一種視頻節目推薦方法及視頻節目推薦裝置與流程
本發明屬于信息處理領域,尤其涉及一種視頻節目推薦方法及視頻節目推薦裝置。
背景技術:
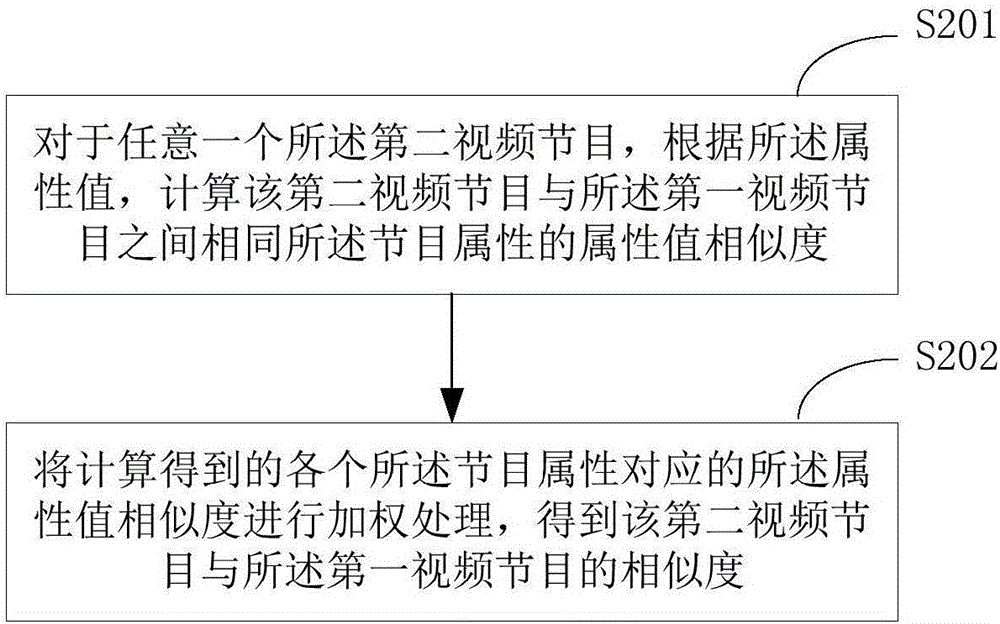
:基于內容的推薦算法(Content-basedRecommendations,CB)是目前最流行的一種推薦方法。它根據用戶過去喜歡的產品(item),為用戶推薦與之相似的其他產品。例如,一個推薦飯店的系統可以依據某個用戶之前喜歡的多個烤肉店,從而為他推薦其他烤肉店。在真實的應用場景中,每個item往往都會有一些可以描述其特征內容的屬性。這些屬性通常可以分為兩種:結構化的屬性與非結構化的屬性。包含結構化屬性的數據可以直接被分析處理,但是,對于包含非結構化屬性的數據而言,例如一篇文章數據,則先要把它轉化為結構化屬性的數據后,才能加以分析使用。由于CB算法并非專門應用于視頻節目的推薦算法,因此,根據CB算法的原理來推薦視頻節目,則需要先將視頻節目的內容轉化為具體的結構化數據。在該過程中,由于視頻節目的內容復雜,視頻畫面變化多端,因此,計算復雜度過大,容易出現誤差,從而導致視頻節目推薦的效果難以滿足用戶的實際需求。技術實現要素:本發明實施例的目的在于提供一種視頻節目推薦方法及視頻節目推薦裝置,旨在解決現有視頻節目推薦方法中計算復雜度過大,容易出現誤差,從而導致視頻節目推薦的效果難以滿足用戶實際需求的問題。本發明實施例是這樣實現的,一種視頻節目推薦方法,包括:獲取多個視頻節目,所述多個視頻節目包括第一視頻節目以及多個第二視頻節目,所述第一視頻節目為用戶最近一次觀看的視頻節目,所述第二視頻節目為待推薦節目;獲取每個所述視頻節目中各節目屬性的屬性值;根據所述屬性值,分別計算所述第一視頻節目與每個所述第二視頻節目之間的相似度;將所述相似度最大的一個所述第二視頻節目輸出為推薦節目。本發明實施例的另一目的在于提供一種視頻節目推薦裝置,包括:第一獲取單元,用于獲取多個視頻節目,所述多個視頻節目包括第一視頻節目以及多個第二視頻節目,所述第一視頻節目為用戶最近一次觀看的視頻節目,所述第二視頻節目為待推薦節目;第二獲取單元,用于獲取每個所述視頻節目中各節目屬性的屬性值;計算單元,用于根據所述屬性值,分別計算所述第一視頻節目與每個所述第二視頻節目之間的相似度;推薦單元,用于將所述相似度最大的一個所述第二視頻節目輸出為推薦節目。本發明實施例中,只需根據視頻節目中各個節目屬性的屬性值,就能計算出每個第二視頻節目與用戶最近一次觀看的視頻節目之間的相似度,并將相似度最大的第二視頻節目作為推薦節目,因此,該推薦節目能夠最大程度上地符合用戶當前的興趣愛好,提高了視頻節目推薦的準確性。此外,相對于CB算法,由于本發明實施例提供的視頻節目推薦方法無須將視頻節目的內容轉化為具體的結構化數據,因此,降低了計算復雜度以及計算誤差出現的可能性,由此提高了節目的推薦效率,滿足了用戶對節目推薦的實際需求。附圖說明圖1是本發明實施例提供的視頻節目推薦方法的實現流程圖;圖2是本發明實施例提供的視頻節目推薦方法S103的具體實現流程圖;圖3是本發明實施例提供的視頻節目推薦方法S201的具體實現流程圖;圖4是本發明實施例提供的視頻節目推薦方法S301的具體實現流程圖;圖5是本發明實施例提供的視頻節目推薦方法S302的具體實現流程圖;圖6是本發明實施例提供的視頻節目推薦裝置的結構框圖。具體實施方式為了使本發明的目的、技術方案及優點更加清楚明白,以下結合附圖及實施例,對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅僅用以解釋本發明,并不用于限定本發明。圖1示出了本發明實施例提供的視頻節目推薦方法的實現流程,詳述如下:在S101中,獲取多個視頻節目,所述多個視頻節目包括第一視頻節目以及多個第二視頻節目,所述第一視頻節目為用戶最近一次觀看的視頻節目,所述第二視頻節目為待推薦節目。在本實施例中,視頻節目播放系統能夠為用戶推薦視頻節目。在該視頻節目播放系統的內部,預設有包含多個視頻節目的視頻節目列表,視頻節目列表中記載了每個視頻節目的片名。視頻播放系統對系統中運行的各個進程進行監聽,當監聽到視頻播放系統中的視頻播放程序被調用至前臺運行時,表示用戶打開了視頻播放界面并準備瀏覽節目列表或準備觀看視頻節目,因此,該視頻播放系統讀取列表中可播放的所有視頻節目的片名。特別地,視頻播放系統還能夠從外部設備中獲取或更新視頻節目列表。例如,當滿足預設的時間間隔時,從云端服務器中獲取更新的視頻節目列表。當用戶利用視頻播放系統觀看了一個視頻節目后,視頻播放系統在獲取視頻節目列表中各個視頻節目的同時,還能夠基于用戶的播放記錄,準確獲取該用戶最近一次觀看的一個視頻節目的片名,該視頻節目稱為第一視頻節目。在視頻節目列表中,除第一視頻節目之外的所有視頻節目均為第二視頻節目,每個第二視頻節目都有可能被推薦至用戶,因此稱為待推薦節目。在S102中,獲取每個所述視頻節目中各節目屬性的屬性值。對于視頻節目列表中的每個視頻節目,可從本地數據庫或云端服務器中查詢到該視頻節目在各個節目屬性上所對應的屬性值。作為本發明的一個實施例,所述節目屬性包括以下至少一項:導演屬性、演員屬性、編劇屬性、片名屬性、類型屬性、國家屬性、語言屬性以及年份屬性。每個節目屬性代表視頻節目中的一類基本信息,除了上述列出的八個基本節目屬性之外,視頻節目的節目屬性還可以包括制作人屬性、翻譯屬性、效果屬性、公司屬性、音樂類型屬性、背景年份屬性等。在確定每一個節目屬性后,還要獲取該節目屬性的屬性值。例如,當視頻節目《變形金剛》的節目屬性為導演屬性時,該節目屬性的屬性值為邁克爾·貝。優選地,在本實施例中,需要獲取上述八個基本節目屬性的屬性值。在特定需求的場景之下,還可以根據實際所需,獲取上述八個基本節目屬性之中的一個或多個屬性值,或者,獲取除上述八個基本節目屬性之外的其他節目屬性的屬性值。在S103中,根據所述屬性值,分別計算所述第一視頻節目與每個所述第二視頻節目之間的相似度。對于任意一個第二視頻節目,其各個節目屬性在第一視頻節目中均存在,因此,通過確定第一視頻節目與第二視頻節目之間每個節目屬性的屬性值之間的特征差異,可得知第一視頻節目與每個第二視頻節目的關聯程度,以相似度來量化二者之間的關聯程度。作為本發明的一個實施例,圖2示出了本發明實施例提供的視頻節目推薦方法S103的具體實現流程,詳述如下:在S201中,對于任意一個所述第二視頻節目,根據所述屬性值,計算該第二視頻節目與所述第一視頻節目之間相同所述節目屬性的屬性值相似度。獲取第二視頻節目與所述第一視頻節目之間相同的一個或多個節目屬性,則每個相同的節目屬性在第一視頻節目與在第二視頻節目中的屬性值分別稱為第一節目屬性值以及第二節目屬性值。例如,當第一視頻節目與任意一個第二視頻節目中的國家屬性為相同節目屬性,則獲取第一視頻節目與第二視頻節目中該國家屬性對應的屬性值,如“中國”、“美國”。若一個第二視頻節目與第一視頻節目之間相同的節目屬性有八個,則存在八個第一節目屬性值,分別為A、B、C、D、E、F、G、H,在該第二視頻節目中,對應的第二節目屬性值也有八個,分別為a、b、c、d、e、f、g、h。在每個相同屬性之間,計算屬性值相似度。即判斷第一視頻節目中第一節目屬性值與第二視頻節目中第二節目屬性值的關聯程度。在上述例子中,計算屬性值相似度的過程具體如下:計算A與a的屬性值相似度、B與b的屬性值相似度、C與c的屬性值相似度、D與d的屬性值相似度、E與e的屬性值相似度、F與f的屬性值相似度、G與g的屬性值相似度以及F與f的屬性值相似度,因此,在每個視頻節目中都具有上述八個基本節目屬性前提下,對于每個第二視頻節目,可得到分別對應第一視頻節目中八個屬性值的八個屬性值相似度。對于僅為線性相關,而不可向量化的兩個屬性值而言(如兩個年份屬性的屬性值),如果兩個屬性值的大小越接近,則其屬性值相似度越高。作為本發明的一個實施例,如圖3所示,上述S201具體如下:在S301中,當相同節目屬性為可向量化的節目屬性時,對所述相同節目屬性分別在所述第一視頻節目與該第二視頻節目中的所述屬性值進行分詞處理,以得到每個所述屬性值對應的多個分詞。在本實施例中,在上述八個基本節目屬性的前提下,第一節目屬性值與第二節目屬性值是可向量化的相同節目屬性的屬性值,如導演屬性、演員屬性、編劇屬性、片名屬性等。如果兩個屬性值之間相同的特征越多,則兩個屬性值越相關。由于屬性值的每個特征可由屬性值內部的每個詞語來體現,因此,為了提取第一節目屬性值中的多個特征,先對屬性值進行分詞處理。作為本發明的一個實施例,如圖4所示,上述S301具體如下:在S401中,對于所述相同節目屬性分別在所述第一視頻節目與該第二視頻節目中的每個所述屬性值,當該屬性值中包含有標點符號時,以所述標點符號為分詞拆分點,對該屬性值進行分詞,以得到該屬性值對應的多個分詞。在S402中,當該屬性值中未包含有任何標點符號時,獲取預設的標準詞庫中的各個詞語。在S403中,判斷該屬性值是否包含所述標準詞庫中的至少一個所述詞語;若該屬性值包含所述標準詞庫中的至少一個所述詞語,則將其包含的每個詞語作為該屬性值對應的多個分詞。即,在本實施例中,對屬性值進行分詞時,分詞過程包括以下兩種情況:情況一:若屬性值中包含有標點符號,則直接以所述標點符號為拆分點。當檢測到第一個標點符號出現時,以該標點符號之前的所有字符作為一個分詞;若確定當前檢測到的標點符號為最后一個標點符號,則以該標點符號之后的所有字符作為一個分詞;若當前檢測到的標點符號并非為最后一個標點符號,則將該標點符號與下一個標點符號之間的所有字符作為一個分詞。其中,標點符號包括空格符號。例如,對于第一視頻節目中的演員屬性,其屬性值為“張涵予、鄧超、袁文康、湯嬿、王寶強”,則以該屬性值中的頓號“、”為拆分點,從而得到該屬性值對應的多個分詞為“張涵予”、“鄧超”、“袁文康”、“湯嬿”、“王寶強”。情況二:若屬性值中未包含有任何標點符號,則以標準詞庫中的各個詞語為比較對象,若該屬性值中包含有標準詞庫中的詞語,則將該詞語作為該屬性值中的一個分詞。由于屬性值中的同一個字符可能會匹配標準詞庫中的不同詞語,因此,將該字符匹配的所有詞語都記錄下來,一并作為該屬性值中的分詞。例如,對于第一視頻節目中的片名屬性,其屬性值為“變形金剛”,則應當采用上述情況二中的分詞算法。該屬性值匹配到標準詞庫中的詞語有“變形金剛”、“金剛”、“變形”,雖然屬性值中的兩個字符“金剛”匹配到了兩個不同的詞語(分別為“變形金剛”和“金剛”),但依照該算法的原理中,需要將匹配到的所有詞語記錄下來,因此,該屬性值對應的多個分詞應當為“變形金剛”、“金剛”、“變形”。在S302中,在一個所述屬性值對應的多個分詞中,對每個所述分詞進行排序,并為每個所述分詞分配權重,以使排序在前的分詞的權重大于或等于排序在后的分詞的權重。作為本發明的一個實施例,圖5示出了本發明實施例提供的視頻節目推薦方法S302的具體實現流程,詳述如下:在S501中,在一個所述屬性值對應的多個分詞中,依照每個所述分詞在該屬性值中出現的先后次序,對各個分詞進行排序,以得到分詞序列。在S502中,在所述分詞序列中,若存在包含有至少兩個相同起始字符的兩個分詞,則將其中字符長度較大的分詞排在字符長度較小的分詞前面。在S503中,依照所述分詞的排序順序,為每個所述分詞分配權重,以使排序在前的分詞的權重大于或等于排序在后的分詞的權重。在S504中,生成權重列表,所述權重列表包含每個所述分詞對應的所述權重。具體地,在本實施例中,依照每個分詞在屬性值中出現的先后次序,對各個分詞進行排序。若兩個分詞中包含有相同的起始詞語,則將其中字符長度較大的分詞排在字符長度較小的分詞前面。此后,依照各個分詞的排序順序,分配權重。繼續以上述例子中“變形金剛”所對應的多個分詞為例,該屬性值“變形金剛”對應的多個分詞為“變形金剛”、“金剛”和“變形”。由于分詞“變形金剛”與“變形”相對于分詞“金剛”來說,在屬性值“變形金剛”中較先出現,因此,“金剛”的排序為三個分詞中的最后一個。并且,分詞“變形金剛”與分詞“變形”均包含有相同的起始詞語,而分詞“變形金剛”的字符長度為4個漢字符,比分詞“變形”的字符長度長,因此,分詞“變形金剛”應當排在“變形”的前面。根據該排序過程可知,屬性值“變形金剛”對應的分詞排序序列為{“變形金剛”,“變形”,“金剛”}。此時,為該序列中的各個分詞分配一個權重,并且權重的大小依照排序順序依次遞減或保持不變,從而得到對應該排序序列的一個權重列表。特別地,在本實施例中,當屬性值對應的分詞個數在五個以內時,依照各個分詞的順序,為每個分詞分配的權重依次為5、4、3、2、2,因此,屬性值“變形金剛”所對應的權重列表如表1所示:表1分詞權重變形金剛5變形4金剛3在S303中,在每一個所述屬性值中,根據各個所述分詞的所述權重,生成該屬性值對應的一個特征向量。具體地,在每一個所述屬性值中,根據各個所述分詞的所述權重,生成該屬性值對應的一個特征向量,所述特征向量中的每個元素值依次為所述權重列表中每個所述分詞對應的所述權重。在本實施例中,以向量化的形式表示第一節目屬性值。在上述八個基本節目屬性的屬性值之中,除了年份屬性的屬性值外,每個第一節目屬性值均能夠表示為一個特征向量。以權重列表中每個分詞對應的權重作為特征向量中的一個元素值,以每個分詞的排序作為特征向量中元素值的排序。因此,在上述例子中,屬性值“變形金剛”對應的特征向量為{5,4,3}。同理,以向量化的形式表示第二節目屬性值,可得到第二節目屬性值對應的特征向量。在S304中,計算第一特征向量與第二特征向量之間的余弦相似度,所述第一特征向量與所述第二特征向量為所述相同節目屬性在所述第一視頻節目與該第二視頻節目中的所述屬性值所分別對應的所述特征向量。余弦相似度S的計算公式為:其中,xa表示第一特征向量的第a個元素值;yb表示第一特征向量的第b個元素值;m、n分別表示第一特征向量、第二特征向量中的元素總數;Sj,k表示滿足第一條件的各個xj·k值的總和,第一條件具體為:在第一特性向量中第j個元素值xj對應的分詞與第二特性向量中第k個元素值yk對應的分詞相同,且j≤n,k≤m。表2示出了第一節目屬性值為“變形金剛Ⅰ”的情況下,該屬性值對應的權重列表,表3示出了第二節目屬性值為“變形金剛Ⅳ”的情況下,該屬性值對應的權重列表。根據上述權重列表可知,第一特征向量為{5,4,3,2},第二特征向量為{5,4,3,2},且第一特征向量中的第1、2、3個元素分別與第二特征向量中的第1、2、3個元素對應的分詞相同,因此,根據上述計算公式可得“變形金剛Ⅰ”與“變形金剛Ⅳ”的余弦相似度為:在S305中,將所述余弦相似度輸出為該第二視頻節目與所述第一視頻節目之間所述相同節目屬性的屬性值相似度。作為本發明的一個實施例,上述S201還包括:當相同節目屬性為不可向量化的節目屬性時,通過預設公式計算該第二視頻節目與所述第一視頻節目之間不可向量化的所述相同節目屬性的屬性值相似度Sy,所述預設公式包括:其中,所述a1與所述b1為不可向量化的所述相同節目屬性分別在所述第一視頻節目與該第二視頻節目中的屬性值。在本實施例中,在上述八個基本節目屬性的前提下,僅存在年份屬性為不可向量化的節目屬性。當第一節目屬性值與第二節目屬性值均為年份屬性的屬性值時,第一節目屬性值與第二節目屬性值均為具體的年份數值。作為本發明的一個實施示例,若第一視頻節目為《變形金剛》,第二視頻節目為《金剛》,則對于第一視頻節目中的年份屬性,其屬性值a1為2007,對于該第二視頻節目中的年份屬性,其屬性值b2為2006,因此,兩個屬性值之間的屬性值相似度Syear為:在S202中,將計算得到的各個所述節目屬性對應的所述屬性值相似度進行加權處理,得到該第二視頻節目與所述第一視頻節目的相似度。由于第一視頻節目包含有八個第一節目屬性值,因此,得到每個第一節目屬性值與第二視頻節目中對應的第二節目屬性值之間的屬性值相似度后,需要匯總計算出第一視頻節目與第二視頻節目之間的一個總的相似度。該相似度Stotal根據如下公式進行計算:Stotal=Wa*SCasts+Wd*Sdirector+Ww*Swriters+Wt*Stitle+Wy*Syear+Wg*Sgenres+Wc*Scontury+Wl*Slanguage其中,SCasts、Sdirector、Swriters、Swriters、Stitle、Syear、Sgenres、Scountry、Slanguage分別表示第一視頻節目與第二視頻節目在演員屬性、導演屬性、編劇屬性、片名屬性、年份屬性、類型屬性、國家屬性以及語言屬性中的屬性值相似度,Wa、Wd、Ww、Wt、Wy、Wg、Wc以及W1均為加權因子,且滿足以下關系:Wa+Wd+Ww+Wt+Wy+Wg+Wc+Wl=1在S104中,將所述相似度最大的一個所述第二視頻節目輸出為推薦節目。對于視頻節目列表中的每一個第二視頻節目,均可以根據上述計算原理得出其與第一視頻節目之間的相似度。在所有視頻節目之中選出相似度最大的一個第二視頻節目,將其顯示在用戶的顯示屏中,以作為推薦節目,推薦至該用戶。本發明實施例中,只需根據視頻節目中各個節目屬性的屬性值,就能計算出每個第二視頻節目與用戶最近一次觀看的視頻節目之間的相似度,并將相似度最大的第二視頻節目作為推薦節目,因此,該推薦節目能夠最大程度上地符合用戶當前的興趣愛好,提高了視頻節目推薦的準確性。此外,相對于CB算法,由于本發明實施例提供的視頻節目推薦方法無須將視頻節目的內容轉化為具體的結構化數據,因此,降低了計算復雜度以及計算誤差出現的可能性,由此提高了節目的推薦效率,滿足了用戶對節目推薦的實際需求。應理解,在本發明實施例中,上述各過程的序號的大小并不意味著執行順序的先后,各過程的執行順序應以其功能和內在邏輯確定,而不應對本發明實施例的實施過程構成任何限定。對應于本發明實施例所提供的視頻節目推薦方法,圖6示出了本發明實施例提供的視頻節目推薦裝置的結構框圖,該裝置可以運行于具有顯示屏的終端設備之中,例如手機、平板、筆記本電腦、電視機、計算機,等等。為了便于說明,僅示出了與本實施例相關的部分。參照圖6,該裝置包括:第一獲取單元61,用于獲取多個視頻節目,所述多個視頻節目包括第一視頻節目以及多個第二視頻節目,所述第一視頻節目為用戶最近一次觀看的視頻節目,所述第二視頻節目為待推薦節目。第二獲取單元62,用于獲取每個所述視頻節目中各節目屬性的屬性值。計算單元63,用于根據所述屬性值,分別計算所述第一視頻節目與每個所述第二視頻節目之間的相似度。推薦單元64,用于將所述相似度最大的一個所述第二視頻節目輸出為推薦節目。可選地,所述節目屬性包括以下至少一項:導演屬性、演員屬性、編劇屬性、片名屬性、類型屬性、國家屬性、語言屬性以及年份屬性。可選地,所述計算單元63包括:計算子單元,用于對于任意一個所述第二視頻節目,根據所述屬性值,計算該第二視頻節目與所述第一視頻節目之間相同所述節目屬性的屬性值相似度。加權子單元,用于將計算得到的各個所述節目屬性對應的所述屬性值相似度進行加權處理,得到該第二視頻節目與所述第一視頻節目的相似度。可選地,所述計算子單元具體用于:當相同節目屬性為可向量化的節目屬性時,對所述相同節目屬性分別在所述第一視頻節目與該第二視頻節目中的所述屬性值進行分詞處理,以得到每個所述屬性值對應的多個分詞;在一個所述屬性值對應的多個分詞中,對每個所述分詞進行排序,并為每個所述分詞分配權重,以使排序在前的分詞的權重大于或等于排序在后的分詞的權重;在每一個所述屬性值中,根據各個所述分詞的所述權重,生成該屬性值對應的一個特征向量;計算第一特征向量與第二特征向量之間的余弦相似度,所述第一特征向量與所述第二特征向量為所述相同節目屬性在所述第一視頻節目與該第二視頻節目中的所述屬性值所分別對應的所述特征向量;將所述余弦相似度輸出為該第二視頻節目與所述第一視頻節目之間所述相同節目屬性的屬性值相似度。可選地,所述計算子單元還用于:對于所述相同節目屬性分別在所述第一視頻節目與該第二視頻節目中的每個所述屬性值,當該屬性值中包含有標點符號時,以所述標點符號為分詞拆分點,對該屬性值進行分詞,以得到該屬性值對應的多個分詞;當該屬性值中未包含有任何標點符號時,獲取預設的標準詞庫中的各個詞語;判斷該屬性值是否包含所述標準詞庫中的至少一個所述詞語;若該屬性值包含所述標準詞庫中的至少一個所述詞語,則將其包含的每個詞語作為該屬性值對應的多個分詞。可選地,所述計算子單元還用于:在一個所述屬性值對應的多個分詞中,依照每個所述分詞在該屬性值中出現的先后次序,對各個分詞進行排序,以得到分詞序列;在所述分詞序列中,若存在包含有至少兩個相同起始字符的兩個分詞,則將其中字符長度較大的分詞排在字符長度較小的分詞前面;依照所述分詞的排序順序,為每個所述分詞分配權重,以使排序在前的分詞的權重大于或等于排序在后的分詞的權重;生成權重列表,所述權重列表包含每個所述分詞對應的所述權重。可選地,所述計算子單元還用于:在每一個所述屬性值中,根據各個所述分詞的所述權重,生成該屬性值對應的一個特征向量,所述特征向量中的每個元素值依次為所述權重列表中每個所述分詞對應的所述權重。可選地,所述計算子單元具體用于:當相同節目屬性為不可向量化的節目屬性時,通過預設公式計算該第二視頻節目與所述第一視頻節目之間不可向量化的所述相同節目屬性的屬性值相似度Sy,所述預設公式包括:其中,所述a1與所述b1為不可向量化的所述相同節目屬性分別在所述第一視頻節目與該第二視頻節目中的屬性值。本領域普通技術人員可以意識到,結合本文中所公開的實施例描述的各示例的單元及算法步驟,能夠以電子硬件、或者計算機軟件和電子硬件的結合來實現。這些功能究竟以硬件還是軟件方式來執行,取決于技術方案的特定應用和設計約束條件。專業技術人員可以對每個特定的應用來使用不同方法來實現所描述的功能,但是這種實現不應認為超出本發明的范圍。所屬領域的技術人員可以清楚地了解到,為描述的方便和簡潔,上述描述的系統、裝置和單元的具體工作過程,可以參考前述方法實施例中的對應過程,在此不再贅述。在本申請所提供的幾個實施例中,應該理解到,所揭露的系統、裝置和方法,可以通過其它的方式實現。例如,以上所描述的裝置實施例僅僅是示意性的,例如,所述單元的劃分,僅僅為一種邏輯功能劃分,實際實現時可以有另外的劃分方式,例如多個單元或組件可以結合或者可以集成到另一個系統,或一些特征可以忽略,或不執行。另一點,所顯示或討論的相互之間的耦合或直接耦合或通信連接可以是通過一些接口,裝置或單元的間接耦合或通信連接,可以是電性,機械或其它的形式。所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位于一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部單元來實現本實施例方案的目的。另外,在本發明各個實施例中的各功能單元可以集成在一個處理單元中,也可以是各個單元單獨物理存在,也可以兩個或兩個以上單元集成在一個單元中。所述功能如果以軟件功能單元的形式實現并作為獨立的產品銷售或使用時,可以存儲在一個計算機可讀取存儲介質中。基于這樣的理解,本發明的技術方案本質上或者說對現有技術做出貢獻的部分或者該技術方案的部分可以以軟件產品的形式體現出來,該計算機軟件產品存儲在一個存儲介質中,包括若干指令用以使得一臺計算機設備(可以是個人計算機,服務器,或者網絡設備等)執行本發明各個實施例所述方法的全部或部分步驟。而前述的存儲介質包括:U盤、移動硬盤、只讀存儲器(ROM,Read-OnlyMemory)、隨機存取存儲器(RAM,RandomAccessMemory)、磁碟或者光盤等各種可以存儲程序代碼的介質。以上所述,僅為本發明的具體實施方式,但本發明的保護范圍并不局限于此,任何熟悉本
技術領域:
的技術人員在本發明揭露的技術范圍內,可輕易想到變化或替換,都應涵蓋在本發明的保護范圍之內。因此,本發明的保護范圍應所述以權利要求的保護范圍為準。當前第1頁1 2 3
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1