基于VPN的分布式網絡爬蟲系統及調度方法與流程
本發明涉及一種分布式網絡爬蟲系統及調度方法,更具體的說,尤其涉及一種基于vpn的分布式網絡爬蟲系統及調度方法。
背景技術:
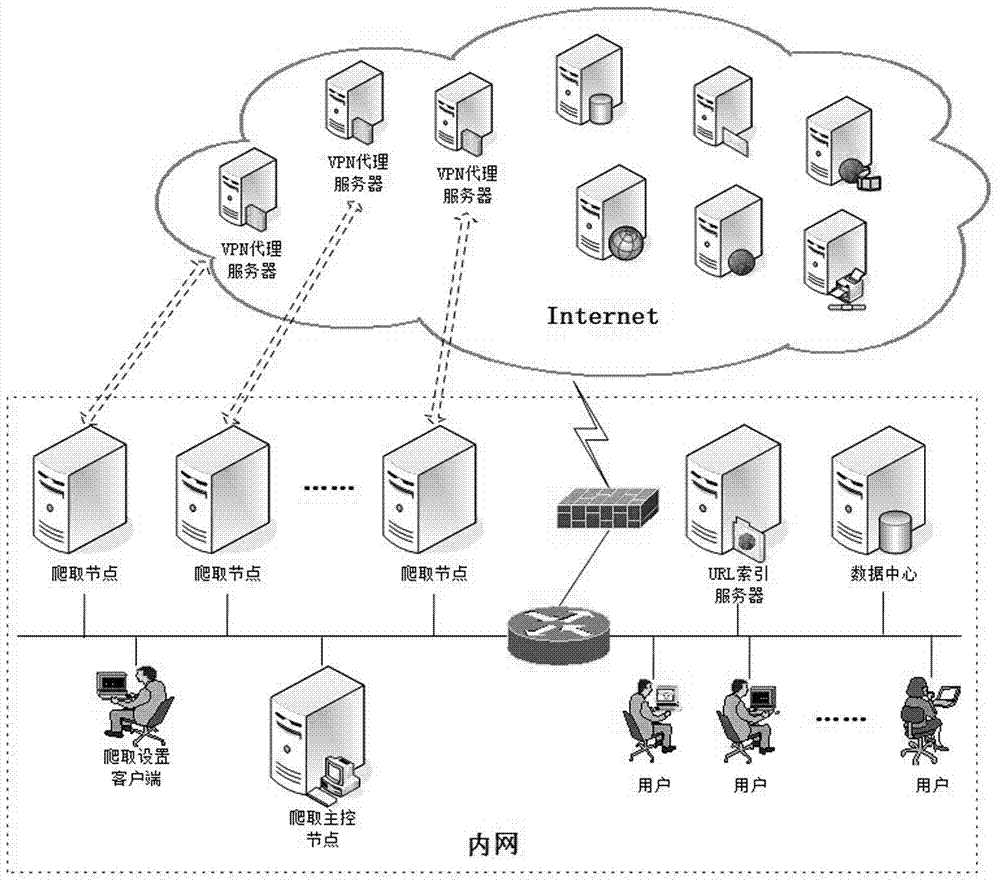
:大數據時代的來臨,網絡上所承載的信息愈加豐富,其中既有指導行業發展走向的政策類網站,也有介紹相關領域最新科技動態及競爭對手產品信息的新聞類網站,還有反映用戶對產品評價的博客、論壇、微博等社交網站。外網數據的有效接入和應用對各級各類企業輔助決策、制定計劃、管理成本、銷售運營、服務售后等提供信息支持,為企業更好知己知彼掌控市場打開了一扇窗口。網絡爬蟲起始于種子鏈接穿行于internet,將訪問到的頁面下載至本地,為網絡數據采集提供技術支撐,為企業深度挖掘和分析網絡數據奠定良好開端。根據網絡爬蟲所部署的地理位置和網絡拓撲結構不同,可以將網絡爬蟲分為部署于同一局域網的單一域網絡爬蟲(single-domaindistributedcrawler,又稱局域網爬蟲)和分散部署于廣域網的多域網絡爬蟲((multi-domaindistributecrawler,又稱廣域網爬蟲)。無論是單一域網爬蟲還是廣域網爬蟲最基本的功能均是網頁數據抓取,而其靈魂則是調度策略,調度策略不同則抓取方法不同。調度策略主要包括種子鏈接分配策略、負載均衡策略、網頁查重策略等。當前種子鏈接分配策略主要分為獨立方式、靜態方式和動態方式三類。獨立方式中各網絡爬蟲互不通信獨立采集各自頁面;靜態方式預先劃分所有網絡鏈接,將劃分好的鏈接分配給網絡爬蟲;動態方式動態地為各網絡爬蟲分配網絡鏈接,網絡爬蟲完成當前抓取任務時為其分配新的抓取任務。無論何種分配方式一般均是以域名(主機)為單位劃分種子鏈接以降低通信開銷。目前負載均衡策略主要分為靜態負載均衡和動態負載均衡,其中靜態負載均衡主要有輪詢方式、比率方式、優先權方式等;而動態負載均衡在抓取過程中收集各爬蟲服務器負載信息,根據負載情況遷移節點任務。無論何種均衡策略其任務遷移的對象均是網絡鏈接,將高負荷爬蟲的網絡鏈接分配給低負荷爬蟲,以均衡整個系統的負載。常用的網頁查重策略有基于數據庫的查重方式、基于b-樹的去重方式、基于hash的去重方式、基于md5編碼的去重方式、基于bloom的去重方式、基于廣義表結構的去重方式等等。國內外的一些公司對大型網絡爬蟲已有成熟的解決方案,但是這些大型搜索引擎只能給大眾用戶提供一種普通不可定制的搜索服務,不可能考慮到不同用戶的個性化需求。然而各類組織無論是政府機關、事業單位還是不同規模的企業在描述信息需求時,更傾向于使用一組關鍵詞來描繪所關注的業務領域,且隨著時間的推移這些關鍵詞也會不斷演進和變化。因此網絡爬蟲公司所提供的通用服務難以滿足組織的深層信息需求,需要為組織個性化定制可部署于組織內的分布式網絡爬蟲。除大型跨國公司及集團類公司,大多數組織辦公地點通常集中于同一區域,因此一般先是通過組建局域網(localareanetwork,lan)實現組織內的辦公自動化(officeautomation,oa),而后通過路由器接入運營商的方式訪問internet。就此而言,單一域網爬蟲更適合于大多數組織的網絡數據抓取。組織對web信息的需求并不僅局限于政策導向類的網站或新聞發布類的網站,為了更進一步地了解目標用戶的需求,組織還需抓取論壇、微博等社交媒體平臺數據。為應對領域的瞬息萬變,組織需實時了解人們話題討論的熱點、風向、傾向等,這對社交媒體平臺數據抓取提出了較高的實時性要求。然而在訪問internet過程中,單一域網爬蟲將共享運營商分配的同一個ip地址,大多數的組織很難擁有獨屬于自己的多個公網ip地址。受目標數據源服務器的限制,同一ip地址的爬蟲在一定時間內只能采集同一目標服務器限定的數據。即使組織在局域網內設置了多個爬蟲,這些爬蟲在訪問目標服務器的過程中也將被運營商分配相同的ip地址,因此當其中一個爬蟲達到訪問上限時,其余爬蟲也將被拒絕訪問。這對組織爬取數據的覆蓋性和完整性提出了極大的挑戰。因此如何在局域網內為組織部署分布式網絡爬蟲,以及如何為部署于局域網中的分布式爬蟲設置合適調度策略,利用有限的ip地址應對不同類型網絡媒體為組織盡可能多的采集數據是本發明基于vpn的分布式網絡爬蟲系統構建的主旨。技術實現要素:本發明為了克服上述技術問題的缺點,提供了一種基于vpn的分布式網絡爬蟲系統及調度方法。本發明的基于vpn的分布式網絡爬蟲系統,其特征在于:包括部署于同一組織局域網內的爬取設置客戶端、爬取主控節點、多個爬取節點、url索引服務器、數據中心和用戶,以及多個遠程vpn代理服務器;組織局域網通過路由器接入運營商的方式訪問internet,以便爬取節點使用vpn代理服務器訪問internet中的目標數據源服務器;爬取設置客戶端用于配置數據源、關鍵詞、爬取策略,爬取主控節點根據爬取設置客戶端的配置為爬取節點分配任務,實現爬取節點的調度以及均衡各爬取節點的負載;爬取節點中部署著網絡爬蟲系統,爬取節點根據爬取主控節點分配的任務選擇一個vpn連接連入遠程vpn代理服務器,使用vpn代理服務器訪問internet中的目標數據源服務器;url索引服務器記錄已爬取過的url及爬取時間,數據中心用于存儲抓取的網頁數據;用戶是網絡數據的使用者,通過與數據中心的交互獲取相關數據。本發明的基于vpn的分布式網絡爬蟲系統,所述爬取主控節點、爬取節點、url索引服務器和數據中心可采用邏輯劃分,并非每個設備均需一個物理設備與其對應;url索引服務器可合并到數據中心,由數據中心承擔已爬取url的記錄;所述爬取設置客戶端可以是任意具有爬取設置權限的用戶。本發明的基于vpn的分布式網絡爬蟲系統的調度方法,通過以下步驟來實現:a).確定新聞類網站和社交媒體類網站的數據采集方法,對于信息更新頻率和數量較低的新聞類網站,采用爬蟲直接抓取目標源數據,再使用關鍵詞進行數據過濾;對于信息更新頻率和數量極高的社交媒體類網站,利用目標數據源的站內檢索結合關鍵詞獲取有效信息,再使用爬蟲抓取檢索結果;b).爬取主控節點為各爬取節點分配任務,對于新聞類網站,將同一域名的新聞類網站分配給一個爬取節點采集目標源數據;對于社交媒體類網站,將同一域名的社交媒體類網站分配到全部爬取節點,并為每個爬取節點分配互不相同的關鍵詞;c).各爬取節點生成初始采集目標數據源url列表,爬取主控節點為每個爬取節點分配vpn連接列表、新聞類網站采集入口url地址、社交媒體類采集入口url地址以及關鍵詞后,爬取節點從vpn連接列表中選擇最久未使用的vpn連接連入遠程vpn代理服務器,使用vpn代理服務器訪問新聞類網站和社交媒體類網站;設爬取節點獲取的新聞類網站的網頁url地址列表為url_init_listweb,獲取的社交媒體類網站的檢索入口url地址列表為url_init_listsoc,爬取節點的初始采集目標數據源列表url_init_list為url_init_listweb與url_init_listsoc的并集;d).各爬取節點確定最終采集目標數據源url列表,爬取節點通過將url_init_list與url索引服務器所維護的url_list進行比較、判斷采集過url地址與初次訪問時間差是否小于相應網頁類型的重訪問時間,形成中間采集目標數據源列表url_intermed_list;然后通過對url_intermed_list進行混排生成最終采集目標數據源列表url_final_list;e).各爬取節點采集目標數據源列表的網頁數據,爬取節點采集url_final_list列表中各url地址所指向的網頁數據,對于新聞類網頁按照網站分組,將網頁數據存放到新聞類網站結果列表data_final_listweb中;對于社交媒體類網頁,將網頁數據存放到社交媒體結果列表data_final_listsoc中;并將data_final_listweb和data_final_listsoc打包發送給數據中心;f).url索引服務器維護更新url列表,url索引服務器接收到爬取節點發送的url_list更新請求后,將所要更新的url地址添加到url_list列表中,并將訪問時間設置為當前時間,實現url_list列表的更新;g).各爬取節點將爬取結果存儲到數據中心,各爬取節點逐一采集各自最終采集目標數據源列表url_final_list中每條url數據源,將采集結果緩存至本地,在完成列表url_final_list中所有數據源的采集后,將采集到的數據一次性發送至數據中心;h).各爬取節點向爬取主控節點匯報狀態,各爬取節點按照約定時間,定時向爬取主控節點發送心跳信號和各自的采集時間表;i).爬取主控節點根據所匯報的狀態調節負載,爬取主控節點根據計算的新聞類網站的權重和社交媒體類網站的各關鍵詞權重,對各爬取節點的負載做出均衡調整。本發明的基于vpn的分布式網絡爬蟲系統的調度方法,設爬取節點數為ncl,不同域名的新聞類網站數為nweb,不同域名的社交媒體類網站數為nsoc,社交媒體類網站的關鍵詞數為nkw;則步驟b)中,為每個爬取節點平均分配個不同域名的新聞類網站,將域名不同的社交媒體類網站分配到所有爬取節點,并為每個爬取節點平均分配個不同的關鍵詞;爬取主控節點維護著爬取節點任務分配表、爬取節點心跳表和vpn連接賬戶表,新聞類網站的任務分配表中記錄各個爬取節點所分配到的網站及各個網站的權重,新聞類網站webi的權重的計算公式為:其中,為抓取新聞類網站webj所花費的時間,i∈[1,nweb],j∈[1,nweb];初始采集各新聞類網站花費時間未知時,認為所有新聞類網站采集時間相同,則各新聞類網站的初始權重為社交媒體類網站的任務分配表中記錄各個爬取節點在每個社交媒體類網站中所分配到的關鍵詞以及不同社交媒體類網站不同關鍵詞的權重,社交媒體類網站soci中關鍵詞kwj的權重的計算公式為:其中,為在社交媒體類網站soci中采集關鍵詞kwk相關的信息所所花費的時間,i∈[1,nsoc],j、k∈[1,nkw];初始在各社交媒體類網站中采集不同關鍵詞相關信息花費時間未知時,認為各關鍵詞相關信息的采集時間相同,則各關鍵詞的初始權重為本發明的基于vpn的分布式網絡爬蟲系統的調度方法,步驟c)中所述的各爬取節點生成初始采集目標數據源url列表具體通過以下步驟來實現:c-1).爬取節點從vpn連接列表中選擇最久未使用的vpn連接連入遠程vpn代理服務器,使用vpn代理服務器訪問新聞類網站和社交媒體類網站,獲取初始采集目標數據源列表,同時記錄使用該vpn連接的開始使用時間;并通過y/n記錄vpn連接最近是否使用過,若最近使用過該vpn連接標識為y,反之標識為n;c-2).爬取節點首先解析采集任務的新聞類網站和社交媒體類網站的主機地址,然后將自身的任務主機地址與暫時停用目標主機列表host_disable_list進行比對,去除出現在host_disable_list中且停用時間小于2小時的任務主機,并刪除host_disable_list中停用時間大于2小時的主機地址;c-3).假設比對host_disable_list之后保留的新聞類網站為webj,webj+1,…,webk,其對應的采集入口url地址分別是爬取節點spideri分別以為接入口獲取相應網站中網頁url地址列表比對host_disable_list之后保留的社交媒體類網站對應的檢索入口url地址分別是各社交媒體分配到spideri的關鍵詞為則爬取節點spideri分別以各社交媒體的檢索地址為接入口結合社交媒體所對應的關鍵詞獲取各社交媒體網頁url地址列表初始采集目標數據源列表url_init_list由url_init_listweb和url_init_listsoc組成,即url_init_list=url_init_listweb∪url_init_listsoc。本發明的基于vpn的分布式網絡爬蟲系統的調度方法,步驟d)中各爬取節點確定最終采集目標數據源url列表具體通過以下步驟來實現:d-1).爬取節點首先將url_init_list與url索引服務器所維護的url_list列表進行比對,查看url_init_list中的每條url地址是否采集過,若未采集則將此條url放入中間采集目標數據源列表url_intermed_list,并在url_intermed_list中記錄此url為新增地址,否則執行步驟d-2);d-2).若url_init_list中某條url地址已存在于url列表,說明已經采集過此url地址中的數據,然而新聞類網站和社交媒體類網站的數據不斷更新,在網頁活躍期內仍需持續采集更新數據;因此,當url_init_list中某條url地址已存在于url_list中,則首先判斷該url地址的網頁類型,將當前時間與該url地址的初次訪問時間對比,若兩者的時間差小于相應網頁的重訪時間標準,則將此url地址放入url_intermed_list,否則不再采集該url地址數據。d-3).首先將url_intermed_list中的url地址按照主機分組劃分成若干子列表,然后采用隨機方法隨機挑選一個子列表,并在該子列表中隨機選擇一個未被選中過的url地址放入url_final_list,迭代子列表和url地址的選擇過程直至選完所有子列表的所有url地址。本發明的基于vpn的分布式網絡爬蟲系統的調度方法,步驟e)中所述的各爬取節點采集目標數據源列表的網頁數據通過以下步驟來實現:e-1).爬取節點從自身的url_final_list中取出一條url地址,通過當前vpn連路采集url地址所指向的網頁數據,若返回結果為網頁數據,則執行步驟e-2);若返回結果為服務器拒絕訪問或其他vpn相關錯誤,則執行步驟e-3);e-2).緩存采集結果,存放到混排的結果列表data_init_list中,并記錄網頁的類型、網頁的來源、社交媒體類網頁所對應的檢索關鍵詞、網頁采集花費的時間;所采集的url地址被標識為新增地址時,則向url索引服務器發送url_list更新請求;e-3).若爬取節點中有標識為最近未使用過的vpn連接,則在標識為最近未使用過的vpn連接中,通過當前時間與最近未使用過的vpn連接的開始使用時間對比,選擇一個最久未使用vpn連接,在連接成功后,執行步驟e-4);若爬取節點的vpn連接全部標識為最近使用過,執行步驟e-5);e-4).使用新的vpn連接采集網頁數據,若返回結果為網頁數據,則執行步驟e-2);若仍出現服務器拒絕訪問或其他vpn相關錯誤,則執行步驟e-3);e-5).爬取節點向爬取主控節點申請新的vpn連接,若成功申請到新的vpn連接則將此vpn加入vpn連接列表,并將申請到的vpn連接標識為最近未使用,執行步驟e-3);若未申請到vpn連接執行步驟e-6);e-6).刪除url_final_list中與此url主機地址相同的未采集url,執行步驟e-1)。本發明的基于vpn的分布式網絡爬蟲系統的調度方法,對社交媒體類網站的大規模采集對外網ip地址的要求遠高于新聞類網站的采集,因此本發明所需的vpn個數主要受限于社交媒體類網站的關鍵詞,通過如下公式估算:其中vpns表示所需vpn連接數,nsearchpage表示檢索結果頁鏈接個數,nvpn_ip表示社交媒體類網站允許一個ip地址采集的頁數;所需爬取節點的個數通過如下公式估算:其中clients表示需要爬取節點的個數,expecttime表示完成一輪采集所花費的期望時間,accesstime表示連接遠程服務器及采集數據時間,vpnlinktime表示vpn單次連接時間。本發明的有益效果是:首先,單一域網絡爬蟲共享同一ip出口地址,訪問的頻率和總量將受到限制,本發明中的爬取節點通過vpn撥號的方式連入遠程vpn代理服務器,進而使用代理服務器的公網ip地址訪問數據源,通過切換vpn連接獲取不同公網ip,解決局域網爬蟲ip地址單一問題;其次,雖然通過連入遠程vpn代理服務器的方式可獲得多個公網ip地址,但就社交新聞類網站的更新頻率而言,ip地址仍是珍貴的稀缺資源,為使用一個ip地址盡可能多的獲取數據,本發明采用多目標數據源url穿插采集的方式,避免同一時間過于密集地采集單一目標服務器中的數據,從而造成服務器拒絕訪問問題,解決社交媒體類網站平臺數據采集覆蓋性和完整性;最后,與當前負載均衡通過分配網絡連接方式不同,本發明采用調整關鍵詞的方式均衡各爬取節點的負載。附圖說明圖1為本發明基于vpn的分布式網絡爬蟲系統的部署結構;圖2為本發明基于vpn的分布式網絡爬蟲系統的數據抓取步驟;圖3為本發明基于vpn的分布式網絡爬蟲系爬取中控節點生成的采集目標數據源列表;圖4為本發明基于vpn的分布式網絡爬蟲系統爬取中控節點生成url_final_list的流程圖。具體實施方式下面結合附圖與實施例對本發明作進一步說明。為解決大多數組織在訪問internet時ip地址單一,從而導致社交網站數據爬取不完整和覆蓋差問題,本發明提出了一種基于vpn的分布式網絡爬蟲系統。如圖1所示,給出了為本發明基于vpn的分布式網絡爬蟲系統的部署結構,本發明基于vpn的分布式網絡爬蟲系統部署于組織局域網內,通過路由器接入運營商的方式訪問internet。基于vpn的分布式網絡爬蟲系統由爬取設置客戶端、爬取主控節點、爬取節點、url索引服務器、數據中心以及最終用戶組成。爬取設置客戶端用于配置數據源、關鍵詞、爬取策略等;爬取主控節點根據爬取設置客戶端的配置為多個爬取節點分配任務,負責爬取節點的調度并均衡各爬取節點的負載;爬取節點中部署著網絡爬蟲系統,在接到爬取主控節點分配的采集任務后選擇一個vpn連接連入遠程vpn代理服務器,使用代理服務器訪問internet中的目標數據源服務器;url索引服務器記錄已爬取過的url及爬取時間;數據中心用于存儲抓取的網頁數據;用戶是網絡數據的使用者,可通過多種方式與數據中心交互。基于vpn的分布式網絡爬蟲系統中的各設備均為邏輯劃分,并非每個設備均需一個物理設備與其對應。其中爬取設置客戶端可以是任意具有爬取設置權限的用戶;在設備性能富有余地的情況下,url索引服務器也可合并到數據中心,由數據中心承擔已爬取url的記錄功能。如圖2所示給出了本發明基于vpn的分布式網絡爬蟲系統的數據抓取步驟,將基于vpn的分布式網絡爬蟲系統部署到組織內往后,所采用的數據抓取方法步驟如圖2所示。步驟一:確定新聞類網站和社交媒體類網站平臺的數據采集方法;步驟二:爬取主控節點為各爬取節點分配任務;步驟三:各爬取節點生成初始采集目標數據源url列表;步驟四:各爬取節點確定采集目標數據源url列表;步驟五:各爬取節點采集目標數據源列表的網頁數據步驟六:url索引服務器維護更新url列表;步驟七:各爬取節點將爬取結果存儲到數據中心;步驟八:各爬取節點向爬取主控節點匯報狀態;步驟九:爬取主控狀態根據所匯報的狀態調節負載。步驟一,新聞類網站和社交媒體類網站平臺的數據采集方法確定如下:組織關注的數據源既有指導行業發展走向的政策類網站,也有介紹相關領域最新科技動態及競爭對手產品信息的新聞類網站,以及反應用戶對產品評價的博客、論壇、微博等社交網站。其中政策類網站和新聞類網站的信息一般是由網站編輯工作人員撰寫錄入,單個網站信息更新頻率和數量較低,其日更新量一般不超過千條。而論壇、微博等社交媒體平臺的信息由活躍于互聯網和移動網的網民自由撰寫發表,單個媒體平臺信息更新頻率和數量極高,日更新量超過億條,任何第三方爬蟲系統都難以應對如此量級的數據采集。所幸組織所關注的重點是業務領域相關信息,這些信息只是各類數據源提供數據的子集。組織通常可采用構建本體知識庫的方式,描述業務領域過濾無效信息。為保證業務領域描述的完整性,構建的本體知識庫一般包含幾百個概念和實例(關鍵詞)。在明確目標數據源和關鍵詞的基礎上,組織獲取有效信息的方法有兩種。其一,使用爬蟲直接抓取目標源數據,再使用關鍵詞進行數據過濾;其二,利用目標數據源的站內檢索結合關鍵詞獲取有效信息,再使用爬蟲抓取檢索結果。假設本體知識庫中的關鍵詞數為nkw,目標數據源中單位時間內信息的更新量為nd,受限于新聞類網站頁面承載的信息量,nd將分布于新聞類網站的多個頁面,一個頁面承載的信息數為c。在新聞類網站信息總更新量nd中,與組織業務領域相關的有效信息量為ni。兩種采集方法與服務器的交互次數可分成兩部分,分別是為得到有效信息所在的位置訪問頁面的次數(訪問目錄頁次數)和抓取信息的次數(訪問內容頁次數)。若ni均勻的分布于nd中,則采用第一種方法獲取全部ni條有效信息需訪問目標數據源次,采用第二種方法獲取全部ni條有效信息需訪問目標數據源次。面對日信息更新量過億的社交媒體類網站平臺,則nd>>c,nd>>ni且nd>>nkw,采用第一種方法訪問目標數據源的次數遠大于第二種方法,顯然對于信息更新頻率極高的社交媒體類網站平臺更適合于采用第二種方法而非第一種方法。而面對日信息更新量少于千條的新聞類網站數據nd并不會比ni大一個數量級,且若新聞類網站是組織挑選的行業內新聞類網站則nd≈ni,此時影響兩種方法訪問服務器次數的關鍵在于nkw。顯然對于信息更新頻率較低的新聞類網站,采用第一種方法采集數據,而后在本地使用關鍵詞過濾信息的方式,可有效減少與服務器的交互次數,增強ip地址利用率。因此本發明采用第一種方法采集新聞類網站數據,而采用第二種方法采集社交媒體類網站數據。步驟二,在明確新聞類網站和社交媒體類網站平臺的采集方法后,爬取主控節點為各爬取節點分配任務的方案如下:當前種子連接分配策略一般是以域名(主機)為單位,將同一域名的數據交由一個爬取節點采集。本發明也采用此種策略采集新聞類網站數據,將同一域名的新聞類網站分配給一個爬取節點采集。如前所述采集社交媒體類網站平臺,訪問目標服務器的次中,nkw次訪問并未采集信息,而是關鍵詞檢索引起的開銷。受同一ip地址訪問總量限制以及關鍵詞的演進和變化,若仍將同一域名的社交媒體類網站也交由一個爬取節點采集,關鍵詞的檢索會造成極大的浪費有限的訪問總量。針對社交媒體類網站數據采集,本發明將同一域名的社交媒體類網站分配到全部爬取節點,并為每個爬取節點分配互不相同的關鍵詞。假設爬取節點數為ncl,不同域名新聞類網站數為nweb,不同域名社交媒體類網站數為nsoc,社交媒體類網站的關鍵詞為nkw。在初始各爬取節點狀態未知時,爬取主控節點的種子連接分配策略為:將域名不同的新聞類網站平均分配到各爬取節點,也即隨機為每個爬取節點分配個不同域名新聞類網站;而將域名不同的社交媒體類網站分配到所有爬取節點,將不同關鍵詞平均分配到各爬取節點,也即為每個爬取節點分配nsoc個不同域名社交媒體類網站,并隨機分配個不同的關鍵詞。爬取主控節點維護著爬取節點任務分配表、爬取節點心跳表和vpn連接賬戶表。如表1所示,給出了新聞類網站爬取任務分配表:表1表1記錄各個爬取節點所分配到的新聞類網站以及各個新聞類網站的權重,新聞類網站webi的權重計算公式為:其中為抓取新聞類網站webj所花費的時間j∈[1,nweb],初始采集各新聞類網站花費時間未知時,認為所有新聞類網站采集時間相同,則各新聞類網站的初始權重為表2給出了社交媒體類網站爬取任務分配表:表2表2的右續表:表2記錄各個爬取節點在每個社交媒體類網站中所分配到的關鍵詞,以及不同社交媒體類網站不同關鍵詞的權重,社交媒體類網站soci中關鍵詞kwj的權重計算公式為:其中為在社交媒體類網站soci中采集關鍵詞kwk相關的信息所花費的時間k∈[1,nsoc],初始在各社交媒體類網站中采集不同關鍵詞相關信息花費時間未知時,認為各關鍵詞相關信息的采集時間相同,則各關鍵詞的初始權重為表3crawlerstatespider1***spider2***spider3***…………spiderncl***如表3所示,給出了爬取節點心跳表,爬取主控節點定時接收各個爬取節點的心跳狀態,并記錄在爬取節點心跳表中,從而了解爬取節點是否宕機以及是否有新的爬取節點加入,心跳表中的state記錄著各個爬取節點向爬取主控節點最后返回心跳時間。當有節點宕機或新節點加入時,根據各個新聞類網站爬取時間、各個社交媒體類網站不同關鍵詞相關信息爬取所花費的時間,以及所擁有的爬取節點數依據負載均衡原則重新分配任務。爬取主控節點在給爬取節點分配任務的同時為其分配一個vpn連接列表,初始時爬取主控節點所分配的vpn連接列表包含兩個ip地址不同vpn連接。在信息采集過程中,當所分配的ip地址達到采集上限時,爬取節點將向主控節點申請新的vpn連接,若存在未分配vpn連接則主控節點將為爬取節點再分配一個連接。如表4所示,給出了爬取中控節點的vpn連接賬戶表:表4vpnconnectionipaddressuserpasswordassignmentvpn1*********spider3vpn2*********nonevpn3*********spider1vpn4*********spiderncl…………………………vpnw*********spider2爬取主控節點在vpn連接賬戶表中記錄著系統所擁有的vpn賬號及各賬號的分配情況,如表4所示,其中assignment記錄著vpn連接賬戶的分配情況。步驟三,各爬取節點在分配到vpn連接列表、新聞類網站采集入口url地址、社交媒體類網站搜索入口url地址以及關鍵詞后,生成初始采集目標數據源列表方案如下:爬取節點中部署著網絡爬蟲系統,在接到爬取主控節點分配的采集任務以及vpn連接列表后,從vpn連接列表中選擇一個最近未使用且最久未使用的vpn連接連入遠程vpn代理服務器,使用代理服務器訪問internet中新聞類網站和社交媒體類網站,獲取初始采集目標數據源列表,同時記錄使用該vpn連接的起始時間。如表5所示,給出了爬取節點的vpn列表:表5爬取節點所維護的vpn列表如表5所示,starttime記錄vpn連接的開始使用時間,recentlyused通過y/n記錄vpn連接最近是否使用過,若最近使用過該vpn連接則標識為y,反之標識為n。暫時停用目標主機列表host_disable_list記錄著暫時不采集的主機地址及起始停用時間。在采集任務開始之前,爬取節點spideri將首先解析采集任務的新聞類網站及社交媒體類網站的主機地址。然后將任務主機地址與host_disable_list進行對比,去除出現在host_disable_list中且停用時間小于2小時的任務主機,并刪除host_disable_list中停用時間大于2小時的主機地址。假設比對host_disable_list之后保留的新聞類網站為webj,webj+1,…,webk,其對應的采集入口url地址分別是爬取節點spideri分別以為接入口獲取相應新聞類網站中網頁url地址列表比對host_disable_list之后保留的社交媒體類網站對應的檢索入口url地址分別是各社交媒體類網站分配到spideri的關鍵詞為則爬取節點spideri分別以各社交媒體類網站的檢索地址為接入口結合社交媒體類網站所對應的關鍵詞獲取各社交媒體類網站網頁url地址列表初始采集目標數據源列表url_init_list由url_init_listweb和url_init_listsoc組成,也即url_init_list=url_init_listweb∪url_init_listsoc。步驟四,各爬取節點在得到初始采集目標數據源列表后,確定采集目標數據源列表包含如下三個階段:階段一:比對url采集列表url索引服務器所維護的url列表(url_list)記錄著所有已爬取過的網頁url及爬取時間,如表6所示,給出了爬取中控節點的url列表:表6urlaccesstimeweborsochttp://…***web_comhttp://…***sochttps://…***web_edu………………https://…***soc其中,accesstime記錄網頁的初次訪問時間,weborsoc用于區分網頁是來自于社交媒體類網站還是新聞類網站,同時根據新聞類網站后綴不同又將新聞類網站網頁分為com、net、edu、gov四種類型。爬取節點首先將url_init_list與url_list進行比對,查看url_init_list中的每條url地址是否采集過,若未采集則將此條url放入中間采集目標數據源列表url_intermed_list,并在url_intermed_list中記錄此url為新增地址,否則轉入階段二;階段二:比對url采集時間若url_init_list中某條url地址已存在于url列表,說明已經采集過此url地址中的數據,然而新聞類網站和社交媒體類網站的數據不斷更新,在網頁活躍期內仍需持續采集更新數據。斯坦福大學的cho和garcia-monlina指出網頁更新時間間隔符合指數分布,不同類型網頁更新頻率不同。本發明分別統計社交媒體類網站網頁、com網站網頁、net網站網頁、edu網站網頁和gov網站網頁的平均更新時間作為重訪時間標準。因此,當url_init_list中某條url地址已存在于url_list中,則首先判斷該url地址的網頁類型,將當前時間與該url地址的初次訪問時間對比,若兩者的時間差小于相應網頁的重訪時間標準,則將此url地址放入url_intermed_list,否則不再采集該url地址數據。階段三:混排中間采集目標數據源列表有限的外網ip地址在大規模信息采集中是極其珍貴的資源,在一定時間內無節制頻繁地訪問同一新聞類網站或社交媒體類網站,會受到目標數據服務器的拒絕,這將成為影響信息采集的制約因素。為充分使用有限的外網ip地址,與其他爬蟲系統不同,本發明避免集中采集同一新聞類網站或社交媒體類網站url地址,將url_intermed_list中的url地址進行混排生成最終采集目標數據源列表url_final_list。如圖3所示,給出了中控節點生成的采集目標數據源列表,圖4給出了本發明中爬取中控節點生成url_final_list的流程圖,首先將url_intermed_list中的url地址按照主機分組劃分成若干子列表,然后采用隨機方法隨機挑選一個子列表,并在該子列表中隨機選擇一個未被選中過的url地址放入url_final_list,迭代子列表和url地址的選擇過程直至選完所有子列表的所有url地址。此外,為避免同一新聞類網站或社交媒體類網站的多次域名尋址節省帶寬,爬取節點可在一次訪問后記錄新聞類網站和社交媒體類網站的ip地址。在url_intermed_list中被標識為新增地址的url在混排到url_final_list時,同樣被標識為新增地址。本發明采用url+標識在url_intermed_list與url_list對比中未出現在url_list中的url地址,也即之前未采集過的網頁url地址。步驟五,爬取節點在得到采集目標數據源列表后,采集網頁數據包含如下兩個階段:階段一:采集url_final_list中各url所指向網頁數據1、從url_final_list中取出一條url地址。2、通過當前vpn鏈路采集url地址所指向的網頁數據。3、監測返回結果,3-1若返回結果為網頁數據,3-1-1統計當前網頁采集花費時間,并緩存采集結果,存放到混排的結果列表data_init_list中,表7給出了混排的結果列表,其中weborsoc記錄網頁的類型,用于區分該網頁是新聞類網站類網頁還是社交媒體類網站類網頁;host記錄網頁的來源新聞類網站或來源社交媒體類網站;keyword記錄社交媒體類網站類網頁所對應的檢索關鍵詞,新聞類網站類網頁則為空值none;cost記錄網頁采集花費的時間;page存儲網頁的具體內容。表7urlweborsochostkeywordcostpageurl1web***none******url2soc************url3web***none******………………………………urlnsoc************3-1-2若所采集的url地址被標識為新增地址時,則向url索引服務器發送url_list更新請求。3-2若返回結果為服務器拒絕訪問或其他vpn相關錯誤,3-2-1若vpn列表的recentlyused有標識為n的vpn連接,則在標識為n的vpn連接中,通過當前時間與vpn列表中的starttime對比,選擇一個最久未使用vpn連接,在連接成功后將starttime記錄為當前時間,標識該vpn連接的recentlyused為y,轉入3-2-2;若vpn列表的recentlyused全部標識為y,則轉入3-2-3。3-2-2使用新的vpn連接采集網頁數據,若返回結果為網頁數據,則將vpn列表中除此vpn連接的其他recentlyused標識為n,轉入3-1;若仍出現相同錯誤,轉入3-2-1。3-2-3爬取節點向爬取主控節點申請新的vpn連接,若成功申請到新的vpn連接則將此vpn加入vpn連接列表,并將recentlyused標識為n,轉入3-2-1;若未申請到vpn連接,則轉入3-2-4。3-2-4將該url主機地址及當前時間記錄到host_disable_list,刪除url_final_list中與此url主機地址相同的未采集url,并將vpn列表中除此vpn連接的其他recentlyused標識為n,轉入1。4、迭代本階段中的步驟1至步驟3直至url_final_list為空。階段二:計算新聞類網站及社交媒體類網站權重,將采集結果發送到數據中心1、在完成本輪url_final_list的采集后,重新分組data_init_list,1-1對于新聞類網頁按照網站分組,存放到新聞類網站結果列表data_final_listweb。1-2對于社交媒體類類網頁按照社交媒體類網站分組后,再按照網頁所對應關鍵詞進行分組,存放到社交媒體類網站結果列表data_final_listsoc。2、計算新聞類網站采集時間和社交媒體類網站各關鍵詞相關信息采集時間,記錄到爬取節點采集時間表,其邏輯結構如表8和表9所示:表8webcostroundwebj******webj+1******………………webk******表9表8給出了爬取節點記錄的新聞類網站的采集時間表,表9給出了所記錄的社交媒體類網站的采集時間表,其中cost記錄各新聞類網站和社交媒體類網站的各關鍵詞采集所花費的時間,round記錄本輪url_final_list采集完成時間。2-1匯總data_final_listweb中同一新聞類網站所有網頁的采集時間,記錄到新聞類網站采集時間表,如表8所示。2-2匯總中同一社交媒體類網站同一關鍵詞所有網站的采集時間,記錄到社交媒體類網站采集時間表,如表9所示。3、將data_final_listweb和data_final_listsoc打包,發送給數據中心,轉入步驟三。步驟六,url索引服務器維護更新url列表url索引服務器在接收到爬取節點發送的url_list更新請求后,將url地址添加到url_list中,并將訪問時間設置為當前時間。為提高檢索速度,url_list可采用倒排索引機制。步驟七,各爬取節點向數據中心發送爬取結果各爬取節點逐一采集各自目標數據源列表中每條url數據源,將采集結果緩存至本地,在完成任務列表中所有數據源的采集后,按照批處理的方式將采集到的數據一次性發送到數據中心。數據中心將統一負責接收并按照規定的存儲格式,對采集結果進行解析存儲。步驟八,各爬取節點向爬取主控節點匯報以下兩種狀態:1、心跳狀態各爬取節點按照約定時間,定時向爬取主控節點發送心跳信號,以表明爬取節點仍處于活動狀態。爬取主控節點若在約定時間內未收到爬取節點的心跳信號,則認為爬取節點宕機,反之則認為爬取節點工作正常。當爬取主控節點收到新的心跳信號時則認為有新的爬取節點加入。2、信息采集情況各爬取節點按照約定時間,定時將各自的采集時間表發送到爬取主控節點,發送成功后清空本地表。步驟九,爬取主控節點調節各爬取節點負載的方案如下:該步驟中所述的爬取主控節點根據所匯報的狀態調節負載具體通過以下步驟來實現:i-1).獲取采集時間表,各爬取節點定時將所記錄的新聞類網站的采集時間表和社交媒體類網站的采集時間表發送至爬取主控節點,爬取主控節點將其存儲至本地的信息采集匯總時間表中;新聞類網站的采集時間表由各新聞類網站及采集網站所花費的時間cost、采集網站的完成時間round組成;執行步驟i-2);i-2).計算平均訪問時間和權重,爬取主控節點以天為單位,在一天結束時分析當天的信息采集匯總時間表,按新聞類網站匯總當天多輪采集時間,計算當天每個新聞類網站的一輪抓取所需平均訪問時間,按社交媒體類網站關鍵詞匯總當天多輪采集時間,計算當天每個社交媒體類網站的每個關鍵詞抓取所需平均訪問時間;按照公式(1)計算各新聞類網站的權重;按照公式(2)計算各社交媒體類網站的各關鍵詞的權重;各爬取節點的社交媒體類網站的關鍵詞負載均衡調節通過步驟i-3)至步驟i-10)來實現;i-3).判斷耗時時間差,爬取主控節點計算出各爬取節點完成某社交媒體類網站的關鍵詞一輪抓取所需平均訪問時間,找出耗時最長和最短的爬取節點,計算兩者耗時時間差,若兩者時間差不大于用戶預設調節時間差閾值,則維持當前社交媒體類網站關鍵詞的分配狀態,均衡負載結束;若兩者時間差大于用戶預設調節時間差閾值,則執行步驟i-4);i-4).關鍵詞排序,爬取主控節點按照權重降序排列該社交媒體類網站的關鍵詞,執行步驟i-5);i-5).重新分配關鍵詞,爬取主控節點從排好序的關鍵詞中,依次取出第1至第ncl個關鍵詞順序分配給spider1、spider2、…、spiderncl,然后依次取出第ncl+1至第2ncl個關鍵詞逆序分配給spider1、spider2、…、spiderncl,迭代該過程,直至分完該社交新聞類網站的所有關鍵詞,將此關鍵詞的分配記錄為初始狀態kw_init_assignment,spideri代表第i個爬取節點,i≤ncl;執行步驟i-6);i-6).迭代次數清零,抽取kw_init_assignment狀態中所有爬取節點中所有關鍵詞的權重,并計算爬取節點所分配關鍵詞權重的方差variance_init,并將迭代次數iteration清零,令iteration=0;i-7).迭代次數加1,令iteration=iteration+1,然后判斷迭代次數iteration是否小于指定迭代次數iteration_threshold,若是,則令本次迭代的方差variance_miniteration等于初始狀態方差,variance_miniteration=variance_init,執行步驟i-8);否則,執行步驟i-10);i-8).交換關鍵詞,隨機選擇兩個爬取節點,并在所選擇的爬取節點中隨機選擇兩個關鍵詞進行交換,然后重新抽取所有爬取節點中所有關鍵詞的權重,計算權重方差variance_random;執行步驟i-9);i-9).比較權重方差的大小,比較variance_random與variance_miniteration的大小;如果variance_random<variance_miniteration,則保持兩個關鍵詞的交換,將variance_random賦值給variance_miniteration,令variance_miniteration=variance_random,并將交換失敗計數counter清零,令counter=0;variance_miniteration為所記錄關鍵詞權重方差的最小值,執行步驟i-8);如果variance_random≥variance_miniteration,則撤銷兩個關鍵詞的交換,并使交換失敗計數counter加1,即令counter=counter+1;若交換失敗計數counter的值小于累計次數閾值counter_threshold,轉入步驟i-8);若counter≥counter_threshold,將此關鍵詞的分配記錄為第iteration次迭代狀態kw_intermediteration_assignment,轉入步驟i-7);i-10).選取最優狀態進行分配,比較多個kw_intermediteration_assignment中的關鍵詞權重方差variance_miniteration的值,將variance_miniteration值最小的kw_intermediteration_assignment記錄為關鍵詞分配最終狀態kw_final_assignment,按照此最終狀態更新爬取節點任務分配表,并按此表重新為各個爬取節點分配任務;各爬取節點的新聞類網站的負載均衡調節采用與步驟i-3)至步驟i-10)相同的方法,只需將步驟i-3)至步驟i-10)中社交媒體類網站的關鍵詞替換為新聞類網站即可。當爬取節點只應用于信息采集時,服務器負載即為兩類數據源的采集工作。此時,當采集任務均衡時,可認為各節點的負載也較為均衡。步驟i-2)所計算的新聞類網站和社交媒體類網站關鍵詞權重描述了采集任務的繁重程度,因此通過均勻地分配新聞類網站和社交媒體類網站關鍵詞,從而使得各爬取節點的權重和相似,即可達到均衡爬取節點負載的目的。此外,為滿足用戶需求,系統所需的vpn個數和爬取節點個數計算方法如下所示:1、vpn個數對社交媒體類網站的大規模采集對外網ip地址的要求遠高于新聞類網站的采集,因此本發明所需的vpn個數主要受限于社交媒體類網站的關鍵詞,可通過如下公式大致估算:其中vpns表示所需vpn連接數,nsearchpage表示檢索結果頁鏈接個數,nvpn_ip表示社交媒體類網站允許一個ip地址采集的頁數。2、爬取節點個數本發明所需爬取節點的個數可通過如下公式大致估算:其中clients表示需要爬取節點的個數,expecttime表示完成一輪采集所花費的期望時間,accesstime表示連接遠程服務器及采集數據時間,vpnlinktime表示vpn單次連接時間。當前第1頁12
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1