一種針對SM3?HMAC的側信道能量分析方法和裝置與流程
本發(fā)明涉及密碼分析領域,尤指一種針對SM3-HMAC(采用SM3密碼算法的哈希消息認證碼)的側信道能量分析方法和裝置。
背景技術:
隨著信息科技的發(fā)展,信息的安全性被提升到了一個前所未有的高度。各種密碼算法正被廣泛地應用于經(jīng)濟、軍事、行政等重要部門,以保護信息的安全性。對稱密碼和公鑰密碼的出現(xiàn)使得信息能從算法級和軟件級得到保護。但是進入21世紀后,隨著分析形式的多樣化,分析性越來越強的方法也隨之產(chǎn)生。
側信道分析避開分析復雜的密碼算法本身,利用的是密碼算法在軟件、硬件實現(xiàn)過程中泄漏的各種信息進行密碼分析。側信道分析的基本原理是:密碼算法在密碼芯片上實現(xiàn)時,由于設備的物理特性,總會產(chǎn)生執(zhí)行時間、功耗、電磁輻射、故障輸出等側信道泄漏;同時由于密碼芯片計算資源和處理能力的限制,密碼算法的主密鑰大都被分割成若干個子密鑰塊并按照一定的順序參與運算,不同時間使用這些子密鑰塊的側信道泄漏可被分析者采集到;這些側信道泄漏同明文、密文和子密鑰具有一定的相關性,分析者可以利用一定的分析方法恢復出子密鑰塊值;在得到足夠的子密鑰塊值后,結合密鑰擴展設計即可恢復主密鑰值。根據(jù)側信道泄漏采集過程中對密碼芯片接口的破壞程度,可以分為侵入式攻擊、半侵入式攻擊和非侵入式攻擊。非侵入式攻擊由于實施方便,實驗設備簡單,攻擊成本較低被廣泛使用。非侵入式攻擊中,攻擊者不需要對密碼芯片接口進行破壞,只需要利用專用設備正常訪問密碼芯片接口,典型分析方法包括計時分析、功耗分析、電磁分析等。側信道能量分析利用了密碼模塊功耗與運算數(shù)據(jù)和執(zhí)行的操作之間的相關性,基于密碼算法實現(xiàn)的能量泄露函數(shù),建立能量模型,使用統(tǒng)計方法,猜測和驗證密碼模塊使用的受保護密鑰或敏感信息。側信道能量分析具體有多種不同的方法,目前常用的方法包括簡單功耗分析(SPA),差分功耗分析(DPA),相關性功耗分析(CPA),模板分析等。
相關性功耗分析(CPA)對部分密鑰位(一個二進制密鑰位或是多個二進制密鑰位)參與的運算過程,考慮側信道泄漏的功耗與部分中間計算結果漢明重量(或者漢明距離,根據(jù)實際芯片而定)的線性相關性,如果在某個位置相關性最強,那么可以判斷該位置猜測密鑰位正確值。
選擇明文分析是在分析者可以控制加密設備輸入的情況的,通過分析密碼算法的結構,選定一組或者幾組特定的明文,使密碼設備正常運算,得到最后的加密結果。再將選擇明文的思想與功耗分析的方法結合,采集密碼設備執(zhí)行某些特定明文時的功耗信息,獲得部分數(shù)據(jù)與功耗信息之間的相關性,再使用CPA或DPA的思想進行分析,獲得密鑰等受保護的信息。
SM3密碼算法是國家密碼局公開算法中唯一的雜湊算法(也稱為Hash哈希函數(shù))。對長度為l(l<264)比特的消息m,SM3雜湊算法經(jīng)過填充、迭代壓縮和輸出的選裁,生成雜湊值,雜湊值輸出長度為256比特。
SM3的運算分為以下三大步驟:
一、消息填充
假設消息m的長度為l比特,則首先將比特“1”添加到消息的末尾,再添加k個“0”,k是滿足l+1+k≡448(mod 512)的最小的非負整數(shù)。然后再添加一個64位比特串。該比特串是長度l的二進制表示。填充后消息記作m′。
二、迭代壓縮
三、雜湊值
ABCDEFGH←V(n),輸出256比特的雜湊值y=ABCDEFGH。
算法中涉及到的常數(shù)與函數(shù)見下:
IV=7380166f 4914b2b9172442d7 da8a0600a96f30bc163138aa e38dee4db0fb0e4e
式中X,Y,Z均為字。
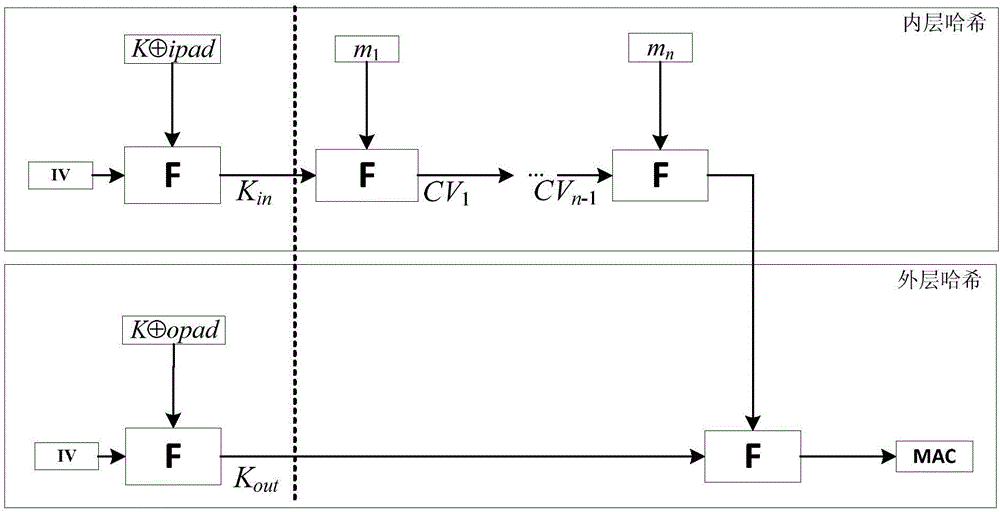
如圖1所示,HMAC(Keyed-Hash Message Authentication Code,哈希消息認證碼)算法描述如下:
對于給定的消息m,使用密鑰K,計算HMAC值的操作如下:
式中為異或(XOR)運算,||為拼接運算,H為hash函數(shù)(如SHA-1,SHA-256,MD5,SM3等),K0為密鑰K進行預處理的結果(通過末尾補0將長度變?yōu)榕cH函數(shù)的分組長度相同),ipad和opad為固定值,ipad=0x3636…3636,opad=0x5C5C…5C5C,長度與H函數(shù)的分組長度相同。IV為雜湊函數(shù)H的初始狀態(tài)值,F(xiàn)為H中壓縮函數(shù),m1,m2,…,mn為輸入的消息分組,Kin,Kout為密鑰,CV1,…,CVN-1為每次雜湊運算的中間狀態(tài)。
SM3作為國家密碼局公開算法中唯一的雜湊算法,其安全性越來越受到重視,側信道分析作為最有效的一種分析手段,被廣泛的應用于各種不同算法、多種不同實現(xiàn)的分析中,對算法的安全性產(chǎn)生了較大的威脅。但是目前對于SM3的側信道分析研究較少,研究的也不夠深入。雖然近兩年來也提出了兩種SM3-HMAC的分析方法,但是都不適用于分析純硬件實現(xiàn)的SM3-HMAC。
技術實現(xiàn)要素:
為了解決上述技術問題,本發(fā)明提供了一種針對SM3-HMAC的側信道能量分析方法和裝置,可以針對硬件實現(xiàn)的SM3-HMAC進行側信道能量分析。
為了達到本發(fā)明目的,本發(fā)明提供了一種針對采用SM3密碼算法的哈希消息認證碼SM3-HMAC的側信道能量分析方法,包括:
針對硬件實現(xiàn)的SM3-HMAC,通過選擇性輸入多組明文的方式,使用漢明距離模型分別獲取SM3密碼算法的中間值θ0θ1θ2θ3η0η1η2η3;
根據(jù)所述中間值θ0θ1θ2θ3η0η1η2η3分別計算參數(shù)A0,B0,C0,D0,E0,F0,G0,H0,得到密鑰Kin;
其中,SM3-HMAC根據(jù)如下公式得到:
式中為異或運算,||為拼接運算,H為采用SM3密碼算法的哈希函數(shù),K0為密鑰K進行預處理的結果,m為輸入的明文,ipad和opad為固定值,IV為首次執(zhí)行SM3密碼算法時壓縮函數(shù)的初始狀態(tài)值;Kin為HMAC運算中調用SM3密碼算法時壓縮函數(shù)的初始狀態(tài)A0B0C0D0E0F0G0H0。
可選地,所述通過選擇性輸入多組明文的方式,使用漢明距離模型分別獲取SM3密碼算法的中間值θ0θ1θ2θ3η0η1η2η3的步驟中,
將每個中間值劃分為多個部分,通過選擇性輸入多組明文的方式,使用漢明距離模型分別獲取所述中間值的每個部分,得到所述中間值。
可選地,所述將每個中間值劃分為多個部分,通過選擇性輸入多組明文的方式,使用漢明距離模型分別獲取所述中間值的每個部分,得到所述中間值的步驟中,
每4比特為一組,將每個中間值劃分為8組,通過選擇性輸入多組明文的方式,使用漢明距離模型,通過功耗分析,分別獲取所述中間值的每個部分,得到所述中間值;
其中,所述功耗分析為相關性功耗分析CPA或差分功耗分析DPA。
可選地,所述通過選擇性輸入多組明文的方式,使用漢明距離模型分別獲取SM3密碼算法的中間值θ0θ1θ2θ3η0η1η2η3的步驟中,
在獲取中間值θ0θ1θ2θ3時,針對每個中間值,進行如下操作:
將明文中部分字固定,其它部分字作為隨機數(shù)輸入,輸入多組明文并進行功耗分析,獲得所述中間值的每一部分,進而得到所述中間值。
可選地,所述通過輸入多組明文的方式,使用漢明距離模型分別獲取SM3密碼算法的中間值θ0θ1θ2θ3η0η1η2η3的步驟中,
在獲取中間值η0η1η2η3時,針對每個中間值,進行如下操作:
將明文中的一個字作為可變字,其它部分字固定,部分字作為隨機數(shù)輸入;
針對所述中間值的每一部分,均執(zhí)行:將所述可變字中的部分比特固定,其它比特作為隨機數(shù)輸入,輸入多組明文并進行功耗分析,獲得所分析的部分;
根據(jù)獲得所述中間值的每一部分,進而得到所述中間值。
可選地,所述方法還包括:
按照得到密鑰Kin的方式,通過選擇性輸入多組明文的方式,使用漢明距離模型獲取SM3密碼算法的中間值,進而得到密鑰Kout;
其中,
本發(fā)明還提供一種針對采用SM3密碼算法的哈希消息認證碼SM3-HMAC的側信道能量分析裝置,包括:
中間值計算模塊,用于針對硬件實現(xiàn)的SM3-HMAC,通過選擇性輸入多組明文的方式,使用漢明距離模型分別獲取SM3密碼算法的中間值θ0θ1θ2θ3η0η1η2η3;
密碼計算模塊,用于根據(jù)所述中間值θ0θ1θ2θ3η0η1η2η3分別計算參數(shù)A0,B0,C0,D0,E0,F0,G0,H0,得到密鑰Kin;
其中,SM3-HMAC根據(jù)如下公式得到:
式中為異或運算,||為拼接運算,H為采用SM3密碼算法的哈希函數(shù),K0為密鑰K進行預處理的結果,m為輸入的明文,ipad和opad為固定值,IV為首次執(zhí)行SM3密碼算法時壓縮函數(shù)的初始狀態(tài)值;Kin為HMAC運算中調用SM3密碼算法時壓縮函數(shù)的初始狀態(tài)A0B0C0D0E0F0G0H0。
可選地,所述中間值計算模塊,進一步用于將每個中間值劃分為多個部分,通過選擇性輸入多組明文的方式,使用漢明距離模型分別獲取所述中間值的每個部分,得到所述中間值。
可選地,所述中間值計算模塊,進一步用于設置每4比特為一組,將每個中間值劃分為8組,通過選擇性輸入多組明文的方式,使用漢明距離模型,通過功耗分析,分別獲取所述中間值的每個部分,得到所述中間值;
其中,所述功耗分析為相關性功耗分析CPA或差分功耗分析DPA。
可選地,所述中間值計算模塊,進一步用于:
在獲取中間值θ0θ1θ2θ3時,針對每個中間值,進行如下操作:將明文中部分字固定,其它部分字作為隨機數(shù)輸入,輸入多組明文并進行功耗分析,獲得所述中間值的每一部分,進而得到所述中間值;
在獲取中間值η0η1η2η3時,針對每個中間值,進行如下操作:將明文中的一個字作為可變字,其它部分字固定,部分字作為隨機數(shù)輸入;針對所述中間值的每一部分,均執(zhí)行:將所述可變字中的部分比特固定,其它比特作為隨機數(shù)輸入,輸入多組明文并進行功耗分析,獲得所分析的部分;根據(jù)獲得所述中間值的每一部分,進而得到所述中間值。。
與現(xiàn)有技術相比,本發(fā)明實施例具有以下優(yōu)點:
(1)可以對純硬件實現(xiàn)的SM3-HMAC的密鑰進行有效分析。現(xiàn)有的分析方案中使用的泄漏模型是漢明重量模型或者是漢明重量模型與漢明距離模型混合使用,而對于硬件實現(xiàn)的算法主要泄漏的信息是漢明距離,漢明重量的泄漏很少,因此漢明重量模型并不適合于硬件實現(xiàn)算法的分析。本發(fā)明實施例提出的分析方法可以分析純硬件實現(xiàn)的SM3-HMAC,分析成功率也較高。
(2)使用兩級選擇明文的方法,使分析中可以使用漢明距離模型。密碼設備在執(zhí)行密碼運算時,側信道方面會有明顯的信息泄漏,不同的實現(xiàn)方式泄漏的信息也不相同,軟件實現(xiàn)的加密運算主要泄漏的是漢明重量,硬件實現(xiàn)的主要泄漏的是漢明距離;為了能夠分析硬件實現(xiàn)的SM3-HMAC,需要使用漢明距離模型,為此本發(fā)明實施例創(chuàng)新性的提出了兩級選擇明文的方法。
(3)通過多次部分CPA分析,降低遍歷空間。本發(fā)明實施例分析中間值時每4bit一組進行分析,進行多次部分CPA分析,可以使分析過程中的遍歷數(shù)由8×232≈343億降低到了8×8×24=1024,大大縮小遍歷空間,有效縮短分析時間。
本發(fā)明的其它特征和優(yōu)點將在隨后的說明書中闡述,并且,部分地從說明書中變得顯而易見,或者通過實施本發(fā)明而了解。本發(fā)明的目的和其他優(yōu)點可通過在說明書、權利要求書以及附圖中所特別指出的結構來實現(xiàn)和獲得。
附圖說明
附圖用來提供對本發(fā)明技術方案的進一步理解,并且構成說明書的一部分,與本申請的實施例一起用于解釋本發(fā)明的技術方案,并不構成對本發(fā)明技術方案的限制。
圖1為HMAC算法示意圖;
圖2為本發(fā)明實施例的針對SM3-HMAC的側信道能量分析方法流程圖;
圖3為本發(fā)明實施例的針對HMAC分析的示意圖;
圖4為本發(fā)明應用示例的分析θ0的流程圖;
圖5為本發(fā)明應用示例的分析η0的流程圖;
圖6為本發(fā)明應用示例的分析θ1的流程圖;
圖7為本發(fā)明應用示例的分析η1的流程圖;
圖8為本發(fā)明應用示例的分析θ2的流程圖;
圖9為本發(fā)明應用示例的分析η2的流程圖;
圖10為本發(fā)明應用示例的分析θ3的流程圖;
圖11為本發(fā)明應用示例的分析η3的流程圖;
圖12為本發(fā)明實施例的針對SM3-HMAC的側信道能量分析裝置示意圖。
具體實施方式
為使本發(fā)明的目的、技術方案和優(yōu)點更加清楚明白,下文中將結合附圖對本發(fā)明的實施例進行詳細說明。需要說明的是,在不沖突的情況下,本申請中的實施例及實施例中的特征可以相互任意組合。
在附圖的流程圖示出的步驟可以在諸如一組計算機可執(zhí)行指令的計算機系統(tǒng)中執(zhí)行。并且,雖然在流程圖中示出了邏輯順序,但是在某些情況下,可以以不同于此處的順序執(zhí)行所示出或描述的步驟。
現(xiàn)有的針對SM3-HMAC的側信道分析方案主要有以下幾個缺點:
(1)現(xiàn)在的分析方案只適合于分析軟件實現(xiàn)的SM3-HMAC算法,不能分析硬件實現(xiàn)的算法。現(xiàn)有的分析方案中使用的泄漏模型是漢明重量模型或者是漢明重量模型與漢明距離模型混合使用,而對于硬件實現(xiàn)的算法主要泄漏的信息是漢明距離,漢明重量的泄漏很少,因此漢明重量模型并不適合于硬件實現(xiàn)算法的分析。在本發(fā)明實施例中,為了能夠分析硬件實現(xiàn)的SM3-HMAC,在分析過程中使用了漢明距離模型。
(2)現(xiàn)有的分析方案分析時遍歷空間過大。現(xiàn)有的分析方案分析時遍歷的空間高達8×232≈343億,需要分析8個中間值或者直接分析密鑰中的一個字,每一個都需要分別將232個不同的值帶入到算法中,分別計算中間值,再與功耗曲線上的每一點計算相關系數(shù)。由于遍歷空間較大,使計算需要大量的內存空間,同時也需要消耗大量的時間。在本發(fā)明實施例中,通過將整體CPA(或DPA)轉換為部分CPA(或DPA),縮小遍歷空間,減少分析過程中的內存消耗,縮短分析計算時間。
如圖2所示,本發(fā)明實施例的針對SM3-HMAC的側信道能量分析方法包括:
步驟101,針對硬件實現(xiàn)的SM3-HMAC,通過選擇性輸入多組明文的方式,使用漢明距離模型分別獲取SM3密碼算法的中間值θ0θ1θ2θ3η0η1η2η3;
步驟102,根據(jù)所述中間值θ0θ1θ2θ3η0η1η2η3分別計算參數(shù)A0,B0,C0,D0,E0,F0,G0,H0,得到密鑰Kin;
其中,SM3-HMAC根據(jù)如下公式得到:
式中為異或運算,||為拼接運算,H為采用SM3密碼算法的哈希函數(shù),K0為密鑰K進行預處理的結果,m為輸入的明文,ipad和opad為固定值,IV為首次執(zhí)行SM3密碼算法時壓縮函數(shù)的初始狀態(tài)值;Kin為HMAC運算中調用SM3密碼算法時壓縮函數(shù)的初始狀態(tài)A0B0C0D0E0F0G0H0。
在本發(fā)明實施例中,在分析過程中使用了漢明距離模型,可以對純硬件實現(xiàn)的SM3-HMAC的密鑰進行有效分析。
其中,步驟101中,可以將每個中間值劃分為多個部分,通過選擇性輸入多組明文的方式,使用漢明距離模型分別獲取所述中間值的每個部分,得到所述中間值。
可選地,步驟101中,每4比特(bit)為一組,將每個中間值劃分為8組,通過選擇性輸入多組明文的方式,使用漢明距離模型,通過功耗分析,分別獲取所述中間值的每個部分,得到所述中間值;
其中,所述功耗分析為CPA或DPA。
可選地,步驟101中,在獲取中間值θ0θ1θ2θ3時,針對每個中間值,進行如下操作:
將明文中部分字固定,其它部分字作為隨機數(shù)輸入,輸入多組明文并進行功耗分析,獲得所述中間值的每一部分,進而得到所述中間值。
可選地,步驟101中,在獲取中間值η0η1η2η3時,針對每個中間值,進行如下操作:
將明文中的一個字作為可變字,其它部分字固定,部分字作為隨機數(shù)輸入;
針對所述中間值的每一部分,均執(zhí)行:將所述可變字中的部分比特固定,其它比特作為隨機數(shù)輸入,輸入多組明文并進行功耗分析,獲得所分析的部分;
根據(jù)獲得所述中間值的每一部分,進而得到所述中間值。
在步驟101中,可采用兩級選擇明文的方式,結合功耗分析,獲得中間值的部分比特。其中,兩級選擇明文的方式是指:在明文中的部分字固定,部分字作為隨機數(shù)輸入的基礎上,另外的字中部分比特固定,部分比特作為隨機數(shù)輸入。在本實施例中,獲取中間值η0η1η2η3時,采取兩級選擇明文的方式。
通過第一級選擇明文,使之分別分析θ0θ1θ2θ3η0η1η2η3八個中間值的32bit是可行的,但是需要一起分析32bit,分析復雜度較高。為了降低分析復雜度,進行多次部分功耗分析,每4bit一組,分析一個中間值分成8次部分CPA進行。但是對于η0η1η2η3由于算法設計時引入了一個非線性的變換P0(),使直接使用8次CPA進行分析不可行;為了解決這個問題,再進行一次選擇明文,每次選擇明文用來分析η0η1η2η3的4bit。
所述方法還可包括:按照得到密鑰Kin的方式,通過輸入多組明文的方式,使用漢明距離模型獲取SM3密碼算法的中間值,進而得到密鑰Kout;
其中,
在本發(fā)明實施例中,可以通過兩級選擇明文,每次選擇明文后進行部分功耗分析,獲得中間值的部分bit,多次選擇明文和部分功耗分析后可以得到八個中間值的全部bit,通過公式計算出使用的密鑰。這樣可以降低遍歷空間,有效縮短分析時間。
如圖3所示,分析的目標為Kin和Kout,分析Kin時的分析對象為圖中上邊標出來的陰影部分的哈希函數(shù),分析Kout時的分析對象為圖中下邊標出來的陰影部分的哈希函數(shù)。兩者分析方式相同,下述分析方法的描述以Kin為例,Kout完全類似。
通過改變目標哈希函數(shù)(SM3)的輸入(圖3中的m1),采集不同的功耗曲線,利用功耗曲線進行分析,得到目標哈希函數(shù)的運算中間值,然后利用中間值計算出密鑰Kin。
1.令SM3的輸入明文m1=W0,W1,W2,W3,W4,W5,W6,W7為隨機值,采集N組不同明文對應的功耗曲線(也稱為能量跡)。
SM3算法的壓縮函數(shù)的計算過程如下:
1:For j=0 To 63
2:SS1←((A<<<12)+E+(Tj<<<(j mod 32)))<<<7
3:
4:TT1←FFj(A,B,C)+D+SS2+W′j
5:TT2←GGj(E,F,G)+H+SS1+Wj
6:D←C
7:C←B<<<9
8:B←A
9:A←TT1
10:H←G
11:G←F<<<19
12:F←E
13:E←P0(TT2)
14:EndFor
第0輪運算:對于第4步,TT10=FF0(A0,B0,C0)+D0+SS20+W′0,必須在第0輪計算,且為4項的和。記θ0=FF0(A0,B0,C0)+D0+SS20,則TT10=θ0+W′0,A1=TT10。同時假設A0和θ0,使用漢明距離模型
HD(A0,A1)=HD(A0,TT10)=HD(A0,θ0+W′0)
式中W0′為已知可變值,A0和θ0為假設值,HD表示漢明距離。使用CPA分析可以同時得到A0和θ0。但如果同時假設A0和θ0的32bit則遍歷空間為264,在現(xiàn)有計算條件下,耗時太長,空間消耗太大,本發(fā)明實施例中使用多次部分CPA來降低遍歷空間,具體如下:
令SM3的輸入明文m=W0,W1,W2,W3,W4,W5,W6,W7為隨機值,采集N組不同明文對應的功耗曲線。N組不同的明文記為其中Wij表示第i組明文的第j個“字”(字,即Word,一個字=4Byte=32bit),得到的N組功耗曲線用矩陣表示為其中T表示選擇的運算部分的持續(xù)時長,pit表示第i組明文對應的功耗曲線的t時刻的功耗值,qt表示不同明文在t時刻的功耗組成的列向量。
1.1分析θ0的0~3bit
假設和使用漢明距離模型
用CPA分析得到具體分析如下:
(1)計算中間值矩陣
分別將的24=16種不同的值代入SM3-HMAC的算法流程,計算出不同明文在第0輪迭代時的結果得到中間結果矩陣其中
表示第j個的假設值代入第i條功耗曲線對應的明文計算得到的中間值。
(2)使用漢明距離模型將中間值矩陣轉成功耗矩陣,由于需要使用到而該值為未知值,對于其24=16種不同的值分別代入漢明距離模型,可以得到一個共有16*16=256列的仿真功耗矩陣
其中的第一個下標i表示第i組明文,第二個下標j表示的假設值為j,上標k表示的假設值為k。此步得到一個N*256的功耗矩陣,矩陣的列數(shù)由j,k決定。
(3)計算相關系數(shù)
計算仿真功耗矩陣H與實測功耗矩陣P之間的相關系數(shù),得到相關系數(shù)矩陣
C的行數(shù)與H的列數(shù)相等,C的列數(shù)與P的列數(shù)相等,表示仿真功耗矩陣H的第l列于與實測功耗P的第t列之間的相關系數(shù),
其中
(4)選取候選值
找出相關系數(shù)矩陣C的最大元素則仿真功耗矩陣H的m列對應的第二個下標為的正確值,m列對應的上標為的正確值。
1.2分析θ0的4~7bit
與分析0~3bit類似,但是要考慮到0~3bit運算時加法的進位會對4~7bit的運算有影響,因此4~7bit分析過程為,假設使用漢明距離模型
式中表示普通的帶有進位的加,+表示模24的模加,用CPA分析得到
1.3分析θ0的8~31bit
與1.2類似,依次分析θ0的4bit,每次分析的假設值和使用的漢明距離模型分別如下:
通過該步的分析,可以得到的全部32bit。如圖4所示,為本發(fā)明應用示例的分析θ0的流程圖。
2.分析η0
對于第5步,TT2←GGj(E,F,G)+H+SS1+Wj,必須在第0輪計算,且為4項的和。記η0=GG0(E0,F0,G0)+H0+SS10,則TT20=η0+W0,E1=P0(TT20)。同時假設E0和η0,使用漢明距離模型
HD(E0,E1)=HD(E0,P0(TT20))=HD(E0,P0(η0+W0))
式中W0為已知可變值,E0和η0為假設值,HD表示漢明距離。使用CPA分析可以同時得到E0和η0。但如果同時假設E0和η0的32bit則遍歷空間為264,在現(xiàn)有計算條件下,耗時太長,空間消耗太大,考慮每4bit一組,進行部分CPA,降低分析復雜度。如圖5所示,為本發(fā)明應用示例的分析η0的流程圖。
2.1分析η0的0~3bit
因此,可見分析低4bit時不能只對低4bit進行假設,因為P0(X)函數(shù)中引入了移位,bit15~18,bit23~26也有參與。
為了解決這個問題,我們再進行一次選擇明文,令隨機,則η0+W0只有bit0~3會產(chǎn)生進位,而進位一直到bit15的可能性極小,我們忽略這種可能,則上式可以變?yōu)椋?/p>
其中
因此,令隨機,W1,W2,W3,W4,W5,W6,W7隨機,采集N組不同明文的功耗曲線,同時假設和可以利用上式使用CPA分析得到具體分析如下:
(1)采集功耗曲線
令隨機,W1,W2,W3,W4,W5,W6,W7隨機,采集N組不同明文的功耗曲線。N組不同的明文記為其中Wij表示第i組明文的第j個“字”,得到的N組功耗曲線用矩陣表示為
其中T表示選擇的運算部分的持續(xù)時長,pit表示第i組明文對應的功耗曲線的t時刻的功耗值,qt表示不同明文在t時刻的功耗組成的列向量。
(2)計算中間值矩陣
分別將的24=16種不同的值代入SM3-HMAC的算法流程,計算出不同明文在第0輪迭代時的結果得到中間結果矩陣其中
η0=GG0(E0,F0,G0)+H0+SS10
表示第j個的假設值代入第i條功耗曲線對應的明文計算得到的中間值。
(3)使用漢明距離模型將中間值矩陣轉成功耗矩陣,
由于需要使用到而該值為未知值,對于其24=16種不同的值分別代入漢明距離模型,可以得到一個共有16*16=256列的仿真功耗矩陣
其中的第一個下標i表示第i組明文,第二個下標j表示的假設值為j,上標k表示的假設值為k。此步得到一個N*256的功耗矩陣,矩陣的列數(shù)由j,k決定。
(4)計算相關系數(shù)
計算仿真功耗矩陣H與實測功耗矩陣P之間的相關系數(shù),得到相關系數(shù)矩陣
C的行數(shù)與H的列數(shù)相等,C的列數(shù)與P的列數(shù)相等,表示仿真功耗矩陣H的第l列于與實測功耗P的第t列之間的相關系數(shù),
其中
(5)選取候選值
找出相關系數(shù)矩陣C的最大元素則仿真功耗矩陣H的m列對應的第二個下標為的正確值,m列對應的上標為的正確值。
2.2分析η0的4~7bit
令W1,W2,W3,W4,W5,W6,W7,為隨機值,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到其中:
與2.1類似,只需要對以下幾步稍作修改即可:
2.1(1)中采集功耗曲線時,需要令W1,W2,W3,W4,W5,W6,W7,為隨機值,采集N組不同明文的功耗曲線;
2.1(2)中計算中間值矩陣時
2.1(3)中使用漢明距離模型
其他步驟與2.1相同。
2.3分析η0的8~11bit
令W1,W2,W3,W4,W5,W6,W7,為隨機值,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
2.4分析η0的12~15bit
令W1,W2,W3,W4,W5,W6,W7,為隨機值,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
2.5分析η0的16~19bit
令W1,W2,W3,W4,W5,W6,W7,為隨機值,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
2.6分析η0的20~23bit
令W1,W2,W3,W4,W5,W6,W7,為隨機值,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
2.7分析η0的24~27bit
令W1,W2,W3,W4,W5,W6,W7,為隨機值,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
2.8分析η0的28~31bit
令W1,W2,W3,W4,W5,W6,W7,為隨機值,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
3.分析θ1
如圖6所示,為本發(fā)明應用示例的分析θ1的流程圖。令W1,W2,W3,W5,W6,W7為隨機數(shù),W0=W4=0,采集N組不同明文的功耗曲線,用來分析θ1。每4bit一組,分別進行CPA分析,獲得θ1的部分bit。具體步驟如下表所示。
4.分析η1
圖7為本發(fā)明應用示例的分析η1的流程圖。
4.1分析η1的0~3bit
令W2,W3,W5,W6,W7,為隨機值,W0=W4=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
4.2分析η1的4~7bit
令W2,W3,W5,W6,W7,W1[7:4]為隨機值,W0=W4=0,W1[31:8]=W1[3:0]=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
4.3分析η1的8~11bit
令W2,W3,W5,W6,W7,W1[11:8]為隨機值,W0=W4=0,W1[31:12]=W1[7:0]=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
4.4分析η1的12~15bit
令W2,W3,W5,W6,W7,W1[15:12]為隨機值,W0=W4=0,W1[31:16]=W1[11:0]=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
4.5分析η1的16~19bit
令W2,W3,W5,W6,W7,W1[19:16]為隨機值,W0=W4=0,W1[31:20]=W1[15:0]=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
4.6分析η1的20~23bit
令W2,W3,W5,W6,W7,W1[23:20]為隨機值,W0=W4=0,W1[31:24]=W1[19:0]=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
4.7分析η1的24~27bit
令W2,W3,W5,W6,W7,W1[27:24]為隨機值,W0=W4=0,W1[31:28]=W1[23:0]=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
4.8分析η1的28~31bit
令W2,W3,W5,W6,W7,W1[31:28]為隨機值,W0=W4=0,W1[27:0]=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
5.分析θ2
圖8為本發(fā)明應用示例的分析θ2的流程圖。令W2,W3,W6,W7為隨機數(shù),W0=W4=W1=W5=0,采集N組不同明文的功耗曲線,用來分析θ2。每4bit一組,分別進行部分CPA分析,獲得θ2的部分bit。具體步驟如下表所示。
6.分析η2
圖9為本發(fā)明應用示例的分析η2的流程圖。
6.1分析η2的0~3bit
令W3,W6,W7,為隨機值,W0=W4=W1=W5=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
6.2分析η2的4~7bit
令W3,W6,W7,為隨機值,W0=W4=W1=W5=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
6.3分析η2的8~11bit
令W3,W6,W7,為隨機值,W0=W4=W1=W5=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
6.4分析η2的12~15bit
令W3,W6,W7,為隨機值,W0=W4=W1=W5=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
6.5分析η2的16~19bit
令W3,W6,W7,為隨機值,W0=W4=W1=W5=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
6.6分析η2的20~23bit
令W3,W6,W7,為隨機值,W0=W4=W1=W5=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
6.7分析η2的24~27bit
令W3,W6,W7,為隨機值,W0=W4=W1=W5=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
6.8分析η2的28~31bit
令W3,W6,W7,為隨機值,W0=W4=W1=W5=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
7.分析θ3
圖10為本發(fā)明應用示例的分析θ3的流程圖。令W3,W7為隨機數(shù),W0=W4=W1=W5=W2=W6=0,采集N組不同明文的功耗曲線,用來分析θ3。每4bit一組,分別進行部分CPA分析,獲得θ3的部分bit。具體步驟如下表所示。
8.分析η3
圖11為本發(fā)明應用示例的分析η3的流程圖。
8.1分析η3的0~3bit
令W7,為隨機值,W0=W4=W1=W5=W2=W6=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
8.2分析η3的4~7bit
令W7,為隨機值,W0=W4=W1=W5=W2=W6=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
8.3分析η3的8~11bit
令W7,為隨機值,W0=W4=W1=W5=W2=W6=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
8.4分析η3的12~15bit
令W7,為隨機值,W0=W4=W1=W5=W2=W6=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
8.5分析η3的16~19bit
令W7,為隨機值,W0=W4=W1=W5=W2=W6=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
8.6分析η3的20~23bit
令W7,為隨機值,W0=W4=W1=W5=W2=W6=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
8.7分析η3的24~27bit
令W7,為隨機值,W0=W4=W1=W5=W2=W6=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
8.8分析η3的28~31bit
令W7,為隨機值,W0=W4=W1=W5=W2=W6=0,采集N組不同明文的功耗曲線,同時假設使用漢明距離模型
使用CPA分析得到
上述分析中間數(shù)θ0,η0,θ1,η1,θ2,η2,θ3,η3的順序可以變換,對結果沒有影響。
9.使用中間值計算密鑰
通過上述8個步驟的分析可以得到θ0,η0,θ1,η1,θ2,η2,θ3,η3,本步通過一系列的計算得到A0,B0…H0。
在第3輪迭代中有,A3=θ2,B3=A2=θ1,C3=(B2<<<9)=(θ0<<<9),D3=C2=(A0<<<9),因此
式中只有A0為未知值,可以直接計算得到A0。同理有
式中只有E0為未知值,可以直接計算得到E0。
在第2輪迭代中有,
式中只有B0為未知值,可以直接計算得到B0。同理有
式中只有F0為未知值,可以直接計算得到F0。
在第1輪迭代有,
式中只有C0為未知值,可以直接計算得到C0。同理有
式中只有G0為未知值,可以直接計算得到G0。
在第0輪迭代中有,
式中只有D0為未知值,可以直接計算得到D0。同理有
式中只有H0為未知值,可以直接計算得到H0。
至此,我們得到了A0,B0…H0的全部值,即得到了Kin。
通過改變輸入的明文m1,可得到不同的hn,則hn為已知可變,Kout為hn進行壓縮運算時的初始狀態(tài),為未知固定,不斷改變m1的輸入值,進而改變的hn值,一層一層地分析出,Kout具體的分析步驟與Kin一致。
恢復出密鑰Kin和Kout,從而成功分析出SM3-HMAC的敏感信息。通過密鑰Kin和Kout,分析者可輸出任意消息的消息鑒別碼。
需要說明的是,上述實施例采用了CPA方式進行分析,采用DPA方式同樣適合本發(fā)明實施例。
另外,上述實施例采用每4bit為一組,將每個中間值劃分為8組的方式,在其它實施例中,也可以采用其它劃分方式。
如圖12所示,本發(fā)明實施例的針對SM3-HMAC的側信道能量分析裝置包括:
中間值計算模塊21,用于針對硬件實現(xiàn)的SM3-HMAC,通過選擇性輸入多組明文的方式,使用漢明距離模型分別獲取SM3密碼算法的中間值θ0θ1θ2θ3η0η1η2η3;
密碼計算模塊22,用于根據(jù)所述中間值θ0θ1θ2θ3η0η1η2η3分別計算參數(shù)A0,B0,C0,D0,E0,F0,G0,H0,得到密鑰Kin;
其中,SM3-HMAC根據(jù)如下公式得到:
式中為異或運算,||為拼接運算,H為采用SM3密碼算法的哈希函數(shù),K0為密鑰K進行預處理的結果,m為輸入的明文,ipad和opad為固定值,IV為首次執(zhí)行SM3密碼算法時壓縮函數(shù)的初始狀態(tài)值;Kin為HMAC運算中調用SM3密碼算法時壓縮函數(shù)的初始狀態(tài)A0B0C0D0E0F0G0H0。
可選地,所述中間值計算模塊21,進一步用于將每個中間值劃分為多個部分,通過選擇性輸入多組明文的方式,使用漢明距離模型分別獲取所述中間值的每個部分,得到所述中間值。
可選地,所述中間值計算模塊21,進一步用于設置每4比特為一組,將每個中間值劃分為8組,通過選擇性輸入多組明文的方式,使用漢明距離模型,通過功耗分析,分別獲取所述中間值的每個部分,得到所述中間值;
其中,所述功耗分析為相關性功耗分析CPA或差分功耗分析DPA。
可選地,所述中間值計算模塊21,進一步用于:
在獲取中間值θ0θ1θ2θ3時,針對每個中間值,進行如下操作:將明文中部分字固定,其它部分字作為隨機數(shù)輸入,輸入多組明文并進行功耗分析,獲得所述中間值的每一部分,進而得到所述中間值;
在獲取中間值η0η1η2η3時,針對每個中間值,進行如下操作:將明文中的一個字作為可變字,其它部分字固定,部分字作為隨機數(shù)輸入;針對所述中間值的每一部分,均執(zhí)行:將所述可變字中的部分比特固定,其它比特作為隨機數(shù)輸入,輸入多組明文并進行功耗分析,獲得所分析的部分;根據(jù)獲得所述中間值的每一部分,進而得到所述中間值。
顯然,本領域的技術人員應該明白,上述的本發(fā)明實施例的模塊或步驟可以用通用的計算裝置來實現(xiàn),它們可以集中在單個的計算裝置上,或者分布在多個計算裝置所組成的網(wǎng)絡上,可選地,它們可以用計算裝置可執(zhí)行的程序代碼來實現(xiàn),從而,可以將它們存儲在存儲裝置中由計算裝置來執(zhí)行,并且在某些情況下,可以以不同于此處的順序執(zhí)行所示出或描述的步驟,或者將它們分別制作成集成電路模塊,或者將它們中的多個模塊或步驟制作成單個集成電路模塊來實現(xiàn)。這樣,本發(fā)明實施例不限制于任何特定的硬件和軟件結合。
雖然本發(fā)明所揭露的實施方式如上,但所述的內容僅為便于理解本發(fā)明而采用的實施方式,并非用以限定本發(fā)明。任何本發(fā)明所屬領域內的技術人員,在不脫離本發(fā)明所揭露的精神和范圍的前提下,可以在實施的形式及細節(jié)上進行任何的修改與變化,但本發(fā)明的專利保護范圍,仍須以所附的權利要求書所界定的范圍為準。
- 還沒有人留言評論。精彩留言會獲得點贊!