所述待識別的網(wǎng)頁的原創(chuàng)性。
一種計算機設備,包括存儲器、處理器及存儲在所述存儲器上并可在所述處理器上運行的計算機程序,所述處理器執(zhí)行所述程序時實現(xiàn)如以上所述的方法。
一種計算機可讀存儲介質(zhì),其上存儲有計算機程序,所述程序被處理器執(zhí)行時實現(xiàn)如以上所述的方法。
基于上述介紹可以看出,采用本發(fā)明所述方案,可分別對保存在數(shù)據(jù)庫中的各網(wǎng)頁進行句子提取,并根據(jù)提取出的句子生成句子級的原創(chuàng)查找詞典,這樣,后續(xù)針對待識別的網(wǎng)頁,即可根據(jù)原創(chuàng)查找詞典,分別識別出從中提取出的各句子是否為原創(chuàng)句子,進而根據(jù)識別結果確定出待識別的網(wǎng)頁的原創(chuàng)性,這樣,即便個別句子的提取等略有變化,也不會影響整個網(wǎng)頁的識別結果,從而提高了識別結果的準確性。
【附圖說明】
圖1為本發(fā)明所述基于人工智能的網(wǎng)頁原創(chuàng)性識別方法實施例的流程圖。
圖2為本發(fā)明所述基于人工智能的網(wǎng)頁原創(chuàng)性識別裝置實施例的組成結構示意圖。
圖3示出了適于用來實現(xiàn)本發(fā)明實施方式的示例性計算機系統(tǒng)/服務器12的框圖。
【具體實施方式】
為了使本發(fā)明的技術方案更加清楚、明白,以下參照附圖并舉實施例,對本發(fā)明所述方案作進一步地詳細說明。
圖1為本發(fā)明所述基于人工智能的網(wǎng)頁原創(chuàng)性識別方法實施例的流程圖,如圖1所示,包括以下具體實現(xiàn)方式:
在101中,分別對保存在數(shù)據(jù)庫中的各網(wǎng)頁進行句子提取;
在102中,根據(jù)提取出的句子生成句子級的原創(chuàng)查找詞典;
在103中,根據(jù)原創(chuàng)查找詞典,分別識別出從待識別的網(wǎng)頁中提取出的各句子是否為原創(chuàng)句子;
在104中,根據(jù)識別結果確定出待識別的網(wǎng)頁的原創(chuàng)性。
即可根據(jù)數(shù)據(jù)庫中保存的網(wǎng)頁生成句子級的原創(chuàng)查找詞典,進而可通過查詢所述原創(chuàng)查找詞典,確定出待識別的網(wǎng)頁的原創(chuàng)性。
以下分別對上述各部分內(nèi)容的具體實現(xiàn)進行詳細說明。
一)句子提取
在實際應用中,為便于搜索引擎的搜索等,可收集/采集大量的網(wǎng)頁,保存在數(shù)據(jù)庫中。
對于保存在數(shù)據(jù)庫中的每個網(wǎng)頁,可分別通過頁面解析等,獲取該網(wǎng)頁的標題(title)以及正文內(nèi)容(page域),另外還可進一步獲取該網(wǎng)頁的統(tǒng)一資源定位符(url,uniformresourelocator)簽名以及入庫時間等。
針對獲取到的正文內(nèi)容,可對其進行句子切分,如可根據(jù)自然語言中具有句子完結意義的結束符及網(wǎng)頁源碼標簽來切分句子,并可過濾掉過短的句子,自然語言中具有句子完結意義的結束符可包括“。”、“?”、“!”等。
之后,可分別計算出每個句子的權值,具體地,可針對每個句子分別進行以下處理:按照基礎粒度對該句子進行切詞及去停用詞處理,之后,根據(jù)處理結果計算該句子的權值,如將該句子中各切分出的詞(term)的逆文本頻率(idf,inversedocumentfrequency)值相加,將相加之和作為該句子的權值,如何獲取idf值為現(xiàn)有技術。
對于每個網(wǎng)頁,可按照權值由大到小的順序?qū)脑摼W(wǎng)頁的正文內(nèi)容中切分出的各句子進行排序,并選出排序后處于前m位的句子,m為大于一的正整數(shù),將選出的句子以及該網(wǎng)頁的標題作為從該網(wǎng)頁中提取出的句子。
m的具體取值可根據(jù)實際需要而定,比如可為30,標題作為特殊句子進行保留并標識。
對于提取出的每個句子,可在切詞和去停用詞處理的基礎上計算出該句子的句子簽名,如simhash值,simhash是一種常用的字符串hash算法,如果兩個句子相同,那么這兩個句子的simhash值也會相同,如果兩個句子相似,那么這兩個句子的simhash值的海明距離會很近。
二)原創(chuàng)查找詞典
按照一)中的方式,可分別從每個網(wǎng)頁中提取出多個句子,之后,可根據(jù)提取出的句子生成句子級的原創(chuàng)查找詞典,即將千億級的網(wǎng)頁資源建成句子—>網(wǎng)頁的倒排拉鏈表,并可利用倒排拉鏈表進行網(wǎng)頁的原創(chuàng)性識別。
相應地,可首先對提取出的各句子進行去重處理,之后,針對去重處理后的每個句子,可分別生成一個倒排拉鏈表。
倒排拉鏈表中可包括:句子簽名以及入庫時間,還可進一步包括:原創(chuàng)時間,還可進一步包括:原創(chuàng)url簽名、拉鏈長度、鄰近拉鏈總長度、采集者列表等。
其中,句子簽名、原創(chuàng)url簽名、入庫時間、原創(chuàng)時間、拉鏈長度、鄰近拉鏈總長度共同組成倒排拉鏈表中的拉鏈頭數(shù)據(jù),即倒排拉鏈表可由拉鏈頭數(shù)據(jù)以及采集者列表兩部分組成。
其中,原創(chuàng)url表示包含倒排拉鏈表對應的句子的網(wǎng)頁中入庫時間最早的網(wǎng)頁的url。
入庫時間表示包含倒排拉鏈表對應的句子的網(wǎng)頁中入庫時間最早的網(wǎng)頁的入庫時間,即原創(chuàng)url對應的入庫時間。
拉鏈長度表示包含倒排拉鏈表對應的句子的網(wǎng)頁數(shù)。
鄰近拉鏈總長度表示倒排拉鏈表對應的句子的拉鏈長度以及倒排拉鏈表對應的句子的鄰近句子的拉鏈長度之和。鄰近句子為與倒排拉鏈表對應的句子的句子簽名之間的海明距離小于預定閾值的句子,所述閾值的具體取值可根據(jù)實際需要而定,比如3。
相應地,原創(chuàng)時間表示:確定出倒排拉鏈表對應的句子的鄰近句子,從包含所述鄰近句子或倒排拉鏈表對應的句子的網(wǎng)頁中選出入庫時間最早的網(wǎng)頁,該選出的網(wǎng)頁的入庫時間即為所述原創(chuàng)時間。
倒排拉鏈表中的采集者列表中可包括:按照入庫時間由先到后的順序,包含倒排拉鏈表對應的句子的網(wǎng)頁中前n個入庫的網(wǎng)頁的url簽名及入庫時間。
即采集者列表中保存有包含倒排拉鏈表對應的句子的網(wǎng)頁中前n個入庫的網(wǎng)頁的url簽名及入庫時間,并按照入庫時間升序排列,n的具體取值可根據(jù)實際需要而定,比如10。
假設句子a和句子b的句子簽名之間的海明距離小于預定閾值,那么句子b則為句子a的鄰近句子,同樣,句子a也為句子b的鄰近句子。
針對原創(chuàng)查找詞典,還可根據(jù)實際需要,對其執(zhí)行插入、刪除或更新等操作,以下分別對各操作的具體實現(xiàn)進行說明。
1)插入操作
即指將待插入的網(wǎng)頁的句子級數(shù)據(jù)插入倒排拉鏈表中。
所述待插入的網(wǎng)頁可以是指新進且有原創(chuàng)識別需求的網(wǎng)頁。
具體地,可首先對待插入的網(wǎng)頁進行句子提取等。
之后,可針對從待插入的網(wǎng)頁中提取出的每個句子,分別進行以下處理:
確定是否存在該句子對應的倒排拉鏈表;
如果否,則建立該句子對應的倒排拉鏈表,并對該句子的鄰近句子對應的倒排拉鏈表進行更新;
如果是,則對該句子對應的倒排拉鏈表以及該句子的鄰近句子對應的倒排拉鏈表進行更新。
在建立該句子對應的倒排拉鏈表時,入庫時間即為待插入的網(wǎng)頁的入庫時間,其它信息可參照前述說明,不再贅述。
對該句子對應的倒排拉鏈表進行更新可包括:如果待插入的網(wǎng)頁的入庫時間早于倒排拉鏈表中的入庫時間,則將倒排拉鏈表中的入庫時間更新為待插入的網(wǎng)頁的入庫時間,將原創(chuàng)url簽名更新為待插入的網(wǎng)頁的url簽名,將拉鏈長度加一,并將待插入的網(wǎng)頁的url簽名及入庫時間加入到采集者列表中等。
對該句子的鄰近句子對應的倒排拉鏈表進行更新可包括:將鄰近句子對應的倒排拉鏈表中的鄰近拉鏈總長度加一,如果待插入的網(wǎng)頁的入庫時間早于鄰近句子對應的倒排拉鏈表中的原創(chuàng)時間,則將鄰近句子對應的倒排拉鏈表中的原創(chuàng)時間更新為待插入的網(wǎng)頁的入庫時間等。
2)刪除操作
即指將待刪除的網(wǎng)頁的句子級數(shù)據(jù)從倒排拉鏈表中刪除。
具體地,可針對從待刪除的網(wǎng)頁中提取出的每個句子,分別對該句子對應的倒排拉鏈表以及該句子的鄰近句子對應的倒排拉鏈表進行更新。
其中,對該句子對應的倒排拉鏈表進行更新可包括:如果倒排拉鏈表中的入庫時間為待刪除的網(wǎng)頁的入庫時間,那么則選出采集者列表中除待刪除的網(wǎng)頁之外的其它各網(wǎng)頁中入庫時間最早的網(wǎng)頁,用選出的網(wǎng)頁的url簽名和入庫時間替代倒排拉鏈表中的原創(chuàng)url簽名及入庫時間,并且,將倒排拉鏈表中的拉鏈長度減一,將待刪除的網(wǎng)頁的url簽名及入庫時間從采集者列表中刪除等。
對該句子的鄰近句子對應的倒排拉鏈表進行更新可包括:將鄰近句子對應的倒排拉鏈表中的鄰近拉鏈總長度減一,如果鄰近句子對應的倒排拉鏈表中的原創(chuàng)時間為待刪除的網(wǎng)頁的入庫時間,則更新鄰近句子對應的倒排拉鏈表中的原創(chuàng)時間等。
3)更新操作
比如,對于已經(jīng)存在于倒排拉鏈表中的網(wǎng)頁,如果其內(nèi)容發(fā)生了變更,那么則可執(zhí)行更新操作。
更新操作可由刪除操作和插入操作組成,即先執(zhí)行刪除操作,再執(zhí)行插入操作,不再贅述。
除上述插入、刪除和更新操作外,在實際應用中,還可能會涉及到一些其它操作,比如人工干預以及天級例行的原創(chuàng)url填充等。
人工干預:一個可能的場景是,某個url的站長投訴,該url才是原創(chuàng),這種情況,經(jīng)核實后,可更新該url的入庫時間,并執(zhí)行更新操作。
天級例行的原創(chuàng)url填充:存在這樣的場景,對于某個句子對應的倒排拉鏈表,其采集者列表中的全部url簽名及入庫時間均被刪除,這樣會導致倒排拉鏈表中的原創(chuàng)url簽名及入庫時間為空,那么則需要對倒排拉鏈表中的原創(chuàng)url簽名及入庫時間進行填充,如利用包含倒排拉鏈表對應的句子的網(wǎng)頁中除刪除的網(wǎng)頁之外的其它網(wǎng)頁中入庫時間最早的網(wǎng)頁的url簽名及入庫時間進行填充。
三)原創(chuàng)性識別
通過上述操作,即可維護一個可隨時訪問的句子級的原創(chuàng)查找詞典,基于該原創(chuàng)查找詞典,即可對所有建到倒排拉鏈表中即保存在數(shù)據(jù)庫中的網(wǎng)頁的原創(chuàng)性進行識別/評估。
具體地,針對待識別的網(wǎng)頁,可首先識別出從中提取出的各句子是否為原創(chuàng)句子。
本發(fā)明中支持精確識別和模糊識別兩種方式,倒排拉鏈表的結構和操作上均支持這兩種識別方式,系統(tǒng)的可擴展性很高。
其中,精確識別的方式可為:
針對從待識別的網(wǎng)頁中提取出的每個句子,分別進行以下處理:
根據(jù)該句子的句子簽名確定出該句子對應的倒排拉鏈表;
將待識別的網(wǎng)頁的入庫時間與對應的倒排拉鏈表中的入庫時間進行比較,若待識別的網(wǎng)頁的入庫時間早于或等于對應的倒排拉鏈表中的入庫時間,則確定該句子為原創(chuàng)句子。
模糊識別的方式可為:
針對從待識別的網(wǎng)頁中提取出的每個句子,分別進行以下處理:
根據(jù)該句子的句子簽名確定出該句子對應的倒排拉鏈表;
將待識別的網(wǎng)頁的入庫時間與對應的倒排拉鏈表中的原創(chuàng)時間進行比較,若待識別的網(wǎng)頁的入庫時間早于或等于對應的倒排拉鏈表中的原創(chuàng)時間,則確定該句子為原創(chuàng)句子。
在分別識別出待識別的網(wǎng)頁中的各句子是否為原創(chuàng)句子之后,即可根據(jù)識別結果確定出待識別的網(wǎng)頁的原創(chuàng)性。
比如,可首先計算出從待識別的網(wǎng)頁中提取出的各句子的權值之和,從而得到第一相加結果,如何獲取句子的權值可參照一)中的說明。
之后,可進一步計算出從待識別的網(wǎng)頁中提取出的各句子中的原創(chuàng)句子的權值之和,從而得到第二相加結果。
最后,用第二相加結果除以第一相加結果,將得到的商作為待識別的網(wǎng)頁的原創(chuàng)性評價結果。
對于一個網(wǎng)頁來說,原創(chuàng)性評估結果的取值越大,說明其中的原創(chuàng)內(nèi)容的比例越大,相應地,該網(wǎng)頁的原創(chuàng)性也就越高。
進一步地,可設置一個閾值,具體取值可根據(jù)實際需要而定,當某一網(wǎng)頁的原創(chuàng)性評估結果大于所述閾值時,則可判定該網(wǎng)頁為原創(chuàng)網(wǎng)頁。
通過上述介紹可以看出,采用本發(fā)明所述方案,即便個別句子的提取等略有變化,也不會影響整個網(wǎng)頁的識別結果,從而相比于現(xiàn)有技術提高了識別結果的準確性。
對于原創(chuàng)性越高的網(wǎng)頁,在實際應用中如在進行資源篩選和召回排序時越應該受到優(yōu)待,對于站長和資源產(chǎn)生方來說,他們的創(chuàng)作的價值得到了認可和保護,對于搜索引擎來說,能夠鼓勵站長去創(chuàng)作更多的優(yōu)質(zhì)資源,而不是轉(zhuǎn)載或剽竊他人的成果,經(jīng)過一定時間的積累,搜索引擎就能夠收錄更多的有價值的資源,繁榮搜索生態(tài)。
以上是關于方法實施例的介紹,以下通過裝置實施例,對本發(fā)明所述方案進行進一步說明。
圖2為本發(fā)明所述基于人工智能的網(wǎng)頁原創(chuàng)性識別裝置實施例的組成結構示意圖,如圖2所示,包括:處理單元201以及識別單元202。
處理單元201,用于分別對保存在數(shù)據(jù)庫中的各網(wǎng)頁進行句子提取,并根據(jù)提取出的句子生成句子級的原創(chuàng)查找詞典。
識別單元202,用于根據(jù)原創(chuàng)查找詞典,分別識別出從待識別的網(wǎng)頁中提取出的各句子是否為原創(chuàng)句子,根據(jù)識別結果確定出待識別的網(wǎng)頁的原創(chuàng)性。
其中,處理單元201可按照以下方式分別對每個網(wǎng)頁進行句子提取:
獲取網(wǎng)頁的標題以及正文內(nèi)容;
對正文內(nèi)容進行句子切分,并分別計算切分出的每個句子的權值;
按照權值由大到小的順序?qū)η蟹殖龅母骶渥舆M行排序;
選出排序后處于前m位的句子,m為大于一的正整數(shù),將選出的句子以及標題作為提取出的句子。
在完成句子提取之后,處理單元201可進一步對提取出的句子進行去重處理,并針對去重處理后的每個句子,分別生成一個倒排拉鏈表。
倒排拉鏈表中包括:句子簽名以及入庫時間,入庫時間表示包含倒排拉鏈表對應的句子的網(wǎng)頁中入庫時間最早的網(wǎng)頁的入庫時間。
待識別的網(wǎng)頁通常為保存在數(shù)據(jù)庫中的網(wǎng)頁,識別單元202可針對從待識別的網(wǎng)頁中提取出的每個句子,分別進行以下處理:
根據(jù)該句子的句子簽名確定出該句子對應的倒排拉鏈表;
將待識別的網(wǎng)頁的入庫時間與對應的倒排拉鏈表中的入庫時間進行比較,若待識別的網(wǎng)頁的入庫時間早于或等于對應的倒排拉鏈表中的入庫時間,則確定該句子為原創(chuàng)句子。
倒排拉鏈表中還可進一步包括:原創(chuàng)時間。
處理單元201可按照以下方式來獲取原創(chuàng)時間:
確定出倒排拉鏈表對應的句子的鄰近句子,鄰近句子為與倒排拉鏈表對應的句子的句子簽名之間的海明距離小于預定閾值的句子;
從包含鄰近句子或倒排拉鏈表對應的句子的網(wǎng)頁中選出入庫時間最早的網(wǎng)頁;
將選出的網(wǎng)頁的入庫時間作為原創(chuàng)時間。
相應地,識別單元202可針對從待識別的網(wǎng)頁中提取出的每個句子,分別進行以下處理:
根據(jù)該句子的句子簽名確定出該句子對應的倒排拉鏈表;
將待識別的網(wǎng)頁的入庫時間與對應的倒排拉鏈表中的原創(chuàng)時間進行比較,若待識別的網(wǎng)頁的入庫時間早于或等于對應的倒排拉鏈表中的原創(chuàng)時間,則確定該句子為原創(chuàng)句子。
之后,識別單元202可計算從待識別的網(wǎng)頁中提取出的各句子的權值之和,得到第一相加結果,并計算從待識別的網(wǎng)頁中提取出的各句子中的原創(chuàng)句子的權值之和,得到第二相加結果,用第二相加結果除以第一相加結果,將得到的商作為待識別的網(wǎng)頁的原創(chuàng)性評價結果。
除上述介紹外,處理單元201還可進一步用于,對原創(chuàng)查找詞典執(zhí)行插入、刪除或更新操作,其中,更新操作包括:依次執(zhí)行刪除操作和插入操作。
倒排拉鏈表中還可進一步包括:原創(chuàng)url簽名、拉鏈長度、鄰近拉鏈總長度。
其中,原創(chuàng)url表示包含倒排拉鏈表對應的句子的網(wǎng)頁中入庫時間最早的網(wǎng)頁的url。
拉鏈長度表示包含倒排拉鏈表對應的句子的網(wǎng)頁數(shù)。
鄰近拉鏈總長度表示倒排拉鏈表對應的句子的拉鏈長度以及倒排拉鏈表對應的句子的鄰近句子的拉鏈長度之和。
句子簽名、原創(chuàng)url簽名、入庫時間、原創(chuàng)時間、拉鏈長度、鄰近拉鏈總長度共同組成倒排拉鏈表中的拉鏈頭數(shù)據(jù)。
倒排拉鏈表中還可進一步包括:采集者列表。
采集者列表中可包括:包含倒排拉鏈表對應的句子的網(wǎng)頁中前n個入庫的網(wǎng)頁的url簽名及入庫時間,n為大于一的正整數(shù)。
相應地,處理單元202可按照以下方式執(zhí)行插入操作:
對待插入的網(wǎng)頁進行句子提取,并針對從待插入的網(wǎng)頁中提取出的每個句子,分別進行以下處理:
確定是否存在該句子對應的倒排拉鏈表;
如果否,則建立該句子對應的倒排拉鏈表,并對該句子的鄰近句子對應的倒排拉鏈表進行更新;
如果是,則對該句子對應的倒排拉鏈表以及該句子的鄰近句子對應的倒排拉鏈表進行更新。
處理單元202可按照以下方式執(zhí)行刪除操作:針對從待刪除的網(wǎng)頁中提取出的每個句子,分別對該句子對應的倒排拉鏈表以及該句子的鄰近句子對應的倒排拉鏈表進行更新。
圖2所示裝置實施例的具體工作流程等請參照前述方法實施例中的相應說明,此處不再贅述。
圖3示出了適于用來實現(xiàn)本發(fā)明實施方式的示例性計算機系統(tǒng)/服務器12的框圖。圖3顯示的計算機系統(tǒng)/服務器12僅僅是一個示例,不應對本發(fā)明實施例的功能和使用范圍帶來任何限制。
如圖3所示,計算機系統(tǒng)/服務器12以通用計算設備的形式表現(xiàn)。計算機系統(tǒng)/服務器12的組件可以包括但不限于:一個或者多個處理器(處理單元)16,存儲器28,連接不同系統(tǒng)組件(包括存儲器28和處理器16)的總線18。
總線18表示幾類總線結構中的一種或多種,包括存儲器總線或者存儲器控制器,外圍總線,圖形加速端口,處理器或者使用多種總線結構中的任意總線結構的局域總線。舉例來說,這些體系結構包括但不限于工業(yè)標準體系結構(isa)總線,微通道體系結構(mac)總線,增強型isa總線、視頻電子標準協(xié)會(vesa)局域總線以及外圍組件互連(pci)總線。
計算機系統(tǒng)/服務器12典型地包括多種計算機系統(tǒng)可讀介質(zhì)。這些介質(zhì)可以是任何能夠被計算機系統(tǒng)/服務器12訪問的可用介質(zhì),包括易失性和非易失性介質(zhì),可移動的和不可移動的介質(zhì)。
存儲器28可以包括易失性存儲器形式的計算機系統(tǒng)可讀介質(zhì),例如隨機存取存儲器(ram)30和/或高速緩存存儲器32。計算機系統(tǒng)/服務器12可以進一步包括其它可移動/不可移動的、易失性/非易失性計算機系統(tǒng)存儲介質(zhì)。僅作為舉例,存儲系統(tǒng)34可以用于讀寫不可移動的、非易失性磁介質(zhì)(圖3未顯示,通常稱為“硬盤驅(qū)動器”)。盡管圖3中未示出,可以提供用于對可移動非易失性磁盤(例如“軟盤”)讀寫的磁盤驅(qū)動器,以及對可移動非易失性光盤(例如cd-rom,dvd-rom或者其它光介質(zhì))讀寫的光盤驅(qū)動器。在這些情況下,每個驅(qū)動器可以通過一個或者多個數(shù)據(jù)介質(zhì)接口與總線18相連。存儲器28可以包括至少一個程序產(chǎn)品,該程序產(chǎn)品具有一組(例如至少一個)程序模塊,這些程序模塊被配置以執(zhí)行本發(fā)明各實施例的功能。
具有一組(至少一個)程序模塊42的程序/實用工具40,可以存儲在例如存儲器28中,這樣的程序模塊42包括——但不限于——操作系統(tǒng)、一個或者多個應用程序、其它程序模塊以及程序數(shù)據(jù),這些示例中的每一個或某種組合中可能包括網(wǎng)絡環(huán)境的實現(xiàn)。程序模塊42通常執(zhí)行本發(fā)明所描述的實施例中的功能和/或方法。
計算機系統(tǒng)/服務器12也可以與一個或多個外部設備14(例如鍵盤、指向設備、顯示器24等)通信,還可與一個或者多個使得用戶能與該計算機系統(tǒng)/服務器12交互的設備通信,和/或與使得該計算機系統(tǒng)/服務器12能與一個或多個其它計算設備進行通信的任何設備(例如網(wǎng)卡,調(diào)制解調(diào)器等等)通信。這種通信可以通過輸入/輸出(i/o)接口22進行。并且,計算機系統(tǒng)/服務器12還可以通過網(wǎng)絡適配器20與一個或者多個網(wǎng)絡(例如局域網(wǎng)(lan),廣域網(wǎng)(wan)和/或公共網(wǎng)絡,例如因特網(wǎng))通信。如圖3所示,網(wǎng)絡適配器20通過總線18與計算機系統(tǒng)/服務器12的其它模塊通信。應當明白,盡管圖中未示出,可以結合計算機系統(tǒng)/服務器12使用其它硬件和/或軟件模塊,包括但不限于:微代碼、設備驅(qū)動器、冗余處理單元、外部磁盤驅(qū)動陣列、raid系統(tǒng)、磁帶驅(qū)動器以及數(shù)據(jù)備份存儲系統(tǒng)等。
處理器16通過運行存儲在存儲器28中的程序,從而執(zhí)行各種功能應用以及數(shù)據(jù)處理,例如實現(xiàn)圖1所示實施例中的方法,即分別對保存在數(shù)據(jù)庫中的各網(wǎng)頁進行句子提取,根據(jù)提取出的句子生成句子級的原創(chuàng)查找詞典,根據(jù)原創(chuàng)查找詞典,分別識別出從待識別的網(wǎng)頁中提取出的各句子是否為原創(chuàng)句子,根據(jù)識別結果確定出待識別的網(wǎng)頁的原創(chuàng)性等。具體實現(xiàn)請參照前述方法實施例中的相應說明,此處不再贅述。
本發(fā)明同時公開了一種計算機可讀存儲介質(zhì),其上存儲有計算機程序,該程序被處理器執(zhí)行時將實現(xiàn)如圖1所示實施例中的方法。
可以采用一個或多個計算機可讀的介質(zhì)的任意組合。計算機可讀介質(zhì)可以是計算機可讀信號介質(zhì)或者計算機可讀存儲介質(zhì)。計算機可讀存儲介質(zhì)例如可以是——但不限于——電、磁、光、電磁、紅外線、或半導體的系統(tǒng)、裝置或器件,或者任意以上的組合。計算機可讀存儲介質(zhì)的更具體的例子(非窮舉的列表)包括:具有一個或多個導線的電連接、便攜式計算機磁盤、硬盤、隨機存取存儲器(ram)、只讀存儲器(rom)、可擦式可編程只讀存儲器(eprom或閃存)、光纖、便攜式緊湊磁盤只讀存儲器(cd-rom)、光存儲器件、磁存儲器件、或者上述的任意合適的組合。在本文件中,計算機可讀存儲介質(zhì)可以是任何包含或存儲程序的有形介質(zhì),該程序可以被指令執(zhí)行系統(tǒng)、裝置或者器件使用或者與其結合使用。
計算機可讀的信號介質(zhì)可以包括在基帶中或者作為載波一部分傳播的數(shù)據(jù)信號,其中承載了計算機可讀的程序代碼。這種傳播的數(shù)據(jù)信號可以采用多種形式,包括——但不限于——電磁信號、光信號或上述的任意合適的組合。計算機可讀的信號介質(zhì)還可以是計算機可讀存儲介質(zhì)以外的任何計算機可讀介質(zhì),該計算機可讀介質(zhì)可以發(fā)送、傳播或者傳輸用于由指令執(zhí)行系統(tǒng)、裝置或者器件使用或者與其結合使用的程序。
計算機可讀介質(zhì)上包含的程序代碼可以用任何適當?shù)慕橘|(zhì)傳輸,包括——但不限于——無線、電線、光纜、rf等等,或者上述的任意合適的組合。
可以以一種或多種程序設計語言或其組合來編寫用于執(zhí)行本發(fā)明操作的計算機程序代碼,所述程序設計語言包括面向?qū)ο蟮某绦蛟O計語言—諸如java、smalltalk、c++,還包括常規(guī)的過程式程序設計語言—諸如”c”語言或類似的程序設計語言。程序代碼可以完全地在用戶計算機上執(zhí)行、部分地在用戶計算機上執(zhí)行、作為一個獨立的軟件包執(zhí)行、部分在用戶計算機上部分在遠程計算機上執(zhí)行、或者完全在遠程計算機或服務器上執(zhí)行。在涉及遠程計算機的情形中,遠程計算機可以通過任意種類的網(wǎng)絡——包括局域網(wǎng)(lan)或廣域網(wǎng)(wan)—連接到用戶計算機,或者,可以連接到外部計算機(例如利用因特網(wǎng)服務提供商來通過因特網(wǎng)連接)。
在本發(fā)明所提供的幾個實施例中,應該理解到,所揭露的裝置和方法等,可以通過其它的方式實現(xiàn)。例如,以上所描述的裝置實施例僅僅是示意性的,例如,所述單元的劃分,僅僅為一種邏輯功能劃分,實際實現(xiàn)時可以有另外的劃分方式。
所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位于一個地方,或者也可以分布到多個網(wǎng)絡單元上。可以根據(jù)實際的需要選擇其中的部分或者全部單元來實現(xiàn)本實施例方案的目的。
另外,在本發(fā)明各個實施例中的各功能單元可以集成在一個處理單元中,也可以是各個單元單獨物理存在,也可以兩個或兩個以上單元集成在一個單元中。上述集成的單元既可以采用硬件的形式實現(xiàn),也可以采用硬件加軟件功能單元的形式實現(xiàn)。
上述以軟件功能單元的形式實現(xiàn)的集成的單元,可以存儲在一個計算機可讀取存儲介質(zhì)中。上述軟件功能單元存儲在一個存儲介質(zhì)中,包括若干指令用以使得一臺計算機設備(可以是個人計算機,服務器,或者網(wǎng)絡設備等)或處理器(processor)執(zhí)行本發(fā)明各個實施例所述方法的部分步驟。而前述的存儲介質(zhì)包括:u盤、移動硬盤、只讀存儲器(rom,read-onlymemory)、隨機存取存儲器(ram,randomaccessmemory)、磁碟或者光盤等各種可以存儲程序代碼的介質(zhì)。
以上所述僅為本發(fā)明的較佳實施例而已,并不用以限制本發(fā)明,凡在本發(fā)明的精神和原則之內(nèi),所做的任何修改、等同替換、改進等,均應包含在本發(fā)明保護的范圍之內(nèi)。
- 還沒有人留言評論。精彩留言會獲得點贊!