基于空間語義增強的醫學文檔語義實體識別方法及系統
本發明涉及自然語言處理、計算機視覺和醫學信息處理領域,特別是涉及一種用于多模態醫學文檔的理解與分析的語義實體識別方法及系統,具體包括利用空間語義信息增強對醫學文檔中語義實體的識別能力,適用于包括化驗單、門診記錄等在內的多種復雜醫學文檔的結構化處理和語義分析。
背景技術:
1、隨著醫學信息化的快速發展,越來越多的醫學文檔以數字化形式保存,這些文檔包括化驗單、門診記錄、電子病歷等,包含了大量重要的患者信息、診斷結果、治療方案等關鍵醫學數據。然而,這些醫學文檔的格式多樣、布局復雜,且存在手寫文本、掃描文檔等多種形式,給信息提取和自動化處理帶來了巨大的挑戰。
2、傳統的光學字符識別(ocr)技術可以用于提取文檔中的文本信息,但僅依靠ocr提取的文本往往難以有效理解文檔的語義結構和空間關系,尤其在醫學文檔中,不同文本區域之間的空間布局對于理解文檔內容至關重要。例如,化驗單中的各項檢查結果往往以特定的空間位置關聯,并且不同類別的語義實體,如患者信息、檢查項目和結果等,需要準確區分和關聯。傳統的基于文本內容的實體識別方法在處理這些多模態信息時,常常忽略了文本框之間的空間關系,導致識別準確性下降。
3、現有的研究大多集中在自然語言處理領域的語義分析和實體識別,或是在計算機視覺領域的ocr技術上。然而,如何有效結合文本的語義信息與其在文檔中的空間位置信息,仍然是一個亟待解決的問題。特別是在醫學文檔中,由于其高度結構化和標準化的特點,利用空間信息與文本內容的聯合處理能夠大幅提升語義實體識別的準確性和魯棒性。
4、因此,迫切需要一種能夠綜合考慮文本內容與空間布局信息的語義實體識別方法,來處理這些復雜的醫學文檔,進而實現對關鍵醫學信息的自動化提取和分析。這對于提高醫學數據處理的效率和準確性,以及輔助智能醫學系統的構建具有重要意義。
技術實現思路
1、針對上述問題,本發明的目的在于提供一種結合空間語義信息和語義特征的多模態醫學文檔理解方案,旨在解決現有技術中由于忽略文本框之間幾何關系等(如距離和角度)而導致的語義實體識別準確性不足的問題。通過引入幾何增強模塊,將文本框之間的空間信息與現有模型的預訓練語義特征進行融合,從而提升在復雜布局和小樣本數據集上的識別性能,尤其是提高模型對醫學文檔中復雜實體的分類能力,克服傳統模型對空間信息利用不足的局限性。
2、具體而言,本發明提供如下技術方案:
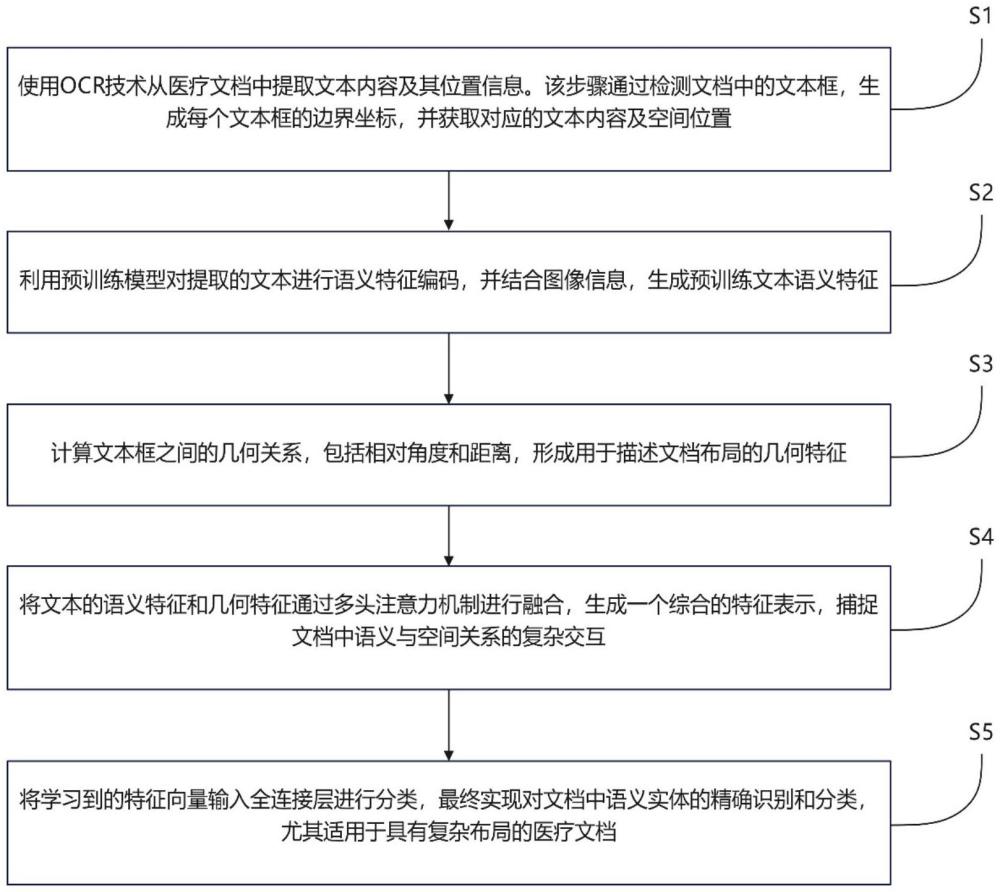
3、一方面,本發明提供了一種基于空間語義增強的醫學文檔語義實體識別方法,該方法包括以下步驟:
4、s1、制作數據集:標注多來源醫學文檔圖像,涵蓋患者信息、檢查項目、診斷結果等的醫學實體數據,確保位置與語義準確無誤;通過數據增強擴充數據集,提升數據多樣性,獲得醫學文檔圖像;
5、s2、通過光學字符識別提取醫學文檔圖像中的文本內容,并獲取文本框的位置坐標;
6、s3、將醫學文檔圖像、s2輸出的文本框的位置坐標及文本內容一起送入文檔理解預訓練模型(如layoutxlm),得到文本特征;
7、s3、空間語義信息提取:基于s2輸出的文本框的位置坐標,計算文本框之間的空間關系,所述空間關系包括文本框之間的相對距離和角度,所述空間關系構成空間語義信息,用于反映文檔中文本框的布局和相互關聯;
8、s4、文本特征與空間語義信息融合:將s2中經過ocr生成的文本特征與空間語義信息結合,形成時空特征矩陣;所述融合方式為:通過多層感知機(mlp)對空間語義信息進行投射,使其與文本特征在同一特征空間中進行表達,實現空間布局信息和文本內容的有效融合;
9、s5、將文本特征與空間語義信息融合后的時空特征矩陣輸入多頭注意力模塊,利用多頭注意力模塊對文本框之間的依賴關系進行計算,通過注意力權重的分配,突出關鍵的語義實體并忽略無關信息;
10、s6、語義實體識別:通過分類器,對經過多頭注意力模塊處理的文本特征進行分類,識別出每個文本框的語義類別,并輸出其對應的置信度。
11、可選地,所述步驟s1中,文本與位置提取,包括:
12、使用ocr技術進行文檔預處理,將醫學文檔圖像進行預處理,提升ocr檢測的效果,具體包括圖像去噪、對比度增強和尺寸縮放;
13、使用dbnet模型檢測文檔中的文本區域,生成每個文本框的邊界坐標(左上角和右下角坐標)。該步驟確保可以精確識別出所有文本塊;
14、利用crnn模型對檢測出的文本框內容進行字符識別,將圖像中的文字轉換為可讀文本。該模型結合了卷積神經網絡(cnn)用于特征提取,和循環神經網絡(rnn)用于序列預測;
15、最終輸出文本內容及其對應的文本框位置坐標,這些信息將用于后續的語義與空間語義特征提取步驟。
16、可選地,所述步驟s2中,語義與空間語義特征提取,包括:
17、使用layoutxlm預訓練模型,對每個文本塊的內容進行語義編碼,生成對應的文本語義向量。此模型結合了文本與布局信息,可以更好地理解文檔的空間結構。
18、可選地,所述步驟s3中,特征融合,包括:
19、根據文本框的邊界坐標,計算文本框之間的幾何關系。具體包括:計算文本框的中心點坐標、計算每個文本框中心點之間的歐氏距離,生成距離矩陣、計算文本框之間的相對角度,生成角度矩陣;
20、對距離和角度矩陣進行歸一化處理,確保不同文檔尺寸或格式下,空間語義特征具有一致性;
21、將提取的語義特征與歸一化的空間語義特征輸出,作為后續步驟中進行特征融合的輸入。
22、可選地,所述步驟s4中,特征融合,包括:
23、構建多頭注意力機制,通過多頭注意力機制,將每個文本塊的語義特征與其空間語義特征進行權重計算,以生成融合后的特征。多頭注意力機制允許模型在不同的注意力頭上捕捉不同特征間的關系;
24、使用transformer架構中的自注意力機制,計算每個文本框與其他文本框之間的注意力權重。這些權重基于語義特征與空間語義特征的相互關系;
25、根據計算出的注意力權重,對文本特征和空間語義特征進行加權,生成融合后的特征表示。這種融合能夠捕捉到文本塊之間的空間和語義交互關系;
26、輸出經過注意力機制加權后的融合特征,作為最終分類模型的輸入。
27、可選地,所述步驟s5中,實體識別與分類,包括:
28、將融合后的特征輸入多層感知機(mlp),通過若干全連接層對特征進行進一步處理。每一層都會通過非線性激活函數(如relu)來增強模型的表示能力;
29、在模型訓練過程中,使用交叉熵損失函數來優化模型參數。該損失函數適用于分類任務,能夠有效處理多類別實體的分類問題;
30、模型通過訓練完成對醫學文檔中不同語義實體的分類,分類結果包括如患者信息、診斷結果、檢驗報告等;
31、最終輸出分類結果,表示文檔中每個文本塊所對應的語義類別,實現對文檔語義實體的精確識別。
32、另一方面,本發明還提供了基于空間語義增強的醫學文檔語義實體識別系統,包括:
33、ocr模塊,用于檢測和識別醫學文檔圖像中的文本區域,輸出文本框的內容及其對應的空間坐標信息,以得到文本特征;
34、空間語義信息提取模塊,用于基于文本框的空間坐標信息,計算文本框之間的相對距離和角度,生成空間語義信息;
35、特征融合模塊,用于將ocr模塊得到的文本特征與空間語義信息進行融合,生成時空特征;
36、注意力機制模塊,通過多頭注意力機制處理融合后的時空特征,突出重要的文本框信息,生成最終的語義特征;
37、分類模塊,用于對處理后的語義特征進行分類,輸出每個文本框的類別和對應的置信度。
38、再一方面,本發明還提供了一種電子設備,所述電子設備包括:
39、處理器;
40、存儲器,所述存儲器上存儲有計算機可讀指令,所述計算機可讀指令被所述處理器加載并執行時,實現如上述針對醫學文檔語義實體數據提取與生成方法的步驟。
41、另一方面,提供了一種計算機可讀存儲介質,所述計算機可讀存儲介質中存儲有程序代碼,所述程序代碼可被處理器調用執行如上述針對醫學文檔語義實體數據提取與生成方法的步驟。
42、本發明提供的技術方案帶來的有益效果至少包括:
43、本發明針對現有醫學文檔理解模型對空間信息利用不足、語義特征提取不充分、布局復雜性處理能力欠缺等問題,提出了一種結合幾何關系的多模態醫學文檔理解方法。本方案有效解決了因忽視文本框幾何關系(如角度和距離)而導致的語義實體識別精度不高的問題,尤其在復雜文檔布局和小樣本數據集上表現出更強的魯棒性。通過對文本框之間的空間特征進行挖掘,能夠精確捕捉不同實體之間的空間關系,提升了醫學文檔中復雜語義實體的識別與分類能力,為醫學智能文檔處理系統提供了高質量的特征輸入。
44、本醫學方案不僅在語義實體識別上表現出更高的精度,還通過將幾何關系與語義信息結合,顯著擴展了模型的適應性與泛化能力。該技術方案可以有效提高醫學文檔的處理效率和準確性,為實現醫學信息自動化處理、病歷分類、病人信息提取等智能應用提供優質的數據基礎,對醫學文檔處理領域中的智能診療系統和自動信息提取算法的發展提供重要的支持。
45、本方案可應用于電子病歷系統的自動化數據處理、醫學文檔分類和信息提取等多個醫學相關領域,能夠為醫學智能系統和相關算法提供有效的數據支撐,助力醫學文檔處理的智能化、精準化發展,推動醫學信息處理與分析技術的進步。
- 還沒有人留言評論。精彩留言會獲得點贊!