一種數據匯聚系統和方法與流程
本發明涉及數據處理領域,更具體地,涉及一種數據匯聚系統和方法。
背景技術:
近些年來,我國的城鎮化建設取得了卓越的成就。但之前的城鎮化進程,在取得巨大成就的同時,也積累下來了很多不符合科學發展觀要求、亟待處理和破解的突出問題。為解決城市發展難題,實現城市可持續發展,建設智慧城市已成為當今世界城市發展不可逆轉的歷史潮流。
智慧城市指的是運用信息和通信技術手段感測、分析、整合城市運行核心系統的各項關鍵信息,從而對包括民生、環保、公共安全、城市服務、工商業活動在內的各種需求做出智能響應。其實質是利用先進的信息技術,實現城市智慧式管理和運行,進而為城市中的人創造更美好的生活,促進城市的和諧、可持續成長。
信息的來源非常豐富且數據類型多樣,存儲和分析挖掘的數據量龐大,在對海量數據進行分析、挖掘,為城市的智慧化、精細化管理提供有效的決策依據之前,需要先將海量數據進行匯聚。
目前現有技術中對于數據的匯聚方法一般有兩種方式,具體包括:
一是運用開源的ETL工具進行數據的匯總。ETL(Extract-Transform-Load),用來描述將數據從來源端經過抽取(extract)、轉換(transform)、加載(load)至目的端的過程。ETL是構建數據倉庫的重要一環,用戶從數據源抽取出所需的數據,經過數據清洗,最終按照預先定義好的數據倉庫模型,將數據加載到數據倉庫中去。雖然ETL基本上能夠解決數據匯聚的問題,但是同時也存在著以下兩個個方面的問題:
1、工具單一:有些ETL工具只能解決部分問題,但是有些數據匯聚的工作需要多個工具的合作,而且這些ETL工具往往規模都比較大,對于一些規模較小的匯聚工作,往往存在著資源浪費的問題。
2、專業性要求高,使用難度大:大多數ETL工具的使用都需要操作人員有一定的編程基礎,對于大多數運維人員和運維企業來說,存在一定的使用難度,同時也增加了使用的成本。
二是通過相關人員編寫相關的腳本,手動進行數據匯聚。此方式需要大量人工干預,使用方式不夠靈活。
技術實現要素:
本發明為克服上述現有技術所述的至少一種缺陷(不足),提供一種使用方式簡單且靈活方便的數據匯聚系統。
本發明還提供一種使用方式簡單且靈活方便的數據匯聚方法。
為解決上述技術問題,本發明的技術方案如下:
一種數據匯聚系統,包括用于從子系統中獲取數據的運行中心和用于生成和配置各個子系統的配置文件的客戶端;
運行中心中設有中心數據庫和用于根據配置文件和各個子系統進行通信以及接收、處理各個子系統的數據并將數據寫入中心數據庫的服務端;
運行中心與各個子系統之間建立統一的基于RESTful通信。
本發明的系統在運行中心與子系統之間建立統一的基于RESTful通信,實現了服務端與各個子系統之間的通信以及各個組件之間的通信,而且運用統一協議,使得系統可以自由地選擇和更換數據的處理方式,使用者無需具備專業的編程知識即可使用系統,整個系統進行數據匯聚的方式變得簡單靈活而且方便 。
上述方案中,服務端中設有用于等待各個子系統推送數據的等待推送進程、用于主動向子系統請求數據的主動請求進程和用于進程調度的調度系統。系統提供了子系統主動推送數據以及主動向子系統請求數據兩種策略,給予了調度系統一定的自由度,使得數據的匯聚能夠分時分段處理,避免同時處理大量數據,從而可以合理分配網絡和技術資源。
上述方案中,服務端中還設有driver層。在建立統一的基于RESTful通信的基礎上,系統抽象出driver層,底層可以根據實際需要使用不同的插件,實現底層實現和上層運用的隔離,系統搭建完成后可以根據具體的應用需求擴展或者更改相應的底層處理方式,增加了系統的靈活性。
一種數據匯聚方法,包括:
運行中心與各個子系統之間預先建立基于RESTful的通信;
客戶端利用數據庫表生成各個子系統的配置文件;
運行中心中的服務端根據配置文件按照調度策略獲取各個子系統的數據來更新運行中心中的中心數據庫。
本發明的方法在運行中心與子系統之間預先建立統一的基于RESTful通信,實現了服務端與各個子系統之間的通信以及各個組件之間的通信,而且運用統一協議,使得服務端可以自由選擇調度策略來獲取子系統的數據,使得數據的匯聚具備一定的靈活性,而且使用者無需具備專業的編程知識即可使用該方法。本發明的數據匯聚方法方式變得簡單靈活而且方便 。
上述方案中,所述數據庫表是從運行中心中生成并導出的;每個子系統對應一個或多個數據庫表。
上述方案中,客戶端生成配置文件時利用字符串匹配的方式從中心數據庫中尋找和獲取需要的數據,生成配置文件中的配置項。本發明的方法使用字符串匹配技術來根據中心數據庫的相關表項和數據結構生成具體的配置文件,使用人員只需要根據自身需要填入一些基本的配置信息即可完成基本的配置工作,減少使用人員工作量的同時還降低了對使用人員的專業要求。
上述方案中,所述調度策略包括子系統主動推送策略;運行中心中的服務端根據配置文件按照子系統主動推送策略獲取各個子系統的數據來更新運行中心中的中心數據庫的具體步驟包括:
運行中心中的服務端啟動等待進程;
服務端接收各個子系統有實時數據需要上送時根據服務端提供的端口向服務端推送的數據;
服務端解析推送的目的url,并搜索是否有與子系統相關的配置文件,配置文件中是否有相關的配置項,若均為是則將接收到的數據更新中心數據庫。
子系統的類型各式各樣,數據的產生都不盡相同,運行中心有時無法獲知子系統一些的實時數據何時產生,因此設計子系統主動推送策略來讓子系統將實時產生的數據推送到服務端,服務端負責接收更新數據即可,使得運行中心可以實現實時數據的匯聚。
上述方案中,服務端接收子系統的數據后還判斷其自身是否處于主動推送模式,若是則將接收到的數據更新中心數據庫。
上述方案中,所述調度策略包括定時策略;
運行中心中的服務端根據配置文件按照調度策略獲取各個子系統的數據來更新運行中心中的中心數據庫的具體步驟包括:
服務端啟動,掃描每個配置文件,讀取和保存相關的配置文件;
服務端根據配置文件添加請求數據的定時任務;
定時任務的出發點達到,服務端根據配置文件內容中的url,向子系統請求數據;
服務端接收子系統返回的數據更新數據庫。
本發明的方法設置定時策略來對子系統的數據進行匯聚,使得子系統數據的匯聚可以分時分段處理,避免運行中心同時處理大量數據,使得運行中心可以合理分配網絡和技術資源。
上述方案中,數據庫更新的方式包括增量更新方式和全量更新方式,增量更新方式指的是服務端將接收到的數據添加到中心數據庫中,全量更新方式指的是服務端將接收到的子系統數據替換中心數據庫中子系統對應的數據。增量更新方式和全量更新方式可以根據數據庫實際的需求確定,對于需要長時間保留的數據則可以采用增量更新方式進行數據更新,對于不需要保留的數據可以采用全量更新方式來更新數據庫,既可以數據的實際需求來執行更新方式,還可以根據實際需求減少中心數據庫的存儲壓力,提高中心數據庫的利用率。
與現有技術相比,本發明技術方案的有益效果是:
本發明由于運用了統一協議,可以自由得更換數據的處理方式,也可以根據具體的項目需求擴展或者更改相關的底層處理方式,使得本發明具備靈活多變的處理方式。
本發明設計了靈活多變的調度策略,使得數據的匯聚能夠分時分段處理,避免了同時處理大量數據,合理分配網絡和技術資源。
本發明設計了靈活的數據更新方式,能夠合理利用數據庫,提高數據庫的利用率。
本發明還提供了靈活而且方便的使用方式,利用字符串匹配技術,根據中心數據庫的相關表項和數據結構生成具體的配置文件,使用人員只需要根據自身需要,填入一些基本的配置信息,就完成基本的配置工作。
附圖說明
圖1為本發明一種數據匯聚系統的架構圖。
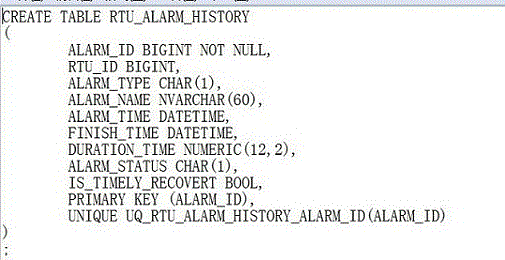
圖2為本發明中導出的數據庫表的示例圖。
圖3為本發明中生成的配置文件的配置示例圖。
圖4為本發明一種數據匯聚方法的流程圖。
具體實施方式
附圖僅用于示例性說明,不能理解為對本專利的限制;
為了更好說明本實施例,附圖某些部件會有省略、放大或縮小,并不代表實際產品的尺寸;
對于本領域技術人員來說,附圖中某些公知結構及其說明可能省略是可以理解的。
在本發明的描述中,需要理解的是,此外,術語“第一”、“第二”僅用于描述目的,而不能理解為指示或暗示相對重要性或隱含所指示的技術特征的數量。由此,限定的“第一”、“第二”的特征可以明示或隱含地包括一個或者更多個該特征。在本發明的描述中,除非另有說明,“多個”的含義是兩個或兩個以上。
在本發明的描述中,需要說明的是,除非另有明確的規定和限定,術語“安裝”、“連接”應做廣義理解,例如,可以是固定連接,也可以是可拆卸連接,或一體地連接;可以是機械連接,也可以是電連接;可以是直接相連,也可以是通過中間媒介間接連接,可以說兩個元件內部的連通。對于本領域的普通技術人員而言,可以具體情況理解上述術語在本發明的具體含義。
下面結合附圖和實施例對本發明的技術方案做進一步的說明。
實施例1
如圖1所示,為本發明一種數據匯聚系統具體實施例的架構圖。參見圖1,本具體實施例一種數據匯聚系統具體包括用于從子系統中獲取數據的運行中心和用于生成和配置各個子系統的配置文件的客戶端101;
運行中心中設有中心數據庫和用于根據配置文件和各個子系統進行通信以及接收、處理各個子系統的數據并將數據寫入中心數據庫的服務端102;
運行中心與各個子系統之間建立統一的基于RESTful通信。
其中,各個子系統是用于采集和處理數據的系統,如各個智慧城市中的用于采集和處理數據的系統。
客戶端101生成的配置文件提供給服務端使用,其可以設置在運行中心中,其所利用的數據庫表是從運行中心中生成并導出的,每個子系統對應一個或多個數據庫表,每個子系統在數據中有一張或多張數據庫表,數據庫表通過表的前綴來區分不同的子系統。如圖2所示,為導出的數據庫表的一個實例。
客戶端101生成配置文件時根據命令自動利用字符串匹配的方式從中心數據庫中尋找和獲取需要的數據,生成配置文件中的配置項,配置項可以為表名稱、屬性名稱、是否為主鍵等。如圖3所示,為客戶端生成的配置文件的一個實例,客戶端101生成配置文件后,使用人員只需根據自身需要填入一些基本的配置信息后就可以完成基本的配置工作。基本的配置信息包括但不限于調度disaptch、時間time、類型type和url,如圖3所示。
運行中心用于對數據進行匯聚,服務端102是運行在運行中心的,其主要的功能是根據配置文件和各個子系統進行通信(包括請求數據和接收數據)、處理接收的數據將其寫入到運行中心的中心數據庫中。服務端102中的配置文件統一存儲在子系統配置文件109中。
如圖1所示,服務端101中設有用于等待各個子系統推送數據的等待推送進程103、用于主動向子系統請求數據的主動請求進程104和用于進程調度的調度系統104。
等待推送進程103調用時具體的工作模式是:
服務端102啟動等待推送進程103;
各個子系統有實時數據需要上送時,根據服務端102提供的端口向服務端102推送的數據;
服務端102接收子系統推送的數據,然后解析推送的目的url,并搜索是否有與子系統相關的配置文件,配置文件中是否有相關的配置項,自身是否處于主動推送模式,若均為是則將接收到的數據更新中心數據庫。其中主動推送模式的判斷過程主要是服務端查看相應的配置來判斷配置是否為主動推送模式,如果是對數據進行處理。
主動請求進程104被調用時的具體工作模式是:
服務端102啟動,掃描每個配置文件,讀取和保存相關的配置文件;
服務端102根據配置文件將主動請求進程104加入到不同的定時任務隊列中;
達到某個定時任務的觸發點服務端102開始執行相關任務;
服務端102根據讀取的配置文件內容中的url,向子系統請求數據;
服務端102接收子系統返回的數據更新數據庫。
其中,服務端102啟動并掃描讀取配置文件后,還會讀取上次成功完成該主動請求進程104對應任務的時間戳,執行完時間戳對應時間之后的失敗任務并及時更新數據。
其中,服務端102更新數據庫的方式包括增量更新方式和全量更新方式,增量更新方式指的是服務端102將接收到的數據添加到中心數據庫中,全量更新方式指的是服務端102將接收到的子系統數據替換中心數據庫中子系統對應的數據。增量更新方式和全量更新方式可以根據數據庫實際的需求確定,對于需要長時間保留的數據則可以采用增量更新方式進行數據更新,對于不需要保留的數據可以采用全量更新方式來更新數據庫,既可以數據的實際需求來執行更新方式,還可以根據實際需求減少中心數據庫的存儲壓力,提高中心數據庫的利用率。
在具體實施過程中,運行中心與各個子系統之間建立統一的基于RESTful通信的具體操作過程為:編寫相關的協議說明文檔;運行中心按照該協議的格式向子系統傳送請求,各個子系統按照要求回復相關內容。
在建立統一的基于RESTful通信的基礎上,服務端102中抽象出driver層105。系統抽象出driver層105,底層可以根據實際需要使用不同的插件,如圖1所示,如使用開源ETL工具106,設置其他擴展插件107,還可以根據中心數據庫的需要內置全量增量導入系統108。driver層的設置實現底層實現和上層運用的隔離,系統搭建完成后可以根據具體的應用需求擴展或者更改相應的底層處理方式,增加了系統的靈活性。
實施例2
本發明在實施例1的基礎上,還提供一種數據匯聚方法,所述數據匯聚方法可以基于實施例1的數據匯聚系統實現。參見圖1,本具體實施例的數據匯聚方法的具體步驟包括:
S201.運行中心與各個子系統之間預先建立基于RESTful的通信;此步驟的目的在于建議統一的協議,實現服務端與各個子系統之間的通信以及各個組件之間的通信,基于該統一的協議,可以對數據處理的接口進行抽象設置driver層,使得底層可以根據實際需要使用不同的插件,以后可以根據具體的項目需求擴展或更改相關的底層處理方式。建立基于RESTful通信的具體實現方式是:
編寫相關的協議說明文檔;
運行中心按照該協議的格式向子系統傳送請求,各個子系統按照要求回復相關內容。
S202.客戶端利用數據庫表生成各個子系統的配置文件;
S203.運行中心中的服務端根據配置文件按照調度策略獲取各個子系統的數據來更新運行中心中的中心數據庫。
在上述方法中,各個子系統是用于采集和處理數據的系統,如各個智慧城市中的用于采集和處理數據的系統。運行中心用于對數據進行匯聚,服務端是運行在運行中心的,其主要的功能是根據配置文件和各個子系統進行通信(包括請求數據和接收數據)、處理接收的數據將其寫入到運行中心的中心數據庫中。服務端中的配置文件統一存儲在子系統配置文件中。
在步驟S202中,數據庫表是從中心數據庫中生成并導出的,每個子系統對應一個數據庫表。客戶端生成配置文件時利用字符串匹配的方式從中心數據庫中尋找和獲取需要的數據,生成配置文件中的配置項,配置項可以為表名稱、屬性名稱、是否為主鍵等。配置文件生成后,使用人員只需要根據自身需要填入一些基本的配置信息即可完成基本的配置工作,減少使用人員工作量的同時還降低了對使用人員的專業要求。
在步驟S203中,調度策略包括但不限于子系統主動推送策略和定時策略;利用子系統主動推送策略進行數據匯聚的具體步驟是:
運行中心中的服務端啟動等待進程;
服務端接收各個子系統有實時數據需要上送時根據服務端提供的端口向服務端推送的數據;
服務端解析推送的目的url,并搜索是否有與子系統相關的配置文件,配置文件中是否有相關的配置項,是否處于主動推送模式,若均為是則將接收到的數據更新中心數據庫。
利用定時策略進行數據匯聚的具體步驟是:
服務端啟動,掃描每個配置文件,讀取和保存相關的配置文件;
服務端根據配置文件將數據請求任務加入到不同的定時任務隊列中;
達到某個定時任務的觸發點服務端開始執行相關任務;
服務端根據讀取的配置文件內容中的url,向子系統請求數據;
服務端接收子系統返回的數據更新數據庫。
其中,服務端啟動并掃描讀取配置文件后,還會讀取上次成功完成該主動請求任務的時間戳,執行完上次失敗的任務并及時更新數據。
具體實施過程中,數據庫更新的方式包括增量更新方式和全量更新方式,增量更新方式指的是服務端將接收到的數據添加到中心數據庫中,全量更新方式指的是服務端將接收到的子系統數據替換中心數據庫中子系統對應的數據。增量更新方式和全量更新方式可以根據數據庫實際的需求確定,對于需要長時間保留的數據則可以采用增量更新方式進行數據更新,對于不需要保留的數據可以采用全量更新方式來更新數據庫,既可以數據的實際需求來執行更新方式,還可以根據實際需求減少中心數據庫的存儲壓力,提高中心數據庫的利用率。
相同或相似的標號對應相同或相似的部件;
附圖中描述位置關系的用于僅用于示例性說明,不能理解為對本專利的限制;
顯然,本發明的上述實施例僅僅是為清楚地說明本發明所作的舉例,而并非是對本發明的實施方式的限定。對于所屬領域的普通技術人員來說,在上述說明的基礎上還可以做出其它不同形式的變化或變動。這里無需也無法對所有的實施方式予以窮舉。凡在本發明的精神和原則之內所作的任何修改、等同替換和改進等,均應包含在本發明權利要求的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!