多平臺航空電子大數據系統及方法與流程
本發明屬于計算機領域,具體涉及一種航空飛行數據系統,尤其涉及一種多平臺航空電子大數據系統;此外,本發明還涉及該多平臺航空電子大數據系統的實現方法。
背景技術:
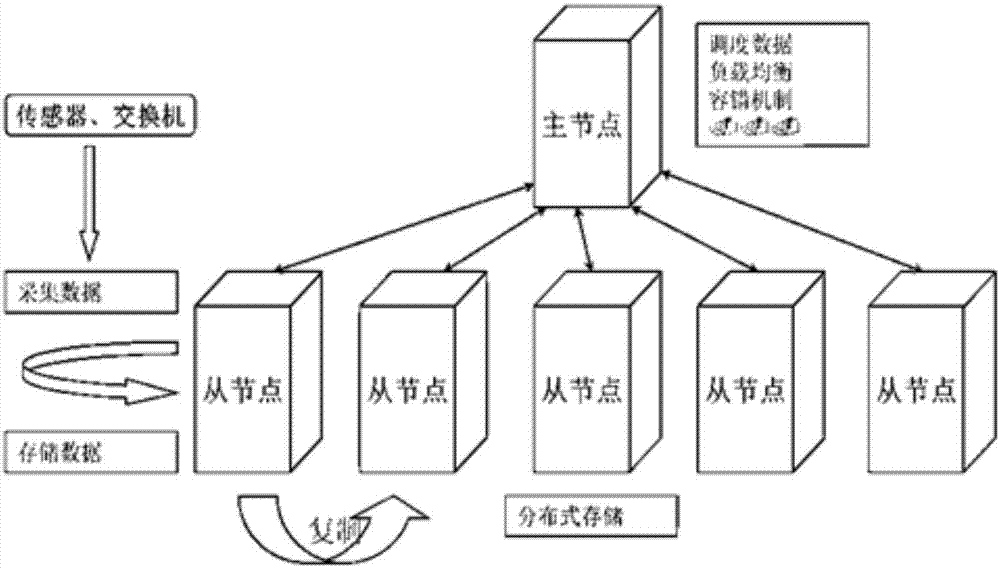
:航空飛行運行是一項龐大的綜合系統。在飛行的全過程中,在各部門各崗位間,都有大量的、種類繁多的數據需要傳遞,比如機組信息、氣象狀況、航行信息、航線風險系數評估、艙單信息、起飛數據、特情預案等數據。由于受到技術和管理模式的限制,傳統的數據傳遞方式是通過電話、發放紙質文檔、手冊等。這些傳統的保障方式存在諸多缺點,甚至成為限制民航業繼續發展的瓶頸。航空數據對每一次航班的安全起飛和經濟效益有著極其重要的影響。而航空數據的特點是多源、復雜、大規模,現有的單一平臺的數據系統的應用有限,因此針對這些多源的大規模飛行數據,亟需研發一種多平臺航空電子大數據系統。本發明是在現有的分布式框架和數據庫平臺的基礎上搭建而來,以下是現在常用的分布式框架和數據庫平臺。1.hadoophadoop是一個分布式系統基礎架構,由apache基金會開發。用戶可以在不了解分布式底層細節的情況下,利用它開發分布式程序。充分利用集群的威力高速運算和存儲。簡單地說來,hadoop是一個可以更容易開發和運行處理大規模數據的軟件平臺。該平臺使用的是面向對象編程語言java實現的,具有良好的可移植性。hadoop的核心是hdfs和mapreduce。hdfs(hadoopdistributedfilesystem)是一種分布式文件系統,隱藏下層負載均衡,冗余復制等細節,對上層程序提供一個統一的文件系統api接口。hdfs針對海量數據特點做了特別優化,包括:超大文件的訪問,讀操作比例遠超過寫操作,pc機極易發生故障造成節點失效等。hdfs把文件分成64mb的塊,分布在集群的機器上,使用linux的文件系統存放。同時每塊文件至少有3份以上的冗余。中心是一個namenode節點,根據文件索引,找尋文件塊。mapreduce是一套從海量數據提取分析元素最后返回結果集的編程模型,大多數分布式運算可以抽象為mapreduce操作。map是把輸入分解成中間的鍵值對,reduce根據鍵值,把map輸出的鍵值對進行合成整理,最終輸出結果。這兩個函數由程序員提供給系統,下層設施把map和reduce操作分布在集群上運行,并把結果存儲在hdfs上。hadoop具有以下幾個優點,使得用戶可以輕松地利用它來開發和運行處理海量數據的應用程序。高可靠性:hadoop能自動地維護數據的多份復制,并且在任務失敗后能自動地重新部署計算任務。高擴展性:hadoop是在可用的計算機集群間分配數據并完成計算任務的,這些集群可以方便地擴展到數以千計的節點中。因此,在不保證低延時的前提下,hadoop具有相當大的吞吐量,非常適合海量數據的運算。高效性:hadoop能夠在節點之間動態地移動數據,并保證各個節點的動態平衡,因此處理速度非常快。高容錯性:hadoop能夠自動保存數據的多個副本,并且能夠自動將失敗的任務重新分配。低成本:hadoop可以通過普通機器組成的服務器群來分發以及處理數據,這些服務器群總計可達數千個節點,而且每個節點都是運行在開源操作系統linux上面的,因此硬件成本會大大降低。此外,與一體機、商用數據倉庫等相比,hadoop是開源的,軟件成本也會大大降低。2.hbasehbase是hadoopdatabase的簡稱,是一個高可靠性、高性能、面向列、可伸縮的分布式存儲系統,其主要功能是在hadoop的hdfs的基礎上用列存儲的方式存儲海量的結構化數據。hbase中存儲的表主要有以下這些特點。大表:一個表可以有數十億行,上百萬列。無模式:每行都有一個可排序的主鍵和任意多的列,列可以根據需要動態的增加,同一張表中不同的行可以有截然不同的列。面向列:面向列(族)的存儲和權限控制,列(族)獨立檢索。稀疏:對于空(null)的列,并不占用存儲空間,表可以設計的非常稀疏。數據多版本:每個單元中的數據可以有多個版本,默認情況下版本號自動分配,是單元格插入時的時間戳。數據類型單一:hbase中的數據都是字符串,沒有類型。hbase適用場景主要有:●存在高并發讀寫●表結構的列族經常需要調整●存儲結構化或半結構化數據●高并發的key-value存儲●key隨機寫入,有序存儲●針對每個key保存一個固定大小的集合hbase也有一些缺點和不適用的場景:●由于只能提供行鎖,hbase對分布式事務支持不好●對于查詢中的join、groupby等操作,hbase的性能很差●查詢如果不使用row-key查詢,性能會很差,因為此時會進行全表掃描,建立二級索引或多級索引需要同時維護一張索引表●對高并發的隨機讀支持有限。體系化對抗環境中,實時感知數據源的數據是一個關鍵性的問題,這些數據源通常來自多種傳感器,高效的管理數據源產生的異構的數據成為這個問題的一個難點。本發明針對這些問題,對現有的分布式框架和相關的數據分析方法進行了一定的研究,嘗試找出處理和分析多源的大規模飛行數據的有效方法。目前,尚未見應用分布式框架和數據庫平臺的多平臺航空電子大數據系統的相關報道。技術實現要素:本發明要解決的技術問題在于提供一種多平臺航空電子大數據系統,該系統處理和分析大規模飛行數據,集成數據采集,數據分類管理,數據存儲和數據分析等功能,采集并分類管理多源異構數據,并將這些數據實時存儲到“資源云”平臺上,“資源云”平臺客戶端節點從云上實時獲取數據,借助云平臺來保證數據的實時性。在數據實時性的基礎上,系統支持歷史數據的關聯模型建立,利用實時的數據和關聯模型完成實時預測,對飛行員的決策提供一定的指導。具體來說,該系統需要實現以下功能:飛行數據采集、飛行數據實時共享、飛行數據關聯分析和實時輔助決策。為此,本發明還提供一種該多平臺航空電子大數據系統的實現方法。為解決上述技術問題,本發明提供一種多平臺航空電子大數據系統,包括數據采集模塊、數據存儲模塊、數據關聯分析模塊和數據關聯分析應用模塊;數據采集模塊從數據源1中獲取pcap數據包文件,經采集分類之后到數據存儲模塊中,完成數據存儲的過程;數據關聯分析模塊從數據源2中獲取訓練數據,完成數據關聯模型建立,將模型提供給數據關聯分析應用模塊使用,完成實時預測,并將結果顯示在屏幕上,數據關聯分析應用模塊利用數據存儲模塊實現的云存儲功能完成實時存儲的功能。作為本發明優選的技術方案,所述數據采集模塊包括輸入文件夾路徑單元、輸出文件夾路徑單元和數據塊選擇單元;所述輸入文件夾路徑單元和所述輸出文件夾路徑單元用于讀取用戶選擇的輸入和輸出的文件夾路徑,所述數據塊選擇單元用于讀取用戶選擇的數據塊類型,所述數據采集模塊根據以上單元讀取的內容來進行數據采集;所述數據采集模塊使用libpcap包從網絡抓取的pcap包中獲取關鍵的時間信息字段,包的源ip,目標ip信息和存儲信息的數據字段,分別為time字段,sourceip字段,destip字段和data字段,使用destip和sourceip結合模擬場景中的數據發送信息,初步確定出包信息數據塊;區分不同的數據塊,按照不同的格式解析,得到獨立的數據塊數據結構,將數據結構以文本的形式寫回硬盤,供下一階段使用。作為本發明優選的技術方案,所述數據存儲模塊包括讀取文件路徑單元和演示控制單元;所述讀取文件路徑單元用于讀取用戶選擇的數據源文件存放路徑;所述演示控制單元用于演示數據的存儲情況,它周期性地讀取存儲記錄并顯示到面板上;所述數據存儲模塊采用hadoop分布式存儲平臺及hbase分布式數據庫,從多架飛機實時獲取數據,然后通過云存儲方式再存儲到多架飛機上,并實時獲取并共享多架飛機的數據。作為本發明優選的技術方案,所述數據關聯分析模塊包括訓練數據路徑單元、訓練參數選擇單元和數據分割方式選擇單元;所述訓練數據路徑單元用于讀取用戶選擇的訓練數據存放路徑,所述訓練參數選擇單元用于讀取用戶選擇的各個訓練參數值,所述數據分割方式選擇單元用于讀取用戶選擇的數據分割方式,所述數據關聯分析模塊根據上述單元讀取的內容來進行模型的建立和訓練;所述數據關聯分析模塊采用svm分類器,對應代碼的svm包,通過svm的方法,對已有的數據和分析結果進行分類,其核心模塊是數據拆分程序和調用的libsvm分類器包,拆分程序將數據源結果為0的記錄拆分成n份,n由用戶輸入,分別和結果為1的記錄組成n個訓練數據集,用libsvm訓練后輸出n個模型,預測時使用n個模型結果進行預測結果進行與/或操作輸出預測結果;所述數據關聯分析模塊中數據關聯模型建立通過用戶指定輸入參數完成。所述svm分類器優選為使用rbf核的非線性svm分類器;所述svm分類器優選為二分割分類器。作為本發明優選的技術方案,所述數據關聯分析應用模塊包括模型路徑選擇單元、讀取文件路徑單元和演示控制單元;所述模型路徑選擇單元用于讀取用戶選擇的訓練模型存放路徑,所述讀取文件路徑單元用于讀取用戶選擇的數據源文件存放路徑,所述演示控制單元利用讀取的模型對數據進行分析,將預測結果顯示到面板上。此外,本發明還提供一種上述系統的實現方法,包括數據采集模塊的數據采集實現、數據存儲模塊的數據存儲實現、數據關聯分析模塊的建立數據關聯模型實現和數據關聯分析應用模塊的實時預測結果顯示實現。作為本發明優選的技術方案,所述數據采集模塊的數據采集實現包括如下步驟:1)界面程序初始化;2)等待用戶操作;3)獲取參數、調用處理程序;4)判斷文件夾是否還有未讀文件,是則進入步驟5),否則結束程序;5)判斷文件中是否仍有數據,是則進入步驟5),否則回到步驟4);6)判斷該數據塊是否為用戶需要,是則進入步驟7),否則回到步驟5);7)解析并輸出數據,回到步驟5)。作為本發明優選的技術方案,所述數據存儲模塊的數據存儲實現包括如下步驟:1)初始化hbase連接;2)創建表、列簇;3)本機數據導入內存;4)開始演示;5)實時數據上傳hbase,同時實時從hbase獲取所有節點數據;6)判斷是否終止演示,是則結束,否則回到步驟4)。作為本發明優選的技術方案,所述數據關聯分析模塊的建立數據關聯模型實現包括如下步驟:1)讀取數據、取出各屬性值的上下界;2)再次掃描數據,用上下界縮放數據后調用read_prob函數產生svm_problem;3)svm_problem進行交叉驗證,得到訓練準確率;4)基于svm_problem調用svm_train函數,生成模型并存儲;5)結束。作為本發明優選的技術方案,所述數據關聯分析應用模塊的實時預測結果顯示實現包括如下步驟:1)初始化hbase連接;2)創建表、列簇;3)本機數據導入內存;4)開始演示;5)實時數據上傳hbase,同時實時從hbase獲取所有節點數據再使用svm算法實時預測結果;6)判斷是否終止演示,是則結束,否則回到步驟4)。根據以上提供的技術方案,與現有技術相比,本發明提供的多平臺航空電子大數據系統,具有以下有益效果:1、該系統集成數據采集,數據分類管理,數據存儲和數據分析等功能,采集并分類管理多源異構數據,并將這些數據實時存儲到“資源云”平臺上,“資源云”平臺客戶端節點從云上實時獲取數據,借助云平臺來保證數據的實時性。在數據實時性的基礎上,系統支持歷史數據的關聯模型建立,利用實時的數據和關聯模型完成實時預測,對飛行員的決策提供一定的指導。具體來說,該系統需要實現以下功能:飛行數據采集、飛行數據實時共享、飛行數據關聯分析、實時輔助決策。2、本發明將hadoop分布式存儲平臺及hbase分布式數據庫優化后應用到航空電子大數據系統,是本領域的首創,本發明對大規模的航電數據進行集成和分布式存儲,能夠實時地采集、存儲和共享數據,并利用歷史數據的分析,對實時數據進行火力打擊的預測,從而成功地為飛行員提供有效的決策指導,預測成功率高達94%。3、本發明用機器學習中的分類算法來解決飛行中火力打擊的結果預測問題,相比于以前直接用軟件模擬飛行過程來得到結果,該方法在保證一定準確率的前提下速度要快好多倍,因此提高了體系化對抗系統的決策效率。由于打擊中擊中的情況要遠遠低于擊不中,造成訓練數據不平衡,影響決策準確度。因此,我們在svm的基礎上,創新地使用數據分割的方法,來提高準確度。將決策輔助功能集成到航電系統中,即可以利用存儲的數據進行訓練分類器,又能用訓練好的分類器進行實時的火力打擊預測,并根據預測結果為飛行器實時地提供決策建議。3、經試驗驗證,本發明系統優選使用rbf核的非線性svm分類器準確率最高,而優選使用二分割分類器的f1值最高。4、經試驗驗證,本發明系統支持靜態減少節點以及動態增加節點。附圖說明下面結合附圖和實施例對本發明進一步說明。圖1是本發明系統中數據存儲模塊的框架結構圖。圖2是本發明系統中數據關聯分析模塊中非線性svm的示例圖。圖3和圖4是本發明系統中數據關聯分析模塊中數據分割的示例圖。圖5是本發明多平臺航空電子大數據系統的總體框架圖。圖6是本發明多平臺航空電子大數據系統的功能結構圖。圖7是本發明多平臺航空電子大數據系統的主程序流程圖。圖8是本發明系統中數據關聯分析應用模塊的示例圖。圖9是本發明系統中數據采集模塊邏輯流程圖。圖10是本發明系統中數據存儲模塊邏輯流程圖。圖11是本發明系統中數據關聯分析模塊邏輯流程圖。圖12是本發明系統中數據關聯分析應用模塊邏輯流程圖。具體實施方式現在結合附圖對本發明作進一步詳細的說明。這些附圖均為簡化的示意圖,僅以示意方式說明本發明的基本結構,因此其僅顯示與本發明有關的構成。體系化對抗中決策者使用的參考數據來自不同飛機系統、不同平臺上的多傳感器、多數據源,實時獲取并可靠存儲這些數據,將數據及時應用到決策體系中成為作戰成功的基礎。為模擬這一體系化環境,本發明用多臺專用測試設備模擬一個飛行節點群,抓取實際飛行環境中傳感器產生的數據作為數據源,用一臺交換機連接各專用測試設備構建局域網,模擬體系化對抗環境中的數據通信。決策者可以通過任一專用測試設備實時查看節點群中各設備節點的實時信息,依據這些數據信息完成決策。在這個模擬的假想作戰場景中,為保證決策者獲取數據的實時性和可靠性,本發明提出基于“資源云”的多平臺航電大數據系統。本發明多平臺航空電子大數據系統的核心是搭建在假想作戰環境中的“資源云”平臺,在多臺專用測試設備上搭建一個數據共享平臺,該數據平臺基于已有的開源云軟件(hadoop,hbase)搭建,主要完成飛行節點之間信息實時共享,可靠存儲,信息處理的功能。平臺的數據源是經過數據采集分類之后的數據信息,原始數據經過數據采集模塊完成采集分類,之后傳輸到“資源云”平臺。最后,各節點上的數據分析模塊從“資源云”平臺實時獲取所有節點的信息,結合歷史數據建立的數據關聯模型進行數據分析,將對各節點的數據分析結果呈現給決策者,提供決策指導。本發明多平臺航空電子大數據系統中各個模塊的技術解決方案如下:1、數據采集與分類方案假想作戰環境的數據來自不同的傳感器,數據之間具有異構性,直接導致體系作戰下航電大數據系統的數據復雜性。經過采集的數據需要通過基于空中云平臺的大數據分類技術來從多個角度對平臺及數據進行分析,增強數據關聯,從而降低面向體系作戰的航電大數據系統的數據復雜性。具體實現中,需要針對多模態勢空間構建不同的數據采集與預處理模式。針對假想作戰環境,本發明采取抓包后逐個按照數據協議解析數據包的方法來采集分類環境中的數據,作為“資源云”平臺數據源。實際應用中,常用的系統數據采集方案有兩種:(1)抓包抓包程序wireshark獲取數據包。wireshark將從網絡中捕獲到的二進制數據按照不同的協議包結構規范,顯示在packetdetails面板中。主要包含物理層的數據幀概況、數據鏈路層以太網幀頭部信息、互聯網層ip包頭部信息、傳輸層的數據段頭部信息、應用層的信息等。過程采用libpcap庫,libpcap是一個網絡數據包捕獲函數庫,功能非常強大,針對網絡接口、端口和協議進行數據包截取。(2)爬蟲網絡數據采集通過網絡爬蟲或網站公開api等方式從網站上獲取數據信息。該方法可以將非結構化數據從網頁中抽取出來,將其存儲為統一的本地數據文件,并以結構化的方式存儲。它支持圖片、音頻、視頻等文件或附件的采集,附件與正文可以自動關聯。除了網絡中包含的內容之外,對于網絡流量的采集可以使用dpi或dfi等帶寬管理技術進行處理。針對假想作戰環境中作戰節點之間的通信代價較高,所以本發明舍棄爬蟲主動獲取數據的方式,優選從實際作戰環境中網絡交換機處利用wireshark軟件抓取體系化對抗平臺上的數據包作為源數據。數據采集模塊解析從交換機中獲取到的數據包,根據包的源ip和目的ip,以及數據包的協議來將數據分為結構化和非結構化的數據。我們根據假想作戰環境中的通信協議,來將數據逐個從二進制文件中解析出內容。得到的數據基本分類如下:(1)結構數據:結構化數據即行數據,可存儲在關系型數據庫里,通過二維表結構來邏輯表達實現的數據。數據將針對不同目標接收目標進行分發,比如無人機、雷達仿真、光電、電子站、三維語音告警、座艙等。采集數據結果將數據分為多個數據塊。數據塊中包括基本信息,如數據類型、發送源、目標號、塊長、更新周期、虛擬鏈路、最大延遲時間、接收端口等。除基本信息外,不同數據塊中的主要內容可進行結構化歸納。(2)非結構化數據在本發明多平臺航空電子大數據系統大數據管理平臺中,非結構數據主要包括圖片、音頻、視頻、超媒體等形式,比如雷達氣象圖像、地理分布圖像、探測敵機聲波圖和視頻流等等。這些數據沒有固定結構,相對于結構化數據而言,非結構化數據不方便用數據庫二維邏輯表來表現,但基于分布式云存儲平臺上的非關系型數據庫,可以實現非結構化數據高效、穩定的存儲。針對非結構化的數據,我們留出接口來完成這些功能。2、數據存儲方案體系化對抗環境中,實時、準確的獲取對抗系統中相關信息的實時變化情況是完成對抗的體系化的一個重要因素。每個作戰節點會實時生成一些關鍵的航電信息,包括節點載機數據,目標的信息等,這些信息實時被其他節點獲取,并實時加入體系化對抗的決策體系中。為實現這個目標,我們在假想作戰環境的節點中搭建“資源云”,采集到每個節點生成的航電信息之后,實時將信息上傳到“資源云”上,其他節點實時查詢數據變化,利用云平臺的高容錯,實時性和可靠性來保證所有航電信息的實時獲取性和難丟失性。(1)“資源云”平臺傳統的“資源云”框架分為幾種不同類型:第一種將原始數據采集在客戶端(client),再由客戶端將數據傳輸至各存儲節點進行分布式存儲;第二種則將數據采集在節點本地,繼而分發至所有存儲節點。考慮到相對于現有的大數據管理架構,本發明的特色在于數據源與數據存儲目的地相同,即從多架飛機實時獲取數據,然后通過云存儲方式再存儲到多架飛機上,并實時獲取并共享多架飛機的數據,故本發明采用第二種框架類型。假想平臺總體采用主從(master/slave)結構模型(如圖1所示),由一個主節點和若干個從節點組成。主節點作為主服務器,管理文件系統命名空間和客戶端對文件的訪問操作。從節點作為從服務器,負責數據的存儲。系統采用“一次寫入、多次讀取(write-once-read-many)”模型,該模型降低了并發性控制要求,簡化了數據聚合性,支持高吞吐量訪問。(1)可靠性“資源云”平臺通過文件分割的方式來將大文件切分為固定大小的小文件,并存儲分割表,將小文件制作多個副本,分別存儲在不同節點上面,在讀取文件時通過分割表來逐份讀取拼接文件后返回給用戶。數據源經過采集和分類之后,寫入硬盤臨時緩存在本地節點上,由于節點的復雜性,部分節點存儲的信息文件較大,超過云平臺默認的文件大小,則會產生文件分割過程,一方面通過文件分割節省線路帶寬,另一方面可以增加系統容錯性。本發明系統的“資源云”通過將一個文件在物理存儲上分割成多個塊,并通過哈希等算法分別將它們拆分到集群的多個節點上,這種特性可以讓分布式存儲系統保存足夠大文件。相比不分割將文件備份到指定機器上來說,文件分割的過程節省了單點到單點之間通信的帶寬,一定程度上使系統的負載更加均衡,另一方面,如果單節點產生故障,無法讀取該節點信息,通過文件分割的方式可以通過備份到其他節點的分割來拼接完成恢復工作。(2)容錯性“資源云”平臺對每個文件進行分割之后,通過一定的哈希算法將數據塊冗余備份到其他節點上面,云平臺的冗余容錯基于hdfs的容錯機制,主要有以下幾點:master節點將文件分割,記錄分割表作為復制的決策,將文件各部分進行標記,記錄當前塊的分割表,按照分割表內容通過哈希算法冗余備份到對應的其他節點上。訪問文件時,當前節點上面沒有對應的文件分割,則到最近的一個冗余備份上請求。master節點的備份,通過zookeeper完成,所有節點選舉出一個master節點和一個backup-master節點,backup-master節點定時對master節點完成快照,保證backup-master信息不落后master太多。當心跳機制檢測到master節點崩潰之后,backup-master取代master節點,并通過zookeeper的選舉機制選出另外一個backup-master節點,備份當前master節點內容。(3)“資源云”其他特點定時快照:快照支持在一個特定時間存儲一個數據拷貝,快照可以將失效的集群回滾到之前一個正常的時間點上。流程狀態:創建數據時,一開始客戶端將文件數據緩存在本地的臨時文件中。應用程序的寫操作被透明地重定向到這個臨時本地文件。當本地文件堆積到一個分塊大小的時候,客戶端才會通知主節點。主節點將文件名插入到文件系統層次中,然后為它分配一個數據塊。主節點構造包括數據節點id(可能是多個,副本數據塊存放的節點也有)和目標數據塊標識的報文,用它回復客戶端的請求。客戶端收到后將本地的臨時文件刷新到指定的數據節點數據塊中。因為如果客戶端對遠程文件系統進行直接寫入而沒有任何本地的緩存,這就會對網速和網絡吞吐量產生很大的影響。當文件關閉時,本地臨時文件中未上傳的殘留數據就會被轉送到數據節點。然后客戶端就可以通知主節點文件已經關閉。此時,主節點將文件的創建操作添加到到持久化存儲中。假如主節點在文件關閉之前死掉,文件就丟掉了。流水式復制:當客戶端寫數據到文件中時,如上所述,數據首先被寫入本地文件中,假設文件的復制因子是3,當本地文件堆積到一塊大小的數據,客戶端從主節點獲得一個數據節點的列表。這個列表也包含存放數據塊副本的數據節點。當客戶端刷新數據塊到第一個數據節點。第一個數據節點開始以4kb為單元接收數據,將每一小塊都寫到本地庫中,同時將每一小塊都傳送到列表中的第二個數據節點。同理,第二個數據節點將小塊數據寫入本地庫中同時傳給第三個數據節點,第三個數據節點直接寫到本地庫中。一個數據節點在接前一個節點數據的同時,還可以將數據流水式傳遞給下一個節點,所以,數據是流水式地從一個數據節點傳遞到下一個。擴展性:大量的應用實踐已經證明該分布式平臺具有著極大的擴展性,可以輕松擴展到數以百計的節點構成的集群上。3、數據分析方案在體系化對抗決策體系中,歷史數據信息是十分寶貴的資源,對歷史信息的分析和提煉可以完成許多功能,比如說歷史火力打擊信息可以用來輔助決策。通過對一組歷史飛行過程及火力打擊的結果分析,我們可以獲取一個飛行狀態的分類器模型,利用這個模型可以預測節點火力打擊結果。把預測模型引入“資源云”平臺上之后,我們可以根據每個節點的火力打擊預測結果,完成一些輔助決策功能,提高體系化對抗系統的決策效率。針對已有的飛行狀態信息數據集和打擊結果,可以近似的把問題看做一個輸入是飛機發射導彈時的航電信息和目標的絕對位置信息,輸出是擊中和沒擊中目標的二分類分類器模型,分析比較常用的二分類分類器,得出一個結果最優的分類器模型應用到決策系統中。(1)分類器算法由于要解決的是一個二分類問題,標號為0和1。那么分類器就是要找到一個面,將所有樣本點分到面的兩側。即,對于任一樣本x=(b1,b2,…bm),分類器決策函數f:f(x)=g(f(x))a.線性可分svm線性可分svm分類器決策函數中的f(x)=wtx+b,它本質上是尋找一個能將樣本點按標號分到兩側的具有最大化margin的超平面,margin是所有數據點到超平面的幾何間隔的最小值。從統計的角度講,由于正負樣本可以看作從兩個不同的分布隨機抽樣得到,若分類邊界與兩個分布的距離越大,抽樣出的樣本落在分類邊界另一邊的概率越小。所以,最大化margin可以保證最壞情況下的泛化誤差最小,分類器確信度更高。分類器決策函數中的f(x)=wtx+b,那么它的超平面為wtx+b=0.給定訓練集合t,超平面wtx+b=0,定義樣本點(xi,yi)到超平面的函數間隔為:幾何間隔為:設n為樣本點數目,定義t中所有樣本點的函數間隔的最小值為:超平面的margin為t中所有樣本點的幾何間隔的最小值:最大化margin可表示為:變化得:可以看出,w、b等比例縮放對超平面和幾何間隔都沒有影響,而函數間隔會同比例縮放。所以,令代入上式,而最大化等價于最小化這樣就得到了線性可分svm的最優化問題:這是一個凸二次規劃問題,應用拉格朗日對偶性,通過求解對偶問題可得到最優解,求解的過程就不贅述了。b.非線性svm對于非線性的分類問題,決策面是一個曲面,曲面通過一定映射,會變成高維空間中的一個超平面,這樣就可以用線性可分svm中的方法來解決。例如,兩類數據分布為兩個圓圈的形狀(如圖2所示),這樣的數據本身是線性不可分的,理想的分界面應該是一個圓而不是一條線(超平面)。若用x1和x1表示這個二維平面的坐標,那么它的決策面可寫成這樣的形式:a0+a1x1+a2x2+a3x12+a4x22+a5x1x2=0如果我們構造一個五維空間,坐標值分別為z1=x1、z2=x2、z3=x12、z4=x22、z5=x1x2,那么上面的決策面方程在新的空間中可以寫作:可以看出,這正是一個超平面的方程。如果我們按這樣的方式將數據映射到五維空間,那么在新空間中原來的非線性數據就變成線性可分的了,從而可以使用線性svm算法處理。由于在線性可分svm的求解過程中,需要計算的地方數據向量總是以內積的形式出現,所以,我們定義計算兩個向量在映射過后的空間中的內積的函數為核函數,用核函數來簡化映射空間中的內積運算。所以,對于非線性情況,處理方法是選擇一個核函數,通過它將數據映射到高維空間,變成高維空間中的一個線性可分問題,以此來解決在原始空間中線性不可分的問題,然后再用線性可分svm算法進行處理。svm常用的核函數有四種:線性核(等同于線性可分svm)、多項式核、rbf核、sigmoid核,具體形式如下表1。表1類型函數表達式線性核ut*v多項式核(g*ut*v+coef0)degreerbf核exp(-g*||u-v||2)sigmoid核tanh(g*ut*v+coef0)數據分割由于樣本數據集中兩類數據比例懸殊,造成不平衡問題。嘗試將訓練集中比例較高的那一類樣本分割成幾塊,每塊與另一類樣本分別組成一個子訓練集,對每個子訓練集進行訓練,得到子分類模型。將子分類模型通過一些運算可以組成新的分類器,對數據進行預測。這樣處理,可以一定程度上改善數據不平衡問題。例如,將label=0的樣本分割成四塊,分別與label=1的樣本組成四個子訓練集,對它們進行訓練得到四個子分類模型。每個子分類模型對輸入數據進行預測,得到四個output,可以對這四個output進行與運算,得到最終的output,這就相當于一個新的分類器。示意圖如圖3和圖4所示。下面結合附圖進一步具體說明本發明的系統架構及流程:(一)程序架構和流程設計如圖5所示,本發明多平臺航空電子大數據系統整體分為4個模塊,數據采集模塊,數據存儲模塊,數據關聯分析模塊和數據關聯分析應用模塊。數據采集模塊從數據源1中獲取pcap數據包文件,經采集分類之后到數據存儲模塊中,完成數據存儲的過程。數據關聯分析模塊從數據源2中獲取訓練數據,可以通過用戶指定輸入參數,完成數據關聯模型建立,將模型提供給數據關聯分析應用模塊使用,完成實時預測,并將結果顯示在屏幕上,數據關聯分析應用模塊利用數據存儲模塊實現的云存儲功能完成實時存儲的功能。由于系統是在分布式平臺基礎上開發的,搭建系統時首先需要在多臺設備(開發系統時使用6臺)上搭建hadoop和hbase完全分布式環境。每臺設備相當于一個飛行節點,其中有一臺作為主節點,來進行調度和顯示等操作。1.數據采集模塊使用libpcap包從網絡抓取的pcap包中獲取關鍵的時間信息字段,包的源ip,目標ip信息和存儲信息的數據字段,分別為time字段,sourceip字段,destip字段和data字段,使用destip和sourceip結合模擬場景中的數據發送信息,可以初步確定出包信息數據塊。區分不同的數據塊,按照不同的格式解析,得到獨立的數據塊數據結構,將數據結構以文本的形式寫回硬盤,供下一階段使用。如圖6和圖7所示,數據采集模塊包括輸入文件夾路徑單元、輸出文件夾路徑單元、數據塊選擇單元。輸入文件夾路徑單元和輸出文件夾路徑單元用于讀取用戶選擇的輸入和輸出的文件夾路徑,數據塊選擇單元用于讀取用戶選擇的數據塊類型,數據采集模塊根據這些單元讀取的內容來進行數據采集。如圖9所示,數據采集模塊邏輯流程包括如下步驟:1)界面程序初始化;2)等待用戶操作;3)獲取參數、調用處理程序;4)判斷文件夾是否還有未讀文件,是則進入步驟5),否則結束程序;5)判斷文件中是否仍有數據,是則進入步驟5),否則回到步驟4);6)判斷該數據塊是否為用戶需要,是則進入步驟7),否則回到步驟5);7)解析并輸出數據,回到步驟5)。2.數據存儲模塊(1)分布式存儲平臺為完成數據可靠性存儲過程,參考技術方案中的設計,借助已有的分布式云平臺,基于hdfs實現數據存儲功能。在六臺專用測試設備上部署hdfs的服務端,待所有節點模擬飛行員就位(設備開機)后,在任一節點啟動hdfs的start-all.sh命令,六臺測試設備組建成統一的數據共享平臺,分別監聽相應功能的端口。數據存儲或查詢請求達到時,使用對應端口傳輸數據。平臺的數據可靠性和容錯性借助hdfs的冗余備份功能完成。(2)分布式數據庫在已有的hdfs穩定存儲的基礎上,項目為規范化管理所有數據,基于hbase實現了一個分布式數據庫,使用hadoop的hdfs來完成可靠存儲,使用hadoop的mapreduce框架來加速系統數據查詢操作。hbase的表格設計如下:實際存儲時,每個數據包對應一個rowkey,每個rowkey只包含一個數據塊的信息,hbase利用列存的方式保證系統數據的可靠性。(3)運行流程該模塊運行過程包括數據存儲和數據顯示兩個步驟。數據存儲:隔40ms吐出一次數據,將數據存儲到hbase中,因樣本數據量較小,讀取完成之后從第一個數據開始再次吐出。數據顯示:另開線程完成文件的讀取過程,每隔10ms從hbase環境中實時查詢從上次時間戳查詢到現在時間戳時間內所有的記錄,從記錄中讀取最后一條記錄,實時顯示在屏幕上。如圖6和圖7所示,數據存儲模塊包括讀取文件路徑單元和演示控制單元,用于數據存儲演示。讀取文件路徑單元用于讀取用戶選擇的數據源文件存放路徑,演示控制單元用于演示數據的存儲情況,它周期性地讀取存儲記錄并顯示到面板上。如圖10所示,數據存儲模塊邏輯流程包括如下步驟:1)初始化hbase連接;2)創建表、列簇;3)本機數據導入內存;4)開始演示;5)實時數據上傳hbase,同時實時從hbase獲取所有節點數據;6)判斷是否終止演示,是則結束,否則回到步驟4)。3.數據關聯分析模塊這一部分主要使用的svm分類器,對應代碼的svm包,通過svm的方法,對已有的數據和分析結果進行分類,其核心模塊是數據拆分程序和調用的libsvm分類器包,拆分程序將數據源結果為0的記錄拆分成n份(n由用戶輸入),分別和結果為1的記錄組成n個訓練數據集,用libsvm訓練后輸出n個模型,預測時使用n個模型結果進行預測結果進行與/或操作輸出預測結果。運行過程主要包括以下三個步驟。數據歸一化:掃描數據集,取出上下界,完成數據的歸一化操作,保證每個變量對結果的作用平衡。數據分割:因為數據的特殊性,結果為0的記錄數量遠多于結果為1,所以本發明采取技術方案中的劃分策略,將結果為1的數據劃分成n份,分別與0組合之后形成n個數據源,這一部分在read_prob函數中實現。數據訓練:調用libsvm軟件包中的各個函數(包括svm_scale、svm_train等),對各svm_problem訓練,生成svm_model并dump(轉存)到硬盤上。如圖6和圖7所示,數據關聯分析模塊包括訓練數據路徑單元、訓練參數選擇單元、數據分割方式選擇單元,用于建立模型、進行模型訓練。訓練數據路徑單元用于讀取用戶選擇的訓練數據存放路徑,訓練參數選擇單元用于讀取用戶選擇的各個訓練參數值,數據分割方式選擇單元用于讀取用戶選擇的數據分割方式,數據關聯分析模塊根據這些單元讀取的內容來進行模型的建立和訓練。如圖11所示,數據關聯分析模塊邏輯流程包括如下步驟:1)讀取數據、取出各屬性值的上下界,包括經度、緯度、高度、橫滾角、直航角、俯仰角和速度7個屬性;2)再次掃描數據,用上下界scale數據(縮放數據,以提高訓練和預測時數據的處理速度)后調用read_prob函數產生svm_problem;3)svm_problem進行crossvalidation(交叉驗證),得到訓練準確率;4)基于svm_problem調用svm_train函數,生成模型并存儲;5)結束。4.數據關聯分析應用模塊應用模塊的整體設計原則是利用數據存儲模塊完成存儲,利用數據關聯分析模塊輸出的最優模型作為輸入模型,對任一數據實時預測,如圖8所示。其中,多分模型的數據預測遵循如下規則:2分:或模型:n1|n2與模型:n1&n24分:先與后或:(n1&n2)|(n3&n4)先或后與:(n1|n2)&(n3|n4)8分:先與后或:(n1&n2&n3&n4)|(n5&n6&n7&n8)先或后與:(n1|n2|n3|n4)&(n5|n6|n7|n8)運行過程主要包括以下三個步驟。初始化:初始化hbase的連接,完成表的創建,列簇的創建等操作,從硬盤讀取需要存儲的文件內容。數據產生:每隔40ms吐出一次數據,將數據存儲到hbase中,因樣本數據量較小,讀取完成之后從第一個數據開始再次吐出。數據顯示:另開線程完成文件的讀取過程,每隔10ms從hbase環境中實時查詢從上次時間戳查詢到現在時間戳時間內所有的記錄,從記錄中讀取最后一條記錄,用這個數據調用svm完成實時預測,并將結果顯示在屏幕上。如圖6和圖7所示,數據關聯分析應用模塊包括模型路徑選擇單元、讀取文件路徑單元、演示控制單元,用于數據分析演示。模型路徑選擇單元用于讀取用戶選擇的訓練模型存放路徑,讀取文件路徑單元用于讀取用戶選擇的數據源文件存放路徑,演示控制單元利用讀取的模型對數據進行分析,將預測結果顯示到面板上。如圖12所示,數據關聯分析應用模塊邏輯流程包括如下步驟:1)初始化hbase連接;2)創建表、列簇;3)本機數據導入內存;4)開始演示;5)實時數據上傳hbase,同時實時從hbase獲取所有節點數據再使用svm算法實時預測結果;6)判斷是否終止演示,是則結束,否則回到步驟4)。(二)接口設計1.數據采集模塊數據采集是多平臺航電大數據系統的“資源云”平臺的數據基礎,為軟件提供一定的數據分析數據源。數據源要求是從實際運行環境中交換機處用wireshark軟件抓包獲取的數據,數據格式要求是pcap數據,包的目標ip和源ip滿足如下要求:表2數據塊名稱目的ip/源ip組網指令224.224.0.110演示場景信息224.224.0.107/224.224.0.108綜合目標數據塊224.224.0.89直升機載機數據塊224.224.0.140演示控制信息各數據包中data字段數據塊滿足協議《xx型演示系統數據接口協議》。2.數據存儲模塊數據存儲模塊是多平臺航電大數據系統的核心,由此模塊完成系統數據存儲功能。此模塊接受來自“數據采集”模塊的數據輸出,輸入數據格式為完整的txt文本文件,每一行為一個解析后的數據包內容,字段之間用逗號分隔,每個數據包字段信息如下:直升機載機數據塊:包時間戳,數據塊id,數據塊時間,經度,緯度,高度,俯仰角,橫滾角,真航角,攻角,地速,北向速度,東向速度,天速綜合目標數據塊:包數據戳,數據塊id,數據塊時間,目標個數,目標1屬性,目標1經度,目標1緯度,目標1高度,目標1方位,目標1俯仰角,目標1北向速度,目標1東向速度,目標1天向速度,目標2屬性,……,目標20天向速度3.數據關聯分析模塊數據關聯分析模塊的主要功能是對歷史數據的分析建立數據模型,此模塊輸入一組訓練數據,通過svm分類器和劃分分類策略完成數據建模過程。訓練數據要求為stk模擬軟件收集到的數據,其格式為7個輸入變量格式和一個0/1的結果數據,所有字段之間用tab制表符(“\t”)分隔,字段信息如下:經度緯度高度參數4參數5參數6參數704.數據關聯分析應用模塊此模塊以stk模擬軟件的輸出文件作為預測數據源,以“數據關聯分析部分”輸出模型作為輸入模型,基于數據存儲模塊進行實時的結果預測,實時顯示在界面上。該部分輸入數據格式(即stk模擬軟件輸出文件)字段信息如下:經度緯度高度參數4參數5參數6參數7(三)全局數據結構設計1.物理結構軟件實現中主要使用的數據結構是對應于數據協議中的一些數據結構,定義數據結構存儲從二進制文件中解析出來的數據,實現的數據結構有下面幾個:frameheader//存儲每個包的數據頭信息helicopt_carrier_parm//存儲載機數據塊字段信息singletargetparameter//存儲單個目標所有信息interrgrated_target_parm//存儲集成目標數據塊字段信息,內部可能包含多個singletargetparameterdemo_scene_info//演示場景信息數據塊demo_ctrl_info//演示控制信息數據塊build_net_cmd//組網指令數據塊record//每個數據塊到系統內之后均被識別成為行數據,記錄成一個record,用長度和type字段來區別類別。2.表結構根據已有的數據分類,結合hbase的按列存儲的特點,我們設計出如下的表結構由多個列簇(columnfamily)構成,每個列簇由多個屬性組成,每個屬性對應于數據塊中的一個字段。表中的列簇有如下幾個:cf_helicoptcarrierparm//直升機載機數據塊列簇cf_integeratedtargetparm//基礎目標數據塊列簇cf_stk//stk數據對應的列簇cf_emptystring//存儲非結構化的包列簇cf_unrecognised//存儲未識別的數據塊對應的列簇各列簇中包含的列為各塊字段信息,cf_emptystring中包含文本形式存儲的包信息,如”87a34b2345f86544e”等,cf_unrecognised只包含類型信息。表格中的行鍵信息使用自定義的格式,格式為“row”+系統時間+helicopterid,例如行鍵為“row147926317632301”,表示系統時間(從1970年1月1日0時起的毫秒數)為1479263176323時,編號為01的節點存儲到云平臺中的數據。3.類結構實現中涉及到的類結構主要有記錄行信息的record類,調用底層hbase的hbaseengine類和調用svm分類器的svmengine類,各自在類的成員變量中完成各自調用過程。4.常量實現設計中涉及到的常量主要是字段名稱信息,數量較大,在此不詳細列出。以下通過具體實驗來驗證本發明的效果:1.分類器算法評測實驗(1)數據集用作實驗的原始飛行數據樣本共4497432個,其中擊中(label=1)的有316768個,未擊中(label=0)的有4180664個。將原始數據按照50%、25%、25%的比例均勻劃分為trainset、validationset、testset三個集合。其中,trainset用來訓練分類器;validationset用來測試不同分類器的性能,確定分類模型的網絡結構或者控制模型復雜程度的參數;testset用來檢驗最終選擇的最優分類模型的性能。(2)實驗結果對不同分類器算法進行測試實驗,評估實驗結果,選取最佳的分類器模型,用testset進行驗證。a.線性可分svm用liblinear實現線性可分svm,進行測試,結果如下表3:表3accuracyprecisionrecallf192.9669%000由于數據集中label=1的數目遠遠低于label=0的實例數目(比例約為1:13),因此線性svm會全部預測0,但是顯然這樣是毫無意義的。b.非線性svm用libsvm實現不同類型的非線性svm,進行測試,結果如下表4:表4核函數accuracyprecisionrecallf1線性核92.9669%000多項式核92.9669%000rbf核94.3549%0.5990.5960.597sigmod核85.9684%000可以看出選用rbf核函數的結果最好,準確率達到了94.4%,1的預測率也超過了50%。c.數據分割子訓練集用前面提到的libsvm的rbf核類型進行訓練,因為它的效果最好。i.二分割將label=0的訓練數據隨機分割成兩塊,與label為1的數據組成兩個子訓練集,訓練得到兩個model,分別對validationset進行預測,得到兩個output,按與和或兩種關系處理output得到最終分類結果。測試結果如下表5:表5accuracyprecisionrecallf1與94.1015%0.5560.8060.658或94.0866%0.5540.8110.659ii.四分割將label=0的訓練數據隨機分割成四塊,與label為1的數據組成四個子訓練集,訓練得到四個model,分別對validationset進行預測,得到四個output,按全與、全或、先與后或、先或后與四種關系處理output得到最終分類結果。測試結果如下表6:表6iii.八分割將label=0的訓練數據隨機分割成八塊,與label為1的數據組成八個子訓練集,訓練得到八個model,分別對validationset進行預測,得到八個output,按全與、全或、先與后或、先或后與四種關系處理output得到最終分類結果。測試結果如下表7:表7accuracyprecisionrecallf1全與91.5268%0.4530.9840.620全或91.2967%0.4460.9870.615先與后或91.4762%0.4510.9850.619先或后與91.3750%0.4490.9860.617iv.三分之二分割將label=0的訓練數據隨機分割成三塊,每兩塊與label為1的數據組成三個子訓練集,訓練得到三個model,分別對validationset進行預測,得到三個output,按與和或兩種關系處理output得到最終分類結果。測試結果如下表8:表8accuracyprecisionrecallf1與94.3033%0.5750.7290.643或94.2959%0.5740.7340.644d.驗證實驗根據以上測試,可以看出,單純使用rbf核的非線性svm分類器準確率最高,而二分割分類器的f1值最高。用testset對這兩種最優分類模型進行驗證實驗,結果如下表9:表9驗證得到,這兩種分類器性能與前面的測試結果基本一致,確實最優。2.多平臺航空電子大數據系統測試a.數據采集模塊測試運行軟件系統,進入數據采集模塊,設置好參數后開始采集。檢查輸出的數據塊文件,均正確,證明采集功能正常。設置不同的blockselection參數,檢查輸出的數據大小,均不同,證明采集模塊能對各種不同的單數據塊進行采集。b.數據存儲模塊測試運行軟件系統,進入數據采集模塊,然后開始演示。觀察dashboard面板上的數據,隨著程序運行,面板能實時顯示集群中各節點的狀態信息,且可以看出飛行數據正被存儲,證明該模塊能夠實時存儲各個節點的數據。c.數據關聯分析模塊測試運行軟件系統,進入數據關聯分析模塊,分別采用不同的核函數選擇參數和分割參數,對輸入數據集進行訓練,均能成功地得到分類模型,證明該模塊能夠用不同方法進行數據分析。d.數據關聯分析應用模塊測試運行軟件系統,進入數據關聯分析應用模塊,選取參數,然后開始演示。界面能實時顯示所有節點的飛行數據和預測火力打擊結果,證明該模塊能夠對飛行數據進行實時存儲和預測。e.系統節點靜態減少測試按照相應的方法,將系統節點由6個靜態減少到4個,檢查集群中hadoop和hbase的節點數,均變成了4,說明系統支持靜態減少節點。f.系統節點動態增加測試按照相應的方法,將系統節點由前一測試中的4個動態增加到6個,并在新增加的節點上運行系統軟件。檢查系統數據存儲功能界面上節點信息的變化,由原來的4成功變成了6,說明系統支持動態增加節點。以上述依據本發明的理想實施例為啟示,通過上述的說明內容,相關工作人員完全可以在不偏離本項發明技術思想的范圍內,進行多樣的變更以及修改。本項發明的技術性范圍并不局限于說明書上的內容,必須要根據權利要求范圍來確定其技術性范圍。當前第1頁12
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1