一種組合模型樹的截面擬合方法與流程
本發明涉及核反應堆設計
技術領域:
,具體涉及一種組合模型樹的截面擬合方法。
背景技術:
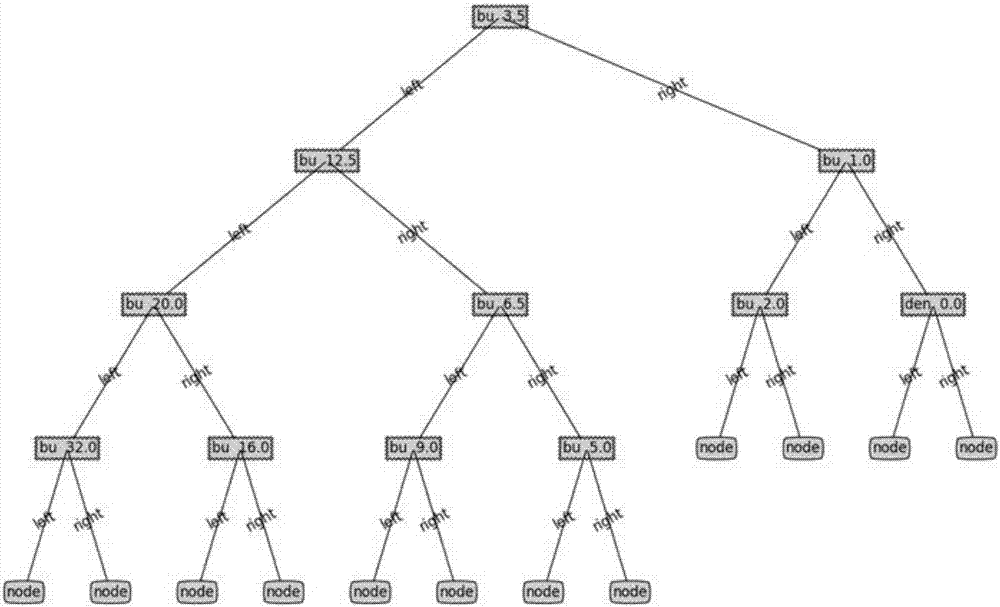
:基于均勻化的反應堆堆芯物理計算框架中,首先利用組件程序的計算結果,基于柵元尺度或組件尺度將幾何均勻化,在能量尺度將能群壓縮至2群~7群之間,得到均勻化截面參數,然后堆芯程序求解這種簡單幾何、少群輸運/擴散方程。對壓水堆堆芯,均勻化截面和燃耗、熱工參數、硼濃度等參數相關。組件程序預先計算一系列離散狀態點的截面值,制作成截面庫供堆芯程序插值使用。若所有狀態參數不做分離處理,則組件程序需要計算狀態點會急劇增加(由狀態點求和變為求積)。目前大多數程序設計中,截面采用主項和多個分項之和的方法,每一項考慮燃耗和其他部分狀態參數的聯合變化。對于同一堆型,狀態參數的組合較為固定。截面庫插值方法中分段查表/插值方法精度最高,但存儲量較大。對pin-by-pin微觀燃耗的壓水堆堆芯計算方法,估計堆芯包含10種組件類型,每種組件包含45個不同的柵元,每個柵元包含了200個微觀/宏觀截面,燃耗點50個,非燃耗參數的狀態點20個,總共約9×107個浮點數,存儲空間約700mb。若為超臨界水堆、高溫氣冷堆等其它復雜堆芯,所需的狀態參數和參數點更多。為了節省少群截面庫的存儲,早期的程序設計采用最小二乘擬合多項式的方式。這種方式能夠明顯節省存儲,但由于擬合公式多為全局性質而非分段,精度受限于擬合公式的選擇和組合。技術實現要素:本發明提供一種組合模型樹的截面擬合方法,在保證擬合精度的同時,減小截面庫的存儲量。本發明通過下述技術方案實現:一種組合模型樹的截面擬合方法,包括以下步驟:1)、截面表達式的建立:截面表達式按截面狀態參數組合展開為一個主項加多個分項;2)、截面擬合:主項和各分項分別采用模型樹方法進行擬合和剪枝;其中,所述模型樹方法在計算過程中只選取燃耗作為可劃分變量,擬合多項式包含狀態參數的耦合二次項。目前,現有的核反應堆堆芯的截面擬合方法中,截面庫插值方法中分段查表/插值方法精度最高,但存儲量較大;最小二乘擬合多項式的方式能夠明顯節省存儲,但由于擬合公式多為全局性質而非分段,精度受限于擬合公式的選擇和組合;分段多項式擬合方法的精度能夠達到分段線性插值的精度,擬合所需數據量約為分段線性插值的50%。但參數的分段點和擬合階數需要使用者根據經驗或嘗試來手動設定[高盛楠論文]。截面擬合本質上是一個回歸問題。作為回歸方法的一種,模型樹方法繼承了分段擬合的思想,按照局部最優劃分逐步遞歸得到數據劃分。但模型樹方法作為一個普適的方法,節點的擬合采用線性多項式,不具體考慮截面和狀態參數之間的依賴關系,可能導致分段劃分區域過多。截面采用主項加多個分項的表達方式能夠在不增加組件程序計算量的情況下,保證模型樹訓練的數據量,即減少了組件程序的計算量,同時保證了每個分項訓練數據集的充分性。本發明根據截面變化的物理特點,對模型樹算法進行了針對性的改進,改進點包括1)只選取燃耗作為可劃分變量,2)擬合多項式不限于線性,包含狀態參數的耦合二次項,比如歷史參數相關分項的擬合多項式添加了燃耗和歷史參數的耦合項,主項添加了慢化劑密度和硼濃度乘積項。以壓水堆為例,選擇燃耗、硼濃度和慢化劑密度作為主項的狀態參數,各分項狀態參數(這里指變化的狀態參數,不變的狀態參數取基準值)均包含燃耗,同時將燃料溫度、控制棒、歷史硼濃度、歷史慢化劑密度和歷史燃料溫度分別作為各分項的狀態參數,共有5個分項。分項對應的數值是該狀態參數下截面值和基準狀態參數下截面值之差。截面表達式見式(1)。式中,bu為燃耗,bor為硼濃度,den為慢化劑密度,tfu為燃料溫度,cr為控制棒插入份額,hbor為歷史硼濃度,hden為歷史慢化劑密度,htfu為歷史燃料溫度。相應的截面值由組件程序計算提供。下標base指主項,其余分項用δ表示,表示分項導致的截面與主項計算截面(base)的偏離。如果不按照上述方式,則組件計算程序需要計算所有狀態參數所有取值點的乘積個組件狀態,其計算量過于巨大。為此將狀態參數分離,影響較密切的分在一個組,并且把影響最大的那個分組的截面計算作為主項(base),認為組與組之間對截面的影響是相互獨立可分離的,就可以選擇各分項與主項之差作為分項,然后求和得到最終的截面。這樣,組件計算計算時,所需計算的狀態數目變為各項內的狀態參數取值點乘積然后求和,數目明顯減少,極大節省了組件計算量。參數的選擇和分組是從實際計算經驗出發,其中主項選擇對截面影響最大的燃耗、硼濃度和慢化劑密度。模型樹方法采用剪枝能夠進一步提高模型樹的泛化能力。泛化能力是指我們希望對于訓練集之外的輸入(其正確的輸出并沒有在訓練集中給出)能夠產生正確的輸出,訓練集上訓練的模型在多大程度上能夠對新的實例預測出正確輸出稱為泛化。剪枝算法能夠提高模型樹的泛化能力,但需要額外提供測試數據,意味著組件程序需要提供額外的計算。當組件程序計算的狀態點較少時,比如慢化劑密度只覆蓋熱態零功率到滿功率的變化區間,所需的溫度分支點約3~5個。但燃耗狀態點通常在50個以上,因此構建樹時,僅采用燃耗狀態作為劃分變量,保證其他狀態參數數據的充裕。另一方面,考慮到歷史效應隨燃耗增加而增加,節點的擬合多項式添加燃耗和歷史參數的耦合項,能夠更好的接近物理真實。本發明在建立截面表達式的時候考慮到了截面和狀態參數之間的依賴關系,通過模型樹方法進行擬合和剪枝不僅能夠確保擬合精度,減小存儲量,而且還能增加泛化能力,同時,本發明述模型樹方法在計算過程中只選取燃耗作為可劃分變量,擬合多項式包含狀態參數的耦合項,進而所需的訓練數據集不會額外增加組件程序的計算量。進一步地,所述主項的表達:根據經驗將狀態參數按相互影響的緊密程度進行分組,其中燃耗作為最主要參數在每個分組都被包含,并選擇影響最大的狀態參數組合作為主項;其余狀態參數組合作為分項。進一步地,所述模型樹方法選用的模型樹為二叉樹,所述擬合是指從二叉樹的根節點開始,選取最優劃分,將訓練數據劃分為兩個子集,再遞歸對每個子集進行最優劃分,直至滿足停止劃分的條件為止,模型樹方法中葉節點對應的數據集采用多項式擬合。具體地,模型樹的頂部節點稱為葉節點,模型樹的底部節點稱為根節點,其余節點稱為內部節點。模型樹方法中葉節點對應的數據集采用線性多項式。內部節點對應了一個數據劃分的規則,即某個狀態參數的某個取值。具體地,劃分的停止條件:1)當數據集內數據數目小于某個預先給定值toln;2)劃分的偏差平方和和不劃分的偏差平方和相差小于某個預先給定值tole。滿足任意一個就停止劃分。本質上,模型樹是一個分段/分片一階多項式擬合方法,從葉節點回溯到根節點對應所有內部節點表征了葉節點多項式對應的分片空間。如果上述toln取值過小,或tole取值過小,則生成的模型樹會有非常多的葉節點,導致過擬合。進一步地,所述最優劃分是指遍歷訓練數據集的所有狀態參數的所有取值,按該取值將訓練數據集劃分為兩個子集,對各子集數據分別進行多項式擬合,計算擬合結果與原值的偏差的平方和,選取偏差平方和最小的劃分作為最優劃分。進一步地,所述剪枝是對停止劃分條件的優化。為避免過擬合的發生,要選擇合適toln和tole。具體地,選取典型狀態,除燃耗外的狀態參數與訓練數據集中的狀態參數應不一致,執行組件計算得到測試用數據。針對測試數據,比較葉節點上一級節點對應數據的計算偏差平方和與兩個葉節點的計算偏差平方和,若前者小于后者,則則認為模型樹存在過擬合(overfitting),泛化能力不足,需要將兩個葉節點合并,稱為剪枝。依次遞歸直至所有的上一級節點的偏差大于葉節點的偏差。本發明與現有技術相比,具有如下的優點和有益效果:1、本發明通過模型樹方法進行截面擬合,能夠顯著減小存儲量。2、本發明根據實際應用對象特點,在建立截面表達式的采用主項+分項的方式,并針對性的改進了模型樹方法,只選取燃耗作為可劃分變量,擬合多項式包含狀態參數的耦合項,使得所需的訓練數據集不會額外增加組件程序的計算量,同時確保了擬合精度,具有較強的泛化能力。附圖說明此處所說明的附圖用來提供對本發明實施例的進一步理解,構成本申請的一部分,并不構成對本發明實施例的限定。在附圖中:圖1為熱群吸收截面主項的原始模型樹;圖2為熱群吸收截面主項的剪枝模型樹;圖3為熱群吸收截面主項的最終模型樹。具體實施方式為使本發明的目的、技術方案和優點更加清楚明白,下面結合實施例和附圖,對本發明作進一步的詳細說明,本發明的示意性實施方式及其說明僅用于解釋本發明,并不作為對本發明的限定。實施例:本發明提供了一種組合模型樹的截面擬合方法。本發明選擇典型載硼玻璃管毒物的afa3g組件作為計算對象。組件富集度3.1%,載有20根硼玻璃管毒物。狀態參數取值如表1所示。對硼濃度、慢化劑密度和燃料溫度的瞬時值和歷史值選點是一致的,基準值均為表中數據的第二個值。該組件裝載了毒物棒,因此沒有控制棒分量。根據經驗,將硼濃度和慢化劑密度的耦合作為主項。按基準狀態燃耗作為主線計算,共有79個燃耗點;硼濃度和慢化劑密度考慮二者耦合,沿主線的再啟動計算79×(3×3-1)個狀態點;燃料溫度沿主線再啟動計算79×(3-1)個狀態點;歷史硼濃度、歷史慢化劑密度和歷史燃料溫度各按支線燃耗計算79×2個狀態點。關于歷史參數的支線燃耗計算中,對應的瞬時值和歷史值取值一樣,為此在支線燃耗上做再啟動使得瞬時值取基準值。對歷史參數的擬合,訓練數據集只選擇相應再啟動的數據集。總共組件計算的狀態點規模為1817,訓練用的規模為1343。如果所有因素都要聯合考慮,則按表1的取點所需計算的狀態點數目將達到57591。圖1為熱群吸收截面主項的訓練模型樹,圖中最上部標識為“bu”的節點為根節點,最下部標為“node”的為葉節點,這里的模型樹可劃分項沒有只限定為燃耗,擬合多項式未包含狀態參數間的耦合項,其中toln取值為4,tole取值為1e-7。由圖1知,只有三個劃分項是非燃耗項,而且靠近樹的葉節點。圖2為該模型樹采用表2測試數據后剪枝后的模型樹。由圖2知,減去了圖左下角的關于硼濃度的兩個節點。這說明燃耗項作為模型樹訓練的主要劃分項,剪枝過程說明非燃耗項作為劃分項存在過擬合的可能。因此僅以燃耗作為劃分項能夠提高模型樹的泛化能力。圖3為本發明最終算法訓練的模型樹,即限定燃耗項,擬合多項式添加了慢化劑密度和硼濃度乘積項。選取與訓練數據集和剪枝數據集不相交的驗證數據集衡量擬合精度,驗證數據集的狀態參數見表3。表4列出了熱群吸收截面的偏差結果。作為更綜合的考慮,表5列出了由吸收截面、裂變中子產生截面和散射截面計算的無限增殖系數kinf的擬合偏差。由計算結果知,最終的組合模型樹具有較好的泛化能力,剪枝模型樹的kinf泛化能力較好,原始模型樹存在過擬合現象。表6列出了模型樹的存儲量比較結果。由表知,本發明提出的組合模型樹方法在保證kinf精度在300pcm以內的同時所需存儲量僅為線性查表方法的10%。表1訓練數據集的狀態參數取值表2剪枝數據集的狀態參數取值硼濃度,ppm300.0,900.0共2個點慢化劑密度,g/cm30.704759,0.746201共2個點表3驗證數據集的狀態參數取值表4熱群吸收截面驗證結果原始模型樹剪枝模型樹最終模型樹最大絕對誤差0.000570.00050-0.00041最大相對誤差-0.00716-0.00745-0.00352相關系數r0.999660.999670.99977相關系數r是指組件程序計算值x和模型樹預測值y的相關系數,滿足下式越接近1表明符合越好表5無限增殖因子kinf驗證結果原始模型樹剪枝模型樹最終模型樹最大絕對誤差0.011810.003880.00255最大相對誤差0.01199-0.003800.00250相關系數r0.999730.999910.99995表6存儲量比較n為采用原始模型樹所需的浮點數存儲數目;m為原始模型樹存儲比,即采用原始模型樹所需的浮點數存儲數目與線性查表方式所需浮點數目的比值。以上所述的具體實施方式,對本發明的目的、技術方案和有益效果進行了進一步詳細說明,所應理解的是,以上所述僅為本發明的具體實施方式而已,并不用于限定本發明的保護范圍,凡在本發明的精神和原則之內,所做的任何修改、等同替換、改進等,均應包含在本發明的保護范圍之內。當前第1頁12
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1