實時量化單元的內存優化方法、系統及電子設備
本申請涉及內存控制,特別是涉及實時量化單元的內存優化。
背景技術:
1、當前,大語言模型(llm)的推理呈現出內存帶寬受限(memory-bound)的特性。因此,優化內存使用成為加速llm推理的關鍵,其中模型權重和kv緩存是內存開銷的主要來源。量化技術是減少內存開銷的主要方法,傳統的大語言模型量化方法通常在張量(tensor)或通道(channel)級別進行映射,分別稱為張量級量化或通道級量化。在這種情況下,異常值(outlier)會顯著影響量化性能,因為它們會大幅增加整個張量或通道內標準值的舍入誤差。為了解決異常值帶來的挑戰,許多研究提出了分組(group)量化方法。分組量化使用較小的分組(例如通道內連續的64個元素)作為量化的基本單元。盡管每個分組引入的映射參數帶來了些許開銷,但細粒度的分組量化能夠將異常值的影響限制在較小的區域內,從而提升整體量化性能。
2、在分組級別上的數據分布多樣性顯著高于張量級別。簡而言之,盡管不同張量之間表現出類似的分布,但張量中不同分組的分布卻可能存在顯著差異。這一觀察強調了在分組量化中實現全面自適應的重要性,分組量化是一種加速大語言模型的新興范式,而顯著的分組級別多樣性需要高度的自適應性才能充分釋放其潛力。因此,找到數據分布與特定數據類型之間的對應關系顯得十分重要,這將顯著提升權重和kv緩存的量化效果。此外,對于kv緩存來說,還需要動態決定每個分組的縮放因子以及數據類型,這為量化過程帶來了一定的挑戰。
3、本發明主要提出一種基于數據分布的統計特征決定其數據類型的方法,并且設計相應的架構支持,支持kv緩存的動態自適應數據類型量化。
技術實現思路
1、鑒于以上所述現有技術的缺點,本申請的目的在于提供一種實時量化單元的內存優化方法、系統及電子設備,用于通過kv緩存的動態自適應數據類型量化,優化實時量化單元的內存,以提高模型推理的效率。
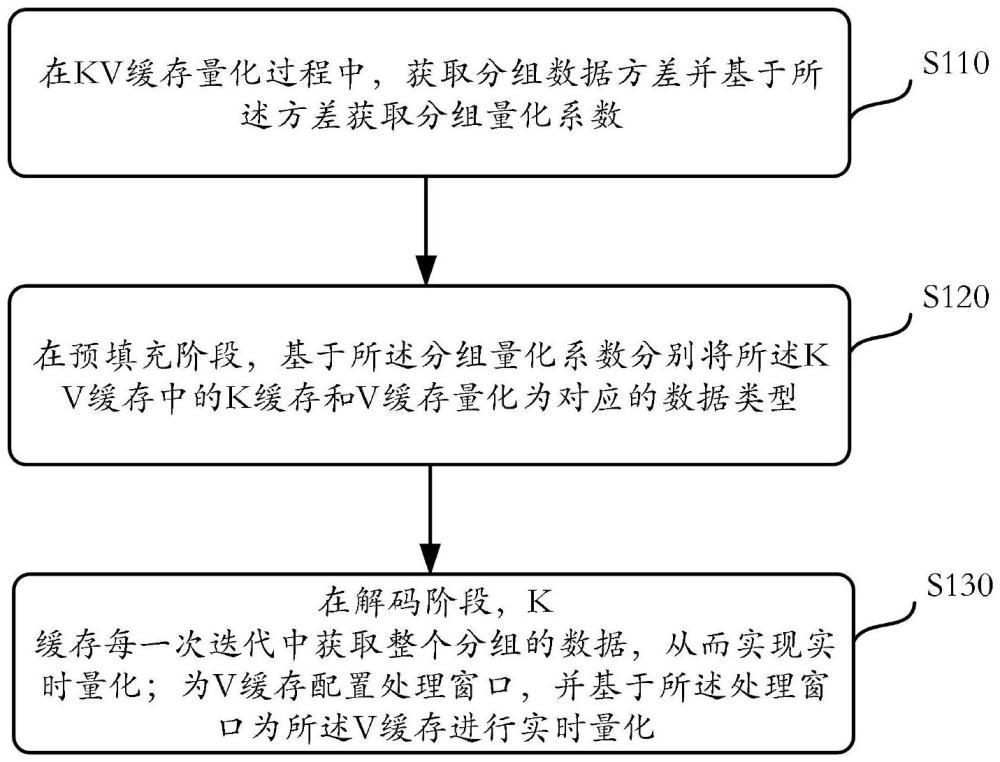
2、為實現上述目的及其他相關目的,本申請提供一種實時量化單元的內存優化方法,所述方法包括:在kv緩存量化過程中,獲取分組數據方差并基于所述方差獲取分組量化系數;在預填充階段,基于所述分組量化系數分別將所述kv緩存中的k緩存和v緩存量化為對應的數據類型;在解碼階段,k緩存每一次迭代中獲取整個分組的數據,從而實現實時量化;為v緩存配置處理窗口,并基于所述處理窗口為所述v緩存進行實時量化。
3、于本申請的一實施例中,所述獲取分組數據方差并基于所述方差獲取分組量化系數包括:對所述分組數據進行流式處理,計算所述分組數據的方差;基于預先配置的所述方差與數據類型的映射關系,獲取當前分組的分組量化系數。
4、于本申請的一實施例中,所述方差呈高斯分布。
5、于本申請的一實施例中,在所述預填充階段,輸入數據為序列數據,所述k緩存和所述v緩存為矩陣數據;所述k緩存和v緩存被量化為4位的數據類型。
6、于本申請的一實施例中,在所述解碼階段,輸入數據為向量數據,所述k緩存和所述v緩存為向量數據。
7、于本申請的一實施例中,所述為v緩存配置處理窗口,并基于所述處理窗口為所述v緩存進行實時量化包括:將解碼階段中的每g次迭代定義為v緩存的一個處理窗口;其中,g為分組大小;對v緩存進行量化處理,直至所述處理窗口被填滿;當所述處理窗口被填滿時,計算當前數據的量化系數,并基于當前數據的量化系數為所述v緩存進行實時量化。
8、于本申請的一實施例中,對v緩存進行量化處理,直至所述處理窗口被填滿中,所述v緩存被量化為8位的數據類型;所述當所述處理窗口被填滿時,計算當前數據的量化系數,并基于當前數據的量化系數為所述v緩存進行實時量化中,8位的數據類型所述v緩存被量化為4位的數據類型。
9、為實現上述目的及其他相關目的,本申請還提供一種實時量化單元的內存優化系統,用于執行上述如上所述的實時量化單元的內存優化方法,所述實時量化單元的內存優化系統包括:多個實時量化單元,每一個所述實時量化單元包括一個比較器和兩個累加器。
10、于本申請的一實施例中,所述實時量化單元的的數量與脈動陣列的大小相匹配,用于以流水線的方式計算k緩存和v緩存的最大值并計算方差。
11、為實現上述目的及其他相關目的,本申請還提供一種電子設備,包括如上所述的實時量化單元的內存優化系統。
12、如上所述,本申請的實時量化單元的內存優化方法、系統及電子設備具有以下有益效果:
13、本申請可以支持kv緩存的動態自適應數據類型量化,優化實時量化單元的內存,以提高模型推理的效率。
技術特征:
1.一種實時量化單元的內存優化方法,其特征在于:所述方法包括:
2.根據權利要求1所述的實時量化單元的內存優化方法,其特征在于:所述獲取分組數據方差并基于所述方差獲取分組量化系數包括:
3.根據權利要求2所述的實時量化單元的內存優化方法,其特征在于:所述方差呈高斯分布。
4.根據權利要求1所述的實時量化單元的內存優化方法,其特征在于:在所述預填充階段,輸入數據為序列數據,所述k緩存和所述v緩存為矩陣數據;所述k緩存和v緩存被量化為4位的數據類型。
5.根據權利要求1或4所述的實時量化單元的內存優化方法,其特征在于:在所述解碼階段,輸入數據為向量數據,所述k緩存和所述v緩存為向量數據。
6.根據權利要求1所述的實時量化單元的內存優化方法,其特征在于:所述為v緩存配置處理窗口,并基于所述處理窗口為所述v緩存進行實時量化包括:
7.根據權利要求6所述的實時量化單元的內存優化方法,其特征在于:對v緩存進行量化處理,直至所述處理窗口被填滿中,所述v緩存被量化為8位的數據類型;所述當所述處理窗口被填滿時,計算當前數據的量化系數,并基于當前數據的量化系數為所述v緩存進行實時量化中,8位的數據類型所述v緩存被量化為4位的數據類型。
8.一種實時量化單元的內存優化系統,用于執行上述如權利要求1至權利要求7任一權利要求所述的實時量化單元的內存優化方法,其特征在于:所述實時量化單元的內存優化系統包括:多個實時量化單元,每一個所述實時量化單元包括一個比較器和兩個累加器。
9.根據權利要求8所述的實時量化單元的內存優化系統,其特征在于:所述實時量化單元的的數量與脈動陣列的大小相匹配,用于以流水線的方式計算k緩存和v緩存的最大值并計算方差。
10.一種電子設備,其特征在于,包括如權利要求8和權利要求9所述的實時量化單元的內存優化系統。
技術總結
本申請提供一種實時量化單元的內存優化方法、系統及電子設備,所述方法包括:在KV緩存量化過程中,獲取分組數據方差并基于所述方差獲取分組量化系數;在預填充階段,基于所述分組量化系數分別將所述KV緩存中的K緩存和V緩存量化為對應的數據類型;在解碼階段,K緩存每一次迭代中獲取整個分組的數據,從而實現實時量化;為V緩存配置處理窗口,并基于所述處理窗口為所述V緩存進行實時量化。本申請可以支持KV緩存的動態自適應數據類型量化,優化實時量化單元的內存,以提高模型推理的效率。
技術研發人員:冷靜文,胡洧銘,過敏意
受保護的技術使用者:上海交通大學
技術研發日:
技術公布日:2025/4/28
- 還沒有人留言評論。精彩留言會獲得點贊!