一種基于半監督學習的企業信用評估方法及其相關設備與流程
本技術涉及科技金融,具體涉及一種基于半監督學習的企業信用評估方法及其相關設備。
背景技術:
1、企業信用貸款是指基于企業的經營情況、信用記錄及還款能力,無需提供實物抵押,由銀行或其他金融機構發放的一種貸款方式,主要用于解決企業短期資金需求,促進企業資金周轉,助力企業快速發展,具有申請便捷、審批快速的特點。企業信用貸款與企業信用息息相關,良好的企業信用記錄往往能助力企業更輕松地獲得貸款批準,享受更低的利率和更靈活的還款條件。反之,信用不佳的企業可能面臨貸款難、利率高的問題,影響企業的資金運作和發展計劃。
2、因此,企業信用貸款的一個關鍵環節是企業信用評估。目前企業信用評估的主要方式包括基于專家經驗的人工評估方式和基于機器學習的有監督評估方式,但是這兩者評估方式都存在對應的缺陷。例如,人工評估依賴于評估人員的經驗和判斷,可能存在主觀性和不一致性;而有監督的機器學習評估方式則依賴于歷史數據的準確性和完整性,若數據標注存在偏差,預測結果可能不準確,而且構造滿足有監督評估方式數量要求的標注樣本需要大量人工的投入,費時費力,此外如果未進行數據集的及時更新,對于新型風險或異常數據,有監督評估方式可能無法有效識別。
技術實現思路
1、本技術實施例的目的在于提出一種基于半監督學習的企業信用評估方法、裝置、計算機設備及存儲介質,以解決現有企業信用評估方法存在的投入工作量大,且評估準確度不高的技術問題。
2、為了解決上述技術問題,本技術實施例提供一種基于半監督學習的企業信用評估方法,采用了如下所述的技術方案:
3、一種基于半監督學習的企業信用評估方法,包括:
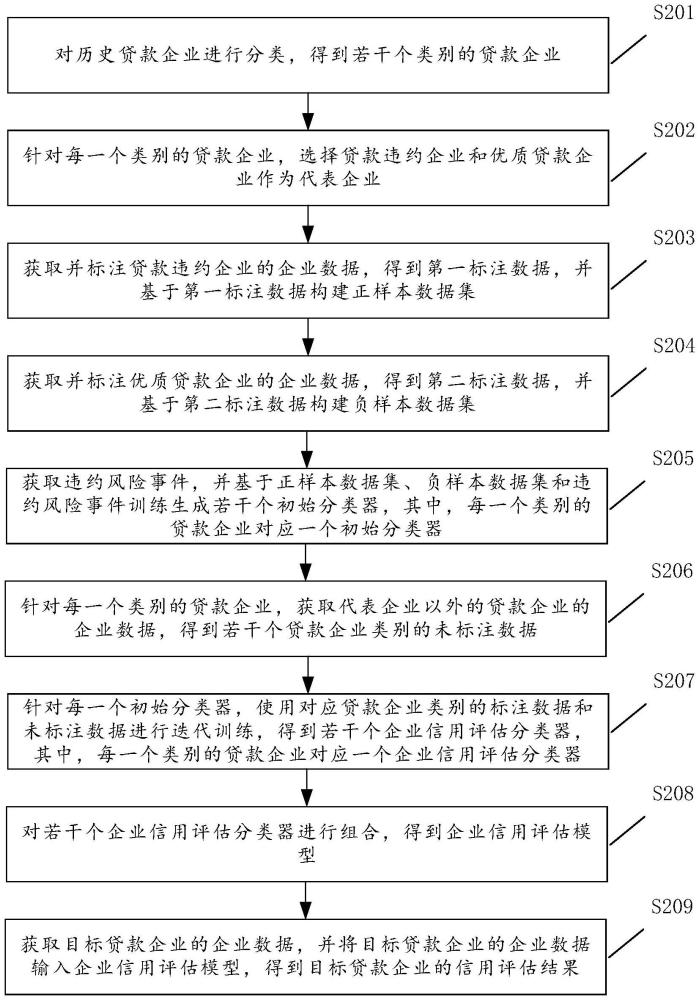
4、對歷史貸款企業進行分類,得到若干個類別的貸款企業;
5、針對每一個類別的貸款企業,選擇貸款違約企業和優質貸款企業作為代表企業;
6、獲取并標注貸款違約企業的企業數據,得到第一標注數據,并基于第一標注數據構建正樣本數據集;
7、獲取并標注優質貸款企業的企業數據,得到第二標注數據,并基于第二標注數據構建負樣本數據集;
8、獲取違約風險事件,并基于正樣本數據集、負樣本數據集和違約風險事件訓練生成若干個初始分類器,其中,每一個類別的貸款企業對應一個初始分類器;
9、針對每一個類別的貸款企業,獲取代表企業以外的貸款企業的企業數據,得到若干個貸款企業類別的未標注數據;
10、針對每一個初始分類器,使用對應貸款企業類別的標注數據和未標注數據進行迭代訓練,得到若干個企業信用評估分類器,其中,每一個類別的貸款企業對應一個企業信用評估分類器;
11、對若干個企業信用評估分類器進行組合,得到企業信用評估模型;
12、獲取目標貸款企業的企業數據,并將目標貸款企業的企業數據輸入企業信用評估模型,得到目標貸款企業的信用評估結果。
13、進一步地,針對每一個類別的貸款企業,選擇貸款違約企業和優質貸款企業作為代表企業的步驟,具體包括:
14、獲取違約風險事件,并對違約風險事件進行解析,得到違約風險基準;
15、針對每一個類別中的所有貸款企業,使用違約風險基準進行貸款違約風險評估,得到貸款違約風險評估結果;
16、根據貸款違約風險評估結果對每一個類別中的所有貸款企業進行貸款違約風險排序;
17、選擇貸款違約風險最高的企業作為貸款違約企業,以及選擇貸款違約風險最低的企業作為優質貸款企業;
18、將貸款違約企業和優質貸款企業作為代表企業。
19、進一步地,企業數據包括結構化數據和非結構化數據,獲取并標注貸款違約企業的企業數據,得到第一標注數據,并基于第一標注數據構建正樣本數據集的步驟,具體包括:
20、從預設的數據庫獲取貸款違約企業的企業數據,得到第一企業數據;
21、對第一企業數據進行分類,識別第一企業數據中的結構化數據和非結構化數據;
22、針對第一企業數據中的非結構化數據進行數據結構化處理,得到第一轉化數據;
23、使用違約風險基準對第一企業數據中的結構化數據和第一轉化數據進行數據標注,得到第一標注數據;
24、基于第一標注數據構建正樣本數據集。
25、進一步地,獲取并標注優質貸款企業的企業數據,得到第二標注數據,并基于第二標注數據構建負樣本數據集的步驟,具體包括:
26、從數據庫獲取優質貸款企業的企業數據,得到第二企業數據;
27、對第二企業數據進行分類,識別第二企業數據中的結構化數據和非結構化數據;
28、針對第二企業數據中的非結構化數據進行數據結構化處理,得到第二轉化數據;
29、使用違約風險基準對第二企業數據中的結構化數據和第二轉化數據進行數據標注,得到第二標注數據;
30、基于第二標注數據構建負樣本數據集。
31、進一步地,非結構化數據包括文本數據、語音數據、圖像數據和視頻數據,針對第一企業數據中的非結構化數據進行數據結構化處理,得到第一轉化數據的步驟,具體包括:
32、針對第一企業數據中的文本數據進行文本特征提取,得到第一文本數據特征;
33、針對第一企業數據中的語音數據進行語音轉文本處理,并對得到的語音文本進行文本特征提取,得到第一語音文本特征;
34、針對第一企業數據中的圖像數據進行圖像特征提取,得到第一圖像數據特征;
35、針對第一企業數據中的視頻數據進行視頻關鍵幀提取,并對提取到的視頻關鍵幀進行圖像特征提取,得到第一視頻關鍵幀特征;
36、組合第一文本數據特征、第一語音文本特征、第一圖像數據特征和第一視頻關鍵幀特征,得到第一轉化數據。
37、進一步地,針對第二企業數據中的非結構化數據進行數據結構化處理,得到第二轉化數據的步驟,具體包括:
38、針對第二企業數據中的文本數據進行文本特征提取,得到第二文本數據特征;
39、針對第二企業數據中的語音數據進行語音轉文本處理,并對得到的語音文本進行文本特征提取,得到第二語音文本特征;
40、針對第二企業數據中的圖像數據進行圖像特征提取,得到第二圖像數據特征;
41、針對第二企業數據中的視頻數據進行視頻關鍵幀提取,并對提取到的視頻關鍵幀進行圖像特征提取,得到第二視頻關鍵幀特征;
42、組合第二文本數據特征、第二語音文本特征、第二圖像數據特征和第二視頻關鍵幀特征,得到第二轉化數據。
43、進一步地,基于梯度提升決策樹集成算法訓練生成企業信用評估分類器,針對每一個初始分類器,使用對應貸款企業類別的標注數據和未標注數據進行迭代訓練,得到若干個企業信用評估分類器的步驟,具體包括:
44、針對每一個初始分類器,從對應貸款企業類別的未標注數據中隨機且有放回地采樣抽取目標未標注數據;
45、基于正樣本數據集、負樣本數據集和目標未標注數據構建新的數據訓練集;
46、使用初始分類器對新的數據訓練集進行數據分類學習,并根據數據分類學習結果對初始分類器進行分類器參數調節;
47、針對每一個初始分類器進行循環迭代訓練,直至每一個未標注數據均參與到數據分類學習為止,得到若干個企業信用評估分類器。
48、為了解決上述技術問題,本技術實施例還提供一種基于半監督學習的企業信用評估裝置,采用了如下所述的技術方案:
49、一種基于半監督學習的企業信用評估裝置,包括:
50、企業分類模塊,用于對歷史貸款企業進行分類,得到若干個類別的貸款企業;
51、企業代表模塊,用于針對每一個類別的貸款企業,選擇貸款違約企業和優質貸款企業作為代表企業;
52、第一標注模塊,用于獲取并標注貸款違約企業的企業數據,得到第一標注數據,并基于第一標注數據構建正樣本數據集;
53、第二標注模塊,用于獲取并標注優質貸款企業的企業數據,得到第二標注數據,并基于第二標注數據構建負樣本數據集;
54、第一分類模塊,用于獲取違約風險事件,并基于正樣本數據集、負樣本數據集和違約風險事件訓練生成若干個初始分類器,其中,每一個類別的貸款企業對應一個初始分類器;
55、數據獲取模塊,用于針對每一個類別的貸款企業,獲取代表企業以外的貸款企業的企業數據,得到若干個貸款企業類別的未標注數據;
56、第二分類模塊,用于針對每一個初始分類器,使用對應貸款企業類別的標注數據和未標注數據進行迭代訓練,得到若干個企業信用評估分類器,其中,每一個類別的貸款企業對應一個企業信用評估分類器;
57、分類器組合模塊,用于對若干個企業信用評估分類器進行組合,得到企業信用評估模型;
58、信用評估模塊,用于獲取目標貸款企業的企業數據,并將目標貸款企業的企業數據輸入企業信用評估模型,得到目標貸款企業的信用評估結果。
59、為了解決上述技術問題,本技術實施例還提供一種計算機設備,采用了如下所述的技術方案:
60、一種計算機設備,包括存儲器和處理器,所述存儲器中存儲有計算機可讀指令,所述處理器執行所述計算機可讀指令時實現如上述任一項所述的基于半監督學習的企業信用評估方法的步驟。
61、為了解決上述技術問題,本技術實施例還提供一種計算機可讀存儲介質,采用了如下所述的技術方案:
62、一種計算機可讀存儲介質,所述計算機可讀存儲介質上存儲有計算機可讀指令,所述計算機可讀指令被處理器執行時實現如上述中任一項所述的基于半監督學習的企業信用評估方法的步驟。
63、與現有技術相比,本技術實施例主要有以下有益效果:
64、本技術提供一種基于半監督學習的企業信用評估方法及其相關設備,本技術基于半監督學習的企業信用評估方案,通過利用少量標注數據和大量未標注數據,顯著提升模型對企業信用風險的評估能力,同時降低數據標注的工作量和人工因素的影響。本技術針對不同類別的企業特性分別構建分類器,能夠捕捉各類別特有的信用風險特征,增強了模型的適應性和精確性;通過迭代訓練充分挖掘未標注數據的潛在信息,使模型具有更高的泛化能力和魯棒性;同時,結合多個分類器的集成策略,進一步提高了評估結果的穩定性和準確性。整體模型能夠高效識別貸款企業的信用水平和違約風險,為金融機構提供科學的決策支持,有助于降低信貸風險和優化資源配置。
- 還沒有人留言評論。精彩留言會獲得點贊!