一種基于雙目深度估計的三維道路場景生成方法
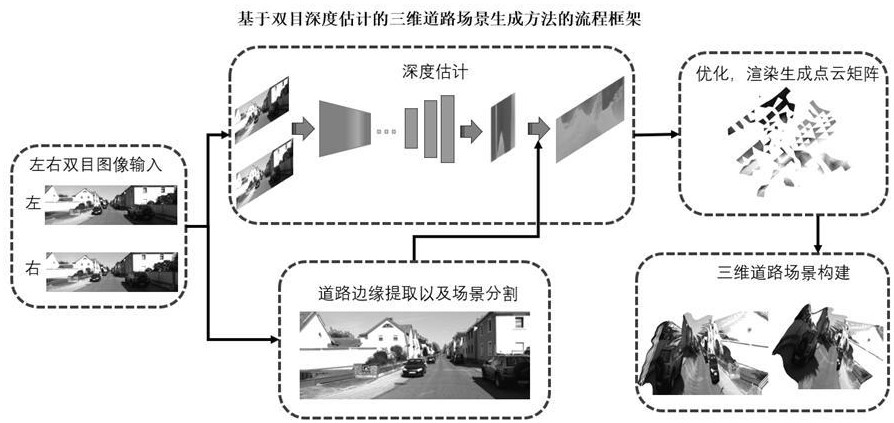
本發明涉及汽車自動駕駛系統顯示技術以及道路場景重建領域,特別涉及一種基于雙目深度估計的三維道路場景生成方法。
背景技術:
1、在自動駕駛和智能交通領域中,道路環境的三維重建是一個至關重要的研究方向。當前,許多技術方案在該領域中得到了應用,但都存在一定的局限性。例如,專利cn110796728b利用激光雷達獲取三維點云數據,通過貪婪投影算法重建目標的外形尺寸、結構、位置和姿態。這類傳統的三維重建方法依賴于高精度的激光雷達,盡管其準確性較高,但設備昂貴,難以在大規模應用場景中實現經濟性。
2、相對而言,攝像頭作為一種經濟高效的傳感器,在某些場景下逐漸替代了激光雷達。例如,專利cn116091695a使用分層強化學習技術來進行三維重建,盡管該方法能夠實現較高的精度,但其主要針對單一物體,而非復雜的道路場景,因此適用性受到限制。另一項專利cn116091703a則采用基于多視圖立體匹配的實時三維重建技術,通過單目攝像頭逐張拍攝的方式構建三維模型,雖然這種方案能夠在一定程度上提高重建精度,但拍攝效率較低,且在動態環境下的精度表現不理想。
3、相比之下,雙目攝像頭以其左右視角的視差信息實現深度估計,是一種成本相對低廉且硬件要求較低的傳感器方案。然而,目前的雙目深度估計算法在面對復雜道路場景時,仍存在諸如精度不足和計算復雜度較高的挑戰。為此,亟需一種新的技術方案,既能有效降低硬件成本,又能提升復雜場景下的重建精度和效率,以克服現有技術的局限性。
技術實現思路
1、本發明提出一種基于雙目深度估計的三維道路場景生成方法,通過雙目攝像頭獲取道路環境的左右視角圖像,結合深度估計算法生成每個像素點的深度信息,并通過邊緣約束算法凸顯道路場景的關鍵特征,最后利用open3d實現高效的三維道路場景生成。本發明能夠顯著提升復雜道路場景的重建精度與效率,有助于自動駕駛和智能交通系統的應用,特別是在低成本硬件環境下實現實時感知。
2、本發明公開了一種基于雙目深度估計的三維道路場景生成方法,基于左右目深度攝像頭傳感器、雙目深度估計神經網絡模型、邊緣約束道路分割模塊和點云數據優化模塊,所述基于雙目深度估計的三維道路場景生成方法包括以下步驟:
3、步驟1、通過左右目深度相機傳感器動態捕捉道路場景畫面;
4、步驟2、將左右目深度畫面通過雙目深度估計神經網絡模型進行計算;
5、步驟3、根據預測的深度圖和相機內參矩陣生成點云數據。
6、更近一步地,在步驟1中,還包括以下步驟:
7、步驟1.1、根據傳感器的內參矩陣配置左右目深度攝像頭,使其同步工作,并設置捕捉幀率和分辨率,以滿足實時處理需求;
8、步驟1.2、通過安裝在車輛上的左右目視覺傳感器采集道路場景左右圖像,并進行預處理;包括:
9、步驟1.2.1、通過攝像頭標定內參矩陣和畸變系數,對圖像進行幾何校正:
10、,?;
11、,?;
12、其中,(x,?y,?z)為像素坐標,(x′,?y′)為標準坐標,(,)為矯正坐標,,?,為畸變系數,;
13、步驟1.2.2、從矯正后的圖像中提取道路感興趣區域,使用邊緣檢測算法結合設定的區域掩模,保留道路表面和重要邊緣特征。
14、更近一步地,在步驟2中,還包括以下步驟:
15、步驟2.1、將預處理后的左右目圖像輸入神經網絡,作為模型的基礎數據;
16、步驟2.2、通過編碼器提取左右目圖像的多層特征并融合;
17、步驟2.3、通過視差估計模塊計算初始視差圖;
18、;
19、其中,為像素坐標上的視差值,用于表示左右目圖像在該像素位置的位移差異,?為像素坐標,和??分別為左右圖像中對應點的橫坐標;
20、步驟2.4、通過空間注意力機制用于提高場景關鍵區域的顯著性;
21、步驟2.5、通過深度邊緣約束模塊增強深度圖中的邊界信息;
22、;
23、其中,表示經過深度邊緣約束模塊優化之后的深度值,為原始深度值,為邊緣檢測值,λ為權重參數;
24、步驟2.6、將視差估計模塊、空間注意力模塊、深度邊緣約束模塊輸出的深度圖進行加權融合;
25、將視差估計模塊、空間注意力模塊、深度邊緣約束模塊輸出的深度圖進行加權融合:
26、;
27、其中,為經過三個模塊加權處理之后得到的最終的深度圖,為視差估計深度圖,為空間注意力增強深度圖,為深度邊緣增強深度圖,,,為融合權重。
28、更近一步地,在步驟2.1中,還包括以下步驟:
29、步驟2.2.1、多級特征提取,包括:
30、低層次特征提取:通過初始的卷積層對左右目圖像進行邊緣和紋理特征提取:
31、;
32、其中,為輸入圖像像素值,為卷積核的寬度,為卷積核的高度,為低層卷積核,為低層次特征輸出;
33、中層次特征提取:使用帶有池化層的卷積模塊提取場景中的幾何和紋理信息,減少冗余數據:
34、;
35、其中,池化窗口的在水平方向上的像素坐標范圍,?是池化窗口在豎直方向上的像素坐標范圍,是池化窗口內的像素坐標索引,為中層次特征輸出;
36、高層次特征提取:使用堆疊的卷積層提取場景語義特征:
37、;
38、其中:
39、?為高層次特征輸出;
40、為上一層的特征圖輸出,在通道上的特征值,是局部窗口內的特征位置;
41、為卷積核,大小為?,輸入通道為?,輸出通道為;
42、為輸出通道c的偏置項;為激活函數,用于引入非線性;
43、通過堆疊多層卷積層,逐步擴大感受野并捕獲語義特征,公式迭代進行,直到最后得到;
44、通過跳躍連接將低、中、高層次特征結合,形成分層特征:
45、;
46、,,分別表示低、中、高層次特征在融合過程中所占的權重。
47、更近一步地,在步驟2.4中,還包括以下步驟:
48、步驟2.4.1、多尺度特征生成;
49、輸入特征圖經不同的卷積核提取不同尺度的特征:
50、;
51、其中,表示核大小為的卷積操作,?表示通過卷積核大小為的的卷積操作后,在像素坐標?上生成的第?個尺度特征圖;
52、步驟2.4.2、將不同尺度的特征圖按權重疊加:
53、;
54、其中,為尺度數量,確保權重歸一化,?表示在像素坐標上,融合了所有尺度特征后的最終特征值;
55、步驟2.4.3、將融合后的特征圖疊加到輸入特征圖上,得到最終增強的特征:
56、;
57、表示在像素坐標處綜合了原始分層特征?和多尺度融合特征增強后的特征圖值。
58、更近一步地,在步驟3中,還包括以下步驟:
59、步驟3.1、將深度圖與相機內參矩陣結合,生成初始點云數據:
60、;
61、其中,為像素坐標;()為相機的光心位置;,分別為相機水平方向和垂直方向的焦距;為深度值;x,y分別表示三維點在相機坐標系的水平方向,垂直方向上的位置,z為相機光軸方向的深度;
62、步驟3.2、對初始點云進行降采樣和去噪處理,以提升數據質量;包括以下步驟:
63、步驟3.2.1、通過體素網格法將初始點云劃分為大小為?s的立方體網格,并用每個網格內點的質心表示該網格的點:
64、;
65、其中,n為網格內點的數量,?為網格的質心坐標,?為每個網格內點的坐標;
66、步驟3.2.2、計算每個點與其個最近鄰的平均距離,剔除不滿足以下條件的離群點:
67、;
68、其中,為平均距離,為標準差,為用戶設定閾值,為每個點與其個最近鄰的平均距離;
69、步驟3.3、將優化后的點云數據輸入open3d庫,生成并渲染三維道路場景,為點云數據增加顏色信息,將深度值映射為顏色:
70、;
71、其中,為點的深度值,和分別為最大和最小深度值。本發明達到的有益效果是:
72、本發明通過雙目深度估計結合邊緣約束算法,提高了復雜道路場景中三維重建的精度;
73、本發明利用open3d的高效點云處理和渲染能力,實現了實時性和可視化;
74、本發明采用低成本的雙目攝像頭替代激光雷達,顯著降低了硬件成本,為大規模應用提供了可行性。
- 還沒有人留言評論。精彩留言會獲得點贊!