一種大規模復雜無線通信系統的仿真方法和系統與流程
本發明涉及無線通信、高性能計算應用領域,尤其涉及的是一種大規模復雜無線通信系統的仿真方法和系統。
背景技術:
隨著社會發展,新的應用和需求不斷出現,如物聯網、公共安全、突發事件等方面的需求,隨之而來的是對無線通信技術提出更高的要求,主要體現在:更高的速率、更低的時延、更加可靠的網絡覆蓋、滿足熱點區域業務要求以及移動條件下仍能提供優質服務。
為了滿足這些要求,一系列技術被提出:更高的頻段、更大的帶寬、天線增強技術、大規模天線陣列以提高速率;采用中繼技術以保障小區邊緣的覆蓋和提升系統容量;針對移動場景,提出移動網絡場景,包括移動中繼(relay)、游牧節點;為了滿足物聯網發展要求,實施mtc(machinetypecommunication,機器類型通信)技術,提出了大規模機器通信(massivemachinecommunication,mmc)的研究方向;針對公共安全需求和增強覆蓋需求,實施終端直通技術(device2device,d2d);針對未來80%-90%的系統吞吐量來自室內和熱點場景,提出密集小區布網方案和256qam高階調制技術;為解決密集組網引起的小區間干擾和頻繁切換問題,提出宏微小區雙鏈接、垂直波束賦形、虛擬小區、無線回傳、mm(massivemimo,大規模多輸入多輸出)和筆形波束賦形等;為了節約能源,提出了小區快速開關和小區發現技術。
上述技術的引入,導致無線網絡有如下發展趨勢:網絡規模越來越大,且網絡規模根據業務變化而動態改變;網絡結構越來越復雜,主要體現在多制式多頻點共存和互操作、多種覆蓋模式共存,拓撲結構復雜,不規則網絡,且隨終端、機器、移動relay(中繼)、游牧節點的移動而動態變化;網絡 節點種類越來越多,由此產生多種無線鏈路共存和多種業務需求共存,網絡節點之間的協作越來越頻繁;多種物理層處理技術將被引入;更多天線相關技術的引入,必然需要對無線信道進行精確建模,如采用射線追蹤技術和3d信道、3d場景建模技術。
傳統的單核/單機仿真平臺已經無法完成對上述技術的仿真和評估,主要體現在無法提供足夠的內存支持大規模場景仿真,無法保存仿真過程中產生的大量信道等數據;無法提供高速的計算速率以支持對大量復雜的物理層處理、大規模天線陣列建模和大量高層邏輯處理;無法提供靈活的架構以支持多制式共存、多模覆蓋、多業務共存等的仿真;無法提供較好的可擴展結構以支持協議的演進,隨著協議的演進,對不同類型網絡節點的添加和刪除可能導致將仿真平臺推倒重來。單核目前用于在64天線超大規模天線陣列技術和射線追蹤仿真中,運行速度極慢,需要幾天才能完成一個仿真;在精確信道建模的射線追蹤技術仿真中內存達到100g,且運算速度非常慢,更不用提對后續5g技術的仿真。
仿真技術的滯后必將嚴重阻礙5g標準的研究和推進,因此,需要研究適用于大規模復雜無線通信系統性能指標的新的仿真方法和平臺。
技術實現要素:
本發明所要解決的技術問題是提供一種大規模復雜無線通信系統的仿真方法和系統,能夠解決大規模復雜無線通信系統仿真過程中面臨的內存壓力、計算壓力,并為仿真平臺提供靈活性、擴展性好的并行架構。
本發明提供了一種大規模復雜無線通信系統的仿真方法,該方法包括:
客戶端讀取仿真配置參數,確定并行工作的各個cpu的功能類型并創建對應的仿真任務,通過任務管理器向并行工作的各個cpu下發仿真任務;
并行工作的cpu接收任務管理器下發的仿真任務,根據客戶端配置的功能類型與其他cpu進行數據交互和同步操作,運行仿真代碼。
可選地,所述客戶端讀取仿真配置參數并進行處理,確定并行工作的各 個cpu的功能類型并創建對應的仿真任務,包括:
根據仿真配置參數配置的并行工作的cpu數量、網絡節點的數量和參數,在本地計算或通過并行工作的cpu協同計算網絡節點之間的干擾關系,根據計算結果確定網絡節點之間的數據交互關系;
確定并行工作的各個cpu的功能類型,根據網絡節點、用戶設備的數據交互關系為負責通信制式仿真的cpu分配網絡節點和用戶設備,構建并行工作的cpu之間的數據交互關系,為需要進行點對點通信的cpu對設置通信時序;
為并行工作的每一個cpu創建對應的仿真任務,所述仿真任務包括數據和仿真代碼;
其中,所述cpu的功能類型包括:時序控制、數據中轉、通信制式仿真。
可選地,所述根據網絡節點、用戶設備的數據交互關系為負責通信制式仿真的cpu分配網絡節點和用戶設備,包括進行以下至少一種處理:
a)將異制式異頻點的網絡節點劃分在不同的通信制式仿真cpu中;
b)將存在數據交互的同制式同頻點的網絡節點劃分在同一種通信制式仿真cpu中,同制式同頻點的網絡節點,根據網絡節點的干擾關系劃分到不同的cpu中;
c)將用戶設備劃分到其接入網絡節點所在的通信制式仿真cpu中。
d)不同并行cpu之間數據交互最少;
e)不同并行cpu之間計算量均衡。
可選地,并行工作的cpu根據客戶端配置的功能類型與其他cpu進行數據交互和同步操作,運行仿真代碼,包括:
并行工作的cpu根據獲取到的仿真任務確定自己的功能是時序控制時,通過運行仿真代碼向其他cpu廣播cpu之間的同步消息。
可選地,并行工作的cpu根據客戶端配置的功能類型與其他cpu進行數據交互和同步操作,運行仿真代碼,包括:
并行工作的cpu根據獲取到的仿真任務確定自己的功能是數據中轉時,接收時序控制cpu廣播的同步消息并獲取當前進行點對點通信的收發cpu對信息,在確定當前是本cpu與負責通信制式仿真的cpu進行點對點通信時,將緩存的其他cpu發送給本cpu當前通信對端的數據延時后發出,接收并緩存本cpu當前通信對端發送給其他cpu的數據。
可選地,并行工作的cpu根據客戶端配置的功能類型與其他cpu進行數據交互和同步操作,運行仿真代碼,包括:
并行工作的cpu根據獲取到的仿真任務確定自己的功能是通信制式仿真時,接收時序控制cpu廣播的同步消息并獲取當前進行點對點通信的收發cpu對信息,在確定當前是本cpu與其他cpu進行點對點通信時,與其他cpu進行數據交互,運行網絡節點協議棧代碼和用戶設備協議棧代碼,計算上行和/或下行干擾。
可選地,所述并行工作的cpu計算上行和/或下行干擾,包括:
在對本cpu中駐留的目標網絡節點計算上行干擾時,獲取本cpu中駐留的用戶設備與所述目標網絡節點之間的位置關系和信道模型、其他cpu中駐留的對所述目標網絡節點存在強干擾的用戶設備與所述目標網絡節點之間的位置關系和信道模型,根據獲取到的信息計算信號之間的慢衰和快衰,根據信號衰落的計算結果確定用戶設備對所述目標網絡節點的上行干擾;
在對本cpu中駐留的目標用戶設備計算下行干擾時,獲取本cpu中駐留的網絡節點與所述目標用戶設備之間的位置關系和信道模型、其他cpu中駐留的對所述目標用戶設備存在強干擾的網絡節點與所述目標用戶設備之間的位置關系和信道模型,根據獲取到的信息計算信號之間的慢衰和快衰,根據信號衰落的計算結果確定網絡節點對所述目標用戶設備的下行干擾。
本發明提供了一種大規模復雜無線通信系統的仿真系統,包括:
客戶端,用于讀取仿真配置參數并進行處理,確定并行工作的各個cpu的功能類型并創建對應的仿真任務,通過任務管理器向并行工作的各個cpu 下發仿真任務;
并行工作的cpu,用于接收任務管理器下發的仿真任務,根據客戶端配置的功能類型與其他cpu進行數據交互和同步操作,運行仿真代碼;
任務管理器,用于接收客戶端提交的仿真任務并下發給并行工作的cpu。
可選地,所述客戶端,用于讀取仿真配置參數并進行處理,確定并行工作的各個cpu的功能類型并創建對應的仿真任務,包括:
根據仿真配置參數配置的并行工作的cpu數量、網絡節點的數量和參數,在本地計算或通過并行工作的cpu協同計算網絡節點之間的干擾關系,根據計算結果確定網絡節點之間的數據交互關系;
確定并行工作的各個cpu的功能類型,根據網絡節點、用戶設備的數據交互關系為負責通信制式仿真的cpu分配網絡節點和用戶設備,構建并行工作的cpu之間的數據交互關系,為需要進行點對點通信的cpu對設置通信時序;
為并行工作的每一個cpu創建對應的仿真任務,所述仿真任務包括數據和仿真代碼;
其中,所述cpu的功能類型包括:時序控制、數據中轉、通信制式仿真。
可選地,所述客戶端,用于根據網絡節點、用戶設備的數據交互關系為負責通信制式仿真的cpu分配網絡節點和用戶設備,包括進行以下至少一種處理:
a)將異制式異頻點的網絡節點劃分在不同的通信制式仿真cpu中;
b)將存在數據交互的同制式同頻點的網絡節點劃分在同一種通信制式仿真cpu中,同制式同頻點的網絡節點,根據網絡節點的干擾關系劃分到不同的cpu中;
c)將用戶設備劃分到其接入網絡節點所在的通信制式仿真cpu中。
d)不同并行cpu之間數據交互最少;
e)不同并行cpu之間計算量均衡。
可選地,并行工作的cpu,用于根據客戶端配置的功能類型與其他cpu進行數據交互和同步操作,運行仿真代碼,包括:
根據獲取到的仿真任務確定自己的功能是時序控制時,通過運行仿真代碼向其他cpu廣播cpu之間的同步消息。
可選地,并行工作的cpu,用于根據客戶端配置的功能類型與其他cpu進行數據交互和同步操作,運行仿真代碼,包括:
根據獲取到的仿真任務確定自己的功能是數據中轉時,接收時序控制cpu廣播的同步消息并獲取當前進行點對點通信的收發cpu對信息,在確定當前是本cpu與負責通信制式仿真的cpu進行點對點通信時,將緩存的其他cpu發送給本cpu當前通信對端的數據延時后發出,接收并緩存本cpu當前通信對端發送給其他cpu的數據。
可選地,并行工作的cpu,用于根據客戶端配置的功能類型與其他cpu進行數據交互和同步操作,運行仿真代碼,包括:
根據獲取到的仿真任務確定自己的功能是通信制式仿真時,接收時序控制cpu廣播的同步消息并獲取當前進行點對點通信的收發cpu對信息,在確定當前是本cpu與其他cpu進行點對點通信時,與其他cpu進行數據交互,運行網絡節點協議棧代碼和用戶設備協議棧代碼,計算上行和/或下行干擾。
可選地,并行工作的cpu,用于計算上行和/或下行干擾,包括:
在對本cpu中駐留的目標網絡節點計算上行干擾時,獲取本cpu中駐留的用戶設備與所述目標網絡節點之間的位置關系和信道模型、其他cpu中駐留的對所述目標網絡節點存在強干擾的用戶設備與所述目標網絡節點之間的位置關系和信道模型,根據獲取到的信息計算信號之間的慢衰和快衰,根據信號衰落的計算結果確定用戶設備對所述目標網絡節點的上行干擾;
在對本cpu中駐留的目標用戶設備計算下行干擾時,獲取本cpu中駐留的網絡節點與所述目標用戶設備之間的位置關系和信道模型、其他cpu 中駐留的對所述目標用戶設備存在強干擾的網絡節點與所述目標用戶設備之間的位置關系和信道模型,根據獲取到的信息計算信號之間的慢衰和快衰,根據信號衰落的計算結果確定網絡節點對所述目標用戶設備的下行干擾。
與現有技術相比,本發明提供的一種大規模復雜無線通信系統的仿真方法和系統,客戶端讀取仿真配置參數并進行處理,確定并行工作的各個cpu的功能類型并創建對應的仿真任務,通過任務管理器向并行工作的各個cpu下發仿真任務,并行工作的cpu接收到任務管理器下發的仿真任務后,根據客戶端配置的功能類型與其他cpu進行數據交互和同步操作,運行仿真代碼。本發明能夠解決大規模復雜無線通信系統仿真過程中面臨的內存壓力、計算壓力,并為仿真平臺提供靈活性、擴展性好的并行架構,以支持多種需求、想法和場景的仿真。
附圖說明
圖1為本發明實施例采用的分布式并行仿真平臺的系統架構示意圖。
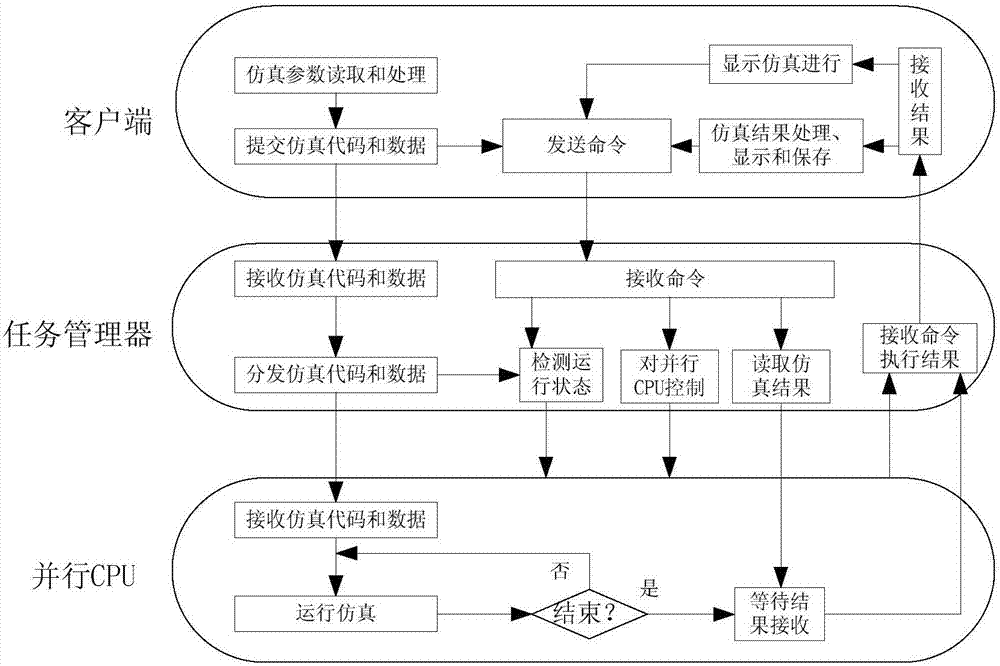
圖2為本發明實施例的分布式并行仿真平臺中客戶端、任務管理器和并行cpu的功能示意圖。
圖3為本發明實施例的一種大規模復雜無線通信系統的仿真方法流程圖。
圖4為本發明實施例的一種大規模復雜無線通信系統的仿真系統示意圖。
圖5為本發明示例1的客戶端實現實例一流程圖。
圖6為本發明示例2的單通信制式仿真平臺cpu構成及相互關系(實例一)示意圖。
圖7為本發明示例3的單通信制式仿真平臺cpu構成及相互關系(實例二)示意圖。
圖8為本發明示例4的多制式共存仿真平臺cpu構成及相互關系(實例三)示意圖。
圖9為本發明示例5的多制式共存仿真平臺cpu構成及相互關系(實例四)示意圖。
圖10為本發明示例6的并行cpu實現流程示意圖。
圖11為本發明示例7的時序控制節點實現流程示意圖。
圖12為本發明示例8的并行cpu數據交互實現流程實例一示意圖。
圖13為本發明示例9的并行cpu數據交互實現流程實例二示意圖。
圖14為本發明示例10的并行cpu數據交互實現流程實例三示意圖。
圖15為本發明示例11的通信制式仿真cpu仿真網絡范圍確定示意圖。
圖16為本發明示例13的通信制式仿真cpu仿真實現流程圖。
圖17為本發明示例14的中轉節點cpu實現流程圖。
具體實施方式
為使本發明的目的、技術方案和優點更加清楚明白,下文中將結合附圖對本發明的實施例進行詳細說明。需要說明的是,在不沖突的情況下,本申請中的實施例及實施例中的特征可以相互任意組合。
本發明采用分布式并行仿真平臺,該仿真平臺的架構主要由三部分組成:客戶端、任務管理器和并行cpu。客戶端是一臺或者多臺遠程pc機,這些pc機由人控制,多臺pc機之間獨立運行。任務管理器是并行仿真機中的一個cpu,這個cpu可以與其他并行cpu共用一臺仿真機也可以獨占一臺仿真機。多臺并行仿真機,每臺仿真機有一個或多個cpu,這些cpu構成并行cpu,這些cpu之間并行獨立運行,有自己獨立的內存。
圖1是并行系統的架構。客戶端通過網絡與仿真實驗室相連,仿真實驗室有多臺高性能仿真機,高性能仿真機之間通過交換機相連,將其中一臺仿真機設置為任務管理器,其余仿真機的cpu構成并行cpu。
如圖2所示,所述分布式并行仿真平臺包含的客戶端、任務管理器、并行cpu的主要功能和信息交互如下:
客戶端,是一臺或者多臺彼此獨立的pc機,可在遠程辦公室等地,由 人操作啟動仿真,主要工作是:啟動仿真、并讀取仿真配置的參數;根據配置的并行cpu數量和仿真中網絡節點的類型和數量,為每個并行cpu分配仿真網絡節點;分配的依據是:不同并行cpu之間數據交互最少,以及不同并行cpu之間計算量盡可能均衡;設置每個并行cpu的類型;根據網絡節點分配結果和不同網絡節點的數據交互關系構建不同并行cpu間的數據交互關系;將讀取和初步處理的仿真數據和仿真平臺代碼提交到任務管理器;向任務管理器發出命令,接收任務管理器返回的命令響應;對多個并行cpu返回的仿真結果進行綜合處理。
任務管理器,可設置在一臺仿真機上,主要工作:接收客戶端提交的數據和代碼,將這些數據和代碼分發到并行cpu中;檢測每個并行cpu的運行狀態;根據客戶端的命令執行相應的操作,如刪除或者取消并行仿真任務、回收狀態為finish(完成)的仿真任務的運行結果等。
并行cpu,接收任務管理器分發的結果,根據本cpu的網絡節點類型和網絡節點id,運行相應的仿真代碼;與相關的并行cpu進行數據交互、同步等操作。
并行cpu可以包括四種功能類型:時序控制、數據中轉、移動節點仿真和通信制式仿真。時序控制功能,用于向所有并行cpu廣播cpu之間的同步消息,驅動仿真進行;中轉功能,用于接收、緩存和轉發歸屬不同并行cpu中網絡節點的信令,包括不同并行cpu之間的用戶切換過程的信令、不同cpu內小區之間的交互和協作信令等;移動節點仿真功能,用于對一些不斷移動的網絡節點進行仿真,將它們劃分一個節點是為了避免它們的移動導致并行cpu之間的負荷失衡;通信制式仿真功能,用于運行不同制式網絡節點的仿真,一個cpu只運行一種制式的仿真,相同通信制式仿真cpu通過點對點直接進行數據交互,各cpu對之間依次進行通信,交互內容包括實時信息,如空口信息、移動用戶和移動網絡節點的位置信息。
相對單核仿真平臺,分布式并行仿真平臺能進行超大規模的網絡仿真,而不會受到內存的限制;能進行復雜的物理層計算、射線追蹤仿真、復雜信道建模等,而不影響速率;能進行多種制式共存互干擾仿真、協作和互操作仿真,而不會增加代碼的復雜度;能很好的支持通信協議的演進,當協議變 動時,只需要對變動的部分進行修改,而不需要對平臺推倒重來,如當需要為某種應用設計一種通信方式時,只需要增加一個并行cpu,然后在這個并行cpu中進行仿真建模的編碼即可;能極大提升仿真的運算效率,特別是需要快速輸出結果的仿真。
如圖3所示,本發明實施例提供了一種大規模復雜無線通信系統的仿真方法,該方法包括:
s101,客戶端讀取仿真配置參數,確定并行工作的各個cpu的功能類型并創建對應的仿真任務,通過任務管理器向并行工作的各個cpu下發仿真任務;
s102,并行工作的cpu接收任務管理器下發的仿真任務,根據客戶端配置的功能類型與其他cpu進行數據交互和同步操作,運行仿真代碼。
其中,所述客戶端讀取仿真配置參數并進行處理,確定并行工作的各個cpu的功能類型并創建對應的仿真任務,包括:
根據仿真配置參數配置的并行工作的cpu數量、網絡節點的數量和參數,在本地計算或通過并行工作的cpu協同計算網絡節點之間的干擾關系,根據計算結果確定網絡節點之間的數據交互關系;
確定并行工作的各個cpu的功能類型,根據網絡節點、用戶設備的數據交互關系為負責通信制式仿真的cpu分配網絡節點和用戶設備,構建并行工作的cpu之間的數據交互關系,為需要進行點對點通信的cpu對設置通信時序;
為并行工作的每一個cpu創建對應的仿真任務,所述仿真任務包括數據和仿真代碼;
其中,所述cpu的功能類型包括:時序控制、數據中轉、通信制式仿真。
其中,所述根據網絡節點、用戶設備的數據交互關系為負責通信制式仿真的cpu分配網絡節點和用戶設備,包括進行以下至少一種處理:
a)將異制式異頻點的網絡節點劃分在不同的通信制式仿真cpu中;
b)將存在數據交互的同制式同頻點的網絡節點劃分在同一種通信制式仿真cpu中,同制式同頻點的網絡節點,根據網絡節點的干擾關系劃分到不同的cpu中;
c)將用戶設備劃分到其接入網絡節點所在的通信制式仿真cpu中。
d)不同并行cpu之間數據交互最少;
e)不同并行cpu之間計算量均衡。
其中,并行工作的cpu根據客戶端配置的功能類型與其他cpu進行數據交互和同步操作,運行仿真代碼,包括:
并行工作的cpu根據獲取到的仿真任務確定自己的功能是時序控制時,通過運行仿真代碼向其他cpu廣播cpu之間的同步消息。
其中,并行工作的cpu根據客戶端配置的功能類型與其他cpu進行數據交互和同步操作,運行仿真代碼,包括:
并行工作的cpu根據獲取到的仿真任務確定自己的功能是數據中轉時,接收時序控制cpu廣播的同步消息并獲取當前進行點對點通信的收發cpu對信息,在確定當前是本cpu與負責通信制式仿真的cpu進行點對點通信時,將緩存的其他cpu發送給本cpu當前通信對端的數據延時后發出,接收并緩存本cpu當前通信對端發送給其他cpu的數據。
其中,并行工作的cpu根據客戶端配置的功能類型與其他cpu進行數據交互和同步操作,運行仿真代碼,包括:
并行工作的cpu根據獲取到的仿真任務確定自己的功能是通信制式仿真時,接收時序控制cpu廣播的同步消息并獲取當前進行點對點通信的收發cpu對信息,在確定當前是本cpu與其他cpu進行點對點通信時,與其他cpu進行數據交互,運行網絡節點協議棧代碼和用戶設備協議棧代碼,計算上行和/或下行干擾。
其中,所述并行工作的cpu計算上行和/或下行干擾,包括:
在對本cpu中駐留的目標網絡節點計算上行干擾時,獲取本cpu中駐留的用戶設備與所述目標網絡節點之間的位置關系和信道模型、其他cpu 中駐留的對所述目標網絡節點存在強干擾的用戶設備與所述目標網絡節點之間的位置關系和信道模型,根據獲取到的信息計算信號之間的慢衰和快衰,根據信號衰落的計算結果確定用戶設備對所述目標網絡節點的上行干擾;
在對本cpu中駐留的目標用戶設備計算下行干擾時,獲取本cpu中駐留的網絡節點與所述目標用戶設備之間的位置關系和信道模型、其他cpu中駐留的對所述目標用戶設備存在強干擾的網絡節點與所述目標用戶設備之間的位置關系和信道模型,根據獲取到的信息計算信號之間的慢衰和快衰,根據信號衰落的計算結果確定網絡節點對所述目標用戶設備的下行干擾。
如圖4所示,本發明實施例提供了一種大規模復雜無線通信系統的仿真系統,包括:
客戶端,用于讀取仿真配置參數,確定并行工作的各個cpu的功能類型并創建對應的仿真任務,通過任務管理器向并行工作的各個cpu下發仿真任務;
并行工作的cpu,用于接收任務管理器下發的仿真任務,根據客戶端配置的功能類型與其他cpu進行數據交互和同步操作,運行仿真代碼;
任務管理器,用于接收客戶端提交的仿真任務并下發給并行工作的cpu。
其中,所述客戶端,用于讀取仿真配置參數并進行處理,確定并行工作的各個cpu的功能類型并創建對應的仿真任務,包括:
根據仿真配置參數配置的并行工作的cpu數量、網絡節點的數量和參數,在本地計算或通過并行工作的cpu協同計算網絡節點之間的干擾關系,根據計算結果確定網絡節點之間的數據交互關系;
確定并行工作的各個cpu的功能類型,根據網絡節點、用戶設備的數據交互關系為負責通信制式仿真的cpu分配網絡節點和用戶設備,構建并行工作的cpu之間的數據交互關系,為需要進行點對點通信的cpu對設置 通信時序;
為并行工作的每一個cpu創建對應的仿真任務,所述仿真任務包括數據和仿真代碼;
其中,所述cpu的功能類型包括:時序控制、數據中轉、通信制式仿真。
其中,所述客戶端,用于根據網絡節點、用戶設備的數據交互關系為負責通信制式仿真的cpu分配網絡節點和用戶設備,包括進行以下至少一種處理:
a)將異制式異頻點的網絡節點劃分在不同的通信制式仿真cpu中;
b)將存在數據交互的同制式同頻點的網絡節點劃分在同一種通信制式仿真cpu中,同制式同頻點的網絡節點,根據網絡節點的干擾關系劃分到不同的cpu中;
c)將用戶設備劃分到其接入網絡節點所在的通信制式仿真cpu中。
d)不同并行cpu之間數據交互最少;
e)不同并行cpu之間計算量均衡。
其中,并行工作的cpu,用于根據客戶端配置的功能類型與其他cpu進行數據交互和同步操作,運行仿真代碼,包括:
根據獲取到的仿真任務確定自己的功能是時序控制時,通過運行仿真代碼向其他cpu廣播cpu之間的同步消息。
其中,并行工作的cpu,用于根據客戶端配置的功能類型與其他cpu進行數據交互和同步操作,運行仿真代碼,包括:
根據獲取到的仿真任務確定自己的功能是數據中轉時,接收時序控制cpu廣播的同步消息并獲取當前進行點對點通信的收發cpu對信息,在確定當前是本cpu與負責通信制式仿真的cpu進行點對點通信時,將緩存的其他cpu發送給本cpu當前通信對端的數據延時后發出,接收并緩存本cpu當前通信對端發送給其他cpu的數據。
其中,并行工作的cpu,用于根據客戶端配置的功能類型與其他cpu 進行數據交互和同步操作,運行仿真代碼,包括:
根據獲取到的仿真任務確定自己的功能是通信制式仿真時,接收時序控制cpu廣播的同步消息并獲取當前進行點對點通信的收發cpu對信息,在確定當前是本cpu與其他cpu進行點對點通信時,與其他cpu進行數據交互,運行網絡節點協議棧代碼和用戶設備協議棧代碼,計算上行和/或下行干擾。
其中,并行工作的cpu,用于計算上行和/或下行干擾,包括:
在對本cpu中駐留的目標網絡節點計算上行干擾時,獲取本cpu中駐留的用戶設備與所述目標網絡節點之間的位置關系和信道模型、其他cpu中駐留的對所述目標網絡節點存在強干擾的用戶設備與所述目標網絡節點之間的位置關系和信道模型,根據獲取到的信息計算信號之間的慢衰和快衰,根據信號衰落的計算結果確定用戶設備對所述目標網絡節點的上行干擾;
在對本cpu中駐留的目標用戶設備計算下行干擾時,獲取本cpu中駐留的網絡節點與所述目標用戶設備之間的位置關系和信道模型、其他cpu中駐留的對所述目標用戶設備存在強干擾的網絡節點與所述目標用戶設備之間的位置關系和信道模型,根據獲取到的信息計算信號之間的慢衰和快衰,根據信號衰落的計算結果確定網絡節點對所述目標用戶設備的下行干擾。
示例1
客戶端實現實例
該實例主要描述多個仿真用例(case)仿真時客戶端的處理過程,依次讀取每個case的仿真數據,為每個case單獨創建并行job,并提交。其流程圖如圖5所示。
s200:從參數表中讀取仿真配置數據;
其中,所述仿真配置數據包括仿真時長、并行cpu數量、路損模型、快衰模型、慢衰模型、網絡規模等。
s201:選擇是在客戶端還是遠程并行計算機上計算網絡節點在網格點上的功率。如果選擇在客戶端上計算,則執行步驟s205,如果選擇是在遠程并行計算機上計算,則執行步驟s202;
評估并行計算和客戶端的內存壓力和計算效率。并行計算時將所有的網絡節點劃分為幾部分,能有效緩解內存壓力并可能提升計算效率,單個并行cpu只計算其中一部分網絡節點在所有網格點上的功率,客戶端計算所有網絡節點在所有網格點上的功率。
內存評估通過客戶端內存和網絡規模進行判斷。效率評估的方法:并行任務的提交和結果回收的時間ttrans,并行計算時間tex,客戶端的計算時間為tpro_client,上述時間都可通過前期測試獲得。在客戶端內存足夠的情況下,如果ttrans+tex≥tpro_client說明客戶端計算效率高,執行s205,一般出現在網絡規模較小的情況;如果ttrans+tex<tpro_client,則說明并行計算效率高,執行s202。在客戶端內存不夠的情況下,可以不進行計算效率的評估,直接執行s202。
其中,通過網格來離散化整個仿真區域,網格可以是正方形、長方形或六邊形,網格點可以配置為所屬網格的中心點,用網格點代表網格區域內的所有點,網格的大小和形狀可以配置;
其中,網絡節點包括:基站、中繼點(relay)、游牧節點等;
其中,網絡節點在一個網格點上的功率是指:網絡節點發射功率經過快衰、慢衰之后到網格點的功率;通過計算網絡節點在網格點上的功率確定網絡節點之間的干擾,便于下一步進行網絡節點的劃分;
s202:在任務管理器中創建并行job,設置并行cpu數、job名、用戶名、提交計算需要的代碼和數據的路徑等,此并行job用于計算所有網絡節點在所有網格點上的功率。
s203:提交并行job。
s204:等待計算完成,并回收計算結果,跳轉到s206。
s205:客戶端計算所有網絡節點在所有網格點上的功率。
s206:設置每個并行cpu功能,根據計算結果確定網絡節點的干擾關系,根據干擾關系對網絡節點、ue進行劃分,將網絡節點和ue劃分到并 行cpu中。
劃分原則是異制式異頻點的網絡節點劃分在不同的cpu中,同制式同頻點網絡節點劃分時將存在數據交互的網絡節點盡可能劃分到同一個cpu中;將ue劃分到其接入網絡節點所在的cpu中;其中,在整網范圍內,計算所有網絡節點到所有ue的參考信號功率,為每個ue找到參考信號功率最強的網絡節點,將ue劃分到所述最強參考信號的網絡節點所在的cpu中。
構建cpu之間的數據交互關系和進行點對點通信的cpu對的通信順序;
s207:創建并行job,用于進行正式仿真。
s208:提交并行job。
s209:判斷所有的仿真用例是否處理完成,處理完則執行s211,否則執行s210。
s210:切換到下一個仿真用例,執行s200。
s211:啟動定時器;
其中,所述定時器用于周期性的查詢job狀態和顯示仿真進程,當job處于完成(finish)狀態時回收和處理仿真結果,并刪除完成狀態的job。
示例2
仿真平臺cpu構成及相互關系實例一
圖6對應于一種lte單通信制式仿真場景下的仿真平臺。
所述仿真平臺包括:客戶端、任務管理器和并行cpu,他們之間進行仿真代碼、仿真數據、命令和仿真結果數據的交互,客戶端通過任務管理器對并行cpu進行控制和操作。他們之間可以雙向通信。
并行cpu可以包括以下類型的cpu:時序控制節點cpu、通信制式仿真節點cpu;
其中,時序控制節點cpu向所有cpu節點廣播cpu之間的同步消息、 當前時刻和仿真結束標志。
lte通信制式仿真節點cpu之間可進行直接的點對點通信,交互的數據是空口信息、移動網絡節點和移動ue的位置信息、網元之間的控制信令等;其中,空口信息用于計算不在同一個cpu中小區的鄰區干擾,需要實時交互;位置信息用于計算實時的信道信息;控制信令存在時延,需要在發送端cpu中緩存一定時間再發送,執行一些協作、切換等操作。
并行cpu還可以包括移動節點仿真cpu,比如圖6中的lte移動節點cpu。單獨劃分移動節點仿真cpu是為了避免站點的移動導致cpu之間計算量負荷失衡,如果沒有移動網絡節點,此cpu可刪除。
示例3
仿真平臺cpu構成及相互關系實例二
圖7對應于另一種lte單通信制式仿真場景下的仿真平臺。
與示例2的lte單通信制式仿真平臺類似,示例3的lte單通信制式仿真平臺也包括:客戶端、任務管理器和并行cpu;示例3與示例2的差異是并行cpu類型中增加中轉節點類型;
中轉節點cpu用于緩存和轉發不同cpu節點中網絡節點的信令,包括切換用戶信息、切換命令、協作命令等,緩存用于模擬信令交互時延。
示例4
仿真平臺cpu構成及相互關系實例三
圖8是一種多通信制式仿真平臺cpu構成及相互關系。
與示例2的lte單通信制式仿真平臺類似,示例4的多通信制式仿真平臺也包括:客戶端、任務管理器和并行cpu;
其中,并行cpu可以包括以下類型的cpu:時序控制節點cpu、通信制式仿真節點cpu;
示例4與示例2的差異是:通信制式仿真節點cpu包括多種制式;每 個并行cpu只運行一種通信制式仿真代碼,通信制式仿真節點cpu之間進行直接的點對點數據通信,相同制式之間交互的是空口信息、移動網絡節點和ue的位置信息和信令,在不考慮系統間互干擾的情況下,不同制式之間只進行信令交互;空口信息需要實時交互,信令需要在發送端緩存一定時間再發送。
示例5
仿真平臺cpu構成及相互關系實例四
圖9是另一種多通信制式仿真平臺cpu構成及相互關系。
與示例4的多通信制式仿真平臺類似,示例5的多通信制式仿真平臺也包括:客戶端、任務管理器和并行cpu;
示例5與示例4的差異是并行cpu中增加中轉節點類型;
中轉節點cpu接收不同制式節點的信令交互,并對信令進行緩存和轉發。
通信制式仿真節點cpu運行仿真代碼,相同制式節點進行直接數據交互,主要交互空口信息,用于不同cpu中鄰區的干擾計算,在不考慮系統間互干擾的情況下,不同制式的數據交互只有信令,且一般不進行直接交互,需要通過中轉節點交互。
示例6
并行cpu運行流程實例一
并行cpu實現流程如圖10所示,包括以下步驟:
s400:讀取仿真數據,當任務管理器分發完數據之后,所有的并行cpu均加載任務管理器分發的仿真配置參數。
s401:讀取本cpu的數據,任務管理器分發到所有并行cpu是相同的代碼和數據,每一個cpu可以根據自己的index,讀取與自己相關的數據,如公共仿真數據、本cpu駐留網絡節點和ue的參數配置、本cpu干擾網 絡節點和ue的參數配置等。
s402:設置本cpu的功能,根據讀取的數據可知本cpu配置的功能,設置好功能之后執行自己的功能。
s403:發送或者接收廣播消息;
在時序控制節點cpu中,進行計時并決策何時發送廣播消息;其他節點cpu則等待接收時序控制節點cpu發送的廣播消息。
s404:等待其他并行cpu接收到廣播消息,實現并行cpu的通信同步。
s405:判斷是否仿真結束,從廣播消息中讀取仿真結束標志,如果讀取到仿真結束標志,則結束流程;如果沒有讀取到仿真結束標志,時序控制節點cpu執行步驟s407,中轉節點cpu、通信制式仿真節點cpu執行步驟s406;
s406:不同cpu(通信制式仿真節點cpu、中轉節點cpu)之間按照通信時序進行數據交互,交互當前時刻的空口信息、移動站點和移動用戶的位置信息、信令;
s407:等待其他并行cpu數據交互完成,實現并行cpu通信同步,時序控制節點cpu、中轉節點cpu執行完步驟s407后跳轉到s411,通信制式仿真節點cpu執行完步驟s407后執行步驟s408;
s408:通信制式仿真節點cpu判斷時序控制節點cpu廣播的cpu之間的同步消息是否為本制式的同步幀,是則執行s409,否則執行s411。
s409:執行本通信制式仿真代碼。
s410:產生交互數據。
s411:等待其他cpu完成,并行cpu代碼執行同步后,跳轉到s403;
其中,在通信制式仿真節點cpu執行s408-s410過程中,時序控制節點cpu和中轉節點cpu可以處于等待狀態,保證并行cpu的代碼執行同步,然后跳轉到s403。
示例7
時序控制節點cpu驅動仿真平臺實例一
時序控制節點產生并廣播當前時刻、不同制式幀到達消息和仿真結束標志三種消息,是整個系統的心臟,驅動仿真的運行,它以最小仿真時間粒度為單位進行時間累加,每累加一次,與所有制式的最小仿真時間單位進行模運算,廣播模為0的制式對應的幀到達消息。圖11以lte、umts、gsm三種制式共存仿真為例說明時序控制節點實現,三種制式最小仿真時間單位分別是:1ms、0.667ms和0.577ms。
s500:設置仿真時長;
設置仿真時長,便于判斷仿真是否結束。
s501:設置共存仿真中各種制式的最小仿真時間單位;
其中,設置各種制式的最小仿真時間單位,便于后續判斷廣播幀到達消息的時刻。
s502:計數器icounter累加,累加的最小時間是最小時間粒度;
其中,三種制式的最小仿真時間單位分別是1ms、0.667ms、0.577ms,則累加的最小時間粒度是1us。
s503:判斷仿真是否結束,是則執行s504,否則執行s505。
s504:廣播消息,消息中仿真結束標志位置1;
s505:將icounter與每一種制式的最小仿真時間粒度進行模運算;
s506,判斷對每一種制式的求模結果中是否至少有一種制式的求模結果為0,是則執行s507,否則返回s502;
s507:廣播模為0的制式的幀到達消息、當前時刻icounter和仿真結束標志(置0),跳轉到s502。
示例8
通信制式仿真節點cpu通信實現實例一
并行cpu之間采用兩種通信方式進行數據交互:廣播和點對點。幀到 達消息通過廣播方式發送給所有并行cpu。中轉節點cpu和通信制式仿真節點cpu之間通過依次點對點通信,一次只有一對cpu通信,在某個cpu對通信過程中,其他cpu等待,cpu對通信的次序在客戶端生成,不同并行cpu中網絡節點的信令交互通過中轉節點cpu實現。
仿真平臺中,先進行廣播通信,再進行點對點的數據交互通信。通信制式仿真節點cpu的點對點數據交互流程圖如圖12所示。
s601:讀取當前進行點對點通信的收發cpu對的信息。
s602:判斷本節點cpu的index是否在收發cpu對中,是則執行s603;否則執行s608。
s603:判斷通信制式仿真節點cpu是否與中轉節點cpu通信,是則執行s605,否則執行s604。
s604:讀取需要實時發出的數據;
其中,需要實時發出的數據,包括本cpu中網絡節點的空口信息,本cpu中ue和移動站點的位置信息等,目的是用于其他cpu中網絡節點計算當前時刻干擾,跳轉到s606。
s605:讀取信令數據。
s606:執行數據收發命令labsendreceive。
s607:保存接收的數據。
s608:執行等待命令,實現并行cpu的通信同步。
s609:判斷所有并行cpu數據交互是否完成,是則直接結束;否則執行s610。
s610:讀取下一對進行點對點通信的收發cpu對信息,跳轉到s602。
示例9
通信制式仿真節點cpu通信實現實例二
與示例8中的實例一的差異是沒有中轉節點轉發信令。
仿真平臺中,先進行廣播通信,再進行點對點的數據交互通信。點對點 數據交互流程圖如圖13所示。
s701:讀取當前進行點對點通信的收發cpu對的信息。
s702:判斷本節點cpu的index是否在收發cpu對中,是則執行s703;否則執行s709。
s703:讀取實時交互數據;
其中,所述實時交互數據包括與對端cpu需要交互的數據,包括空口信息,移動ue和移動站點的位置信息等,目的是用于當前仿真時刻計算干擾、產生干擾ue和網絡節點的快衰信息。
s704:判斷是否有信令發送,是則執行s705;否則跳轉到s707。
s705:判斷信令時延是否到,是則執行s706,否則執行s707。
s706:讀取信令數據。
s707:執行數據收發命令labsendreceive。
s708:保存接收的數據。
s709:執行等待命令,實現并行cpu的同步。
s710:判斷所有并行cpu數據交互是否完成,是則直接結束;否則執行s711。
s711:讀取下一對收發cpu對信息,跳轉到s702。
示例10
通信制式仿真節點cpu通信實現實例三
實例三不采用點對點依次通信,而是采用所有并行cpu同時通信方式,也沒有中轉節點cpu,信令和數據一起發送。流程圖如圖14所示。
s800:是否有實時數據交互,是則執行s801;否則執行s802。
s801:讀取需要發出的實時交互數據,準備發送;
其中,所述需要發出的實時交互數據包括空口信息,ue和移動站點的位置信息等,目的是用于當前仿真時刻計算干擾、產生干擾ue和網絡節點 的快衰信息。
s802:判斷是否有交互信令發送,有信令發送則執行s803;否則執行s805。
s803:判斷信令時延是否到,是則執行s804;否則執行s805。
s804:讀取信令數據。
s805:執行gcat數據交互命令。
s806:讀取發送給本cpu的數據,并保存。
s807:執行等待命令,等待其他并行cpu完成數據交互,實現同步,結束。
示例11
通信制式仿真節點cpu仿真實現實例一
本部分主要介紹通信制式仿真節點cpu確定仿真范圍的方法和具體仿真實現。
由客戶端實現可知,通信制式仿真節點的仿真范圍包括:本cpu中駐留的網絡節點和這些網絡節點的接入ue、其他cpu中對本cpu駐留網絡節點和ue存在強干擾的網絡節點和ue、異制式cpu中的網絡節點。
單個制式cpu仿真的網絡范圍應該包括網絡節點和這些網絡節點的接入ue,由于上下行干擾的差異,在分別進行上下行仿真時仿真范圍有所差異:
上行:仿真范圍包括:本cpu中駐留的網絡節點和ue、對本cpu駐留網絡節點存在強干擾的其他cpu駐留的ue、異制式cpu中的網絡節點;
下行:仿真范圍包括:本cpu中駐留的網絡節點和ue、對本cpu駐留ue存在強干擾的其他cpu駐留的網絡節點、異制式cpu中的網絡節點;
上下行同時仿真,則是上、下行仿真范圍的并集。
如圖15所示,本cpu中駐留的網絡節點和ue仿真范圍確定方法是: 找到這些節點中在上、下、左、右四個方向上最遠的節點,以這四個點作為矩形邊上的點確定一個矩形區域,在這個矩形區域的基礎上再擴大一定范圍(為了防止ue移動越界),由此決定的擴大后的矩形區域為仿真范圍。在立體場景仿真中,如果駐留網絡節點不連續,則用相同的方法另外再確定一個矩形區域,比如圖15中cpu_n仿真網絡范圍2。
對本cpu駐留節點存在干擾的節點(包括ue和網絡節點),如果其地理位置不在上述過程確定的仿真范圍內,則單獨將其三維地理位置信息加入到本cpu的仿真范圍中,這樣能極大減少仿真網格點數,還能實現立體場景仿真。
以ue運動和切換仿真說明通信制式仿真節點運行仿真,流程如圖16所示。
s900:接收廣播消息。
s901:判斷仿真是否完成,是則直接結束,否則執行s902。
s902:判斷是否是本制式幀到達消息,是則執行s903,否則執行s912。
s903:數據更新;
根據接收到的信息對本cpu中的網絡節點和ue數據進行更新。
s904:判斷是否為第一子幀,如果是第一子幀,執行s905,否則執行s906。
s905:小區重選,然后跳轉到s910;
在客戶端進行ue劃分時,rsrp(referencesignalreceivingpower,參考信號接收功率)功率計算和在單個并行cpu中rsrp計算的網絡規模可能不一樣,計算的慢衰和快衰可能有差異,導致最終在單個并行cpu中ue選擇的網絡節點與在客戶端選擇的不一樣,此處進行重新選擇,備選的網絡節點是并行cpu中的駐留網絡節點、干擾網絡節點和其他制式網絡節點。將最終選擇到其他cpu中網絡節點的ue_id和目標網絡節點id和目標cpuid保存,以便在s910中更新本cpu的ue數據。
s906:產生信道數據,用于協議棧仿真;
上下行產生的信道數據存在差異;
對于下行,由于干擾來自網絡節點發出的信號,因此只需要考慮網絡節點對ue的信號和干擾,快衰和慢衰主要是針對本cpu所有駐留網絡節點、干擾網絡節點,與本cpu駐留ue之間的信號衰落。
對于上行,由于干擾來自ue發送的上行信號,因此只需要考慮ue對網絡節點的信號和干擾,快衰和慢衰主要是針對本cpu所有駐留ue、干擾ue,與本cpu中駐留網絡節點之間的信號衰落。
上下行同時仿真時,需要計算的快衰和慢衰則是上述單向仿真時網絡節點和ue的組合。
并行cpu之間可以不進行快衰、慢衰數據的交互,目的是減少交互的數據量,降低通信時延,快衰的隨機數以ue和網絡節點的位置作為隨機種子,從而保證ue和網絡節點在不同cpu中的快衰和慢衰一致。保證仿真的完整性。
s907:運行網絡節點側協議棧代碼;
在網絡節點物理層計算單個網絡節點上行干擾時,對于單個資源,找到分配相同資源的駐留ue和干擾ue,將對該網絡節點干擾最強的n1個ue作為干擾,干擾稍弱的n2個ue作為噪聲,其他ue干擾可以不考慮。
s908:運行ue側協議棧代碼;
在ue物理層計算單個ue下行干擾時,將n1個干擾最強駐留網絡節點和干擾網絡節點作為干擾計算,干擾稍弱的n2個駐留網絡節點和干擾網絡節點作為噪聲計算,其余干擾可以不考慮。
s909:動態仿真流程;
改變本cpu中駐留運動網絡節點、駐留ue的位置;
主要計算本cpu中駐留網絡節點、干擾網絡節點、其他制式網絡節點到駐留ue的rsrp(referencesignalreceivingpower,參考信號接收功率),進行切換判決等操作,產生切換請求命令等。
s910:數據更新;
主要處理s905、s909產生的命令導致本cpu中ue切換到其他cpu變化的數據更新,如s905、s09中有重選、切換接納命令,且相應的ue重 選、切換到其他cpu中的網絡節點,則刪除此ue在本cpu中的信息。
s911:交互數據打包。
s912:等待其他cpu完成,實現同步。跳轉到s900。
示例12
中轉節點cpu數據交互實例一
不同制式cpu之間通過中轉節點作為中介進行信令交互,中轉節點對信令的緩存模擬信令交互時延,同時簡化了通信制式仿真節點cpu代碼設計,實現切換、協作和互操作等仿真。不同制式cpu之間數據交互的內容包括:源cpuid、目標cpuid、緩存時延、消息實體。中轉節點cpu數據交互流程如圖17所示。
s1000:接收同步幀消息,假設目前接收的同步幀消息是制式a。
s1001:讀取當前進行點對點通信的收發cpu對信息。
s1002:判斷當前進行點對點通信的收發cpu對是否為自己與制式a的一個cpu(比如,cpu_i),是則執行s1003,否則執行s1008。
s1003:判斷緩存中是否有其他制式cpu發給cpu_i的信令,是則執行s1004,否則執行s1008。
s1004:判斷其他制式cpu發送給cpu_i的信令時延是否到了,是則執行s1005,否則執行s1008。
s1005:讀取其他制式cpu發送給cpu_i的信令。
s1006:與cpu_i之間執行數據交互命令labsendreceive。
s1007:保存cpu_i發送給其他制式cpu的信令。
s1008:等待其他cpu完成通信,實現并行cpu的通信同步。
s1009:判斷所有的通信是否完成,是則直接結束,否則執行s1010。
s1010:讀取下一對進行點對點通信的收發cpu對信息,跳轉到s1002。
上述實施例提供的一種大規模復雜無線通信系統的仿真方法和系統,客戶端讀取仿真配置參數并進行處理,確定并行工作的各個cpu的功能類型并創建對應的仿真任務,通過任務管理器向并行工作的各個cpu下發仿真任務,并行工作的cpu接收到任務管理器下發的仿真任務后,根據客戶端配置的功能類型與其他cpu進行數據交互和同步操作,運行仿真代碼。本發明實施例能夠解決大規模復雜無線通信系統仿真過程中面臨的內存壓力、計算壓力,并為仿真平臺提供靈活和可擴展性很好的并行架構,以支持多種需求、想法和場景的仿真。
本領域普通技術人員可以理解上述方法中的全部或部分步驟可通過程序來指令相關硬件完成,所述程序可以存儲于計算機可讀存儲介質中,如只讀存儲器、磁盤或光盤等。可選地,上述實施例的全部或部分步驟也可以使用一個或多個集成電路來實現,相應地,上述實施例中的各模塊/單元可以采用硬件的形式實現,也可以采用軟件功能模塊的形式實現。本發明不限制于任何特定形式的硬件和軟件的結合。
需要說明的是,本發明還可有其他多種實施例,在不背離本發明精神及其實質的情況下,熟悉本領域的技術人員可根據本發明作出各種相應的改變和變形,但這些相應的改變和變形都應屬于本發明所附的權利要求的保護范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!