基于機器學習的耐鹽大豆全基因組選擇方法、系統及應用
本發明屬于耐鹽大豆全基因組選擇,特別涉及一種基于機器學習的大豆耐鹽性狀的全基因組選擇技術及其應用。
背景技術:
1、大豆(glycine?max)是世界第四大作物和種植面積最大的油料作物,穩定或增加國產大豆供給對維護國家糧油安全和農業可持續發展具有重要的戰略意義。目前,由于全球氣候變化、不合理灌溉和化肥施用不當等問題,超過20%的耕地受到鹽脅迫的影響,土壤鹽堿化問題日益突出,嚴重威脅我國糧食安全。因此,開發耐鹽堿大豆品種,提高大豆的產量和品質,提高土地利用率,增加農民收入和農業經濟效益,促進我國農業可持續發展均具有重要的理論和實踐意義。
2、目前大豆耐鹽堿研究基礎相對薄弱,存在耐鹽堿鑒定技術體系不完善、育種效率低等突出問題。傳統選育模式主要依靠具體表型觀測和育種者的經驗,結合簡單的生物統計學分析,伴隨著隨機性大、效率低下、綜合評價能力弱和育種周期長等一系列問題。而全基因組選擇技術是一種通過基因型預測個體表型的選擇育種新策略,其可以有效縮減傳統表型選擇帶來的高昂田間成本,提升了育種效率。
3、然而,早期的基因組選擇技術用到的遺傳變異位點較少,使用傳統的統計學方法,如回歸方法等,表型預測精度仍有待提高。隨著高通量測序和人工智能的發展,全基因組重測序和機器學習方法逐漸應用于作物基因組選擇育種中。現有的基因組選擇方法多采用全snp數據分析,忽視了某些關鍵snp對表型的重要影響,這可能導致預測結果不夠理想。現有機器學習預測模型在snp數據的特征提取與融合上可能存在一定局限性,從而影響預測精度。
4、因此,如何提升耐鹽大豆的篩選精度,成為了育種領域亟待解決的問題。
技術實現思路
1、為解決現有技術中的上述問題,本發明提供了一種基于機器學習的耐鹽大豆全基因組選擇技術。
2、根據本發明第一實施例,提供了一種基于機器學習的耐鹽大豆全基因組選擇方法,包含以下步驟:
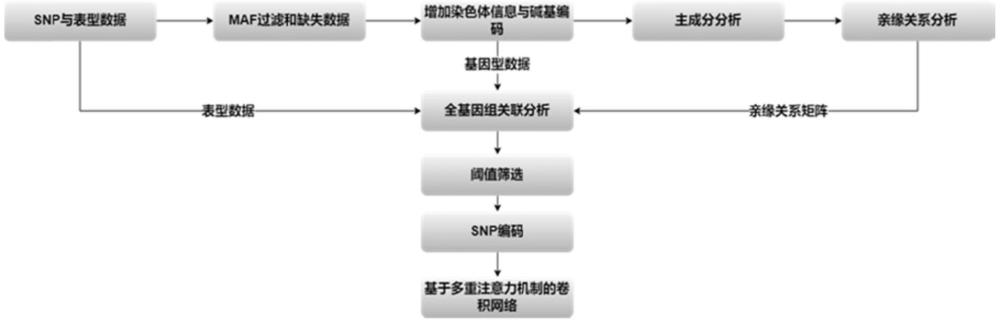
3、1)數據獲取:獲取大豆群體材料及其全基因組重測序數據;測定大豆群體鹽處理前后的葉片焦枯指數、na+、k+、ca2+、cl-含量等表型。對snp進行嚴格質控,刪除缺失率較高的個體,對snp位點的缺失率、雜合率以及次等位基因頻率(minor?allele?frequency,maf)進行詳細檢查和篩選。
4、2)大豆耐鹽表型的全基因組關聯分析(genome-wide?association?study,gwas):利用plink對群體結構進行分析并估計樣本間的親緣關系,同時通過混合線性模型對基因型和表型進行關聯分析,結合群體結構的遺傳相關性矩陣和親緣關系矩陣以減少潛在的混雜效應,獲得高質量的與表型顯著關聯的snp位點。
5、3)建立模型:選取與表型顯著相關的snp作為模型的輸入特征。將大豆重測序數據集分成訓練集和測試集,使用機器學習方法對訓練集進行訓練后,建立模型。采用ca(coordinate?attention)注意力機制和多重殘差模塊的卷積神經網絡建立預測模型,所構建的模型為rescanet。
6、4)模型準確度評估:將與鹽脅迫表型顯著關聯的snp位點和鹽脅迫表型輸入到線性回歸和機器學習svr模型中進行預測。比較線性回歸(linear?regression,lr)、svr和rescanet模型的預測準確度和均方誤差(mean?squared?error,mse)。rescanet預測模型的準確度相較于lr和svr模型極顯著提高,mse顯著降低。
7、本發明的第二實施例,提供了一種將前一實施例中的基于機器學習的耐鹽大豆全基因組選擇系統,所述系統包括以下模塊:
8、1)基因型獲取模塊:獲取大豆種質資源群體的鹽處理后葉片焦枯、na+、k+、ca2+、cl-含量表型,獲得大豆種質資源重測序數據;利用鹽脅迫表型全基因組關聯分析,篩選高質量snp位點;
9、2)模型建立模塊:針對大豆鹽脅迫表型和基因型數據集,采用五折交叉驗證,針對每一折將數據分為五個子集,其中四個子集用于訓練,剩余的一個子集用于測試,并計算皮爾遜相關系數pcc;引入ca注意力機制模塊和兩重殘差模塊建立大豆鹽脅迫機器學習預測模型rescanet;
10、3)待測鹽脅迫表型的大豆群體表型預測模塊:輸入待預測的大豆群體基因型數據snp,使用大豆鹽脅迫表型機器學習rescanet模型,預測大豆群體中每個個體的鹽脅迫表型;根據預測表型選擇耐鹽大豆品種進行田間表型實驗。
11、本發明的第三實施例,提供了一種將前一實施例中的基于機器學習的耐鹽大豆全基因組選擇技術在篩選和鑒定耐鹽大豆中的應用,包含以下步驟:
12、1)獲取待檢測的大豆樣本,對其進行全基因組重測序;
13、2)獲得待檢測樣本的全基因組snp位點;
14、3)對snp進行嚴格質控,刪除缺失率較高的個體,對snp位點的缺失率、雜合率以及次maf進行詳細檢查和篩選。
15、4)選取與表型顯著相關的snp位點輸入機器學習rescanet預測模型,進行大豆鹽脅迫的表型預測。
16、本發明的第四實施例,提供了一種將前一實施例中的基于機器學習的耐鹽大豆全基因組選擇技術在大豆品種選育或輔助大豆育種中的應用,包含以下步驟:
17、1)獲取待檢測的大豆樣本,對其進行全基因組重測序;
18、2)獲得待檢測樣本的全基因組snp位點;
19、3)對snp進行嚴格質控,刪除缺失率較高的個體,對snp位點的缺失率、雜合率以及次maf進行詳細檢查和篩選。
20、4)選取與表型顯著相關的snp位點輸入機器學習rescanet預測模型,進行大豆鹽脅迫的表型預測。
21、5)確定模塊,用于結合耐鹽大豆選擇和育種,根據表型數據預測結果,選擇具有耐鹽潛力的大豆品種進行實驗室和田間的耐鹽選擇。
22、本發明實施例提供的基于機器學習的耐鹽大豆全基因組選擇技術,首先對用于建模的大豆群體的基因型和鹽脅迫表型進行考察,利用機器學習的ca注意力機制和多重殘差模塊的卷積神經網絡構建模型,利用該模型預測待測大豆樣本的鹽脅迫表型,指導耐鹽大豆選擇育種。
23、本實例的有益效果為,能夠有效預測大豆鹽脅迫表型,降低田間選育成本,顯著提高耐鹽大豆育種效率。預測模型的優點為:
24、1.通過選取與表型顯著相關的snp作為模型的輸入特征,能夠聚焦于具有重要影響的變異,同時減少特征數量,提升模型訓練效率和表現。
25、2.引入多重注意力機制模塊,通過為不同遺傳變異位點分配多個注意力權重,模型能夠在不同層次上同時關注關鍵位點的多種特征。這種方法能夠有效捕捉復雜的遺傳關聯,提升模型對不同遺傳變異位點重要性的區分能力,從而更精準地識別與表型相關的遺傳變異。
26、3.引入ca注意力機制,能夠根據每個特征通道的重要性自適應地調整其權重。這種機制通過增強重要通道的特征響應,抑制不相關或冗余的通道,從而幫助模型更有效地聚焦于關鍵的基因特征,提升對基因數據的表達和學習能力。
- 還沒有人留言評論。精彩留言會獲得點贊!