一種基于CUDA的H.264并行編碼器的實現方法與流程
【技術領域】
本發明屬于視頻編碼領域,尤其涉及一種基于cuda的h.264并行編碼器的實現方法。
背景技術:
現在,h.264/avc作為當今最流行的視頻編碼標準,以其高圖像質量和高壓縮比的性能而受到廣泛歡迎,但是提高了圖像質量和編碼效率,同時也大大增加了h.264的計算復雜度,而現有的基于通用處理器的串行結構編碼器無法達到高清實時編碼的性能,而專用硬件的開發成本高,周期長,通用性差,不適合大規模使用,所以亟需為h.264編碼器尋找一種高效的實現方法。
技術實現要素:
為了解決現有技術中的上述問題,本發明提出了一種基于cuda的h.264并行編碼器的實現方法。
本發明采用的技術方案具體如下:
一種基于cuda的h.264并行編碼器的實現方法,該方法包括以下步驟:
(1)對h.264編碼器結構進行調整,包括對編碼器功能模塊進行幀級分隔,以及對該編碼器在cpu和gpu上的任務進行劃分;
(2)所述編碼器的各個功能模塊在cuda上并行化運行,即在模塊級對h.264編碼器的功能模塊分別進行幀間預測、幀內預測編碼、熵編碼、去塊濾波4個過程。
進一步地,功能模塊的幀級分隔包括如下步驟:
(1.1)按照編碼器核心函數的功能,將核心函數中的各個功能函數分隔成獨立的循環體,使每個功能函數在幀一級進行獨立循環;
(1.2)將編碼器中的大型數據結構按照其生命周期劃分成多個簡單數據結構,并且根據其實際的生命周期進行本地化。
進一步地,所述步驟1.2具體包括:
將所述大型數據結構分成局部變量、偽全局變量和真全局變量三種類型;
(a)如果所述大型數據結構是局部變量,則其不作變化;
(b)如果所述大型數據結構是偽全局變量,則通過重命名的方法,將該偽全局變量按照其實際生命周期劃分成不同的變量;
(c)如果所述大型數據結構是真全局變量,則考察該真全局變量的數據結構中,是否有部分變量是偽全局變量或局部變量,如果有,則將這些變量從該真全局變量中分離出去,對分離出去的偽全局變量再進行如上述步驟b的處理。
進一步地,cpu和gpu的任務劃分包括:
(2.1)由cpu完成視頻文件的輸入并對視頻文件進行預處理;
(2.2)cpu將視頻文件中的原始幀和參考幀傳送給gpu,由gpu進行后續的編碼操作;
(2.3)gpu進行幀間預測;
(2.4)gpu執行幀內預測編碼;
(2.5)gpu進行并行化熵編碼;
(2.6)gpu進行去塊濾波。
進一步地,所述幀間預測采用多分辨率多窗口(mrmw)算法。
進一步地,在幀內預測編碼過程中,采用一次讀取多次處理的方式加載數據,即每個線程塊向對應的共享存儲器中加載處理多個宏塊需要的數據,cuda的kernel函數內部通過一層循環對這些數據進行預測編碼,當此次讀取的數據處理結束之后將重建數據寫回,然后再加載新的數據進行處理;相應的kernel的組織為兩重循環結構,外層循環控制變量對應加載的次數,內存循環控制變量對應每次加載的數據需處理的次數。
進一步地,kernel內部以宏塊為單位進行處理,所述宏塊包括多個子宏塊,幀內預測編碼包括三個階段:
第一階段:每個子宏塊交由幀內預測線程塊中的一個線程進行幀內預測處理;
第二階段:由dct線程塊中的一個線程對一個子宏塊中的一行或一列像素進行dct處理;
第三階段:由量化線程塊中的一個線程對一個像素進行量化處理。
進一步地,在并行化熵編碼過程中,每個cuda線程塊處理8個連續的宏塊,每一個線程處理一個子宏塊的熵編碼。
進一步地,所述去塊濾波以幀為單位,包括邊界強度的計算和濾波。
進一步地,所述預處理包括對視頻分量yuv的分離以及編碼器基本參數設置。
本方法的有益效果為:提高了h.264編碼器的執行效率,在不降低編碼性能的前提下降低編碼的計算復雜度,提高編碼速度。
【附圖說明】
此處所說明的附圖是用來提供對本發明的進一步理解,構成本申請的一部分,但并不構成對本發明的不當限定,在附圖中:
圖1是本發明對核心函數的循環體分割示意圖。
圖2是本發明數據結構簡單化和局部化的示意圖。
圖3是本發明cpu-gpu上的任務劃分圖。
圖4是本發明幀間預測編碼存儲模型。
圖5是本發明cavlc編碼階段cuda并行模型。
圖6是去塊濾波函數分離示意圖。
【具體實施方式】
下面將結合附圖以及具體實施例來詳細說明本發明,其中的示意性實施例以及說明僅用來解釋本發明,但并不作為對本發明的限定。
本發明基于h.264的串行程序x264,基于對此程序的分析,根據cuda架構提出了并行h.264編碼器框架并且在cuda上實現并行h.264編碼器的方法。該方法包括以下兩個方面:
(1)總體結構優化
總體結構優化是對h.264編碼器結構進行調整,對基于cuda的h.264并行編碼器的框架進行設計,該調整和設計主要包括兩個方面:對編碼器功能模塊進行幀級分隔;以及對cpu和gpu進行任務劃分。
(2)各個功能模塊在cuda上的并行化,即在模塊級對h.264編碼器的功能模塊分別進行幀間預測、幀內預測編碼、熵編碼、去塊濾波4個過程,從并行模型設計和存儲模型等方面實現編碼器在cuda上的并行化。
下面對該方法的這兩個方面進行詳細說明。
功能模塊的幀級分隔:
功能模塊的幀級分隔的具體步驟如下:
(1.1)松散函數耦合度
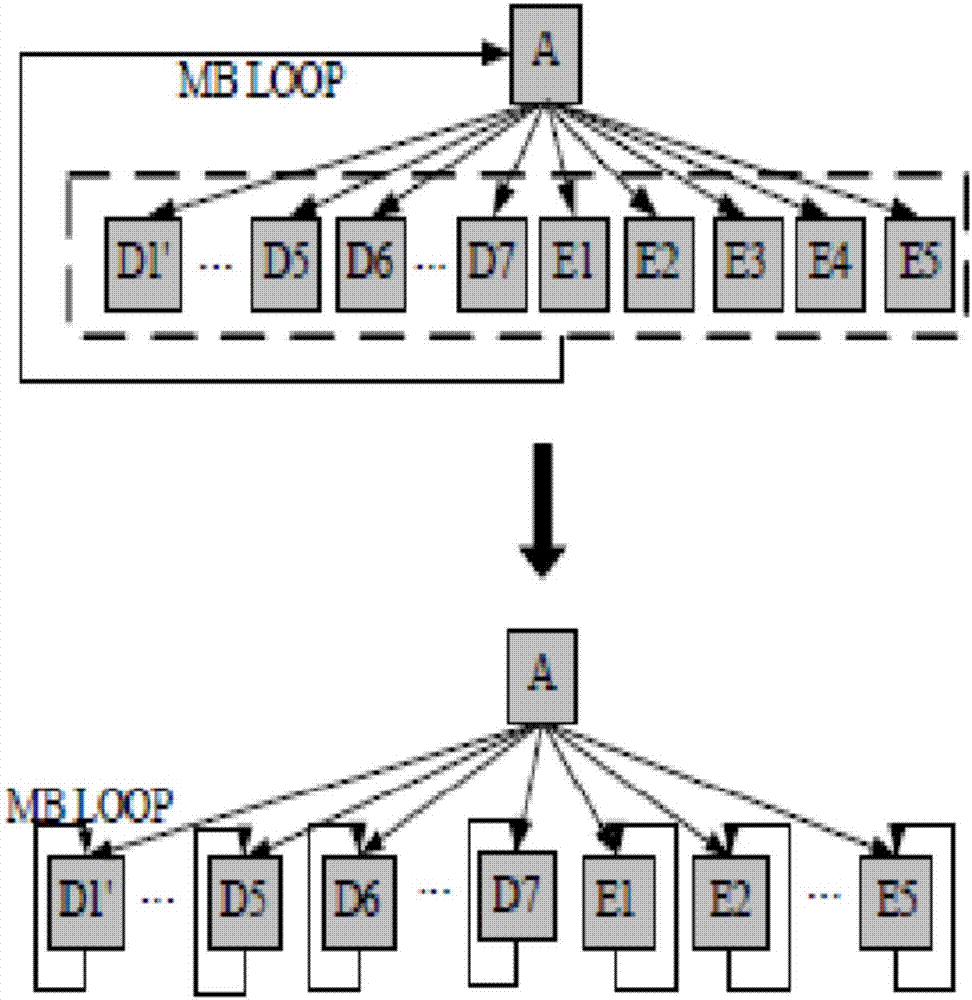
在h.264編碼器中,其核心函數(main函數)是一個大的循環體,如圖1上方所示,a為main函數,其包括下方的d1’,…,d5,d6,…,d7,e1,e2,e3,e4,e5所有的函數作為一個整個的大的循環體,main函數的每一次循環都執行一遍所有的函數,這種方式循環體路徑長,如果直接進行并行程序的開發,函數負載太重。
因此本發明按照核心函數的功能,將核心函數的整個循環分割成多個相對獨立的循環體,如圖1下方所示,每個函數在幀一級進行獨立循環,將d1’,…,d5,d6,…,d7,e1,e2,e3,e4,e5每個都分割成獨立的循環體,例如d1’函數是個循環體,d5函數是個循環體,d7函數是個循環體,e1函數是個循環體等等。這樣,每個函數獨立集中處理一個任務,獨立循環,在每個循環體執行的過程中,指令的局域性更好,失效次數低。
(1.2)將h.264編碼器中的數據結構簡單化和局部化
參見圖2,為了減少數據傳輸的時間,本發明將編碼器中的大型數據結構按照其生命周期劃分成多個簡單數據結構,并且根據其實際的生命周期進行本地化。具體地,所述大型數據結構可以分成局部變量、偽全局變量和真全局變量三種類型。
對于局部變量,例如圖2中函數0中的本地變量a,不作變化。
對于偽全局變量b,即雖然是全局變量,但是該變量的作用范圍可以拆分成多個實際生命周期,則通過重命名的方法,將該偽全局變量按照其實際生命周期分為不同的變量。如圖2所示,對于偽全局變量b,其在函數0和函數1之間的變量值沒有關系,可以拆分成2個生命周期,因此將函數1中的該偽全局變量重命名為b0,而函數2中沒有使用到該變量b,則函數2中就可以不再定義該變量b。
對于真全局變量c,則需要考察該真全局變量的數據結構中,是否有部分變量是偽全局變量或局部變量,如果有,則將這些變量從c中分離出去,分離出去的偽全局變量再進行如上處理。如果圖2所示,真全局變量c可以拆分成一個偽全局變量和一個局部變量,則限制該偽全局變量的作用范圍在函數0和函數1,限制局部變量c0的作用范圍只在函數2.
cpu和gpu的任務劃分
參考圖3,其示出了本發明h.264編碼器各個功能模塊在cpu和gpu上的任務劃分以及cpu-gpu之間的數據流動情況。
(2.1)首先由cpu完成視頻文件的輸入并對視頻文件進行預處理,包括對視頻分量yuv的分離,以及編碼器基本參數設置等。
(2.2)cpu將原始幀和參考幀傳送給gpu,由gpu進行后續的編碼操作。
gpu以幀為單位,通過執行四個模塊對幀進行處理,基本流程是:對一幀的幀間預測結束之后,再進行相應的幀內預測編碼,然后對得到的變量化系數進行熵編碼,以此類推,直至整幀的熵編碼和去塊濾波結束之后再將結果數據傳回cpu。
(2.3)gpu執行幀間預測。
幀間預測是h.264編碼器中計算需求最大的部分,傳統幀間預測所需的計算量約占整個編碼器的70%,雖然圖像質量較好但復雜。本發明采用現有技術中的多分辨率多窗口(mrmw)算法進行幀間預測。由于本發明對功能模塊進行了幀級分隔,使用mrmw算法相對于現有技術可以大幅度減少幀間預測的時間。
(2.4)gpu執行幀內預測編碼。
幀內預測并行度并不高,cuda每個線程塊能夠同時處理最大的數據量為1個宏塊(256像素),對于共享存儲器的壓力并不大,而相鄰宏塊之間存在生產者-消費者之間的關系,為了減少為全局存儲中相關數據的訪問次數,本發明采用一次讀取多次處理的方式加載數據。即每個線程塊向對應的共享存儲器中加載處理多個宏塊需要的數據,cuda的kernel函數內部通過一層循環對這些數據進行預測編碼,當此次讀取的數據處理結束之后將重建數據寫回,然后再加載新的數據進行處理。相應的kernel的組織為兩重循環結構,外層循環控制變量對應加載的次數,內存循環控制變量對應每次加載的數據需處理的次數。
參見附圖4,其示出了幀內預測編碼的存儲模型。圖4左上部分由多個宏塊(mb)組成的一個圖像幀,每次讀取幀數據時,都從原始圖像幀中讀取一個strip,并存儲到共享存儲器中(如圖4右上所示),kernel內部以宏塊為單位對該strip進行處理。
圖4中部和下部示出了kernel對一個宏塊的處理過程。圖4的左中部分示出了一個4*4的宏塊,其包括子宏塊0到子宏塊15,每個子宏塊包括4*4個像素,其幀內預測編碼包括三個階段:
第一階段:如圖4左中和左下部分,每個子宏塊交由幀內預測線程塊(predictionthreadblock)中的一個線程進行幀內預測處理,共需要16個線程(線程0至線程15)。
第二階段:如圖4的正中和正下部分,由dct線程塊中的一個線程對一個子宏塊中的一行或一列像素進行dct處理,共需64個線程(線程0至線程63)。
第三階段:如圖4的右中和右下部分,由量化線程塊(quantthreadblock)中的一個線程對一個像素進行量化處理(以行優先的方式),共需256個線程(線程0值線程255)。
(2.5)gpu進行并行化熵編碼。
參考附圖5,其為cavlc編碼階段cuda并行模型,示出了亮度交流分量熵編碼階段數據與線程的映射關系。其中每個cuda線程塊處理8個連續的宏塊,即線程塊b0處理第0行中的mb0到mb7,線程塊b14處理mb112到mb119,以此類推。線程塊內連續的16個線程分別處理一個宏塊中16個子宏塊。圖5中共有1200個線程塊,每個線程塊包含128個線程,線程數達到了130560個,每一個線程處理一個子宏塊的熵編碼,從而實現了130560個線程并行熵編碼。雖然熵編碼是一個分支密集型的組件,但是經過功能模塊的幀級分隔,將各種分量分離,已經消除了一些分支路徑,通過大量線程實現大規模的數據并行足以彌補分支操作帶來的影響。
(2.6)gpu進行去塊濾波,如圖6所示,所述去塊濾波以幀為單位,包括邊界強度的計算和濾波。
通過上述過程,本發明從系統和模塊級兩個方面實現了h.264在cuda上的并行化過程,在不降低編碼性能的前提下降低編碼的計算復雜度,提高編碼速度。
以上所述僅是本發明的較佳實施方式,故凡依本發明專利申請范圍所述的構造、特征及原理所做的等效變化或修飾,均包括于本發明專利申請范圍內。
- 還沒有人留言評論。精彩留言會獲得點贊!