一種點擊率預估中基于元學習的雙層優化方法
本發明屬于大數據處理,具體是涉及一種點擊率預估中基于元學習的雙層優化方法。
背景技術:
1、點擊率預估是信息檢索中的重要任務之一,它估計用戶在看到廣告或商品后點擊的概率,這個概率值可用于排序和推薦系統,以提升用戶體驗和業務指標。目前,基于經驗風險最小化的點擊率預估模型研究取得了顯著成果,例如?deepfm、dcn和din。這些研究通常假設訓練和測試數據是獨立同分布的,并通過最小化訓練數據中的預測誤差來優化點擊率預估模型。
2、然而在現實世界中,這個假設并不成立。因為未來時間步的數據與歷史時間步的數據之間存在差異。這種差異可能是因為用戶興趣隨時間推移而發生變化,從而導致交互數據的分布也隨之改變。
3、未來數據的分布與歷史數據分布存在差異的原因有很多。首先,歷史數據中存在一些強相關性,但這種強相關性無法泛化到未來。其次,流媒體數據的屬性通常會隨時間推移而變化,導致用戶交互模式在歷史和未來環境之間動態變化,例如商品受歡迎程度的分布。再者,個人興趣和背景信息的潛在數據分布會隨著時間的推移而逐漸變化,例如用戶隨時間反復查看同一商品時,點擊興趣可能會下降。這些因素導致歷史訓練數據和現實世界測試數據之間隨著時間的推移而出現差異,這種現象被稱為時序分布漂移。
4、時序分布漂移會對點擊率預估模型的性能產生負面影響,隨著時間步的增加,點擊率預估模型的性能會下降。這表明在歷史數據上訓練良好并基于經驗風險最小化的模型在泛化到未來時間步的真實世界測試數據時,會受到時序分布漂移的限制。進一步來說,這些基于經驗風險最小化且使用歷史數據進行訓練的模型,在受到時序分布漂移的影響時,會導致其在未來時間步上的性能下降。
技術實現思路
1、本發明旨在至少在一定程度上解決相關技術中存在的技術問題之一。
2、本發明的目的在于提供一種點擊率預估中基于元學習的雙層優化方法,適用于大多數點擊率預估模型的優化,幫助點擊率預估模型應對時序分布漂移。
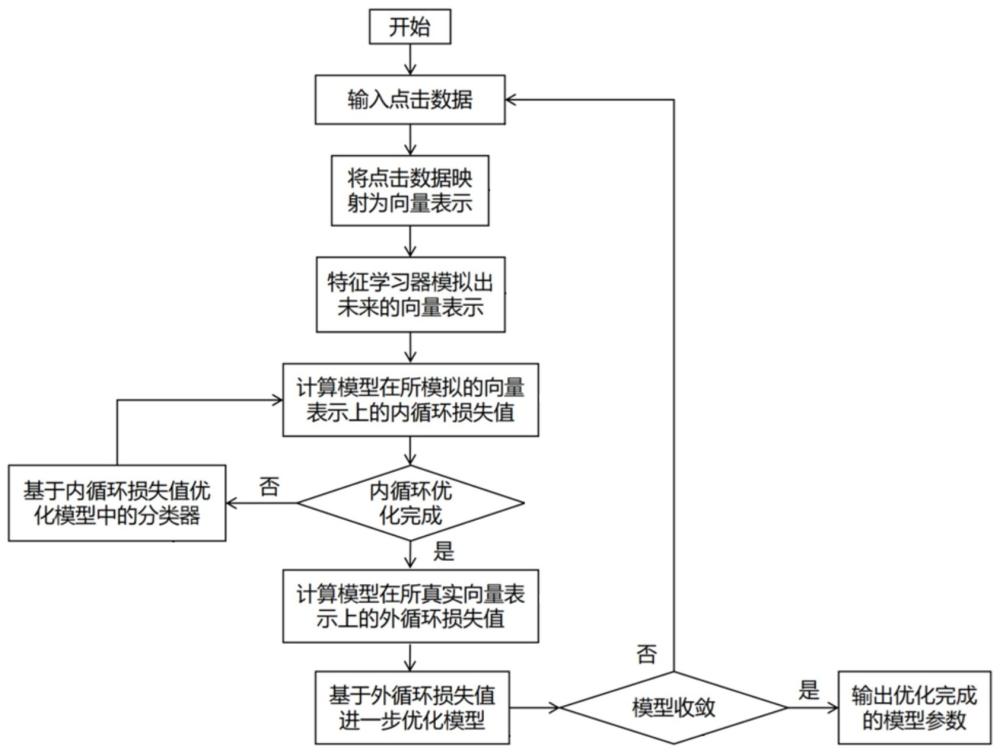
3、為了達到上述的目的,本發明一方面提供一種點擊率預估中基于元學習的雙層優化方法,包括:
4、s1、對于一個點擊率預估模型,從第1~t個時間步中各選取一批數據,并利用嵌入模型計算每批數據的向量表示;
5、s2、利用特征學習器來捕捉所述向量表示的演化趨勢,并根據所捕捉到的演化趨勢來預測第t個時間步的數據在下一個時間步的向量表示;
6、s3、根據所預測的下一個時間步的向量表示,計算所述點擊率預估模型在這些向量表示上的損失值,記為內循環損失值;
7、s4、基于獲得的內循環損失值,使用梯度下降方法優化點擊率預估模型中的分類器;
8、s5、根據步驟s4優化后的點擊率預估模型,計算其在下一個時間步的真實向量表示上的損失值,記為外循環損失值;
9、s6、基于獲得的外循環損失值,再次使用梯度下降方法優化點擊率預估模型中的分類器;
10、s7、重復步驟s1~s6,直至模型收斂,完成對所述點擊率預估模型的優化。
11、本發明進一步優選地技術方案為,步驟s1中所述點擊率預估模型由1個嵌入模型和1個分類器組成,其中,表示模型的輸入,和分別表示嵌入模型和分類器的參數;對于給定用戶與物品的交互特征,嵌入模型先將交互特征映射為向量表示,然后分類器將向量表示映射為用戶對該物品的點擊概率。
12、作為優選,步驟s1中嵌入模型將第t個時間步的數據映射為向量表示,具體計算式為:;
13、其中,表示嵌入模型的參數,表示第t個時間步的原始數據,表示第t個時間步的數據的向量表示,為映射函數。
14、作為優選,步驟s2中所述特征學習器為基于注意力機制構建的模型;特征學習器以歷史時刻的向量表示作為輸入,以下一時刻的向量表示作為輸出,該輸出即為特征學習器對未來向量表示的預測;
15、特征學習器根據所捕捉到的演化趨勢來預測第t個時間步的數據在下一個時間步的向量表示的計算式為:
16、;
17、;
18、;
19、式中,、和均為可學習的參數,表示查詢矩陣,用于從輸入序列中提取查詢信息,表示鍵矩陣,用于從輸入序列中提取鍵信息,表示值矩陣,用于從輸入序列中提取值信息;為超參數,表示注意力的頭數,取值范圍為;和均為線性層中的可學習的參數,表示該線性層的激活函數;表示第 i個特征表示與第 j個特征表示之間的注意力權重,表示第 i個特征表示與第 k個特征表示之間的注意力權重;、分別表示注意力權重與注意力機制計算的輸出結果;即為預測得到的下一時刻的向量表示。
20、作為優選,步驟s3中內循環損失值的計算式為:
21、;
22、式中,為超參數,表示損失函數的權重,取值為,表示正則化的權重;表示當輸入的數據為,且數據的向量表示為時,參數為的分類器的輸出結果;表示計算模型的輸出結果與標簽的二向交叉熵損失值;表示正則化,用于使分類器在上的預測輸出和在上的預測輸出接近;
23、為標量,的計算式為:
24、;
25、其中表示當輸入的數據為,且數據的向量表示為時,參數為的分類器的輸出結果;為超參數,取值范圍為1~5。作為優選,步驟s4中基于獲得的內循環損失值,使用梯度下降方法優化點擊率預估模型中的分類器時,分類器參數更新表示為:
26、;
27、其中,表示內循環損失值對分類器參數的梯度;為超參數,表示內循環學習率,取值范圍為0.0001~0.1;表示根據內循環損失值優化后的分類器的參數。
28、作為優選,步驟s5中外循環損失值的計算式為:
29、;
30、其中,表示當輸入的數據為,且數據的向量表示為時,參數為的分類器的輸出結果;表示計算分類器的輸出結果與標簽的二向交叉熵損失值。
31、作為優選,步驟s6中基于獲得的外循環損失值,使用梯度下降方法優化點擊率預估模型中的分類器時,分類器參數更新表示為:
32、;
33、其中,表示外循環損失值對點擊率預估模型中所有參數的梯度;為超參數,表示外循環學習率,取值范圍為0.0001~0.1;表示未經步驟s4更新的全部模型參數,表示使用外循環損失值更新后的全部模型參數。
34、本發明另一方面提供一種非暫態計算機可讀存儲介質,其上存儲有計算機指令,該計算機指令使計算機執行上述的點擊率預估中基于元學習的雙層優化方法。
35、本發明又一方面提供一種電子設備,包括:處理器、通信接口、存儲器和通信總線,其中,處理器,通信接口,存儲器通過通信總線完成相互間的通信,處理器調用存儲器中的邏輯指令,以執行上述的點擊率預估中基于元學習的雙層優化方法。
36、本發明再一方面提供一種計算機程序產品,所述計算機程序產品包括計算機程序,計算機程序存儲在非暫態計算機可讀存儲介質上,所述計算機程序被處理器執行時,計算機執行上述的點擊率預估中基于元學習的雙層優化方法。
37、有益效果:本發明通過預測未來時序分布漂移后的向量表示,并利用雙層優化機制,使模型能夠更好地適應數據分布的變化,提高點擊率預估模型應對時序分布漂移的能力,從而提高在未來時間步上的點擊率預估性能。
38、本發明的優化方法不僅關注模型在歷史數據上的表現,更注重模型在未來真實數據上的泛化能力,確保模型在實際應用中能夠取得良好的效果,提升模型泛化能力。也因此本發明的優化方法適用于大多數點擊率預估模型,例如deepfm、dcn和din等,具有良好的通用性。
- 還沒有人留言評論。精彩留言會獲得點贊!