一種基于多元化地理信息點的融合方法與流程
本發明涉及一種基于多元化地理信息點的融合方法,屬于地理信息處理技術領域。
背景技術:
近年來,隨著網絡的大規模發展,各種信息資源的數量急劇增長,計算機對地理名稱、坐標信息等各種自然語言處理應用的普及,人們需要一個快速且準確的方法來計算多個地理信息點之間的信息相似度。尤其,短文本相似度的計算具有十分重要的作用,它的應用能夠極大地提高識別多個地理信息點的精度。另外,地圖中的經緯度信息對于鄰近區域的查詢具有很大的便利,建立地理信息點的融合方法對查詢起到非常重要的作用。
對于約占人類信息80%左右的地理信息來說,由于具有分布性、多樣性、復雜性的特點,給地理信息的共享和操作帶來了許多不便。大部分地理信息是表示在不同地圖上的,面對浩如煙海的地理信息,能夠快速、準確、高質量地從中抽取出用戶所關心、真正有用的信息這一需求日益迫切,然而,對于提取到的地理信息處理手段較弱,導致信息排查困難和信息利用率低下。同時,目前地理信息資源的提供者對數據的描述值停留在數據的表明層次上,數據之間缺乏必要的關聯,從而直接影響到用戶獲取信息的速度和效率。快速并高質量的融合方法可以將大量地理信息進行分類處理,找出匹配的信息點,以及不匹配的信息點,從而通過這種方法來減輕工作量,方便人們對地理信息的充分利用。
由于越來越多的短文本應用的出現,比如電子文本,地理信息和地圖信息,人們對短文本處理的需求日益迫切。但是對于短文本而言,因為相似的短文本并不一定有相同的詞,自然語言的靈活性使得人們可以通過不同的措詞表達相同的意思,所以現有的相似度計算方法應用效果并不很好,例如在對地理位置名稱的數據處理中表現不佳。此外,傳統的文本相似度計算過程中,對文本的表達方式通常去掉停用詞,比如“的”,“是”,“中”等等,但是在對短文本的處理過程中,因為它們蘊含了一些句子的結構信息,所以一些停用詞不能被忽略,這使得傳統的文本相似度計算方法在處理短文本的文本相似度計算過程中不能得到很好的結果。
對文本相似度計算而言,常用的文本間相似度計算方法是余弦相似度方法,該方法將文本看作空間中的一個點并將其表示為向量形式,利用向量之間的夾角大小來定量地計算文本間相似度,該方法沒有考慮文本間具有相同語義的特征詞,不能充分體現文本之間的語義相似性。因此,現有相似度計算方法存在大量的缺點和疏漏。
技術實現要素:
本發明要解決的技術問題是提供一種基于多元化地理信息點的融合方法,通過在不同地理參考坐標系的地圖中找到某個相同的區域,進行地理信息數據匹配并尋找出不同地圖的地理信息是否有相同的信息點。
本發明的技術方案是:一種基于多元化地理信息點的融合方法,具體步驟為:
(a)、信息提取及預處理:在不同地理參考坐標系的地圖中,首先進行地圖坐標的變換,再找到某個相同區域的地理信息點,然后將提取到的地理信息按照地理名稱、經緯度坐標等不同類別進行分類;
(b)、地理信息中的地理名稱首先定義相似度:包括分詞后的相似度處理、命名實體識別后的相似度處理、排列組合和加法運算四個步驟,根據計算兩個相似度值得出的結果情況來判斷,如果不相似,則匹配結束,多個地理信息點的地理名稱不相同;如果相似或不確定,則進行多個地理信息點經緯度距離之間的匹配;
(c)、經緯度信息處理:通過計算多個地理信息點兩兩之間的經緯度距離來判斷,如果兩兩之間的距離差值大于某一個門限δ,則這幾個地理信息點不匹配;如果兩兩之間的距離差值小于某一個門限δ,則這幾個地理信息點匹配。
(d)、相似度結果情況展示:根據得出的最終結果情況,在不同的地圖上用不同的顏色標注出來,來判定是否為同一地理信息點。
所述步驟(b)中地理名稱的相似度處理,具體包括如下步驟:
(b1)、根據文本分詞后的結果計算得到一個相似度值;
(b2)、根據文本命名實體識別后的結果計算得到另一個相似度值;
(b3)、通過排列組合和加法運算來得出最終的結果情況;
(b4)、判斷多個地理信息文本是否相似。
所述步驟(b1)中計算句子相似度包括下列步驟:
(b11)、給定一個句子x1,經過漢語分詞系統分詞后,得到的所有詞yi構成句子x1的向量表示,分詞后的向量表示x1=[y1,y2,......,yn];給定句子x2,同理,分詞后的向量表示x2=[y1,y2,......,ym];
(b12)、x1中詞的個數是x1的向量長度,用len(x1)表示;同理,x2的向量長度表示為len(x2);
(b13)、將x1、x2中所有的所有詞yi進行合并,對于重復出現的詞只保留一個,由此得到兩個向量之和,稱為x1、x2的并集,表示x=x1ux2=[y1,y2,......,ym,yn],則并集長度len(x)<=len(x1)+len(x2);
(b14)、依次計算x1和x2的集合x中的y1、y2、......、ym、yn在x1中每一個詞的相似度(值為0到1之間),并將所有結果中的最大值稱為yi在x1中的語義分數,用zi表示;x中每個分詞的語義分數組成的一個向量稱為x1基于x的語義向量,表示為w1=[z1,z2,...,zn],對于x中的每一個詞yi,如果yi在x1中出現,則在語義向量w1中將yi的語義分數zi設為1;如果x1中不包含yi,則計算yi在x1中的語義分數zi=n(n為預先設定的閾值,無閾值設為0,本文中閾值為0.2);
(b15)、語義向量計算語義相似度的計算公式如下:
所述步驟(b3)中還包括下列步驟:
步驟(b31)、把步驟(b1)中和步驟(b2)中得到的多種地圖的相似度值通過一個排列組合,全部排列起來;
步驟(b32)、把排列起來的相似度值通過加法運算,即全部相加;
步驟(b33)、把加起來的相似度值用一個門限m來控制。
所述步驟(b4)中還包括下列步驟:
(b41)、若加法后的相似度值小于門限m,則不相似,匹配結束,多個地理信息文本不相同;
(b42)、如果加法后的相似度值大于門限m或在門限m附近,認為相似或不確定,則進行多個地理信息點經緯度距離之間的匹配。
計算多個地理信息點兩兩之間的經緯度距離,是通過下列公式來計算的(計算的結果單位為米):
wgs84_a=6378137.0為赤道上到地球中心的地球半徑距離,單位為米;
d=d×π÷180為角度轉化成弧度,其中,d為角度;
rade1=rad(e1);
rade2=rad(e2);
a=rade1–rade2為兩點緯度之差;
b=rad(n1)-rad(n2)為兩點經度之差;
s=s1×wgs84_a
其中,e1表示a點緯度,n1表示a點經度,e2表示b點緯度,n2表示b點經度。
本發明的有益效果是:本發明的地理信息點的融合方法改變了人工查詢方式的機械性和低效率;地理信息點的融合方法顯著提高短文本查詢的效率以及文本間語義相似度計算的準確性。
附圖說明
圖1是本發明實施例基于兩種地圖的地理信息點的融合方法流程圖;
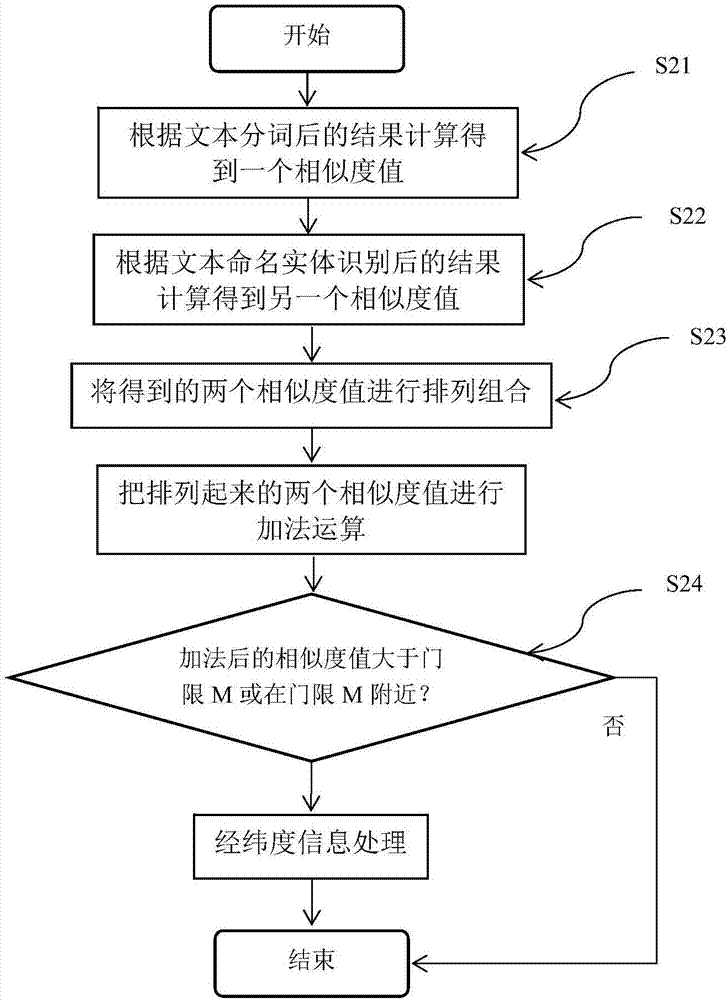
圖2是本發明實施例中地理名稱的相似度處理流程圖;
圖3是本發明實施例基于兩種地圖的地理信息點的融合方法的結構示意圖。
具體實施方式
下面結合附圖和具體實施方式,對本發明作進一步說明。
實施例1:一種基于多元化地理信息點的融合方法,具體步驟為:
(a)、信息提取及預處理:在不同地理參考坐標系的地圖中,首先進行地圖坐標的變換,再找到某個相同區域的地理信息點,然后將提取到的地理信息按照地理名稱、經緯度坐標等不同類別進行分類;
(b)、地理信息中的地理名稱首先定義相似度:包括分詞后的相似度處理、命名實體識別后的相似度處理、排列組合和加法運算四個步驟,根據計算兩個相似度值得出的結果情況來判斷,如果不相似,則匹配結束,多個地理信息點的地理名稱不相同;如果相似或不確定,則進行多個地理信息點經緯度距離之間的匹配;
(c)、經緯度信息處理:通過計算多個地理信息點兩兩之間的經緯度距離來判斷,如果兩兩之間的距離差值大于某一個門限δ,則這幾個地理信息點不匹配;如果兩兩之間的距離差值小于某一個門限δ,則這幾個地理信息點匹配。
(d)、相似度結果情況展示:根據得出的最終結果情況,在不同的地圖上用不同的顏色標注出來,來判定是否為同一地理信息點。
所述步驟(b)中地理名稱的相似度處理,具體包括如下步驟:
(b1)、根據文本分詞后的結果計算得到一個相似度值;
(b2)、根據文本命名實體識別后的結果計算得到另一個相似度值;
(b3)、通過排列組合和加法運算來得出最終的結果情況;
(b4)、判斷多個地理信息文本是否相似。
所述步驟(b1)中計算句子相似度包括下列步驟:
(b11)、給定一個句子x1,經過漢語分詞系統分詞后,得到的所有詞yi構成句子x1的向量表示,分詞后的向量表示x1=[y1,y2,......,yn];給定句子x2,同理,分詞后的向量表示x2=[y1,y2,......,ym];
(b12)、x1中詞的個數是x1的向量長度,用len(x1)表示;同理,x2的向量長度表示為len(x2);
(b13)、將x1、x2中所有的所有詞yi進行合并,對于重復出現的詞只保留一個,由此得到兩個向量之和,稱為x1、x2的并集,表示x=x1ux2=[y1,y2,......,ym,yn],則并集長度len(x)<=len(x1)+len(x2);
(b14)、依次計算x1和x2的集合x中的y1、y2、......、ym、yn在x1中每一個詞的相似度(值為0到1之間),并將所有結果中的最大值稱為yi在x1中的語義分數,用zi表示;x中每個分詞的語義分數組成的一個向量稱為x1基于x的語義向量,表示為w1=[z1,z2,...,zn],對于x中的每一個詞yi,如果yi在x1中出現,則在語義向量w1中將yi的語義分數zi設為1;如果x1中不包含yi,則計算yi在x1中的語義分數zi=n(n為預先設定的閾值,無閾值設為0,本文中閾值為0.2);
(b15)、語義向量計算語義相似度的計算公式如下:
所述步驟(b3)中還包括下列步驟:
步驟(b31)、把步驟(b1)中和步驟(b2)中得到的多種地圖的相似度值通過一個排列組合,全部排列起來;
步驟(b32)、把排列起來的相似度值通過加法運算,即全部相加;
步驟(b33)、把加起來的相似度值用一個門限m來控制。
所述步驟(b4)中還包括下列步驟:
(b41)、若加法后的相似度值小于門限m,則不相似,匹配結束,多個地理信息文本不相同;
(b42)、如果加法后的相似度值大于門限m或在門限m附近,認為相似或不確定,則進行多個地理信息點經緯度距離之間的匹配。
實施例2:如圖1所示,下面進一步詳細說明本發明的基于多元化地理信息點的融合方法。
所述基于兩種地圖的地理信息點的融合方法的具體步驟如下:
步驟s1,信息提取及預處理,是在不同地理參考坐標系的地圖中,首先進行地圖坐標的變換,再找到某個相同區域的地理信息點,然后將提取到的地理信息按照地理名稱、經緯度坐標等不同類別進行分類;
步驟s2,地理信息中的地理名稱首先定義相似度,包括分詞后的相似度處理、命名實體識別后的相似度處理、排列組合和加法運算四個步驟,根據計算兩個相似度值得出的結果情況來判斷,如果不相似,則匹配結束,多個地理信息點的地理名稱不相同;如果相似或不確定,則進行多個地理信息點經緯度距離之間的匹配;
步驟s3,經緯度信息處理,通過計算兩個地理信息點之間的經緯度距離來判斷,如果兩個地理信息點之間的距離差值大于門限δ=100m,則這兩個地理信息點不匹配;如果兩個地理信息點之間的距離差值小于門限δ=100m,則這兩個地理信息點匹配。
步驟s4,相似度結果情況展示,根據得出的最終結果情況,在所選擇的兩個地圖上用不同的顏色展現出來,來判定是否為同一地理信息點;如果最終結果是匹配,則在兩個地圖上用紅色標記出來;如果最終結果是不匹配,則在兩個地圖上用藍色標記出來。
具體地,所述步驟s1中,選擇的兩個地圖是百度地圖和高德地圖,在兩個地圖中找到兩個相同的鄰近區域的地理信息點,包括下列步驟:
打開百度首頁,點擊地圖,然后在百度地圖的右上角,點擊“地圖api”,在api的頁面,把鼠標移動到菜單項“工具”,在下拉菜單中選擇“坐標拾取工具”,接著在搜索欄輸入想要找到的某個區域“大理洱海”,然后“百度一下”,就會在地圖上出現相應的標記,點擊要抓取的某一個點,就能看到相應的坐標,再點擊坐標右邊的“復制”按鈕就完成了第一個抓取地理信息點的工作;
打開高度地圖,在右上角工具欄中選擇標記,然后找到在百度地圖中與之相同的區域“大理洱海”,定位后選擇分享獲取鏈接地址,接著在新建窗口中打開此地址,就能獲取第二個經緯度信息了;
所述步驟s1中,將提取到的信息按照地理名稱、經緯度坐標等不同類別進行分類,是通過建立excel表,地理名稱類放一豎列,經緯度坐標類放一豎列,不同地理參考坐標系的地圖名稱放一行。
具體地,所述地理名稱的相似度處理,如圖2所示,包括下列四個步驟:
步驟s21,根據文本分詞后的結果計算得到一個相似度值(介于0-1之間);
其中,文本分詞使用的是ikanalyzer一個開源的,基于java語言開發的輕量級的中文分詞工具包;以開源項目luence為應用主體的,結合詞典分詞和文法分析算法的中文分詞組件。
本發明實施例中,計算句子相似度,包括下列步驟:
(1)給定一個句子x1:大理祥和旅館,經過漢語分詞系統分詞后,得到的所有詞yi構成句子x1的向量表示。分詞后的向量表示x1=[大,理,祥,和,旅,館];給定句子x2:大理祥和客棧,同理,分詞后的向量表示x2=[大,理,祥,和,客棧];
(2)x1中詞的個數是x1的向量長度,用len(x1)=6表示;同理,x2的向量長度表示為len(x2)=5;
(3)將x1、x2中所有的所有詞yi進行合并,對于重復出現的詞只保留一個,由此得到兩個向量之和,稱為x1、x2的并集,表示x=x1ux2=[大,理,祥,和,旅,館,客棧],則并集長度len(x)=7<=len(x1)+len(x2)=11;
(4)依次計算x1和x2的集合x中的大、理、祥、和、旅、館、客棧,在x1:大理祥和旅館中每一個詞的相似度(值為0到1之間),并將所有結果中的最大值稱為yi在x1中的語義分數,用zi表示。x中每個分詞的語義分數組成的一個向量稱為x1基于x的語義向量,表示為w1=[1,1,1,1,1,1,0.2];(對于x中的每一個詞yi,如果yi在x1中出現,則在語義向量w1中將yi的語義分數zi設為1;如果x1中不包含yi,則計算yi在x1中的語義分數zi=n,n為預先設定的閾值,無閾值設為0,本文中閾值為0.2);同理,x2基于x的語義向量,表示為w1=[1,1,1,1,0.2,0.2,1]。
(5)語義向量計算語義相似度的計算公式如下:
由公式計算得出,大理祥和旅館和大理祥和客棧的語義相似度是0.8304385591050395。
步驟s22,根據文本命名實體識別后的結果計算得到另一個相似度值(介于0-1之間);
其中,文本命名實體識別使用的是hanlp自然語言處理包開源。
本發明實施例中,計算句子相似度,包括下列步驟:
(1)給定句子x1:大理祥和旅館,經過文本命名實體識別后,得到的所有詞yi構成句子x1的向量表示。命名實體識別后的向量表示x1=[大理,祥和,旅館];給定句子x2:大理祥和客棧,同理,命名實體識別后的向量表示x2=[大理,祥和,客棧];
(2)x1中詞的個數是x1的向量長度,用len(x1)=3表示;同理,x2的向量長度表示為len(x2)=3;
(3)將x1、x2中所有的所有詞yi進行合并,對于重復出現的詞只保留一個,由此得到兩個向量之和,稱為x1、x2的并集,表示x=x1ux2=[大理,祥和,旅館,客棧],則并集長度len(x)=4<=len(x1)+len(x2)=6;
(4)依次計算x1和x2的集合x中的大理、祥和、旅館、客棧,在x1:大理祥和旅館中每一個詞的相似度(值為0到1之間),并將所有結果中的最大值稱為yi在x1中的語義分數,用zi表示。x中每個分詞的語義分數組成的一個向量稱為x1基于x的語義向量,表示為w1=[1,1,1,0.2];(對于x中的每一個詞yi,如果yi在x1中出現,則在語義向量w1中將yi的語義分數zi設為1;如果x1中不包含yi,則計算yi在x1中的語義分數zi=n,n為預先設定的閾值,無閾值設為0,本文中閾值為0.2);同理,x2基于x的語義向量,表示為w1=[1,1,0.2,1]。
(5)語義向量計算語義相似度的計算公式如下:
由公式計算得出,大理祥和旅館和大理祥和客棧的語義相似度是0.7894736842105263。
步驟s23,通過排列組合和加法運算來得出最終的結果情況,把s21和s22中得到的兩個地圖的相似度值通過一個排列組合,全部排列起來,然后把排列起來的相似度值通過加法運算,即兩者相加得0.8304385591050395+0.7894736842105263=1.61991223,把加起來的相似度值用一個門限m來控制;
步驟s24,判斷多個地理信息點的地理名稱是否相似,如果加法后的相似度值小于門限m=1,則不相似,匹配結束,兩個地理信息點的地理名稱不相同;如果加法后的相似度值大于門限m=1或在門限m=1附近,認為相似或不確定,則進行兩個地理信息點經緯度距離之間的匹配。由步驟s23加法后的相似度1.61991223得出,1.61991223>1,所以進行兩個地理信息點經緯度距離之間的匹配。
具體地,所述步驟s3中,計算兩個地理信息點之間的經緯度距離,是通過下列公式來計算的(計算的結果單位為米):
wgs84_a=6378137.0為赤道上到地球中心的地球半徑距離,單位為米;
d=d×π÷180為角度轉化成弧度,其中,d為角度;
rade1=rad(e1);
rade2=rad(e2);
a=rade1–rade2為兩點緯度之差;
b=rad(n1)-rad(n2)為兩點經度之差;
s=s1×wgs84_a
其中,e1表示a點緯度,n1表示a點經度,e2表示b點緯度,n2表示b點經度。
由計算得出,大理祥和旅館和大理祥和客棧的經緯度距離小于門限δ=100m,所以,得出這兩個地理信息點匹配;并在百度地圖和谷歌地圖中,用紅色標記這兩個點。
相應地,一種基于多元化地理信息點的融合方法,如圖3所示,包括信息提取及預處理模塊1、地理名稱的相似度處理模塊2、經緯度信息處理模塊3和相似度處理結果展示模塊4,信息提取及預處理模塊1包括至少兩條信息,經緯度信息處理模塊2包括至少兩條經緯度信息,其特征在于,其中:
所述信息提取及預處理模塊1,用于在不同地理參考坐標系的地圖中,首先進行地圖坐標的變換,再找到某個相同區域的地理信息點,然后將提取到的地理信息按照地理名稱、經緯度坐標等不同類別進行分類;
所述地理名稱的相似度處理模塊2,用于根據分詞后的相似度處理、命名實體識別后的相似度處理,來進行排列組合和最后的加法運算,然后根據計算兩個相似度值得出的結果情況來判斷,如果不相似,則匹配結束,多個地理信息點的地理名稱不相同;如果相似或不確定,則進行多個地理信息點經緯度距離之間的匹配。
所述經緯度信息處理模塊3,用于通過計算多個地理信息點兩兩之間的經緯度距離來判斷,如果兩兩之間的距離差值大于某一個門限δ,說明這幾個地理信息點不匹配;如果兩兩之間的距離差值小于某一個門限δ,則這幾個地理信息點匹配。
所述相似度結果情況展示模塊4,根據得出的最終結果情況,在不同的地圖上用不同的顏色展現出來,來判定是否為同一地理信息點。
以上結合附圖對本發明的具體實施方式作了詳細說明,但是本發明并不限于上述實施方式,在本領域普通技術人員所具備的知識范圍內,還可以在不脫離本發明宗旨的前提下作出各種變化。
- 還沒有人留言評論。精彩留言會獲得點贊!