一種基于MySQL協議內存數據庫的Blob數據存儲方法與流程
本發明屬于數據管理,特別涉及一種基于mysql協議內存數據庫的blob數據存儲方法。
背景技術:
1、mysql是一個廣泛使用的關系型數據庫管理系統(rdbms)。mysql提供了數據存儲與管理、數據檢索與查詢、數據處理與優化、數據備份與恢復等豐富的功能,使其成為企業和開發者構建各種規模應用的理想選擇。
2、內存數據庫(in-memory?database,imdb)是一種特殊的數據庫管理系統,它的主要特征是將所有數據存儲在計算機系統的主內存(ram)中,而不是傳統的硬盤驅動器或其他非易失性存儲介質上。由于內存的讀寫速度遠遠高于磁盤存儲,內存數據庫能夠提供非常快速的數據訪問和處理速度,通常響應時間可以達到微秒級。
3、mysql的memory存儲引擎(有時也稱為heap存儲引擎)是一種內存存儲引擎,它將整個表的數據存儲在服務器的ram中,而不是硬盤上。由于數據存儲在內存中,memory引擎提供了非常快的數據訪問速度,不受磁盤i/o限制。這使得memory引擎非常適合用于創建臨時表和高速緩存表,尤其是在需要進行大量讀寫操作的場景下。
4、但現有mysql的memory存儲引擎不支持blob數據的存儲,而其它常見的內存數據庫(如redis、apache?ignite、h2?database等)均支持blob數據存儲,但是不支持mysql協議。并且這些內存數據庫在處理blob數據時存在一些不足:
5、h2?database作為一個關系型數據庫管理系統,支持內存存儲和文件存儲兩種模式。當h2?database采用內存存儲模式時,即可將其當作一個內存數據庫。h2?database支持在內存中存儲blob大對象,但當內存中當存儲的數據量太大時,h2?database存在內存溢出問題。同時h2?database不支持單表的內存存儲和文件存儲混合存儲模式,因此它不能解決存儲大量blob數據時的內存溢出問題。
6、redis使用內存作為其主存儲介質,當數據量過大時,采用過期或淘汰策略釋放內存空間。因此當數據量大時,redis可能面臨數據丟失問題。如果redis關閉數據淘汰策略,又可能出現內存溢出問題。此外,redis提供了數據持久化功能,但是采用的是全量數據持久化的方式,效率較低。
7、apache?ignite提供了一個分布式內存數據網格平臺。和redis類似,apacheignite的數據同樣主要存儲在內存中,apache?ignite的內存分為堆內內存和堆外內存兩部分。apache?ignite先把數據存儲在堆內內存,當堆內內存達到飽和時,講數據存儲到堆外內存。當堆外內存也達到飽和時,ignite會開始將較舊或較少訪問的數據條目溢出到磁盤上。這些數據仍然可以通過查詢和操作訪問,但它們不再駐留在內存中。另外,apacheignite也支持持久化存儲,即在將數據存儲在內存的同時,將數據也持久化存儲。apacheignite的磁盤存儲和持久化存儲均為表數據的全量存儲,并不會單獨針對blob數據存儲。
8、公開號為cn112506937a的中國專利公開了一種數據庫模型的在線配置方法、裝置、設備和介質,方法包括:s1、在瀏覽器上提供數據源配置界面,在用戶配置完成后獲取對應的數據庫的連接后保存配置信息;s2、在瀏覽器上提供數據庫模型的配置界面,配置后的模型信息發到后端,并保存在對應的數據源的數據表以及數據列模型中;s3、在瀏覽器上提供同步數據庫模型信息的界面,供選出未同步的數據庫模型的數據后發送到后臺,再由后臺通過數據庫同步器同步到對應數據源下;s4、若同步成功后,在同步數據庫模型信息的界面更新同步狀態標簽,供用戶查看。根據該方法所述規則,mysql數據庫存儲的blob數據的大小大于一定閾值時,自動轉為mediumblob或longblob,并沒有考慮到數據的實際使用場景,可能導致額外的存儲開銷和管理復雜性;且對于較大的blob數據,mysql會將其存儲在磁盤,訪問這些數據時涉及大量磁盤讀寫操作,可能導致數據檢索速度慢,延遲增大。
技術實現思路
1、本發明提供一種基于mysql協議內存數據庫的blob數據存儲方法,旨在解決blob數據因占用大量內存和長時間寫入,可能導致內存溢出和寫入失敗的問題。
2、為解決上述技術問題,本發明提供一種基于mysql協議內存數據庫的blob數據存儲方法,包括以下步驟:
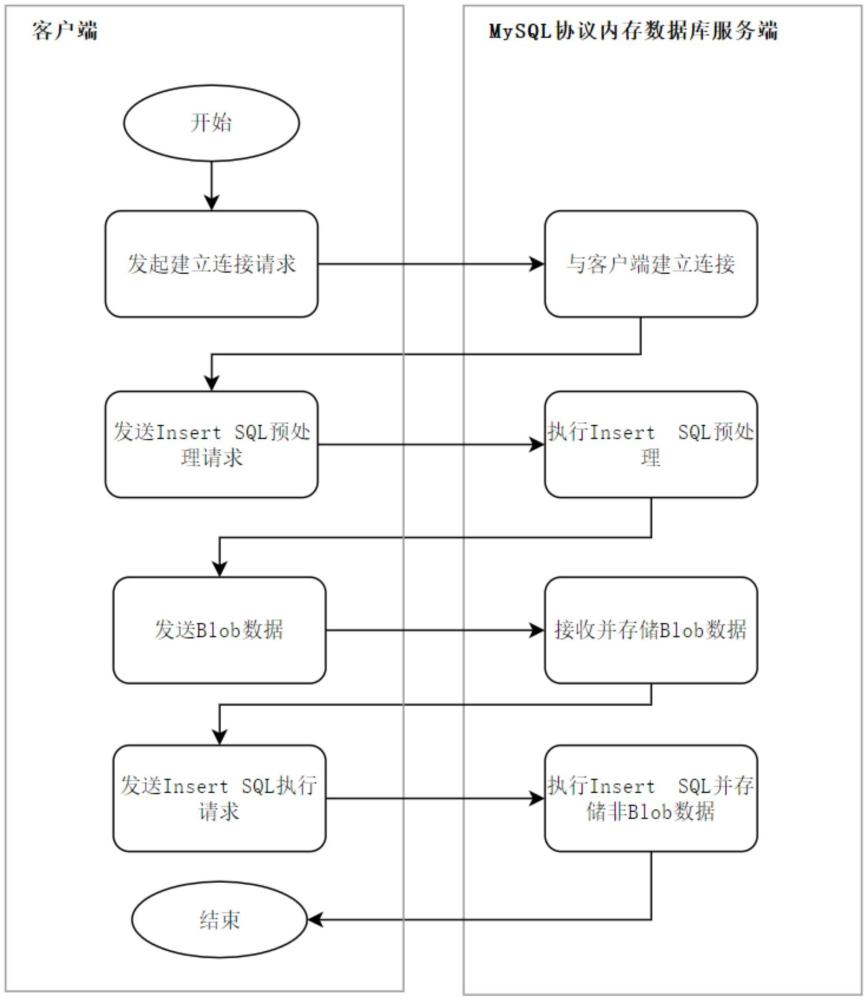
3、步驟a:客戶端與mysql協議內存數據庫的服務端建立連接,服務端為每個連接生成一個唯一的connection_id。
4、步驟b:客戶端通過發送com_stmt_prepare報文,將insert?sql預處理請求發送到服務端,insert?sql預處理請求包含blob類型的字段列。服務端接收com_stmt_prepare報文后,對insert?sql進行預處理,預處理成功后返回com_stmt_prepare_ok報文,報文包含statement_id以及insert?sql中的所有參數信息。
5、步驟c:客戶端發送com_stmt_send_long_data報文到服務端,報文中包含blob數據。服務端接收com_stmt_send_long_data報文后,根據服務端算法,將blob數據存儲至內存或文件系統。
6、步驟d:客戶端通過發送com_stmt_execute報文,將insert?sql執行請求到服務端,insert?sql執行請求包含非blob類型的所有參數數據。服務端接收com_stmt_execute報文后,將參數數據存儲至內存,并綁定步驟c保存的blob數據,存儲成功后服務端返回com_stmt_execute_ok報文。
7、優選的,所述步驟b中服務端接收報文后,對insert?sql進行預處理,預處理成功后返回com_stmt_prepare_ok報文具體為:
8、步驟b1:服務端接收com_stmt_prepare報文,報文中包含了需要預處理的insertsql預處理請求。
9、步驟b2:解析報文中的insert?sql文本字符串,將其轉換為sql字符串數據。
10、步驟b3:通過解析com_stmt_prepare報文的insert?sql預處理請求創建preparecontext對象,該對象表示本次預處理請求的上下文,存儲了connection_id、preparestatment對象在內的信息,其中connection_id用于標識客戶端與服務端之間的每個獨立連接,preparestatment對象用于存儲本次insert寫入的基本信息。
11、步驟b4:生成statement_id,所述statement_id用于唯一標識每一次insert寫入,創建的preparecontext對象和statement_id為一對一的映射關系。
12、步驟b5:根據步驟b2解析得到的sql字符串數據,判斷該insert?sql是否已經預處理,已經預處理表示客戶端已傳輸過相同的insert?sql并已生成preparedstatment對象,若insert?sql已經預處理,則執行步驟b6,否則執行步驟b7。
13、步驟b6:根據sql字符串數據從緩存中讀取本次insert寫入的基本信息,得到緩存的preparedstatment對象,跳轉至步驟b9。
14、步驟b7:解析insert?sql中的基本信息,并創建preparedstatment對象。
15、步驟b8:將preparedstatment對象緩存至內存中,其緩存的標識符為sql文本字符串。
16、步驟b9:將preparedstatment對象存儲至preparecontext對象。
17、步驟b10:返回com_stmt_prepare_ok報文,報文中包含步驟b4生成的statement_id以及insert?sql中的所有參數信息,所述參數信息包括參數類型以及參數序號。
18、優選的,所述步驟b3中本次insert寫入的基本信息具體包括:insert操作將數據寫入的目標表名、涉及的列字段、每個字段對應的值以及其中哪些數據通過參數化方式傳入。
19、優選的,所述步驟c中服務端接收com_stmt_send_long_data報文后,根據服務端算法,將blob數據存儲至內存或文件系統具體為:
20、步驟c1:服務端接收com_stmt_send_long_data報文。
21、步驟c2:解析報文中的statement_id。
22、步驟c3:解析報文中的param_id,param_id用于標識參數的序號。
23、步驟c4:創建blob對象,并從報文中讀取二進制數據,將二進制數據存儲到blob對象。
24、步驟c5:從連接中取出connection_id,再根據connection_id、statement_id和param_id判斷是否為新的參數,若connection_id、statement_id和statement_id均已存在,則表示報文傳輸的參數為已有的參數,跳轉至步驟c6。否則跳轉至步驟c8。
25、步驟c6:根據connection_id、statement_id和param_id從內存中讀取blob對象索引,blob對象索引用于存儲blob對象存儲的位置,包含3個屬性:blob對象是否存儲在內存、blob對象在內存中的id、blob對象在文件中的路徑。
26、步驟c7:根據blob對象索引判斷blob對象存儲位置,若blob對象存儲在文件,則將二進制數據追加到文件存儲。如果blob對象存儲在內存,則將二進制數據追加到內存存儲。并跳轉至步驟c12。
27、步驟c8:判斷blob內存存儲區域是否空余,如果blob內存存儲區域空余,跳轉至步驟c9。否則跳轉至步驟c10。
28、步驟c9:存儲blob對象到內存并跳轉至步驟c11。
29、步驟c10:存儲blob對象到文件存儲。
30、步驟c11:存儲blob對象索引到內存,索引中存儲了blob對象存儲的位置,表示對象存儲在內存還是存儲在文件。
31、步驟c12:返回com_stmt_send_long_data_ok報文。
32、步驟c13:若客戶端是否繼續傳輸com_stmt_send_long_data報文,跳轉至步驟c1,繼續接收并存儲新的報文。否則流程結束。
33、優選的,所述步驟d中服務端接收com_stmt_execute報文后,將參數數據存儲至內存,并綁定步驟c保存的blob數據,存儲成功后服務端返回ok報文具體為:
34、步驟d1:接收com_stmt_execute報文。
35、步驟d2:解析報文得到statement_id。
36、步驟d3:從報文中解析null_bitmap,null_bitmap用于表示參數數據中的null數據。
37、步驟d4:解析報文中非null且非blob的參數數據。
38、步驟d5:根據statement_id獲取preparedstatment對象。
39、步驟d6:根據preparedstatment對象獲取表名。
40、步驟d7:根據表名構造存儲對象。
41、步驟d8:根據步驟d3中的null_bitmap設置所有為null的參數數據,將其存儲至存儲對象。
42、步驟d9:根據步驟d4中所有非null且非blob的參數數據,將其存儲至存儲對象。
43、步驟d10:設置存儲對象中的blob屬性,將步驟c中存儲的所有blob對象索引作為存儲對象中的blob屬性值。
44、步驟d11:將存儲對象保存至內存。
45、步驟d12:返回com_stmt_execute_ok報文。
46、另一方面,本發明提供一種基于mysql協議內存數據庫的blob數據存儲系統,包括服務端與客戶端,所述系統實現如本發明任一實施例所述的基于mysql協議內存數據庫的blob數據存儲方法。
47、再一方面,本發明還提供一種電子設備,應用于客戶端,所述電子設備包括:建立連接模塊、sql預處理請求模塊、長數據傳輸模塊以及sql執行請求模塊。
48、建立連接模塊,用于與服務端建立連接。
49、sql預處理請求模塊,用于發送com_stmt_prepare報文,將insert?sql預處理請求發送到服務端,并接收服務端返回的com_stmt_prepare_ok報文。
50、長數據傳輸模塊,用于發送com_stmt_send_long_data報文到服務端,并接收服務端返回的com_stmt_send_long_data_ok報文。
51、sql執行請求模塊,用于發送com_stmt_execute報文,將insert?sql執行請求到服務端,并接收服務端返回的com_stmt_execute_ok報文。
52、再一方面,本發明還提供一種電子設備,應用于服務端,所述電子設備包括:連接管理模塊、sql預處理模塊、blob數據存儲模塊以及sql執行處理模塊。
53、連接管理模塊,用于與客戶端建立連接,并為每個連接生成一個唯一的connection_id。
54、sql預處理模塊,用于接收com_stmt_prepare報文,并對insert?sql進行預處理,預處理成功后返回com_stmt_prepare_ok報文。
55、blob數據存儲模塊,用于接收com_stmt_send_long_data報文,根據服務端算法,將blob數據存儲至內存或文件系統,并返回com_stmt_send_long_data_ok報文。
56、sql執行處理模塊,用于接收com_stmt_execute報文,并將參數數據存儲至內存,綁定保存的blob數據,存儲成功后服務端返回com_stmt_execute_ok報文。
57、與現有技術相比,本發明具有以下技術效果:
58、1、本發明所述方案解決了mysql中內存存儲引擎不能存儲blob數據的問題,通過com_stmt_send_long_data報文分步上傳,能夠靈活地將blob數據存儲到內存或磁盤中,從而打破了mysql內存引擎對大數據類型的限制,允許mysql內存數據庫處理和存儲blob類型的數據。
59、2、redis和h2?database等內存數據庫在處理blob類型的大對象時容易因為內存不足而發生溢出。本發明通過將blob數據獨立處理并存儲到磁盤或者內存中(基于數據的大小與內存策略),避免了大對象直接占用大量內存,從而有效地防止內存溢出問題。同時blob數據可以按需分配存儲,避免了全量存儲策略帶來的內存壓力。
- 還沒有人留言評論。精彩留言會獲得點贊!