基于大模型的文件元數據的生成方法、裝置、設備和介質與流程
本公開涉及ai(artificial?intelligence,人工智能)領域,具體涉及nlp(natural?language?processing,自然語言處理)、大模型、llm(large?language?model,大語言模型)、深度學習、大數據等,尤其涉及基于大模型的文件元數據的生成方法、裝置、設備和介質。
背景技術:
1、隨著信息化技術的飛速發展,數據量呈現出爆炸性增長的趨勢,在這龐大的數據海洋中,非結構化數據占據了絕大多數。由于這些非結構化數據的數據量巨大且種類繁多,傳統的數據管理方式已經無法滿足高效存儲、檢索和分析的需求,因此,為了更好地管理和利用這些寶貴的資源,對非結構化文件的元數據進行自動提取變得尤為重要。
技術實現思路
1、本公開提供了一種用于基于大模型的文件元數據的生成方法、裝置、設備和介質。
2、根據本公開的一方面,提供了一種基于大模型的文件元數據的生成方法,包括:
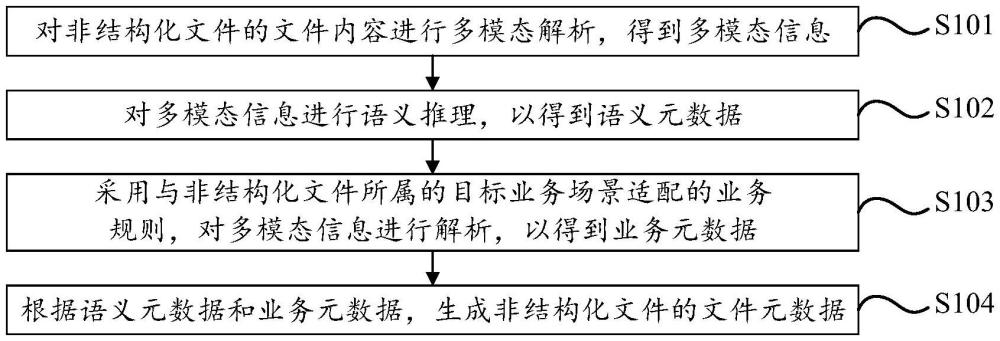
3、對非結構化文件的文件內容進行多模態解析,得到多模態信息;
4、對所述多模態信息進行語義推理,以得到語義元數據;
5、采用與所述非結構化文件所屬的目標業務場景適配的業務規則,對所述多模態信息進行解析,以得到業務元數據;
6、根據所述語義元數據和所述業務元數據,生成所述非結構化文件的文件元數據。
7、根據本公開的另一方面,提供了一種基于大模型的文件元數據的生成裝置,包括:
8、第一解析模塊,用于對非結構化文件的文件內容進行多模態解析,得到多模態信息;
9、語義推理模塊,用于對所述多模態信息進行語義推理,以得到語義元數據;
10、第二解析模塊,用于采用與所述非結構化文件所屬的目標業務場景適配的業務規則,對所述多模態信息進行解析,以得到業務元數據;
11、生成模塊,用于根據所述語義元數據和所述業務元數據,生成所述非結構化文件的文件元數據。
12、根據本公開的再一方面,提供了一種電子設備,包括:
13、至少一個處理器;以及
14、與所述至少一個處理器通信連接的存儲器;其中,
15、所述存儲器存儲有可被所述至少一個處理器執行的指令,所述指令被所述至少一個處理器執行,以使所述至少一個處理器能夠執行本公開上述一方面提出的基于大模型的文件元數據的生成方法。
16、根據本公開的又一方面,提供了一種計算機指令的非瞬時計算機可讀存儲介質,所述計算機指令用于使所述計算機執行本公開上述一方面提出的基于大模型的文件元數據的生成方法。
17、根據本公開的還一方面,提供了一種計算機程序產品,包括計算機程序,所述計算機程序在被處理器執行時實現本公開上述一方面提出的基于大模型的文件元數據的生成方法。
18、應當理解,本部分所描述的內容并非旨在標識本公開的實施例的關鍵或重要特征,也不用于限制本公開的范圍。本公開的其它特征將通過以下的說明書而變得容易理解。
技術特征:
1.一種基于大模型的文件元數據的生成方法,包括:
2.根據權利要求1所述的方法,其中,所述根據所述語義元數據和所述業務元數據,生成所述非結構化文件的文件元數據,包括:
3.根據權利要求2所述的方法,其中,所述非結構化文件的復雜屬性,采用以下步驟獲取得到:
4.根據權利要求3所述的方法,其中,所述根據所述第一嵌套關系、所述編碼方式和所述內容質量中的至少一項,獲取所述非結構化文件的復雜屬性,包括:
5.根據權利要求1所述的方法,其中,所述對所述多模態信息進行語義推理,以得到所述非結構化文件的語義元數據,包括:
6.根據權利要求1所述的方法,其中,所述對所述多模態信息進行語義推理,以得到所述非結構化文件的語義元數據,包括:
7.根據權利要求6所述的方法,其中,所述提示模版中還包括參考示例,其中,所述參考示例中包括所述目標業務場景下的參考文本以及所述參考文本中的語義信息。
8.根據權利要求1-7中任一項所述的方法,其中,所述多模態信息包括以下至少一項:
9.根據權利要求8所述的方法,其中,所述視頻文本描述是采用以下步驟獲取得到的:
10.根據權利要求1-7中任一項所述的方法,其中,所述方法還包括:
11.根據權利要求10所述的方法,其中,所述方法還包括:
12.一種基于大模型的文件元數據的生成裝置,包括:
13.一種電子設備,包括:
14.一種存儲有計算機指令的非瞬時計算機可讀存儲介質,其中,所述計算機指令用于使所述計算機執行根據權利要求1-11中任一項所述的基于大模型的文件元數據的生成方法。
15.一種計算機程序產品,包括計算機程序,所述計算機程序在被處理器執行時實現根據權利要求1-11中任一項所述基于大模型的文件元數據的生成方法的步驟。
技術總結
本公開提供了一種基于大模型的文件元數據的生成方法、裝置、設備和介質,涉及人工智能領域,具體涉及NLP、大模型、LLM、深度學習、大數據等技術領域。具體實現方案為:對非結構化文件的文件內容進行多模態解析,得到多模態信息;對多模態信息進行語義推理,以得到語義元數據;采用與非結構化文件所屬的目標業務場景適配的業務規則,對多模態信息進行解析,以得到業務元數據;根據語義元數據和業務元數據,生成非結構化文件的文件元數據。
技術研發人員:任啟強
受保護的技術使用者:北京百度網訊科技有限公司
技術研發日:
技術公布日:2025/4/28
- 還沒有人留言評論。精彩留言會獲得點贊!