一種基于深度學習多層次分割新聞視頻的通用方法與流程
本發明屬于計算機人工智能和視頻處理領域,具體來說,涉及到一種基于深度學習多層次分割新聞視頻的通用方法。
背景技術:
多媒體技術和互聯網的發展給我們的日常生活帶來了很多的視頻資源,如何對海量的數字媒體進行有效的管理、組織、檢索成為了圖像處理領域里的熱門研究課題。傳統的方法一般是采用人工手段對視頻各部分的段落進行手動的事件分割,并對分割后的事件加入人為描述信息,但是這樣不僅耗時而且摻雜了許許多多人為的主觀因素。事件分割作為視頻標注檢索的首要工作,起到了關鍵的作用。
新聞視頻與人類的日常生活密切相關,新聞視頻均由多段獨立的新聞事件組成,事件與事件之間會存在主持人播報環節,由于新聞事件之間的復雜性,因此希望通過利用主持人播報環節找到事件之間的分割點。同一頻道的主持人位置相對固定,但背景不同;然而在不同頻道之間,主持人所處位置卻也不同。因此,需要一種通用的方法來解決多類新聞頻道之間的事件分割問題。
另外,深度學習作為當下熱門人工智能方法在圖像處理領域發揮了至關重要的作用,并且在圖像處理領域也取得了傲人的成績。因此,本方法主要是基于深度學習的多層次分割新聞視頻的通用方法。
事件分割本身是視頻標注檢索的首要工作,面向多類頻道的分割方法能夠提高新聞視頻分割的普適性。基于深度學習能夠減少人工提取特征的局限性,進而提高了方法的準確率。本方法旨在面向多類新聞視頻時能夠起到自動分割新聞事件的作用,在保證準確率的前提下,提高時效性,節省人力成本,極大地提高工作效率。
技術實現要素:
本發明首先根據頻道標識符(logo)及主持人臉的特點,有別于統一的數據處理方式,對其進行針對性的方式處理,提高后續訓練及檢測效果;然后,考慮到多類新聞視頻之間的差異性,本文率先提出預先進行新聞logo識別,將識別后的頻道再輸入至各自的人臉檢測通道中依次識別的方法,進而提高了視頻分割的通用性;最后,基于主持環節的共同點,本文提出采用人工特征及時間閾值的交叉檢測進行精篩選,進而最終檢測到各頻道的主持環節,實現分割多類新聞視頻的通用方法。本方法大大增強了分割各類新聞視頻的普適性,進而更好地代替手動分割視頻方法,極大地減少了人力成本,提高視頻處理的效率。
本發明采用的技術方案是:
一種基于深度學習多層次分割新聞視頻的通用方法,其特征在于,包括以下步驟:
1、訓練數據的準備、擴張及預處理
本文應用兩種不同的深度網絡模型進行訓練檢測,需要大量的logo數據以及人臉數據進行訓練,因此,需要針對不同的數據類型,進行不同方式的數據獲取及擴張,增強訓練模型的魯棒性,提高檢測效果。具體步驟如下:
(1.1)獲取數據
首先將獲取到的視頻拆分成幀序列。
本文針對人臉圖片的特性,提出一種提取人臉正樣本和負樣本的方法:設定一個固定大小M*M的滑動窗口在獲取的人臉圖片上進行滑動,當窗口與人臉的交集大于60%,視為正樣本;本文為保證網絡能夠收斂,負樣本之間需要存在共性,故提出只有當窗口與人臉交集在15%-30%之間,才將其視為負樣本。
對于logo區域的提取,本文采用固定大小n*n的矩形窗口在視頻logo處統一進行截取,得到logo的圖片。
(1.2)數據擴張
由于訓練深度網絡需要大量的數據,僅將視頻中獲取到的圖片用于訓練遠遠不夠。于是需要對訓練數據進行不同方式的數據擴張,加大數據量,提高訓練及檢測效果。
針對新聞logo圖片,我們對其采用圖像銳化的方式進行處理同時保留了銳化之前的logo圖像。本方法擴大了數據量,加快網絡的收斂速度,從而提高了檢測效果。
針對人臉圖片,本文對(1.1)中得到的所有人臉樣本進行不同比例的裁剪,然后放大到原來尺寸M*M,這樣不僅會加強人臉的細節部分,還會將原來數據集擴大。針對主持人頭部扭轉的情況,本實驗將所有人臉數據進行左右各45度方向的旋轉,這樣不僅增強了訓練結果的旋轉魯棒性,又將數據擴大。
(1.3)預處理
本文將logo圖片及人臉樣本進行同樣的去均值處理,求得所有圖片像素矩陣的均值,作為中心,然后將輸入圖片減去均值,再做后續操作。去均值操作能夠進一步提高訓練效果。
(1.4)標注數據集
最后,將(1.1)(1.2)(1.3)步驟得到的人臉數據分為正樣本和負樣本兩類進行標注;對于得到的logo圖片,根據需要檢測的類別,對其進行標注。
2、兩類深度網絡的構建與訓練
本文涉及到logo圖片的識別及主持人臉的檢測,所以根據圖像類型的不同,大小的不同,特征的不同,采用兩種不同的網絡進行訓練,以便得到最優的檢測結果。
基于logo圖片形狀規則,大小與種類固定的特性,本文提出,對構建的網絡,根據需要分割的視頻類數O,預先設置輸出為O類的分類器。相比之下,人臉的訓練數據包含了更大的差異性,需要采用更加深度的網絡進行訓練,對于人臉網絡的分類器,本文只需要對人臉做出檢測(只要檢測出是否存在人臉即可),故采用二分類的分類器。
綜上所述,本文提出采用兩種不同的深度網絡進行訓練與檢測,具體內容如下:
(2.1)構建logo卷積神經網絡。
卷積神經網絡整體包含了輸入層、卷積層、池化層、全連接層以及最后的softmax分類器。
網絡輸入層的輸入固定為n*n像素點大小。共由兩層卷積層,兩層Max池化層交替組合而成,然后連接全連接層,最后一層本文將根據頻道種類數O,設計出輸出為O類的softmax分類器進行分類。
(2.2)構建人臉卷積神經網絡
對于人臉卷積神經網絡輸入層的輸入固定為M*M像素點大小。人臉網絡是由四層卷積層,兩層Max池化層交替連接而成的,最后一層的卷積層選擇用兩個特征核進行全卷積滑動,輸出兩張全局特征圖,進而輸出至softmax二分類器中進行檢測。
(2.3)訓練卷積神經網絡。
向兩個構建完成的網絡輸入訓練圖片,根據卷積神經網絡算法逐層計算后,得到輸出值,反向傳播,計算每個輸出值與對應圖片所屬類別的誤差,根據最小誤差準則,修正網絡每層的參數,將誤差最小化,逐漸使訓練的網絡收斂,分別得到logo識別模型以及人臉檢測模型用于以后的環節當中。
3、頻道種類的識別
由于視頻種類多樣,想找到一種通用的方法對所有種類的視頻進行事件的自動分割并不可能,因此需要大量的人力用于手動分割視頻事件,這樣不僅消耗了大量的人工成本,而且效率也不高。
不同新聞視頻之間存在明顯的差異性及共同點。新聞視頻的差異性表現在不同頻道的主持人位置及大小范圍的各不相同。針對差異性,本文率先提出一種預先識別頻道類別,根據頻道類別再進行主持人播報場景檢測的方法。另一方面新聞視頻的共性表現在:1、所有新聞視頻logo出現的位置相同;2、所有新聞均是播報環節與事件環節依次更替進行。針對這些共性,本文提出:1、根據每個新聞視頻logo位置的不變性,即可統一對所有新聞視頻固定位置范圍進行logo的識別。2、只要識別出主持人播報環節即可將左右視頻段視為事件環節,進而實現新聞視頻的自動分割。
本方法利用(2.3)訓練生成的logo識別模型對待檢測視頻的固定矩形框區域(也就是logo所在的n*n像素區域)進行頻道類別的識別。logo卷積神經網絡預先識別出頻道類別,將識別后的頻道輸入至主持人臉檢測環節當中,實現后續操作。本方法能夠在保證分割效率的基礎上,使分割變得更加便捷、高效,能夠對更多頻道的視頻進行自動分割,提高分割視頻方法的通用性。
4、主持人場景的檢測及分割
本文根據頻道識別后的視頻特點進行進一步的場景檢測。場景檢測根據頻道特性,分為初步檢測和二次篩選兩個部分。具體內容如下:
(4.1)基于深度網絡的初步檢測
不同頻道的主持人位置截然不同,由于鏡頭的距離導致主持人臉的范圍也大不相同,故本文基于這一新聞視頻特性提出,根據頻道類別O提前分別設定好O類固定位置及固定大小的人臉檢測矩形框P1,P2,P3…….PO,采用(2.3)中訓練得到的人臉檢測模型對矩形框內的人臉進行檢測。如果模型檢測為人臉,則初步判斷為主持播報場景,進而能夠得到多個主持播報場景的候選視頻段。
(4.2)基于顏色特征及時間閾值的交叉篩選
針對在同一視頻中主持人穿著不變以及主持環節持續時間的規律,同時兼顧視頻檢測分割的實時性,旨在視頻播放完成后便得到最終的分割片段,故本方法提出采用顏色特征和經過人為大量觀察后所得到的時間閾值T,對(4.1)中初步篩選得到的候選視頻段進行交叉篩選,在保證實時性的基礎上,進一步剔除干擾視頻段。交叉篩選內容具體如下:首先,依據O類新聞頻道,在頻道檢測過程中為不同節目的主持人的衣著位置人工設定好固定大小的O類矩形框Q1,Q2,Q3……QO以將衣著范圍確定;然后,對矩形框內區域進行RGB空間的顏色特征提取,計算每個候選視頻段中的平均顏色特征向量;最后,利用歐式距離度量每個視頻段的平均顏色特征向量與同一視頻中的所有候選視頻段的平均顏色特征向量之間的距離,經過大量實驗總結觀察得出,當距離小于閾值L且檢測出的視頻段持續時間均大于時間閾值T時,則最終確認該視頻段為主持人播報場景。
最終,本文通過基于兩類深度網絡的初篩選以及基于顏色特征和時間閾值的交叉檢測,自動篩選得到了最終的主持人播報場景。
(4.3)視頻分割
基于新聞視頻之間存在的共性,本文提出在檢測出主持人播報場景后,可以對整個視頻中主持播報場景時域兩邊的視頻段自動判斷為新聞事件場景,從而進行時域上的分割,最終實現了一種基于深度學習多層次分割新聞視頻的通用方法。本方法能夠達到非常高的準確率,并且對于多類頻道的新聞有著很好的效果,不僅節省了手動分割視頻場景的人力成本,而且還極大地提高了分割新聞視頻場景的效率。
有益效果
1、本發明根據訓練數據的不同及其特性,采用針對性的數據處理方法,能夠為接下來的檢測提供幫助,進而提高分割準確率。
2、本發明依據不同新聞之間的差異性以及共同性,對新聞視頻進行先類別、后場景的分層次檢測。這樣遠遠提高了分割方法的普適性,大大降低了工作人員手動分割新聞視頻的人工成本。
3、本發明首先采用兩類深度網絡進行初步篩選,然后結合傳統特征與新聞視頻的時長特性進行二次交叉篩選,進而實現新聞視頻自動分割的通用方法。在保證時效性的基礎上,能夠進一步得到更準確的分割結果。
附圖說明
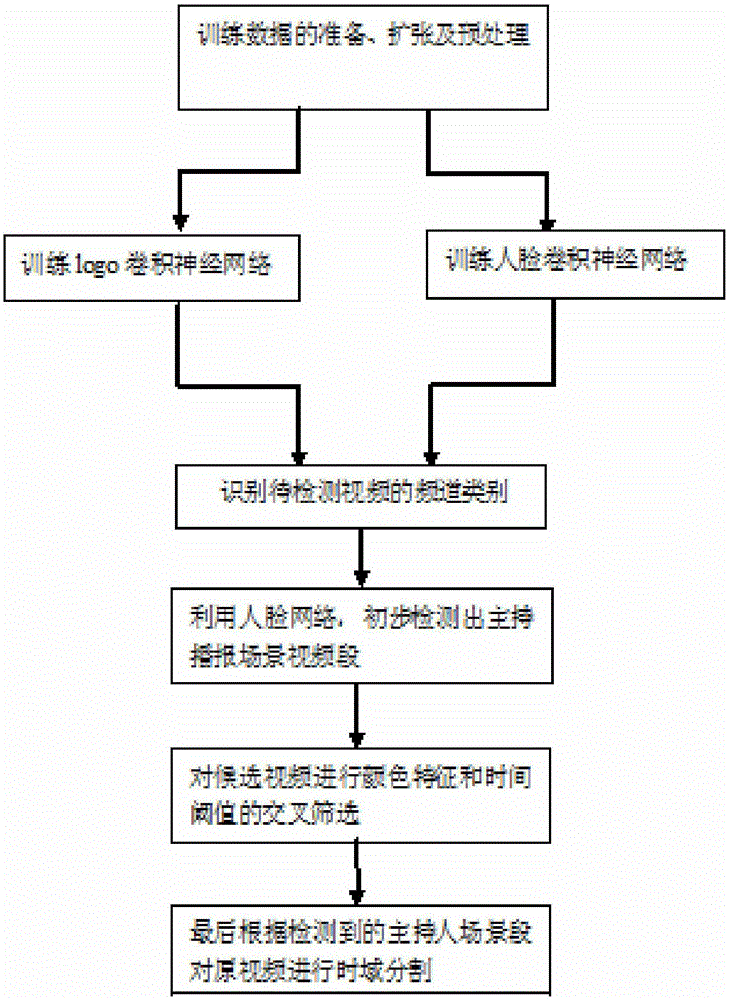
圖1是本發明的整體流程圖;
具體實施方式
圖1是本發明的整體流程圖,下面為本發明的具體實施步驟:
1、訓練數據的準備、擴張及預處理
為了使訓練模型的收斂程度更好,更快,檢測準確率更高,需要將現有的視頻內數據進行針對性的數據擴張以及預處理提高檢測效果。具體訓練數據準備及數據預處理的步驟如下:
(1.1)初步獲取logo及人臉訓練數據
本實驗選取九類新聞視頻進行測試,分別為:CCTV1、CCTV2、CCTV3、CCTV4、CCTV5、CCTV9、CCTV13、上海電視臺、遼寧電視臺。將所有實驗視頻拆分成幀序列,然后獲取每幀logo相同位置處的28*28的矩形區域。
本實驗采取一種固定的提取人臉正樣本和負樣本的方法:設定一個60*60像素區域的滑動窗口,在圖片上進行步長為20像素的滑動,當窗口與人臉的交集大于60%,視為正樣本;當窗口與人臉交集在10%-30%之間,視為負樣本。
(1.2)數據擴張
針對視頻中的logo圖片,本文采用銳化的方式對圖片進行處理,另外將處理前的logo圖像進行保留,這樣不僅提高了訓練的魯棒性,還將原來的數據集擴大為原來的兩倍,進而加快模型收斂。
針對人臉樣本,本實驗固定(1.1)中所有獲得的正負人臉樣本的左上角(0,0)點對其裁剪,剪裁為原圖的70%、80%、90%三類大小,然后再放大為原來(60*60)的尺寸,這樣不僅會加強人臉的細節部分,提高訓練模型的魯棒性,還會將原來數據擴大,加強模型的收斂,防止訓練模型欠擬合;盡管播報環節的主持人所處位置不變,可是仍會有一些面部表情的變化,以及頭部的扭轉,故本實驗將所有的人臉數據進行左右各45度方向的旋轉,這樣增強了訓練數據的旋轉魯棒性,又將數據擴大。
(1.3)預處理
將得到的圖像數據進行去均值處理,求得所有圖片像素矩陣的均值作為中心,然后將輸入圖片減掉均值,再做后續的操作。去均值能夠進一步提高檢測效果。
(1.4)標注數據集
本文選擇九類新聞視頻作為試驗對象,進而將得到的logo數據分為九類,依次為CCTV1、CCTV2、CCTV3、CCTV4、CCTV5、CCTV9、CCTV13、上海電視臺、遼寧電視臺;將得到的人臉數據分為正樣本和負樣本兩類,最后,對所有數據進行標注。
2、兩類深度網絡的構建與訓練
將步驟1中標注好的圖像數據輸入至卷積神經網絡中進行訓練,本文采用兩種深度網絡分別對多類logo圖片以及人臉圖片的所有正負樣本進行訓練。方法具體步驟如下:
(2.1)構建及訓練logo的卷積神經網絡。
將(1.4)中標注好的九類logo數據均作為訓練數據,最后得到標注好的訓練數據共18000張,每一類圖片2000張左右。高斯隨機初始化卷積神經網絡參數。logo卷積神經網絡的網絡結構是:使用28*28像素的輸入圖片,兩層卷積層,兩層池化層,每批次訓練圖片為128張。第一層卷積層由6個5*5的卷積核構成,每個卷積核與輸入圖片的局部5*5區域相連進行滑動卷積,卷積公式如下:
其中σ為激活函數,Mat為圖像矩陣,表示卷積運算,W表示卷積核,b表示偏移量。
其中激活函數公式如下(這里取Relu激活函數):
σ=Max(0,x) (2)
卷積核在圖片上滑動,輸出6張24*24的特征圖,卷積核的目的是進行不同方式的卷積得到不同特性的特征。然后連接Max池化層進行降維,減少數據量,其中Max池化層的卷積核為2*2,滑動步長為2,得到6張12*12的特征圖。第二層卷積層包含16個5*5的卷積核,故滑動卷積后得到16張8*8的特征圖,再連接一層Max池化層,得到16張4*4的特征圖。為了將局部特征融合在一起形成全局特征,獲取更大的信息量,所以將得到的特征圖輸入至全連接層。網絡的最后連接一個輸出為九類的softmax分類器進行分類,根據上一層全連接層得到的結果,softmax分類器輸出該圖片屬于某一類別的概率值,概率值最大者即為頻道的正確類別。至此logo的卷積神經網絡構建完畢。
訓練過程:將每個圖像訓練數據通過卷積神經網絡算法進行逐層計算后,得到輸出值,計算獲取每個輸出值與對應的圖像訓練數據所屬類別的誤差。根據最小誤差準則,通過所述誤差進行逐層修正所述深度卷積神經網絡分類器中各層參數。當誤差逐漸下降趨于穩定,判斷網絡已經收斂,訓練結束,生成檢測模型。
(2.2)構建及訓練人臉卷積神經網絡。
卷積神經網絡使用60*60像素的輸入圖片,每批次訓練圖片256張,共四層卷積層,第一層卷積層采用32個卷積核與原圖5*5區域進行滑動卷積,得到32張56*56的特征圖,然后連接一個2*2像素的Max池化層降低特征圖的數據量,得到32張28*28的特征圖,將其輸入至第二層卷積層,采用64個卷積核與上一層特征圖進行5*5區域滑動卷積,得到64張24*24的特征圖,再次用Max池化層降低數據量,得到64張12*12的特征圖。第三層卷積層,采用64個3*3的卷積特征核滑動卷積,得到64張10*10的特征圖,將結果直接輸入到第四層卷積層中。最后一層卷積層用2個卷積核分別進行一個10*10的全卷積,進而得到最后的兩張特征圖。將兩張特征圖輸入至最后的softmax層進行檢測。至此人臉卷積神經網絡構建完成。訓練過程依照(2.1)中訓練過程進行。
3、頻道種類的識別
由于新聞頻道非常之多,故本實驗選取九類新聞節目進行實驗,對九類新聞視頻的固定位置處的logo圖片進行識別分類。首先,將待檢測視頻輸入至logo檢測算法中,根據新聞視頻logo固定不變的特性,預先設定視頻的左上角28*28區域處的矩形框,用訓練生成的logo識別模型對矩形框進行識別分類,根據softmax層輸出分類概率大小,概率最高的一類即為最終識別的頻道類別。通過本文設計的新聞logo識別方法能夠提前識別出頻道的類別,將識別分類后的頻道輸入至對應頻道的主持人臉檢測通道中去。
正是因為本文提出的基于深度網絡預先對頻道logo進行識別,才能夠提高識別效率,使分割方法變得更加便捷、通用,能夠使其對更多種類的新聞視頻進行分割,提高了分割視頻方法的通用性。
4、主持人場景的檢測及分割
(4.1)基于深度網絡的初步檢測
根據3中得到的識別結果,將識別分類后的九類視頻輸入至對應的主持播報檢測通道中,不同的通道檢測的區域不同,如:CCTV13中盡管主持背景復雜,但是根據場景特點,該節目的主持人的面部始終處于橫坐標720<X<810,縱坐標170<Y<250之間。具體步驟如下:
首先,根據logo卷積神經網絡的輸出類別,將輸出視頻輸入至對應類別的檢測通道中;然后,每個通道依據各自頻道主持人的位置及面部大小,提前設置該通道的矩形檢測框,足以將主持人臉完全包圍(如步驟3中識別出頻道類別為CCTV13,則將其輸入至CCTV13的主持播報環節檢測當中,然后預先在CCTV13的檢測通道中設置720<X<810,170<Y<250像素范圍內,設置90*80尺寸的矩形框);最后,對輸入通道后的視頻矩形框處,均采用(2.2)中訓練好的人臉模型進行檢測,根據模型得到的最后一層輸出的特征圖,將檢測到的特征圖進行歸一化以及二值化處理,計算矩形框區域內特征數值為1的個數,進行累加,如果數值大于該頻道預先設定好的閾值U,(節目不同,閾值也不相同)則初步檢測為主持人播報環節,進而從整個視頻中獲得多個候選主持播報環節的視頻段。
(4.2)基于顏色特征及時間閾值的交叉篩選
針對在同一視頻內每個新聞主持人衣著固定的特點,以及主持播報環節持續時間的規律,另一方面,考慮到檢測視頻的實時性,希望視頻播放完成后便得到分割片段,故采用顏色特征與時間閾值交叉篩選的方式進一步從候選視頻段中得到最終的主持播報環節。
首先,對于不同的新聞頻道,預先手動設置固定大小及位置的衣服矩形框,每一類頻道的衣服矩形框位置及大小固定,然而不同頻道的衣服位置及大小不同;然后,對(4.1)中獲取的候選視頻段,進行衣服矩形框處的顏色特征提取,提取公式如下:
式中pi,j表示彩色圖像第i個顏色通道分量中灰度為j的像素出現的概率,N表示衣服矩形框中的像素個數,通過上述公式求出候選視頻段中各自的平均特征向量;最后,利用歐式距離度量每個候選視頻段的平均特征向量與同一視頻內的所有候選視頻段的平均特征向量之間的距離,經過大量的實驗觀察所得,當歐式距離差值小于給定距離閾值0.4,同時視頻段的持續時間大于給定的時間閾值5秒,則最終將其判斷為主持播報場景視頻段。
(4.3)分割視頻
通過步驟(4.1)(4.2)分別經過深度網絡的初步檢測,以及顏色特征和時間閾值的二次交叉篩選,得到了最終的主持人播報場景。根據新聞視頻之間的共性:主持播報場景與新聞事件場景之間均是依次進行的,故可以判斷出主持播報場景左右兩個時間區域內的視頻均為新聞事件場景,最終,便可將主持播報環節與新聞事件環節分割開。
具體效果說明
本實驗是一種基于深度學習多層次分割新聞視頻的通用方法。本文將待檢測的完整新聞視頻輸入至實驗系統中,即可在無需人為干預的情況下,能夠自動對待檢測的多類新聞視頻進行有效的時域分割,將新聞事件與主持播報環節分割開。本方法處理的過程完全自動同時能夠達到很好的時效性,能夠在新聞視頻時長的1.5倍時間內處理完成;而且對于大量的實時視頻有著較好的分割效果,經過大量實驗可得視頻分割的準確率能夠達到95.2%,完全可以代替人工來分割新聞視頻,進而節省大量人力成本,極大地提高了工作效率。
- 還沒有人留言評論。精彩留言會獲得點贊!