一種基于任務運行日志實現表級血緣關系信息構建的方法與流程
本發明涉及一種血緣關系信息構建的方法,尤其涉及一種基于任務運行日志實現表級血緣關系信息構建的方法。
背景技術:
1、現有技術提供一種基于元數據的數據血緣關系分析方法及系統(專利文獻號:cn110555032a),該方法通過開源語法分析器定義sql的詞法規則和語法規則,將sql轉化為抽象語法樹,再通過邏輯層和物理層優化器進行變換,生成最終的執行計劃,從而分析出輸入輸出表、字段和相應的處理條件。這種方法能夠有效地完成數據表、字段間的關系梳理。
2、現有另一種技術是關于基于數據血緣的數據任務分析方法、系統及介質,該技術在數據任務執行時,分析數據血緣關系,建立映射關系并保存。當元數據信息變更時,該系統能夠比對當前任務的數據血緣映射關系,并對變更內容進行標記,同步變更相關的數據任務信息。這有助于解決數據任務在數據血緣變更時需人工解析影響的問題。
3、在當前的大數據時代背景下,數據的準確性和可追溯性對于保障數據質量和業務決策至關重要。然而,現有技術在自動化構建數據血緣關系方面存在明顯不足,特別是在處理大規模或復雜數據流的場景下,這些方法往往表現出較低的自動化程度、準確性不足,以及適應性不強。
技術實現思路
1、本發明所要解決的技術問題是提供一種基于任務運行日志實現表級血緣關系信息構建的方法,能夠高效、準確地從任務運行日志中構建表級數據血緣關系。
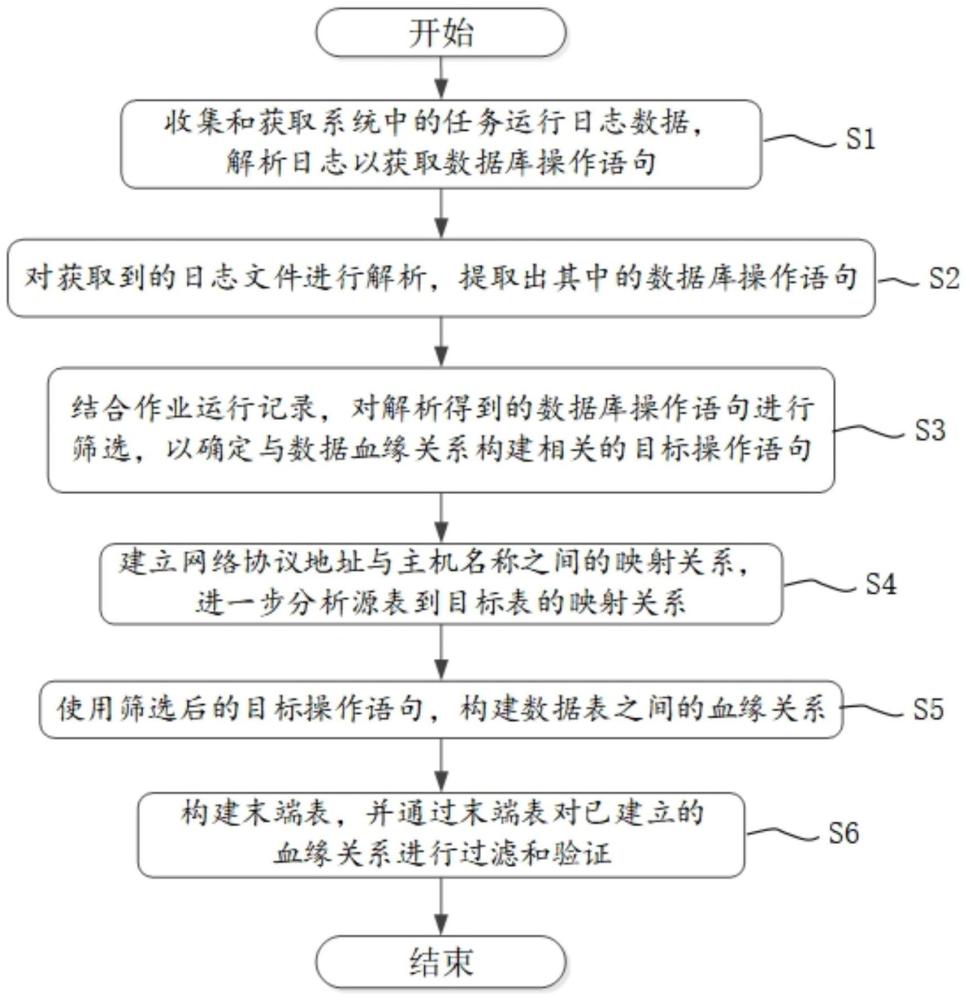
2、本發明為解決上述技術問題而采用的技術方案是提供一種基于任務運行日志實現表級血緣關系信息構建的方法,包括如下步驟:s1)收集和獲取系統中的任務運行日志數據,解析日志以獲取數據庫操作語句;s2)對獲取到的日志文件進行解析,提取出其中的數據庫操作語句;s3)結合作業運行記錄,對解析得到的數據庫操作語句進行篩選,以確定與數據血緣關系構建相關的目標操作語句;s4)建立網絡協議地址與主機名稱之間的映射關系,進一步分析源表到目標表的映射關系;s5)使用篩選后的目標操作語句,構建數據表之間的血緣關系。
3、進一步地,所述步驟s1中任務運行日志數據為純文本格式或json格式,包含日期、時間、日志級別和日志內容。
4、進一步地,所述步驟s3基于解析得到的數據庫操作語句和元數據,自動識別并配置數據加工任務的批次依賴關系,生成批次調度信息,規定每個數據加工任務的執行順序、時間以及所需的資源。
5、進一步地,所述步驟s2使用正則表達式或字符串處理方式將數據庫操作語句從作業運行記錄中分離出來,所述步驟s3完成初步篩選后,所述步驟s4結合映射關系進行如下精確篩選:通過dns系統、hosts文件和/或網絡配置文件,建立網絡協議地址與主機名稱之間的映射關系;在解析數據庫操作語句的同時,記錄操作語句的來源信息,包括發起操作的客戶端ip地址和主機名稱;將操作語句的來源信息與網絡協議與主機名映射關系進行匹配;根據數據血緣關系構建的需求,結合操作語句的來源信息進一步篩選目標操作語句。
6、進一步地,所述步驟s5包括:s51、確定需要管理的數據類型,并定義元數據屬性;s52、識別數據源,利用元數據抽取工具或服務,自動化地收集所述數據源中的元數據;s53、從收集到的元數據中,篩選出與目標操作相關的語句;并對篩選出的操作語句進行解析,識別出數據表之間的依賴關系和數據流動路徑;s54、確定血緣關系類型和設計圖模型;s55、根據解析出的操作語句和設計圖模型,實現算法來追蹤數據的流動路徑;確定從一個數據元素到另一個數據元素的完整路徑,包括所有中間步驟和轉換;s56、使用圖數據庫或圖處理框架來存儲血緣關系,并提供查詢機制;s57、實時或定期監控數據源的變化,并根據監控到的變化,及時更新血緣關系圖模型和存儲的數據。
7、進一步地,所述步驟s51中的數據類型包括數據庫表、字段、視圖和存儲過程,所述元數據屬性包括名稱、描述、數據類型、來源和去向。
8、進一步地,所述步驟s54中的血緣關系類型包括上游/下游關系、父子關系和依賴關系,所述設計圖模型為有向圖、無向圖或混合圖。
9、進一步地,還包括步驟s6:構建末端表,并通過末端表對已建立的血緣關系進行過濾和驗證;所述末端表為數據流程中的最終輸出表或目標表,所述末端表接收來自上游表的數據,并作為數據血緣關系鏈的終點。
10、進一步地,所述步驟s6包括:s61、選擇數據流程中的最終輸出表或目標表為末端表,所述末端表接收來自上游表的數據,并作為數據血緣關系鏈的終點;s62、根據數據流程圖和元數據管理信息,識別出所有的末端表;收集末端表的屬性信息,包括表名、字段名、數據類型和數據格式;s63、建立末端表過濾規則;s64、應用過濾規則進行自動化過濾或手動驗證;s65、驗證血緣關系的準確性;s66、實時或定期監控數據源的變化,根據驗證結果和業務需求,對過濾規則和驗證方法進行持續優化和更新。
11、進一步地,所述步驟s63中的過濾規則包括:數據完整性規則:確保末端表中的數據是完整的,沒有缺失或重復的數據;數據一致性規則:檢查末端表中的數據是否與上游表的數據保持一致,包括字段值、數據類型和數據格式;數據有效性規則:驗證末端表中的數據是否滿足業務規則和邏輯約束;所述步驟s65包括:追溯數據流動路徑:從末端表開始,向上游追溯數據的流動路徑,驗證每個數據流轉步驟的正確性;檢查數據轉換邏輯:驗證數據在流轉過程中的轉換邏輯是否正確,包括字段的映射和數據的計算;對比元數據與實際數據:將元數據中的血緣關系與實際數據流動路徑進行對比,確保兩者一致。
12、本發明對比現有技術有如下的有益效果:本發明提供的基于任務運行日志實現表級血緣關系信息構建的方法,通過深入分析任務運行日志,能夠自動識別關鍵數據操作,構建起數據表之間的血緣聯系,從而顯著提升數據血緣分析的效率和準確性。這不僅減輕了數據分析師的負擔,還增強了數據處理流程的透明度和可靠性。具體優點如下:1、提高效率:自動化的血緣關系構建大幅減少了人工干預,縮短了數據處理時間。2、增強準確性:通過精確識別數據流向,降低了因手動追蹤可能出現的錯誤。3、提升適應性:本發明能夠適應不同的數據環境和結構,具有較好的通用性和靈活性。4、保障數據安全:準確的血緣關系有助于快速定位數據問題,為數據安全提供了額外的保障。
技術特征:
1.一種基于任務運行日志實現表級血緣關系信息構建的方法,其特征在于,包括如下步驟:
2.如權利要求1所述的基于任務運行日志實現表級血緣關系信息構建的方法,其特征在于,所述步驟s1中任務運行日志數據為純文本格式或json格式,包含日期、時間、日志級別和日志內容。
3.如權利要求1所述的基于任務運行日志實現表級血緣關系信息構建的方法,其特征在于,所述步驟s3基于解析得到的數據庫操作語句和元數據,自動識別并配置數據加工任務的批次依賴關系,生成批次調度信息,規定每個數據加工任務的執行順序、時間以及所需的資源。
4.如權利要求1所述的基于任務運行日志實現表級血緣關系信息構建的方法,其特征在于,所述步驟s2使用正則表達式或字符串處理方式將數據庫操作語句從作業運行記錄中分離出來,所述步驟s3完成初步篩選后,所述步驟s4結合映射關系進行如下精確篩選:
5.如權利要求1所述的基于任務運行日志實現表級血緣關系信息構建的方法,其特征在于,所述步驟s5包括:
6.如權利要求5所述的基于任務運行日志實現表級血緣關系信息構建的方法,其特征在于,所述步驟s51中的數據類型包括數據庫表、字段、視圖和存儲過程,所述元數據屬性包括名稱、描述、數據類型、來源和去向。
7.如權利要求5所述的基于任務運行日志實現表級血緣關系信息構建的方法,其特征在于,所述步驟s54中的血緣關系類型包括上游/下游關系、父子關系和依賴關系,所述設計圖模型為有向圖、無向圖或混合圖。
8.如權利要求1所述的基于任務運行日志實現表級血緣關系信息構建的方法,其特征在于,還包括步驟s6:構建末端表,并通過末端表對已建立的血緣關系進行過濾和驗證;所述末端表為數據流程中的最終輸出表或目標表,所述末端表接收來自上游表的數據,并作為數據血緣關系鏈的終點。
9.如權利要求8所述的基于任務運行日志實現表級血緣關系信息構建的方法,其特征在于,所述步驟s6包括:
10.如權利要求8所述的基于任務運行日志實現表級血緣關系信息構建的方法,其特征在于,所述步驟s63中的過濾規則包括:
技術總結
本發明公開了一種基于任務運行日志實現表級血緣關系信息構建的方法,包括如下步驟:S1)收集和獲取系統中的任務運行日志數據,解析日志以獲取數據庫操作語句;S2)對獲取到的日志文件進行解析,提取出其中的數據庫操作語句;S3)結合作業運行記錄,對解析得到的數據庫操作語句進行篩選,以確定與數據血緣關系構建相關的目標操作語句;S4)建立網絡協議地址與主機名稱之間的映射關系,進一步分析源表到目標表的映射關系;S5)使用篩選后的目標操作語句,構建數據表之間的血緣關系。本發明通過深入分析任務運行日志,能夠自動識別關鍵數據操作,構建起數據表之間的血緣聯系,從而顯著提升數據血緣分析的效率和準確性。
技術研發人員:劉迎風,張向飛,劉辰昀,潘佳,翁程凱,汪瑜,范倍銘
受保護的技術使用者:上海市大數據中心
技術研發日:
技術公布日:2025/4/28
- 還沒有人留言評論。精彩留言會獲得點贊!