一種融合式虛擬場景互動的方法及系統(tǒng)與流程
本發(fā)明涉及多媒體數(shù)據(jù)處理領域,尤其涉及一種融合了兩個以上數(shù)據(jù)的多媒體數(shù)據(jù)處理技術。
背景技術:
虛擬場景合成技術是一種應用于電視臺演播廳錄播節(jié)目或電影制作中的多媒體數(shù)據(jù)處理技術,例如天氣預報節(jié)目等。
現(xiàn)有技術中,虛擬場景合成技術通常通過將攝像裝置采集到的純色背景中的人像提取出來,然后與渲染出來的虛擬場景背景進行疊加合成,再將合成后的圖像數(shù)據(jù)輸出用于播放或錄制存儲。
但是,現(xiàn)有的虛擬場景技術無法實現(xiàn)主播對象與觀眾對象之間高品質(zhì)的互動交流。具體的,例如在網(wǎng)絡直播領域中,現(xiàn)有的直播平臺和技術,使得觀眾只能看到主播攝像頭拍攝的畫面,觀眾可以向主播贈送虛擬禮物,但是這些虛擬禮物只能在現(xiàn)有的場景下進行粗糙地疊加。又例如,現(xiàn)有MTV制作通常由導演和表演者交流后錄制完成,錄制過程缺乏趣味性,錄制效果單一。并且在現(xiàn)有直播技術中,為了使客戶端能夠看到其他客戶端與主播之間的互動效果,需要客戶端將互動信息和素材發(fā)送到云端服務器,云端服務器通知所有在線客戶端從指定位置下載素材,并由客戶端疊加到直播畫面上。可見,客戶端需要下載指定素材,效率低下,且浪費流量;并且需要每個客戶端在本地存儲所述互動素材,占用客戶端存儲空間,而且互動內(nèi)容不便于及時進行擴展。同時,現(xiàn)有的互動內(nèi)容一般只是簡單、生硬地疊加到圖像或視頻的表面層,并將圖像或視頻的部分內(nèi)容完全覆蓋,互動內(nèi)容與圖像或視頻的融合感差,顯示效果一般。例如,若互動內(nèi)容為用戶為主播送了一朵花,則在視頻表面覆蓋一朵花,其顯示效果很突兀,無法將互動內(nèi)容與視頻場景自然的融合在一起。
因此發(fā)明人認為需要研發(fā)一種能實現(xiàn)不同場景滿足下,通過網(wǎng)絡實現(xiàn)交流互動的虛擬場景技術。
技術實現(xiàn)要素:
為此,需要提供一種實現(xiàn)在虛擬場景中進行豐富多彩,靈活方便的互動的系統(tǒng)與方法,用于解決現(xiàn)有技術中,主播對象與觀眾對象之間互動交流效果單一,互動內(nèi)容擴展不便的問題。
為實現(xiàn)上述目的,發(fā)明人提供了一種融合式虛擬場景互動的方法,包括以下步驟:
將一個以上第一對象更新到虛擬場景中,并在接收到互動指令時,根據(jù)互動指令將互動內(nèi)容更新到虛擬場景中,得到圖像數(shù)據(jù)。
進一步的,所述融合式虛擬場景互動的方法,包括以下步驟:
實時獲取一個以上攝像裝置的信號,采集得到一個以上的第一圖像數(shù)據(jù);
根據(jù)預設的條件,從每個第一圖像數(shù)據(jù)中提取一個以上的第一對象;
接收來自第一終端發(fā)送的互動指令;
將一個以上的第一對象實時更新到虛擬場景中,并根據(jù)互動指令,更新或切換虛擬場景,得到視頻數(shù)據(jù)。
進一步的,在實時獲取一個以上攝像裝置的信號,采集得到一個以上的第一圖像數(shù)據(jù)的同時,實時獲取傳聲器的信號,采集得到第一聲音數(shù)據(jù);
將第一對象實時更新到虛擬場景中的同時,也將將第一聲音實時更新到虛擬場景中,得到第一多媒體數(shù)據(jù),所述第一多媒體數(shù)據(jù)包括第一聲音數(shù)據(jù)與視頻數(shù)據(jù)。
進一步的,所述第一終端為智能移動終端或遙控器。
進一步的,所述互動指令包括將第一素材更新到虛擬場景中的指令;
將一個以上的第一對象實時更新到虛擬場景中,并根據(jù)互動指令,將第一素材也更新到虛擬場景中,得到視頻數(shù)據(jù)。
進一步的,所述互動指令還包括第一素材的內(nèi)容數(shù)據(jù)。
進一步的,所述第一素材包括:文字素材、圖像素材、聲音素材或圖像素材與聲音素材的結合。
進一步的,所述互動指令包括變換虛擬場景鏡頭的命令(適合一對一直播的場景)。
進一步的,根據(jù)互動指令將互動內(nèi)容更新到虛擬場景中,得到視頻數(shù)據(jù)之后還包括步驟:將視頻數(shù)據(jù)通過顯示裝置顯示或存儲記錄視頻數(shù)據(jù)。
進一步的,根據(jù)互動指令將互動內(nèi)容更新到虛擬場景中,得到視頻數(shù)據(jù)之后還包括步驟:通過實時流傳輸協(xié)議,將所述視頻數(shù)據(jù)直播給局域網(wǎng)中的在線客戶端;或?qū)⑺鲆曨l數(shù)據(jù)發(fā)送給第三方網(wǎng)絡服務器;第三方網(wǎng)絡服務器生成所述視頻數(shù)據(jù)的互聯(lián)網(wǎng)直播鏈接。
進一步的,所述虛擬場景為3D虛擬舞臺。
為實現(xiàn)上述目的,發(fā)明人還提供了一種融合式虛擬場景互動的系統(tǒng),用于將一個以上第一對象更新到虛擬場景中,并在接收到互動指令時,根據(jù)互動指令將互動內(nèi)容更新到虛擬場景中,得到視頻數(shù)據(jù)。
進一步的,所述融合式虛擬場景互動的系統(tǒng)包括:
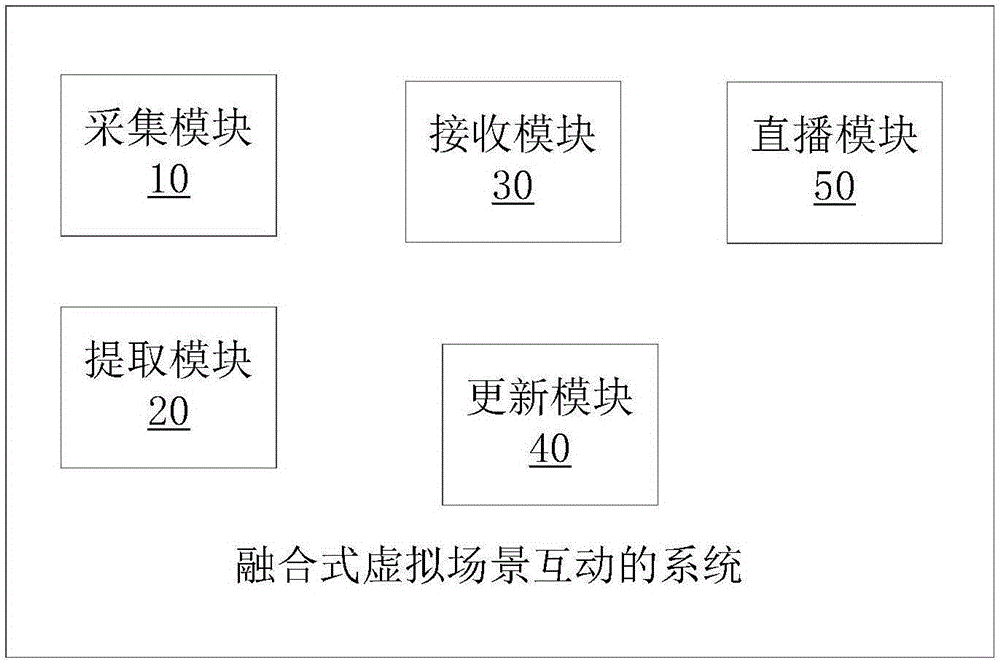
采集模塊,用于實時獲取一個以上攝像裝置的信號,采集得到一個以上的第一圖像數(shù)據(jù);
提取模塊,用于根據(jù)預設的條件,從每個第一圖像數(shù)據(jù)中提取一個以上的第一對象;
接收模塊,用于接收來自第一終端發(fā)送的互動指令;
更新模塊,用于將一個以上的第一對象實時更新到虛擬場景中,并根據(jù)互動指令,更新或切換虛擬場景,得到視頻數(shù)據(jù)。
進一步的,所述采集模塊還用于采集得到第一圖像數(shù)據(jù)的同時,實時獲取傳聲器的信號,采集得到第一聲音數(shù)據(jù);
所述更新模塊還用于將第一對象實時更新到虛擬場景中的同時,也將第一聲音實時更新到虛擬場景中,得到第一多媒體數(shù)據(jù),所述第一多媒體數(shù)據(jù)包括第一聲音數(shù)據(jù)與視頻數(shù)據(jù)。
進一步,根據(jù)互動指令將互動內(nèi)容更新到虛擬場景中,得到視頻數(shù)據(jù)之后還包括直播模塊:通過實時流傳輸協(xié)議,將所述視頻數(shù)據(jù)直播給局域網(wǎng)中的在線客戶端;或?qū)⑺鲆曨l數(shù)據(jù)發(fā)送給第三方網(wǎng)絡服務器;第三方網(wǎng)絡服務器生成所述視頻數(shù)據(jù)的互聯(lián)網(wǎng)直播鏈接。
進一步的,所述第一終端為智能移動終端或遙控器。
進一步的,所述互動指令包括將第一素材更新到虛擬場景中的指令;
將第一對象實時更新到虛擬場景中,并根據(jù)互動指令,將第一素材也更新到虛擬場景中,得到視頻數(shù)據(jù)。
進一步的,所述互動指令還包括第一素材的內(nèi)容數(shù)據(jù)。
進一步的,所述第一素材包括:文字素材、圖像素材、聲音素材或圖像素材與聲音素材的結合。
進一步的,所述互動指令包括變換虛擬場景鏡頭的命令。
進一步的,還包括顯示模塊或存儲模塊,顯示模塊用于得到視頻數(shù)據(jù)之后,將視頻數(shù)據(jù)通過顯示裝置顯示;所述存儲模塊用于,得到視頻數(shù)據(jù)之后,存儲記錄視頻數(shù)據(jù)。
進一步的,所述第一終端為智能移動終端或遙控器。
進一步的,所述虛擬場景為3D虛擬舞臺。
為解決上述技術問題,發(fā)明人還提供了一種融合式虛擬場景互動的系統(tǒng),包括第一終端、第二終端和服務器,所述第一終端和第二終端通過網(wǎng)絡與服務器連接;
所述第二終端連接有一個以上攝像裝置,用于實時獲取所述攝像裝置的信號,并采集得到一個以上的第一圖像數(shù)據(jù);以及根據(jù)預設的條件,從每個第一圖像數(shù)據(jù)中提取一個以上的第一對象;
所述第二終端還用于將一個以上的第一對象實時更新到虛擬場景中,并根據(jù)接收到的互動指令,更新或切換虛擬場景,得到視頻數(shù)據(jù),以及將視頻數(shù)據(jù)發(fā)送給服務器;
所述第一終端用于生成互動指令,并發(fā)送給服務器;以及從服務器獲取所述視頻數(shù)據(jù),并顯示所述視頻數(shù)據(jù);
所述服務器用于將所述互動指令實時的發(fā)送給第二終端,以及接收第二終端發(fā)送的視頻數(shù)據(jù)。
進一步的,所述第二終端還連接有一個以上傳聲器,第二終端在采集第一圖像數(shù)據(jù)的同時,實時獲取傳聲器的信號,采集得到第一聲音數(shù)據(jù);以及將第一對象實時更新到虛擬場景中的同時,也將第一聲音實時更新到虛擬場景中,得到第一多媒體數(shù)據(jù),所述第一多媒體數(shù)據(jù)包括第一聲音數(shù)據(jù)與視頻數(shù)據(jù)。
進一步的,所述攝像裝置為數(shù)碼攝像機或網(wǎng)絡攝像頭。
區(qū)別于現(xiàn)有技術,上述技術方案通過將第一對象實時更新到虛擬場景中,并且可以根據(jù)接收到的互動指令,對虛擬場景進行更新或切換,以實現(xiàn)在得到的視頻數(shù)據(jù)中既具有豐富多彩的場景變化效果,又同時保存有第一對象的實時活動效果。上述技術方案中觀眾可通過終端發(fā)送互動指令,在主播端將互動的內(nèi)容與第一對象更新至虛擬場景中,使互動內(nèi)容、主播對象以及虛擬場景融合在一起,因此各終端均可看到互動的效果,大大提高了主播對象與觀眾之間互動交流的豐富性與趣味性;并且在本技術方案中,互動的內(nèi)容是在主播端就融合至虛擬場景中,因此,觀眾的終端無需從服務器下載互動素材,從而便于互動內(nèi)容的擴展。另外,由于互動的內(nèi)容是在圖像或視頻形成的初期,與第一對象一起更新到虛擬場景中的,即互動內(nèi)容是與第一對象以及虛擬場景一同渲染成像的,因此互動內(nèi)容是融合在虛擬場景中,融為虛擬場景的一部分,相對目前只將互動內(nèi)容簡單疊加在視頻的表面層相比,其顯示的立體效果更好,且可以跟虛擬場景融合的更加自然協(xié)調(diào)。
附圖說明
圖1為具體實施方式所述融合式虛擬場景互動的方法的流程圖;
圖2為具體實施方式所述融合式虛擬場景互動的系統(tǒng)的模塊框圖;
圖3為具體實施方式所述融合式虛擬場景互動的方法在數(shù)字娛樂場所應用的示意圖;
圖4為具體實施方式所述融合式虛擬場景互動的方法在數(shù)字娛樂場所應用的示意圖;
圖5為具體實施方式所述融合式虛擬場景互動的方法在網(wǎng)絡直播應用的示意圖;
圖6為具體實施方式所述融合式虛擬場景互動的方法的流程圖;
圖7為具體實施方式所述融合式虛擬場景互動的系統(tǒng)的示意圖。
附圖標記說明:
10、采集模塊
20、提取模塊
30、接收模塊
40、更新模塊
50、直播模塊
301、顯示裝置
302、機頂盒
303、攝像裝置
304、傳聲器
305、輸入裝置
401、顯示裝置
402、機頂盒
403、攝像裝置
404、移動終端
405、傳聲器
406、輸入裝置
501、傳聲器
502、個人電腦
503、攝像裝置
504、移動終端
505、云端服務器
701、服務器
702、第二終端
703、攝像裝置
704、傳聲器
705、第一終端
具體實施方式
為詳細說明技術方案的技術內(nèi)容、構造特征、所實現(xiàn)目的及效果,以下結合具體實施例并配合附圖詳予說明。
請參閱圖1,本實施例提供了一種融合式虛擬場景互動的方法,本實施例可以應用于網(wǎng)絡直播或MTV制作等多種需求中。該融合式虛擬場景互動的方法,將一個以上第一對象更新到虛擬場景中,并在接收到互動指令時,根據(jù)互動指令將互動內(nèi)容更新到虛擬場景中,得到視頻數(shù)據(jù)。
具體的,本實施例的方法包括以下步驟:
S101實時獲取一個以上攝像裝置的信號,采集得到一個以上的第一圖像數(shù)據(jù)。
S102根據(jù)預設的條件,從每個第一圖像數(shù)據(jù)中提取一個以上的第一對象。其中,所述第一圖像數(shù)據(jù)是指包括兩幀以上連續(xù)圖像的圖像數(shù)據(jù)(或稱為視頻數(shù)據(jù)),并非單幀靜態(tài)圖像,在提取第一對象時,可以從每幀的圖像中分別提取出第一對象,因此所得到的第一對象也是包括有兩幀以上連接對象。在不同的實施例中根據(jù)需要,第一對象可以是不同的具體對象,例如第一對象可以是真人主播,可以是寵物動物等;第一對象的數(shù)量可以是單個,也可以是2個以上。根據(jù)這些實際需求的不同,可以使用不同的算法和設置,以有效地在第一數(shù)據(jù)圖像中提取第一對象。以下通過一具體提取第一對象的算法實施例進行舉例說明。
在某一實施例中,第一圖像數(shù)據(jù)中,第一對象為人物主播,主播所處的背景為純色背景。提取第一圖像數(shù)據(jù)中第一對象的具體步驟為:GPU將第一圖像數(shù)據(jù)中的每個像素的顏色值與預設的閾值做比較;若像素的顏色值在預設的閾值內(nèi),則將該像素點的Alpha通道設為零,即將背景顯示為透明色,提取出對象。
由于背景為純色,所以本實施例采用色度鍵法進行摳圖。其中預設的閾值為背景顏色的顏色值,例如,背景顏色為綠色,則預設的像素點RGB顏色值的閾值為(0±10、255-10、0±10)。背景色可以選擇綠色或藍色,在拍攝的場所可同時設置兩種顏色的背景,供主播選擇。當主播穿與綠色反差較大的衣服唱歌時,可選用綠色的背景。在對象(人像)提取過程中,由于主播穿的衣服與背景色相差較大,所以圖像中的每個像素的顏色值與預設的閾值進行比較后,背景部分像素點的顏色值在預設的閾值內(nèi),將背景部分像素點的Alpha通道設為零,即將背景顯示為透明色;而人像部分的像素點不在預設的閾值內(nèi),保留人像部分,從而實現(xiàn)將人像從圖像中提取出來。
在具體的實施例中,還可以利用設備上的GPU進行摳圖處理操作,不占用CPU時間,提高系統(tǒng)速度;并且由于GPU是專門對圖像進行處理的硬件,對不同大小的像素運算時間一樣,例如,8位、16位、32位的像素運算時間均一樣,可大大節(jié)省了對像素的運算時間;而普通的CPU會隨像素大小的增大延長處理時間,所以本實施例的人像提取速度大大提高。上述的區(qū)別點使得本實施例中還可以采用帶有GPU的嵌入式設備實現(xiàn),即使嵌入式方案中的CPU性能較弱,但是應用本實施例的方案,嵌入式設備方案仍然能實現(xiàn)流暢顯示,因為若使用CPU從第一圖像數(shù)據(jù)中提取第一對象,CPU需進行讀取攝像裝置獲取的視頻,并進行摳圖等處理,CPU負擔太重,無法進行流暢的顯示。而本實施例應用于嵌入式方案中,將上述摳圖處理放入GPU中進行,既減輕了CPU的負擔,同時不會對GPU的運行造成影響。
S103接收來自第一終端發(fā)送的互動指令。在不同的實施例中,所述第一終端通過計算機網(wǎng)絡發(fā)送互動指令,計算機網(wǎng)絡可以是Internet網(wǎng)絡也可以是局域網(wǎng),可以是由有線網(wǎng)絡、WiFi網(wǎng)絡或3G/4G移動通訊網(wǎng)絡等進行連接。第一終端可以是PC,也可以是手機、平板電腦等移動通訊設備,還可以是智能手表、智能手環(huán)、智能眼鏡等穿戴式設備。在一些實施例中,第一終端還可以遙控器等近距離控制裝置,第一終端可產(chǎn)生紅外信號、無線電波等信號來發(fā)送相應的互動指令。
S104將一個以上的第一對象實時更新到虛擬場景中,并根據(jù)互動指令,更新或切換虛擬場景,得到第二圖像數(shù)據(jù)。
在實施例中,所述虛擬場景包括計算機模擬的虛擬現(xiàn)實場景或真實拍攝的視頻場景等。更進一步的,實施例還可以結合新近發(fā)展的3D圖像技術來提供虛擬場景,例如3D虛擬現(xiàn)實場景或3D視頻場景。
3D虛擬現(xiàn)實場景技術是一種可以創(chuàng)建和體驗虛擬世界的計算機仿真系統(tǒng),它利用計算機生成一種現(xiàn)實場景的3D模擬場景,是一種多源信息融合的交互式的三維動態(tài)視景和實體行為的系統(tǒng)仿真。虛擬場景包括任何現(xiàn)實生活中存在的實際場景,包含視覺、聽覺等任何能通過體感感受到的場景,通過計算機技術來模擬實現(xiàn)。3D虛擬現(xiàn)實場景的一種應用是3D虛擬舞臺,3D虛擬舞臺是通過計算機技術模擬現(xiàn)實舞臺,實現(xiàn)一種立體感、真實感強的舞臺效果。可以通過3D虛擬舞臺實現(xiàn),在現(xiàn)實中不在舞臺上的主播對象在各種舞臺上進行表演的場景效果。
3D視頻是拍攝影像時,用兩臺攝影機模擬左右兩眼視差,分別拍攝兩條影片,然后將這兩條影片同時放映到銀幕上,放映時讓觀眾左眼只能看到左眼圖像,右眼只能看到右眼圖像。最后兩幅圖像經(jīng)過大腦疊合后,就能看到具有立體縱深感的畫面,即為3D視頻。
在不同虛擬場景中互動的實施例中,互動指令可以包括不同的內(nèi)容,在某些實施例中,所述互動指令包括將第一素材更新到虛擬場景中的命令。具體為:在將第一對象實時更新到虛擬場景的同時,根據(jù)所述互動指令,將第一素材也更新到虛擬場景中,從而得到所述視頻數(shù)據(jù)。
所述第一素材可以為圖像素材、聲音素材或者圖像素材與聲音素材的結合。以網(wǎng)絡直播為例,所述第一素材包括有虛擬禮物、點贊、背景音、喝彩等,網(wǎng)絡直播的觀眾可通過移動手機,向主播送鮮花等虛擬禮物的互動指令,所送的禮物將以鮮花圖片的形式在虛擬場景中體現(xiàn)出來。網(wǎng)絡直播的觀眾還可以通過移動手機,向主播發(fā)送鼓掌的互動指令,鼓掌的互動指令將以掌聲的形式進行播放。
這些第一素材可以是系統(tǒng)預置的,供給用戶選擇使用,而在某些實施例中,所述互動指令除了包括將第一素材更新到虛擬場景中的命令,還可包括了第一素材的內(nèi)容數(shù)據(jù)。例如觀眾在通過移動終端上傳一個贈送虛擬禮物的互動指令,以及在互動指令中還包含了一張所贈送虛擬禮物的圖片,在接收到所述互動指令后,將所述禮物的圖片更新至虛擬場景中。因此觀眾在發(fā)送互動指令時,除了可以選擇互動的方式,還可以根據(jù)自己的喜好自定義第一素材的內(nèi)容數(shù)據(jù),如喜歡的圖片素材、聲音素材或圖片與聲音結合的素材。
在一些實施例中,所述互動指令還包括變換虛擬場景鏡頭的命令,所述變換虛擬場景鏡頭的命令包括有切換虛擬場景鏡頭的視角,改變虛擬場景鏡頭焦距以及對虛擬場景進行局部模糊處理等。通過切換虛擬場景鏡頭的視角,可以模擬從不同視角觀看虛擬場景的畫面;通過改變虛擬場景鏡頭焦距,可對拉近和推遠虛擬場景的畫面;而對對虛擬場景進行局部模糊處理,可使虛擬場景中未模糊處理部分畫面被突出顯示。通過所述變換虛擬場景鏡頭的命令,可大大提高觀眾的互動程度和趣味性。
區(qū)別于現(xiàn)有的直播互動,是將互動的內(nèi)容是直接的疊加至圖像或視頻的表面層,因此在視覺效果上,所疊加的互動內(nèi)容像是漂浮在虛擬場景的表面,從而導致互動內(nèi)容的視覺效果很突兀,很難與虛擬場景融合成一體。在上述實施例中,所述互動內(nèi)容是在第一對象更新至虛擬場景的同時,更新至虛擬場景中,其中,所述第一對象、互動內(nèi)容以及虛擬場景是一同渲染成像的,因此互動內(nèi)容與第一對象可以自然、協(xié)調(diào)的融合在虛擬場景中,從而具有良好的視覺效果。在實施例中,所述互動內(nèi)容還可是通過3D建模而得到的3D互動模型,3D互動模型與第一對象以及虛擬場景實時渲染,從而得到3D互動模型在虛擬場景中自然展現(xiàn),如互動內(nèi)容為獻花時,所獻的鮮花可在虛擬場景中立體展現(xiàn);如互動內(nèi)容為點贊時,點贊的信息能夠在虛擬場景中的虛擬屏幕上顯示。
在一實施例中,在實時獲取攝像裝置的信號,采集得到第一圖像數(shù)據(jù)的同時,實時獲取傳聲器的信號,采集得到第一聲音數(shù)據(jù);
將第一對象實時更新到虛擬場景中的同時,也將第一聲音實時更新到虛擬場景中,得到視頻數(shù)據(jù)。以網(wǎng)絡直播為例,所述第一聲音數(shù)據(jù)為網(wǎng)絡主播的說明或演唱的聲音,或演主播演唱的聲音及歌曲伴奏的混合聲音。通過實時將第一聲音實時更新到虛擬場景中,同時,在顯示終端實時顯示更新后的視頻數(shù)據(jù)。這樣,不僅可聽到網(wǎng)絡主播的聲音,還可以在顯示終端看到與聲音同步的畫面(人像與虛擬場景的結合),實現(xiàn)了虛擬舞臺的效果。
在上述實施例中,得到視頻數(shù)據(jù)之后,將視頻數(shù)據(jù)通過顯示裝置顯示,通過在顯示裝置上顯示所述視頻數(shù)據(jù),用戶可看到第一對象與虛擬場景合成后的視頻。在顯示視頻數(shù)據(jù)時,可先對視頻數(shù)據(jù)的畫面進行編碼,通過編碼處理可使視頻數(shù)據(jù)在顯示裝置實時流暢顯示。在現(xiàn)有技術中,一般不對原始畫面進行處理,原始畫面數(shù)據(jù)量大,所以現(xiàn)有技術還未出現(xiàn)對人像和虛擬場景合成后的畫面,實時在客戶端顯示的技術。而本實施例將更新后得到的視頻數(shù)據(jù)的畫面先進行編碼,經(jīng)過編碼操作可大大減小畫面大小。
例如:在分辨率為720P的情況下,1幀視頻的大小為1.31MByte,1秒視頻為30幀畫面,所以,現(xiàn)有視頻中,1秒視頻的大小為:30*1.31=39.3MByte;本實施例對畫面進行編碼后,還是在分辨率為720P下,設碼率為4Mbit,1秒的視頻的大小為4Mbit,由于1Byte=8bit,所以1秒的視頻為0.5MByte;與現(xiàn)有視頻相比,編碼后的視頻數(shù)據(jù)大大減小,從而編碼后的視頻數(shù)據(jù)可流暢地在網(wǎng)絡上進行傳輸,實現(xiàn)在客戶端流暢顯示音視頻數(shù)據(jù)。
在一些實施例中,得到視頻數(shù)據(jù)之后,存儲記錄視頻數(shù)據(jù)。所存儲的視頻數(shù)據(jù)可上傳至網(wǎng)關服務器,網(wǎng)關服務器將接收的視頻數(shù)據(jù)上傳至云端服務器,云端服務器接收視頻數(shù)據(jù)并生成分享地址。通過上述步驟,實現(xiàn)了視頻數(shù)據(jù)的分享。在通過終端設備(例如手機、電腦、平板等帶顯示屏的電子設備)登錄分享地址,即可直接播放音視頻數(shù)據(jù)或下載所述視頻數(shù)據(jù)。
所得到的視頻數(shù)據(jù)除了可以在本地的顯示裝置上進行播放,還可以在網(wǎng)絡端進行實時播放。具體為:
網(wǎng)絡客戶端通過實時流傳輸協(xié)議獲取所述視頻數(shù)據(jù),并對視頻數(shù)據(jù)中的視頻數(shù)據(jù)解碼顯示畫面,所述畫面內(nèi)容可為3D場景渲染的畫面;音頻數(shù)據(jù)解碼后通過音頻播放設備(例如揚聲器)播放。所述實時流傳輸協(xié)議可以是RTSP協(xié)議。其中,視頻數(shù)據(jù)中的圖像數(shù)據(jù)預先經(jīng)過編碼操作,通過圖像數(shù)據(jù)編碼操作,可實現(xiàn)客戶端流暢播放視頻數(shù)據(jù)。
請參閱圖2,發(fā)明人還提供了一種通過計算機網(wǎng)絡實現(xiàn)在虛擬場景中互動的系統(tǒng),用于將一個以上第一對象更新到虛擬場景中,并在接收到互動指令時,根據(jù)互動指令將互動內(nèi)容更新到虛擬場景中,得到視頻數(shù)據(jù)。該實現(xiàn)在虛擬場景中互動的系統(tǒng)以應用于網(wǎng)絡直播或MTV制作等多種需求中。具體的,實現(xiàn)在虛擬場景中互動的系統(tǒng)包括有:
采集模塊10,用于實時獲取攝像裝置的信號,采集得到第一圖像數(shù)據(jù);
提取模塊20,用于根據(jù)預設的條件,從第一圖像數(shù)據(jù)中提取第一對象;
接收模塊30,用于接收來自第一終端通過計算機網(wǎng)絡發(fā)送的互動指令;
更新模塊40,用于將第一對象實時更新到虛擬場景中,并根據(jù)互動指令,更新或切換虛擬場景,得到視頻數(shù)據(jù)。
在不同的實施例中根據(jù)需要,第一對象可以是不同的具體對象,例如第一對象可以是真人主播,可以是寵物動物等;第一對象的數(shù)量可以是單個,也可以是2個以上。根據(jù)這些實際需求的不同,可以使用不同的算法和設置,以有效地在第一數(shù)據(jù)圖像中提取第一對象。其中,所述第一圖像數(shù)據(jù)是指包括兩幀以上連續(xù)圖像的圖像數(shù)據(jù)(或稱為視頻數(shù)據(jù)),并非單幀靜態(tài)圖像,在提取第一對象時,可以從每幀的圖像中分別提取出第一對象,因此所得到的第一對象也是包括有兩幀以上連接對象。以下通過一具體提取第一對象的算法實施例進行舉例說明。
所述計算機網(wǎng)絡可以是Internet網(wǎng)絡也可以是局域網(wǎng),可以是由有線網(wǎng)絡、WiFi網(wǎng)絡或3G/4G移動通訊網(wǎng)絡等進行連接。第一終端可以是PC,也可以是手機、平板電腦等移動通訊設備,還可以是智能手表、智能手環(huán)、智能眼鏡等穿戴式設備。
在實施例中,所述虛擬場景包括計算機模擬的虛擬現(xiàn)實場景或真實拍攝的視頻場景等。更進一步的,實施例還可以結合新近發(fā)展的3D圖像技術來提供虛擬場景,例如3D虛擬現(xiàn)實場景或3D視頻場景。
在不同虛擬場景中互動的實施例中,互動指令可以包括不同的內(nèi)容,在某些實施例中,所述互動指令包括將第一素材更新到虛擬場景中的命令。具體為:在將第一對象實時更新到虛擬場景的同時,根據(jù)所述互動指令,將第一素材也更新到虛擬場景中,從而得到所述視頻數(shù)據(jù)。所述第一素材包括:圖像素材、聲音素材或圖像素材與聲音素材的結合。
在一些實施例中,所述互動指令還包括變換虛擬場景鏡頭的命令,所述變換虛擬場景鏡頭的命令包括有切換虛擬場景鏡頭的視角,改變虛擬場景鏡頭焦距以及對虛擬場景進行局部模糊處理等。
所述采集模塊10還用于在采集得到第一圖像數(shù)據(jù)的同時,實時獲取傳聲器的信號,采集得到第一聲音數(shù)據(jù);
所述更新模塊40還用于在將第一對象實時更新到虛擬場景中的同時,也將將第一聲音實時更新到虛擬場景中,得到視頻數(shù)據(jù)。以網(wǎng)絡直播為例,所述第一聲音數(shù)據(jù)為網(wǎng)絡主播的說明或演唱的聲音,或演主播演唱的聲音及歌曲伴奏的混合聲音。通過實時將第一聲音實時更新到虛擬場景中,同時,在顯示終端實時顯示更新后的視頻數(shù)據(jù)。這樣,不僅可聽到網(wǎng)絡主播的聲音,還可以在顯示終端看到與聲音同步的畫面(人像與虛擬場景的結合),實現(xiàn)了虛擬舞臺的效果。
所述實現(xiàn)在虛擬場景中互動的系統(tǒng)還包括顯示模塊或存儲模塊,顯示模塊用于得到視頻數(shù)據(jù)之后,將視頻數(shù)據(jù)通過顯示裝置顯示;通過在顯示裝置上顯示所述視頻數(shù)據(jù),用戶可看到第一對象與虛擬場景合成后的視頻。在顯示視頻數(shù)據(jù)時,可先對視頻數(shù)據(jù)的畫面進行編碼,通過編碼處理可使視頻數(shù)據(jù)在顯示裝置實時流暢顯示。在現(xiàn)有技術中,一般不對原始畫面進行處理,原始畫面數(shù)據(jù)量大,所以現(xiàn)有技術還未出現(xiàn)對人像和虛擬場景合成后的畫面,實時在客戶端顯示的技術。而本實施例將更新后得到的視頻數(shù)據(jù)的畫面先進行編碼,經(jīng)過編碼操作可大大減小畫面大小。
所述存儲模塊用于,得到視頻數(shù)據(jù)之后,存儲記錄視頻數(shù)據(jù)。所存儲的視頻數(shù)據(jù)可上傳至網(wǎng)關服務器,網(wǎng)關服務器將接收的視頻數(shù)據(jù)上傳至云端服務器,云端服務器接收視頻數(shù)據(jù)并生成分享地址。
在一具體的實施例中,所述通過計算機網(wǎng)絡實現(xiàn)在虛擬場景中互動的系統(tǒng)還包括直播模塊50,用于根據(jù)互動指令將互動內(nèi)容更新到虛擬場景中,得到視頻數(shù)據(jù)之后:通過實時流傳輸協(xié)議,將所述視頻數(shù)據(jù)直播給局域網(wǎng)中的在線客戶端;或?qū)⑺鲆曨l數(shù)據(jù)發(fā)送給第三方網(wǎng)絡服務器;第三方網(wǎng)絡服務器生成所述視頻數(shù)據(jù)的互聯(lián)網(wǎng)直播鏈接。
以下以數(shù)字娛樂場所(KTV)為例,對本虛擬場景互動的方法進行詳細說明。請參閱圖3,數(shù)字娛樂場所的包廂內(nèi)包括有歌曲點唱系統(tǒng),所述歌曲點唱系統(tǒng)用于點歌以及演唱所點的歌曲,包括有機頂盒302、顯示裝置301、傳聲器304和輸入裝置305,通過輸入裝置305可選擇所要點唱的歌曲,以及對包廂內(nèi)的音響系統(tǒng)和燈光系統(tǒng)進行控制。所述數(shù)字娛樂場所內(nèi)還包括有攝像裝置303,并可實現(xiàn)虛擬舞臺功能。在歌曲點唱系統(tǒng)中設有多個虛擬舞臺的場景可供選擇,例如“中國好聲音”、“我是歌手”、“青年歌手賽”等,用戶在演唱歌曲時可選擇自己喜歡的虛擬舞臺場景。所述攝像裝置303用于實時獲取演唱者的圖像數(shù)據(jù),并從演唱者的圖像數(shù)據(jù)中摳取出人物圖像;所述傳聲器304用于獲取演唱者的聲音數(shù)據(jù);所述聲音數(shù)據(jù)通過音響系統(tǒng)與歌曲的伴奏一起播放,而所摳取出的人物圖像則實時更新至虛擬舞臺的場景中,并通過顯示裝置顯示,因此在包廂內(nèi)可觀看到演唱者在虛擬舞臺上進行演唱的畫面。
在一些實施例中,所述攝像裝置是直接連接于機頂盒302,由機頂盒302完成從從演唱者的圖像數(shù)據(jù)中摳取出人物圖像,并更新至虛擬舞臺場景中。
在其他實施例中,所述數(shù)字娛樂場所還可設置一專門的圖像處理設備(例如PC機),用于進行虛擬舞臺場景的實現(xiàn),該圖像處理設備與所述攝像裝置以及機頂盒連接,攝像裝置所拍攝的演唱者的圖像數(shù)據(jù),交由圖像處理設備進行人物圖像摳圖,以及將而所摳取出的人物圖像實時更新至虛擬舞臺的場景中,所得到的虛擬舞臺場景數(shù)據(jù)再通過機頂盒在顯示裝置上顯示出來。
如圖4所示,在上述實施例中,機頂盒402或圖像處理設備還可通過網(wǎng)絡或近場通信方式連接智能手機、平板電腦等智能移動終端404,通過移動終端404可向機頂盒402或圖像處理設備發(fā)送互動指令,機頂盒402或圖像處理設備在將演唱者的人物摳圖更新到虛擬舞臺的同時,根據(jù)所述互動指令,切換虛擬舞臺的場景,從而實現(xiàn)虛擬舞臺互動。例如,數(shù)據(jù)娛樂場所包廂內(nèi)的聽眾,可通過移動手機向演唱者發(fā)送“獻花”的互動指令,機頂盒或圖像處理設備在接收到該“獻花”的互動指令后,將一個鮮花的圖像直接添加至虛擬舞臺的畫面上,并將鮮花的圖像直接添加至人物圖像的手上。
以下以網(wǎng)絡直播為例,對本虛擬場景互動的方法進行詳細說明。如圖5所示,在網(wǎng)絡直播間內(nèi)設置有攝像裝置、傳聲器501以及個人電腦502,傳聲器501用于獲取網(wǎng)絡主播的聲音數(shù)據(jù),所述攝像裝置503用于獲取網(wǎng)絡主播的圖像信息,所述攝像裝置503和傳聲器501連接于個人電腦,個人電腦502通過計算機網(wǎng)絡連接于云端服務器505,并將直播間的音視頻數(shù)據(jù)實時傳輸至云端服務器505,而觀眾通過電腦或智能移動終端等網(wǎng)絡終端504,登陸云端服務器可觀看網(wǎng)絡直播間內(nèi)的直播音視頻。
為了實現(xiàn)虛擬場景直播,網(wǎng)絡直播間內(nèi)的個人電腦內(nèi)設置有多種虛擬場景供選擇,個人電腦從攝像裝置所拍攝到的圖像數(shù)據(jù)中提取出網(wǎng)絡主播的人物圖像;以及將所提取的人物圖像和傳聲器所采集的聲音數(shù)據(jù)更新至所選的虛擬場景中,得到網(wǎng)絡主播與虛擬場景相結合的視頻數(shù)據(jù)。個人電腦將該視頻數(shù)據(jù)上傳至云端服務器,因此網(wǎng)絡端觀眾通過網(wǎng)絡終端,就可觀看到網(wǎng)絡主播在虛擬場景中表演的音視頻。
網(wǎng)絡端觀眾還可通過所述網(wǎng)絡終端與網(wǎng)絡主播進行互動,互動的效果將在虛擬場景中展現(xiàn)出來。其中,網(wǎng)絡觀眾通過網(wǎng)絡終端向云端服務器發(fā)送互動指令,由云端服務器將互動指令轉(zhuǎn)發(fā)至對應的網(wǎng)絡直播間,網(wǎng)絡直播間的個人電腦在接收到互動指令后,根據(jù)互動指令實時更新或切換虛擬場景。
在另一實施例中,網(wǎng)絡直播間內(nèi)的個人電腦將攝像裝置所獲取的主播的視頻數(shù)據(jù),以及傳聲器所獲取的聲音數(shù)據(jù),直接實時的傳輸給云端服務器,云端服務器內(nèi)設置有多種虛擬場景,為實現(xiàn)虛擬場景直播,云端服務器從圖像數(shù)據(jù)中提取出網(wǎng)絡主播的人物圖像;以及將所提取的人物圖像和傳聲器所采集的聲音數(shù)據(jù)更新至所選的虛擬場景中,從而由云端服務器得到網(wǎng)絡主播與虛擬場景相結合的視頻數(shù)據(jù),云端服務器將所得到的視頻數(shù)據(jù)實時發(fā)送給對應的網(wǎng)絡直播間和在線的網(wǎng)絡終端,因此網(wǎng)絡觀眾與網(wǎng)絡主播均可看到網(wǎng)絡主播在虛擬場景中表演的音視頻。
網(wǎng)絡觀眾在與網(wǎng)絡主播互動時,云端服務器根據(jù)網(wǎng)絡終端所發(fā)送的互動指令,實時更新或切換虛擬場景。
請參閱圖6,發(fā)明人還提供了一實施例,一種融合式虛擬場景互動的方法,包括以下步驟:
將一個以上第一對象更新到虛擬場景中,并在接收到互動指令時,根據(jù)互動指令將互動內(nèi)容更新到虛擬場景中,得到視頻數(shù)據(jù)。
其中,所述第一對象為攝像裝置的信號中的對象,在不同的實施例中根據(jù)需要,第一對象可以是不同的具體對象,例如第一對象可以是真人主播,可以是寵物動物等;第一對象的數(shù)量可以是單個,也可以是2個以上。第一對象可通過上述實施例中的算法或使用GPU進行摳圖處理,從攝像裝置的數(shù)據(jù)圖像中提出得到。
所述互動指令則是由客戶端通過計算機網(wǎng)絡發(fā)送的,計算機網(wǎng)絡可以是Internet網(wǎng)絡也可以是局域網(wǎng),可以是由有線網(wǎng)絡、WiFi網(wǎng)絡、3G/4G移動通訊網(wǎng)絡、藍牙網(wǎng)絡或ZigBee網(wǎng)絡等進行連接。客戶端可以是PC,也可以是手機、平板電腦等移動通訊設備,還可以是智能手表、智能手環(huán)、智能眼鏡等穿戴式設備。
在實施例中,所述虛擬場景包括計算機模擬的虛擬現(xiàn)實場景或真實拍攝的視頻場景等。更進一步的,實施例還可以結合新近發(fā)展的3D圖像技術來提供虛擬場景,例如3D虛擬現(xiàn)實場景或3D視頻場景。
在不同虛擬場景中互動的實施例中,互動指令可以包括不同的內(nèi)容,在某些實施例中,所述互動指令包括將第一素材更新到虛擬場景中的命令。具體為:在將第一對象實時更新到虛擬場景的同時,根據(jù)所述互動指令,將第一素材也更新到虛擬場景中,從而得到所述視頻數(shù)據(jù)。
所述第一素材可以為圖像素材、聲音素材或者圖像素材與聲音素材的結合。以網(wǎng)絡直播為例,所述第一素材包括有虛擬禮物、點贊、背景音、喝彩等。這些第一素材可以是系統(tǒng)預置的,供給用戶選擇使用,而在某些實施例中,所述互動指令除了包括將第一素材更新到虛擬場景中的命令,還可包括了第一素材的內(nèi)容數(shù)據(jù)。
在一些實施例中,所述互動指令還包括變換虛擬場景鏡頭的命令,所述變換虛擬場景鏡頭的命令包括有切換虛擬場景鏡頭的視角,改變虛擬場景鏡頭焦距以及對虛擬場景進行局部模糊處理等。
在一實施例中,在實時獲取攝像裝置的信號,采集得到第一圖像數(shù)據(jù)的同時,實時獲取傳聲器的信號,采集得到第一聲音數(shù)據(jù);
將第一對象實時更新到虛擬場景中的同時,也將第一聲音實時更新到虛擬場景中,得到視頻數(shù)據(jù)。
請參閱圖7,發(fā)明人提供了一實施例,一種融合式虛擬場景互動的系統(tǒng),該虛擬場景互動的系統(tǒng),包括第一終端705、第二終端702和服務器701,所述第一終端和第二終端通過網(wǎng)絡與服務器連接。
所述第二終端702連接有一個以上攝像裝置703,用于實時獲取所述攝像裝置的信號,并采集得到一個以上的第一圖像數(shù)據(jù);以及根據(jù)預設的條件,從每個第一圖像數(shù)據(jù)中提取一個以上的第一對象;在不同的實施例中根據(jù)需要,第一對象可以是不同的具體對象,例如第一對象可以是真人主播,可以是寵物動物等;第一對象的數(shù)量可以是單個,也可以是2個以上。根據(jù)這些實際需求的不同,可以使用不同的算法和設置,以有效地在第一數(shù)據(jù)圖像中提取第一對象。在不同實施例中,所述攝像裝置為數(shù)碼攝像機或網(wǎng)絡攝像頭。
所述第二終端702還用于將一個以上的第一對象實時更新到虛擬場景中,并根據(jù)接收到的互動指令,更新或切換虛擬場景,得到視頻數(shù)據(jù),以及將視頻數(shù)據(jù)發(fā)送給服務器701。所述第二終端可以是電腦或小型的服務器等,在實施例中,所述虛擬場景包括計算機模擬的虛擬現(xiàn)實場景或真實拍攝的視頻場景等。更進一步的,實施例還可以結合新近發(fā)展的3D圖像技術來提供虛擬場景,例如3D虛擬現(xiàn)實場景或3D視頻場景。
所述第一終端705用于生成互動指令,并發(fā)送給服務器;以及從服務器獲取所述視頻數(shù)據(jù),并顯示所述視頻數(shù)據(jù);所述互動指令通過計算機網(wǎng)絡發(fā)送給服務器,計算機網(wǎng)絡可以是Internet網(wǎng)絡也可以是局域網(wǎng),可以是由有線網(wǎng)絡、WiFi網(wǎng)絡、3G/4G移動通訊網(wǎng)絡、藍牙網(wǎng)絡或ZigBee網(wǎng)絡等進行連接。第一終端可以是PC,也可以是手機、平板電腦等移動通訊設備,還可以是智能手表、智能手環(huán)、智能眼鏡等穿戴式設備。
所述服務器用于將所述互動指令實時的發(fā)送給第二終端,以及接收第二終端發(fā)送的視頻數(shù)據(jù)。
在本實施例中,所述第二終端還連接有一個以上傳聲器704,第二終端在采集第一圖像數(shù)據(jù)的同時,實時獲取傳聲器的信號,采集得到第一聲音數(shù)據(jù);以及將第一對象實時更新到虛擬場景中的同時,也將第一聲音實時更新到虛擬場景中,得到第一多媒體數(shù)據(jù),所述第一多媒體數(shù)據(jù)包括第一聲音數(shù)據(jù)與視頻數(shù)據(jù)。
需要說明的是,在本文中,諸如第一和第二等之類的關系術語僅僅用來將一個實體或者操作與另一個實體或操作區(qū)分開來,而不一定要求或者暗示這些實體或操作之間存在任何這種實際的關系或者順序。而且,術語“包括”、“包含”或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、物品或者終端設備不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、物品或者終端設備所固有的要素。在沒有更多限制的情況下,由語句“包括……”或“包含……”限定的要素,并不排除在包括所述要素的過程、方法、物品或者終端設備中還存在另外的要素。此外,在本文中,“大于”、“小于”、“超過”等理解為不包括本數(shù);“以上”、“以下”、“以內(nèi)”等理解為包括本數(shù)。
本領域內(nèi)的技術人員應明白,上述各實施例可提供為方法、裝置、或計算機程序產(chǎn)品。這些實施例可采用完全硬件實施例、完全軟件實施例、或結合軟件和硬件方面的實施例的形式。上述各實施例涉及的方法中的全部或部分步驟可以通過程序來指令相關的硬件來完成,所述的程序可以存儲于計算機設備可讀取的存儲介質(zhì)中,用于執(zhí)行上述各實施例方法所述的全部或部分步驟。所述計算機設備,包括但不限于:個人計算機、服務器、通用計算機、專用計算機、網(wǎng)絡設備、嵌入式設備、可編程設備、智能移動終端、智能家居設備、穿戴式智能設備、車載智能設備等;所述的存儲介質(zhì),包括但不限于:RAM、ROM、磁碟、磁帶、光盤、閃存、U盤、移動硬盤、存儲卡、記憶棒、網(wǎng)絡服務器存儲、網(wǎng)絡云存儲等。
上述各實施例是參照根據(jù)實施例所述的方法、設備(系統(tǒng))、和計算機程序產(chǎn)品的流程圖和/或方框圖來描述的。應理解可由計算機程序指令實現(xiàn)流程圖和/或方框圖中的每一流程和/或方框、以及流程圖和/或方框圖中的流程和/或方框的結合。可提供這些計算機程序指令到計算機設備的處理器以產(chǎn)生一個機器,使得通過計算機設備的處理器執(zhí)行的指令產(chǎn)生用于實現(xiàn)在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能的裝置。
這些計算機程序指令也可存儲在能引導計算機設備以特定方式工作的計算機設備可讀存儲器中,使得存儲在該計算機設備可讀存儲器中的指令產(chǎn)生包括指令裝置的制造品,該指令裝置實現(xiàn)在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能。
這些計算機程序指令也可裝載到計算機設備上,使得在計算機設備上執(zhí)行一系列操作步驟以產(chǎn)生計算機實現(xiàn)的處理,從而在計算機設備上執(zhí)行的指令提供用于實現(xiàn)在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能的步驟。
盡管已經(jīng)對上述各實施例進行了描述,但本領域內(nèi)的技術人員一旦得知了基本創(chuàng)造性概念,則可對這些實施例做出另外的變更和修改,所以以上所述僅為本發(fā)明的實施例,并非因此限制本發(fā)明的專利保護范圍,凡是利用本發(fā)明說明書及附圖內(nèi)容所作的等效結構或等效流程變換,或直接或間接運用在其他相關的技術領域,均同理包括在本發(fā)明的專利保護范圍之內(nèi)。
- 還沒有人留言評論。精彩留言會獲得點贊!
- 物聯(lián)圖元的3D場景建立方法及系統(tǒng)與流程
- 一種適用于多應用場景的安全數(shù)據(jù)融合方法與流程
- 一種針對wlan與5g融合組網(wǎng)應用場景的高效初始接入認證方法
- 一種固定移動網(wǎng)絡融合場景下的隧道建立方法及系統(tǒng)的制作方法
- 一種融合場景中實現(xiàn)座席呼叫的方法、裝置和系統(tǒng)的制作方法
- 一種固定移動網(wǎng)絡融合場景下的多連接建立方法及系統(tǒng)的制作方法
- 一種基于三維空間場景的監(jiān)控視頻融合系統(tǒng)和方法
- 高速公路場景下一種多特征融合的多車輛視頻跟蹤方法
- 一種融合附加信息的大場景三維重建方法
- 一種基于圖片虛擬內(nèi)容融合真實場景的實現(xiàn)方法及系統(tǒng)的制作方法
- 一種融合場景中實現(xiàn)座席呼叫的方法、裝置和系統(tǒng)的制作方法
- 一種固定移動網(wǎng)絡融合場景下的多連接建立方法及系統(tǒng)的制作方法
- 一種固網(wǎng)移動融合場景下的策略控制方法
- 基于視頻地圖與增強現(xiàn)實的犯罪現(xiàn)場還原方法
- 一種基于三維空間場景的監(jiān)控視頻融合系統(tǒng)和方法
- 一種基于機器人云臺的攝像機控制方法及系統(tǒng)的制作方法
- 高速公路場景下一種多特征融合的多車輛視頻跟蹤方法
- 一種融合附加信息的大場景三維重建方法
- 一種基于圖片虛擬內(nèi)容融合真實場景的實現(xiàn)方法及系統(tǒng)的制作方法
- 基于同心圓環(huán)圖案組的增強現(xiàn)實方法