一種監控和配置資源的方法及裝置與流程
本發明實施例涉及大數據中集群的監控和報警以及作業調優領域,尤其涉及一種監控和配置資源的方法及裝置。
背景技術:
在大數據處理領域,隨著數據中心的數據和服務器的增加,對數據和資源的監控、利用有了更高的要求。由于集群規模的增大和程序在利用資源方面要求的增高,能夠實時監控集群狀態并因此做出針對于集群和運行作業的及時反饋,在很大程度上影響著整個大數據平臺的整體功能和作業效率。
監控集群中的節點是集群管理的一個重要組成部分,即跟蹤節點的狀態。Ganglia是一個用來監控集群中節點的應用程序,廣泛應用于各大互聯網公司的大數據平臺和云平臺之上。
對于系統管理者來說,網絡監控系統的意義和作用主要在于以下兩點:一個是可以及時的關注到服務器的一些異常情況,并根據預設值的閥值進行警告,比如磁盤空間不足,cpu和內存利用率異常增高,運行的進程突然增多,以及運行的作業速度和之前對比明顯緩慢,運行作業的某個階段占用內存異常并導致作業多次運行失敗,某個節點宕機或者集群出現大面積宕機情況;還有一個是在較為復雜的應用環境中出現問題時,比如網絡中斷、應用程序出錯、系統崩潰等情況發生時,面對服務器和應用程序,可以根據監控系統給出的警告快速DXXW到問題所在,為排除故障贏得時間。
部分關鍵業務系統已經在實際生產活動中部署了監控程序,但是存在以下局限性:
所能監控的程序項目有限,局限于cpu負載,內存使用,磁盤空間等項目;監控局限性,不能推廣到其他系統并進行監控數據的整合;安全局限性,需要能夠直接探測到其他應用的服務端口和遠程讀取簡單網絡管理協議(Simple Network Management Protocol,SNMP)等系統信息,這對于網絡安全性要求較高的業務上有挑戰性。
Nagios可以實現對網絡上的服務器進行全面的監控,包括服務器上運行的服務(Apache、MySQL、FTP、DNS和hadoop,Hbase,Solr等)的狀態和服務器系統資源的狀態。
大數據應用平臺業務系統的數量在不斷地增加,相互之間的融合和交互日漸增多,應用架構體系之間出現的問題概率也隨之增大,通過自動化監控和反饋系統,能夠實時查看平臺應用和服務的狀態,在運行作業時發現系統性能的瓶頸,并自動處理或者警告,保證整個平臺系統高效、可靠地運轉,減輕檢測和系統管理人員的工作強度,提高工作效率,優化程序設計結構,并減少因故障帶來的損失。
作業調度系統是管理集群和管理運行作業的重要組成部分,在大數據平臺應用中有很多作業調度系統,比如hadoop和spark的DAG(Database Availability Group)調度,Oozie的Workflow調度,但是如何能將調度系統和資源監控系統結合起來是各個公司著重解決的問題。此外,大數據平臺的監控系統在具體的實際生產應用時,如果能將監控數據和實時運行作業數據結合起來,并據此評分反饋給相應的程序工程師和管理者,并將反饋時集群的狀態信息和作業信息保存日志記錄下來,作為知識庫,以供將來參考。系統工程師也可以據此數據對于現有集群的狀態有更深入了解,并為將來集群擴容做好數據準備。
開源(和商業)監視軟件有倆個主要的問題如下:
(1)沒有任何工具可以監視所需的一切內容;
(2)需要讓這些工具完全適應不同的自定義工作。
技術實現要素:
本發明實施例的目的在于提出一種監控和配置資源的方法及裝置,如何在保證監控資源和作業的同時,又能根據監控情況,來達到優化集群資源利用,程序性能優化并能及時報警達到止損危害的目的。
為達此目的,本發明實施例采用以下技術方案:
第一方面,一種監控和配置資源的方法,所述方法包括:
Ganglia動態收集不同功能集群的信息,在資源監控系統中對各個節點信息進行評分并周期性的記錄到日志中;
Nagios在資源報警系統中設置不同級別的警告,并設置不同種類的發送消息的插件并自定義消息內容,獲取所述ganglia發送的數據并記錄到所述日志中;
所述Nagios根據所述資源反饋系統的評分對任務和資源進行優化和重新分配。
優選地,所述Ganglia動態收集不同功能集群的信息,在資源監控系統中對各個節點信息進行評分并周期性的記錄到日志中之前,還包括:
通過主機管理對被監控設備進行添加、修改、刪除和查詢操作,所述添加操作包括手動輸入和支持網絡拓撲自動發現預設網段中所有設備的方式,所述支持網絡拓撲自動發現預設網段中所有設備的方法包括自動發現需要用戶指定網絡段、再以ping的方式掃描所有的IP并判斷掃描出每個設備的類型后再添加到主機表中的方法。
優選地,所述Ganglia動態收集不同功能集群的信息,包括:
所述Ganglia監控集群中節點的的cpu和內存信息,根據oozie的workflow中的不同job以及對應的運行狀態,判斷程序在運行過程中的資源占用情況,在getmad配置文件中配置所需要的心跳頻率;
若在不同功能集群上運行的作業超過預設作業數量閾值,所述Ganglia根據反饋的占用的資源信息和不同節點的狀態結合yarn或者mesos上的job以及對應的運行狀況,制定程序中的優化策略。
優選地,所述Ganglia動態收集不同功能集群的信息,包括:
獲取所述被監控設備對應的類型,并通過所述類型查找出所對應的服務,再以列表的形式顯示出所述被監控設備可監控到的服務。
優選地,所述在資源監控系統中對各個節點信息進行評分,包括:
在每個監測周期統計相應周期內的數據,對不同時間段內的數據進行抽樣,并得到統計樣本的最值、均值、標準差。
優選地,所述對不同時間段內的數據進行抽樣,包括:
先選擇一個參考時間t1,根據pi=wi/ui獲取所述時間ti內產生的數據Vi,所述數據Vi的權重為:wi=f(ti-t1),f為單調不減的函數;所述wi=ea(ti-t1),a>0;ui為0到1之間的隨機數。
第二方面,一種監控和配置資源的裝置,所述裝置包括:
收集模塊,用于動態收集不同功能集群的信息;
評分模塊,用于在資源監控系統中對各個節點信息進行評分;
第一記錄模塊,用于周期性的記錄到日志中;
第二記錄模塊,用于在資源報警系統中設置不同級別的警告,并設置不同種類的發送消息的插件并自定義消息內容,獲取所述ganglia發送的數據并記錄到所述日志中;
分配模塊,用于根據所述資源反饋系統的評分對任務和資源進行優化和重新分配。
優選地,所述裝置還包括:
處理模塊,用于在所述Ganglia動態收集不同功能集群的信息,在資源監控系統中對各個節點信息進行評分并周期性的記錄到日志中之前,通過主機管理對被監控設備進行添加、修改、刪除和查詢操作,所述添加操作包括手動輸入和支持網絡拓撲自動發現預設網段中所有設備的方式,所述支持網絡拓撲自動發現預設網段中所有設備的方法包括自動發現需要用戶指定網絡段、再以ping的方式掃描所有的IP并判斷掃描出每個設備的類型后再添加到主機表中的方法。
優選地,所述收集模塊,具體用于:
監控集群中節點的的cpu和內存信息,根據oozie的workflow中的不同job以及對應的運行狀態,判斷程序在運行過程中的資源占用情況,在getmad配置文件中配置所需要的心跳頻率;若在不同功能集群上運行的作業超過預設作業數量閾值,根據反饋的占用的資源信息和不同節點的狀態結合yarn或者mesos上的job以及對應的運行狀況,制定程序中的優化策略;
所述收集模塊,還具體用于::
獲取所述被監控設備對應的類型,并通過所述類型查找出所對應的服務,再以列表的形式顯示出所述被監控設備可監控到的服務。
優選地,所述評分模塊,具體用于:在每個監測周期統計相應周期內的數據,對不同時間段內的數據進行抽樣,并得到統計樣本的最值、均值、標準差;
所述評分模塊,還具體用于:
先選擇一個參考時間t1,根據pi=wi/ui獲取所述時間ti內產生的數據Vi,所述數據Vi的權重為:wi=f(ti-t1),f為單調不減的函數;所述wi=ea(ti-t1),a>0;ui為0到1之間的隨機數。
本發明實施例提供的一種監控和配置資源的方法及裝置,Ganglia動態收集不同功能集群的信息,在資源監控系統中對各個節點信息進行評分并周期性的記錄到日志中;Nagios在資源報警系統中設置不同級別的警告,并設置不同種類的發送消息的插件并自定義消息內容,獲取所述ganglia發送的數據并記錄到所述日志中;所述Nagios根據所述資源反饋系統的評分對任務和資源進行優化和重新分配。從而根據量化資源和作業信息對大數據平臺運行進行優化和調整;對歷史數據和處理方法形成知識庫,方便更新監控模式,并可以依據知識庫處理遇到的問題。
附圖說明
圖1是本發明實施例提供的一種監控和配置資源的方法的流程示意圖;
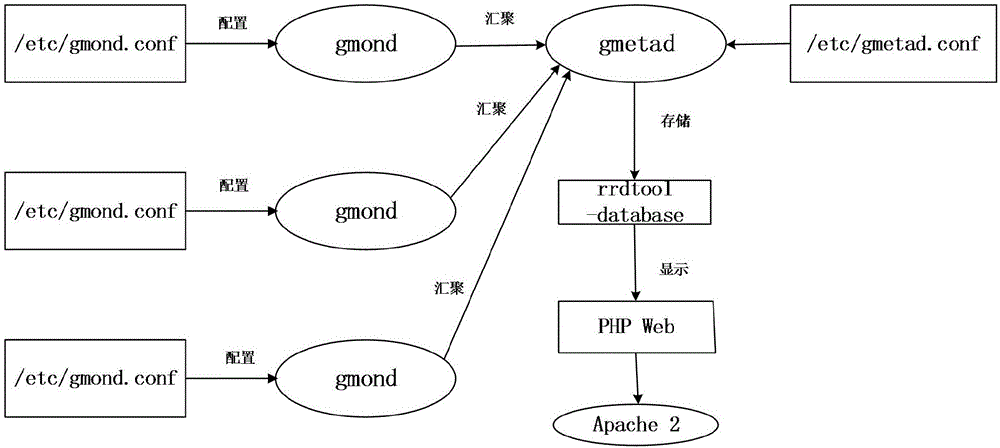
圖2是本發明實施例提供的一種ganglia的數據流圖的流程示意圖;
圖3是本發明實施例提供的一種Nagios性能處理架構示意圖;
圖4是本發明實施例提供的一種集群架構示意圖;
圖5是本發明實施例提供的一種監控和配置資源的方法的流程示意圖;
圖6是本發明實施例提供的一種監控配置功能的流程示意圖;
圖7是本發明實施例提供的一種監控和配置資源的裝置的功能模塊示意圖。
具體實施方式
下面結合附圖和實施例對本發明實施例作進一步的詳細說明。可以理解的是,此處所描述的具體實施例僅僅用于解釋本發明實施例,而非對本發明實施例的限定。另外還需要說明的是,為了便于描述,附圖中僅示出了與本發明實施例相關的部分而非全部結構。
參考圖1,圖1是本發明實施例提供的一種監控和配置資源的方法的流程示意圖。
如圖1所示,所述監控和配置資源的方法包括:
步驟101,Ganglia動態收集不同功能集群的信息,在資源監控系統中對各個節點信息進行評分并周期性的記錄到日志中;
如圖2所示,其中Ganglia監控系統包括三個主要部分:gmond、gmetad和ganglia-web。他們之間通過XDL(xml的壓縮格式)或者XML格式傳遞監控數據,達到監控效果。集群內的節點,通過運行gmond收集發布節點狀態信息,然后gmetad周期性的輪詢gmond收集到的信息,然后存入rrd數據庫,通過web服務器可以對其進行查詢展示。gmond帶來的系統負載很少,可以在集群中各臺服務器上運行而不會影響用戶的性能。由于集群處于網絡中,可以通過集群節點的時鐘(NTP)設置避免集群節點間的“抖動(Jitter)”。
對于ganglia的二次開發采用SOA模式。
如圖3所示,在大數據平臺系統中使用Nagios進行數據采集,由于采集到的數據格式不符合日常使用和管理,需要通過對Nagios監控產生的性能數據進行解析,解析成符合日常管理規范的數據,并保存到系統數據庫中,用于數據的展示。
此處性能處理架構的設計思路是通過socket方式將Nagios采集到的性能數據發送至自主研發的中間件程序,然后該程序進行解析處理,在形成統一的格式后,再統一發送至系統數據庫。
在性能數據解析程序時,需要在Nagios的服務定義里面開啟處理性能數據選項,否則會沒有性能數據輸出。在命令文件里定義處理性能數據命令:
其中192.168.251.60為實驗中Nagios服務短的IP。對于開發方法,此處采用Socket方式實現,生成jar包并注冊成服務,方法如下:
(1)判斷性能數據,如果為null則報錯并提示,找到次資源相關組件和指標,修改指標為1。
(2)通過正則表達式將性能數組分割得到相應的數組。
(3)循環數組中每個元素,用等號分割,等號左邊為指標名,等號右邊再用分號分割,取第一個元素,為指標的值。
(4)查詢監控實例是否在數據庫中。如果不在則不進行處理,如果存在則進行下步處理。
(5)通過服務名稱,指標名稱查詢該指標是否存在數據庫中,如果不存在則增加新的警告類型。
(6)將指標值存入數據庫。
優選地,所述Ganglia動態收集不同功能集群的信息,包括:
所述Ganglia監控集群中節點的的cpu和內存信息,根據oozie的workflow中的不同job以及對應的運行狀態,判斷程序在運行過程中的資源占用情況,在getmad配置文件中配置所需要的心跳頻率;
若在不同功能集群上運行的作業超過預設作業數量閾值,所述Ganglia根據反饋的占用的資源信息和不同節點的狀態結合yarn或者mesos上的job以及對應的運行狀況,制定程序中的優化策略。
優選地,所述Ganglia動態收集不同功能集群的信息,包括:
獲取所述被監控設備對應的類型,并通過所述類型查找出所對應的服務,再以列表的形式顯示出所述被監控設備可監控到的服務。
優選地,所述在資源監控系統中對各個節點信息進行評分,包括:
在每個監測周期統計相應周期內的數據,對不同時間段內的數據進行抽樣,并得到統計樣本的最值、均值、標準差。
所述對不同時間段內的數據進行抽樣,包括:
先選擇一個參考時間t1,根據pi=wi/ui獲取所述時間ti內產生的數據Vi,所述數據Vi的權重為:wi=f(ti-t1),f為單調不減的函數;所述wi=ea(ti-t1),a>0;ui為0到1之間的隨機數。
步驟102,Nagios在資源報警系統中設置不同級別的警告,并設置不同種類的發送消息的插件并自定義消息內容,獲取所述ganglia發送的數據并記錄到所述日志中;
步驟103,所述Nagios根據所述資源反饋系統的評分對任務和資源進行優化和重新分配。
具體的,如圖4所示,在軟硬件方面為集群環境,不同的集群可以組成不同的組,如hadoop組,solr組,spark組等,集群中通用為Linux系統,此設計實驗時為CentOs6.4系統。在大數據平臺即生產系統中為不同的功能集群組件,由于組件的底層存儲為hadoop的HDFS,所以需要在配置hadoop的metrics,從而使ganglia和nagios的功能插件能夠和集群關聯。Ganglia動態收集不同功能集群的信息,在資源監控系統中,對各個節點信息進行評分并周期性的記錄到日志中,可以在今后查看相應的記錄并根據歷史數據對業務進行調整。在資源報警系統中,可以設置不同級別的警告,并設置不同種類的發送消息的插件并自定義消息內容,通過ganglia傳入的數據,nagios做出相應的反應,并記錄到相應的日志中。可以設置資源反饋系統的評分標準如表1,根據標準來定義警告的行為,并可以根據反饋系統的評分對任務和資源進行優化和重新分配。
表1
此處表1中的的評分對象模型為默認的線性關系評分,也可根據實際數據和需要更換其他模型。
本發明實施例提供的一種監控和配置資源的方法,Ganglia動態收集不同功能集群的信息,在資源監控系統中對各個節點信息進行評分并周期性的記錄到日志中;Nagios在資源報警系統中設置不同級別的警告,并設置不同種類的發送消息的插件并自定義消息內容,獲取所述ganglia發送的數據并記錄到所述日志中;所述Nagios根據所述資源反饋系統的評分對任務和資源進行優化和重新分配。從而根據量化資源和作業信息對大數據平臺運行進行優化和調整;對歷史數據和處理方法形成知識庫,方便更新監控模式,并可以依據知識庫處理遇到的問題。
參考圖5,圖5是本發明實施例提供的一種監控和配置資源的方法的流程示意圖。
如圖5所示,所述監控和配置資源的方法包括:
步驟501,通過主機管理對被監控設備進行添加、修改、刪除和查詢操作,所述添加操作包括手動輸入和支持網絡拓撲自動發現預設網段中所有設備的方式,所述支持網絡拓撲自動發現預設網段中所有設備的方法包括自動發現需要用戶指定網絡段、再以ping的方式掃描所有的IP并判斷掃描出每個設備的類型后再添加到主機表中的方法;
具體的,如圖6所示,監控系統的模塊設計:
主機和主機組的管理:(1)主機名(2)網絡地址(3)監控時段(4)聯系人(5)通知時段。
服務和服務組的管理:(1)主機名(2)監控命令(3)監控時段,聯系人和通知段通知等。
時間規則管理:(1)名稱(2)具體定義的時間段(3)時間段中日期的指定(4)特殊日期(如不需要監控的節假日等)。
通過主機管理來對被監控設備進行添加、修改、刪除和查詢操作。添加設備支持手動添加,即手動輸入設備名稱和IP地址;也支持網絡拓撲自動發現某網段中所有設備的方式,自動發現需要用戶指定網絡段,此處默認是服務器所在的網關,然后以ping的方式掃描所有的IP,判斷掃描出每個設備的類型,最后再添加到主機表中(res_host)。
通過資源配置來對監控對象實施具體的監控操作。資源配置會首先通過選中設備查出其所對應的類型,進而通過該類型查找出所對應的服務,然后以列表的形式顯示出該設備可監控到的服務:在確認后,將確認的服務添加到資源實例列表中,最后將設備和服務實例寫入到配置文件中。
步驟502,Ganglia動態收集不同功能集群的信息,在資源監控系統中對各個節點信息進行評分并周期性的記錄到日志中;
步驟503,Nagios在資源報警系統中設置不同級別的警告,并設置不同種類的發送消息的插件并自定義消息內容,獲取所述ganglia發送的數據并記錄到所述日志中;
步驟504,所述Nagios根據所述資源反饋系統的評分對任務和資源進行優化和重新分配。
在應用展現層面,可以將資源監測的各種應用數據進行匯總和整理,對報警信息和來源進行呈現,并據此對集群的擴容和任務的分配提供參考性的建議,并可以根據需要設置不同的插件,從而得到不同的警告種類。系統人員和程序員也可以根據匯集信息結合過去的監控知識,對現在的運行狀態進行綜合評價,從而進行進一步的資源分配和任務分配,也可以根據作業運行情況查看相應時間段的資源和作業運行情況,如附圖6。
在服務應用層面系統人員可以根據不同功能集群進行模型設計,主要包括集群的分組,評分系統的配置,不同任務和作業的運行評價,以及不同功能集群的預警配置(此處默認的預警方式為短信或email)。程序員可以設置查看相關的作業程序運行狀況,并根據一些重要的參數指標如作業階段運行時間,作業占用cpu核數和內存比率,以及作業高峰的線程數來對作業整體運行指標進行評價,并作為改進程序設計和性能的重要參考。
Ganglia監控集群中節點的的cpu和內存信息,根據oozie的workflow中的不同job以及運行狀態,倆者結合判斷程序在運行過程中的資源占用情況,在getmad配置文件中配置所需要的心跳頻率(一般為30ms)。如果也集群上運行的作業較多,需要根據ganglia反饋的占用的資源信息和不同節點的狀態結合yarn或者mesos上的job運行狀況,優化作業進程并調整作業的細節方面,并由此制定程序中的優化策略。
在現在集群的作業運行時,由于計算和IO消耗,使得需要得到查詢結果和最終運行結果有時候超過了規定時間,尤其是當spark集群在運行時,對內存消耗較大,有時候會受到到同集群其他job的運行的影響,這時就需要根據反饋信息來優化程序,定點進行進行壓縮策略(如snappy和LZO)和串行化(Protobuf或Kryo,Avro)策略,減小資源消耗。
參考圖7,圖7是本發明實施例提供的一種監控和配置資源的裝置的功能模塊示意圖。
如圖7所示,所述裝置包括:
收集模塊701,用于動態收集不同功能集群的信息;
評分模塊702,用于在資源監控系統中對各個節點信息進行評分;
第一記錄模塊703,用于周期性的記錄到日志中;
第二記錄模塊704,用于在資源報警系統中設置不同級別的警告,并設置不同種類的發送消息的插件并自定義消息內容,獲取所述ganglia發送的數據并記錄到所述日志中;
分配模塊705,用于根據所述資源反饋系統的評分對任務和資源進行優化和重新分配。
優選地,所述裝置還包括:
處理模塊,用于在所述Ganglia動態收集不同功能集群的信息,在資源監控系統中對各個節點信息進行評分并周期性的記錄到日志中之前,通過主機管理對被監控設備進行添加、修改、刪除和查詢操作,所述添加操作包括手動輸入和支持網絡拓撲自動發現預設網段中所有設備的方式,所述支持網絡拓撲自動發現預設網段中所有設備的方法包括自動發現需要用戶指定網絡段、再以ping的方式掃描所有的IP并判斷掃描出每個設備的類型后再添加到主機表中的方法。
優選地,所述收集模塊701,具體用于:
監控集群中節點的的cpu和內存信息,根據oozie的workflow中的不同job以及對應的運行狀態,判斷程序在運行過程中的資源占用情況,在getmad配置文件中配置所需要的心跳頻率;若在不同功能集群上運行的作業超過預設作業數量閾值,根據反饋的占用的資源信息和不同節點的狀態結合yarn或者mesos上的job以及對應的運行狀況,制定程序中的優化策略;
所述收集模塊701,還具體用于:
獲取所述被監控設備對應的類型,并通過所述類型查找出所對應的服務,再以列表的形式顯示出所述被監控設備可監控到的服務。
優選地,所述評分模塊702,具體用于:在每個監測周期統計相應周期內的數據,對不同時間段內的數據進行抽樣,并得到統計樣本的最值、均值、標準差;
所述評分模塊702,還具體用于:
先選擇一個參考時間t1,根據pi=wi/ui獲取所述時間ti內產生的數據Vi,所述數據Vi的權重為:wi=f(ti-t1),f為單調不減的函數;所述wi=ea(ti-t1),a>0;ui為0到1之間的隨機數。
本發明實施例提供的一種監控和配置資源的裝置,Ganglia動態收集不同功能集群的信息,在資源監控系統中對各個節點信息進行評分并周期性的記錄到日志中;Nagios在資源報警系統中設置不同級別的警告,并設置不同種類的發送消息的插件并自定義消息內容,獲取所述ganglia發送的數據并記錄到所述日志中;所述Nagios根據所述資源反饋系統的評分對任務和資源進行優化和重新分配。從而根據量化資源和作業信息對大數據平臺運行進行優化和調整;對歷史數據和處理方法形成知識庫,方便更新監控模式,并可以依據知識庫處理遇到的問題。
以上結合具體實施例描述了本發明實施例的技術原理。這些描述只是為了解釋本發明實施例的原理,而不能以任何方式解釋為對本發明實施例保護范圍的限制。基于此處的解釋,本領域的技術人員不需要付出創造性的勞動即可聯想到本發明實施例的其它具體實施方式,這些方式都將落入本發明實施例的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!