一種AR兒童情景扮演投影教學(xué)方法及系統(tǒng)與流程
本發(fā)明涉及AR投影技術(shù)領(lǐng)域,尤其是涉及一種AR兒童情景扮演投影教學(xué)方法及系統(tǒng)。
背景技術(shù):
隨著信息技術(shù)的快速發(fā)展,視頻教學(xué)已經(jīng)走入兒童教學(xué)中,它對(duì)兒童的教學(xué)活動(dòng)起到了很大的輔助作用。兒童的興趣廣泛,思維處于具體形象思維階段,對(duì)比較抽象的事物還很難大量接受,促進(jìn)具體形象思維的發(fā)展才是早期開發(fā)兒童學(xué)習(xí)潛力的途徑。視頻教學(xué)以其形象直觀的表現(xiàn)形式,更能夠滿足兒童教學(xué)在這方面的要求。
目前兒童的視頻教學(xué)大部分是使用播放器直接播放視頻來完成,兒童故事浸入感不夠,缺少人和機(jī)器的互動(dòng),趣味性不夠,教學(xué)過程比較單調(diào)。
技術(shù)實(shí)現(xiàn)要素:
本發(fā)明的目的在于克服上述技術(shù)不足,提出一種AR兒童情景扮演投影教學(xué)方法及系統(tǒng),解決現(xiàn)有技術(shù)中兒童視頻教學(xué)浸入感不夠,缺少人和機(jī)器的互動(dòng)的技術(shù)問題。
為達(dá)到上述技術(shù)目的,本發(fā)明的技術(shù)方案提供一種AR兒童情景扮演投影教學(xué)方法,其中,包括:
S1、采集AR互動(dòng)卡片圖像、用戶面部圖像、用戶實(shí)時(shí)肢體動(dòng)作數(shù)據(jù)、用戶語音,利用深度傳感設(shè)備采集所述用戶實(shí)時(shí)肢體動(dòng)作數(shù)據(jù);
S2、識(shí)別所述AR互動(dòng)卡片圖像的信息,調(diào)用所述AR互動(dòng)卡片對(duì)應(yīng)的3D情景劇模板,所述3D情景劇模板包括3D角色模型和背景模型,所述3D角色模型由面部模型和肢體模型組成,所述背景模型為動(dòng)態(tài)或者靜態(tài);
S3、對(duì)所述用戶面部圖像進(jìn)行切割,將切割后的面部圖像合成到所述3D角色模型的所述面部模型;
S4、將所述用戶實(shí)時(shí)肢體動(dòng)作數(shù)據(jù)與所述3D角色模型的所述肢體模型進(jìn)行數(shù)據(jù)交互,控制所述3D角色模型的肢體運(yùn)動(dòng);
S5、對(duì)所述用戶語音進(jìn)行變聲處理;
S6、將S2中調(diào)用的所述3D情景劇模板轉(zhuǎn)化為投影投射在投影屏幕上,其中,所述背景模型轉(zhuǎn)化為動(dòng)態(tài)或者靜態(tài)的背景投影,所述3D角色模型根據(jù)所述用戶實(shí)時(shí)肢體動(dòng)作相應(yīng)地轉(zhuǎn)化為動(dòng)態(tài)的3D角色投影,投影的同時(shí)播放變聲處理后的所述用戶語音。
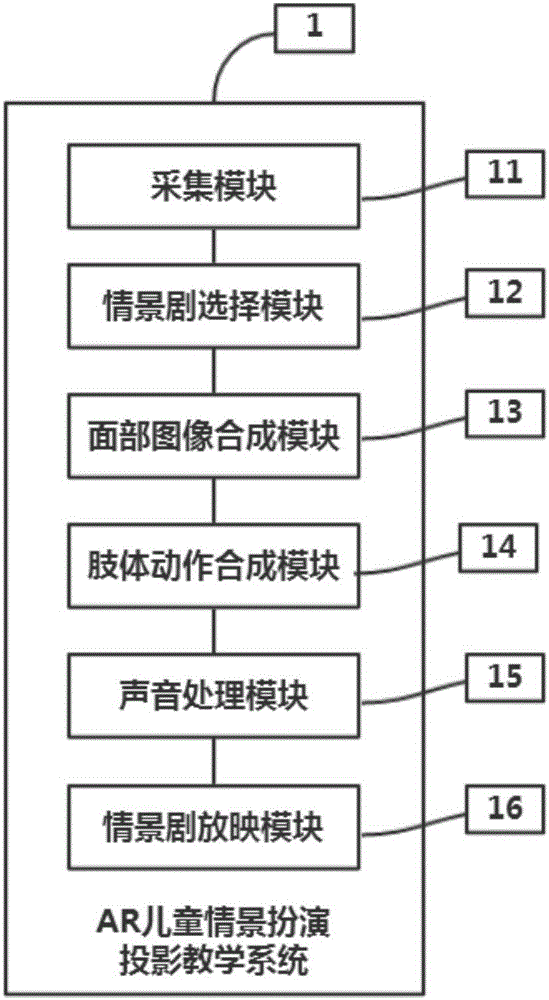
本發(fā)明的技術(shù)方案還提供一種AR兒童情景扮演投影教學(xué)系統(tǒng),其中,包括:
采集模塊:采集AR互動(dòng)卡片圖像、用戶面部圖像、用戶實(shí)時(shí)肢體動(dòng)作數(shù)據(jù)、用戶語音,利用深度傳感設(shè)備采集所述用戶實(shí)時(shí)肢體動(dòng)作數(shù)據(jù);
情景劇選擇模塊:識(shí)別所述AR互動(dòng)卡片圖像的信息,調(diào)用所述AR互動(dòng)卡片對(duì)應(yīng)的3D情景劇模板,所述3D情景劇模板包括3D角色模型和背景模型,所述3D角色模型由面部模型和肢體模型組成,所述背景模型為動(dòng)態(tài)或者靜態(tài);
面部圖像合成模塊:對(duì)所述用戶面部圖像進(jìn)行切割,將切割后的面部圖像合成到所述3D角色模型的所述面部模型;
肢體動(dòng)作合成模塊:將所述用戶實(shí)時(shí)肢體動(dòng)作數(shù)據(jù)與所述3D角色模型的所述肢體模型進(jìn)行數(shù)據(jù)交互,控制所述3D角色模型的肢體運(yùn)動(dòng);
聲音處理模塊:對(duì)所述用戶語音進(jìn)行變聲處理;
情景劇放映模塊:將情景劇選擇模塊中調(diào)用的所述3D情景劇模板轉(zhuǎn)化為投影投射在投影屏幕上,其中,所述背景模型轉(zhuǎn)化為動(dòng)態(tài)或者靜態(tài)的背景投影,所述3D角色模型根據(jù)所述用戶實(shí)時(shí)肢體動(dòng)作相應(yīng)地轉(zhuǎn)化為動(dòng)態(tài)的3D角色投影,投影的同時(shí)播放變聲處理后的所述用戶語音。
與現(xiàn)有技術(shù)相比,本發(fā)明的有益效果包括:通過切換AR互動(dòng)卡片可以切換不同情景劇投影到投影屏幕上,通過將面部圖像合成到3D角色模型,將用戶實(shí)時(shí)肢體動(dòng)作數(shù)據(jù)與3D角色模型交互,讓情景劇中的角色擁有用戶的面部特征,且可以根據(jù)用戶的動(dòng)作而做出相應(yīng)動(dòng)作,可以實(shí)現(xiàn)較強(qiáng)的人機(jī)交互,讓兒童有很強(qiáng)的故事浸入感,趣味性很強(qiáng)。
附圖說明
圖1是本發(fā)明提供的一種AR兒童情景扮演投影教學(xué)方法流程圖;
圖2是本發(fā)明提供的一種AR兒童情景扮演投影教學(xué)系統(tǒng)結(jié)構(gòu)框圖。
附圖中:1、AR兒童情景扮演投影教學(xué)系統(tǒng),11、采集模塊,12、情景劇選擇模塊,13、面部圖像合成模塊,14、肢體動(dòng)作合成模塊,15、聲音處理模塊,16、情景劇放映模塊。
具體實(shí)施方式
為了使本發(fā)明的目的、技術(shù)方案及優(yōu)點(diǎn)更加清楚明白,以下結(jié)合附圖及實(shí)施例,對(duì)本發(fā)明進(jìn)行進(jìn)一步詳細(xì)說明。應(yīng)當(dāng)理解,此處所描述的具體實(shí)施例僅僅用以解釋本發(fā)明,并不用于限定本發(fā)明。
如圖1,本發(fā)明提供了一種AR兒童情景扮演投影教學(xué)方法,其中,包括:
S1、采集AR互動(dòng)卡片圖像、用戶面部圖像、用戶實(shí)時(shí)肢體動(dòng)作數(shù)據(jù)、用戶語音,利用深度傳感設(shè)備采集用戶實(shí)時(shí)肢體動(dòng)作數(shù)據(jù);
S2、識(shí)別AR互動(dòng)卡片圖像的信息,調(diào)用AR互動(dòng)卡片對(duì)應(yīng)的3D情景劇模板,3D情景劇模板包括3D角色模型和背景模型,3D角色模型由面部模型和肢體模型組成,背景模型為動(dòng)態(tài)或者靜態(tài);
S3、對(duì)用戶面部圖像進(jìn)行切割,將切割后的面部圖像合成到3D角色模型的面部模型;
S4、將用戶實(shí)時(shí)肢體動(dòng)作數(shù)據(jù)與3D角色模型的肢體模型進(jìn)行數(shù)據(jù)交互,控制3D角色模型的肢體運(yùn)動(dòng);
S5、對(duì)用戶語音進(jìn)行變聲處理;
S6、將S2中調(diào)用的3D情景劇模板轉(zhuǎn)化為投影投射在投影屏幕上,其中,背景模型轉(zhuǎn)化為動(dòng)態(tài)或者靜態(tài)的背景投影,3D角色模型根據(jù)用戶實(shí)時(shí)肢體動(dòng)作相應(yīng)地轉(zhuǎn)化為動(dòng)態(tài)的3D角色投影,投影的同時(shí)播放變聲處理后的用戶語音。
本發(fā)明所述的AR兒童情景扮演投影教學(xué)方法,步驟S1包括:
將AR互動(dòng)卡片有圖像的一面放置到攝像頭前方10cm-15cm處,利用攝像頭采集AR互動(dòng)卡片圖像,當(dāng)識(shí)別到AR互動(dòng)卡片圖像的信息后,將攝像頭前方的互動(dòng)卡片取下,并且利用攝像頭采集用戶面部圖像,利用語音采集裝置采集用戶語音。
本發(fā)明所述的AR兒童情景扮演投影教學(xué)方法,步驟S2包括:
每一張AR互動(dòng)卡片上設(shè)置有特定圖像,識(shí)別到特定圖像的信息,調(diào)用特定的3D情景劇模板,進(jìn)而投影出特定的背景和3D角色;
每一個(gè)3D情景劇模板包含多個(gè)3D角色模型可供選擇;
切換AR互動(dòng)卡片可以切換3D情景劇模板,從而切換投影出的情景劇,情景劇由角色和角色之外的背景構(gòu)成。
本發(fā)明所述的AR兒童情景扮演投影教學(xué)方法,步驟S3包括:
使用Molioopencv技術(shù)處理用戶面部圖像,識(shí)別出人臉輪廓,然后對(duì)眼睛、嘴巴、鼻子進(jìn)行標(biāo)記切割,且在將切割后的面部圖像合成到3D角色模型的面部模型之前,將切割后的面部圖像進(jìn)行Q版化的后期處理。
本發(fā)明所述的AR兒童情景扮演投影教學(xué)方法,步驟S5包括:
根據(jù)情景劇需要,對(duì)采集的用戶語音進(jìn)行變聲處理。
本發(fā)明所述的AR兒童情景扮演投影教學(xué)方法,步驟S6包括:
3D情景劇模板的投影的播放速度可以調(diào)節(jié),3D情景劇模板的投影可以暫停、停止;
經(jīng)過S3、S4、S5步驟,3D角色模型的面部模型已經(jīng)和切割后的用戶面部圖像結(jié)合,肢體模型與用戶實(shí)時(shí)肢體動(dòng)作數(shù)據(jù)進(jìn)行交互,當(dāng)3D情景劇模板轉(zhuǎn)化為投影時(shí),投影中的角色擁有用戶的面部特征,可以根據(jù)用戶的動(dòng)作而做出相應(yīng)動(dòng)作,投影包含背景,且投影的同時(shí)播放變聲處理后的用戶語音。
如圖2,本發(fā)明提供一種AR兒童情景扮演投影教學(xué)系統(tǒng)1,其中,包括:
采集模塊11:采集AR互動(dòng)卡片圖像、用戶面部圖像、用戶實(shí)時(shí)肢體動(dòng)作數(shù)據(jù)、用戶語音,利用深度傳感設(shè)備采集用戶實(shí)時(shí)肢體動(dòng)作數(shù)據(jù);
情景劇選擇模塊12:識(shí)別AR互動(dòng)卡片圖像的信息,調(diào)用AR互動(dòng)卡片對(duì)應(yīng)的3D情景劇模板,3D情景劇模板包括3D角色模型和背景模型,3D角色模型由面部模型和肢體模型組成,背景模型為動(dòng)態(tài)或者靜態(tài);
面部圖像合成模塊13:對(duì)用戶面部圖像進(jìn)行切割,將切割后的面部圖像合成到3D角色模型的面部模型;
肢體動(dòng)作合成模塊14:將用戶實(shí)時(shí)肢體動(dòng)作數(shù)據(jù)與3D角色模型的肢體模型進(jìn)行數(shù)據(jù)交互,控制3D角色模型的肢體運(yùn)動(dòng);
聲音處理模塊15:對(duì)用戶語音進(jìn)行變聲處理;
情景劇放映模塊16:將情景劇選擇模塊12中調(diào)用的3D情景劇模板轉(zhuǎn)化為投影投射在投影屏幕上,其中,背景模型轉(zhuǎn)化為動(dòng)態(tài)或者靜態(tài)的背景投影,3D角色模型根據(jù)用戶實(shí)時(shí)肢體動(dòng)作相應(yīng)地轉(zhuǎn)化為動(dòng)態(tài)的3D角色投影,投影的同時(shí)播放變聲處理后的用戶語音。
本發(fā)明所述的AR兒童情景扮演投影教學(xué)系統(tǒng)1中,情景劇選擇模塊12:
每一張AR互動(dòng)卡片上設(shè)置有特定圖像,識(shí)別到特定圖像的信息,調(diào)用特定的3D情景劇模板,進(jìn)而投影出特定的背景和3D角色;
每一個(gè)3D情景劇模板包含多個(gè)3D角色模型可供選擇。
本發(fā)明所述的AR兒童情景扮演投影教學(xué)系統(tǒng)1中,面部圖像合成模塊13:
使用Molioopencv技術(shù)處理用戶面部圖像,識(shí)別出人臉輪廓,然后對(duì)眼睛、嘴巴、鼻子進(jìn)行標(biāo)記切割,且在將切割后的面部圖像合成到3D角色模型的面部模型之前,將切割后的面部圖像進(jìn)行Q版化的后期處理。
本發(fā)明所述的AR兒童情景扮演投影教學(xué)系統(tǒng)1中,情景劇放映模塊16:
3D情景劇模板的投影的播放速度可以調(diào)節(jié),3D情景劇模板的投影可以暫停、停止。
本發(fā)明在使用過程中,采集AR互動(dòng)卡片圖像、用戶面部圖像、用戶實(shí)時(shí)肢體動(dòng)作數(shù)據(jù)、用戶語音,利用深度傳感設(shè)備采集用戶實(shí)時(shí)肢體動(dòng)作數(shù)據(jù);識(shí)別AR互動(dòng)卡片圖像的信息,調(diào)用AR互動(dòng)卡片對(duì)應(yīng)的3D情景劇模板,3D情景劇模板包括3D角色模型和背景模型,3D角色模型由面部模型和肢體模型組成,背景模型為動(dòng)態(tài)或者靜態(tài);對(duì)用戶面部圖像進(jìn)行切割,將切割后的面部圖像合成到3D角色模型的面部模型;將用戶實(shí)時(shí)肢體動(dòng)作數(shù)據(jù)與3D角色模型的肢體模型進(jìn)行數(shù)據(jù)交互,控制3D角色模型的肢體運(yùn)動(dòng);對(duì)用戶語音進(jìn)行變聲處理;將調(diào)用的3D情景劇模板轉(zhuǎn)化為投影投射在投影屏幕上,其中,背景模型轉(zhuǎn)化為動(dòng)態(tài)或者靜態(tài)的背景投影,3D角色模型根據(jù)用戶實(shí)時(shí)肢體動(dòng)作相應(yīng)地轉(zhuǎn)化為動(dòng)態(tài)的3D角色投影,投影的同時(shí)播放變聲處理后的用戶語音。
本發(fā)明的有益效果包括:通過切換AR互動(dòng)卡片可以切換不同情景劇投影到投影屏幕上,通過將面部圖像合成到3D角色模型,將用戶實(shí)時(shí)肢體動(dòng)作數(shù)據(jù)與3D角色模型交互,讓情景劇中的角色擁有用戶的面部特征,且可以根據(jù)用戶的動(dòng)作而做出相應(yīng)動(dòng)作,可以實(shí)現(xiàn)較強(qiáng)的人機(jī)交互,讓兒童有很強(qiáng)的故事浸入感,趣味性很強(qiáng)。
以上所述本發(fā)明的具體實(shí)施方式,并不構(gòu)成對(duì)本發(fā)明保護(hù)范圍的限定。任何根據(jù)本發(fā)明的技術(shù)構(gòu)思所做出的各種其他相應(yīng)的改變與變形,均應(yīng)包含在本發(fā)明權(quán)利要求的保護(hù)范圍內(nèi)。
- 還沒有人留言評(píng)論。精彩留言會(huì)獲得點(diǎn)贊!
- 一種基于VR/AR教學(xué)方法及系統(tǒng)與流程
- 一種AR兒童情景扮演投影教學(xué)方法及系統(tǒng)與流程
- 遠(yuǎn)程教學(xué)方法與流程
- 滑雪機(jī)安全快捷換刃教學(xué)方法與流程
- 交互式無線教學(xué)方法與流程
- 課堂隨筆教學(xué)方法及系統(tǒng)與流程
- 一種無人值守的健身教練遠(yuǎn)程教學(xué)方法與制造工藝
- 多媒體電子教學(xué)方法及多媒體電子教學(xué)盒與制造工藝
- 遠(yuǎn)程教學(xué)輔助系統(tǒng)及該系統(tǒng)用遠(yuǎn)程教學(xué)方法和設(shè)備與制造工藝
- 機(jī)器人教學(xué)平臺(tái)及其教學(xué)方法與制造工藝
- 一種無線4d數(shù)字互動(dòng)教學(xué)系統(tǒng)及教學(xué)方法
- 教學(xué)方法及處理系統(tǒng)的制作方法
- 通過仿真手段展示數(shù)據(jù)的方法和裝置制造方法
- 用于產(chǎn)生免疫球蛋白樣分子的方法和手段的制作方法
- 用于產(chǎn)生免疫球蛋白樣分子的方法和手段的制作方法
- 系統(tǒng)化教學(xué)方法
- 教學(xué)方法及系統(tǒng)的制作方法
- 一種輔助學(xué)校教育的遠(yuǎn)程教學(xué)方法及系統(tǒng)的制作方法
- 用于x線機(jī)操作系統(tǒng)功能仿真實(shí)驗(yàn)平臺(tái)的教學(xué)方法
- 遠(yuǎn)程移動(dòng)即時(shí)影像語言教學(xué)方法