一種推薦系統(tǒng)的大語言模型對齊微調(diào)方法、系統(tǒng)及設(shè)備
本技術(shù)涉及信息推薦,尤其是涉及一種推薦系統(tǒng)的大語言模型對齊微調(diào)方法、系統(tǒng)及設(shè)備。
背景技術(shù):
1、隨著互聯(lián)網(wǎng)技術(shù)的發(fā)展,電子商務(wù)、社交媒體等各大平臺的迅速興起,由于信息呈現(xiàn)爆炸式增長,用戶不可避免面臨信息過載的問題。對于這種現(xiàn)象,推薦系統(tǒng)作為一種能夠快速挖掘用戶興趣的技術(shù),已經(jīng)成為各大網(wǎng)絡(luò)平臺的重要組成部分。推薦系統(tǒng)通過挖掘用戶的歷史行為數(shù)據(jù)和物品的特征信息,利用算法模型為用戶推薦個性化的內(nèi)容,從而提升用戶體驗和平臺效率。
2、由于多數(shù)推薦系統(tǒng)的公開訓(xùn)練數(shù)據(jù)集中數(shù)據(jù)較為稀疏,這將導(dǎo)致推薦系統(tǒng)未能有效利用其他外部知識。推薦系統(tǒng)如若能夠獲得關(guān)于推薦目標全面的知識,往往具有更好的表現(xiàn)。大語言模型作為一種新興技術(shù),在推薦系統(tǒng)中存在著廣泛的應(yīng)用場景。通過自監(jiān)督學(xué)習(xí),大語言模型從海量數(shù)據(jù)中提取知識,獲得強大的外部知識覆蓋和知識表達能力,這對推薦目標的背景知識補充提供了一種方法。然而,要從大語言模型中獲取與推薦任務(wù)高度相關(guān)且有價值的知識并非一件簡單的事情,由于其大語言模型的訓(xùn)練數(shù)據(jù)集覆蓋范圍廣泛且形式多樣,這意味著模型生成的結(jié)果中可能會引入噪聲,從而對推薦系統(tǒng)的性能造成不利影響。
技術(shù)實現(xiàn)思路
1、本技術(shù)旨在提出一種推薦系統(tǒng)的大語言模型對齊微調(diào)方法、系統(tǒng)及設(shè)備,能夠充分利用大語言模型自帶的廣泛外部知識,從而提高推薦效果。
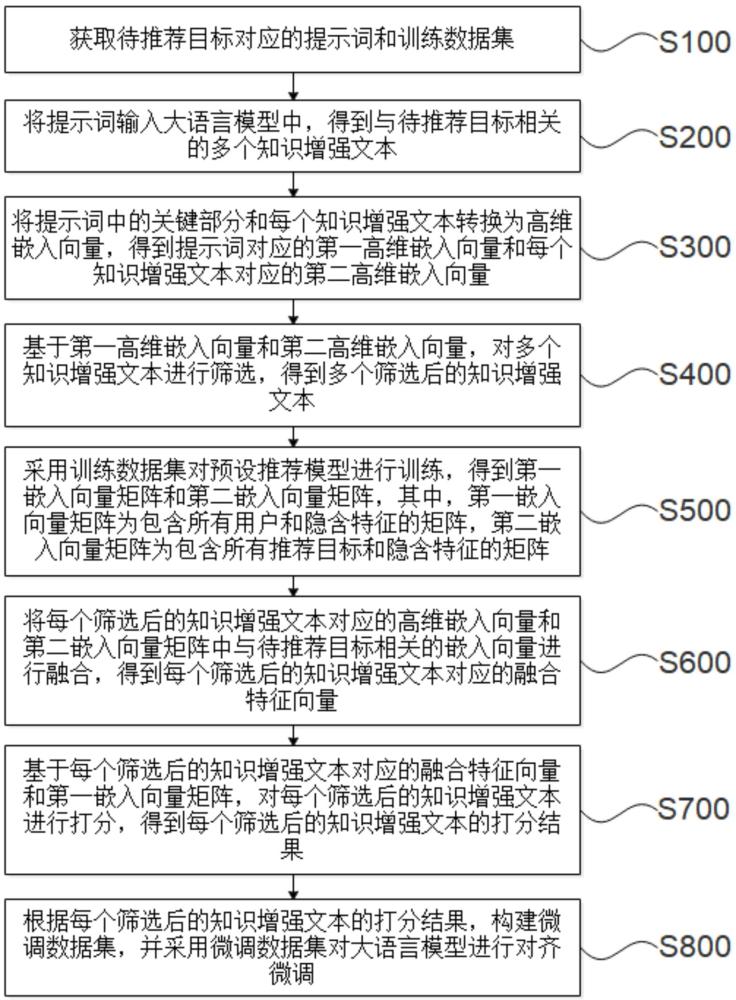
2、第一方面,本技術(shù)實施例提供了一種推薦系統(tǒng)的大語言模型對齊微調(diào)方法,所述方法包括:
3、獲取待推薦目標對應(yīng)的提示詞和訓(xùn)練數(shù)據(jù)集;
4、將所述提示詞輸入大語言模型中,得到與所述待推薦目標相關(guān)的多個知識增強文本;
5、將所述提示詞中的關(guān)鍵部分和每個所述知識增強文本轉(zhuǎn)換為高維嵌入向量,得到提示詞對應(yīng)的第一高維嵌入向量和每個所述知識增強文本對應(yīng)的第二高維嵌入向量,所述關(guān)鍵部分用于表征與所述待推薦目標相關(guān)的信息;
6、基于所述第一高維嵌入向量和所述第二高維嵌入向量,對所述多個知識增強文本進行篩選,得到多個篩選后的知識增強文本;
7、采用所述訓(xùn)練數(shù)據(jù)集對預(yù)設(shè)推薦模型進行訓(xùn)練,得到第一嵌入向量矩陣和第二嵌入向量矩陣,其中,所述第一嵌入向量矩陣為包含所有用戶和隱含特征的矩陣,所述第二嵌入向量矩陣為包含所有推薦目標和隱含特征的矩陣;
8、將每個所述篩選后的知識增強文本對應(yīng)的高維嵌入向量和所述第二嵌入向量矩陣中與所述待推薦目標相關(guān)的嵌入向量進行融合,得到每個所述篩選后的知識增強文本對應(yīng)的融合特征向量;
9、基于每個所述篩選后的知識增強文本對應(yīng)的融合特征向量和所述第一嵌入向量矩陣,對每個所述篩選后的知識增強文本進行打分,得到每個所述篩選后的知識增強文本的打分結(jié)果;
10、根據(jù)每個所述篩選后的知識增強文本的打分結(jié)果,構(gòu)建微調(diào)數(shù)據(jù)集,并采用所述微調(diào)數(shù)據(jù)集對所述大語言模型進行對齊微調(diào)。
11、與現(xiàn)有技術(shù)相比,本技術(shù)第一方面具有以下有益效果:
12、本方法通過獲取待推薦目標對應(yīng)的提示詞和訓(xùn)練數(shù)據(jù)集;將提示詞輸入大語言模型中,得到與待推薦目標相關(guān)的多個知識增強文本,通過提示詞優(yōu)化了響應(yīng)文本的知識表達能力,有效緩解了數(shù)據(jù)稀疏性問題。通過將提示詞中的關(guān)鍵部分和每個知識增強文本轉(zhuǎn)換為高維嵌入向量,得到提示詞對應(yīng)的第一高維嵌入向量和每個知識增強文本對應(yīng)的第二高維嵌入向量,基于第一高維嵌入向量和第二高維嵌入向量,對多個知識增強文本進行篩選,得到多個篩選后的知識增強文本,能夠去除低質(zhì)量樣本,保留高質(zhì)量樣本,并且讓知識增強樣本在后續(xù)的選擇中分布差異增大,解決后期微調(diào)效率過低的問題。再采用訓(xùn)練數(shù)據(jù)集對預(yù)設(shè)推薦模型進行訓(xùn)練,得到第一嵌入向量矩陣和第二嵌入向量矩陣,將每個篩選后的知識增強文本對應(yīng)的高維嵌入向量和第二嵌入向量矩陣中與待推薦目標相關(guān)的嵌入向量進行融合,得到每個篩選后的知識增強文本對應(yīng)的融合特征向量,基于每個篩選后的知識增強文本對應(yīng)的融合特征向量和第一嵌入向量矩陣,對每個篩選后的知識增強文本進行打分,得到每個篩選后的知識增強文本的打分結(jié)果,基于預(yù)設(shè)推薦模型對增強知識文本進行打分,生成監(jiān)督信號,為后期構(gòu)建微調(diào)數(shù)據(jù)集和對大語言模型進行對齊微調(diào)奠定良好的數(shù)據(jù)基礎(chǔ)。最后根據(jù)每個篩選后的知識增強文本的打分結(jié)果,構(gòu)建微調(diào)數(shù)據(jù)集,并采用微調(diào)數(shù)據(jù)集對大語言模型進行對齊微調(diào),通過高質(zhì)量的知識增強文本構(gòu)建微調(diào)數(shù)據(jù)集,能夠充分利用大語言模型自帶的廣泛外部知識對大語言模型進行對齊微調(diào),通過對齊微調(diào)后的大語言模型對待推薦目標進行推薦,能夠提高推薦效果。
13、在一些實施方式中,所述基于所述第一高維嵌入向量和所述第二高維嵌入向量,對所述多個知識增強文本進行篩選,得到多個篩選后的知識增強文本,包括:
14、計算所述第一高維嵌入向量和所述第二高維嵌入向量之間的相似度,將所述相似度小于預(yù)設(shè)值的知識增強文本從所述多個知識增強文本中去除,得到剩余知識增強文本;
15、對所述剩余知識增強文本對應(yīng)的第二高維嵌入向量進行聚類,得到聚類結(jié)果;
16、根據(jù)所述聚類結(jié)果對所述剩余知識增強文本進行篩選,得到多個篩選后的知識增強文本。
17、在一些實施方式中,所述采用所述訓(xùn)練數(shù)據(jù)集對預(yù)設(shè)推薦模型進行訓(xùn)練,得到第一嵌入向量矩陣和第二嵌入向量矩陣,包括:
18、將貝葉斯個性化排序算法構(gòu)建為預(yù)設(shè)推薦模型;
19、采用所述訓(xùn)練數(shù)據(jù)集對所述預(yù)設(shè)推薦模型進行訓(xùn)練,得到第一嵌入向量矩陣和第二嵌入向量矩陣。
20、在一些實施方式中,所述基于每個所述篩選后的知識增強文本對應(yīng)的融合特征向量和所述第一嵌入向量矩陣,對每個所述篩選后的知識增強文本進行打分,得到每個所述篩選后的知識增強文本的打分結(jié)果,包括:
21、將每個所述篩選后的知識增強文本對應(yīng)的融合特征向量輸入多層感知機,得到每個所述篩選后的知識增強文本對應(yīng)的輸出結(jié)果;
22、將所述輸出結(jié)果和所述第一嵌入向量矩陣進行點乘,得到每個所述篩選后的知識增強文本對應(yīng)的點乘結(jié)果;
23、根據(jù)所述點乘結(jié)果,對每個所述篩選后的知識增強文本進行打分,得到每個所述篩選后的知識增強文本的打分結(jié)果。
24、在一些實施方式中,所述根據(jù)每個所述篩選后的知識增強文本的打分結(jié)果,構(gòu)建微調(diào)數(shù)據(jù)集,包括:
25、對每個所述篩選后的知識增強文本的打分結(jié)果進行排序,得到排序后的分數(shù);
26、根據(jù)所述排序后的分數(shù),將所述篩選后的知識增強文本進行兩兩組合,以構(gòu)建微調(diào)數(shù)據(jù)集。
27、在一些實施方式中,在采用所述微調(diào)數(shù)據(jù)集對所述大語言模型進行對齊微調(diào)之前,所述方法包括:
28、將所述微調(diào)數(shù)據(jù)集中的每個篩選后的知識增強文本的分數(shù)歸一化為概率分布;
29、根據(jù)所述概率分布,計算信息熵;
30、根據(jù)所述信息熵,計算加權(quán)因子;
31、根據(jù)所述加權(quán)因子,構(gòu)建對所述大語言模型進行對齊微調(diào)時的目標優(yōu)化函數(shù)。
32、在一些實施方式中,所述根據(jù)所述加權(quán)因子,構(gòu)建對所述大語言模型進行對齊微調(diào)時的目標優(yōu)化函數(shù),包括:
33、;
34、其中,表示目標優(yōu)化函數(shù),表示當(dāng)前策略,表示參考策略,表示微調(diào)數(shù)據(jù)集,表示提示詞,表示第個知識增強樣本,表示第個知識增強樣本,表示加權(quán)因子,表示羅吉斯蒂克函數(shù),表示溫度系數(shù)。
35、第二方面,本技術(shù)實施例還提供了一種推薦系統(tǒng)的大語言模型對齊微調(diào)系統(tǒng),所述系統(tǒng)包括:
36、數(shù)據(jù)獲取單元,用于獲取待推薦目標對應(yīng)的提示詞和訓(xùn)練數(shù)據(jù)集;
37、知識增強文本獲取單元,用于將所述提示詞輸入大語言模型中,得到與所述待推薦目標相關(guān)的多個知識增強文本;
38、高維嵌入向量轉(zhuǎn)換單元,用于將所述提示詞中的關(guān)鍵部分和每個所述知識增強文本轉(zhuǎn)換為高維嵌入向量,得到提示詞對應(yīng)的第一高維嵌入向量和每個所述知識增強文本對應(yīng)的第二高維嵌入向量,所述關(guān)鍵部分用于表征與所述待推薦目標相關(guān)的信息;
39、知識增強文本篩選單元,用于基于所述第一高維嵌入向量和所述第二高維嵌入向量,對所述多個知識增強文本進行篩選,得到多個篩選后的知識增強文本;
40、嵌入向量矩陣獲取單元,用于采用所述訓(xùn)練數(shù)據(jù)集對預(yù)設(shè)推薦模型進行訓(xùn)練,得到第一嵌入向量矩陣和第二嵌入向量矩陣,其中,所述第一嵌入向量矩陣為包含所有用戶和隱含特征的矩陣,所述第二嵌入向量矩陣為包含所有推薦目標和隱含特征的矩陣;
41、嵌入向量融合單元,用于將每個所述篩選后的知識增強文本對應(yīng)的高維嵌入向量和所述第二嵌入向量矩陣中與所述待推薦目標相關(guān)的嵌入向量進行融合,得到每個所述篩選后的知識增強文本對應(yīng)的融合特征向量;
42、知識增強文本打分單元,用于基于每個所述篩選后的知識增強文本對應(yīng)的融合特征向量和所述第一嵌入向量矩陣,對每個所述篩選后的知識增強文本進行打分,得到每個所述篩選后的知識增強文本的打分結(jié)果;
43、大語言模型對齊微調(diào)單元,用于根據(jù)每個所述篩選后的知識增強文本的打分結(jié)果,構(gòu)建微調(diào)數(shù)據(jù)集,并采用所述微調(diào)數(shù)據(jù)集對所述大語言模型進行對齊微調(diào)。
44、第三方面,本技術(shù)實施例還提供了一種電子設(shè)備,包括至少一個控制處理器和用于與所述至少一個控制處理器通信連接的存儲器;所述存儲器存儲有可被所述至少一個控制處理器執(zhí)行的指令,所述指令被所述至少一個控制處理器執(zhí)行,以使所述至少一個控制處理器能夠執(zhí)行如上所述的一種推薦系統(tǒng)的大語言模型對齊微調(diào)方法。
45、第四方面,本技術(shù)實施例還提供了一種計算機可讀存儲介質(zhì),所述計算機可讀存儲介質(zhì)存儲有計算機可執(zhí)行指令,所述計算機可執(zhí)行指令用于使計算機執(zhí)行如上所述的一種推薦系統(tǒng)的大語言模型對齊微調(diào)方法。
46、可以理解的是,上述第二方面至第四方面與相關(guān)技術(shù)相比存在的有益效果與上述第一方面與相關(guān)技術(shù)相比存在的有益效果相同,可以參見上述第一方面中的相關(guān)描述,在此不再贅述。
- 還沒有人留言評論。精彩留言會獲得點贊!