基于使用行為區分電視歸屬屬性的系統與方法與流程
本發明涉及大數據和人工智能技術領域,具體涉及一種基于使用行為區分電視歸屬屬性的系統與方法。
背景技術:
在大數據背景下,采集終端的數據進行分析是大多數終端生產者都在做的事情,智能電視也不例外,電視終端從被激活開始,其數據一直在被采集,大數據平臺開發者想要分析的是用戶的數據,但是,這個終端可能被用戶使用,或者在賣場做展示,也有可能存在工廠或者賣場倉庫中,對于判斷哪一臺屬于用戶正在使用的存在一定困難。
目前使用的區分方式是通過電視上報的經緯度排除其是賣場、工廠機,但是經度1度表示111.11公里,數據稍微有一點點偏差,計算出的地理位置差異很大,而往往終端上報的經緯度精確度是不夠的,因此,這種方法的準確率很低。也有利用ip來計算地理位置的,但用戶和賣場的ip都經常變化,計算出的地理位置更不準確。前述的利用上報經緯度或者ip來計算地理位置的方法,由于經度1度代表的實際地理距離為111.11公里,緯度一度在中國范圍內代表的實際距離也很大,要把地理距離精確度控制在1公里范圍內,經緯度需要精確到小數點后三位,而方圓1公里的精確度都不能準確區分賣場、工廠或者用戶。事實證明,現在的電視終端上報的經緯度完全達不到準確計算地理位置的要求。而ip,由于用戶和賣場的ip不是固定ip,也不能準確的計算地理位置。地理位置計算不準,終端就沒辦法區分賣場、工廠或者用戶。
技術實現要素:
本發明克服了現有技術的不足,提供一種基于使用行為區分電視歸屬屬性的系統與方法,用于解決判斷終端歸屬狀態不準確的技術問題。
考慮到現有技術的上述問題,根據本發明公開的一個方面,本發明采用以下技術方案:
一種基于使用行為區分電視歸屬屬性的方法,包括以下步驟:
步驟一:將電視激活當天開機時間小于一時間設定值且激活后不再開機的、以及所述電視與工廠的距離小于一距離設定值的判定為工廠庫存電視;反之,則將所述電視判定為賣場電視或用戶終端;
步驟二:收集所述賣場電視或用戶終端的使用行為數據,將所述使用行為數據做k-means聚類,根據聚類后各數據在質心中的值的分布來確定對電視歸屬屬性分類有用的數據;
步驟三:根據k-means聚類得到的對電視歸屬屬性分類有用的數據重新做k-means聚類,聚類得到的質心用于計算gmm算法的初始期望、方差,以及初始分布概率;
步驟四:用步驟三中計算出來的參數對賣場電視、用戶終端做gmm聚類,得到賣場電視和用戶終端的正態分布的期望和標準差,以及某一電視屬于所述賣場電視或用戶終端的概率,根據概率大小確定電視的歸屬屬性。
為了更好地實現本發明,進一步的技術方案是:
根據本發明的一個實施方案,所述步驟一中的時間設定值為5分鐘。
根據本發明的另一個實施方案,所述使用行為數據包括:最近賣場的大概距離、某段時間內平均整機開機時長、平均主場景的使用次數和時長、平均app的使用次數和時長。
根據本發明的另一個實施方案,所述步驟二的k-means聚類中,觀察聚類后各類類型的質心對應到各數據的值,如果某類數據在各質心的值層次分明,那么這類數據能有效分類,如果某類數據在各質心較相近,或毫無規律,則它對有效分類作用不大。
根據本發明的另一個實施方案,所述步驟二中篩選后得到的對電視歸屬屬性分類有用的數據包括終端與賣場的距離和整機開機時長。
根據本發明的另一個實施方案,還包括定期抽樣用戶終端,并計算該用戶終端被分為賣場類的比例。
根據本發明的另一個實施方案,還包括定期抽樣查詢在賣場展示終端的mac,并查看這些mac被分為用戶終端的比例。
根據本發明的另一個實施方案,在步驟6與步驟7的比例之和大于一設定比例值的情況下,將數據平臺上所有終端重新做gmm聚類。
根據本發明的另一個實施方案,還包括終端屬性狀態更新:
每天檢查已被分為工廠的終端是否有開機,在有開機的情況,則該終端不再為工廠類,判定被置為賣場或者用戶狀態。
本發明還可以是:
一種基于使用行為區分電視歸屬屬性的系統,包括以下:
用于實現將電視激活當天開機時間小于一時間設定值且激活后不再開機的、以及所述電視與工廠的距離小于一距離設定值的判定為工廠庫存電視,反之,則將所述電視判定為賣場電視或用戶終端的模塊;
用于實現收集所述賣場電視或用戶終端的使用行為數據,將所述使用行為數據做k-means聚類,根據聚類后各數據在質心中的值的分布來確定對電視歸屬屬性分類有用的數據的模塊;
用于實現根據k-means聚類得到的對電視歸屬屬性分類有用的數據重新做k-means聚類,聚類得到的質心用于計算gmm算法的初始期望、方差,以及初始分布概率的模塊;
用于實現根據計算出來的參數對賣場電視、用戶終端做gmm聚類,得到賣場電視和用戶終端的正態分布的期望和標準差,以及某一電視屬于所述賣場電視或用戶終端的概率,根據概率確定電視的歸屬屬性的模塊。
與現有技術相比,本發明的有益效果之一是:
本發明的一種基于使用行為區分電視歸屬屬性的系統與方法,可以從現有已經激活的智能電視終端中準確的區分出工廠終端、用戶終端和賣場終端,以及可跟蹤終端,及時判斷出其歸屬狀態的變化;本發明對判斷終端屬性的準確性和靈活性更高,對單一數據的依賴性大大降低。
附圖說明
為了更清楚的說明本申請文件實施例或現有技術中的技術方案,下面將對實施例或現有技術的描述中所需要使用的附圖作簡單的介紹,顯而易見地,下面描述中的附圖僅是對本申請文件中一些實施例的參考,對于本領域技術人員來講,在不付出創造性勞動的情況下,還可以根據這些附圖得到其它的附圖。
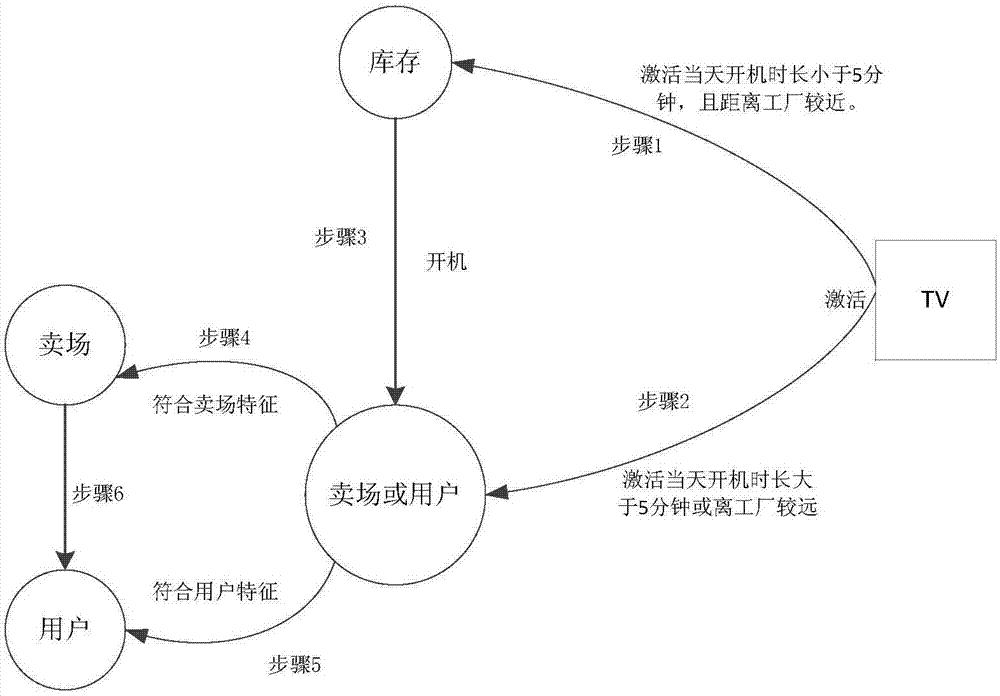
圖1示出了根據本發明一個實施例的電視歸屬屬性轉換流程框圖。
圖2示出了根據本發明一個實施例的聚類流程框圖。
圖3示出了根據本發明一個實施例的狀態更新流程框圖。
具體實施方式
下面結合實施例對本發明作進一步地詳細說明,但本發明的實施方式不限于此。
實施例1
一種基于使用行為區分電視歸屬屬性的方法,包括兩條主線,一條是對電視終端進行屬性分類,一條是根據使用行為及時更新終端的屬性狀態,具體地:
(一)電視終端屬性分類:
步驟一:將電視激活當天開機時間小于一時間設定值且激活后不再開機的、以及所述電視與工廠的距離小于一距離設定值的判定為工廠庫存電視;反之,則將所述電視判定為賣場電視或用戶終端。
由于工廠在電視生產出來后需要對其做測試,然后存入庫存中,如果在聯網測試時被激活,一般測試時間在5分鐘以內,且當天不再開機。同時,工廠的地址有限。因此,優選將開機時長小于等于5分鐘,地理位置離工廠較近的終端判定為工廠終端。
步驟二:收集所述賣場電視或用戶終端的使用行為數據,將所述使用行為數據做k-means聚類,根據聚類后各數據在質心中的值的分布來確定對電視歸屬屬性分類有用的數據。
由于除開工廠終端外,非工廠電視終端的歸屬類型不可知,沒有樣本數據,無法直接使用分類算法訓練分類模型,因此,本實施例首先以大數據平臺上收集到的所有非工廠的用戶的使用行為數據做k-means聚類,根據聚類后各數據在k個質心(中心點)中的值的分布來確定哪些數據對分類有用。
步驟三:根據k-means聚類得到的對電視歸屬屬性分類有用的數據重新做k-means聚類,聚類得到的質心用于計算gmm算法的初始期望、方差,以及初始分布概率。
k-means聚類的原理是將訓練樣本分為k個簇,在不斷迭代的過程中,讓每個樣本與其所屬簇的質心的距離最近,那么每個樣本的類型確定了,且質心各特征的值也確定了。如果某一個特征在k個簇的質心值較相似,或者層次不清,那么說明這個數據特征對分類不起作用,或者作用不明顯。因此,k-means聚類能發現哪些用戶行為對分類有效,哪些行為無用,以此來選擇對分類有效的數據,拿這些有用的數據再深入聚類。
步驟四:用步驟三中計算出來的參數對賣場電視、用戶終端做gmm聚類,得到賣場電視和用戶終端的正態分布的期望和標準差,以及某一電視屬于所述賣場電視或用戶終端的概率,根據概率確定電視的歸屬屬性。
由于用戶和賣場的特征范圍沒有明顯的界定,更符合正態分布。k-means不能準確的聚出用戶和賣場的特征,用基于em算法(最大期望算法)做極大似然的gmm模型(混合高斯模型)對賣場、用戶終端進行聚類,分出賣場和用戶終端,并得到賣場和用戶的正態分布特征參數。
gmm算法認為所有數據組成的分布都是由多個高斯分布(即正態分布)混合而成。用gmm來對賣場和用戶聚類,認為賣場和用戶使用終端的行為服從各自的正態分布,兩個正態分布的特征有明顯差異。要使gmm中各高斯分布最優,就要找到各分布的極大似然值,而gmm的極大似然函數屬于凹函數,凹函數的最大似然值在其所有輸入數據的均值處得到,因此,然均值最大。那么gmm的極大似然值最大,因此,通過em(期望最大)算法逼近gmm的最大似然值,求賣場和用戶的最優分布。gmm聚類的過程就是通過大量終端有效分類數據不斷迭代計算,求最大期望的過程,當達到最大期望,得到兩個正態分布的特征(期望、方差),以及根據特征和終端數據計算出各終端屬于兩類的概率。后續分類時只需通過聚類得到的兩個分布的特征值,計算該終端在兩個分布中的概率即可,在某分布中概率更大,則屬于該類。
依據以上描述,工廠、賣場、用戶三種終端的特征和分類方法均已找出。同時,為了驗證模型的準確性,以及賣場和用戶使用行為是否有變化,采用了兩種驗證方法驗證當下模型的準確性,一是定期抽樣用戶終端,用其有效使用行為數據重新做分類驗證,看其是否依然滿足用戶概率大于賣場概率,計算分類失誤的比例。同時,定期隨機選擇賣場,調查賣場終端的部分mac地址,檢查此部分mac是否屬于賣場終端的mac,并計算分類失誤比例。分類比例大于p,重新收集數據做gmm聚類。
(二)屬性狀態更新:
電視從激活到報廢整個生命周期中歸屬狀態的轉換過程如圖1所示:首先,終端被激活有兩種可能,一種是激活當天開機時長小于等于5分鐘,且地理位置距離工廠較近,這時工廠激活,激活后變為庫存(如圖1中步驟1)。另一種是非工廠激活(如步驟2),庫存終端賣出或者投放到賣場展示,則也變為非工廠終端(如步驟3)。非工廠終端有兩種可能:賣場終端、用戶終端。根據以上描述中聚類得到的特征,以及終端上報的數據分別計算在兩個高斯分布中的概率,從而被分類為賣場終端或者用戶終端(如步驟4、5)。賣場終端在展示完成后基本上也會變為用戶終端,因而,定期對賣場終端的數據分類,監測賣場終端是否變為用戶終端(如步驟6)。
由于工廠終端還會被運往賣場終端或者賣給用戶,賣場終端也可能賣給用戶,只有用戶終端屬性不會再變化,因此,本發明除了對未分類的終端進行分類外,還定期跟蹤工廠和賣場終端,直到他們變為用戶終端,實現了終端歸屬屬性定期更新,動態變化。
實施例2
一種基于使用行為區分電視歸屬屬性的方法,參見圖2所示:
(1)首先,工廠測試終端的時間在5分鐘以內,且測試完成后終端作為庫存,不再開機。因此,工廠電視的特點:激活當天開機時長小于5分鐘,且激活后不再開機。
(2)將數據平臺上除工廠電視以外的所有電視可用的數據都整理出來,如終端與最近賣場的大概距離、某段時間內平均整機開機時長、平均主場景的使用次數和時長、平均app的使用次數和時長。
(3)用這些數據進行k-means聚類,類型數量為6,觀察聚類后6類類型的質心對應到各數據的值,如果某類數據在各質心的值層次分明,那么這類數據能有效分類,如果某類數據在各質心較相近,或毫無規律,那么,它對有效分類作用不大。經過這樣的篩選,發現最有效的數據是終端與賣場的距離、整機開機時長。
(4)用終端和賣場的距離、此前10天整機開機作為聚類數據平均時長重新做k-means聚類,聚2類,聚類得到的質心用于計算gmm算法的初始期望、方差,以及初始分布概率。
(5)用步驟(4)中計算出來的初始參數對聚類數據做gmm聚類,聚2類,聚類得到2個正態分布的期望和標準差,以及每一個用戶終端被分為以上兩種類型的概率,其中開機時長期望小,距離期望大的那一類為用戶類。根據概率對終端進行分類,概率大的那一類即為其被分的類型。
如圖3所示,終端屬性狀態更新:
對于數據平臺上已經激活的電視終端,在聚類獲取特征時,即可被分為工廠、用戶或者賣場類型,具體步驟:
(1)每天新增的終端首先判斷當天開機時長是否小于5分鐘,且距離工廠較近,如果是,則為工廠終端,如果不是,則存為賣場或用戶狀態(如圖1)。
(2)每天檢查已被分為工廠的終端是否有開機,有開機,則此終端不再為工廠類,被置為賣場或者用戶狀態
(3)將10天前轉為賣場或者用戶狀態的用gmm聚類得到的兩類正態分布特征參數,分別計算被分為用戶、賣場類型的概率,如果為賣場概率大,則被分為賣場類大于賣場類,否則為用戶類。
(4)每天計算賣場類與賣場的距離、前10天的平均開機時長,用這兩個數據和2類正態分類對賣場終端進行分類,檢查賣場類是否轉變為用戶類。
(5)定期(周期較長)按1%抽樣用戶終端,用于賣場的距離、10天平均開機時長分類,計算被分為賣場類的比例;
(6)定期(周期較長)聯系20個賣場,查詢在賣場展示終端的mac,并查看這些mac被分為用戶終端的比例,與(5)中比例相加大于n%,將數據平臺上所有終端重新做gmm聚類。
以上實施步驟中,聚類過程的步驟做一次即可,而對于終端屬性狀態更新的步驟一般每天定時執行。
綜上所述,本發明提出了一種基于電視使用行為分析電視歸屬狀態的算法,利用電視的開機時長、地理位置、ip狀態、對應用的使用情況等行為運用機器學習算法對電視的使用行為特征進行聚類,剔除工廠、賣場終端,最后剩下的就是用戶終端。此套方法可動態追蹤任何一臺電視從激活、庫存、到用戶或者賣場整個過程中歸屬屬性的變化。
本說明書中各個實施例采用遞進的方式描述,每個實施例重點說明的都是與其它實施例的不同之處,各個實施例之間相同相似部分相互參見即可。
在本說明書中所談到的“一個實施例”、“另一個實施例”、“實施例”、等,指的是結合該實施例描述的具體特征、結構或者特點包括在本申請概括性描述的至少一個實施例中。在說明書中多個地方出現同種表述不是一定指的是同一個實施例。進一步來說,結合任一實施例描述一個具體特征、結構或者特點時,所要主張的是結合其他實施例來實現這種特征、結構或者特點也落在本發明的范圍內。
盡管這里參照本發明的多個解釋性實施例對本發明進行了描述,但是,應該理解,本領域技術人員可以設計出很多其他的修改和實施方式,這些修改和實施方式將落在本申請公開的原則范圍和精神之內。更具體地說,在本申請公開和權利要求的范圍內,可以對主題組合布局的組成部件和/或布局進行多種變型和改進。除了對組成部件和/或布局進行的變型和改進外,對于本領域技術人員來說,其他的用途也將是明顯的。
- 還沒有人留言評論。精彩留言會獲得點贊!